视频分割方法、设备、计算机设备及介质
文献发布时间:2023-06-19 11:14:36
技术领域
本申请涉及图像自动化处理领域,特别是涉及一种视频分割方法、设备、计算机设备及介质。
背景技术
视频压缩算法及应用的快速发展,带来了海量的视频数据。视频中蕴含了丰富的信息,然而,由于视频数据巨大,不像文字直接表示出了抽象概念,因此视频信息的提取及结构化相对复杂。目前,视频信息的提取方法主要是先对视频进行分割,然后给分割后的每个片段分类打上标签,是视频信息提取及结构化的一种思路。基于传统的计算机视觉对视频进行分割,一般需要人工设计图像特征,这样设计的特征不能灵活的适应各种场景的变化。目前大部分实际可用的视频分割仅仅根据每帧的颜色信息,经过各种传统计算机视觉的变换,检测相邻两帧的变化,从而确定视频分割点,然后继续利用机器学习中的聚类算法,对分割好的相邻的视频片段进行聚合,相似类别的会归为一类。然而,上述这些方法只能完成粗浅的分割,并且不能识别出视频中每个片段的语义。
发明内容
本申请的目的在于克服上述问题或者至少部分地解决或缓减解决上述问题。
根据本申请的一个方面,提供了一种视频分割方法,包括:
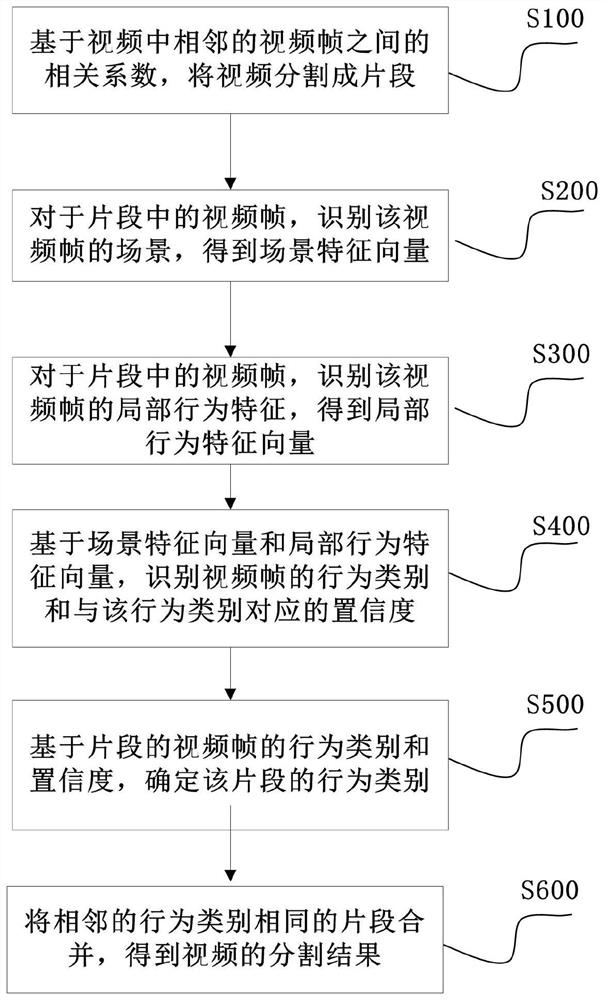
片段分割步骤:基于视频中相邻的视频帧之间的相关系数,将所述视频分割成片段;
场景识别步骤:对于所述片段中的视频帧,识别该视频帧的场景,得到场景特征向量;
局部行为特征识别步骤:对于所述片段中的视频帧,识别该视频帧的局部行为特征,得到局部行为特征向量;
视频帧行为类别判断步骤:基于所述场景特征向量和所述局部行为特征向量,识别所述视频帧的行为类别和与该行为类别对应的置信度;
片段行为类别确定步骤:基于所述片段的视频帧的行为类别和置信度,确定该片段的行为类别;
片段合并步骤:将相邻的行为类别相同的片段合并,得到所述视频的分割结果。
该方法能够同时对双路模型进行融合,综合利用场景和局部行为两个维度,对整体行为信息进行提取,从而快速地对视频进行分割。
可选地,所述片段分割步骤包括:
直方图计算步骤:计算所述视频的每一个视频帧的YCbCr直方图;
相关系数计算步骤:计算该视频帧的YCbCr直方图与前一个视频帧的YCbCr直方图的相关系数;
阈值比较步骤:在所述相关系数小于预定的第一阈值时,将该视频帧作为新的片段的起始帧。
可选地,所述场景识别步骤包括:
分辨率转化步骤:将所述视频帧的RGB通道分别转化为固定尺寸的分辨率;和
场景特征向量生成步骤:将经过分辨率转化后的视频帧输入到第一网络模型中,得到该视频帧的场景特征向量,其中,所述第一网络模型为:去掉最后一层全连接层和Softmax分类器的VGG16网络模型。
可选地,所述局部行为特征识别步骤包括:
最短边长固定步骤:将所述视频帧的RGB通道分别转化为最短边长固定的分辨率;和
局部行为特征向量生成步骤:将最短边长固定的视频帧输入到第一网络模型中,将所述第一网络模型的输出结果输入到基于区域的卷积神经网络(FasterRCNN)模型中,利用所述基于区域的卷积神经网络的输出结果计算最优检测类别结果,将所述最优检测类别结果经过感兴趣区域池化层得到局部行为特征向量。
可选地,所述视频帧行为类别判断步骤包括:
视频帧特征向量合并步骤:将所述场景特征向量和所述局部行为特征向量合并为视频帧特征向量;和
行为类别和置信度计算步骤:将所述视频帧特征向量输入到第三网络,得到所述视频帧的行为类别和与该行为类别对应的置信度,其中,所述第三网络由4个全连接层与Softmax分类器依次连接形成。
可选地,所述片段行为类别判断步骤包括:在行为类别相同的视频帧数量与所述片段的视频帧总数量的比值大于预定的第二阈值的情况下,将该行为类别作为该片段的行为类别。
根据本申请的另一个方面,还提供了一种视频分割装置,包括:
片段分割模块,其配置成用于基于视频中相邻的视频帧之间的相关系数,将所述视频分割成片段;
场景识别模块,其配置成用于对于所述片段中的视频帧,识别该视频帧的场景,得到场景特征向量;
局部行为特征识别模块,其配置成用于对于所述片段中的视频帧,识别该视频帧的局部行为特征,得到局部行为特征向量;
