基于数值模拟与人口数据的选址数据处理方法及系统
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及计算机数值模拟及模型数据处理领域,尤其涉及一种基于数值模拟与人口数据的选址数据处理方法及系统。
背景技术
合理的企业布局选址,由于收到客观自然环境因素、城市建设数据因素等影响,可以有效降低企业生产活动可能导致的大气污染物(例如SO
在我国工业发展早期,企业选址时考虑的因素主要是交通、规划要求以及经济效益等,现有的工厂企业的布局选址方法中,考虑地方经济水平、交通状况的方法已经有很多,形成了相对完善的选址方法,单该些方法对环境健康等影响的考虑相对较少,随着公共卫生安全越来越受到公共大众的关注,人们开始呼吁在企业进行选址时考虑更多的环境健康风险等多种因素,但对于涉及到公共健康药品等特殊类型生产企业的简况风险评估方法,当前仍旧是欠缺的,依据现有的建厂选址方式及参考模型,并不能满足未来区域对于环境健康等方面的总体要求。
发明内容
有鉴于此,本发明提出了一种基于数值模拟与人口数据的选址数据处理方法及系统,主要考虑利用人群分布数据、大气污染物排放扩散特征数据等,通过建立更为精准科学的数学模型,合理处理选址数据,为现有的企业选址方法提供补充。
具体而言,本发明提供了如下技术方案:
一方面,本发明提供了一种基于数值模拟与人口数据的选址数据处理方法,该方法包括:
S1、确定选址的地理范围,作为模型建立的模拟范围;
S2、基于所述模拟范围,以及建设用地数据,将模拟范围划分为网格单元,形成备选地块;
S3、将企业源强信息数据依次放入各备选地块,并确定所述企业源强信息数据在各备选地块中的位置坐标信息,进而进行大气污染物扩散模拟,得到大气污染物空间浓度分布数据;
S4、基于各备选地块的划分,将模拟范围内的人口数据网格化,形成人口分布网格数据;
S5、基于人口分布网格数据、大气污染物空间浓度分布数据,计算各备选地块的健康风险值;计算不同布局情景下模拟范围内所有备选地块的总风险值;所述总风险值基于不同布局情景下的健康风险值获得;
S6、对不同布局情景下的所述总风险值进行排序,以总风险值最低的布局情景作为选址模型。
优选的,所述企业源强信息数据包括污染物排放强度、排放速率、排放高度、排放方式。
优选的,所述位置坐标信息包括UTMX、UTMY、海拔高度。
优选的,所述S3中,将企业源强信息数据依次放入各备选地块时,以备选地块中心点作为企业厂址布局数据中心点,确定企业源强信息数据在各备选地块中的位置坐标信息。
优选的,所述企业源强信息数据包括点源格式、面源格式;
点源格式包括:烟囱的坐标、烟囱高度、烟囱内径、烟囱出口温度、烟囱出口烟气平均流速、污染物排放量;
面源格式包括:左下角坐标、左上角坐标、右上角坐标、右下角坐标、高程、面源排放高度、污染物排放强度。
优选的,所述S5中,计算各网格的健康风险值方式为:
P
其中,P
优选的,所述总风险值为某一布局情景下各备选地块的健康风险值之和。
优选的,所述S2中,网格划分的分辨率大于等于50m×50m。
此外,本发明还提供了一种基于数值模拟与人口数据的选址数据处理系统,所述系统包括:
网格划分模块,用于确定选址的地理范围,作为模型建立的模拟范围;以及基于所述模拟范围,以及建设用地数据,将模拟范围划分为网格单元,形成备选地块;
污染浓度计算模块,用于将企业源强信息数据依次放入各备选地块,并确定所述企业源强信息数据在各备选地块中的位置坐标信息,进而进行大气污染物扩散模拟,得到大气污染物空间浓度分布数据;
人口数据模块,基于各备选地块的划分,将模拟范围内的人口数据网格化,形成人口分布网格数据;
