基于原始视频的ADHD多特征提取与融合分类方法及其系统
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及视觉与机器学习技术领域,特别是涉及一种基于原始视频的ADHD多特征提取与融合分类方法及其系统。
背景技术
注意力缺陷多动障碍(ADHD),俗称为多动症,是一种由多种因素造成的精神疾病,其特征表现是注意力不集中、冲动和多动,ADHD群体前额叶发育迟缓,导致患者行为能力过剩,大脑匹配不足,ADHD神经影像学及神经心理学指出ADHD的病因与前额叶、纹状体及小脑功能的缺损有关。往往ADHD会伴随着双相情感障碍和抑郁等心理问题,这些症状可能会增加成年人犯罪、离婚、失业、学习障碍、社会成就降低以及自杀的风险。
ADHD的诊断通常是基于有经验的儿科精神科医生对儿童父母和教师意见的临床量表审查,采用conners父母评定量表、教师评定量表和注意多动缺陷筛查量表(SNAP-IV)根据其评分值将ADHD患者划分为轻微、中度、严重三种类型。诊断过程中不同的父母、老师甚至精神病学家的诊断结果可能不同,造成的主观原因是ADHD的精神病理尚不清楚。到目前为止,还没有客观的方法来诊断ADHD。
虽然已经有一些生物标志物来识别ADHD的方法,如磁共振成像(MRI)、脑电图(EEG)和正电子发射断层扫描(PET)等等,但这些生物标志物通常只能由大城市医院的专业医生获得,并且成本昂贵,不具有普适性。
因此亟需提供一种新型的基于原始视频的ADHD多特征提取与融合分类方法及其系统来解决上述问题。
发明内容
本发明所要解决的技术问题是提供一种实惠、方便、有效的基于原始视频的ADHD多特征提取与融合分类方法及其系统,分类准确率高、易于推广。
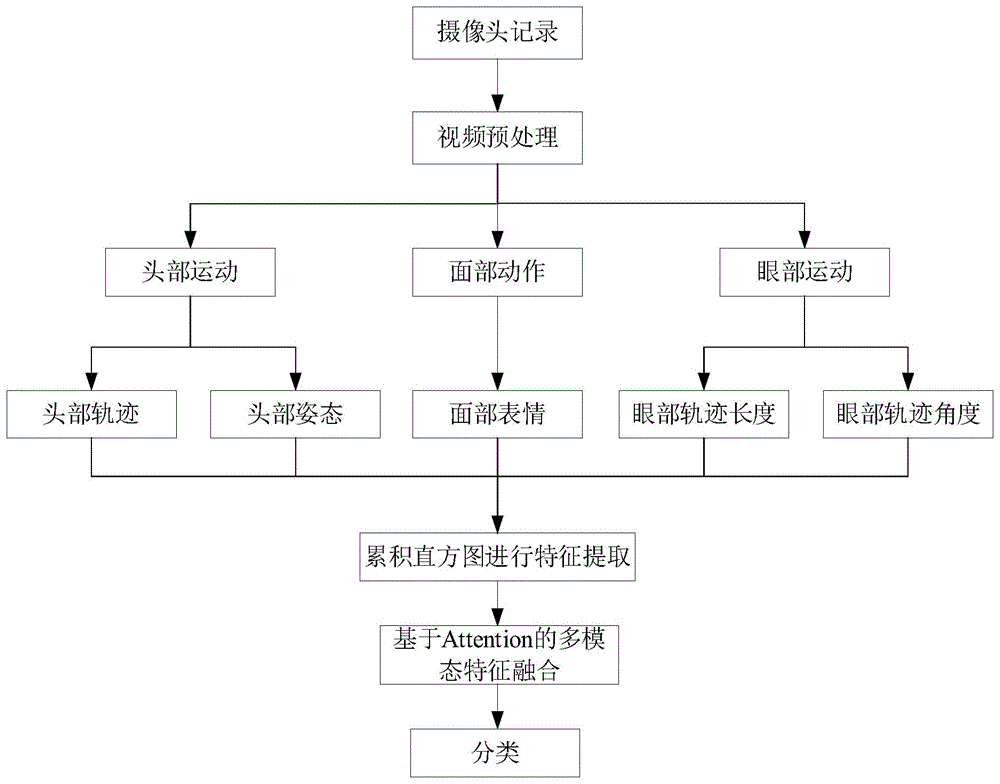
为解决上述技术问题,本发明采用的一个技术方案是:提供一种基于原始视频的ADHD多特征提取与融合分类方法,包括以下步骤:
S1:利用网络摄像头采集受试者观看视频记录,对所述视频进行预处理,得到预处理后的图像帧;
S2:对预处理后的图像帧,分析面部动作、眼部运动和头部运动在内的行为模式;
S3:提取所述行为模式的特征分量并融合;
S4:构建深度学习网络,对所述融合后的特征进行分类。
在本发明一个较佳实施例中,步骤S1的具体步骤包括:
S11:利用摄像头和同步控制系统,记录视频行为数据;
S12:利用ffmpeg开源计算机程序将视频流转化为图像帧;
S13:完成所有图片的尺度归一化;
S14:利用约束局部神经场对归一化后的图像进行人脸检测,得到面部特征点位置P
在本发明一个较佳实施例中,步骤S2的具体步骤包括:
S21:跟踪连续图像帧,分析面部动作进行表情分类;
S22:跟踪连续图像帧,确定头部位置坐标,分析其头部运动;
S23:跟踪连续图像帧,构建深度学习框架获取双眼瞳孔中心,分析其眼部运动。
进一步的,步骤S21的具体步骤包括:
利用面部动作编码的方法,分析人脸区域P
进一步的,步骤S22的具体步骤包括:
S221:确定面部68特征点的第28个点为头部位置的三维坐标,跟踪连续帧的头部位置,堆叠位置坐标(x
S222:利用PnP算法根据平移矩阵T、旋转矩阵Z和面部特征点位置P
式中s代表一个尺度因子,f
进一步的,步骤S23的具体步骤包括:
