一种基于关键点筛选的姿态跟踪方法
文献发布时间:2023-06-19 13:26:15
技术领域
本发明属于图像处理技术领域,尤其涉及一种基于关键点筛选的姿态跟踪方法。
背景技术
计算机视觉领域中的多人姿态跟踪任务就是指通过对输入的视频图像进行处理,在视频的每一帧中检测出每个行人的姿态,再通过对目标的外观特征、位置、运动状态等信息进行计算分析,随着时间推移正确记录每个人的连续姿态轨迹。作为计算机视觉领域的一个热门问题,人体姿态跟踪是计算机视觉中几乎所有与人类有关问题研究的基础,在人机交互、视频监控、活动识别、体育视频分析领域都具有广泛的应用,这些实际需求引起了人们对这一话题的极大兴趣。
现有的多人姿态跟踪方法通常是采用自顶向下的框架,首先通过多人姿态估计的方法,检测出每个人体的边界框信息,之后对每个人体边界框进行姿态估计得到姿态信息。接下来根据视频当前帧中需要跟踪的人体的信息,与下一帧中获得的信息进行匹配。
尽管多人姿态跟踪技术已经得到广泛的应用,但由于多人姿态估计与跟踪不仅要考虑解决多目标跟踪中普遍具有的挑战性的问题如尺度变化、平面旋转、光照变化,并且视频中还存在人的姿态变化复杂等的情况,都对多人姿态估计与跟踪造成困难。除此之外,在Pose Track挑战赛数据集中,需要将低于一定阈值的关键点清空,以往的方法全部都是根据经验进行阈值调整,阈值的选择往往很影响模型最终的性能。这些问题使得模型的多目标跟踪精度(MOTA)指标还有待提升。
发明内容
为了解决上述已有技术存在的不足,本发明提出一种基于关键点筛选的姿态跟踪方法,能够解决多人姿态跟踪任务中人体关键点阈值难以调整,以及关键点识别低而引起的多目标跟踪精度(MOTA)指标低的问题。本发明的具体技术方案如下:
一种基于关键点筛选的姿态跟踪方法,包括以下步骤:
S1:构建数据集;
S1-1:采用COCO 2017数据集进行检测和姿态估计,PoseTrack 2018数据集进行姿态估计与跟踪;
S1-2:在PoseTrack 2018数据集的基础上,构建行人重识别数据集,裁剪PoseTrack 2018数据集中的所有人体框,保存为图片,对同一视频中具有id的人体框给予相同的标签,最终生成包含4613个标签,共计119656个图片的行人重识别数据集;
S2:构建基于自顶向下框架和通用型关键点筛选网络的多人姿态跟踪模型;
S3:模型训练;
S4:将待测视频输入模型,得到检测结果。
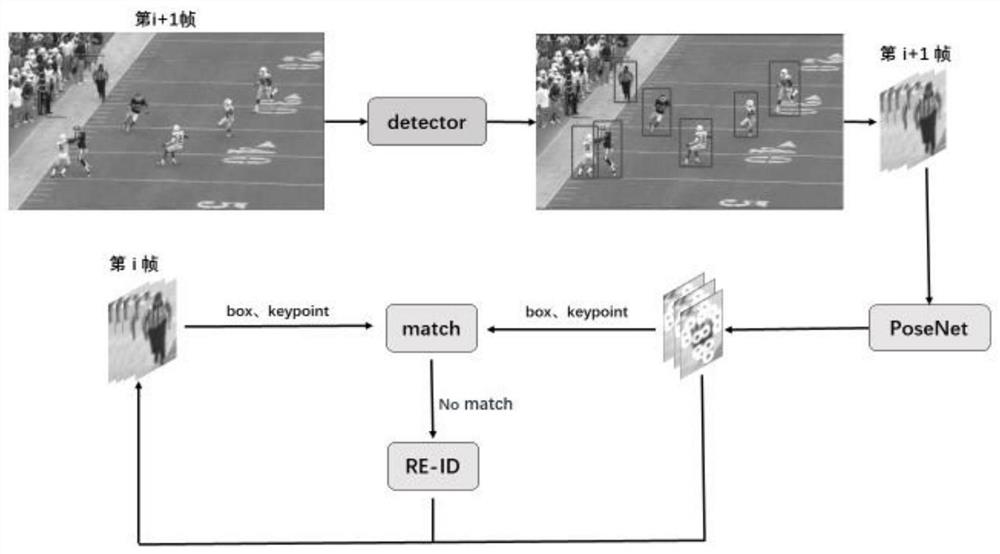
进一步地,所述多人姿态跟踪模型包括目标检测模块、姿态估计与关键点筛选模块、匹配模块以及行人重识别模块,其中,
所述目标检测模块是基于多任务多阶段的混合级联结构模型即HTC模型,HTC模型的骨干网络使用101层的ResNeXt网络,并采用特征图金字塔网络即FPN网络、基于PCK指标的非极大抑制算法;
所述姿态估计与关键点筛选模块,采用通用型姿态估计网络,分别通过关键点预测模块和关键点筛选模块,得到每个关键点的热力图和存在概率,最终获得人体姿态;
所述匹配模块将当前帧的人体姿态与现有的人体姿态轨迹进行数据关联,采用基于边界框的交并比距离的匈牙利算法进行关联;对于丢失轨迹的人体,将其加入到所述行人重识别模块中;当出现新增的人体时,使用所述行人重识别模块找回丢失的人体轨迹。
进一步地,所述基于PCK指标的非极大抑制算法即使用PCK距离作为两个人体框的相似度量,当确认一个人体框被保留时,删除PCK距离大于设定阈值的其他人体框。
进一步地,所述关键点预测模块与所述关键点筛选模块采用相同的网络结构,由三层卷积核为3x3的转置卷积组成,所述关键点预测模块最终对每个关键点生成一张热力图,所述关键点筛选模块对生成的每个关键点的特征图通过全连接层得到每个关键点存在的二分类概率。
