表征移动穿过纳米孔的多核苷酸的方法
文献发布时间:2023-06-19 19:28:50
技术领域
本公开提供了在靶多核苷酸相对于检测器如跨膜纳米孔移动时表征所述靶多核苷酸的方法。本公开还提供了用于此类方法的新型多核苷酸衔接子和试剂盒。本公开还提供了重新读取多核苷酸的方法。
背景技术
纳米孔感测是一种依赖于对分析物分子与离子传导通道之间的个别结合或相互作用事件的观察的分析物检测和表征方法。可以通过在电绝缘膜中放置纳米尺寸的单孔和测量在存在分析物分子的情况下通过孔的电压驱动的离子电流来产生纳米孔传感器。纳米孔内部或附近的分析物的存在将改变通过孔的离子流,从而引起在通道上测量的离子或电流改变。分析物的同一性通过其独特的电流特征揭露,尤其是电流块的持续时间和程度以及与孔相互作用期间电流电平的变化。
多核苷酸是用于以这种方式进行感测的重要分析物。多核苷酸分析物的纳米孔感测可以揭示所感测的分析物的身份并对其执行单分子计数,但也可以提供有关其组成的信息,例如其核苷酸序列,以及例如碱基修饰、氧化、还原、脱羧、脱氨基等特征的存在。纳米孔感测可能允许快速且廉价的多核苷酸测序,从而提供数十到数万个碱基长度的多核苷酸的单分子序列读段。
使用纳米孔感测的聚合物表征的基本组成部分中的两个组成部分是:(1)控制聚合物移动通过孔;以及(2)在聚合物移动通过孔时区分组分构建块。在分析物(例如多核苷酸)的纳米孔感测期间,重要的是控制多核苷酸相对于孔的移动。不受控制的移动可阻止或阻碍多核苷酸的准确表征。例如,当不控制多核苷酸相对于孔的移动时,准确区分均聚多核苷酸中的每个核苷酸是成问题的。
已知通过使用马达蛋白来控制多核苷酸的移动来控制多核苷酸相对于检测器如纳米孔的移动。合适的马达蛋白包含多核苷酸处理酶,例如解旋酶、核酸外切酶、拓扑异构酶等。马达蛋白以受控方式处理多核苷酸。因此,马达蛋白可以用于控制如多核苷酸等聚合物相对于检测器如纳米孔的移动。
当检测器是纳米孔时,所公开的方法通常涉及使用马达蛋白将多核苷酸馈送到纳米孔中。此移动方向在本文中进行了更详细的描述。涉及将多核苷酸馈送到纳米孔中的方法已被广泛开发并证明在对多核苷酸进行表征方面非常有用。
然而,仍然需要表征多核苷酸的另外的方法。一个问题是,在一些情况下,可能期望获得与从涉及将多核苷酸馈送到检测器如纳米孔中的方法获得的数据不同的数据。例如,在涉及将多核苷酸馈送到检测器中的方法中,由多核苷酸表征产生的数据的错误概况在一些情况下对于多核苷酸的准确表征可能不是最佳的。另一个问题是,当使用马达蛋白将多核苷酸馈送到检测器如纳米孔中时,所述马达蛋白可能会以不受控制的方式在多核苷酸链上向前跳跃。这种现象也被称为滑移。当表征多核苷酸时,滑移可能是有问题的,例如,它会导致多核苷酸中的一个或多个核苷酸不能被准确表征。当多核苷酸的表征是要确定其序列时,这特别是有问题的。迄今为止,用于减少滑移的策略必须集中在修饰马达蛋白上,以最小化其在多核苷酸链上滑移的倾向。然而,相对于检测器如纳米孔使多核苷酸移动的替代性方法也将是有用的。
还需要改进当表征多核苷酸时获得的数据的方法。一个问题是,在一些情况下,期望提高当表征多核苷酸时获得的表征数据的准确度。在一些已知的方法中,对来自多核苷酸的样品的多个多核苷酸进行表征并且聚集获得的数据,以提高总体准确度。然而,这可能会引起问题。例如,样品中的异质性可以意指当聚集从表征多条多核苷酸链获得的数据时,可能会丢失关于链之间差异的有用信息。此外,一旦加工了初始链,就需要捕获新链进行表征,从而导致效率低下。因此需要替代的和/或改进的表征多核苷酸的方法。
由于这些和其它原因,需要新的和/或改进的相对于检测器如纳米孔使多核苷酸移动的方法。
发明内容
本公开涉及一种通过使用马达蛋白在靶多核苷酸相对于检测器移动时表征所述靶多核苷酸的方法。更具体地,本公开涉及其中马达蛋白将多核苷酸从检测器中移动出去的方法。因此,多核苷酸的移动方向与其中将多核苷酸移动到纳米孔中的已知方法相反。这在本文中进行了更详细的描述。
在所公开的方法中,马达蛋白最初在多核苷酸上在停靠部分(stalling moiety)处停靠,并且本文所提供的方法涉及使马达蛋白解停靠(destalling),使得所述马达蛋白可以控制多核苷酸从检测器(例如纳米孔)中移动出去。本文更详细地描述了使马达蛋白停靠和解停靠的方法。
虽然本公开提供了作为示例性检测器的纳米孔,但本文所提供的方法适用于检测器,所述检测器包含(i)零模波导,(ii)场效应晶体管,任选地纳米线场效应晶体管;(iii)AFM尖端;(iv)纳米管,任选地碳纳米管以及(V)纳米孔。所公开的方法特别适用于其中使多核苷酸移动穿过检测器或穿过含有检测器的结构,例如检测器芯片中的孔的方法。
因此,本文提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使具有第一开口和第二开口的检测器或(ii)包括检测器的具有第一开口和第二开口的结构与所述靶多核苷酸接触;其中所述靶多核苷酸具有停靠在其上的马达蛋白;其中所述马达蛋白在停靠部分停靠;
(ii)使所述停靠部分与所述纳米孔接触,由此使所述马达蛋白解停靠;以及
(iii)在所述马达蛋白控制所述靶多核苷酸在从所述第二开口到所述第一开口的方向上穿过所述检测器或结构的移动时对所述靶多核苷酸的特性进行一个或多个测量;由此表征所述靶多核苷酸。
本文还提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使检测器与结合有马达蛋白的所述靶多核苷酸接触,其中所述靶多核苷酸在所述马达蛋白的多核苷酸结合位点处与所述马达蛋白结合;
(ii)在所述马达蛋白控制所述靶多核苷酸在第一方向上相对于所述检测器的移动时对所述靶多核苷酸的特性进行一个或多个测量;
(iii)使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在第二方向上相对于所述检测器移动;
(iv)将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在所述第一方向上相对于所述检测器的所述移动时对所述靶多核苷酸的特性进行一个或多个测量;
由此表征所述靶多核苷酸。
本文还提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使具有第一开口和第二开口的跨膜纳米孔的所述第一开口与所述靶多核苷酸接触;其中所述靶多核苷酸具有停靠在其上的马达蛋白;其中所述马达蛋白在停靠部分停靠;
(ii)使所述停靠部分与所述纳米孔接触,由此使所述马达蛋白解停靠;以及
(iii)在所述马达蛋白控制所述靶多核苷酸在从所述纳米孔的所述第二开口到所述纳米孔的所述第一开口的方向上穿过所述纳米孔的移动时对所述靶多核苷酸的特性进行一个或多个测量;由此表征所述靶多核苷酸。
在一些实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的所述移动。在一些实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述反式侧,并且所述纳米孔的所述第二开口位于所述顺式侧,并且所述马达蛋白控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的所述移动。
在一些实施例中,所述方法包括跨所述纳米孔施加力,并且其中所述马达蛋白控制所述靶多核苷酸在与所施加的力相反的方向上穿过所述纳米孔的所述移动;其中所述力优选地包括跨所述纳米孔施加的电压电位。
在一些实施例中,所述马达蛋白是解旋酶。在一些实施例中,所述马达蛋白是DNA依赖性ATP酶(Dda)解旋酶。
在一些实施例中,衔接子与靶多核苷酸的一端或两端连接。在一些实施例中,所述马达蛋白停靠在所述衔接子上。
在一些实施例中,所述纳米孔在所述靶多核苷酸的第一端处捕获前导序列,并且所述马达蛋白在所述靶多核苷酸的第二端处或在与所述靶多核苷酸的所述第二端连接的衔接子上停靠。
在一些实施例中:
-所述靶多核苷酸是单链的;
-所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述靶多核苷酸的所述第一端处或包括在与所述靶多核苷酸的所述第一端连接的衔接子中;并且
-所述马达蛋白停靠在所述靶多核苷酸的所述第二端处或停靠在所述靶多核苷酸的所述第二端处的衔接子上。
在一些实施例中,所述靶多核苷酸是双链的。
在一些实施例中:
-所述靶多核苷酸是双链的,并且包括第一链和第二链;
-所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述多核苷酸的第一端处并且包括在所述第一链中或包括在与所述第一链连接的衔接子中;并且
-所述马达蛋白停靠在所述靶多核苷酸的第二端处。
在一些实施例中,所述马达蛋白停靠在所述靶多核苷酸的所述第一链的所述第二端处或停靠在所述靶多核苷酸的所述第一链的所述第二端处的衔接子上。在一些实施例中,所述第一链和所述第二链通过所述第一链的所述第二端处的发夹衔接子连接在一起;并且所述马达蛋白停靠在所述发夹衔接子处。在一些实施例中,所述第一链和所述第二链通过与(i)所述第一链的所述第二端和(ii)所述第二链的第一端连接的发夹衔接子连接在一起,并且所述马达蛋白停靠在所述双链多核苷酸的所述第二链的第二端处或停靠在所述第二链的所述第二端处的衔接子上。
在一些实施例中,所述靶多核苷酸包括与标签序列互补的部分。在一些实施例中,所述靶多核苷酸包括具有与其杂交的寡核苷酸的部分,并且其中所述寡核苷酸包括:(a)用于与所述靶多核苷酸杂交的杂交部分和(b)(i)与标签序列互补的部分或(ii)能够与标签结合的亲和分子。在一些实施例中,所述靶多核苷酸是双链的并且所述与标签序列互补的部分是所述多核苷酸的所述第一链的一部分和/或所述具有与其杂交的寡核苷酸的部分是所述多核苷酸的所述第一链的一部分。
在一些实施例中,所述马达蛋白停靠在包括一个或多个停靠单元的停靠位点处,所述一个或多个停靠单元独立地选自:
-多核苷酸二级结构,优选地发夹或G-四链体(TBA);
-核酸类似物,优选地选自肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)和无碱基核苷酸;
-间隔子单元,其选自硝基吲哚、肌苷、吖啶、2-氨基嘌呤、2-6-二氨基嘌呤、5-溴-脱氧尿苷、反向胸苷(反向dT)、反向双脱氧胸苷(ddT)、双脱氧胞苷(ddC)、5-甲基胞苷、5-羟甲基胞苷、2'-O-甲基RNA碱基、异脱氧胞苷(Iso-dC)、异脱氧鸟苷(Iso-dG)、C3(OC
-荧光团、如traptavidin、链霉亲和素和中性亲和素等亲和素和/或生物素、胆固醇、亚甲蓝、二硝基酚(DNP)、地高辛和/或抗地高辛以及二苄基环辛炔基团。
在一些实施例中,使所述马达蛋白解停靠包括向所述多核苷酸施加解停靠力,其中所述解停靠力的幅度低于读取力和/或与读取力具有相反方向,其中所述读取力是在所述马达蛋白控制所述靶多核苷酸的移动并且进行测量以确定所述多核苷酸的一个或多个特性的同时施加的力。在一些实施例中,使所述马达蛋白解停靠包括在所述解停靠力与所述读取力之间逐步施加所施加的力一次或多次。
在一些实施例中,所述马达蛋白停靠在包括一个或多个停靠单元和一个或多个暂停部分的停靠位点处;并且其中使所述一个或多个暂停部分与所述纳米孔接触延迟了所述多核苷酸穿过所述纳米孔的所述移动,由此使所述马达蛋白从所述一个或多个停靠单元中解停靠。在一些实施例中,所述暂停部分包括一个或多个暂停单元,所述一个或多个暂停单元独立地选自:
-多核苷酸二级结构,优选地发夹或G-四链体(TBA);
-核酸类似物,优选地选自肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)和无碱基核苷酸;
-荧光团、如traptavidin、链霉亲和素和中性亲和素等亲和素和/或生物素、胆固醇、亚甲蓝、二硝基酚(DNP)、地高辛和/或抗地高辛以及二苄基环辛炔基团;以及
-多核苷酸结合蛋白。
在一些实施例中,所述靶多核苷酸包括用于防止所述马达蛋白与所述多核苷酸脱离的阻断部分。在一些实施例中,所述靶多核苷酸包括在所述靶多核苷酸的第一端处的前导序列并且所述马达蛋白停靠在所述靶多核苷酸的第二端处或在与所述靶多核苷酸的所述第二端连接的衔接子上;并且所述阻断部分定位于所述马达蛋白与所述多核苷酸的所述第二端之间,由此防止所述马达蛋白在所述靶多核苷酸的所述第二端处与所述靶多核苷酸脱离。
还提供了一种多核苷酸衔接子,其具有第一端和第二端,所述第一端包括用于与双链多核苷酸分析物连接的连接点;其中所述多核苷酸衔接子包括(i)在所述连接点的方向上以用于加工所述衔接子的朝向停靠在所述多核苷酸衔接子上的马达蛋白和(ii)定位于所述马达蛋白与所述衔接子的所述第二端之间的阻断部分。
还提供了一种试剂盒,其包括如本文所描述的第一衔接子以及第二衔接子,所述第二衔接子包括在第一端处的单链前导序列和在第二端处的用于与双链多核苷酸分析物连接的连接点。
在本文所提供的多核苷酸衔接子或试剂盒的一些实施例中,所述多核苷酸衔接子、所述马达蛋白和/或所述阻断部分如本文所定义。
附图说明
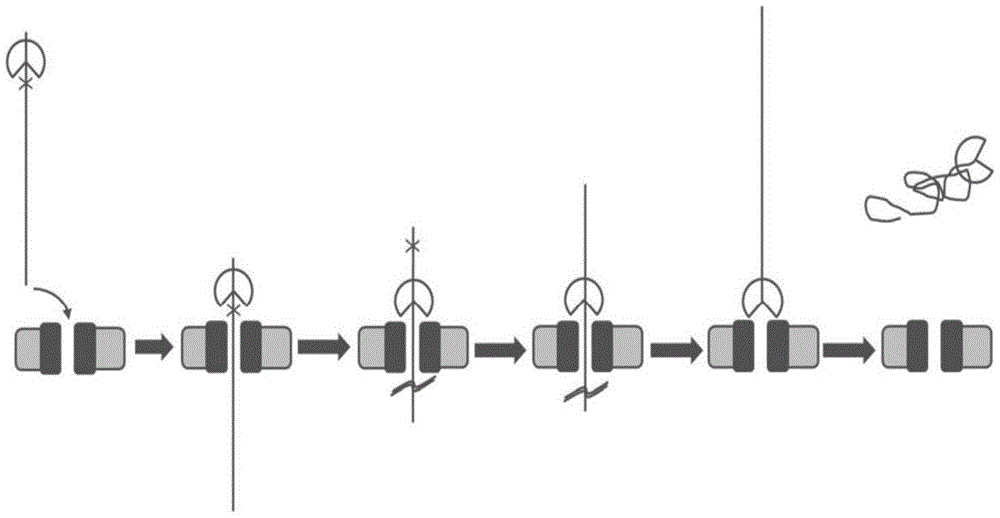
图1:示意图示出了(A)根据本文所提供的方法在马达蛋白的控制下多核苷酸(PN)从纳米孔中移动出去的方向与(B)在对比方法中多核苷酸移动到纳米孔中之间相比的区别。空心箭头示出了马达蛋白(MP)和PN的易位方向。在两种情况下,MP都是例如5'-3'解旋酶。
图2:本文所提供的方法的实施例的示意图,其中所述靶多核苷酸是单链的;靶多核苷酸包括定位于所述靶多核苷酸的第一端处的前导序列;并且马达蛋白在靶多核苷酸的第二端处被停靠部分(x)停靠。前导序列被纳米孔捕获,并且单链多核苷酸易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就控制多核苷酸从孔中移动出去。
图3:本文所提供的方法的实施例的示意图,其中靶多核苷酸是双链的;靶多核苷酸包括定位于所述靶多核苷酸的第一链的第一端处的前导序列(波浪线);并且马达蛋白在所述靶多核苷酸的所述第一链的第二端处的停靠部分(x)处停靠。前导序列被纳米孔捕获,并且靶多核苷酸的第一链易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白(MP)就会控制靶多核苷酸(PN)的第一链从孔中移动出去。
图4:本文所提供的方法的实施例的示意图,其中靶多核苷酸是双链的;靶多核苷酸包括定位于所述靶多核苷酸的第一链的第一端处的前导序列(波浪线);并且马达蛋白(MP)在连接靶多核苷酸的第一链的第二端和靶多核苷酸的第二链的第一端的发夹衔接子处的停靠部分(x)处停靠。前导序列被纳米孔捕获,并且靶多核苷酸的第一链易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就会控制靶多核苷酸(PN)的第一链从孔中移动出去。
图5:本文所提供的方法的实施例的示意图,其中靶多核苷酸是双链的;靶多核苷酸包括定位于所述靶多核苷酸的第一链的第一端处的前导序列;并且发夹衔接子连接靶多核苷酸的第一链的第二端和靶多核苷酸的第二链的第一端。马达蛋白(MP)在靶多核苷酸的第二链的第二端处的停靠部分(x)处停靠。前导序列(波浪线)被纳米孔捕获,并且靶多核苷酸的第一链、发夹衔接子和靶多核苷酸的第二链易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就会控制第二链、发夹衔接子和靶多核苷酸(PN)的第一链从孔中移动出去。
图6:带有DNA解旋酶的纳米孔测序适配体可以将5'易位至3',其中3'链优先被纳米孔捕获。适配体包括两个寡核苷酸,被称为顶部链(A)和底部链(B)。顶部链包括:5'生物素部分(C)与单价traptavidin(D)复合;DNA马达(方向性5'-3')加载在poly(dT)结合位点(E)上闭合,并被内部间隔子18部分(F)停靠;3'dT碱基用于与dA加尾的双链(G)连接。底部链包括:5'磷酸部分(H);含有BNA碱基的双链体区作为停靠化学(I);二十个连续的3'-末端胸苷碱基,作为前导(波浪线,J);位点(K)用于杂交疏水性系链。参见实例1。
图7:草图示出了图6中的测序适配体(A)与dA加尾的双链DNA多核苷酸(B)的两端连接以产生连续双链体。
图8:实例1的实验示意图,示出了多核苷酸分析物的捕获、‘解停靠’和测序。V
(A)施加的测序电位(120mV)。打开孔;通过3'前导捕获多核苷酸分析物(来自图7)。通过纳米孔分离双链体;补体链被去除。
(B)多核苷酸到达在间隔子部分处停靠的酶。酶不能在间隔子部分之上移动。
(C)施加的解锁电位(零mV),使得酶移动远离纳米孔并自由易位到间隔子部分之上。
(D)施加的测序电位(120mV)。多核苷酸被纳米孔易位,直到酶到达纳米孔,然后酶控制多核苷酸从纳米孔中移动出去。
(E)DNA马达到达前导并空转。
(F)施加的解锁电位;从纳米孔中喷出的DNA马达和分析物。
循环从(A)重复。
图9:顶部:实例1的代表性电流对时间迹线。状态A-F对应于图8中描述的那些状态。底部:顶部迹线中示出的加框区(1秒)的扩展,示出了多核苷酸从纳米孔中受控移动出去。
所施加的电位如下:A、B:120mV;C:0mV;D、E和F:120mV;循环重复。
图10:实例2中描述的实验的组分,其中多核苷酸分析物的两条链首先在没有酶的情况下易位穿过纳米孔;然后酶‘解停靠’;然后酶控制多核苷酸分析物的两条链从纳米孔中移动出去。
A.衔接子含有发夹部分和与多核苷酸分析物的一端特异性连接的3'-TCCT突出端。
B.测序衔接子,与实例1和图6中描述的相同。
C.带有不对称末端的多核苷酸分析物,一种具有3'dA-尾,并且另一种具有3'-AGGA突出端。模板链和补体链分别由虚线和实线表示。
D.A、B和C的连接产生文库分子D。
图11:实例2的实验示意图,示出了多核苷酸分析物的两条链的捕获、‘解停靠’和测序。V
(A)施加的测序电位(120mV)。打开孔;通过3'前导捕获多核苷酸分析物(来自图7)。通过纳米孔分离双链体;模板链和补体链被易位到反式室中。
(B)多核苷酸到达在间隔子部分处停靠的酶。酶不能在间隔子部分之上移动。
(C)施加的解锁电位(可变,0mV至-120mV),使得酶移动远离纳米孔并自由易位到间隔子部分之上。
(D)施加的测序电位(120mV)。多核苷酸被纳米孔易位,直到酶到达纳米孔,然后酶控制多核苷酸从纳米孔中移动出去。
(E)DNA马达在模板部分之上移动并到达发夹。
(F)DNA马达在补体部分之上移动;模板链和补体链在顺式室中重新折叠。马达到达前导部分并在纳米孔上空转。
施加的解锁电位;从纳米孔中喷出的DNA马达和分析物。
