一种基于混合数据的数据服务方法
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及数据服务技术领域,特别涉及一种基于混合数据的数据服务方法。
背景技术
基于混合数据的数据服务是一种将多源数据进行加工后通过标准接口对外统一提供服务的能力;其根本作用是将企业的数据资产便捷地转化成业务能力(应对企业应用之间、系统之间数据即时交换、共享的需求)。
与其他“即服务”模式(IaaS、PaaS、SaaS)类似,数据即服务基本是通过提供一个平台来将数据变成服务,以供用户进行稳定高效的数据消费的方式实现的。
拥有足够的数据不再是当今公司的主要问题,对于数据的管理和数据的便捷消费成为了企业面临的难题。
大多数公司都想将数据转化为公司重要的战略资产,而数据分散在不同业务系统和数据库,数据的获取主要依靠开发团队针对各个业务需求和所需取数的平台单独开发数据接口,就会出现以下问题:
一、开发的效率和数据传输稳定性都取决于开发团队的能力;
二、每次出现新的需求或前后台出现变化,都需要技术团队重新开发,导致IT员工需要花费大量时间和经理去做繁琐而重复的工作,员工做的疲累、公司也付出了许多无效成本;
三、各自开发接口也会导致管理混乱,没有全局的权限管控,数据安全隐患众多;
四、计算性能还不一定稳定,遇到高并发的请求系统很可能崩溃。
发明内容
为解决上述问题,本发明旨在提出一种基于混合数据的数据服务方法,通过整合多种不同系统、不同类型的数据源,实现跨域、跨集群的数据融合,减少IT部门的重复开发,有效的进行权限控制,保护数据资产的安全。。
为达到上述目的,本发明的技术方案是这样实现的:
一种基于混合数据的数据服务方法,包括以下步骤:
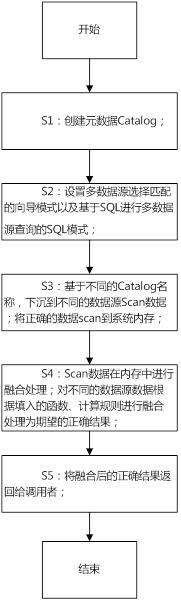
S1:创建元数据Catalog;
S2:设置多数据源选择匹配的向导模式以及基于SQL进行多数据源查询的SQL模式;
S3:基于不同的Catalog名称,下沉到不同的数据源Scan数据;将正确的数据scan到系统内存中;
S4:Scan数据在内存中进行融合处理;对不同的数据源数据根据填入的函数、计算规则进行融合处理为期望的正确结果;
S5:将融合后的正确结果返回给调用者。
进一步的,所述元数据Catalog为Hive数据源或Oracle数据源。
进一步的,所述向导模式支持引导式操作。
进一步的,所述SQL模式支持ANSI SQL2003语法。
进一步的,所述S3具体为:基于不同的Catalog下沉到不同数据源scan数据,将不同的Catalog连接信息进行匹配连接,对查询条件事先进行谓词下推用于减少数据量的返回数量,并将正确的查询结果拉取到内存中。
进一步的,所述S5中的融合后的正确结果是以json的形式返回。
进一步的,所述调用者通过权限控制模块进行数据调用。
进一步的,所述权限控制模块的工作流程为:创建catalog→选择schema→选择table→选择column→选择用户、角色→选择赋予何种权限。
有益效果:本发明通过整合多种不同系统、不同类型的数据源,实现跨域、跨集群的数据融合,减少IT部门的重复开发,有效的进行权限控制,保护数据资产的安全。本发明降低了工厂的IT开发成本,提高需求响应效率,从而提升了整体利润。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例所述的基于混合数据的数据服务方法的主体流程图;
图2为本发明实施例所述的基于混合数据的数据服务方法的权限控制模块工作流程图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面将参考附图并结合实施例来详细说明本发明。
专业术语解释说明:
数据即服务:是指与数据相关的任何服务都能够发生在一个集中化的位置,如聚合、数据质量管理、数据清洗等,然后再将数据提供给不同的系统和用户,而无需再考虑这些数据来自于哪些数据源。
IaaS:基础设施服务,Infrastructure-as-a-service。
PaaS:平台服务,Platform-as-a-service。
SaaS:软件服务,Software-as-a-service。
实施例1
参见图1-2:一种基于混合数据的数据服务方法,包括以下步骤:
S1:创建元数据Catalog;
S2:设置多数据源选择匹配的向导模式以及基于SQL进行多数据源查询的SQL模式;
S3:基于不同的Catalog名称,下沉到不同的数据源Scan数据;将正确的数据scan到系统内存中;
S4:Scan数据在内存中进行融合处理;对不同的数据源数据根据填入的函数、计算规则进行融合处理为期望的正确结果;
S5:将融合后的正确结果返回给调用者。
在一具体的实例中,所述元数据Catalog为Hive数据源或Oracle数据源。
需要说明的是,本实施例的元数据Catalog主要以插件Plugin的方式严格区分不同的数据源,不同的数据源的连接方式不同且有不同的参数配置,例如,Hive数据源需要填入thrift连接信息,Oracle数据源输入填入jdbc连接地址;针对不同的数据源都严格遵守相应的规范,并相互隔离,以此达到便于对数据源进行区分。
在一具体的实例中,所述向导模式支持引导式操作。
本实施例的支持引导式操作的向导模式可以逐步进行多数据源下的表以及字段的选择和确认。
在一具体的实例中,所述SQL模式支持ANSI SQL2003语法。
本实施例的支持ANSI SQL2003语法的SQL模式可以通过填入的Catalog名称下的库名、表名、字段名来确认具体的信息。
在一具体的实例中,所述S3具体为:基于不同的Catalog下沉到不同数据源scan数据,将不同的Catalog连接信息进行匹配连接,对查询条件事先进行谓词下推用于减少数据量的返回数量,并将正确的查询结果拉取到内存中。
本实施例通过上述操作,提高了需求响应效率。
在一具体的实例中,所述S5中的融合后的正确结果是以json的形式返回。
本实施例通过json的形式返回,从而便于调用者的数据解析。
在一具体的实例中,所述调用者通过权限控制模块进行数据调用。
在一具体的实例中,所述权限控制模块的工作流程为:创建catalog→选择schema→选择table→选择column→选择用户、角色→选择赋予何种权限。
本实施例通过权限控制模块能够有效的进行权限控制,从而保护数据资产的安全性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 用于基于与第一数据服务建立的数据上下文相关联的回退状况的存在而实现回退到第二数据服务的方法和装置
- 基于数据服务访问情况动态调整数据服务集群的方法