S231:利用Haar级联对预处理后的图像进行初步眼部区域检测;
S232:将初步检测的眼部区域送入基于注意力机制的ResNet网络进行特征提取操作,得到人眼图像的深层特征;
S233:利用一个全局平均池化层进行特征降维操作,得到人眼图像的降维特征Q;
S234:利用四个全连接层对降维的特征映射至目标位置,输出双目瞳孔中心点位置P,计算公式如下:
P=W4*ReLu(W3*ReLu(W2*ReLu)(W1*Q+b1)+b2)+b3)+b4
式中,W1,W2,W3,W4表示四个全连接层的权重,b1,b2,b3,b4表示四个全连接的偏置,ReLu为激活函数;
S235:取双目瞳孔中心的中心坐标为眼部位置坐标,堆叠眼部位置坐标(x
更进一步的,步骤S232的具体步骤包括:
S2321:利用一个卷积层和池化层进行初步特征提取;
S2322:将初步提取的特征送入残差连接块,残差连接块共有四个残差块,每个残差块由双通道组成,上层为主通道,下层是一个由卷积层和空间注意力模块组成的掩码通道;主通道将输入人眼图像X,输出为人眼图像特征F(X),掩码通道将输入人眼图像X,输出为人眼图像注意力特征G(X),人眼图像特征F(X)和人眼图像注意力特征G(X)相加,得到人眼图像深层特征M(X),计算公式如下:M
式中:F
在本发明一个较佳实施例中,步骤S3的具体步骤包括:
利用累积直方图提取面部表情F、眼部运动长度E
X={F,E
h
S=concat([a
式中,X为某一时刻多种模态的特征表示,k为模态数量,h
在本发明一个较佳实施例中,步骤S4的具体步骤包括:
将融合后的特征S馈送到LSTM网络中对ADHD进行二分类,输入序列的维度为(d,t,v),d为特征向量维度,t为时间步长,v为特征数量,其分类过程可表示如下:
首先定义LSTM网络的结构,包括输入层、LSTM层和输出层,输入层接收大小为[t,v]的特征向量,LSTM层用于学习特征之间的时序关系,输出层用于进行二分类;
其次初始化LSTM网络的参数,包括LSTM层的隐藏状态、记忆状态和权重矩阵,遍历时间步长t,将每个时间步的特征向量v输入到LSTM网络中,LSTM层根据当前输入的特征向量和前一个时间步的隐藏状态和记忆状态,更新隐藏状态和记忆状态,并生成一个输出,直到遍历完所有的时间步;
最后获取LSTM网络的最后一个时间步的输出传递给输出层,并使用激活函数将其映射到[0,1]的范围内,进行二分类;
训练阶段使用交叉熵损失函数计算损失,定义如下:
式中y
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种基于原始视频的ADHD多特征提取与融合分类系统,采用如上任一项所述的基于原始视频的ADHD多特征提取与融合分类方法,包括:
信号采集与预处理模块,利用网络摄像头采集受试者观看视频记录,对所述视频进行预处理,得到预处理后的图像帧;
多模态信号分析模块,用于对所述信号采集与预处理模块预处理后的图像帧,分析面部动作、眼部运动和头部运动在内的行为模式;
信号特征提取与融合模块,用于提取所述行为模式的特征分量并融合;
信号分类模块,用于构建深度学习网络,对所述信号特征提取与融合模块融合后的特征进行分类。
本发明的有益效果是:
(1)本发明采用基于原始视频的ADHD多特征提取与融合分类方法,充分结合了面部表情、眼部运动和头部运动多模态行为模式数据,并采用了一种基于注意力机制的ResNet网络,使得网络模型集中关注图像中与瞳孔相关的区域,同时采用残差连接来缓解梯度消失的问题,增加眼动追踪的可靠性。在特征提取模块,使用累积直方图从视频序列的行为模式数据中单独提取时间和空间信息,从而提高特征的区分度,同时建立基于Attention算法的多模态特征层融合方法,利用Attention机制动态学习各个模态的贡献度,减小数据维度,让信息进行充分的跨模态交互与融合。最终利用LSTM处理时间序列数据的同时最大程度地保留特征信息,提高分类的准确性;
(2)由于目前没有公开的ADHD儿童视频数据集,因此,使用本发明所述方法在合肥市第三人民医院收集的ADHD数据集上取得了比较好的结果,分类准确率达98.7%。
(3)本发明基于视频序列对ADHD患者进行分类,避免了侵入性影响、降低了成本,保证了分类的精度且易于推广;通过多模态特征融合,减少了单一模态数据的局限性,具有更好的准确性和有效性,此外该发明还可以用于自闭症病例的分类。
附图说明
图1是本发明基于原始视频的ADHD多特征提取与融合分类方法的流程示意图;
图2是本发明的面部68特征点部分示意图;
图3是本发明所述方法步骤S23分析眼部运动的具体步骤流程图;
图4是所述空间注意力模块的结构示意图;
图5是基于原始视频的ADHD多特征提取与融合分类系统的结构框图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
请参阅图1,本发明实施例包括:
一种基于原始视频的ADHD多特征提取与融合分类方法,包括:
S1:利用网络摄像头采集受试观看视频记录,对所述视频进行预处理,具体步骤包括:
S11:利用摄像头和同步控制系统,当开始播放观看视频时,软件将启动摄像头模块开始记录视频行为数据,播放完成后,软件将同步停止摄像头模块的录制;
S12:利用ffmpeg开源计算机程序将视频流转化为图像帧,以便于视频内容的分析和理解;
S13:完成所有图片的尺度归一化,包括尺度缩放、最大最小归一化等;
S14:利用约束局部神经场(CLNF)对归一化后的图像进行人脸检测,在检测到人脸后,进行面部68特征点定位,如图2所示。
S2:对预处理后的图像帧,分析面部动作、眼部运动和头部运动在内的行为模式,具体步骤包括:
S21:跟踪连续帧,分析面部动作进行表情分类,具体步骤包括:
利用面部动作编码的方法,分析人脸区域P
S22:跟踪连续图像帧,确定头部位置坐标,分析其头部运动,具体步骤包括:
S221:确定面部68特征点的第28个点为头部位置的三维坐标,跟踪连续帧的头部位置,堆叠位置坐标(x
S222:利用PnP算法根据平移矩阵T、旋转矩阵Z和面部特征点位置P
式中s代表一个尺度因子,f
S23:跟踪连续图像帧,构建深度学习框架获取双眼瞳孔中心,分析其眼部运动,如图3所示,具体步骤包括:
S231:利用Haar级联对预处理后的图像进行初步眼部区域检测,避免面部丢失以及闭眼造成眼部特征点定位错误;
S232:将初步检测的眼睛区域送入基于注意力机制的ResNet网络进行特征提取操作,得到人眼图像的深层特征,具体步骤包括:
S2321:利用一个卷积层和池化层初步提取特征,增强网络的泛化性;