健康风险值计算模块,用于基于人口分布网格数据、大气污染物空间浓度分布数据,计算各备选地块的健康风险值;以及计算不同布局情景下模拟范围内所有备选地块的总风险值;所述总风险值基于不同布局情景下的健康风险值获得;
排序模块,用于对不同布局情景下的所述总风险值进行排序,以总风险值最低的布局情景作为选址模型。
优选的,所述系统还包括输出模块,以备选地块方式输出各布局情景下的选址模型,在输出的选址模型中,基于各备选地块的健康风险值以不同颜色标识各备选地块。
额外的,本发明还提供了一种设备,该设备包括处理器及存储器,所述处理器可以调用存储器中的计算机指令,以执行如上所述的基于数值模拟与人口数据的选址数据处理方法。
与现有技术相比,本发明技术方案在数据处理及建模时,充分考虑了人口数据因素、健康风险因素,是对现有的企业建设选址方法的一个有效补充,能够更为精确合理地建立符合实际地理环境、人口环境的数值模型,从而为后续的建设选址的科学合理性提供数据支撑。本发明可以避免因为企业选址不当,而造成的企业搬迁经济损失、环境污染影响、人口健康损害、社会舆情等问题。本方案方法简便,可视化的数据比对更为直观。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
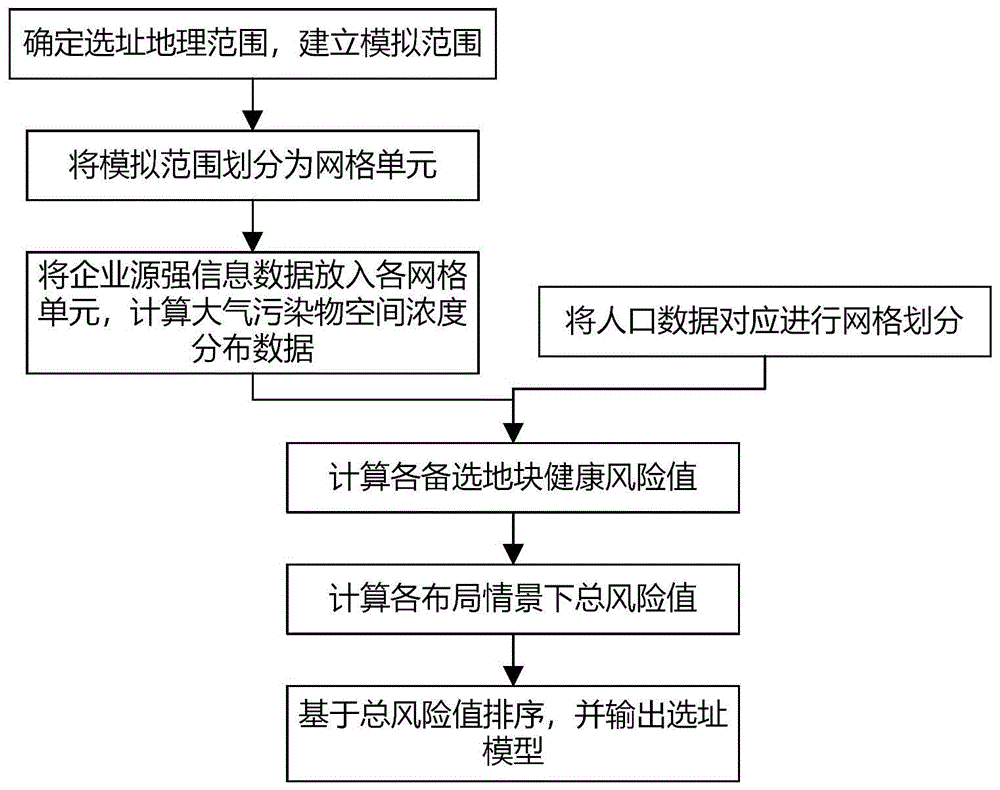
图1为本发明实施例的方法流程图;
图2为本发明实施例的布局选址研究区域研究地块划分图;
图3为本发明实施例的情景1各备选网格总健康风险值对比图;
图4为本发明实施例的情景2各备选网格总健康风险值对比图。
具体实施方式
下面结合附图对本发明实施例进行详细描述。应当明确,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本领域技术人员应当知晓,下述具体实施例或具体实施方式,是本发明为进一步解释具体的发明内容而列举的一系列优化的设置方式,而该些设置方式之间均是可以相互结合或者相互关联使用的,除非在本发明明确提出了其中某些或某一具体实施例或实施方式无法与其他的实施例或实施方式进行关联设置或共同使用。同时,下述的具体实施例或实施方式仅作为最优化的设置方式,而不作为限定本发明的保护范围的理解。
本发明的方案,主要考虑利用人群分布数据、大气污染物排放扩散特征数据等,通过建立更为精准科学的数学模型,优化企业的布局选址,为现有的企业选址方法提供补充,可对一定区域内各位置选址建厂的人群健康风险等影响进行科学定量评估,从而识别最优选址地点,为最终的选址建设提供科学的依据。
结合图1所示,在一个具体的实施例中,本方案的实施步骤如下:
(1)设定选址范围:根据项目实际情况或对于建设需求数据等,确定选址的地理范围,该范围亦作为模型的模拟范围;
(2)划分备选网格单元:根据模拟范围(即上一步中确定的选址范围)和企业规模(即建设用地规模),将选址范围划分为合理分辨率的网格单元,即备选地块数据;网格分辨率应根据企业厂址实际占地面积数据范围和选址范围确定,应保证备选地块可将企业完整容纳且网格数量不可过多,例如在14km×14km的选址范围,可以选用100m×100m的网格,在50km×50km的选址范围时可选用1km×1km的网格,在一个优选的实施方式中,最小分辨率设置为50m×50m。
(3)污染物扩散模拟:将企业源强信息数据依次放入各个备选地块,该企业源强信息数据包括污染物排放强度、排放速率、排放高度、排放方式等。
确定企业源强在各备选网格的位置坐标信息,位置坐标信息包括UTM坐标系统(可以通用例如横墨卡托格网系统等)下的企业源强位置点的经纬坐标UTMX、UTMY以及海拔高度。UTMX为企业源强位置点的经度坐标、UTMY为企业源强位置点的纬度坐标,UTMX、UTMY的确定可通过excel等方式操作完成、亦可通过编程等方式实现。
