基于多粒度推理的视觉自注意力模型的压缩方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及人工神经网络的压缩与加速,尤其是涉及一种基于多粒度推理的视觉自注意力模型的压缩方法。
背景技术
注意力模型(Transformer)在自然语言处理取得巨大的成功,这启发人们将其迁移到计算机视觉领域,提出视觉自注意力模型(Vision Transformer,ViT)。ViT已经在计算机视觉领域广泛传播,并很快成为各种常见视觉任务中最普遍和最有前景的架构之一。如图像分类(Graham B,El-Nouby A,Touvron H,et al.LeViT:a Vision Transformer inConvNet's Clothing for Faster Inference[C]//Proceedings of the IEEE/CVFInternational Conference on Computer Vision.2021:12259-12269.),目标检测(Carion N,Massa F,Synnaeve G,et al.End-to-end object detection withtransformers[C]//European conference on computer vision.Springer,Cham,2020:213-229.)等。ViT的基本思想是将一副图像切割为一系列补丁(patch),并使用线性转换将这些补丁转化为输入标记(token)。ViTs的优点在于它能通过多头自注意力机制(Multi-HeadSelf-Attention,MHSA)的机制捕捉到图像不同部分之间的长距离关系。
ViT的计算量与输入标记数量的平方成正比,过高的计算成本严重阻碍ViT的落地应用。最直观的方法是通过减少推理过程中的标记数量,以达到减少计算量的目的。因为图像通常充满冗余的区域,比如背景。这一特性激发许多研究者的灵感,例如在网络前向过程中进一步放弃信息量较小的标记。PSViT(Tang Y,Han K,Wang Y,et al.Patch slimmingfor efficient vision transformers[J].arXiv preprint arXiv:2106.02852,2021.)引入一个自上而下的标记修剪范式。DynamicViT(Rao Y,Zhao W,Liu B,et al.Dynamicvit:Efficient vision transformers with dynamic token sparsification[J].Advancesin neural information processing systems,2021,34.)通过一个可学习的预测模块学习给每个标记打分,而EViT(Liang Y,Ge C,Tong Z,et al.Not all patches are whatyou need:Expediting vision transformers via token reorganizations[J].arXivpreprint arXiv:2202.07800,2022.)利用现成的类注意力来衡量标记的重要性。在DVT(Wang Y,Huang R,Song S,et al.Not all images are worth 16x16 words:Dynamicvision transformers with adaptive sequence length[J].arXiv e-prints,2021:arXiv:2105.15075.)中,多个ViT是级联的,每个图像的标记数量由早停机制确认。尽管这些标记放弃方法降低计算成本,但它们存在两个缺点:1)牺牲识别的准确性。例如,PS-ViT和尽管在DeiT-S(Touvron H,Cord M,Douze M,et al.Training data-efficient imagetransformers&distillation through attention[C]//International Conference onMachine Learning.PMLR,2021:10347-10357.)上节省1.6~2.0G FLOPs,但也使得ImageNet上的Top-1性能降低0.4%。2)引入额外训练负担。例如,DynamicViT需要训练额外的标记重要性预测模块,DVT将训练参数增加三倍。