进一步地,所述行人重识别模块采用姿态估计网络HRNet作为骨干网络来进行特征提取获得每个人的特征图,每次对现有姿态轨迹和当前帧的姿态关联,对于丢失的轨迹进行保存;对于未能成功匹配的姿态,使用所述行人重识别模块与已丢失的行人轨迹进行对比,若对比成功,则将新的姿态与丢失的姿态轨迹合并,若对比失败,则生成新的轨迹;
在训练阶段,设置每个具有相同标签的人为一个类别,获得每个人的特征图后,将其接入分类网络进行分类,使用多分类交叉熵作为其损失函数;
在姿态跟踪过程中,提取每个人的特征图和已丢失的行人进行特征匹配,使用L1距离即哈密顿距离来比较两个人的距离,当距离小于阈值时,认为是同一个人。
进一步地,所述关键点预测模块输出的热力图还将通过二阶高斯滤波对热力图进行平滑。
进一步地,所述步骤S3为对模型进行分开训练,具体为:
S3-1:目标检测模块采用HTC检测器,在PoseTrack 2018验证集上mAP达到0.346,目标检测模块仅在COCO 2017数据集上训练,不在PoseTrack 2018数据集上微调;
S3-2:姿态估计与关键点筛选模块在COCO2017上进行训练,将训练好的模型在PoseTrack 2018数据集上微调,由于只有关键点被注释,通过将其所有关键点的边界框延长20%的长度以获得一个人实例的基本真值框,通过在高度或宽度上延伸边界框,人体边界框被制成固定的纵横比;
在姿态估计与关键点筛选模块的训练中,对姿态进行数据增强,包括随机缩放、随机旋转和随机翻转,采用adam作为优化器;
S3-3:行人重识别模块则是将PoseTrack 2018数据集将同一个标签的行人从原图中裁剪出来,构成新的数据集,使用经过PoseTrack 2018数据集预训练的HRNet网络作为骨干网络,训练时将HRNet网络输出的特征图通过全连接层分类,验证时候只使用HRNet网络输出的特征图,不再通过全连接层。
本发明的有益效果在于:本发明在现有的基于自顶向下的多人姿态估计方法的基础上,在现有的姿态估计网络上加上通用型关键点筛选网络,提高模型的精度的同时,降低关键点阈值对跟踪精度造成的影响。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,可以根据这些附图获得其他的附图。其中:
图1是本发明的网络流程图;
图2是本发明的姿态估计与关键点筛选模块;
图3是HRNet网络结构;
图4是关键点筛选模块网络结构;
图5是姿态估计可视化结果;
图6是姿态跟踪可视化结果。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
本发明能够在现有的基于自顶向下的多人姿态估计方法的基础上,加上通用型关键点筛选模型,提高模型的精度的同时,降低关键点阈值对跟踪精度造成的影响。
一种基于关键点筛选的姿态跟踪方法,包括以下步骤:
S1:构建数据集;
S1-1:采用COCO 2017数据集进行检测和姿态估计,PoseTrack 2018数据集进行姿态估计与跟踪;
S1-2:在PoseTrack 2018数据集的基础上,构建行人重识别数据集,裁剪PoseTrack 2018数据集中的所有人体框,保存为图片,对同一视频中具有id的人体框给予相同的标签,最终生成包含4613个标签,共计119656个图片的行人重识别数据集;
S2:构建基于自顶向下框架和通用型关键点筛选网络的多人姿态跟踪模型;
S3:模型训练;
S4:将待测视频输入模型,得到检测结果。
如图1-4所示,本发明构建了一个基于自顶向下框架和通用型关键点筛选网络的多人姿态跟踪模型,包含目标检测模块、姿态估计与关键点筛选模块、匹配模块以及行人重识别模块。目标检测模块是基于多任务多阶段的混合级联结构模型即HTC模型,HTC模型的骨干网络使用101层的ResNeXt网络,并采用特征图金字塔网络即FPN网络、基于PCK指标的非极大抑制算法;
