一种数据异常动态识别与多模式自匹配的数据清洗技术
文献发布时间:2023-06-19 09:44:49
技术领域
本发明专利属于水文水资源数据处理及整编领域,尤其涉及一种数据异常动态识别与多模式自匹配的数据清洗技术。
背景技术
水文资料是国民经济建设和生态文明建设的一项重要基础资料和信息资源,事关水利事业和经济社会发展大局,关系到防洪安全、供水安全、生态安全、涉水工程安全。近年来,随着水文站网和基础设施的快速建设与发展,全国水文部门共有各类水文测站12万余处,90%以上站点实现了自动监测,信息总量达10亿余条/年。但是,这些水文监测数据在采集、传输及存储过程中,由于设备、环境及人为等原因会导致数据中存在缺失、离群等多种异常数据,这些异常数据会降低决策的准确率,严重影响数据的服务质量。此外,在整编时效性上虽然提出了“日清月结”的要求,但由于人工集中审查的工作模式,需要到次年1月才能全面完成上年度水文资料整编工作。因此,水文数据的实时动态清洗与整编必不可少。
当前,水文数据清洗整编针对的异常数据主要分为两类:离群点及缺失点。对于离群点的判定大多采用阈值判定法,这种方法对于明显离群点(位数错误、单位错误、数据超出范围)判断较为准确,对于不明显离群点存在遗漏;缺失点插补方面,已有的方法在处理短期缺失时(5天以下)较为有效,但是无法处理中期(5-15天)和长期(15天以上)的数据缺失插补。
因此,针对异常值识别和缺失值插补等问题,采用数据异常动态识别与多模式自匹配的数据清洗技术,通过对原始监测数据的定时同步,自动调用清洗整编算法,每日自动计算生成整编成果,并对插补数据进行动态更新。实现水文监测数据的实时动态清洗与整编,切实提高水文数据整编的时效性。
发明内容
本发明专利的目的就是针对上述现有技术存在的问题,提出了一种数据异常动态识别与多模式自匹配的数据清洗技术。本发明专利的技术方案是这样实现的:一种数据异常动态识别与多模式自匹配的数据清洗技术,包括以下步骤:
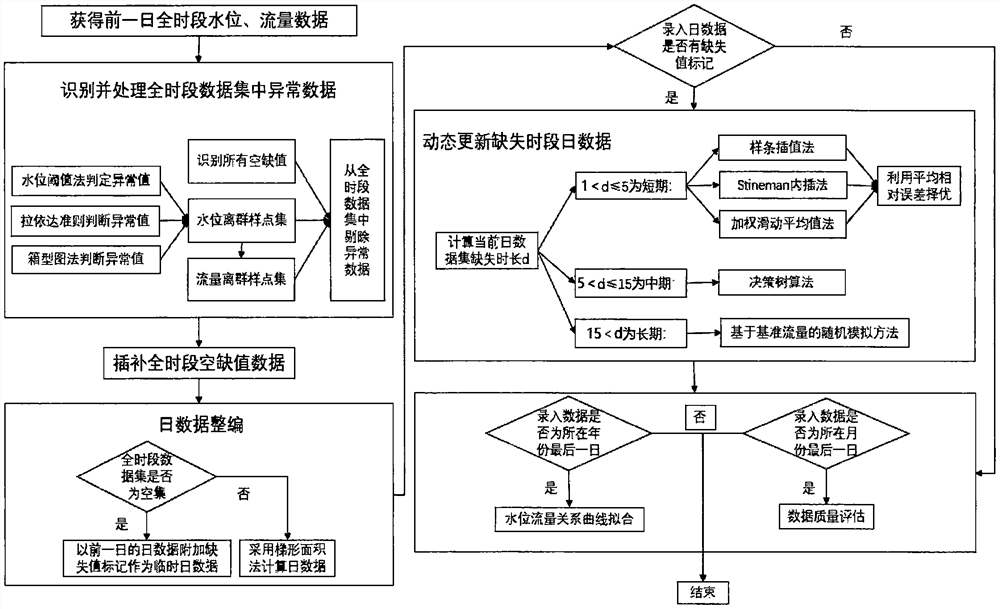
S1、定时获取全国水文监测站前一天0时至24时的水位、流量全时段数据集;
S2、识别并处理异常数据:首先识别出全时段数据集中所有空缺值,对空缺值作空缺值标记;其次采用“阈值判定+拉依达准则/箱型图法”作为离群点判断方法对其余异常数据进行识别,建立水位离群样点集,并将其对应的流量数据纳入流量离群样点集,同时对离群点数据作离群样点标记;在全时段数据集中删除离群样点标记和空缺值标记对应数据;若删除离群样点标记和空缺值标记对应数据后,全时段数据集为空集,则执行步骤S4;所述空缺值标记、离群样点标记为以不同颜色、字体、字号、索引及标注所体现出该数据与其余数据具有相对区别度;
S3、插补全时段空缺值数据:对于一对流量和水位数据中单一缺少任一数据的情况,则利用最近一年合格的水位流量关系曲线插补得到对应的流量或者水位数据,并附加插补值标记回补入全时段数据集中;所述水位流量关系曲线的合格标准为相关性系数达到90%以上;所述插补值标记为以不同颜色、字体、字号、索引及标注所体现出该数据与其余数据具有相对区别度;
S4、日数据整编:若全时段数据集非空,则采用梯形面积法将步骤S3补齐后的监测数据整编为日数据并录入日数据集,所述日数据为日平均水位和日平均流量;若全时段数据集为空集,则判定为日数据缺失,并暂时以前一日数据附加缺失值标记作为当天临时日数据录入日数据集,所述缺失值标记为以不同颜色、字体、字号、索引及标注所体现出该数据与其余数据具有相对区别度;