视频帧行为类别判断模块,其配置成用于基于所述场景特征向量和所述局部行为特征向量,识别所述视频帧的行为类别和与该行为类别对应的置信度;
片段行为类别确定模块,其配置成用于基于所述片段的视频帧的行为类别和置信度,确定该片段的行为类别;和
片段合并模块,其配置成用于将相邻的行为类别相同的片段合并,得到所述视频的分割结果。
该装置能够同时对双路模型进行融合,综合利用场景和局部行为两个维度,对整体行为信息进行提取,从而快速地对视频进行分割。
根据本申请的另一个方面,还提供了一种计算机设备,包括存储器、处理器和存储在所述存储器内并能由所述处理器运行的计算机程序,其中,所述处理器执行所述计算机程序时实现如上所述的方法。
根据本申请的另一个方面,还提供了一种计算机可读存储介质,优选为非易失性可读存储介质,其内存储有计算机程序,所述计算机程序在由处理器执行时实现如上所述的方法。
根据本申请的另一个方面,还提供了一种计算机程序产品,包括计算机可读代码,当所述计算机可读代码由计算机设备执行时,导致所述计算机设备执行如上所述的方法。
根据下文结合附图对本申请的具体实施例的详细描述,本领域技术人员将会更加明了本申请的上述以及其他目的、优点和特征。
附图说明
后文将参照附图以示例性而非限制性的方式详细描述本申请的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分。本领域技术人员应该理解,这些附图未必是按比例绘制的。附图中:
图1是根据本申请的视频分割方法的一个实施例的示意性流程图;
图2是本申请的行为预测网络的示意性框图;
图3是训练本申请的行为预测网络的示意性框图;
图4是根据本申请的视频分割装置的一个实施例的示意性框图;
图5是本申请的计算设备的一个实施例的框图;
图6是本申请的计算机可读存储介质的一个实施例的框图。
具体实施方式
根据下文结合附图对本申请的具体实施例的详细描述,本领域技术人员将会更加明了本申请的上述以及其他目的、优点和特征。
本申请的实施方案提供了一种视频分割方法,图1是根据本申请的视频分割方法的一个实施例的示意性流程图。该方法可以包括:
S100片段分割步骤:基于视频中相邻的视频帧之间的相关系数,将所述视频分割成片段;
S200场景识别步骤:对于所述片段中的视频帧,识别该视频帧的场景,得到场景特征向量;
S300局部行为特征识别步骤:对于所述片段中的视频帧,识别该视频帧的局部行为特征,得到局部行为特征向量;
S400视频帧行为类别判断步骤:基于所述场景特征向量和所述局部行为特征向量,识别所述视频帧的行为类别和与该行为类别对应的置信度;
S500片段行为类别确定步骤:基于所述片段的视频帧的行为类别和置信度,确定该片段的行为类别;
S600片段合并步骤:将相邻的行为类别相同的片段合并,得到所述视频的分割结果。
本申请提供的方法能够同时对双路模型进行融合,综合利用场景和局部行为两个维度,对整体行为信息进行提取,从而快速地对视频进行分割。本发明利用深度学习技术,从人的行为类别的维度对视频进行分割。一方面,使用深度学习技术可以提取更加抽象的通用特征,另一方面,视频中的动态信息及因果事件主要由人的行为定义,因此按照人的行为类别对视频进行分割也是最为合理的。
可选地,所述S100片段分割步骤可以包括:
S101直方图计算步骤:计算所述视频的每一个视频帧的YCbCr直方图;
S102相关系数计算步骤:计算该视频帧的YCbCr直方图与前一个视频帧的YCbCr直方图的相关系数;和
S103阈值比较步骤:在所述相关系数小于预定的第一阈值时,将该视频帧作为新的片段的起始帧。
颜色空间可以包括:RGB、CMY(三基色)、HSV(Hue,Saturation,Value,色调、饱和度、亮度)、HIS(Hue,Saturation,Intensity,色调、饱和度、强度)、YCbCr。其中YCbCr的Y是指亮度分量,Cb指蓝色色度分量,Cr指红色色度分量。以YCbCr为例,在一个可选实施方案中,对视频进行片段分割:
基于YCbCr颜色空间,对所述帧的YCbCr数据进行归一化处理,构建归一化后YCbCr直方图,该直方图的横轴表示归一化的级数,纵轴表示所述级数对应的像素点数量。归一化处理时,可选地,可以把Y、Cb、Cr别分为16份、9份、9份,即16-9-9模式,此时归一化的级数取值为16+9+9=34。确定级数并进行归一化处理的原因是考虑到人类的视觉分辨能力和计算机的处理速度,因此按照颜色的不同范围和主观颜色感知进行间隔不等的归一化处理,即量化处理。
利用下式计算所述帧与该帧的前一帧之间的相关系数d(H
其中,l表示归一化的级数,bins1表示归一化的总级数,H
将所述第一相似度与第一阈值进行比较,若所述第一相似度小于第一阈值,表明该帧有很大可能是新片段(clip)的起始帧,则将该帧作为新片段的起始帧。第一阈值可以根据实验及实际应用确定。可选地,第一阈值取0.85。
针对步骤S103中粗略切割的每段视频clip(i),其中,i表示每段视频的序号,每秒截取一帧图像,送入行为预测网络,网络输出行为的标识符(id),用clip(i)_frame(j)_id表示,并且输出对应的相应的置信度clip(i)_frame(j)_confidence。行为预测网络是专门用于行为预测的网络,每个行为与一个id一一对应。行为预测网络可以包括第一网络模型、第二网络模型和第三网络模型。下面描述单帧图像经过该行为预测网络最终得到行为类别的流程。
可选地,所述S200场景识别步骤可以包括:
S201分辨率转化步骤:将所述视频帧的RGB通道分别转化为固定尺寸的分辨率;和
S202场景特征向量生成步骤:将经过分辨率转化后的视频帧输入到第一网络模型中,得到该视频帧的场景特征向量,其中,所述第一网络模型为:去掉最后一层全连接层和Softmax分类器的VGG16网络模型。
图2是本申请的行为预测网络的示意性框图。图像RGB通道分别转化为尺寸固定的分辨率,例如,转化为224x224的分辨率,将转化后的视频帧输入第一网络模型,也称场景识别子网络。第一网络模型是针对预先定义的几个场景训练好的场景识别的改进的VGG16网络,该改进的VGG16网络去掉了最后的全连接层及Softmax分类器。场景识别子网络的输出为1x1x25088维的向量,记为场景特征向量place_feature_vector。
需要说明的是,视觉几何组(Visual Geometry Group,VGG)是牛津大学工程科学的一个组织,该组织通过对表情数据库进行深度学习建立的模型为VGG模型,VGG模型的特征为VGG特征,VGG特征可以包括:FC6层特征。VGG16 Net深度神经网络结构。
VGG16 Net网络结构总共包含5个堆栈式的卷积神经网络(ConvNet),每个ConvNet又由多个卷积层(Conv)组成,Conv层之后紧跟着非线性映射层(ReLU),每个ConvNet后为池化层(Pooling),最后为3个全连接层和1个soft-max(最大化层),其中每个全连接层具有4096个通道,soft-max层具有1000个通道根据具体的任务,可以选择不同的输出数目)。该网络引入较小的卷积核(3×3),增加了ReLU层,卷积层和全连接层的输入都直接连接ReLU层,同时在全连接层fc6和fc7使用了一种正则化方法(Dropout),这样的网络结构大大缩短了训练时间,增大了网络的灵活性,同时防止出现过拟合现象。本发明综合考虑网络模型的学习和表征能力、结构的灵活性以及训练时间等因素,选取VGG16 Net作为本发明的特征提取器。该模型中的矩阵调整函数(Reshape函数)是可以重新调整矩阵的行数、列数、维数的函数。
可选地,所述S300局部行为特征识别步骤可以包括:
S301最短边长固定步骤:将所述视频帧的RGB通道分别转化为最短边长固定的分辨率;和
S302局部行为特征向量生成步骤:将最短边长固定的视频帧输入到第一网络模型中,将所述第一网络模型的输出结果输入到基于区域的卷积神经网络(FasterRCNN)模型中,利用所述基于区域的卷积神经网络的输出结果计算最优检测类别结果,将所述最优检测类别结果经过感兴趣区域池化层得到局部行为特征向量。