图12:(a)来自实例2的数据的代表性电流-时间迹线,其中解停靠电压在0与-120mV之间变化。当弹出电位增加到-60mV以上时没有观察到任何事件,这表明反式形成的发夹在此电压下对链的弹出具有抗性。受控移动部分由虚线框包围。(b)实例2中描述的事件的代表性电流-时间迹线。状态A-G对应于图11中描述的状态。
图13:实例3的代表性电流-时间轨迹,示出了将多核苷酸分析物捕获到纳米孔中并从纳米孔中受控移动出去。使用实例3中描述的‘主动解停靠’过程‘解停靠’DNA马达。星号表示施加了主动解停靠电位的位置,首先5秒向上五次,然后25秒向上五次,解停靠尝试之间的休息状态为3秒。在第一次尝试5秒之后,酶被解停靠并控制多核苷酸从纳米孔中移动出去,根据实例1和2,可以看到模板(Temp.)和补体(Comp)部分,然后是前导状态。A:电流-时间迹线示出了类似于实例1中描述的‘1D DNA文库’的行为,其在第一次尝试之后解停靠。B:电流-时间迹线示出了与实例2中描述的类似的由发夹部分连接的连接模板-补体多核苷酸(‘2D DNA文库’)的行为,其在第四次尝试之后解停靠。
图14:实例4中描述的实验的发夹部分,其中多核苷酸分析物的两条链首先在没有酶的情况下易位穿过纳米孔;然后酶‘解停靠’;然后酶控制多核苷酸分析物的两条链从纳米孔中移动出去。发夹中的另外的部分在初始无酶捕获阶段期间引入了另外的信号。这些部分在图中描绘如下:
(A)发夹中没有部分,作为对照。
(B)具有寡核苷酸i的发夹与发夹环杂交
(C)发夹环中的三个连续的荧光素-dT碱基ii,用星号表示
(D)根据(C),但寡核苷酸i与发夹环杂交
图15:示意图示出了带有发夹部分的双链多核苷酸分析物的捕获和无酶易位,其中发夹部分任选地携带庞大的荧光团和任选地与发夹环杂交的寡核苷酸。所述示意图示出了另外两个可检测的中间体A1和A2,所述中间体对应于与纳米孔顶部的发夹环杂交并且仅与纳米孔的管腔中的荧光团杂交的寡核苷酸,其中荧光团位于纳米孔的管腔中。另外的状态D1对应于纳米孔的管腔中的荧光团,以及在荧光团之上移动的酶。
图16:
(a)示出了对模板链和补体链通过发夹部分连接的多核苷酸的无酶移动的鉴定的数据。在酶控制的移动步骤之前,通过施加的电位引导多核苷酸穿过纳米孔。实验示意图与实例2和图11中描述的类似。发夹是图14A中描述的发夹。(i)与测序衔接子和仅含有DNA的发夹衔接子连接的多核苷酸文库。(ii)(i)中所示的分子的代表性电流-时间迹线。对组分A-G的分配基于图11中描述的状态A-G。(iii)(ii)中所示加框去的放大视图,示出了对开孔水平A和停靠水平B的鉴定。带星号区,其形状和噪声与B不同,并且与在此实例中描述的其它代表性分子的关系也不同,推测来自无酶易位部分。
(b)示出了对模板链和补体链通过发夹部分连接的多核苷酸的无酶移动的鉴定的数据,其中寡核苷酸与发夹杂交。在酶控制的移动步骤之前,通过施加的电位引导多核苷酸穿过纳米孔。实验示意图与实例2和图11中描述的类似。发夹是图14B中描述的发夹。(i)与测序衔接子和含有寡核苷酸(ON)与其杂交的DNA的发夹衔接子连接的多核苷酸文库。(ii)(i)中所示的分子的代表性电流-时间迹线。对组分A-G的分配基于图11中描述的状态A-G。(iii),(ii)中所示加框区的放大视图,示出了对开孔水平A和停靠水平B的鉴定。当与图16a中所示的实例相比时,由杂交寡核苷酸产生另外的水平A2(在图15中描述)。因此,带星号区对应于无酶易位。
(c)示出了对模板链和补体链通过发夹部分连接的多核苷酸的无酶移动的鉴定的数据,其中三个大基团(三个连续的荧光素-dT碱基;FAM)存在于发夹中。在酶控制的移动步骤之前,通过施加的电位引导多核苷酸穿过纳米孔。实验示意图与实例2和图11中描述的类似。发夹是图14C中描述的发夹。(i)与测序衔接子和含有荧光素碱基的发夹衔接子连接的多核苷酸文库。(ii)(i)中所示的分子的代表性电流-时间迹线。对组分A-G的分配基于图11中描述的状态A-G。假定通过酶在庞大的FAM区之上的缓慢移动产生了另外的D1水平。(由于弹出阶段G,补体区E被缩减,因此在此实例中未看到状态F)。(iii)(ii)中所示加框区的放大视图,示出了对开孔水平A和停靠水平B的鉴定。当与图16a中所示的实例相比时,另外的约20pA的向下滴答电流水平A1(在图15中描述)由FAM基团产生。因此,带星号区对应于无酶易位。
(d)示出了对模板链和补体链通过发夹部分连接的多核苷酸的无酶移动的鉴定的数据,其中三个大基团(三个连续的荧光素-dT碱基;FAM)存在于发夹中并且寡核苷酸(ON)与其杂交。在酶控制的移动步骤之前,通过施加的电位引导多核苷酸穿过纳米孔。实验示意图与实例2和图11中描述的类似。发夹是图14D中描述的发夹。(i)与测序衔接子和含有寡核苷酸(ON)与其杂交的荧光素碱基(FAM)的发夹衔接子连接的多核苷酸文库。(ii)(i)中所示的分子的代表性电流-时间迹线。对组分A-G的分配基于图11中描述的状态A-G。假定通过酶在庞大的FAM区之上的缓慢移动产生了电流水平向下滴答的另外的D1水平。(iii)(ii)中所示加框区的放大视图,示出了对开孔水平A和停靠水平B的鉴定。当与图16a和图16c中所示的实例相比时,另外的约20pA的向下滴答电流水平A1(在图15中描述)由FAM基团产生。通过与图16b的比较,还可以看到由于杂交ON导致的另外的水平A2。因此,带星号区对应于无酶易位。
(e)测量大肠杆菌测试文库的无酶易位的持续时间。(i)来自实例4中描述的随机大肠杆菌测试文库的四个代表性实例,其中双链多核苷酸在一端与测序衔接子连接,并且在另一端与发夹部分连接。发夹部分具有与其杂交的寡核苷酸。因此所得多核苷酸类似于图16b的多核苷酸,除了多核苷酸是随机长度的。示出的四个实例是事件拟合的电流-时间迹线,其简化了原始数据。水平A2和无酶部分(用星号表示)在每个实例中示出。使用60pA(虚线)的阈值来划分无酶部分A2。因此,带星号部分的持续时间是在电流穿过开孔水平A与寡核苷酸水平A2之间的60pA阈值的时间之间测量的。(ii)酶控链持续时间(测量为图16b、ii中所示的周期D和E的总和)与无酶捕获持续时间(如此图第i部分所描述测量)之间的关系,测量30个实例,并示出为散点图。线性回归线示出为R
图17:
(a)带有DNA解旋酶的纳米孔测序适配体可以将5'易位至3',其中3'链优先被纳米孔捕获。酶通过含有BNA区的单独阻断链并且由加载有解旋酶的链上的间隔子部分停靠。适配体包括被称为顶部链(A)、底部链(B)、阻断链(C)和反向阻断剂(D)的寡核苷酸。阻断链和反向阻断剂均与双链体的顶部链形成区杂交。DNA马达(具有方向性5'-3')加载在C与D之间的单链区中的闭合的poly(dT)结合位点(E)上,并由内部间隔子18部分(F)停靠。顶部链带有用于与dA加尾的双链连接的3'dT碱基。底部链包括:5'磷酸部分(带圆圈的P);二十个连续的胸苷碱基,作为前导(波浪线,G);位点(H)用于杂交疏水性系链。
(b)示意图示出了测序衔接子(A),如图17a中所描述,在两端处与双链多核苷酸分析物(B)连接。
(c)实例5的实验示意图,示出了多核苷酸分析物的捕获、‘解停靠’和测序。V
(A)施加的测序电位(120mV)。打开孔;通过3'前导捕获多核苷酸分析物(来自图7)通过纳米孔分离双链体;补体链被去除。
(B)纳米孔在阻断链部分短暂停靠。
(C)多核苷酸到达在间隔子部分处停靠的酶。酶不能在间隔子部分之上移动。
(D)施加的解锁电位(零mV),使得酶移动远离纳米孔并自由易位到间隔子部分之上。
(E)施加的测序电位(120mV)。多核苷酸被纳米孔易位,直到酶到达纳米孔,然后酶控制多核苷酸从纳米孔中移动出去。
(F)DNA马达到达前导并空转。
(G)施加的解锁电位;从纳米孔中喷出的DNA马达和分析物。循环从(A)重复。
(d)i,实例5的代表性电流-时间轨迹,示出了使用衔接子将多核苷酸分析物捕获到纳米孔中并从纳米孔中受控移动出去,在所述衔接子中,生物素-traptavidin反向阻断剂被单独的反向阻断剂寡核苷酸替代,如图17a和17b中所描述的。使用实例5和较早的实例3中描述的‘主动解停靠’过程‘解停靠’DNA马达。水平A-G(如图17c中所描述)通过与先前实例的关系来分配。
加框区ii(无酶易位)和iii(酶控制易位)示出为扩展的。
图18:
(a)实例6的实验示意图,示出了多核苷酸分析物的两条链的捕获、‘解停靠’和测序,其中偶尔重新读取所述链。V
(A)施加的测序电位(120mV)。打开孔;通过3'前导捕获多核苷酸分析物(来自图7)。通过纳米孔分离双链体;模板链和补体链被易位到反式室中。
(B)多核苷酸到达在间隔子部分处停靠的酶。酶不能在间隔子部分之上移动。
(C)施加的解锁电位(可变,0mV至-120mV),使得酶移动远离纳米孔并自由易位到间隔子部分之上。
(D)施加的测序电位(120mV)。多核苷酸被纳米孔易位,直到酶到达纳米孔,然后酶控制多核苷酸从纳米孔中移动出去。
(E)DNA马达在模板部分之上移动并到达发夹。
(F)DNA马达在补体部分之上移动;模板链和补体链在顺式室中重新折叠。马达到达前导部分并在纳米孔上空转。
当酶从3'-5'被推动时,状态(F)可能会返回到状态(E),从而能够重新读取链的(RR)。
(G)施加的解锁电位;从纳米孔中喷出的DNA马达和分析物。
(b)来自实例6的代表性电流-时间迹线,示出了一实例,在所述实例中,多核苷酸酶通过酶在所施加的电位下从C3前导向后推动被读取两次。酶控制部分(i)和(ii)示出为扩展的,并且C3水平也被鉴定。
(c)来自实例6中描述的实验的六个代表性重新读取实例。酶控制部分使用HMM模型绘制,所述模型使用所用的孔和酶组合的数据进行训练。所示实例中的读段至少两次映射到噬菌体λDNA的七个限制性片段的混合物的同一链。
图19:(a)实例7中描述的数据的代表性HMM映射实例,其中数据在120mV的测序电位下收集。(b)实例7中描述的数据的代表性HMM映射实例,其中数据在140mV的测序电位下收集。(c)实例7中描述的数据的代表性HMM映射实例,其中数据在160mV的测序电位下收集。(d)从图19a、19b和19c的数据中提取的单分子酶速度的直方图。指示了每个群体中的分子数量。每个群体的中值如下:120mV,319碱基对/秒;140mV,259碱基对/秒;160mV,196碱基对/秒。
图20:(a)实验示意图,与图18a/实例6中所示的相同。另外地,用于测量无酶易位(在步骤A与C之间)的‘进入’阶段用星号标记。(b)实例8中示出的三个库实例的代表性电流-时间迹线:10kb PCR片段(顶部);噬菌体λDNA(中部);以及T4 DNA(底部)。未记录T4 DNA的全长读段,因此示出了示例部分片段。在每个实例中,‘进入’阶段用星号标记,并且酶控制阶段用E标记。每个部分的持续时间是手工测量的,并标记在迹线上。示出了T4实例的进入阶段的扩展视图。不可能根据图20a可靠地检测标记为B的部分(孔顶部的阻断剂寡核苷酸)。(c)从实例8中描述的31个示例轨迹测量的测量捕获持续时间的Log-log散点图。标志物根据其来源库以灰度着色。
具体实施方式
本发明将相对于具体实施例并参考某些附图来说明,但本发明并不受限于此而只受权利要求限制。权利要求中的任何附图标记不应被解释为限制范围。当然,应当理解,不一定所有方面或优点可以根据本发明的任何特定实施例来实现。因此,例如,本领域技术人员将认识到,本发明可以以实现或优化如本文所教导的一个优点或一组优点的方式体现或执行,而不必实现如本文可以教导或建议的其它方面或优点。
当结合附图阅读时,通过参考以下详细描述,可以最好地理解本发明(关于组织和操作方法两者)以及其特征和优点。本发明的各方面和优点将根据下文描述的一个或多个实施例而变得显而易见,并且将参考所述实施例进行阐述。在整个本说明书中对“一个实施例”或“一实施例”的提及意味着结合实施例描述的特定特征、结构或特性包含在本发明的至少一个实施例中。因此,在整个本说明书中各个地方出现的短语“在一个实施例中(inone embodiment)”或“在一实施例中(in an embodiment)”不一定都是指同一个实施例,但是可以指代同一个实施例。类似地,应当理解,在本发明的示例性实施例的描述中,出于简单化本公开并且帮助理解各种发明性方面中的一个或多个的目的,本发明的各种特征有时被一起分组在单个实施例、附图或其描述中。然而,本公开的方法不应被解释为反映所要求保护的发明需要的特征比在每个权利要求中明确地叙述的更多的意图。相反,如以下权利要求书所反映,发明性方面在于比单个前述公开的实施例的所有特征更少。
应当理解,除非上下文另有说明,否则本公开的“实施例”可以具体地组合在一起。所有公开的实施例的特定组合(除非上下文另有暗示)是要求保护的发明的进一步公开的实施例。
另外,如在本说明书和所附权利要求中所使用的,除非内容另外明确指明,否则单数形式的“一个/一种(a/an)”以及“所述(the)”均包含复数对象。因此,例如,对“多核苷酸”的提及包含两个或更多个多核苷酸;对“马达蛋白”的提及包含两个或更多个此类蛋白质;对“解旋酶”的提及包含两个或更多个解旋酶;对“单体”的提及是指两个或更多个单体;对“孔”的提及包含两个或更多个孔等。
本文引用的所有出版物、专利和专利申请,无论是上文还是下文,均通过引用整体并入本文。
定义
当提及单数名词(例如“一个(a)”或“一种(an)”、“所述(the)”)时使用不定冠词或定冠词时,除非另有具体说明,否则这包含所述名词的复数形式。在本说明书和权利要求书中使用术语“包括(comprising)”时,其并不排除其它要素或步骤。此外,说明书和权利要求书中的术语第一、第二、第三等用于区分相似要素,而不一定用于描述顺序或时间次序。应当理解,如此使用的术语在适当情况下是可互换的,并且本文所描述的本发明的实施例能够以不同于本文所描述或说明的其它顺序操作。提供以下术语或定义仅用于帮助理解本发明。除非本文另有具体定义,否则在本文中使用的所有术语具有对本发明所属领域的技术人员来说相同的含义。针对本领域的定义和术语,执业医师特别参照Sambrook等人,《分子克隆:实验室手册(Molecular Cloning:A Laboratory Manual),第4版,纽约普莱恩斯维尤的冷泉港出版社(Cold Spring Harbor Press,Plainsview,New York)(2012);和Ausubel等人,《分子生物学最新方案(Current Protocols in Molecular Biology)》(增刊114),纽约约翰威利父子出版社(John Wiley&Sons,New York)(2016)。本文提供的定义不应被解释为具有小于本领域普通技术人员所理解的范围。
当提及如量、持续时间等可测量的值时,如本文所用的术语“约”意味着涵盖与指定值的±20%或±10%,更优选地±5%,甚至更优选地±1%,以及还更优选地±0.1%的偏差,因为此类偏差适合于执行所公开的方法。
如本文所用,术语“核苷酸序列”、“DNA序列”或“一个或多个核酸分子”是指任何长度的核苷酸的聚合形式,无论是核糖核苷酸还是脱氧核糖核苷酸。此术语仅指分子的一级结构。因此,此术语包含双链和单链DNA,以及RNA。如本文所用的术语“核酸”是单链或双链共价连接的核苷酸序列,其中每个核苷酸上的3'和5'末端通过磷酸二酯键连接。多核苷酸可以由脱氧核糖核苷酸碱基或核糖核苷酸碱基构成。核酸可以在体外合成制造,或者从天然来源中分离。核酸可以进一步包含经修饰的DNA或RNA,例如已经被甲基化的DNA或RNA,或已经经受翻译后修饰的RNA,所述翻译后修饰例如是采用7-甲基鸟苷的5'封端、如裂解和聚腺苷酸化等3'加工以及剪接。核酸还可以包含合成核酸(XNA),如己糖醇核酸(HNA)、环己烯核酸(CeNA)、苏糖核酸(TNA)、甘油核酸(GNA)、锁定核酸(LNA)和肽核酸(PNA)。核酸(在本文中也称为“多核苷酸”)的大小通常表示为双链多核苷酸的碱基对(bp)的数量,或在单链多核苷酸的情况下,表示为核苷酸(nt)的数量。一千bp或nt等于千碱基(kb)。长度小于约40个核苷酸的多核苷酸通常被称为“寡核苷酸”,并且可以包括用于如通过聚合酶链反应(PCR)操纵DNA的引物。
在本公开的上下文中,术语“氨基酸”以其最广泛的意义使用,并且意指包含含有胺(NH
术语“多肽”和“肽”在本文中可互换使用以指代氨基酸残基的聚合物以及其变体和合成类似物。因此,这些术语适用于氨基酸聚合物,其中一个或多个氨基酸残基是合成的非天然存在的氨基酸,如对应的天然存在的氨基酸的化学类似物,以及适用于天然存在的氨基酸聚合物。多肽还可以经历成熟或翻译后修饰过程,所述过程可以包含但不限于:糖基化、蛋白水解切割、脂质化、信号肽切割、前肽切割、磷酸化等。可以使用重组技术例如通过表达重组或合成的多核苷酸来制备肽。重组产生的肽通常基本上不含培养基,例如,培养基占蛋白质制剂体积的小于约20%,更优选地小于约10%,最优选地小于约5%。
术语“蛋白质”用于描述具有二级或三级结构的折叠多肽。蛋白质可以由单个多肽构成,或者可以包括组装形成多聚体的多个多肽。多聚体可以是同源寡聚体或异源寡聚体。蛋白质可以是天然存在的或野生型蛋白质,或者是经修饰的或非天然存在的蛋白质。蛋白质可以例如通过一个或多个氨基酸的添加、取代或缺失而不同于野生型蛋白质。
蛋白质的“变体”涵盖肽、寡肽、多肽、蛋白质和酶,其相对于所讨论的未经修饰的或野生型蛋白质具有氨基酸取代、缺失和/或插入,并且具有与其所衍生的未经修饰的蛋白质类似的生物和功能活性。如本文所用,术语“氨基酸同一性”是指序列在氨基酸对氨基酸的基础上在比较窗口上相同的程度。因此,“序列同一性百分比”通过以下来计算:在比较窗口上比较两个经过最佳比对的序列,确定相同的氨基酸残基(例如,Ala、Pro、Ser、Thr、Gly、Val、Leu、Ile、Phe、Tyr、Trp、Lys、Arg、His、Asp、Glu、Asn、Gln、Cys和Met)出现在这两个序列中的位置的数量以产生匹配位置的数量,用匹配位置的数量除以比较窗口中的位置的总数(即,窗口大小),以及将结果乘以100以产生序列同一性百分比。
对于本发明的所有方面和实施例,“变体”与对应的野生型蛋白质的氨基酸序列具有至少50%、60%、70%、80%、90%、95%或99%完整序列同一性。序列同一性还可以是全长多核苷酸或多肽的片段或部分。因此,序列可以与全长参考序列具有仅50%的整体序列同一性,但是特定区域、结构域或亚基的序列可以与参考序列共享80%、90%或多达99%的序列同一性。