图像的空间冗余性可以分为两种,图像间空间冗余性和图像内空间冗余性。前者指不同图像的难度不一样,例如简单图片可以使用计算量低的模型成功识别,而困难图片可能就只有计算量高的模型才能正确识别。后者指图像内部可以分为重要区域和不重要区域,通常模型能否正确识别主要是基于重要区域。例如,DynamicViT这种通过直接改变整张图片标记编码数量的工作,关注的就是图像间空间冗余性;而PSViT,DynamicViT等通过剪枝减少标记数量的工作关注的就是图像内空间冗余性。
因此,在进行ViT模型压缩训练时,现有的方法专注于单一空间冗余性。本发明既关注图像间空间冗余性,也关注图像内空间冗余性,并基于此提出一个视觉自注意力模型的多粒度推理框架。
发明内容
本发明的目的是基于现有技术存在的上述技术问题,针对ViT模型压缩,提供一种基于多粒度推理的视觉自注意力模型的压缩方法。只需应用本发明设计的训练方式,可直接从头训练得到一个ViT模型,该模型可根据输入图片的难度,自适应调整模型复杂度;与普通模型对比,本发明可以实现在压缩计算复杂度的情况下,同时性能更好。
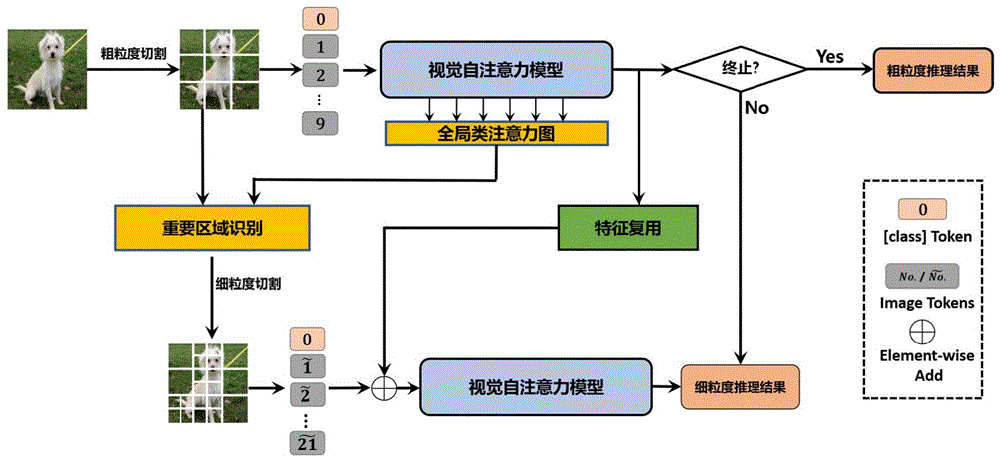
本发明包括以下步骤:
1)将图像切割成粗粒度patch,并将粗粒度patch编码成标记,输入模型进行第一阶段推理,获得粗粒度推理结果;
2)计算粗粒度推理结果的置信度,置信度超过阈值则停止推理,否则进行第二阶段推理;
3)根据全局类注意力选出重要的粗粒度patch进行进一步的细粒度切割,获取细粒度切割patch的标记编码;
4)将粗粒度推理提取到的特征经过线性变化加到细粒度标记编码上,结果输入模型进行第二阶段推理,获取细粒度推理结果;
5)训练时,粗粒度推理结果使用细粒度推理结果进行监督,细粒度推理结果采用真实标签进行监督。
在步骤1)中,所述将图像切割成粗粒度patch,并将粗粒度patch编码成标记的具体是:
将粗粒度patch对应的标记输入模型,获取粗粒度编码特征:
根据粗粒度编码特征获取粗粒度推理结果:
在步骤2)中,所述计算粗粒度推理结果的置信度具体是:
设置一个阈值η,若j>η,则停止推理,反之进行第二阶段推理。
在步骤3)中,所述全局类注意力为:
细粒度切割patch的标记编码是:
在步骤4)中,所述第二阶段推理的模型输入是:
细粒度推理结果为:
在步骤5)中,训练损失是:
loss=CE(p
本发明提出一个两阶段推理框架,在第一阶段对整张图片进行粗粒度patch切割,第二阶段对图片中信息含量高的区域进行进一步的细粒度切割;设计基于全局类注意力图的重要区域识别;设计特征复用模块,使得第二阶段可以复用第一阶段提取的特征;设计两阶段推理框架的训练范式,使得模型可以不引入额外参数。可以实现根据样本难度自适应调整模型复杂度。本发明可应用于在图像分类领域上的ViT模型,与现有牺牲识别精度的标记丢弃研究相比,本发明提供的两阶段推理架构提供更好的识别能力,大大提升模型的性能。与现有的多模型级联自适应决定标记数量的研究相比,本发明提供的两阶段推理架构不仅提供更好的识别能力,还极大的减少参数量与训练开销。
附图说明
图1为本发明的方法流程示意图。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
本发明针对当前ViT压缩造成性能损失,提出一种两阶段多粒度推理框架。使用该多粒度推理框架,可以实现无损压缩,并且可以实现一个模型根据输入图片难度自适应调整图片难度。涉及人工神经网络的压缩与加速。本发明方法简称CF-ViT。
本发明实施例方法框架图如图1所示。
符号说明:
ViT将二维图像分割成的二维patch,并使用线性投影将patch映射成标记。还附加一个额外的[class]标记(类标记),代表全局图像信息。此外,所有的标记都被添加一个可学习的位置嵌入。因此,ViT模型的输入标记序列是:
一个ViT模型包含K个顺序堆叠的编码器,每个编码器由一个自我注意(SA)模块和前馈网络(FFN)组成。在第k个编码器的SA中,标记序列X
被称为类注意力,反映类标记和其他标记之间的相互作用。SA的输出A
1.第一阶段:粗粒度推理
CF-ViT首先进行粗略的分割,以识别"简单"的图像。同时,当遇到"困难"的样本时,它还会定位信息区域以进行有效推理。在粗略阶段,CF-ViT模型v的输入是:
其中,N
类标记
其中,n表示类别编号。至此,可以得到输入的预测类别为:
希望有一个大的
为了更好的进行细粒度推理,在粗粒度推理阶段还需要统计全局类注意力分数。使用指数夹权平均来对不同层的类注意力分数进行聚合:
其中,β是一个加权因子。基于此,最后一个编码器的输出即全局类注意力
2.第二阶段:细粒度推理
基于全局类注意力选择有信心的粗粒度patch,这些patch的注意力分数在N
对细粒度分割后的patch进行编码:
为了更好的提升细粒度推理阶段的性能,设计特征复用模块。其将粗粒度的标记特征维度对应到细粒度的特征标记上:
将对齐后的特征直接和细粒度的特征标记相加,输入模型执行细粒度推理:
类标记
3.训练目标函数
在CV-ViT的训练过程中,设置置信度阈值η=1,这意味着细粒度推理阶段将始终对每个输入图像进行执行。一方面,希望细粒度的分割能够很好地适应地面真实标签y,从而对输入进行准确预测。另一方面,希望粗粒度的拆分与细粒度的拆分有类似的输出,这样大多数输入可以在粗粒度推理阶段得到很好的识别。因此,CF-ViT的训练损失如下:
loss=CE(p
其中,CE(·,·)和KL(·,·)分别代表交叉熵损失和Kullback-Leibler散度。
4.实现细节
所有的模型都在ImageNet(Deng J,Dong W,Socher R,et al.Imagenet:A large-scale hierarchical image database[C]//2009IEEE conference on computer visionand pattern recognition.Ieee,2009:248-255.)集上进行训练,其包含1000个类别,有120万张训练集图片和5万张验证集图片。使用DeiT-S(Touvron H,Cord M,Douze M,etal.Training data-efficient image transformers&distillation through attention[C]//International Conference on Machine Learning.PMLR,2021:10347-10357.)和LV-ViT-S(Jiang Z H,Hou Q,Yuan L,et al.All tokens matter:Token labeling fortraining better vision transformers[J].Advances in Neural InformationProcessing Systems,2021,34.)作为ViT骨干(Backbone)。采用AdamW优化器,数据增强包括MixUp(Zhang H,Cisse M,Dauphin Y N,et al.mixup:Beyond empirical riskminimization[J].arXiv preprint arXiv:1710.09412,2017.),CutMix(Yun S,Han D,OhS J,et al.Cutmix:Regularization strategy to train strong classifiers withlocalizable features[C]//Proceedings of the IEEE/CVF international conferenceon computer vision.2019:6023-6032.)。
5.应用领域
本发明可应用于分类ViT模型,以实现对分类ViT模型的压缩和加速。
表1表示使用本发明训练方法得到的模型和基础骨干ViT模型的性能对比,可以发现通过本发明(CF-ViT)在速度与精度上得取得优势,并且可以在GPU上获得实际推理加速。
表1
表1中的模型吞吐量(Throughput)显示在单个A100 GPU上每秒处理的图像数量,为了准确估计吞吐量,以512的批处理量反复给每个模型提供50次。然后,取平均值作为实际吞吐量。从表1中可以观察到,CF-ViT平衡了精度和效率。可以看出,当与骨干网保持相同的精度时,CF-ViT将DeiT-S的模型FLOPs大大降低61%,LV-ViT-S降低了53%。因此,本发明的CF-ViT获得处理图像的巨大能力,导致吞吐量比DeiT-S提高1.88x,比LV-ViT-S提高2.01x。此外,在较大的置信度阈值下,本发明的CF-ViT不仅表现出FLOPs和吞吐量,而且表现出更好的top-1精度。特别是,当η=1表示所有的输入都被送到精细推理阶段时,本发明的CF-ViT显著提高DeiT-S的性能1.0%和LV-ViT-S的性能0.3%。这些结果很好地证明本发明的CF-ViT能够很好地保持模型性能和模型效率之间的权衡。
表2
表2将本发明和近期压缩方法进行对比,包括:IA-RED