S5、动态更新缺失时段日数据:若当天录入日数据集的数据不带有缺失值标记,则不进行步骤S5;若当天录入日数据集的数据带有缺失值标记,则在日数据集中,以当前录入的日数据为起点按照时间顺序溯源检索缺失值标记,以检索到首个不含缺失值标记的数据为止,计算缺失时长,并将缺失时长分为短期、中期和长期三类,针对不同缺失时长分别采用短时插补法、中时插补法和长时插补法对缺失数据进行插补计算并替换S4步骤中产生的临时数据;所述短期为1<d≤5天;所述中期为5<d≤15天;所述长期15<d天,其中,d为缺失时长;
S6、数据质量评估:若当天录入日数据集的数据不是所在月份的最后一日数据,则不进行步骤S6;若当天录入日数据集的数据是所在月份的最后一日数据,则以全年的全时段数据集为对象,对每个水文站当月以及累计到当前月的监测频次、异常数据个数、缺失时长等进行统计评价;
S7、水位流量关系曲线拟合:若当天录入日数据集的数据不是所在年份的最后一日数据,则不进行步骤S7;若当天录入日数据集的数据是所在年份的最后一日数据,则以全年的全时段数据集为处理对象,删除具有空缺值标记和离群样点标记的数据后,采用最小二乘法对水位流量关系曲线进行函数拟合,将相关性系数最大的一种拟合函数作为最优拟合,若最优拟合的相关性系数小于90%,则标记作为异常年份。
进一步,步骤S2中的“阈值判定+拉依达准则/箱型图法”评判方法包含如下三步:
①通过水位阈值法判定异常值:统计分析不同地区不同时期的水位变化分布特点,确定水位分期分区阈值S,若按照时间顺序排列的全时段水位数据集{S
|S
则判定i时刻对应的水位数据S
②通过拉依达准则判定异常值:假设全时段数据集符合正态分布,计算全时段数据集的均值μ和标准差σ,若全时段数据集{A
③通过箱型图法判定异常值:若全时段数据集{A
④将异常值数据集1、异常值数据集2和异常值数据集3求并集得到水位离群样点集。
进一步,步骤S5中针对短期缺失时长数据采用短时插补法,所述短时插补法是在精度分析的基础上,在样条插值法、Stineman内插法、加权滑动平均值法中通过精度分析对短时期缺失数据进行择优插补;
所述样条插值法属于非线性插值方法,其样条函数为:
式中:P
所述Stineman内插法:记x
其中若斜率
其中,I、J和K为任意3个满足条件:
对于端点,则通过
所述加权滑动平均值法:令{Y
式中:ω
所述精度分析是通过平均相对误差(MARE)对模型精度进行评估,MARE值越接近0,表示模型预报精度越高,计算公式如下所示:
式中,n为径流序列长度;y
进一步,步骤S5中针对中期缺失时长数据采用中时插补法,所述中时插补法为决策树算法,首先利用自助重采样技术从原始训练样本集中有放回地随机抽取多个样本生成新的训练样本集;然后根据自助样本集构建多棵决策树形成随机森林;最后根据输入的待分类/回归样本,随机森林对每棵决策树的输出结果采用简单多数投票或单棵树输出结果简单平均决定最后的预测结果。
进一步,步骤S5中针对长期缺失时长数据采用长时插补法,所述长时插补法为基于基准流量的随机模拟方法:①选取插补年待插补数据的前一日流量作为流量基准值Q
其中,Q
本发明具有以下优点:
①异常数据检测对象范围广泛,包含由于设备、环境及人为等原因造成的缺失及多种离群样点类型的识别;②针对缺失时段的长度采用不同的插补方法,自动完成短期、中期和长期时段的数据插补;③实时动态清洗提高了数据整编的时效性。
附图说明
图1是一种数据异常动态识别与多模式自匹配的数据清洗技术流程示意图。
具体实施方式