术语“野生型”是指与天然存在的来源分离的基因或基因产物。野生型基因是群体中最常观察到的基因,并且因此被任意设计为基因的“正常”或“野生型”形式。相反,术语“经修饰的”、“突变体”或“变体”是指与野生型基因或基因产物相比时显示序列的修饰(例如,取代、截短或插入)、翻译后修饰和/或功能特性质(例如,改变的特性)的基因或基因产物。注意,天然存在的突变体可以被分离;通过与野生型基因或基因产物相比时其具有改变的特性这一事实来鉴定这些突变体。用于引入或取代天然存在的氨基酸的方法在本领域是众所周知的。例如,可通过在编码突变单体的多核苷酸中的相关位置处用精氨酸的密码子(CGT)置换甲硫氨酸的密码子(ATG),而用精氨酸(R)来取代甲硫氨酸(M)。用于引入或取代非天然存在的氨基酸的方法在本领域也是众所周知的。例如,可以通过在用于表达突变单体的IVTT系统中包含合成氨基酰基-tRNA来引入非天然存在的氨基酸。可替代地,其可以通过在大肠杆菌中表达突变单体来引入,所述突变单体在存在那些特定氨基酸的合成(即非天然存在的)类似物的情况下对于特定氨基酸是营养缺陷型的。如果突变单体使用部分肽合成产生,则其还可以通过裸连接产生。保守取代用具有相似化学结构、相似化学特性或相似侧链体积的其它氨基酸替代氨基酸。引入的氨基酸可以具有与其替代的氨基酸相似的极性、亲水性、疏水性、碱性、酸性、中性或电荷。可替代地,保守取代可以引入芳香族或脂肪族的另一种氨基酸代替预先存在的芳香族或脂肪族氨基酸。保守氨基酸改变在本领域是众所周知的,并且可以根据如在下表1中限定的20种主要氨基酸的性质来进行选择。在氨基酸具有类似极性的情况下,还可以参考表2中的氨基酸侧链的亲水性尺度来确定这一点。
表1-氨基酸的化学性质
表2-亲水性标度
突变体或经修饰的蛋白质、单体或肽还可以以任何方式和在任何位点进行化学修饰。优选地通过将分子与一个或多个半胱氨酸(半胱氨酸连接)连接、将分子与一个或多个赖氨酸连接、将分子与一个或多个非天然氨基酸连接、表位的酶修饰或末端的修饰对突变体或经修饰的单体进行化学修饰。用于进行此类修饰的合适方法在本领域是众所周知的。经修饰的蛋白质、单体或肽的突变体可以通过任何分子的连接进行化学修饰。例如,经修饰的蛋白质、单体或肽的突变体可以通过染料或荧光团的连接进行化学修饰。
如本文所用,亚烷基是未经取代的或经取代的二齿部分,其通过从烃化合物的相同碳原子去除两个氢原子或从两个不同碳原子各自去除一个氢原子而获得,所述烃化合物可以是脂肪族或脂环族的并且是饱和的。烃化合物可以具有1至20个碳原子,在所述情况下亚烷基是C
亚烯基是未经取代的或经取代的二齿部分,其通过从烃化合物的相同碳原子去除两个氢原子或从两个不同碳原子各自去除一个氢原子而获得,所述烃化合物可以是脂肪族或脂环族的并且包括一个或多个碳-碳双键。烃化合物可以具有2至20个碳原子,在所述情况下亚烯基是C
亚炔基是未经取代的或经取代的二齿部分,其通过从烃化合物的相同碳原子去除两个氢原子或从两个不同碳原子各自去除一个氢原子而获得,所述烃化合物可以是脂肪族或脂环族的并且包括一个或多个碳-碳三键。烃化合物可以具有2至20个碳原子,在所述情况下亚炔基是C
亚芳基是未经取代的或经取代的单环或稠合多环双齿部分,其通过去除芳香族化合物的两个氢原子、从两个不同芳香族环原子各自去除一个芳香族环原子而获得,所述部分具有5至14个环原子(除非另有说明)。通常,每个环具有5至7个或5至6个环原子。亚芳基可以是经未取代的或经取代的。
亚杂芳基是通过去除杂芳基的两个氢原子、从两个不同环原子各自去除一个环原子而获得的二齿部分。杂芳基是经取代的或未经取代的单环或稠合多环(例如,双环或三环)芳香族基团,其通常在环部分中含有5至14个原子,包含至少一个杂原子,例如1、2或3个选自O、S、N、P、Se和Si的杂原子,更典型地来自O、S和N。实例包含吡啶基、吡嗪基、嘧啶基、哒嗪基、呋喃基、噻吩基、吡唑烷基、吡咯基、噁二唑基、异噁唑基、噻二唑基、噻唑基、咪唑基、三唑基、吡唑基、噁唑基、异噻唑基、苯并呋喃基、异苯并呋喃基、苯并噻吩基、吲哚基、吲唑基、咔唑基、吖啶基、嘌呤基、肉桂基、喹喔啉基、萘啶基、苯并咪唑基、苯并噁唑基、喹啉基、喹唑啉基和异喹啉基。
亚碳环基,也被称为亚环烷基,是通过去除未经取代的或经取代的环状烷基中的两个氢原子、从两个碳原子各自去除一个碳原子而获得的二齿部分。通常,所述部分具有3至10个碳原子(除非另有说明),包含3至10个环原子。实例包含环丙烷(C3)、环丁烷(C4)、环戊烷(C5)、环己烷(C6)、环庚烷(C7)、甲基环丙烷(C4)、二甲基环丙烷(C5)、甲基环丁烷(C5)、二甲基环丁烷(C6)、甲基环戊烷(C6)、二甲基环戊烷(C7)、甲基环己烷(C7)、二甲基环己烷(C8)、薄荷烷(C10)。
亚杂环基部分是通过从杂环基的两个不同环原子去除两个氢原子而获得的二齿部分。杂环基是未经取代的或经取代的环状基团,其通常在环部分含有5至14个原子,包含至少一个杂原子,例如1、2或3个选自O、S、N、P、Se和Si的杂原子,更典型地来自O、S和N。实例包含哌嗪、哌啶、吗啉、1,3-噁嗪烷、吡咯烷、咪唑烷、噁唑烷、四氢吡嗪、四氢吡啶、二氢-1,4-噁嗪、四氢嘧啶、二氢-1,3-噁嗪、二氢吡咯、二氢咪唑和二氢噁唑基团。
亚芳基-亚烷基是通过在如本文所定义的亚芳基与亚烷基之间形成键而形成的基团。亚杂芳基-亚烷基是通过在如本文所定义的亚杂芳基与亚烷基之间形成键而形成的基团。亚碳环基-亚烷基是通过在如本文所定义的亚碳环基与亚烷基之间形成键而形成的基团。亚杂环基-亚烷基是通过在如本文所定义的亚杂环基与亚烷基之间形成键而形成的基团。
当基团被描述为被取代时,它通常被一个或多个如1个、2个或3个,通常1个或2个,通常1个取代基取代。合适的取代基可以独立地选自卤素;-OR'和–NR'
表征多核苷酸的方法
本公开涉及一种通过使用马达蛋白在靶多核苷酸相对于检测器如纳米孔移动时表征所述靶多核苷酸的方法。任何合适的马达蛋白可以在本文所提供的方法中使用。本文更详细地描述了示例性马达蛋白。
本公开还涉及表征靶多核苷酸的方法,所述方法包括使检测器与所述多核苷酸接触并重新读取所述多核苷酸,例如当所述多核苷酸相对于检测器来回移动时。这在本文中进行了更详细的描述。
更具体地,在一些实施例中,本公开涉及其中马达蛋白将多核苷酸从检测器(例如,移动出纳米孔)中移动出去的方法。因此,在此类实施例中,多核苷酸的移动方向与其中将多核苷酸移动到纳米孔中的已知方法相反。这在本文中进行了更详细的描述。
虽然本公开提供了作为示例性检测器的纳米孔,但本文所提供的方法适用于检测器,所述检测器包含(i)零模波导,(ii)场效应晶体管,任选地纳米线场效应晶体管;(iii)AFM尖端;(iv)纳米管,任选地碳纳米管以及(V)纳米孔。所公开的方法特别适用于其中使多核苷酸移动穿过检测器或穿过含有检测器的结构,例如检测器芯片中的孔的方法。
在所公开的方法中,马达蛋白通常最初在多核苷酸上在停靠部分处停靠。合适的停靠部分在本文中更详细地描述。马达蛋白在多核苷酸上的停靠具有各种优点。例如,在停靠的同时,马达蛋白通常比未停靠时消耗更少的燃料,例如当相对于多核苷酸自由移动时。减少这种非生产性燃料使用可以是有利的。
本文提供的方法通常涉及使马达蛋白解停靠,使得所述马达蛋白可以控制多核苷酸从检测器(例如,纳米孔)中移动出去。本文更详细地描述了使马达蛋白解停靠的方法。马达蛋白的受控解停靠具有各种优点,包含可以准确地确定马达蛋白开始加工多核苷酸的点。这可以用于表征多核苷酸,使得例如在数据记录开始之前,不会由于马达蛋白在多核苷酸上的不期望移动而丢失数据。
所公开的方法至少部分地基于这样的认识,即当多核苷酸从检测器如纳米孔中移动出去时获得的数据可以不同于当将相同的多核苷酸移动到检测器(例如,纳米孔)中时获得的数据。在一些实施例中,包含信号分布、噪声分布和误差分布的数据特性都可以不同于其中将相同多核苷酸移动到检测器如纳米孔中的对比方法。在一些实施例中,在所公开的方法中获得的数据与在其它已知方法中获得的数据相比具有优势。因此,当需要多核苷酸表征时,所公开的方法增加了可用的选择。因此,期望表征多核苷酸的用户可以选择最适合所讨论的特定应用的方法。
如上文所解释的,在一些实施例中,所公开的方法涉及将靶多核苷酸从检测器如纳米孔中移动出去。本文将讨论纳米孔作为示例性检测器,但方法不限于此。
纳米孔通常具有两个开口:第一开口和第二开口。此类开口通常被称为纳米孔的顺式开口和反式开口。通常第一开口是顺式开口并且第二开口是反式开口,但在一些实施例中,分别地,第一开口是反式开口并且第二开口是顺式开口。纳米孔中的符号“顺式”和“反式”开口在本领域中是常规的。例如,纳米孔的顺式开口通常面向纳米孔装置的顺式室,如本文所描述的具有顺式室和反式室的设备,并且反式开口通常面向反式室。
在本文提供的某些方法中,纳米孔的第一开口与使马达蛋白停靠在其上的多核苷酸接触。所述方法涉及使用马达蛋白来控制靶多核苷酸在从纳米孔的第二开口到纳米孔的第一开口的方向上穿过所述纳米孔的移动。
因此,从马达蛋白的角度来看,靶多核苷酸被移动出纳米孔。符号“出去”涉及多核苷酸向马达蛋白的整体移动。这种移动方向可以与其中靶多核苷酸被马达蛋白“移动到纳米孔中”的替代性模式形成对比。
这些移动方案的差异是深刻的。在本文所提供的其中多核苷酸被“移动出”孔的方法中,移动的方向是从距马达蛋白最远的纳米孔的入口(即,远侧入口)朝向最靠近马达蛋白的纳米孔的入口(近侧入口)。在其中将多核苷酸“移动到孔中”的对比方法中,移动的方向是从最靠近马达蛋白的纳米孔的入口(近侧入口)朝向距离马达蛋白最远的纳米孔的入口(远侧入口)。
因此,在所提供的方法的一些实施例中,纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述顺式侧处并且所述纳米孔的所述第二开口位于所述反式侧处。在此类实施例中,所述马达蛋白定位于所述膜的所述顺式侧上并且控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的移动。
在所提供的方法的其它实施例中,纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述反式侧处并且所述纳米孔的所述第二开口位于所述顺式侧处。在此类实施例中,所述马达蛋白定位于所述膜的所述反式侧上并且控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的移动。
图1示意性地展示了在本文所提供的方法中多核苷酸从孔中移动出去的方向与在对比方法中多核苷酸移动到孔中的方向相之间比的区别。
重新读取
在一些实施例中,本文提所供的方法包括重新读取多核苷酸以表征所述多核苷酸。重新读取所述多核苷酸包括在多核苷酸相对于检测器来回移动时对所述多核苷酸的特性进行一个或多个测量。
在一个实施例中,本文提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使检测器与结合有马达蛋白的所述靶多核苷酸接触,其中所述靶多核苷酸在所述马达蛋白的多核苷酸结合位点处与所述马达蛋白结合;
(ii)在所述马达蛋白控制所述靶多核苷酸在第一方向上相对于所述检测器的移动时对所述靶多核苷酸的特性进行一个或多个测量;
(iii)使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在第二方向上相对于所述检测器移动;
(iv)将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在所述第一方向上相对于所述检测器的所述移动时对所述靶多核苷酸的特性进行一个或多个测量;
由此表征所述靶多核苷酸。
在一相关实施例中,本文提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使检测器与结合有马达蛋白的所述靶多核苷酸接触,其中所述靶多核苷酸在所述马达蛋白的多核苷酸结合位点处与所述马达蛋白结合;
(ii)在所述马达蛋白控制所述靶多核苷酸在第一方向上相对于所述检测器的移动时对所述靶多核苷酸的特性进行一个或多个测量;
(iii)允许所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在第二方向上相对于所述检测器移动;
(iv)允许所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在所述第一方向上相对于所述检测器的所述移动时对所述靶多核苷酸的特性进行一个或多个测量;
由此表征所述靶多核苷酸。
与先前已知的方法相比,所公开的方法具有许多优点。例如,靶多核苷酸的每次读取应具有与使用相同链和相同检测器部分等效的准确度。这允许每次读取使用相同的碱基调用模型。它还促进对来自多个读段的数据进行组合。此外,多次重新读取天然序列,从而允许保留(例如)表观遗传信息。所述方法也是自适应的:可以多次重复重新读取,直到获得所需准确度的数据。
更详细地,所述方法可以包括在马达蛋白控制所述靶多核苷酸在第一方向上相对于所述检测器的移动时对所述靶多核苷酸的特性进行一个或多个测量。所述第一方向可以是马达蛋白驱动多核苷酸的移动的方向。所述第一方向可以是跨所述检测器施加的力的方向。所述第一方向可以与跨所述检测器施加的力的方向相反。
通常,所述检测器包括在具有第一开口和第二开口的结构中,或者包括具有第一开口和第二开口的跨膜纳米孔;并且步骤(i)包括用所述靶多核苷酸收缩所述第一开口。通常,所述马达蛋白控制所述靶多核苷酸在从所述第二开口到所述第一开口的方向上的移动。通常,当所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合时,所述靶多核苷酸在从所述第一开口到所述第二开口的方向上移动。
因此,当检测器是或包括纳米孔时,第一方向可以是如本文所描述的“进入”纳米孔。因此,在一些实施例中,在进行一个或多个测量的同时多核苷酸从纳米孔中移动出去。在一些实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白定位于所述膜的所述顺式侧上并控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的所述移动。在其它实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白定位于所述膜的所述反式侧上并控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的所述移动。
更常见的是,当检测器是或包括纳米孔时,第一方向是如本文所描述的“从纳米孔出去”。因此,在一些实施例中,在进行一个或多个测量的同时多核苷酸从纳米孔中移动出去。在一些实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白定位于所述膜的所述顺式侧上并控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的所述移动。在其它实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,并且所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白定位于所述膜的所述反式侧上并控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的所述移动。
所提供的方法可以包括使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合。这在下文更详细地进行描述。一旦所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,所述靶多核苷酸就在第二方向上相对于所述检测器移动。所述第二方向通常与所述第一方向相反。
因此,在其中所述检测器是或包括纳米孔的方法的一些实施例中,其中所述靶多核苷酸相对于所述检测器移动的第一方向是进入所述纳米孔,并且其中所述靶多核苷酸相对于所述检测器移动的第二方向是从纳米孔出去。在其它实施例中,其中所述靶多核苷酸相对于所述检测器移动的第一方向是从纳米孔出去,并且其中所述靶多核苷酸相对于所述检测器移动的第二方向是进入纳米孔。
所提供的方法然后可以包括将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合。然后,在对所述多核苷酸的特性进行一个或多个测量时,所述马达蛋白控制所述靶多核苷酸在所述第一方向上相对于的移动。所述第一方向与上文所描述的第一方向相同。
因此,在一个实施例中,本文还提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使具有第一开口和第二开口的跨膜纳米孔的所述第一开口与结合有马达蛋白的所述靶多核苷酸接触,其中所述靶多核苷酸在所述马达蛋白的多核苷酸结合位点处与所述马达蛋白结合;
(ii)在所述马达蛋白控制所述靶多核苷酸在从所述纳米孔的所述第一开口到所述纳米孔的所述第二开口的方向上的移动时对所述靶多核苷酸的特性进行一个或多个测量;
(iii)使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在从所述纳米孔的所述第二开口到所述纳米孔的所述第一开口的方向上移动;
(iv)将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在从所述纳米孔的所述第一开口到所述纳米孔的所述第二开口的所述方向上的所述移动时对所述靶多核苷酸的特性进行一个或多个测量;
由此表征所述靶多核苷酸。表征所述靶多核苷酸可以例如包括确定所述靶多核苷酸的序列。
例如,在一些实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的所述移动。在其它实施例中,所述纳米孔的所述第一开口位于所述膜的所述反式侧,并且所述纳米孔的所述第二开口位于所述顺式侧,并且所述马达蛋白控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的所述移动。在一些实施例中,所述方法包括跨所述纳米孔施加力(例如电压电位),并且所述马达蛋白控制所述靶多核苷酸在与所施加的力相同的方向上穿过所述纳米孔的移动。
在另一个实施例中,本文提供了一种表征靶多核苷酸的方法,所述方法包括:
(i)使具有第一开口和第二开口的跨膜纳米孔的所述第一开口与结合有马达蛋白的所述靶多核苷酸接触,其中所述靶多核苷酸在所述马达蛋白的多核苷酸结合位点处与所述马达蛋白结合;
(ii)在所述马达蛋白控制所述靶多核苷酸在从所述纳米孔的所述第二开口到所述纳米孔的所述第一开口的方向上的移动时对所述靶多核苷酸的特性进行一个或多个测量;
(iii)使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在从所述纳米孔的所述第一开口到所述纳米孔的所述第二开口的方向上移动;