姿态估计与关键点筛选模块,采用通用型姿态估计网络,分别通过关键点预测模块和关键点筛选模块,得到每个关键点的热力图和存在概率,最终获得人体姿态;
匹配模块将当前帧的人体姿态与现有的人体姿态轨迹进行数据关联,采用基于边界框的交并比距离的匈牙利算法进行关联;对于丢失轨迹的人体,将其加入到行人重识别模块中;当出现新增的人体时,使用行人重识别模块找回丢失的人体轨迹。
(1)目标检测模块是基于多任务多阶段的混合级联结构(HTC)模型,使用ResNeXt作为骨干网络进行特征提取,使用特征金字塔网络(FPN)进行多尺度测试,最后使用PCK距离来进行非极大抑制算法来过滤冗余的人体提议框,从而得到最终的人体边界框。
HTC网络的每个阶段结合级联和多任务改善信息流,并利用空间背景进一步提高准确性。HTC模型的骨干网络使用101层的ResNeXt网络,ResNeXt是深度残差网络(ResNet)和Inception的结合体,不同于Inception v4的是,ResNext不需要人工设计复杂的Inception结构细节,而是每一个分支都采用相同的拓扑结构。ResNeXt的本质是分组卷积,通过变量基数来控制组的数量。
FPN网络解决人体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小人体检测的性能。除此之外,采用基于PCK指标的非极大抑制算法剔除冗余人体提议框,PCK用于计算检测的关键点之间的归一化距离小于设定阈值的比例,在人体交互遮挡的情况下,传统的基于IOU距离容易将交互遮挡的人体给错误过滤,而PCK距离可以通过姿态信息在有交互遮挡情况下更好的保留下人体提议框,比传统检测模型中使用的IOU指标更加适用于人体检测。PCK距离公式为:
其中,i表示ID为i的关键点,k表示第k个阈值T
(2)姿态估计与关键点筛选模块的骨干网络如图2所示,其骨干网络采用的是高分辨率子网络(HRNet)。如图3所示,HRNet是通过在高分辨率特征图主网络逐渐并行加入低分辨率特征图子网络,不同网络实现多尺度融合与特征提取实现的。
本发明将HRNet网络多多分辨率输出中的第三层输出作为姿态估计模型的特征提取部分获得人体姿态特征图,再分别通过姿态估计模块和关键点筛选模块,得到每个关键点的热力图和存在概率。
关键点预测模块和关键点筛选模块采用相同的网络结构,由三层卷积核为3x3的转置卷积组成,姿态估计模块最终对每个关键点生成一张热力图,而关键点筛选模块则在转置卷积的基础上,分别对生成的每个关键点的特征图通过全连接层得到每个关键点存在的二分类概率。此外,关键点预测模块输出得到的热力图还将通过二阶高斯滤波对热力图进行平滑,得到更加准确的关键点位置。
具体的,关键点预测模块输出为15个关键点的热力图,关键点的标签为高斯分布的概率图,训练的损失函数为:
其中,i表示第i个关键点,j表示热力图中第j个位置是关键点的概率,
关键点筛选模块的输出为15个关键点的二分类概率,关键点的标签为one-hot二值分布,损失函数为:
其中,y
(3)匹配模块将当前帧的人体姿态与前一帧现有姿态轨迹进行数据关联,采用基于边界框的交并比(IOU)距离的匈牙利算法进行关联。IOU距离的计算公式如下:
其中,box1当前帧的人体姿态对应的边界框和box2前一帧现有姿态轨迹对应的边界框,area为计算box的面积。
(4)行人重识别模块,采用姿态估计网络HRNet作为骨干网络来进行特征提取获得每个人的特征图,每次对现有姿态轨迹和当前帧的姿态关联,对于丢失的轨迹进行保存;对于未能成功匹配的姿态,使用所述行人重识别模块与已丢失的行人轨迹进行对比,若对比成功,则将新的姿态与丢失的姿态轨迹合并,若对比失败,则生成新的轨迹;