下面结合附图对本发明专利实施方案进行详细描述。定时获得全国水文监测站发来的前一日0-24时水位、流量全时段数据集A;对数据集A进行空缺值检索,并对空缺值作空缺值标记,所述空缺值标记为以不同颜色、字体、字号、索引及标注所体现出该数据与其余数据具有相对区别度;。随后通过“阈值判定+拉依达准则/箱型图法”挖掘离群样点集:第一步:统计分析不同地区不同时期的水位变化分布特点,确定水位分期分区阈值S,若按照时间顺序排列的全时段水位数据集{S
|S
则判定i时刻对应的水位数据S
若删除离群样点标记和空缺值标记对应数据后,全时段数据集非空,则进行插补空缺值数据的相应工作。插补空缺值数据时,对于一对流量和水位数据中单一缺少任一数据的情况,则利用最近一年合格的水位流量关系曲线插补得到对应的流量或者水位数据,并附加插补值标记回补入全时段数据集中;所述水位流量关系曲线的合格标准为相关性系数达到90%以上;所述插补值标记为以不同颜色、字体、字号、索引及标注所体现出该数据与其余数据具有相对区别度。
若删除离群样点标记和空缺值标记对应数据后,全时段数据集为空集,则执行日数据整编的相应工作。日数据整编时,若全时段数据集非空,则采用梯形面积法将补齐后的监测数据整编为日数据并录入日数据集,所述日数据为日平均水位和日平均流量;若全时段数据集为空集,则判定为日数据缺失,并暂时以前一日数据附加缺失值标记作为当天临时日数据录入日数据集,所述缺失值标记为以不同颜色、字体、字号、索引及标注所体现出该数据与其余数据具有相对区别度;
若当天录入日数据集的数据不带有缺失值标记,则不进行动态更新缺失时段日数据。若当天录入日数据集的数据带有缺失值标记,则在日数据集中,以当前录入的日数据为起点按照时间顺序溯源检索缺失值标记,以检索到首个不含缺失值标记的数据为止,计算缺失时长,针对不同缺失时长分别采用短时插补法、中时插补法和长时插补法对缺失数据进行插补计算并替换S4步骤中产生的临时数据。若缺失时长d为1<d≤5天则判定缺失时长为短期,在精度分析的基础上,通过样条插值法、Stineman内插法、加权滑动平均值法对短期缺失数据进行插补,并通过平均相对误差(MARE)进行精度评估,选择MARE值更接近0的方法所对应的值作为插补值。若计算的缺失时长d为5<d≤15天则判定缺失时长为中期,采用决策树算法进行插补,首先利用自助重采样技术从原始训练样本集中有放回地随机抽取多个样本生成新的训练样本集;然后根据自助样本集构建多棵决策树形成随机森林;最后根据输入的待分类/回归样本,随机森林对每棵决策树的输出结果采用简单多数投票或单棵树输出结果简单平均决定最后的预测结果。若计算的缺失时长d为15<d天则判定缺失时长为长期,采用基于基准流量的随机模拟方法:①选取插补年待插补数据的前一日流量作为流量基准值Q
其中,Q
动态更新缺失时段日数据工作完成后,若当天录入日数据集的数据不是所在月份的最后一日数据,则不进行数据质量评估工作,若当天录入日数据集的数据是所在月份的最后一日数据,则以全年的全时段数据集为对象,对每个水文站当月以及累计到当前月的监测频次、异常数据个数、缺失时长等进行统计评价;若当天录入日数据集的数据不是所在年份的最后一日数据,则不进行水位流量关系曲线拟合;若当天录入日数据集的数据是所在年份的最后一日数据,则以全年的全时段数据集为处理对象,删除具有空缺值标记和离群样点标记的数据后,采用最小二乘法对水位流量关系曲线进行函数拟合,将相关性系数最大的一种拟合函数作为最优拟合,若最优拟合的相关性系数小于90%,则标记作为异常年份,供决策者参考。
- 一种数据异常动态识别与多模式自匹配的数据清洗技术
- 一种基于模式匹配算法自动生成工艺流程的编排技术