(iv)将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在从所述纳米孔的所述第二开口到所述纳米孔的所述第一开口的所述方向上的所述移动时对所述靶多核苷酸的特性进行一个或多个测量;
由此表征所述靶多核苷酸。表征所述靶多核苷酸可以例如包括确定所述靶多核苷酸的序列。
例如,在一些实施例中,所述纳米孔跨越具有顺式侧和反式侧的膜,所述纳米孔的所述第一开口位于所述膜的所述顺式侧处,并且所述纳米孔的所述第二开口位于所述反式侧处,并且所述马达蛋白控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的所述移动。在其它实施例中,所述纳米孔的所述第一开口位于所述膜的所述反式侧,并且所述纳米孔的所述第二开口位于所述顺式侧,并且所述马达蛋白控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的所述移动。在一些实施例中,所述方法包括跨所述纳米孔施加力(例如电压电位),并且所述马达蛋白控制所述靶多核苷酸在与所施加的力相反的方向上穿过所述纳米孔的移动。
将多核苷酸在第二方向上相对于检测器的移动与可能发生的自发滑动区分开来是重要的。例如,一个或两个碱基的滑动不是本文所描述的重新读取的实例。通常,在步骤(iii)中,所述靶多核苷酸相对于所述检测器移动的距离的长度为至少10个核苷酸。在一些实施例中,所述靶多核苷酸相对于所述检测器移动的距离的长度为至少20个核苷酸,例如长度为至少30个核苷酸,如长度为至少40个核苷酸,例如长度为至少50个核苷酸,如长度为至少100个核苷酸。可以使用更长的距离。在步骤(iii)中的一些实施例中,所述靶多核苷酸相对于所述检测器移动的距离的长度为至少1000个核苷酸(1kb),如至少2kb,例如长度为至少5kb或至少10kb,例如长度为至少100kb或至少1000kb。
所述方法的步骤(iii)和(iv)可以重复多次以多次重新读取靶多核苷酸。步骤(iii)和(iv)可以重复至少一次,如至少2次,如至少3次,例如至少4次,例如至少5次,例如至少10次,如至少20次,例如至少50次,如至少100次,例如至少1000次,如至少10,000次,例如至少100,000次或更多次。因此,所述方法可以包括使多核苷酸相对于检测器向后和向前“使用牙线进行清洁(flossing)”。
因此,如果步骤(iii)和(iv)重复1次(并且仅1次)使得所述方法包括步骤(iii)和(iv)两次且仅两次,则所述方法将包括步骤(i)、(ii)、(iii)、(iv)、(iii
多核苷酸的在所述方法的步骤(ii)中读取的部分和多核苷酸的在步骤(iv)中读取的部分通常重叠。换言之,所述方法涉及多次重新读取多核苷酸的至少一部分。因此,在步骤(ii)中的一些实施例中,所述马达蛋白控制所述靶多核苷酸的第一部分在所述第一方向上相对于所述检测器的所述移动;并且在步骤(iv)中,所述马达蛋白控制所述靶多核苷酸的第二部分在所述第一方向上相对于所述检测器的所述移动;并且所述第一部分与所述第二部分至少部分地重叠。在一些实施例中,所述第二部分与所述第一部分的至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少97%、至少98%或至少99%重叠。在一些实施例中,所述第一部分与所述第二部分相同。因此,在一些实施例中,所述多核苷酸的一部分在所提供的方法中被重复表征。当在每次重复时所述多核苷酸的所述第二部分与前一次重复的多核苷酸的第一部分部分地但不完全地重叠时,所述多核苷酸相对于检测器以锯齿形方式逐步升降。当在每次重复时所述多核苷酸的所述第二部分与前一次重复的多核苷酸的第一部分完全重叠时,所述多核苷酸的相同部分相对于检测器向后和向前使用牙线进行清洁。
在移动期间施加的力
在所公开的方法的一些实施例中,可以跨检测器例如跨纳米孔施加力。可以控制力以控制所述方法。例如,通过增加力,可以增加或减少多核苷酸穿过检测器(例如,纳米孔)的移动,例如可以控制多核苷酸移动穿过孔的速率。
在本文所提供的方法中,可以施加任何合适的力。所述力可以是跨检测器,例如跨纳米孔施加的电位。在一些实施例中,没有跨纳米孔施加外力。例如,在一些实施例中,不施加电位。此类实施例在一些实施例中特别适合其中在多核苷酸相对于纳米孔移动时进行光学测量的方法。
在其它实施例中,所述力可以是跨纳米孔施加的电压力。可以使用任何合适的设备如本文所描述的设备来施加电压力。合适的电压电位在本文中更详细地描述。
在一些实施例中,所述力跨嵌入有纳米孔的膜施加。所述力通常从膜的顺式侧到反式侧施加;即从纳米孔的顺式侧到反式侧。所述力可以是跨纳米孔施加的正电压或跨纳米孔施加的负电压。
通常,所述力是跨纳米孔施加的正电压,使得孔的反式侧相对于孔的顺式侧为正。在此类实施例中,所述力因此会吸引带负电荷的多核苷酸从孔的顺式侧移动到反式侧。在此类实施例中,本文所提供的方法通常包括在孔的顺式侧处使用马达蛋白来控制多核苷酸在从所述孔的所述反式侧到所述孔的所述顺式侧的方向上抵抗所施加的力的移动;即在与所施加的力相反的方向上。然而,在一些实施例中,本文所提供的方法(例如,重新读取多核苷酸的方法)可以包括在孔的顺式侧处使用马达蛋白来控制多核苷酸在从所述孔的所述顺式侧到所述孔的所述反式侧的方向上在与所施加的力相同的方向上的移动。
在其它实施例中,所述力是跨纳米孔施加的负电压,使得孔的反式侧相对于孔的顺式侧为负。在此类实施例中,所述力因此会吸引带负电荷的多核苷酸从孔的反式侧移动到顺式侧。在此类实施例中,本文所提供的方法通常包括在孔的反式侧处使用马达蛋白来控制多核苷酸在从所述孔的所述顺式侧到所述孔的所述反式侧的方向上抵抗所施加的力的移动;即在与所施加的力相反的方向上。然而,在一些实施例中,本文所提供的方法(例如,重新读取多核苷酸的方法)可以包括在孔的反式侧处使用马达蛋白来控制多核苷酸在从所述孔的所述反式侧到所述孔的所述顺式侧的方向上在与所施加的力相同的方向上的移动。
然而,如下文所解释的,本文所提供的方法不依赖于在与所施加的力相反的方向上使多核苷酸移动。在一些实施例中,移动方向可以与任何施加的力的方向相同,同时仍处于孔外的方向。在此类实施例中,马达蛋白通常控制多核苷酸以大于单独施加的力所产生的速度的速度从孔中移动出去。
因此,在一些实施例中,所述力是跨纳米孔施加的正电压,使得孔的反式侧相对于孔的顺式侧为正;并且所述方法可以包括在孔的反式侧处使用马达蛋白来控制多核苷酸在所施加的力下在从孔的顺式侧到孔的反式侧的方向上的移动。在其它实施例中,所述力是跨纳米孔施加的负电压,使得孔的反式侧相对于孔的顺式侧为负;并且所述方法可以包括在孔的顺式侧处使用马达蛋白来控制多核苷酸在所施加的力下在从孔的反式侧到孔的顺式侧的方向上的移动。
设置
在所提供的方法的一些实施例中,前导序列包括在靶多核苷酸中或与多核苷酸连接。在本文所提供的方法中,前导序列可以被检测器(例如,纳米孔)捕获。
本文中更详细地描述了前导序列。通常,前导序列是没有显著二级结构的单链多核苷酸区。例如,前导序列通常不形成发夹或G-四链体,并且因此易于被纳米孔捕获。
前导序列通常提供在多核苷酸的第一端处或包括在与多核苷酸第一端连接的衔接子中。本文更详细地描述了衔接子。
通常,在多核苷酸的第一端处提供前导序列(例如,通过包括在靶多核苷酸的第一端中或通过包括在与靶多核苷酸的第一端连接的多核苷酸衔接子中),并且马达蛋白停靠在靶多核苷酸的第二端处或在与靶多核苷酸的第二端连接的衔接子上。例如,前导序列可以存在于单链多核苷酸的3'端处,并且马达蛋白可以定位于单链多核苷酸的5'端处。可替代地,前导序列可以存在于单链多核苷酸的5'端处,并且马达蛋白可以定位于单链多核苷酸的3'端处。这种设置允许多核苷酸的第一端被纳米孔捕获并穿过纳米孔,例如从第一端到第二端。多核苷酸的第二端处的马达蛋白通常防止多核苷酸使纳米孔完全易位。在本文所提供的方法中,通过在从第二端到第一端的方向上加工多核苷酸,所述多核苷酸的所述第二端处的马达蛋白通常可以因此控制所述多核苷酸从纳米孔朝向马达蛋白中移动出去。
在一些实施例中,所述靶多核苷酸是单链的;所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述靶多核苷酸的所述第一端处或包括在与所述靶多核苷酸的所述第一端连接的衔接子中;并且所述马达蛋白停靠在所述靶多核苷酸的所述第二端处或停靠在所述靶多核苷酸的所述第二端处的衔接子上。在此类实施例中,前导序列通常被纳米孔捕获,并且单链多核苷酸易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就控制多核苷酸从孔中移动出去。图2示意性地展示了这种设置。
在一些实施例中,靶多核苷酸是双链的。
在一些实施例中,所述靶多核苷酸是双链的,并且包括第一链和第二链;所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述多核苷酸的第一端处并且包括在所述第一链中或包括在与所述第一链连接的衔接子中;并且所述马达蛋白停靠在所述靶多核苷酸的第二端处。这种设置允许双链多核苷酸的第一链的第一端被纳米孔捕获并从第一端到第二端穿过纳米孔。多核苷酸的第二端处的马达蛋白通常防止多核苷酸使纳米孔完全易位。所述双链多核苷酸的所述第一链可以是模板链。所述双链多核苷酸的所述第一链可以是补体链。
在一些实施例中,所述马达蛋白停靠在所述靶多核苷酸的所述第一链的所述第二端处或停靠在所述靶多核苷酸的所述第一链的所述第二端处的衔接子上。在一些实施例中,所述靶多核苷酸是双链的,并且包括第一链和第二链;所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述多核苷酸的第一端处并且包括在所述第一链中或包括在与所述第一链连接的衔接子中;并且所述马达蛋白停靠在所述靶多核苷酸的所述第一链的所述第二端处或停靠在所述靶多核苷酸的所述第一链的所述第二端处的衔接子上。例如,前导序列可以存在于双链多核苷酸的第一链的3'端处,并且所述马达蛋白可以定位于双链多核苷酸的第一链的5'端处。可替代地,前导序列可以存在于双链多核苷酸的第一链的5'端处,并且马达蛋白可以定位于双链多核苷酸的第一链的3'端处。在此类实施例中,前导序列通常被纳米孔捕获,并且单链多核苷酸易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就会控制多核苷酸的第一链从孔中移动出去。图3示意性地展示了这种设置。
在一些实施例中,所述第一链和所述第二链通过所述第一链的所述第二端处的发夹衔接子连接在一起;并且所述马达蛋白停靠在所述发夹衔接子处。在一些实施例中,发夹衔接子在其5'端处与第一链的3'端连接,并且在其3'端处与靶双链多核苷酸的第二链的5'端连接。在一些实施例中,发夹衔接子在其3'端处与第一链的5'端连接,并且在其5'端处与靶双链多核苷酸的第二链的3'端连接。因此,发夹衔接子将第一链与第二链连接。发夹衔接子通常将双链多核苷酸的第一链的第二端与双链多核苷酸的第二链的第一端连接。
在一些实施例中,所述靶多核苷酸是双链的,并且包括第一链和第二链;所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述多核苷酸的第一端处并且包括在所述第一链中或包括在与所述第一链连接的衔接子中;所述第一链和所述第二链通过所述第一链的所述第二端处的发夹衔接子连接在一起;并且所述马达蛋白停靠在所述发夹衔接子处。在此类实施例中,前导序列通常被纳米孔捕获,并且双链多核苷酸的第一链易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就会控制双链多核苷酸的第一链从孔中移动出去。图4示意性地展示了这种设置。
在一些实施例中,所述第一链和所述第二链通过与(i)所述第一链的所述第二端和(ii)所述第二链的第一端连接的发夹衔接子连接在一起,并且所述马达蛋白停靠在所述双链多核苷酸的所述第二链的第二端处或停靠在所述第二链的所述第二端处的衔接子上。在一些实施例中,发夹衔接子在其5'端处与第一链的3'端连接,并且在其3'端处与靶双链多核苷酸的第二链的5'端连接;并且所述马达蛋白停靠在所述第二链的3'端处。在一些实施例中,发夹衔接子在其3'端处与第一链的5'端连接,并且在其5'端处与靶双链多核苷酸的第二链的3'端连接,并且所述马达蛋白质停靠在所述第二链的5'端处。因此,发夹衔接子将第一链与第二链连接。
在一些实施例中,所述靶多核苷酸是双链的,并且包括第一链和第二链;所述靶多核苷酸包括前导序列,其中所述前导序列定位于所述多核苷酸的第一端处并且包括在所述第一链中或包括在与所述第一链连接的衔接子中;所述第一链和所述第二链通过与(i)所述第一链的所述第二端和(ii)所述第二链的第一端连接的发夹衔接子连接在一起;并且所述马达蛋白停靠在所述双链多核苷酸的所述第二链的第二端处或停靠在所述第二链的所述第二端处的衔接子上。在此类实施例中,前导序列通常被纳米孔捕获,并且双链多核苷酸的第一链、发夹衔接子和双链多核苷酸的第二链易位穿过纳米孔,直至到达停靠的马达蛋白。一旦解停靠,马达蛋白就会控制第二链并且任选地还控制发夹衔接子以及进一步任选地控制双链多核苷酸的第一链从孔中移动出去。图5示意性地展示了这种设置。
将显而易见的是,马达蛋白可以不停靠在多核苷酸的末端处,而是可以沿着多核苷酸部分地停靠。如本文所用,在此类实施例中,马达蛋白停靠在要在本文所提供的方法中表征的多核苷酸的部分的末端处。本领域技术人员将理解,在本文提供的方法中,表征的多核苷酸的部分可以通过将马达蛋白定位在多核苷酸上来确定,并且这是可以由方法的使用者控制的参数。
在包括重新读取靶多核苷酸的所公开的方法的实施例中(例如在包括以下的方法中:在所述马达蛋白控制所述靶多核苷酸在第一方向上相对于所述检测器的移动时对所述靶多核苷酸的特性进行一个或多个测量;使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在第二方向上相对于所述检测器移动;并且将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在所述第一方向上相对于所述检测器的所述移动时对所述靶多核苷酸的特性进行一个或多个测量),可以配置或设计前导序列以当马达蛋白位于前导序列附近时,例如当马达蛋白接触前导序列时,促进靶多核苷酸与马达蛋白的多核苷酸结合位点解结合。
在此类实施例中,马达蛋白对前导序列的亲和力通常低于对靶多核苷酸的亲和力,即低于对要表征的靶多核苷酸的部分的亲和力。在一些实施例中,前导具有与靶多核苷酸不同的结构。在一些实施例中,前导包括与靶多核苷酸不同类型的核苷酸。
例如,在一些实施例中,靶多核苷酸包括脱氧核糖核苷酸(DNA)。在此类实施例中,前导可以包括一个或多个缺乏核碱基和糖部分(例如,间隔子部分)两者的核苷酸。合适的间隔子部分在本文中更详细地描述,并且包含C2间隔子、C3间隔子、C6间隔子、iSp9间隔子、iSp18间隔子等。可替代地或另外地,前导可以包括核糖核苷酸(RNA)、肽核苷酸(PNA)、甘油核苷酸(GNA)、苏糖核苷酸(TNA)、锁定核苷酸(LNA)、桥接核苷酸(BNA)或无碱基核苷酸。在一些实施例中,前导可以包括一个或多个具有经修饰的磷酸键(例如,包括甲基膦酸酯或硫代磷酸酯键)的核苷酸。
在一些其它实施例中,靶多核苷酸包括核糖核苷酸(RNA)。在此类实施例中,前导可以包括一个或多个如上定义的间隔子、脱氧核糖核苷酸(DNA)、肽核苷酸(PNA)、甘油核苷酸(GNA)、苏糖核苷酸(TNA)、锁定核苷酸(LNA)、桥接核苷酸(BNA)、无碱基核苷酸或包括经修饰的磷酸键的核苷酸。
通常,靶多核苷酸包括脱氧核糖核苷酸(DNA)并且前导包括一个或多个间隔子部分(例如,C3间隔子)和/或一个或多个核糖核苷酸。
前导可以仅包括一种类型的与靶多核苷酸不同的多核苷酸。例如,当靶多核苷酸是DNA时,前导可以包括间隔子部分或RNA。前导可以包括超过一种类型的与靶多核苷酸不同的多核苷酸。例如,当靶多核苷酸是DNA时,前导可以包括间隔子部分和RNA。前导可以包括与靶多核苷酸属于相同类型的多核苷酸的部分。例如,当靶多核苷酸是DNA时,前导可以包括除了间隔子多核苷酸或RNA之外的DNA的部分。此类部分可以被称为“陷阱”;即基于间隔子(例如,C3间隔子)和/或RNA(例如,2'-甲氧基尿苷)多核苷酸的前导可以包括一个或多个DNA陷阱。陷阱通常包括1至10个核苷酸,如1至6个核苷酸,例如1个、2个、3个、4个或5个核苷酸,如1至3个核苷酸。当靶多核苷酸是DNA时,前导序列因此可以包括一个或多个RNA(例如,2'-甲氧基尿苷)和/或间隔子(例如,C3间隔子)部分和长度为1至10个核苷酸的一个或多个DNA(例如,胸苷)陷阱。
本领域技术人员还将理解,当前导包括多核苷酸链时,前导的序列通常不是决定性的并且可以根据马达蛋白和其它实验条件例如待表征的任何多核苷酸来控制或选择。在实例如实例10中仅以说明的方式提供了示例性序列。例如,前导可以包括如SEQ ID NO:70、71或72中的一个或多个等序列或与SEQ ID NO:70、71或72中的一个或多个具有至少20%,如至少30%,例如至少40%,如至少50%,例如至少60%,如至少70%,例如至少80%,例如至少90%,例如至少95%序列相似性或同一性的多核苷酸序列。前导的序列通常可以改变,而不会对本文所提供的方法的功效产生负面影响。
使马达蛋白停靠
如上文所解释的,本文所提供的方法包括表征使马达蛋白在停靠部分处停靠在其上的靶多核苷酸。
任何合适的停靠部分可以在本文所提供的方法中使用。在一些实施例中,停靠部分包括如本文所描述的停靠位点。在一些实施例中,停靠位点包括一个或多个停靠单元。
可以使用任何合适的停靠单元。停靠单元通常提供阻碍马达蛋白移动的能量屏障。例如,停靠单元可以通过减少马达蛋白在多核苷酸上的牵引使马达蛋白停靠。这可以例如通过使用无碱基“间隔子”,即其中从一个或多个核苷酸去除了碱基的停靠单元来实现。停靠单元可以物理地阻止马达蛋白的移动,例如通过引入庞大的化学基团以物理地阻碍蛋白质的移动。
在一些实施例中,停靠单元可以包括线性分子,如聚合物。通常,此类停靠单元具有与靶多核苷酸不同的结构。例如,如果靶多核苷酸是DNA,则所述停靠单元或每个停靠单元通常不包括DNA。具体地,如果靶多核苷酸是脱氧核糖核酸(DNA)或核糖核酸(RNA),则所述停靠单元或每个停靠单元优选地包括肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)或带有核苷酸侧链的合成聚合物。在一些实施例中,停靠单元可以包括一个或多个硝基吲哚、一个或多个肌苷、一个或多个吖啶、一个或多个2-氨基嘌呤、一个或多个2-6-二氨基嘌呤、一个或多个5-溴-脱氧尿苷、一个或多个反向胸苷(反向dT)、一个或多个反向双脱氧胸苷(ddT)、一个或多个双脱氧胞苷(ddC)、一个或多个5-甲基胞苷、一个或多个5-羟甲基胞苷、一个或多个2'-O-甲基RNA碱基、一个或多个异脱氧胞苷(Iso-dC)、一个或多个异脱氧鸟苷(Iso-dG)、一个或多个C3(OC