在具体操作时,以备选网格(即各个备选地块)中心点为企业厂址布局中心点,计算排放源强在网格点内的坐标。海拔高度,可以在确定了UTMX、UTMY后,使用Global mapper等软件从地形数据中进行提取,例如可采用美国地质勘探局(USGS)发布的SRTMDEM 90m分辨率地形数据。利用数值模型对各备选地块情境下企业大气污染物排放进行大气污染物扩散模拟;得出不同布局情景下大气污染物扩散贡献结果,形成大气污染物空间浓度分布数据,输出网格文件,文件可采用例如.grd格式等。数值模型可以选用AERMOD、CALPUFF等模型。
企业源强信息数据分为点源、面源两种类型。
点源格式:包括烟囱的坐标(X、Y)、烟囱高度(m)、烟囱内径(m)、烟囱出口温度(℃)、烟囱出口烟气平均流速(m/s)、污染物排放量(g/s)等。
面源格式:包括左下角坐标(X、Y)、左上角坐标(X、Y)、右上角坐标(X、Y)、右下角坐标(X、Y)、高程(米)、面源排放高度(米)、污染物排放强度(g/m
无论是点源还是面源,在本方案中的作用都是提供污染物的释放源强,在方案使用时将相应位置参数和排放参数输入数值模型系统即可。在网格中同时存在点源与面源数据时,将二者同时输入模型即可,模型是可同时模拟点源和面源的污染物释放过程的。对于涉及多个网格的面源,在处理时应保证面源中心与备选网格中心点坐标一致即可。
(4)计算健康风险值
健康风险值计算的基础数据采用在中国人口问题研究中使用较多的LandscanGlobal人口数据进行进一步的健康风险分析。该数据将地理因子、自然环境因子、社会经济因子等都纳入其计算算法,提升了数据质量和准确性,是目前涉及人口数据研究中被广泛采用的相对权威和准确的人口空间数据。本数据的数据格式为.asc格式,利用ArcGis软件对数据格式转换为.grd格式的网格数据,同时调整数据网格分辨率,并裁剪输出选址范围内的人口分布.grd网格文件。网格分辨率应与污染物扩散模拟输出的.grd文一致。
基于Landscan Global人口数据(也可选用研究区域可获取的其他人口网格化数据)和数值模型模拟的大气污染物空间浓度分布数据,以及选址区域网格划分数据,定义了考虑人群影响与污染物浓度情况下的网格健康风险值的计算方法,即公式(1),用来表征企业大气污染物排放带来的环境健康影响,该公式以污染物浓度和人口为计算基础,两项相乘之积可同时反映不同网格间人口与污染物浓度差异的影响,定量的体现不同备选网格间的环境健康风险情况,便于直观比较,以及进一步进行总体评估。
P
式中,P
各网格总风险值P
计算每一布局情景下各网格(即各备选地块)的健康风险值P
(5)健康风险排序及选址优化:将所有布局情景的总风险值进行排序,即可筛选得到大气环境影响小的优选地块。在本实施例中,P值越大,代表总风险越高。
下面,以某市的生物医药厂选址为例,对本发明的方案进一步展开阐述。
1、布局选址模拟方案设置
本实例中以某生物药厂为例对选址优化方法进行了应用,为对比分析边界效应对选址的影响,例如布局点位于边界网格时,网格之外的高浓度区域的健康风险值存在无法进行计算的情况,本实例中共设置两个情景:(1)不设置缓冲网格;(2)设置缓冲网格。两情景的设置方式如下:
情景1:选取范围为14km×14km的区域,将该区域分为1km×1km,共196个网格单元作为备选地块,即图2中的所有网格区域;将该企业排放源强数据依次放入各个备选地块,依次放入的过程为:确定企业在各备选地块的源强位置坐标(即UTMX、UTMY、海拔高度数据);UTMX、UTMY的确定可通过excel操作完成或者编程实现;以备选网格中心点为企业布局中心点,计算排放源强在网格点内的坐标数据;海拔高度为在确定了UTMX、UTMY后,使用globalmapper软件从地形数据进行提取,可采用美国地质勘探局(USGS)发布的SRTMDEM90m分辨率地形数据。