参见图2,将所述视频帧的RGB通道分别转化为最短边长,例如600像素的分辨率,将视频帧输入第二网络模型,也称局部行为检测子网络中。第二网络模型是针对预先定义好的几个局部行为训练好的局部行为检测网络。第二网络模型可以包括:第一网络模型、FasterRCNN、最优检测模块和池化层。第二网络模型的数据处理流程是,将所述第一网络模型的输出结果输入到FasterRCNN模型中,最优检测模块利用所述基于区域的卷积神经网络的输出结果计算最优检测类别结果,将所述最优检测类别结果经过感兴趣区域(region ofinterest,ROI)池化层(Pooling Layer)得到局部行为特征向量。该第二网络模型基于FasterRCNN,但是只使用最优的检测类别。
最优检测类别基于如下量化的公式决定:针对每个FasterRCNN输出的检测目标和矩形框,例如,检测目标取softmxax输出的最大的概率值Softmax_max,矩形框的面积记为S,计算最优检测类别结果opt_detection:
opt_detection=SCALE*softmax_max+WEIGHT*S
其中,SCALE是系数,为了防止softmax_max被S的取值范围淹没;WEIGHT是针对面积的权重值。可选地,SCALE=1000,WEIGHT=0.7,表示局部行为的权重稍高于面积的权重。
最优检测类别结果经过感兴趣区域池化层将7x7x512维的输出结果转化为1x1x25088向量,记为局部行为特征向量local_action_feature_vector。在图2中,在得到局部行为特征向量后,通过FC1、FC2、FC M、Softmax M得到的结果,以及将FC2的结果输入FCM*4,利用窗口回归函数Bbox_Pred得到的结果能够用于评价局部行为特征向量的识别效果,其中M为局部行为类别。
可选地,所述S400视频帧行为类别判断步骤可以包括:
S401视频帧特征向量合并步骤:将所述场景特征向量和所述局部行为特征向量合并为视频帧特征向量;和
S402行为类别和置信度计算步骤:将所述视频帧特征向量输入到第三网络,得到所述视频帧的行为类别和与该行为类别对应的置信度,其中,所述第三网络由4个全连接层与Softmax分类器依次连接形成。
在S401中,将场景特征向量place_feature_vector和局部行为特征向量local_action_feature_vector合并为一个视频帧特征向量,该向量的大小为1x1x(25088+25088)=50176维向量,记为feature_vector,参见图2。
可选地,所述S500片段行为类别判断步骤可以包括:在行为类别相同的视频帧数量与所述片段的视频帧总数量的比值大于预定的第二阈值的情况下,将该行为类别作为该片段的行为类别。
在S402中,该视频帧特征向量feature_vector经过4层全连接层FC,FC1至FC4。其中,FC1输出4096通道,FC2输出4096通道,FC3输出1000通道,FC4输出C个类别的分数,参见图2。C可以根据实际需要的行为类别数量选择,一般选取15至30较好。FC4的输出接入Softmax分类器,最终输出每个行为类别的预测置信度。选取置信度最高的行为类别,作为该帧行为类别输出,记为clip(i)_frame(j)_id,clip(i)_frame(j)_confidence。
在S500片段行为类别确定步骤中,针对片段clip(i)中每秒截取的帧,都进行步骤S200至S400的处理,预测出每帧的行为类别。clip(i)中id相同的帧占总预测帧数的百分比记为same_id_percent。只要存在这样的id,使得same_id_percent>same_id_percent_thres,其中same_id_percent_thres表示设定的阈值,并且相同id的帧的置信度超过65%的占比超过80%。就将该id作为该片段clip(i)的行为类别输出。
在步骤S600片段合并步骤中,针对通过步骤S100粗略得到的每个片段,都进行上述的处理,得到每个片段的行为类别。如果相邻的片段的行为类别相同,就把这两个片段合并为一个片段。最终得到该视频按照行为类别分割的短视频。