在一些实施例中,停靠单元可以包括一个或多个导致马达蛋白停靠的化学基团。在一些实施例中,合适的化学基团是一个或多个化学侧基。一个或多个化学基团可以与多核苷酸中的一个或多个核碱基连接。一个或多个化学基团可以与多核苷酸的主链连接。可以存在任何数目的适当的化学基团,如2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个或更多。合适的基团包含但不限于荧光团、链霉亲和素和/或生物素、胆固醇、亚甲蓝、二硝基苯酚(DNP)、地高辛和/或抗地高辛和二苯基环辛炔基团。
在一些实施例中,停靠单元可以包括聚合物。在一些实施例中,停靠单元可以包括聚合物,所述聚合物是多肽或聚乙二醇(PEG)。
在一些实施例中,停靠单元可以包括一个或多个无碱基核苷酸(即,缺少核碱基的核苷酸),如2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个或更多个无碱基核苷酸。在无碱基核苷酸中,核碱基可以被-H(idSp)或-OH替代。通过从一个或多个相邻核苷酸中去除核碱基,可以将无碱基残基插入到靶多核苷酸中。例如,可以将多核苷酸修饰为包含3-甲基腺嘌呤、7-甲基鸟嘌呤、1,N6-亚乙烯基腺嘌呤肌苷或次黄嘌呤,并且可以使用人烷基腺嘌呤DNA糖苷酶(hAAG)从这些核苷酸中去除核碱基。可替代地,可以将多核苷酸修饰成包含尿嘧啶,并且用尿嘧啶-DNA糖苷酶(UDG)去除核碱基。在一个实施例中,一个或多个停靠单元不包括任何无碱基核苷酸。
可以根据多核苷酸/多核苷酸衔接子的性质、马达蛋白和进行所述方法的条件来设计或选择合适的停靠单元。例如,许多多核苷酸加工蛋白在体内加工DNA,并且此类蛋白通常可以使用任何不是DNA的东西来停靠。
在所提供的方法的一些实施例中,马达蛋白因此停靠在包括一个或多个停靠单元的停靠位点处,所述一个或多个停靠单元独立选自:
-多核苷酸二级结构,优选地发夹或G-四链体(TBA);
-核酸类似物,优选地选自肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)和无碱基核苷酸;
-间隔子单元,其选自硝基吲哚、肌苷、吖啶、2-氨基嘌呤、2-6-二氨基嘌呤、5-溴-脱氧尿苷、反向胸苷(反向dT)、反向双脱氧胸苷(ddT)、双脱氧胞苷(ddC)、5-甲基胞苷、5-羟甲基胞苷、2'-O-甲基RNA碱基、异脱氧胞苷(Iso-dC)、异脱氧鸟苷(Iso-dG)、C3(OC
-荧光团、如traptavidin、链霉亲和素和中性亲和素等亲和素和/或生物素、胆固醇、亚甲蓝、二硝基酚(DNP)、地高辛和/或抗地高辛以及二苄基环辛炔基团。
如本文所描述的停靠部分也可以用于配置前导以适用于所公开的重新读取方法。如上文所解释的,在此类方法的一些实施例中,配置或设计如本文所描述的前导序列以当马达蛋白位于前导序列附近时,例如当马达蛋白接触前导序列时,促进靶多核苷酸与马达蛋白的多核苷酸结合位点的解结合。在一些实施例中,前导序列可以包括上文所描述的任何间隔子部分。
使马达蛋白解停靠
在一些实施例中,本文所提供的方法包括使停靠部分与检测器(例如,纳米孔)接触,由此使马达蛋白解停靠。一旦解停靠,马达蛋白可以控制多核苷酸从检测器中移动出去(例如,从纳米孔中移动出去),如本文更详细描述的。
在其最简单的形式中,使停靠部分与检测器例如纳米孔接触可以使马达蛋白从停靠部分中解停靠。然而,在一些实施例中,所述方法包括如本文所描述主动使马达蛋白解停靠。
在一些实施例中,使所述马达蛋白解停靠包括向所述多核苷酸施加解停靠力,其中所述解停靠力的幅度低于读取力和/或与读取力具有相反方向,其中所述读取力是在所述马达蛋白控制所述靶多核苷酸的移动并且进行测量以确定所述多核苷酸的一个或多个特性的同时施加的力。
例如,读取力通常可以提供为从+2V至-2V的电压电位,通常是-400mV至+400mV。所使用的电压优选地处于具有下限和上限的范围内,所述下限选自-400mV、-300mV、-200mV、-150mV、-100mV、-50mV、-20mV和0mV,并且所述上限独立地选自+10mV、+20mV、+50mV、+100mV、+150mV、+200mV、+300mV和+400mV。所使用的电压更优选地处于100mV到240mV的范围内,并且最优选地处于120mV到220mV的范围内。解停靠力的幅度通常低于读取力。例如,解停靠力可以为约-100mV至+100mV,如约-50mV至约+50mV,例如约-25mV至约+25mV。
例如,在一些实施例中,读取力是+50mV至+300mV,更优选地在+100mV至+200mV的范围内,如+120mV至+150mV的电压电位,并且解停靠力是-50至+50mV如-40mV至+40mV,例如-20mV至+20mV如0mV的电压电位。
在一些实施例中,解停靠力在方向上与读取力相反。例如,在一些实施例中,读取力作为正电压电位施加并且解停靠力作为负电压电位施加。在其它实施例中,读取力作为负电压电位施加并且解停靠力作为正电位施加。当解停靠力与读取力属于相反方向时,其可以与所述读取力具有相等的幅度或可以具有比读取力更低的幅度。
在一些实施例中,解停靠力在零电位下施加。例如,在一些实施例中,读取力作为正电压电位施加并且解停靠力在零施加电位下施加。在其它实施例中,读取力作为负电压电位施加并且解停靠力在零施加电位下施加。
在一些实施例中,施加解停靠力持续足以使马达蛋白从停靠部分解停靠的时间。在一些实施例中,施加解停靠力持续1毫秒至约10秒,如约10毫秒至约1秒,例如约100毫秒至约700毫秒,如约300毫秒至约500毫秒。
在一些实施例中,使马达蛋白解停靠包括在解停靠力与读取力之间改变所施加的力一次或多次。在一些实施例中,以此方式改变所施加的力包括使所施加的电位在解停靠力与读取力之间逐步施加或斜变。当斜变时,可以使用任何合适的波形,例如斜变可以是线性斜变、指数斜变或S形斜变。
在一些实施例中,所施加的力在单个解停靠力与读取力之间逐步施加。在一些实施例中,所施加的力在一系列不同的解停靠力与读取力之间逐步施加。在一些实施例中,所施加的力在一系列增加的解停靠力与读取力之间逐步施加。每个步骤的解停靠力可以是任何合适的解停靠力,例如本文所描述的任何解停靠力;并且在每个步骤处可以施加持续任何合适的持续时间,例如本文所描述的任何持续时间。
在一些实施例中,解停靠力与读取力相同。这也被称为“自由运行”设置中的解停靠。
在一些实施例中,所述马达蛋白停靠在包括一个或多个停靠单元和一个或多个暂停部分的停靠位点处;并且其中使所述一个或多个暂停部分与所述纳米孔接触延迟了所述多核苷酸穿过所述纳米孔的所述移动,由此使所述马达蛋白从所述一个或多个停靠单元中解停靠。此类实施例适用于自由运行设置。
在一些实施例中,暂停部分提供阻碍多核苷酸移动穿过纳米孔的能量屏障。例如,暂停部分可以通过提供在多核苷酸可以穿过纳米孔之前需要去除的物理块来阻碍多核苷酸移动穿过纳米孔。
不受理论束缚,本发明人相信暂停部分使多核苷酸穿过纳米孔的移动延迟了足以使马达蛋白克服停靠单元并解停靠的时间。
在一些实施例中,暂停部分包括一个或多个暂停单元,所述一个或多个暂停单元包括多核苷酸二级结构,优选地发夹或G-四链体(TBA)。此类二级结构防止多核苷酸自由穿过纳米孔。使暂停部分与纳米孔接触导致二级结构解离(例如,解旋)。二级结构解离所花费的时间使马达蛋白从停靠单元中解停靠。
在一些实施例中,暂停部分包括一个或多个包括杂交寡核苷酸的暂停单元。寡核苷酸可以与靶多核苷酸杂交并防止靶多核苷酸移动穿过纳米孔。使暂停部分与纳米孔接触导致杂交的寡核苷酸与靶多核苷酸解离。杂交的寡核苷酸与靶多核苷酸解离所花费的时间允许马达蛋白从停靠单元中解停靠。
在一些实施例中,暂停部分包括一个或多个暂停单元,所述一个或多个暂停单元包括核酸类似物,优选地选自肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)和无碱基核苷酸。核酸类似物可以与靶多核苷酸一致地提供,或者可以与靶多核苷酸杂交或以其它方式连接。当核酸类似物与靶多核苷酸一致地提供时,使暂停部分与纳米孔接触导致核酸类似物穿过纳米孔。核酸类似物穿过孔所花费的时间允许马达蛋白从停靠单元中解停靠。当核酸类似物与靶多核苷酸杂交时,使暂停部分与纳米孔接触通常导致核酸类似物与靶多核苷酸解离,使得靶多核苷酸可以穿过纳米孔。核酸类似物与多核苷酸解离所花费的时间允许马达蛋白从停靠单元中解停靠。
在一些实施例中,暂停部分包括一个或多个暂停单元,所述一个或多个暂停单元包括化学基团,如荧光团、如traptavidin、链霉亲和素和中性亲和素等亲和素和/或生物素、胆固醇、亚甲蓝、二硝基酚(DNP)、地高辛和/或抗地高辛以及二苄基环辛炔基团。化学基团可以与靶多核苷酸连接并防止靶多核苷酸移动穿过纳米孔。在一些实施例中,使暂停部分与纳米孔接触导致化学基团从靶多核苷酸中去除。在一些实施例中,使暂停部分与纳米孔接触导致化学基团穿过纳米孔。化学基团从靶多核苷酸中去除和/或穿过纳米孔所花费的时间允许马达蛋白从停靠单元中解停靠。
在一些实施例中,暂停部分包括一个或多个包括多核苷酸结合蛋白的暂停单元。本文更详细地描述了合适的多核苷酸结合蛋白。多核苷酸结合蛋白可以与多核苷酸结合并防止多核苷酸移动穿过纳米孔。使暂停部分与纳米孔接触延迟了多核苷酸穿过纳米孔的移动,例如当多核苷酸结合蛋白移动以接触马达蛋白时。这样做所花费的时间允许马达蛋白从停靠单元中解停靠。
不受理论束缚,本发明人还认为暂停部分通常确定多核苷酸在停靠单元处的构象。当停靠部分包括线性基团如一个或多个间隔子18(iSp18)[(OCH
因此,在一些实施例中,马达蛋白停靠在包括一个或多个停靠单元和一个或多个暂停单元的停靠位点处,所述一个或多个停靠单元和所述一个或多个暂停单元独立地选自:
-多核苷酸二级结构,优选地发夹或G-四链体(TBA);
-核酸类似物,优选地选自肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)和无碱基核苷酸;
-荧光团、如traptavidin、链霉亲和素和中性亲和素等亲和素和/或生物素、胆固醇、亚甲蓝、二硝基酚(DNP)、地高辛和/或抗地高辛以及二苄基环辛炔基团;以及
-多核苷酸结合蛋白;
并且使一个或多个暂停部分与纳米孔接触延迟了多核苷酸穿过纳米孔的移动,由此使马达蛋白从一个或多个停靠单元中解停靠。
马达蛋白
如本领域技术人员将理解的,任何合适的马达蛋白均可用于本文提供的方法和产品中。
马达蛋白可以是能够与多核苷酸结合并控制其相对于检测器例如纳米孔移动例如穿过孔的任何蛋白质。
更详细地,马达蛋白如解旋酶通常可以在至少两种主动操作模式(当提供有用于促进移动的所有必要的组分,例如ATP和Mg
当提供有用于促进移动的所有必要的组分时,马达蛋白可以沿着多核苷酸如DNA以5'-3'方向或3'-5'方向移动。许多马达蛋白以5'-3'方向加工多核苷酸,如DNA。以此方式控制多核苷酸的移动的马达蛋白通常适用于本文所提供的方法。
然而,当马达蛋白未提供有用于促进移动的必需的组分,或被修饰以防止其主动控制多核苷酸相对于纳米孔的移动时,它仍然可以被动地控制多核苷酸相对于纳米孔的移动。例如,马达蛋白可以与多核苷酸结合并在多核苷酸通过施加的场(例如通过本文提供的方法中的第一力)被牵拉到孔中时充当使多核苷酸的移动减慢的制动器。在“非主动”模式下,DNA是3'还是5'向下被捕获(即,在5'-3'方向上或在3'-5'方向上移动穿过纳米孔)通常无关紧要,因为所施加的力提供了用于使多核苷酸移动穿过纳米孔的动力。然而,在此类实施例中,马达蛋白仍然可以控制多核苷酸相对于纳米孔的移动,例如通过充当制动器。当在非主动模式中时,通过马达蛋白对多核苷酸的移动控制可以多种方式(包含棘轮、滑动和制动)描述。通常,本文所提供的方法不包括使用以被动模式操作的马达蛋白。然而,在本文所提供的使用多核苷酸结合蛋白的方法的实施例中,多核苷酸结合蛋白可以是在被动模式下操作的马达蛋白。
如上文所解释的,本文所提供的方法的一些实施例还包括使用多核苷酸结合蛋白作为暂停部分以阻碍多核苷酸链移动穿过纳米孔。在一些实施例中,多核苷酸结合蛋白可以是本文所描述的马达蛋白。在其它实施例中,多核苷酸结合蛋白可以是与多核苷酸结合但不具有多核苷酸加工能力的蛋白质;即在一些实施例中,它不是马达蛋白。
多核苷酸处理酶是能够与多核苷酸相互作用的多肽。酶可以通过切割多核苷酸以形成单独的核苷酸或较短核苷酸链如二核苷酸或三核苷酸来对多核苷酸进行修饰。所述酶可以通过将多核苷酸朝向或使其移动到特定位置来对多核苷酸进行修饰。如本文所用的马达蛋白可以是或可以源自多核苷酸处理酶。多核苷酸结合蛋白可以是或可以源自多核苷酸处理酶。
在一个实施例中,马达蛋白和/或多核苷酸结合蛋白源自任何酶分类(EC)组的成员:3.1.11、3.1.13、3.1.14、3.1.15、3.1.16、3.1.21、3.1.22、3.1.25、3.1.26、3.1.27、3.1.30和3.1.31。
通常,马达蛋白和/或多核苷酸结合蛋白是解旋酶、聚合酶、核酸外切酶、拓扑异构酶或其变体。
在一些实施例中,马达蛋白和/或多核苷酸结合蛋白可以被修饰为防止所述马达蛋白与多核苷酸脱离。这在本文所公开的包括重新读取靶多核苷酸的方法中特别有用。因此,在此类方法的一些实施例中,靶多核苷酸不与马达蛋白脱离。
如本文所用,术语“脱离”是指马达蛋白与靶多核苷酸的解离。因此,马达蛋白可以被修饰为防止其与靶多核苷酸解离,例如解离到反应介质中。区分马达蛋白的潜在“脱离”与马达蛋白与靶多核苷酸的“解结合”是重要的。如本文所用,“解结合”是指靶多核苷酸瞬时释放到马达蛋白的活性位点(本文更详细地描述),但并不意味着脱离。因此,例如,马达蛋白可以被修饰为防止马达蛋白与多核苷酸上脱离,但不防止马达蛋白与多核苷酸上解结合。当解结合时,马达蛋白仍然与靶多核苷酸接合。例如,马达蛋白可以仍然与靶多核苷酸接合(即,它可以被防止与靶多核苷酸脱离)。因为它在靶多核苷酸周围是拓扑闭合的。多核苷酸结合位点可以仍然自由以结合或解结合靶多核苷酸,使得马达蛋白可以与靶多核苷酸结合或解结合,同时马达蛋白仍然与靶多核苷酸接合。当马达蛋白与靶多核苷酸解结合时,它可能能够在施加的力下在靶多核苷酸上(例如,沿着靶多核苷酸)移动并且可能能够与靶多核苷酸重新结合。当在靶多核苷酸上接合但与靶多核苷酸解结合时,马达蛋白不能与靶多核苷酸解离。
马达蛋白和/或多核苷酸结合蛋白可以适于以任何合适的方式防止脱离。例如,可以将马达蛋白和/或多核苷酸结合蛋白加载在多核苷酸上,并且然后对其进行修饰以防止其与多核苷酸脱离。可替代地,马达蛋白和/或多核苷酸结合蛋白可以被修饰为防止其在加载到多核苷酸上之前与多核苷酸脱离。可以使用本领域已知的方法,如在WO 2014/013260(特此通过引用整体并入)中所讨论的方法并特别参考描述修饰马达蛋白如解旋酶以防止其与多核苷酸链脱离来实现对马达蛋白和/或多核苷酸结合蛋白的修饰以防止其与多核苷酸脱离。例如,可以通过用四甲基偶氮二甲酰胺(TMAD)处理来修饰马达蛋白和/或多核苷酸结合蛋白。各种其它闭合部分在本文中更详细地描述。
例如,马达蛋白和/或多核苷酸结合蛋白可以具有多核苷酸解结合开口;例如,当马达蛋白和/或多核苷酸结合蛋白与链脱离时,多核苷酸链可以通过的空腔、裂缝或空隙。在一些实施例中,多核苷酸解结合开口是当马达蛋白/多核苷酸结合蛋白与多核苷酸脱离时多核苷酸可以通过的开口。在一些实施例中,给定马达蛋白/多核苷酸结合蛋白的多核苷酸解结合开口可以通过参考其结构,例如参考其X射线晶体结构来确定。X射线晶体结构可以在多核苷酸底物存在和/或不存在下获得。在一些实施例中,可以使用本领域已知的标准包通过分子建模来推断或证实给定马达蛋白/多核苷酸结合蛋白中多核苷酸解结合开口的位置。在一些实施例中,多核苷酸解旋开口可以通过马达蛋白的一个或多个部分例如一个或多个结构域的移动而瞬时产生。
可以通过关闭多核苷酸解结合开口来修饰马达蛋白/多核苷酸结合蛋白。多核苷酸解结合开口可以用闭合部分闭合。因此,闭合多核苷酸解结合开口可以防止马达蛋白/多核苷酸结合蛋白与多核苷酸脱离。例如,可以通过共价关闭多核苷酸解结合开口来修饰马达蛋白和/或多核苷酸结合蛋白。然而,如上文所解释的,闭合多核苷酸解结合开口并不一定能防止靶多核苷酸与马达蛋白的多核苷酸结合位点解结合。在一些实施例中,用于以此方式寻址的优选蛋白是解旋酶。
在一些实施例中,尤其是在包括重新读取靶多核苷酸的所公开的方法的实施例中,马达蛋白可以被修饰为防止靶多核苷酸与靶多核苷酸脱离。可以以任何合适的方式修饰马达蛋白。
不受理论的束缚,发明人认为促进解结合和延迟重新结合可以促进重新读取。不受理论的束缚,发明人认为这可能是因为马达蛋白对靶多核苷酸采取的每个步骤都与马达蛋白与多核苷酸解结合的概率相关。这种解结合的可能性可以用所谓的解离速率来鉴定。据信增加解离率促进了马达蛋白相对于多核苷酸链的回落。类似地,并且再次不受理论束缚,发明人认为一旦与靶多核苷酸解结合,马达蛋白在重新结合之前可以沿着靶多核苷酸移动的距离与缔合速率相关。因此,可以通过增加马达蛋白相对于靶多核苷酸的解离速率和降低缔合速率来促进重新读取。鉴于本文的公开内容,为给定类型的多核苷酸定制马达蛋白的解离速率和缔合速率在本领域技术人员的能力范围内。因此,所述马达蛋白可以被修饰为促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合和/或延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合。在一些实施例中,所述马达蛋白被修饰为既促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合又延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合。
在一些实施例中,所述马达蛋白可以用闭合部分修饰以用于(i)拓扑闭合所述马达蛋白的在所述靶多核苷酸周围的所述多核苷酸结合位点并且(ii)促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合和/或延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合。可以以任何合适的方式修饰马达蛋白以促进此类闭合部分的连接。
在一些实施例中,闭合部分可以包括双官能交联部分。闭合部分可以包括双官能交联剂。双官能交联剂可以在马达蛋白上的两个点处连接并闭合马达蛋白的多核苷酸解结合开口,由此防止多核苷酸与马达蛋白脱离,同时允许多核苷酸与马达蛋白的多核苷酸结合位点解结合。