在训练阶段,设置每个具有相同标签的人为一个类别,获得每个人的特征图后,将其接入分类网络进行分类,使用多分类交叉熵作为其损失函数;
在姿态跟踪过程中,提取每个人的特征图和已丢失的行人进行特征匹配,使用L1距离即哈密顿距离来比较两个人的距离,当距离小于阈值时,认为是同一个人。
另外,本发明的网络模型是分模块进行训练:
S3-1:目标检测模块采用HTC检测器,在PoseTrack 2018验证集上mAP达到0.346,目标检测模块仅在COCO 2017数据集上训练,不在PoseTrack 2018数据集上微调。
S3-2:姿态估计与关键点筛选模块在COCO 2017上进行训练,将训练好的模型在PoseTrack 2018数据集上微调,由于只有关键点被注释,通过将其所有关键点对应的边界框延长20%的长度以获得人体边界框,通过在高度或宽度上延伸边界框,人体边界框被制成固定的纵横比;例如,高度:宽度=4:3,采用的分辨率为384:288,热力图的大小为分辨率的四分之一,即96:72。
在姿态估计与关键点筛选模块的训练中,对姿态进行数据增强,包括随机缩放(30%)、随机旋转(40度)和随机翻转,采用adam作为优化器。
S3-3:行人重识别模块则是将PoseTrack 2018数据集将同一个标签的行人从原图中裁剪出来,构成新的数据集,共包含4613个行人标签,119656个图片,使用经过PoseTrack2018数据集预训练的HRNet网络作为骨干网络,训练时将HRNet网络输出的特征图通过全连接层分类,验证时候只使用HRNet网络输出的特征图,不再通过全连接层。
实施例1
为了验证模型每个模块的有效性,在关键模块上进行消融实验。如表1所示,实验过程包括基准实验和连续在此基础上添加两个模块:
·基准实验:采用HTC检测器、HRNet姿态估计网络、和IOU匹配作为基准方法。
·基准+关键点筛选模块:在基准方法的基础上,加入了关键点筛选模块(checkmodel)。
·基准+关键点筛选模块+行人重识别(re-id):在基准方法的基础上,加入了关键点
筛选模块(check model)和行人重识别(re-id)。
从表中发现,本发明的网络中的每个模块对性能的提升都有一定的贡献,尤其是关键点筛选模块对性能提升的贡献最大。
表1本发明的方法在PoseTrack 2018数据集上的消融实验
本实施例还验证了关键点筛选模块在不同的自顶向下的姿态估计网络中模型的有效性,如表2所示,HRNet、Hourglass和pose_resnet分别测试在有无关键点筛选模块情况下的多目标跟踪精确度(MOTA)指标,实验结果证明关键点筛选模块可以有效提高姿态跟踪网络的性能,也说明本发明的方法具有良好的泛化能力。
表2关键点筛选模块在不同姿态估计网络中的消融实验
如表3所示,在自顶向下的姿态估计网络的框架下,人体关键点的阈值设置很大程度上影响跟踪精度MOTA指标。而在使用了关键点筛选模块下,人体关键点阈值对跟踪精度MOTA指标的影响将显著性的减小,缓解了多人姿态跟踪任务中人体关键点阈值难以调整的问题。
表3关键点筛选模块在不同阈值下的性能表现
表4报告了本发明的方法与其他方法的结果对比,包括:LightTrack、Miracle+、OpenSV AI、STAF。从表中发现,本发明的方法在PoseTrack 2018数据集上表现出优异的结果,其中,图5为该数据集上姿态估计可视化结果,图6为姿态跟踪可视化结果。
表4本发明的方法与其他方法对比
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于关键点筛选的姿态跟踪方法
- 一种基于光流法的受限局部人脸关键点检测与跟踪方法