应该理解的是,S300局部行为特征识别步骤和S400视频帧行为类别判断步骤并非必须按照顺序执行,也可以同时执行,或者先后执行。
图3是训练本申请的行为预测网络的示意性框图。可选地,该方法还可以包括行为预测网络的训练步骤。
对于第一网络模型,也就是场景预测网络,该网络模型使用VGG16对N个预定义场景进行分类。输出的场景类别N根据实际需求选取,一般选取30至40。例如,场景类别可以是餐厅、篮球场、音乐厅等等。训练策略如下:权重w初始化采用下式进行:
w=np.random.randn(n)*sqrt(2.0/n)
其中,np.random.randn(n)是生成随机数的函数,即对每个卷积层的每个通道的滤波器的n个权重初始化为高斯分布,可以采用numpy方法生成。利用平方根函数计算得到的sqrt(2.0/n),以保证每层的每个神经元的输入的分布方差一致。采用dropout技术来进行正则化,防止过拟合,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。每个神经元激活的概率为超参数p。池化后的结果经过两个FC4096、FC N、Softmax N后输入到代价函数。代价函数采用交叉熵损失函数cross-entropy loss(Softmax)计算得到。其中,权重更新策略采用SGD+Momentum(随机梯度下降+动量)方法实现。学习率(learningrate)按照step decay(阶跃衰变)随着训练时间降低。
对于第二网络模型,也就是局部行为预测网络,该网络使用FasterRCNN,训练方法采用FasterRCNN的标准训练方法。输出的局部行为类别M根据实际需求选取,一般选取15至30。例如,局部行为可以是吃饭、打篮球约会等。在得到局部行为特征向量后,通过两个FC4096、FC M、Softmax M得到的预测结果,以及将第二个FC 4096的结果输入FC M*4,利用窗口回归函数Bbox_Pred得到的结果能够用于评价局部行为特征向量的识别效果,其中M为局部行为类别。Softmax M和FC M*4的结果输入到由FasterRCNN定义的交叉熵损失。
第一网络模型和第二网络模型训练完成后,训练第三网络。场景网络去掉Softmax分类器和最后的几层全连接层,剩下的各层参数保持不变,最后一层池化层转化为1x1x25088维,记为视频帧特征向量。对于局部行为识别网络。训练第三网络模型时,每个图像经过该局部行为识别网络预测出多个局部行为及其位置矩形框,按照最优检测类别,选取最优检测类别,得到对应的感兴趣区域池化层的7x7x512维的向量输出,进一步转换为1x1x25088维的局部行为特征向量。场景特征向量和局部行为特征向量组合为1x1x(25088+25088)=50176维,记为视频帧特征向量。该视频帧特征向量经过4层全连接层FC1至FC4。FC4的输出依次接入Softmax C和交叉熵损失cross-entropy loss。对于第三网络模型,其他参数保持不变,只训练4层FC的参数。参数训练策略采取第一网络模型的训练策略。
对于第三网络模型预测的C个行为类别,第二网络模型预测的M个局部行为类别,第一网络模型预测的N个场景类别,可按如下方式选取。首先根据业务需求定义整体的C个行为类别,比如吃饭、打篮球、约会。然后根据这C个整体行为,对其中可能的局部行为类别进行定义,一般可以保持和整体行为一致,比如吃饭、打篮球、约会。最后根据整体行为分类,对N个可能的场景进行定义,例如,针对吃饭,可以定义餐厅、咖啡厅等场景等等。
根据本申请的另一个实施方案还提供了一种视频分割装置,图4是根据本申请的视频分割装置的一个实施例的示意性框图。该装置可以包括:
片段分割模块100,其配置成用于基于视频中相邻的视频帧之间的相关系数,将所述视频分割成片段;
场景识别模块200,其配置成用于对于所述片段中的视频帧,识别该视频帧的场景,得到场景特征向量;