闭合部分可以连接在马达蛋白上的任何合适位置处。例如,闭合部分可以交联马达蛋白的两个氨基酸残基。通常,至少一个由闭合部分交联的氨基酸是半胱氨酸或非天然氨基酸。半胱氨酸或非天然氨基酸可以通过取代或修饰马达蛋白的天然存在的氨基酸残基而被引入到马达蛋白中。用于引入非天然氨基酸的方法在本领域中是熟知的并且包含例如与包括此类非天然氨基酸的合成多肽链的天然化学连接。用于将半胱氨酸引入到马达蛋白中的方法同样在本领域技术人员的能力范围内,例如使用如以下等参考文献中公开的技术:Sambrook等人,《分子克隆:实验手册》,第4版,纽约普莱恩斯维尤的冷泉港出版社(2012);和Ausubel等人,《分子生物学最新方案》(增刊114),纽约约翰威利父子出版社(2016)。
在一些实施例中,闭合部分的长度为约
不受理论束缚,本发明人认为通常较长的闭合部分可以增加马达蛋白与多核苷酸的解离速率并且因此促进重新读取。
在一些实施例中,闭合部分包括键。在一些实施例中,闭合部分包括二硫键。可以通过用任何合适的试剂如TMAD处理马达蛋白来形成二硫键。
在一些实施例中,闭合部分包括在马达蛋白上的两个点击化学基团之间形成键的试剂。本文提供了点击化学试剂的实例。
在一些实施例中,闭合部分包括蛋白质。例如,生物素基团可以存在于马达蛋白上并且闭合部分可以包括链霉亲和素。标签如snoop-tag或spy-tag可以存在于马达蛋白上并且闭合部分可以分别包括蛋白质如snoop-catcher或spy-catcher。
在一些实施例中,所述闭合部分包括式[A-B-C]的结构,其中A和C各自独立地是用于与所述马达蛋白中的氨基酸残基反应的反应性官能团,并且B是连接部分。在一些实施例中,闭合部分包括硫基之间的连接,例如半胱氨酸残基上的硫醇基。因此在一些实施例中,A和C是半胱氨酸反应性官能团。
在一些实施例中,连接部分B包括直链或支链、未经取代的或经取代的亚烷基、亚烯基、亚炔基、亚芳基、亚杂芳基、亚碳环基或亚杂环基部分,所述部分任选地被一个或多个选自以下的原子或基团中断和/或终止于所述一个或多个原子或基团:O、N(R)、S、C(O)、C(O)NR、C(O)O、未经取代的或经取代的亚芳基、亚芳基-亚烷基、亚杂芳基、亚杂芳基-亚烷基、亚碳环基、亚碳环基-亚烷基、亚杂环基和亚杂环基-亚烷基;其中R选自H、未经取代的或经取代的烷基以及未经取代的或经取代的芳基。通常R为H或甲基,更通常地为H。
通常,亚烷基是C
通常,亚烷基、亚烯基或亚炔基部分可以是未中断的或被一个或多个选自O、N(R)、S、C(O)、C(O)NR和C(O)O以及未经取代的或经取代的亚芳基的原子或基团中断或终止于所述一个或多个原子或基团。通常,亚烷基、亚烯基或亚炔基部分可以是未中断的或被一个或多个选自O和N(R)以及未经取代的或经取代的亚芳基的原子或基团中断或终止于所述一个或多个原子或基团。更经常地,亚烷基、亚烯基或亚炔基部分可以是未中断的或被一个或多个O原子中断或终止于所述原子。
例如,连接部分经常是未中断的或被一个或多个O原子中断的或终止于所述原子的未经取代的或经取代的C
在一些实施例中,连接部分B包括亚烷基、氧化烯或聚氧化烯基团和/或其中A和C各自为马来酰亚胺基团。亚烷基、氧化烯或聚氧化烯基团的长度可以例如为约
例如,连接部分可以包括PEG部分,如(CH
适于使用如上文所描述的闭合部分闭合的马达蛋白在本文中更详细地讨论。在一些优选的实施例中,马达蛋白是解旋酶,例如如本文所描述的Dda解旋酶。
在一个实施例中,马达蛋白和/或多核苷酸结合蛋白是或源自核酸外切酶。合适的酶包含但不限于来自大肠杆菌的核酸外切酶I(SEQ ID NO:1)、来自大肠杆菌的核酸外切酶III(SEQ ID NO:2)、来自嗜热栖热菌的RecJ酶(SEQ ID NO:3)和噬菌体λ核酸外切酶(SEQID NO:4)、TatD核酸外切酶以及其变体。包括SEQ ID NO:3中所示序列的三个亚基或其变体相互作用以形成三聚体核酸外切酶。
在一个实施例中,马达蛋白和/或多核苷酸结合蛋白是聚合酶。聚合酶可以是
在一个实施例中,马达蛋白和/或多核苷酸结合蛋白是拓扑异构酶。在一个实施例中,拓扑异构酶是部分分类(EC)组5.99.1.2和5.99.1.3中的任一个的成员。拓扑异构酶可以是逆转录酶,其是能够催化从RNA模板形成cDNA的酶。它们可从例如New England
在一个实施例中,马达蛋白和/或多核苷酸结合蛋白是解旋酶。可以根据本文提供的方法使用任何合适的解旋酶。例如,根据本公开使用的所述马达蛋白或每个酶可以独立地选自Hel308解旋酶、RecD解旋酶、TraI解旋酶、TrwC解旋酶、XPD解旋酶和Dda解旋酶或其变体。单聚解旋酶可以包括连接在一起的若干结构域。例如,TraI解旋酶和TraI亚组解旋酶可以含有两个RecD解旋酶结构域、释放酶结构域和C末端结构域。这些结构域通常形成能够起作用而不会形成寡聚体的单聚解旋酶。合适的解旋酶的具体实例包含Hel308、NS3、Dda、UvrD、Rep、PcrA、Pif1和TraI。这些解旋酶通常作用于单链DNA。可以沿着双链DNA的两条链移动的解旋酶的实例包含FtfK和六聚酶复合物,或多亚基复合物,如RecBCD。在一个实施例中,马达蛋白是Dda(DNA依赖性ATP酶)解旋酶。
Hel308解旋酶在出版物如WO 2013/057495中有所描述,其全部内容通过引用并入。RecD解旋酶在如WO 2013/098562的出版物中有描述,其全部内容通过引用并入。XPD解旋酶在如WO 2013/098561的出版物中有所描述,其全部内容通过引用并入。Dda解旋酶在如WO 2015/055981和WO 2016/055777的出版物中有所描述,其各自的全部内容通过引用并入。
在一个实施例中,解旋酶可以包括SEQ ID NO:6(Trwc Cba)或其变体中所示的序列、SEQ ID NO:7(Hel308 Mbu)或其变体中所示的序列或者SEQ ID NO:8(Dda)或其变体中所示的序列。变体可以以本文所讨论的方式中的任何方式中天然序列不同。SEQ ID NO:8的示例变体包括E94C/A360C。SEQ ID NO:8的另一个示例变体包括E94C/A360C,并且然后是(ΔM1)G1G2(即M1的缺失,并且然后是G1和G2的添加)。
通常,马达蛋白或多核苷酸结合蛋白可以具有燃料结合位点。DNA的主动解旋可以与燃料水解偶联,例如在马达蛋白中。
燃料通常是游离核苷酸或游离核苷酸类似物。游离核苷酸可以是但不限于腺苷一磷酸(AMP)、腺苷二磷酸(ADP)、腺苷三磷酸(ATP)、鸟苷一磷酸(GMP)、鸟苷二磷酸(GDP)、鸟苷三磷酸(GTP)、胸苷一磷酸(TMP)、胸苷二磷酸(TDP)、胸苷三磷酸(TTP)、尿苷一磷酸(UMP)、尿苷二磷酸(UDP)、尿苷三磷酸(UTP)、胞苷一磷酸(CMP)、胞苷二磷酸(CDP)、胞苷三磷酸(CTP)、环腺苷一磷酸(cAMP)、环鸟苷一磷酸(cGMP)、脱氧腺苷一磷酸(dAMP)、脱氧腺苷二磷酸(dADP)、脱氧腺苷三磷酸(dATP)、脱氧鸟苷一磷酸(dGMP)、脱氧鸟苷二磷酸(dGDP)、脱氧鸟苷三磷酸(dGTP)、脱氧胸苷一磷酸(dTMP)、脱氧胸苷二磷酸(dTDP)、脱氧胸苷三磷酸(dTTP)、脱氧尿苷一磷酸(dUMP)、脱氧尿苷二磷酸(dUDP)、脱氧尿苷三磷酸(dUTP)、脱氧胞苷一磷酸(dCMP)、脱氧胞苷二磷酸(dCDP)和脱氧胞苷三磷酸(dCTP)。游离核苷酸通常选自AMP、TMP、GMP、CMP、UMP、dAMP、dTMP、dGMP或dCMP。游离核苷酸通常是三磷酸腺苷(ATP)。
马达蛋白的辅因子是允许马达蛋白发挥功能的因子。辅因子优选地是二价金属阳离子。二价金属阳离子优选地为Mg
在一些实施例中,多核苷酸结合蛋白是如本文所用的马达蛋白。如本文所用,术语多核苷酸结合蛋白和多核苷酸结合部分可以互换使用。
例如,多核苷酸结合蛋白或多核苷酸结合部分可以包括一个或多个独立地选自以下的结构域:螺旋-发夹-螺旋(HhH)结构域、真核生物单链结合蛋白(SSB)、细菌SSB、古细菌SSB、病毒SSB、双链结合蛋白、滑动夹、进行性因子、DNA结合环、复制起始蛋白、端粒结合蛋白、阻遏物、锌指和增殖细胞核抗原(PCNA)。
螺旋-发夹-螺旋(HhH)结构域是以序列非特异性方式结合DNA的多肽基序。合适的结构域包含来自坎德勒氏甲烷嗜热菌(Methanopyrus kandleri)(SEQ ID NO:54)的拓扑异构酶V的结构域H(残基696至751)和结构域HI(残基696至802)。多核苷酸结合部分可以是如SEQ ID NO:55或其多核苷酸结合变体所示的SEQ ID NO:54的结构域H-L。HhH结构域可以包括SEQ ID NO:40或48或49或其多核苷酸结合变体中所示的序列。
SSB以序列非特异性方式以高亲和力结合单链DNA。SSB属于以下谱系:类;所有β蛋白,折叠;OB-折叠,超家族:核酸结合蛋白,家族;单链DNA结合域,SSB。SSB可以来自真核生物,如来自人、小鼠、大鼠、真菌、原生动物或植物;来自原核生物,如细菌和古生菌;或来自病毒。真核SSB也被称为复制蛋白A(RPA)。在大多数情况下,它们是由不同大小的单元形成的异源三聚体。一些较大的单元(例如,酿酒酵母(Saccharomyces cerevisiae)的RPA70)是稳定的并以单体形式结合ssDNA。细菌SSB以稳定的同源四聚体(例如,大肠杆菌、耻垢分枝杆菌(Mycobacterium smegmatis)和幽门螺杆菌(Helicobacter pylori))或同源二聚体(例如,耐辐射球菌(Deinococcus radiodurans)和玛氏热袍菌(Thermotoga maritima))的形式结合DNA。少数,例如由泉古菌硫磺矿硫化叶菌(crenarchaeote Sulfolobussolfataricus)编码的SSB是同源四聚体。来自其它物种的一些SSB已被示出是单体的(詹氏甲烷球菌(Methanococcus jannaschii)和热自养甲烷嗜热杆菌(Methanothermobacterthermoautotrophicum))。仍其它物种的古生菌,包含闪烁古生球菌(Archaeoglobusfulgidus)和布氏拟甲烷球菌(Methanococcoides burtonii),含有两个与RPA具有序列相似性的开放阅读框。病毒SSB作为单体结合DNA。
SSB通常被选择或修饰为具有羧基端(C端)区,所述区没有净负电荷或相对于野生型蛋白质具有减少的净负电荷。此类SSB通常不会阻断跨膜孔。SSB的C端区通常为C端处的SSB的约最后三分之一、四分之一、五分之一或八分之一。C端区通常是SSB的C端的约最后10个至约最后60个氨基酸,例如SSB的C端的约最后20个至最后40个如最后30个氨基酸。
包括不具有净负电荷的C端区的SSB的实例包含人线粒体SSB(HsmtSSB;SEQ IDNO:50)、人复制蛋白A 70kDa亚基、人复制蛋白A 14kDa亚基、来自尖毛虫属毛虫(Oxytrichanova)的端粒末端结合蛋白α亚基,来自尖毛虫属毛虫的端粒末端结合蛋白β亚基的核心结构域、来自粟酒裂殖酵母(Schizosaccharomyces pombe)的端粒蛋白1(Pot1)的保护、人Pot1、来自小鼠或大鼠的BRCA2的OB折叠结构域、来自phi29(SEQ ID NO:51)的p5蛋白;以及其多核苷酸结合变体。可以在其C端区进行修饰以减少净负电荷的SSB的实例包含大肠杆菌的SSB(EcoSSB;SEQ ID NO:52)、结核分枝杆菌(Mycobacterium tuberculosis)的SSB、耐辐射球菌的SSB、嗜热栖热菌的SSB、硫磺矿硫化叶菌的SSB、人复制蛋白A 32kDa亚基(RPA32)片段、酿酒酵母的CDC13 SSB、来自大肠杆菌的原始体复制蛋白N(PriB)、拟南芥的PriB、假定蛋白At4g28440、T4(gp32;SEQ ID NO:53)的SSBRB69(gp32;SEQ ID NO:41)的SSB、T7(gp2.5;SEQ ID NO:42)的SSB以及其多核苷酸结合变体。WO 2014/013259中公开了用于降低净负电荷的合适修改。
双链结合蛋白以高亲和力结合双链DNA。合适的双链结合蛋白包含但不限于突变体S(MutS;NCBI参考序列:NP_417213.1;SEQ ID NO:56)、Sso7d(硫磺矿硫化叶菌P2;NCBI参考序列:NP_343889.1;SEQ ID NO:57;《核酸研究(Nucleic Acids Research)》,2004,第32卷,第3期,1197-1207)、Sso10b1(NCBI参考序列:NP_342446.1;SEQ ID NO:58)、Sso10b2(NCBI参考序列:NP_342448.1;SEQ ID NO:59)、色氨酸阻遏物(Trp阻遏物;NCBI参考序列:NP_291006.1;SEQ ID NO:60)、λ阻遏物(NCBI参考序列:NP_040628.1;SEQ ID NO:61)、Cren7(NCBI参考序列:NP_342459.1;SEQ ID NO:62)、主要组蛋白类别H1/H5、H2A、H2B、H3和H4(NCBI参考序列:NP_066403.2,SEQ ID NO:63)、dsbA(NCBI参考序列:NP_049858.1;SEQID NO:64)、Rad51(NCBI参考序列:NP_002866.2;SEQ ID NO:65)、滑动夹和拓扑异构酶VMka(SEQ ID NO:54)或这些蛋白质的多核苷酸结合变体。
其它多核苷酸结合蛋白包含滑动夹。滑动夹通常是环绕dsDNA的多聚体蛋白(同源二聚体或同源三聚体)。滑动夹通常需要辅助蛋白(夹加载器)在ATP依赖性过程中将它们组装在DNA螺旋周围。它们也不直接接触DNA,充当拓扑系链。与DNA滑动夹相关的是作为病毒蛋白的进行性因子,所述病毒蛋白将其同源聚合酶锚定到DNA,导致产生的片段长度显著增加。它们可以是单体的(如单纯性疱疹病毒1的UL42的情况)或多聚体(来自巨细胞病毒的UL44是二聚体)。UL42通常包括SEQ ID NO:43或SEQ ID NO:47或其多核苷酸结合变体中所示的序列。
另一种多核苷酸结合蛋白是噬菌体T7 DNA聚合酶的硫氧还蛋白结合结构域(TBD)(残基258至333)。TBD与硫氧还蛋白(例如来自大肠杆菌)的结合导致多肽将构象改变为结合DNA的构象。其它多核苷酸结合蛋白包含来自噬菌体Φx174的辅助蛋白cisA和来自噬菌体M13的基因II蛋白。这些蛋白质具有固有的DNA结合能力,其中一些可以识别特异性DNA序列。其它多核苷酸结合蛋白包含端粒结合蛋白。
小的DNA结合基序(如螺旋-转角-螺旋)识别特异性DNA序列。在噬菌体434阻遏物的情况下,62个残基片段被工程化,并被示出为保留了DNA结合能力和特异性。锌指由大约30个以特定方式结合DNA的氨基酸组成。通常每个锌指仅识别三个DNA碱基,但可以连接多个锌指以获得对更长序列的识别。
增殖细胞核抗原(PCNA)形成了在dsDNA或ssDNA上向上向下滑动的非常紧的夹。来自泉古菌的PCNA是SEQ ID NO:44、45和46的异源三聚体。因此,多核苷酸结合蛋白可以是包括SEQ ID NO:44、45和46或其多核苷酸结合变体中所示的序列的三聚体。另一个PCNA滑动夹(NCBI参考序列:ZP_06863050.1;SEQ ID NO:66)形成二聚体。因此,多核苷酸结合蛋白可以是包括SEQ ID NO:66或其多核苷酸结合变体的二聚体。
多核苷酸结合基序可以选自以下中的任何一种:
/>
/>
多核苷酸
本发明的方法涉及在靶多核苷酸相对于检测器如纳米孔移动时表征所述多核苷酸。
多核苷酸(如核酸)为包括两个或更多个核苷酸的大分子。多核苷酸可以是单链的或双链的。双链多核苷酸由两个单链多核苷酸杂交在一起制成。靶多核苷酸可以是单链多核苷酸或双链多核苷酸。
多核苷酸可以包括任何核苷酸的任何组合。核苷酸可以是天然存在的或人工的。
核苷酸通常含有核碱基、糖和至少一个磷酸基。核碱基和糖形成核苷。
核碱基通常是杂环的。核碱基包含但不限于嘌呤和嘧啶,并且更具体地包含腺嘌呤(A)、鸟嘌呤(G)、胸腺嘧啶(T)、尿嘧啶(U)和胞嘧啶(C)。
糖通常是戊糖。核苷酸糖包含但不限于核糖和脱氧核糖。糖优选地是脱氧核糖。多核苷酸优选地包括以下核苷:脱氧腺苷(dA)、脱氧尿苷(dU)和/或胸苷(dT)、脱氧鸟苷(dG)和脱氧胞苷(dC)。
核苷酸通常是核糖核苷酸或脱氧核糖核苷酸。核苷酸通常含有单磷酸、二磷酸或三磷酸。核苷酸可以包括多于三个磷酸,如4个或5个磷酸。磷酸可以连接在核苷酸的5'或3'侧上。核苷酸包含但不限于单磷酸腺苷(AMP)、单磷酸鸟苷(GMP)、单磷酸胸苷(TMP)、单磷酸尿苷(UMP)、单磷酸5-甲基胞苷、单磷酸5-羟基甲基胞苷、单磷酸胞苷(CMP)、单磷酸环腺苷(cAMP)、单磷酸环鸟苷(cGMP)、单磷酸脱氧腺苷(dAMP)、单磷酸脱氧鸟苷(dGMP)、单磷酸脱氧胸苷(dTMP)、单磷酸脱氧尿苷(dUMP)、单磷酸脱氧胞苷(dCMP)和单磷酸脱氧甲基胞苷。核苷酸优选地选自AMP、TMP、GMP、CMP、UMP、dAMP、dTMP、dGMP、dCMP和dUMP。
核苷酸可以无碱基(即缺乏核碱基)。核苷酸还可以缺乏核碱基和糖(即是C3间隔子)。
多核苷酸中的核苷酸可以以任何方式彼此连接。核苷酸通常通过其糖和磷酸基连接,如在核酸中那样。核苷酸可以通过其核碱基连接,如在嘧啶二聚体中那样。
多核苷酸可以是核酸,如脱氧核糖核酸(DNA)或核糖核酸(RNA)。多核苷酸可以包括与一个DNA链杂交的一个RNA链。多核苷酸可以是本领域中已知的任何合成核酸,如肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)或具有核苷酸侧链的其它合成聚合物。PNA主链由通过肽键连接的重复N-(2-氨基乙基)-甘氨酸单元构成。GNA主链由通过磷酸二酯键连接的重复二醇单元构成。TNA主链由通过磷酸二酯键连接在一起的重复苏糖构成。LNA由如上文所论述的具有额外的连接核糖部分中的2'氧和4'碳的桥的核糖核苷酸形成。
多核苷酸优选是DNA、RNA或DNA或RNA杂交体,最优选地是DNA。DNA/RNA杂交体可以在同一条链上包括DNA和RNA。优选地,DNA/RNA杂交体包括与RNA链杂交的一条DNA链。
可以更改多核苷酸的主链以减少链断裂的可能性。例如,已知DNA在许多条件下都比RNA更稳定。可以修饰多核苷酸链的主链以避免由例如苛刻的化学物质如自由基引起的损坏。
含有非天然或修饰的碱基的DNA或RNA可通过使用适当的聚合酶在修饰的NTP存在下扩增天然DNA或RNA多核苷酸来产生。
多核苷酸中的核苷酸可以被修饰。核苷酸可以被氧化或甲基化。多核苷酸中的一个或多个核苷酸可以是受损的。例如,多核苷酸可以包括嘧啶二聚体。此类二聚体通常与紫外线损伤有关并且是皮肤黑色素瘤的主要病因。多核苷酸中的一个或多个核苷酸可以用标记或标签修饰。