如表1所示,为某备选网格源强数据示例,利用数值模型(例如CALPUFF模型、AERMOD模型等)模拟微生物气溶胶在各备选网格的大气环境扩散过程,得到气溶胶对网格的浓度贡献.grd文件;计算各情境下的网格健康风险值P
表1源强释放参数表
情景2:考虑网格设置的边界效应,选取范围为14km×14km的区域,将该区域分为1km×1km,共196个网格单元,如图2中的深色区域。将最靠外的两层网格设置为缓冲网格,不作为备选地块,仅将内部的10×10共100个网格单元作为备选地块。将该企业排放源强依次放入各个备选地块,利用数值模型模拟微生物气溶胶在大气环境的扩散情况;计算各情境下的网格健康风险值P
2、布局选址模拟结果分析
根据布局选址方案设置,利用数值模型对196个备选地块进行模拟,计算了各布局情境下该生产企业对周边区域的总人群健康风险值,见表2。下面分两个情景对模拟结果进行讨论:
情景1:在该情境下,196个备选地快的总健康风险值范围为1.98×107~3.09×1010,其中最小健康风险值出现在整个区域最西北处的183号网格,为1.98×107,最大健康风险值出现在整个区域南部的35号网格,为3.09×1010。各备选网格的总健康风险分布对比见图3所示,可以看出高总健康风险值的网格主要分布在研究区域南部,该区域是人口密度较大的某市市区,在这一区域选址建厂将导致高的健康风险,不适合该生物医药生产企业选址建厂。低总健康风险值主要是研究区域的北部,该区域为人口密度较小的某市郊区,在这些网格选址建厂所带来的总健康风险值相对较小,以左上角的183号地块最小,选取该地块作为当前情景下的最优选址网格,具体如图3所示。
情景2:在不考虑边界效应的情况下,情景1选出了183号地块作为最优布局网格,但该点仅对研究区域内的人口健康风险进行了考虑,未考虑边界之外的人口健康风险。情景2在情景1的基础上,设置了2km的缓冲区域,仅对内圈层的10×10个网格进行总风险比较,该情景可以更加全面地将企业周边的人口数据因素纳入考虑之中。基于该情景的计算结果见表2中加粗部分。该情境下的健康风险范围为8.96×107~3.09×1010。最大总健康风险值35号网格与情景1的结果相同,但最小健康风险值位置发生了变化,出现在157号网格,为8.96×107,在本情景下,选取该地块作为当前情景下的最优选址网格,具体参见图4所示。
通过对比情景1与情景2的结果,认为设置缓冲区域的情景2的选址方法更加合理,因此将情景2的最终布局选址点157号网格作为最优布局点,该布局点与企业原址相比,周围人群分布更少,带来的人群健康风险更低。
4.应用结果讨论
在本实例中,通过应用本方案提出的企业布局选址方式,以某生物药厂的布局选址为例,将14km×14km范围划分为1km×1km的196个网格,利用数值模型进行了196次运算,并计算了各地块的总健康风险,经过不同地块的对比,选择157号地块作为了最终的布局选址地块。在进行案例应用的过程中,对该方法的进一步改进方向,提出以下几点思考:
(1)边界效应。本方案中设置了考虑边界效应和不考虑边界效应的两种情景,两种情景的计算结果有所差异,针对这一问题,优选的实施方式是:在利用本方法进行企业布局选址计算时,模型建模区域应该大于可选区域,设置一定距离的缓冲区域,以更加合理的对位于可选区域边界处地块进行健康风险评估。
(2)实际应用。在本方案中,对14×14km范围内的196个网格依次进行了数值模型模型模拟,并计算了所有情景的总健康风险值,计算量大,耗时较久。在实际的应用中,企业的布局选址需要考虑多方面的因素,如交通、人口密度、成本等,为减少模型运算量,可利用这些因素对选址区域进行初步筛选,在得到较少数量的备选地块后,再利用该方法进行环境健康风险计算,选出最优布局点,将该方法作为现有企业选址方法的补充。