所述卷积层为第一卷积层,卷积核大小设置为7*7,单位为像素,步长设置为2,单位为像素,填充设置为3,单位为像素;池化层的卷积核大小设置为3*3,单位为像素,步长设置为2,单位为像素,填充设置为1,单位为像素。
S2322:将初步提取的特征送入残差连接块,残差连接块共有四个残差块,每个残差块由双通道组成,上层为主通道,下层是一个掩码通道,主通道由一个卷积层构成,该卷积层的卷积核的大小设置为3×3,单位为像素,步长设置为1,单位为像素,填充设置为1,单位为像素,此通道的作用是提取特征;下层为掩码通道,掩码通道由两个相同的卷积层和一个空间注意力模块组成,两个所述的卷积层分别为第二卷积层、第三卷积层,主通道将输入人眼图像X,输出为人眼图像特征F(X),掩码通道将输入人眼图像X依次经过第二卷积层、第三卷积层、空间注意力模块,输出为人眼图像注意力特征G(X),人眼图像特征F(X)和人眼图像注意力特征G(X)相加,得到人眼图像深层特征M(X),计算公式如下:M
式中:F
第二卷积层的卷积核大小设置为3*3,单位为像素,步长设置为1,单位为像素,填充设置为1,单位为像素;第三卷积层的卷积核大小设置为3*3,单位为像素,步长设置为1,单位为像素,填充设置为1,单位为像素。
如图4所示,空间注意力模块由双通道组成,上层的为主通道,由一个全局最大池化层和重塑层构成,此通道用于保留最显著的特征;下层为一个掩码通道,掩码通道由一个全局平均池化层、重塑层、卷积层构成,所述卷积层为第四卷积层,卷积核大小设置为1*1,单位为像素,步长设置为1,单位为像素,填充设置为1,单位为像素,此通道提供一个注意力特征,促使下一个注意力模块更加专注于眼角、瞳孔等关键位置提取特征。主通道将输入人眼图像特征D(X),输出为人眼图像全局特征E(X),掩码通道将输入人眼图像特征D(X)依次经过全局平均池化层、重塑层,输出为人眼图像全局特征H(X),将人眼图像全局特征H(X)与输入人眼图像特征D(X)像素相乘,得到加权的人眼特征I(X),然后将人眼特征I(X)作为权重,经过卷积层,输出为注意力权重特征J(X),将输入人眼图像特征D(X)和注意力权重特征J(X)像素相乘,得到人眼图像注意力特征K(X),计算公式如下:
K
式中:符号*表示矩阵的点乘。通过这种先乘后加的特征叠加的方式,既可以侧重于关键位置的特征,又不会丢失图片的整体信息。
S233:利用一个全局平均池化层进行特征降维操作,得到人眼图像的降维特征,使用全局平均池化层代替全连接层,既保证了模型在瞳孔中心定位任务中的准确性,又极大地减少了参数量;
S234:利用四个全连接层对降维的特征映射至目标位置,输出双目瞳孔中心点位置P,计算公式如下:
P=W4*ReLu(W3*ReLu(W2*ReLu)(W1*Q+b1)+b2)+b3)+b4
式中,W1,W2,W3,W4表示四个全连接层的权重,b1,b2,b3,b4表示四个全连接的偏置,ReLu为激活函数。
S235:取双目瞳孔中心的中心坐标为眼部位置坐标,堆叠眼部位置坐标(x
S3:提取所述行为模式的特征分量并融合;
将面部表情E分为8种,分配到对应类别。将眼部轨迹的长度分量El以及头部轨迹长度H分为7个等级,根据欧几里得距离计算连续两帧之间的长度,并分配到对应等级。将眼部轨迹的角度分量Ea分为10个区域,三种头部姿态角度P、Y、R分别对应三个区域,使用反正切函数计算连续两帧之间的角度,并分配到对应区域,El、Ea、Hl计算过程如下:
利用累积直方图提取面部表情F、眼部运动长度E
X={F,E
h
S=concat([a
式中,X为某一时刻多种模态的特征表示,k为模态数量,h
Attention算法通过不断调整各模态的权重,并与对应的特征向量进行相乘,最后级联得到融合特征向量。Attention算法有效实现了多模态信息的互补性和多模态贡献度计算,保证了多模态信息融合的合理性和准确度。
S4:构建深度学习网络,对所述的融合后的特征进行分类;
融合后的特征S带有大量的时间信息,LSTM是一种递归神经网络,专门设计用于解决长期依赖问题,堆叠多层LSTM,增加模型的学习能力和表示能力。将融合后的特征S馈送到LSTM网络中对ADHD进行二分类,输入序列的维度为(d,t,v),d为特征向量维度,t为时间步长,v为特征数量,其分类过程可表示如下:
首先定义LSTM网络的结构:包括输入层、LSTM层和输出层。输入层接收大小为[t,v]的特征向量,LSTM层用于学习特征之间的时序关系,输出层用于进行二分类;其次初始化LSTM网络的参数:包括LSTM层的隐藏状态、记忆状态和权重矩阵等。遍历时间步长t,将每个时间步的特征向量v输入到LSTM网络中,LSTM层根据当前输入的特征向量和前一个时间步的隐藏状态和记忆状态,更新隐藏状态和记忆状态,并生成一个输出,直到遍历完所有的时间步;最后获取LSTM网络的最后一个时间步的输出传递给输出层,并使用激活函数(如sigmoid函数)将其映射到[0,1]的范围内,进行二分类。
训练阶段使用交叉熵损失函数计算损失,定义如下:
式中y
参阅图5,本发明示例中还提供一种基于原始视频的ADHD多特征提取与融合分类系统,采用如上任一项所述的基于原始视频的ADHD多特征提取与融合分类方法,包括:
信号采集与预处理模块,利用网络摄像头采集受试者观看视频记录,对所述视频进行预处理,得到预处理后的图像帧;
多模态信号分析模块,用于对所述信号采集与预处理模块预处理后的图像帧,分析面部动作、眼部运动和头部运动在内的行为模式;
信号特征提取与融合模块,用于提取所述行为模式的特征分量并融合;
信号分类模块,用于构建深度学习网络,对所述信号特征提取与融合模块融合后的特征进行分类。
综上所述,本发明采用基于原始视频的ADHD多特征提取与融合分类方法,充分结合了面部表情、眼部运动和头部运动行为模式数据,并采用了一种基于注意力机制的ResNet网络,使得网络模型集中关注图像中与瞳孔相关的区域,同时采用残差连接来缓解梯度消失的问题,增加眼动追踪的可靠性。在特征提取模块,使用累积直方图从视频序列的行为模式数据中单独提取时间和空间信息,从而提高特征的区分度,同时建立基于Attention算法的多模态特征层融合方法,利用Attention机制动态学习各个模态的贡献度,减小数据维度,让信息进行充分的跨模态交互与融合。最终利用LSTM处理时间序列数据的同时最大程度地保留特征信息,提高分类的准确性。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 层叠电感器的制造方法以及层叠电感器
- 一种层叠电感器及其制造方法
- 一种层叠状NiO微纳米材料的制备方法及其应用
- 一种电感防护环保型热缩套管及其制备方法
- 一种层叠电感及其制备方法
- 一种基于金属磁性浆料的层叠电感器及其制备方法