局部行为特征识别模块300,其配置成用于对于所述片段中的视频帧,识别该视频帧的局部行为特征,得到局部行为特征向量;
视频帧行为类别判断模块400,其配置成用于基于所述场景特征向量和所述局部行为特征向量,识别所述视频帧的行为类别和与该行为类别对应的置信度;
片段行为类别确定模块500,其配置成用于基于所述片段的视频帧的行为类别和置信度,确定该片段的行为类别;和
片段合并模块600,其配置成用于将相邻的行为类别相同的片段合并,得到所述视频的分割结果。
本申请提供的装置能够同时对双路模型进行融合,综合利用场景和局部行为两个维度,对整体行为信息进行提取,从而快速地对视频进行分割。
可选地,所述片段分割模块100可以包括:
直方图计算模块,其配置成用于计算所述视频的每一个视频帧的YCbCr直方图;
相关系数计算模块,其配置成用于计算该视频帧的YCbCr直方图与前一个视频帧的YCbCr直方图的相关系数;和
阈值比较模块,其配置成用于在所述相关系数小于预定的第一阈值时,将该视频帧作为新的片段的起始帧。
可选地,所述场景识别模块200可以包括:
分辨率转化模块,其配置成用于将所述视频帧的RGB通道分别转化为固定尺寸的分辨率;和
场景特征向量生成模块,其配置成用于将经过分辨率转化后的视频帧输入到第一网络模型中,得到该视频帧的场景特征向量,其中,所述第一网络模型为:去掉最后一层全连接层和Softmax分类器的VGG16网络模型。
可选地,所述局部行为特征识别模块300可以包括:
最短边长固定模块,其配置成用于将所述视频帧的RGB通道分别转化为最短边长固定的分辨率;和
局部行为特征向量生成模块,其配置成用于将最短边长固定的视频帧输入到第一网络模型中,将所述第一网络模型的输出结果输入到基于区域的卷积神经网络(FasterRCNN)模型中,利用所述基于区域的卷积神经网络的输出结果计算最优检测类别结果,将所述最优检测类别结果经过感兴趣区域池化层得到局部行为特征向量。
可选地,所述视频帧行为类别判断模块400可以包括:
视频帧特征向量合并模块,其配置成用于将所述场景特征向量和所述局部行为特征向量合并为视频帧特征向量;和
行为类别和置信度计算模块,其配置成用于将所述视频帧特征向量输入到第三网络,得到所述视频帧的行为类别和与该行为类别对应的置信度,其中,所述第三网络由4个全连接层与Softmax分类器依次连接形成。
图5是本申请的计算设备的一个实施例的框图。本申请的另一个实施方案还提供了一种计算设备,该计算设备包括存储器1120、处理器1110和存储在所述存储器1120内并能由所述处理器1110运行的计算机程序,该计算机程序存储于存储器1120中的用于程序代码的空间1130,该计算机程序在由处理器1110执行时实现用于执行任一项根据本发明的方法步骤1131。
本申请另一个实施方案还提供了一种计算机可读存储介质。图6是本申请的计算机可读存储介质的一个实施例的框图,该计算机可读存储介质包括用于程序代码的存储单元,该存储单元设置有用于执行根据本发明的方法步骤的程序1131’,该程序被处理器执行。
本申请实施例还提供了一种包含指令的计算机程序产品。当该计算机程序产品。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、获取其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。
专业人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令处理器完成,所述的程序可以存储于计算机可读存储介质中,所述存储介质是非短暂性(英文:non-transitory)介质,例如随机存取存储器,只读存储器,快闪存储器,硬盘,固态硬盘,磁带(英文:magnetic tape),软盘(英文:floppy disk),光盘(英文:optical disc)及其任意组合。
以上所述,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 视频分割方法、设备、计算机设备及介质
- 核电试验视频分割方法、装置、计算机设备和存储介质