单链多核苷酸可以含有具有强二级结构的区域,如发夹、四链体或三链体DNA。这些类型的结构可以用于控制多核苷酸相对于纳米孔的移动。例如,二级结构可以用于使多核苷酸穿过纳米孔的移动暂停,如本文更详细描述的。沿着链的每个连续二级结构在链解旋和易位时暂停链相对于纳米孔的移动。多核苷酸可以在其易位穿过纳米孔之后重新形成二级结构。此类二级结构可以用于防止多核苷酸在低负电压或未施加负电压(施加到纳米孔的反式侧)下穿过纳米孔向后移动,并且因此有助于控制多核苷酸的移动,因此它仅在本文所提供的方法的相关步骤中以受控方式发生。
如本文所用,双链多核苷酸可以包括单链区和具有其它结构的区域,例如发夹环、三链体和/或四链体。如上文所描述,在单链多核苷酸的上下文中,这类二级结构可以为有用的。
双链分子的两条链可以共价连接,例如在分子的末端处,通过将一条链的5'端与另一条链的3'端以发夹结构连接。
靶多核苷酸可以是任何长度。例如,靶多核苷酸的长度可以是至少10个、至少50个、至少100个、至少150个、至少200个、至少250个、至少300个、至少400个或至少500个核苷酸或核苷酸对。靶多核苷酸可以是1000个或更多个核苷酸或核苷酸对,长度为5000个或更多个核苷酸或核苷酸对或长度为100000个或更多个核苷酸或核苷酸对或长度为500,000个或更多个核苷酸或核苷酸对,或长度为1,000,000个或更多个核苷酸或核苷酸对,长度为10,000,000或更多个核苷酸或核苷酸对,或长度为100,000,000或更多个核苷酸或核苷酸对,或长度为200,000,000或更多个核苷酸或核苷酸对,或染色体的整个长度。
靶多核苷酸可以是寡核苷酸。寡核苷酸是短核苷酸聚合物,其通常具有50个或更少核苷酸,如40个或更少、30个或更少、20个或更少、10个或更少或5个或更少核苷酸。靶寡核苷酸的长度优选地是约15至约30个核苷酸,例如长度是约20至约25个核苷酸。例如,寡核苷酸的长度可以是约15、约16、约17、约18、约19、约20、约21、约22、约23、约24、约25、约26、约27、约28、约29或约30个核苷酸。
靶多核苷酸可以是较长多核苷酸的片段。在此实施例中,较长多核苷酸典型地片段化为多个,如两个或更多个较短的多核苷酸。
靶多核苷酸可以包括PCR反应的产物、基因组DNA、内切核酸酶消化的产物和/或DNA文库。
靶多核苷酸可以是天然存在的。靶多核苷酸可以从细胞分泌。可替代地,目标分析物可以是存在于细胞内部的分析物,使得在实施方法之前必须从细胞中提取分析物。
靶多核苷酸可以来源于常见的生物体,如病毒、细菌、古细菌、植物或动物。可以选择或改变此类生物体以调整靶多核苷酸的序列,例如通过调整碱基组成、去除不需要的序列元件等。为了获得期望的多核苷酸特征,选择和更改生物体为本领域普通技术人员的常规操作。
可以基于序列的期望特性来选择靶多核苷酸的来源生物体。期望特征包含由生物体产生的单链与双链多核苷酸的比率;由生物体产生的多核苷酸序列的复杂性、由生物体产生的多核苷酸的组成(如GC组成)或由生物体产生的连续多核苷酸链的长度。例如,当需要大约50kb的连续多核苷酸链时,可使用λ噬菌体DNA。如果需要更长的连续链,可以使用其它生物体来产生多核苷酸;例如,大肠杆菌产生大约4.5Mb的连续dsDNA。
靶多核苷酸通常获自人或动物,例如获自尿液、淋巴、唾液、粘液、精液或羊水,或获自全血、血浆或血清。靶多核苷酸可以获自植物,例如谷类、豆类、水果或蔬菜。靶多核苷酸可以包括基因组DNA。可以使基因组DNA片段化。可以通过任何合适的方法使DNA片段化。例如,片段化DNA的方法是本领域已知的,这样的方法可以使用转座酶,如MuA转座酶。通常,不对基因组DNA进行片段化。
在一些实施例中,多核苷酸为合成的或半合成的。例如,DNA或RNA可以是纯合成的,通过常规的DNA合成方法如基于亚磷酰胺的化学方法合成。合成的多核苷酸亚基可以通过已知手段,如连接或化学键接合在一起,以产生更长的链。在一些实施例中,内部自形成结构(例如,发夹、四链体)可以设计到基底中,例如,通过连接适当的序列。合成的多核苷酸可通过本领域已知的手段(包含PCR、掺入细菌工厂等)进行复制并且放大以用于生产。
在一些实施例中,多核苷酸可以具有简化的核苷酸组成。在一些实施例中,多核苷酸具有相同亚基的重复模式。例如,重复单元可为(AmGn)q,其中m、n和q为正整数。例如,m通常为1至20,如1至10,例如1至5,例如1、2、3、4或5。n通常为1至20,如1至10,例如1至5,例如1、2、3、4或5。m和n可以相同或不同。q通常为1至约100,000。典型的重复单元可以为例如(AAAAAAGGGGGG)q。重复的多核苷酸可以通过本领域已知的许多手段来制备,例如通过将合成的亚基与使得能够连接的粘性末端串接在一起。在一些实施例中,多核苷酸因此可为串接的多核苷酸。串接多核苷酸的方法在PCT/GB2017/051493中描述。
在一些实施例中,多核苷酸可以包括含有反应性侧链的碱基。可以根据需要在侧链上并入任何合适的反应性官能团。反应性官能团的合适实例包含点击化学试剂。点击化学反应的合适的实例包含但不限于以下:
(a)1,3偶极环加成反应的无铜变体,其中,叠氮化物与炔烃在应变下(例如在环辛烷环中)反应;
(b)一个连接子上的氧亲核试剂与另一个连接子上的环氧化物或氮丙啶反应性部分的反应;以及
(c)Staudinger连接,其中炔烃部分可以被芳基膦替代,导致与叠氮化物的特定反应以产生酰胺键。
多核苷酸衔接子
在一些实施例中,马达蛋白和/或多核苷酸结合蛋白(如果存在)可以提供在多核苷酸衔接子上。WO 2015/110813描述了将马达蛋白加载到靶多核苷酸例如衔接子上,并且据此其全部内容以引用方式并入。
衔接子通常包括能够与靶多核苷酸的末端连接的多核苷酸链。靶多核苷酸通常旨在用于根据本文所公开的方法进行表征。
多核苷酸衔接子可以添加到靶多核苷酸的两个末端。可替代地,可以将不同的衔接子添加至靶多核苷酸的两端。可以将衔接子添加到靶多核苷酸的仅一端。向多核苷酸添加衔接子的方法是本领域已知的。衔接子可以例如通过连接,通过点击化学,通过标记,通过拓扑异构化或通过任何其它合适的方法与多核苷酸连接。
衔接子可以是合成的或人造的。通常,衔接子包括如本文所描述的聚合物。在一些实施例中,衔接子包括多核苷酸。在一些实施例中,衔接子可以包括单链多核苷酸链。在一些实施例中,衔接子可以包括双链多核苷酸。多核苷酸衔接子可以包括DNA、RNA、经修饰的DNA(如碱性DNA)、RNA、PNA、LNA、BNA和/或PEG。通常,衔接子包括单链和/或双链DNA或RNA。
衔接子可以包括如本文所描述的停靠部分。衔接子可以包括马达蛋白或多核苷酸结合蛋白的加载位点。衔接子可以包括标签。
衔接子可以是Y衔接子。Y衔接子通常是双链的,并且包括(a)在一端,两条链杂交在一起的区域,和(b)在另一端,两条链不互补的区域。链的非互补部分形成突出端。衔接子的杂交茎通常与双链多核苷酸的第一链的5'端和双链多核苷酸的第二链的3'端连接;或与双链多核苷酸的第一链的3'端和双链多核苷酸的第二链的5'端连接。由于两条链通常不像双链部分那样彼此不杂交,所以在Y衔接子中非互补区域的存在使衔接子具有Y形状。马达蛋白或多核苷酸结合蛋白可以与衔接子如Y衔接子的突出端结合。在另一个实施例中,马达蛋白或多核苷酸结合蛋白可以与双链区结合。在其它实施例中,马达蛋白或多核苷酸结合蛋白可以与衔接子的单链和/或双链区结合。在其它实施例中,第一马达蛋白或多核苷酸结合蛋白可以与此类衔接子的单链区结合,并且第二马达蛋白或多核苷酸结合蛋白可以与衔接子的双链区结合。
在一个实施例中,衔接子包括膜锚或孔锚。在一些实施例中,锚可以与和突出端互补并因此杂交的多核苷酸连接,所述突出端与马达蛋白或多核苷酸结合蛋白结合。
在一些实施例中,多核苷酸衔接子例如Y衔接子的非互补链之一可包含前导序列,所述前导序列当与跨膜孔接触时能够穿入纳米孔中。
前导序列通常包括聚合物,例如多核苷酸,例如DNA或RNA、经修饰的多核苷酸(例如无碱基DNA)、PNA、LNA、聚乙二醇(PEG)或多肽。在一些实施例中,前导序列包括DNA的单链,例如聚dT区段。前导序列可以是任何长度,但是通常长度为10至150个核苷酸,如长度为20至120、30至100、40至80或50至70个核苷酸。
在一个实施例中,多核苷酸衔接子是发夹环衔接子。发夹环衔接子是包括单个多核苷酸链的衔接子,其中多核苷酸链的端能够彼此杂交或被杂交至彼此,并且其中多核苷酸的中间段形成环。可以使用本领域已知的方法设计合适的发夹环衔接子。通常,发夹环衔接子的3'端与双链多核苷酸的第一链的5'端连接,并且发夹环衔接子的5'端与双链多核苷酸的第二链的3'端连接;或者发夹环衔接子的5'端与双链多核苷酸的第一链的3'端连接,并且发夹环衔接子的3'端与双链多核苷酸的第二链的5'端连接。如下文更详细解释的,多核苷酸衔接子可以与靶多核苷酸连接以表征靶多核苷酸。
本领域技术人员还将理解,当衔接子包括多核苷酸链时,衔接子的序列通常不是决定性的并且可以根据马达蛋白和其它实验条件例如待表征的任何多核苷酸来控制或选择。在实例中仅以说明的方式提供了示例性序列。例如,衔接子可以包括如SEQ ID NO:21-26或28-33中的一个或多个等序列或与SEQ ID NO:21-26或28-33中的一个或多个具有至少20%,如至少30%,例如至少40%,如至少50%,例如至少60%,如至少70%,例如至少80%,例如至少90%,例如至少95%序列相似性或同一性的多核苷酸序列。衔接子的序列通常可以改变,而不会对本文所提供的方法的功效产生负面影响。
在一些实施例中,多核苷酸衔接子可以包括用于加载马达蛋白和/或多核苷酸结合蛋白的加载位点。加载位点可以是例如可以被马达蛋白或多核苷酸结合蛋白靶向的单链区。加载位点可以是多核苷酸衔接子的区域,包括马达蛋白或多核苷酸结合蛋白的外源性多核苷酸链可以与所述区域结合,以将所述马达蛋白或所述多核苷酸结合蛋白转移至要在本文所提供的方法中评估的多核苷酸。
因此,在本文所提供的方法中使用的马达蛋白可以停靠在多核苷酸衔接子上。在其它实施例中,马达蛋白在靶多核苷酸上停靠,但在多核苷酸衔接子上不停靠。
阻断部分
在一些实施例中,可以使用阻断部分来防止马达蛋白与靶多核苷酸脱离。
在一些实施例中,阻断部分包括在靶多核苷酸中。在一些实施例中,阻断部分包括在与靶多核苷酸连接的多核苷酸衔接子中。在一些实施例中,多核苷酸衔接子,例如本文所描述的多核苷酸衔接子包括阻断部分。
阻断部分可以用于防止马达蛋白与靶多核苷酸脱离。例如,如果马达蛋白存在于靶多核苷酸或多核苷酸衔接子中的多核苷酸链的3'端处,则阻断部分通常定位于马达蛋白与链的3'端之间。如果马达蛋白存在于靶多核苷酸或多核苷酸衔接子中的多核苷酸链的5'端处,则阻断部分通常定位于马达蛋白与链的5'端之间。
例如,在一些实施例中,多核苷酸衔接子可以包括第一端和第二端,所述第一端包括用于与靶多核苷酸分析物连接的连接点;并且马达蛋白可以在多核苷酸衔接子上以用于在连接点的方向上加工衔接子的朝向停靠。在此类实施例中,阻断部分可以定位于马达蛋白与衔接子的第二端之间,以防止马达蛋白与多核苷酸衔接子的第二端脱离。
例如,在一些实施例中,多核苷酸衔接子可以包括3'端和5'端,所述3'端包括用于与靶多核苷酸分析物的5'端连接的连接点;并且马达蛋白可以在多核苷酸衔接子上以用于在3'端的方向上(即,5'→3'方向上)加工衔接子的朝向停靠。在此类实施例中,阻断部分可以定位于马达蛋白与衔接子的5'端之间,以防止马达蛋白与多核苷酸衔接子的5'端脱离。在其它实施例中,多核苷酸衔接子可以包括5'端和3'端,所述5'端包括用于与靶多核苷酸分析物的3'端连接的连接点;并且马达蛋白可以在多核苷酸衔接子上以用于在5'端的方向上(即,3'→5'方向)加工衔接子的朝向停靠。在此类实施例中,阻断部分可以定位于马达蛋白与衔接子的3'端之间,以防止马达蛋白与多核苷酸衔接子的3'端脱离。
在一些实施例中,所述靶多核苷酸包括在所述靶多核苷酸的第一端处的前导序列并且所述马达蛋白停靠在所述靶多核苷酸的第二端处或在与所述靶多核苷酸的所述第二端连接的衔接子上;并且所述阻断部分定位于所述马达蛋白与所述多核苷酸的所述第二端(即,所述多核苷酸的在所述多核苷酸的第二端处的末端)之间,由此防止所述马达蛋白在所述靶多核苷酸的所述第二端处与所述靶多核苷酸脱离。
例如,在一些实施例中,所述靶多核苷酸包括在第一链的5'端处的前导序列,并且所述马达蛋白在与所述靶多核苷酸的所述第一链的3'端连接的衔接子上在所述第一链的所述3'端处停靠;并且所述阻断部分定位于所述马达蛋白与所述多核苷酸的所述第一链的3'端之间,由此防止所述马达蛋白在所述靶多核苷酸的所述第一链的所述3'端处与所述靶多核苷酸脱离。在其它实施例中,所述靶多核苷酸包括在第一链的3'端处的前导序列,并且所述马达蛋白在与所述靶多核苷酸的所述第一链的5'端连接的衔接子上在所述第一链的所述5'端处停靠;并且所述阻断部分定位于所述马达蛋白与所述多核苷酸的所述第一链的5'端之间,由此防止所述马达蛋白在所述靶多核苷酸的所述第一链的所述5'端处与所述靶多核苷酸脱离。当然,多核苷酸衔接子可以与双链多核苷酸或单链多核苷酸连接。当靶多核苷酸是双链多核苷酸时,阻断部分通常定位于与马达蛋白相同的链上。如果马达蛋白存在于双链多核苷酸的每条链上(例如,当双链多核苷酸旋转对称时),阻断部分通常存在于多核苷酸的每条链上。
在所提供的方法中可以使用任何合适的阻断部分。合适的阻断部分包含许多可以用作如本文所描述的暂停部分的相同基团。例如,阻断部分可以包括以下中的一种或多种:
-多核苷酸二级结构,优选地发夹或G-四链体(TBA);
-核酸类似物,优选地选自肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)、桥接核酸(BNA)和无碱基核苷酸;
-荧光团、如traptavidin、链霉亲和素和中性亲和素等亲和素和/或生物素、胆固醇、亚甲蓝、二硝基酚(DNP)、地高辛和/或抗地高辛以及二苄基环辛炔基团;以及
-多核苷酸结合蛋白。
这些元件在本文中在暂停部分的上下文中更详细地描述。
间隔子
在一些实施例中,多核苷酸或多核苷酸衔接子可以包括一个或多个间隔子,例如一个至约10个间隔子,例如1个至约5个间隔子,例如1个、2个、3个、4个或5个间隔子。间隔子可以包括任何合适数量的间隔子单元。间隔子通常提供阻碍多核苷酸结合蛋白移动的能量屏障。例如,间隔子可以通过减少蛋白质的牵引,例如使用无碱基间隔子来阻碍马达蛋白或多核苷酸结合蛋白的移动。间隔子可以物理地阻止蛋白质的移动,例如通过引入庞大的化学基团以物理地阻碍多核苷酸结合蛋白的移动。
在一些实施例中,一个或多个间隔子包含在多核苷酸或多核苷酸衔接子中以在它们穿过或跨过纳米孔时提供独特的信号。一个或多个间隔子可以用于定义或分离多核苷酸的一个或多个区域;例如从靶多核苷酸中分离衔接子。
在一些实施例中,间隔子可以包括线性分子,如聚合物,例如多肽或聚乙二醇(PEG)。通常,此类间隔子具有与靶多核苷酸不同的结构。例如,如果靶多核苷酸是DNA,则所述间隔子或每个间隔子通常不包括DNA。具体地,如果靶多核苷酸是脱氧核糖核酸(DNA)或核糖核酸(RNA),则所述间隔子或每个间隔子优选地包括肽核酸(PNA)、甘油核酸(GNA)、苏糖核酸(TNA)、锁定核酸(LNA)或带有核苷酸侧链的合成聚合物。在一些实施例中,间隔子可以包括一个或多个硝基吲哚、一个或多个肌苷、一个或多个吖啶、一个或多个2-氨基嘌呤、一个或多个2-6-二氨基嘌呤、一个或多个5-溴-脱氧尿苷、一个或多个反向胸苷(反向dT)、一个或多个反向双脱氧胸苷(ddT)、一个或多个双脱氧胞苷(ddC)、一个或多个5-甲基胞苷、一个或多个5-羟甲基胞苷、一个或多个2'-O-甲基RNA碱基、一个或多个异脱氧胞苷(Iso-dC)、一个或多个异脱氧鸟苷(Iso-dG)、一个或多个C3(OC
在一些实施例中,间隔子可以包括一个或多个化学基团,例如一个或多个化学侧基。一个或多个化学基团可以与多核苷酸衔接子中的一个或多个核碱基连接。一个或多个化学基团可以与多核苷酸衔接子的主链连接。可以存在任何数目的适当的化学基团,如2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个或更多。合适的基团包含但不限于荧光团、链霉亲和素和/或生物素、胆固醇、亚甲蓝、二硝基苯酚(DNP)、地高辛和/或抗地高辛和二苯基环辛炔基团。
在一些实施例中,间隔子可以包括一个或多个无碱基核苷酸(即,缺少核碱基的核苷酸),如2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个或更多个无碱基核苷酸。在无碱基核苷酸中,核碱基可以被-H(idSp)或-OH替代。通过从一个或多个相邻核苷酸中去除核碱基,可以将无碱基间隔子插入到靶多核苷酸中。例如,可以将多核苷酸修饰为包含3-甲基腺嘌呤、7-甲基鸟嘌呤、1,N6-亚乙烯基腺嘌呤肌苷或次黄嘌呤,并且可以使用人烷基腺嘌呤DNA糖苷酶(hAAG)从这些核苷酸中去除核碱基。可替代地,可以将多核苷酸修饰成包含尿嘧啶,并且用尿嘧啶-DNA糖苷酶(UDG)去除核碱基。在一个实施例中,一个或多个间隔子不包括任何无碱基核苷酸。
可以根据多核苷酸或多核苷酸衔接子的性质、马达蛋白和进行所述方法的条件来设计或选择合适的间隔子。
标签
在一些实施例中,多核苷酸或多核苷酸衔接子可以包括标签或系链。例如,多核苷酸可以例如通过其衔接子结合到纳米孔上的标签,并且例如在通过纳米孔表征多核苷酸期间在某些点处释放。强的非共价结合(例如,生物素/亲和素)仍然是可逆的,并且可以用于本文所描述的方法的一些实施例中。
在一些实施例中,孔标签和多核苷酸衔接子对可以被配置成使得多核苷酸上的结合位点(例如,由衔接子的锚或前导序列或由衔接子的双链体茎内的捕获序列提供的结合位点)与纳米孔上的标签的结合强度或亲和力足以维持纳米孔与多核苷酸之间的连接,直到所施加的力放置于其上以从纳米孔释放结合的多核苷酸。
在一些实施例中,标签或系链不带电荷。这样可以确保在电位差的影响下,标签或系链不会被拉入纳米孔中。
吸引或结合多核苷酸或衔接子的一个或多个分子可以与检测器(例如,孔)连接。可以使用与衔接子和/或靶多核苷酸杂交的任何分子。连接到孔的分子可以选自PNA标签、PEG连接子、短寡核苷酸、带正电荷的氨基酸和适体。具有与它们连接的此类分子的孔是本领域已知的。例如,使短寡核苷酸与其连接的孔公开于Howarka等人(2001)《自然生物技术(Nature Biotech.)》19:636-639和WO 2010/086620中,并且包括连接于孔的管腔内的PEG的孔公开于Howarka等人(2000)《美国化学协会期刊(J.Am.Chem.Soc.)》122(11):2411-2416中。