在又一个实施例中,本方案还可以通过设置一种基于数值模拟与人口数据的选址数据处理系统的方式来实现,该系统包括:
网格划分模块,用于确定选址的地理范围,作为模型建立的模拟范围;以及基于所述模拟范围,以及建设用地数据,将模拟范围划分为网格单元,形成备选地块;
污染浓度计算模块,用于将企业源强信息数据依次放入各备选地块,并确定所述企业源强信息数据在各备选地块中的位置坐标信息,进而进行大气污染物扩散模拟,得到大气污染物空间浓度分布数据;
人口数据模块,基于各备选地块的划分,将模拟范围内的人口数据网格化,形成人口分布网格数据;
健康风险值计算模块,用于基于人口分布网格数据、大气污染物空间浓度分布数据,计算各备选地块的健康风险值;以及计算不同布局情景下模拟范围内所有备选地块的总风险值;所述总风险值基于不同布局情景下的健康风险值获得;
排序模块,用于对不同布局情景下的所述总风险值进行排序,以总风险值最低的布局情景作为选址模型。
此外,为便于使用者的直观比对和使用,所述系统还包括输出模块,以备选地块方式输出各布局情景下的选址模型,在输出的选址模型中,基于各备选地块的健康风险值以不同颜色标识各备选地块。例如,参考图3、图4,在某一特定的情景下的选址模型,可以通过不同颜色深度,或者不同的色彩,或者不同的填充线性等方式,标识出不同的备选地块的健康风险值,从而便于模型之间的直观比对。当然,输出方式也可以是输出如表2所示的风险值数据表,以进行风险值的直接比对。
本方案在又一种实施方式下,可以通过设备的方式来实现,该设备可以包括执行上述各个实施方式中各个或几个步骤的相应模块。因此,可以由相应模块执行上述各个实施方式的每个步骤或几个步骤,并且该电子设备可以包括这些模块中的一个或多个模块。模块可以是专门被配置为执行相应步骤的一个或多个硬件模块、或者由被配置为执行相应步骤的处理器来实现、或者存储在计算机可读介质内用于由处理器来实现、或者通过某种组合来实现。该设备可以利用总线架构来实现。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本方案的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本方案的实施方式所属技术领域的技术人员所理解。处理器执行上文所描述的各个方法和处理。例如,本方案中的方法实施方式可以被实现为软件程序,其被有形地包含于机器可读介质,例如存储器。在一些实施方式中,软件程序的部分或者全部可以经由存储器和/或通信接口而被载入和/或安装。当软件程序加载到存储器并由处理器执行时,可以执行上文描述的方法中的一个或多个步骤。备选地,在其他实施方式中,处理器可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行上述方法之一。
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,可以具体实现在任何可读存储介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random AccessMemory,RAM)等。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 基于大数据分析平台的发电大数据预处理方法及系统
- 一种基于元数据的数据共享自订阅处理方法及系统
- 基于数值模拟的数据处理方法、存储介质、电子装置
- 基于数值模拟的数据处理方法、存储介质、电子装置