连接到检测器(例如,跨膜孔)的短寡核苷酸,所述寡核苷酸包括与前导序列中的序列或衔接子中另一个单链序列互补的序列,可以用于在本文所描述的方法中增强靶多核苷酸的捕获。
在一些实施例中,标签或系链可以包括或可以是寡核苷酸(例如,DNA、RNA、LNA、BNA、PNA或吗啉代)。寡核苷酸(例如,DNA、RNA、LNA、BNA、PNA或吗啉基)可以具有约10-30个核苷酸的长度或约10-20个核苷酸的长度。在一些实施例中,用于标签或系链中的寡核苷酸(例如,DNA、RNA、LNA、BNA、PNA或吗啉基)可以具有至少一个被修饰用于与其它修饰或固体基质表面(包含例如珠粒)的末端(例如,3'端或5'端)缀合。末端改性剂可以添加可以用于缀合的反应性官能团。可以添加的官能团的实例包含但不限于氨基、羧基、硫醇、马来酰亚胺、氨氧基和其任何组合。官能团可以与不同长度的间隔子(例如,C3、C9、C12、间隔子9和18)组合以增加官能团与寡核苷酸序列末端的物理距离。
在一些实施例中,标签或系链可包含或是吗啉基寡核苷酸。吗啉基寡核苷酸的长度可以为约10至30个核苷酸或长度为约10至20个核苷酸。吗啉基寡核苷酸可以是修饰的或未修饰的。例如,在一些实施例中,吗啉基寡核苷酸可以在寡核苷酸的3'端和/或5'端被修饰。吗啉基寡核苷酸的3'端和/或5'端上的修饰的实例包含但不限于3'亲和标签和用于化学连接的官能团(包含例如3'-生物素、3'-伯胺、3'-二硫化物酰胺、3'-吡啶基二硫基及其任何组合);5'端修饰(包含例如5'-伯胺和/或5'-dabcyl),用于点击化学的修饰(包含例如3'-叠氮化物、3'-炔烃、5'-叠氮化物、5'-炔烃)以及其任何组合。
在一些实施例中,标签或系链可以进一步包括聚合物连接子,例如,以刺进偶联到检测器,例如,纳米孔。示例性聚合物连接子包含但不限于聚乙二醇(PEG)。聚合物连接子的分子量可以为约500Da到约10kDa(包含端值),或约1kDa到约5kDa(包含端值)。聚合物连接子(例如,PEG)可以用不同的官能团官能化,包含例如但不限于马来酰亚胺、NHS酯、二苯并环辛炔(DBCO)、叠氮化物、生物素、胺、炔烃、醛和其任何组合。在一些实施例中,标签或系链可以进一步包括具有5'-马来酰亚胺基团和3'-DBCO基团的1kDa PEG。在一些实施例中,标签或系链可以进一步包括具有5'-马来酰亚胺基团和3'-DBCO基团的2kDa PEG。在一些实施例中,标签或系链可以进一步包括具有5'-马来酰亚胺基团和3'-DBCO基团的3kDa PEG。在一些实施例中,标签或系链可以进一步包括具有5'-马来酰亚胺基团和5'-DBCO基团的3kDaPEG。
标签或系链的其它实例包含但不限于His标签、生物素或链霉亲和素、与分析物结合的抗体、与分析物结合的适体、分析物结合结构域,如DNA结合结构域(包含例如肽拉链,如亮氨酸拉链、单链DNA结合蛋白(SSB))及其任何组合。
可以使用本领域已知的任何方法,将标签或系链连接到纳米孔的外表面,例如,在膜的顺式侧。例如,一种或多种标签或系链可以通过一种或多种半胱氨酸(半胱氨酸键)、一种或多种伯胺(如赖氨酸)、一种或多种非天然氨基酸、一种或多种组氨酸(His标签)、一种或多种生物素或链霉亲和素、一种或多种基于抗体的标签、表位的一种或多种酶修饰(包含例如乙酰转移酶)和其任意组合与纳米孔连接。用于进行此类修饰的合适方法在本领域是众所周知的。合适的非天然氨基酸包含但不限于4-叠氮基-L-苯丙氨酸(Faz),以及LiuC.C.和Schultz P.G.,《生物化学年鉴(Annu.Rev.Biochem.)》,2010,79,413-444的图1中编号为1-71的氨基酸中的任一种。
在一个或多个标签或系链通过半胱氨酸键连接到纳米孔的一些实施例中,可以将一种或多种半胱氨酸引入到通过取代形成纳米孔的一种或多种单体中。在一些实施例中,可以通过连接如下来对纳米孔进行化学修饰:(i)马来酰亚胺,包含二溴马来酰亚胺,如:4-苯基偶氮马来酰亚胺、1.N-(2-羟乙基)马来酰亚胺、N-环己基马来酰亚胺、1.3-马来酰亚胺基丙酸、1.1-4-氨基苯基-1H-吡咯,2,5,二酮、1.1-4-羟基苯基-1H-吡咯,2,5,二酮、N-乙基马来酰亚胺、N-甲氧基羰基马来酰亚胺、N-叔丁基马来酰亚胺、N-(2-氨基乙基)马来酰亚胺、3-马来酰亚胺基-PROXYL、N-(4-氯苯基)马来酰亚胺,1-[4-(二甲氨基)-3,5-二硝基苯基]-1H-吡咯-2,5-二酮、N-[4-(2-苯并咪唑基)苯基]马来酰亚胺,N-[4-(2-苯并噁唑基)苯基]马来酰亚胺、N-(1-萘基)-马来酰亚胺、N-(2,4-二甲苯基)马来酰亚胺、N-(2,4-二氟苯基)马来酰亚胺、N-(3-氯-对甲苯基)-马来酰亚胺、1-(2-氨基-乙基)-吡咯-2,5-二酮盐酸盐、1-环戊基-3-甲基-2,5-二氢-1H-吡咯-2,5-二酮、1-(3-氨基丙基)-2,5-二氢-1H-吡咯-2,5-二酮盐酸盐、3-甲基-1-[2-氧代-2-(哌嗪-1-基)乙基]-2,5-二氢-1H-吡咯-2,5-二酮盐酸盐、1-苄基-2,5-二氢-1H-吡咯-2,5-二酮、3-甲基-1-(3,3,3-三氟丙基)-2,5-二氢-1H-吡咯-2,5-二酮、1-[4-(甲氨基)环己基]-2,5-二氢-1H-吡咯-2,5-二酮三氟乙酸、SMILES O=C1C=CC(=O)N1CC=2C=CN=CC2、SMILES O=C1C=CC(=O)N1CN2CCNCC2、1-苄基-3-甲基-2,5-二氢-1H-吡咯-2,5-二酮、1-(2-氟苯基)-3-甲基-2,5-二氢1H-吡咯-2,5-二酮、N-(4-苯氧基苯基)马来酰亚胺,N-(4-硝基苯基)马来酰亚胺;(ii)碘乙酰胺,如:3-(2-碘乙酰胺)-丙基,N-(环丙基甲基)-2-碘乙酰胺、2-碘-N-(2-苯乙基)乙酰胺、2-碘-N-(2,2,2-三氟乙基)乙酰胺、N-(4-乙酰苯基)-2-碘乙酰胺,N-(4-(氨基磺酰基)苯基)-2-碘乙酰胺、N-(1,3-苯并噻唑-2-基)-2-碘乙酰胺、N-(2,6-二乙基苯基)-2-碘乙酰胺、N-(2-苯甲酰基-4-氯苯基)-2-碘乙酰胺;(iii)溴乙酰胺:如N-(4-(乙酰氨基)苯基)-2-溴乙酰胺、N-(2-乙酰苯基)-2-溴乙酰胺、2-溴-n-(2-氰基苯基)乙酰胺、2-溴-N-(3-(三氟甲基)苯基)乙酰胺、N-(2-苯甲酰基苯基)-2-溴乙酰胺、2-溴-N-(4-氟苯基)-3-甲基丁酰胺、N-苄基-2-溴-N-苯基丙酰胺、N-(2-溴-丁酰基)-4-氯-苯磺酰胺、2-溴-N-甲基-N-苯基乙酰胺、2-溴-N-苯乙基-乙酰胺、2-金刚烷-1-基-2-溴-N-环己基-乙酰胺、2-溴-N-(2-甲基苯基)丁酰胺、单溴乙酰苯胺;(iv)二硫化物,如:醛硫醇-2、醛硫醇-4、异丙基二硫醚、1-(异丁基二硫烷基)-2-甲基丙烷、二苄基二硫化物、4-氨基苯基二硫化物、3-(2-吡啶基二硫代)丙酸、3-(2-吡啶基二硫代)丙酸酰肼、3-(2-吡啶基二硫代)丙酸N-琥珀酰亚胺酯、am6amPDP1-βCD;以及(v)硫醇,如:4-苯基噻唑-2-硫醇、Pulpald、5,6,7,8-四氢-喹唑啉-2-硫醇。
在一些实施例中,标签或系链可以直接或通过一个或多个连接子连接到纳米孔。可以使用WO 2010/086602中描述的杂交连接子将标签或系链连接到纳米孔。可替代地,可以使用肽连接子。肽连接子是氨基酸序列。肽连接子的长度、柔性和亲水性通常被设计为使得其不干扰单体和孔的功能。优选的柔性肽连接子是2个到20个,如4个、6个、8个、10个或16个丝氨酸和/或甘氨酸氨基酸的延伸段。更优选的柔性连接子包含(SG)
锚
在一个实施例中,多核苷酸或多核苷酸衔接子可以包括膜锚或跨膜孔锚。在一个实施例中,锚有助于根据本文所公开的方法表征靶多核苷酸。例如,膜锚或跨膜孔锚可以促进所选多核苷酸在纳米孔周围的定位。
锚可以是可以插入到膜中的多肽锚和/或疏水性锚。在一个实施例中,疏水性锚是脂质、脂肪酸、甾醇、碳纳米管、多肽、蛋白质或氨基酸,例如胆固醇、棕榈酸酯或生育酚。锚可以包括硫醇、生物素或表面活性剂。
一方面,锚可以是生物素(用于与链霉亲和素结合)、直链淀粉(用于与麦芽糖结合蛋白或融合蛋白结合)、Ni-NTA(用于与聚组氨酸或聚组氨酸标记的蛋白结合)或肽(如抗原)。
在一个实施例中,锚可以包括连接子,或2个、3个、4个或更多个连接子。优选的连接子包含但不限于聚合物,如多核苷酸、聚乙二醇(PEG)、多糖和多肽。这些连接子可以是线性、支链或环状的。例如,连接子可以是环状多核苷酸。衔接子可以与环状多核苷酸连接子上的互补序列杂交。一个或多个锚或一个或多个连接子可以包括可被切割或分解的组分,如限制性位点或光不稳定基团。连接子可以用马来酰亚胺基团官能化以与蛋白质中的半胱氨酸残基连接。WO 2010/086602中描述了适合的连接子。
在一个实施例中,锚是胆固醇或脂肪酰基链。例如,可以使用具有的长度为6到30个碳原子的任何脂肪酰基链,如十六烷酸。WO 2012/164270和WO 2015/150786中公开了合适的锚的实例以及将锚与衔接子连接的方法。
在另一个实施例中,锚可以由以下组成或包括以下:对多核苷酸或多核苷酸衔接子的疏水性修饰。疏水性修饰可以包括包含在多核苷酸或多核苷酸锚中的经修饰的磷酸基团。疏水性修饰可以例如包括硫代磷酸酯,如Jones等人,《美国化学学会杂志》2021,143,22,8305中描述的电荷中和的烷基硫代磷酸酯(PPT),所述文献的全部内容特此通过引用并入。合适的烷基包含例如C
检测器
在本文所提供的方法中,多核苷酸相对于检测器如纳米孔移动。检测器可以选自以下:(i)零模波导;(ii)场效应晶体管,任选地纳米线场效应晶体管;(iii)AFM尖端;(iv)纳米管,任选地碳纳米管;以及(v)纳米孔。优选地,所述检测器是纳米孔。
可以以任何合适的方式在本文所提供的方法中表征多核苷酸。在一个实施例中,多核苷酸通过当多核苷酸相对于纳米孔移动时检测离子电流或光信号来进行表征。这在本文中进行了更详细的描述。所述方法适用于这些和其它检测多核苷酸的方法。
在另一个非限制性实例中,在一个实施例中,多核苷酸通过检测多核苷酸加工反应,如边合成边测序反应的副产物来进行表征。所述方法因此可以涉及检测通过酶,如聚合酶向核酸链中顺序添加(聚)核苷酸的产物。产物可以是酶的一种或多种性质的变化,例如酶的构型。这种方法因此可以包括在以下条件下使如聚合酶或逆转录酶等酶经受双链多核苷酸:响应于依次遇到的模板链核酸碱基和/或掺入模板指定的天然或类似物碱基(即,掺入事件),使得将核苷酸碱基模板依赖性掺入生长中的寡核苷酸链中会引起酶的构象变化,响应于这种掺入事件检测酶的构象变化,并且由此检测模板链的序列。在此类方法中,可以根据本文所提供的方法移动多核苷酸链。这种方法可以涉及使用本领域的技术人员已知的方法,如在US 2017/0044605中描述的方法,检测和/或测量掺入事件。
在另一个实施例中,可以对副产物进行标记,以便在将核苷酸添加到与模板链互补的合成核酸链中时释放磷酸标记的物质,并且例如,使用如本文所描述的检测器检测磷酸标记的物质。可以根据本文的方法移动以此方式表征的多核苷酸。合适的标记物可以是使用纳米孔或零模波导或通过拉曼光谱(Raman spectroscopy)或其它检测器检测的光学标记物。合适的标记物可以是使用纳米孔或其它检测器检测的非光学标记物。
在另一种方法中,不标记核苷磷酸酯(核苷酸),并且在向与模板链互补的合成核酸链中添加核苷酸后,检测到天然副产物物质。合适的检测器可以是离子敏感的场效应晶体管或其它检测器。
这些和其它检测方法适用于本文所描述的方法。当多核苷酸相对于检测器移动时,可以使用检测器进行任何合适的测量。
纳米孔
在其中检测器是纳米孔的所公开的方法的实施例中,可以使用任何合适的纳米孔。在一个实施例中,纳米孔是跨膜孔。
跨膜孔是某种程度上跨膜的结构。它允许由施加的电势驱动的水合离子在膜上或膜内流动。跨膜孔通常穿过整个膜,使得水合离子可以从膜的一侧流向膜的另一侧。然而,跨膜孔不必要穿过膜。它可能在一端封闭。例如,孔可以是膜中的孔、间隙、通道、沟槽或狭缝,水合离子可以沿着膜流入或流入到膜中。
在本文所提供的方法中,纳米孔通常具有第一开口和第二开口。第一开口通常是顺式开口,并且第二开口通常是反式开口。然而,在一些实施例中,第一开口是反式开口,并且第二开口是顺式开口。在本文所提供的方法中使用的马达蛋白通常在纳米孔的第一开口处提供并且因此控制靶多核苷酸在从纳米孔的第二开口朝向纳米孔的第一开口的方向上的移动。
在本文提供的方法中可以使用任何跨膜孔。孔可以是生物的或人工的。合适的孔包含但不限于蛋白质孔、多核苷酸孔和固态孔。孔可以是DNA折纸孔(origami pore)(Langecker等人,《科学(Science)》,2012;338:932-936)。WO2013/083983中公开了合适的DNA折纸孔。
在一个实施例中,纳米孔是跨膜蛋白孔。跨膜蛋白孔是允许水合离子(如多核苷酸)从膜的一侧流向膜的另一侧的多肽或多肽集合。在本文所提供的方法中,跨膜蛋白孔能够形成允许由施加的电势驱动的水合离子从膜的一侧流向另一侧的孔。跨膜蛋白孔优选地允许多核苷酸从膜(如三嵌段共聚物膜)的一侧流到另一侧。跨膜蛋白孔允许多核苷酸移动通过孔。
在一个实施例中,纳米孔是跨膜蛋白孔,其为单体或寡聚体。孔优选地由若干重复的亚基,如至少6个、至少7个、至少8个、至少9个、至少10个、至少11个、至少12个、至少13个、至少14个、至少15个或至少16个亚基构成。孔优选地是六聚体、七聚体、八聚体或非聚体的孔。孔可以是同型寡聚体或异型低聚物。
在一个实施例中,跨膜蛋白孔包括离子可以通过其流动的桶或通道。孔的亚基通常围绕中心轴线,并向跨膜β-桶或通道或跨膜α-螺旋束或通道贡献链。
通常,跨膜蛋白质孔的桶或通道包括促进与分析物,如靶多核苷酸(如本文所描述的)的相互作用的氨基酸。这些氨基酸优选地位于桶或通道的缢痕附近。跨膜蛋白孔通常包括一个或多个带正电荷的氨基酸,如精氨酸、赖氨酸或组氨酸,或芳香族氨基酸,如酪氨酸或色氨酸。这些氨基酸通常促进孔与核苷酸、多核苷酸或核酸之间的相互作用。
在一个实施例中,纳米孔是源自β-桶孔或α-螺旋束孔的跨膜蛋白孔。β-桶孔包括由β-链形成的桶或通道。合适的β-桶孔包含但不限于β-毒素,如α-溶血素、炭疽毒素和白细胞素,以及细菌的外膜蛋白/孔蛋白,如耻垢分枝杆菌(Mycobacterium smegmatis)孔蛋白(Msp),例如MspA、MspB、MspC或MspD、CsgG,外膜孔蛋白F(OmpF)、外膜孔蛋白G(OmpG)、外膜磷脂酶A和奈瑟氏球菌(Neisseria)自转运蛋白(NalP)以及其它孔隙,如胞溶素。α-螺旋束孔包括由α-螺旋形成的桶或通道。合适的α-螺旋束孔包含但不限于内膜蛋白和α外膜蛋白,如WZA和ClyA毒素。
在一个实施例中,纳米孔是衍生自或基于Msp、α-溶血素(α-HL)、胞溶素、CsgG、ClyA、Sp1以及溶血蛋白fragaceatoxin C(FraC)的跨膜孔。
在一个实施例中,纳米孔是衍生自CsgG,例如衍生自来自大肠杆菌菌株K-12亚株MC4100的CsgG的跨膜蛋白孔。此类孔是寡聚的,并且通常包括源自CsgG的7个、8个、9个或10个单体。孔可以是源自包括相同单体的CsgG的同质寡聚孔。可替代地,孔可以是源自包括至少一种不同于其它单体的单体的CsgG的异质寡聚孔。在WO 2016/034591中公开了源自CsgG的合适的孔的实例。
在一个实施例中,纳米孔是源自溶酶素的跨膜孔。WO 2013/153359中公开了源自胞溶素的合适的孔的实例。
在一个实施例中,纳米孔是源自或基于α-溶血素(α-HL)的跨膜孔。野生型α-溶血素孔由7个相同的单体或亚基形成(即,它是七聚的)。α-溶血素孔可以是α-溶血素-NN或其变体。变体优选地包括在位置E111和K147处的N个残基。
在一个实施例中,纳米孔是源自Msp,例如源自MspA的跨膜蛋白孔。WO 2012/107778中公开了衍生自MspA的合适的孔的实例。
在一个实施例中,纳米孔是源自或基于ClyA的跨膜孔。
膜
在所公开的方法中,检测器通常是存在于膜中的纳米孔。可以使用任何合适的膜。
膜优选地是两亲层。两亲层是由如磷脂等两亲分子形成的层,其具有亲水性和亲脂性两者。两亲性分子可以是合成的或天然存在的。非天然存在的两亲物和形成单层的两亲物在所属领域中是已知的,并且包含例如嵌段共聚物(Gonzalez-Perez等人,《朗缪尔(Langmuir)》,2009,25,10447-10450)。嵌段共聚物是聚合在一起的两个或更多个单体亚基产生单一聚合物链的聚合材料。嵌段共聚物通常具有由每个单体亚基贡献的性质。然而,嵌段共聚物可以具有由个别子单元形成的聚合物不拥有的独特特性。嵌段共聚物可以进行工程化,使得单体亚基中的一个在水性介质中是疏水性的(即亲脂性),而其它亚基是亲水性的。在此情况下,嵌段共聚物可以拥有两亲特性,并且可以形成模拟生物膜的结构。嵌段共聚物可以是二嵌段的(其由两个单体子单元组成),但也可以由超过两个的单体子单元来构建,形成表现为两亲物的更复杂的排列。共聚物可以是三嵌段、四嵌段或五嵌段共聚物。膜优选地是三嵌段共聚物膜。
古细菌双极性四醚脂质是天然存在的脂质,其被构建成使得脂质形成单层膜。这些脂质一般发现于在苛刻生物环境中存活的嗜极生物、嗜热生物、嗜盐生物和嗜酸生物中。其稳定性被认为是源于最终双层的融合性质。直接了当的做法是,通过产生具有一般基序亲水性-疏水性-亲水性的三嵌段聚合物来构建模拟这些生物实体的嵌段共聚物材料。这种材料可以形成表现类似于脂质双层并且涵盖从囊泡到层状膜的一系列阶段表现的单体膜。由这些三嵌段共聚物形成的膜在生物脂质膜上保持若干优势。因为合成三嵌段共聚物,所以可以小心地控制准确的构建,以提供形成膜和与孔和其它蛋白质相互作用所需的正确链长度和特性。
还可以由不分类为脂质亚材料的子单元来构建嵌段共聚物;例如可以由硅氧烷或其它非基于烃的单体来制成疏水性聚合物。嵌段共聚物的亲水性亚区段还可以具备低蛋白质结合特性,这允许产生当暴露于原始生物样品时具有高度抗性的膜。此头基单元还可以源自非经典的脂质头基。
与生物脂质膜进行比较,三嵌段共聚物膜还具有增加的机械和环境稳定性,例如高许多的操作温度或pH范围。嵌段共聚物的合成性质提供定制用于广泛范围应用的基于聚合物的膜的平台。
在一些实施例中,膜是国际申请第WO2014/064443号或第WO2014/064444号中所公开的膜中的一个膜。
两亲分子可以进行化学修饰或官能化,以便于偶联多核苷酸。两亲性层可以是单层或双层。两亲性层通常是平面的。两亲性层可以是弯曲的。两亲性层可以是支撑式的。
两亲膜通常是天然可移动的,基本上以大约10
膜可以是脂质双层。脂质双层是细胞膜的模型,并且用作一系列实验研究的极佳平台。例如,脂质双层可以用于通过单通道记录对膜蛋白的活体外研究。可替代地,脂质双层可以用作检测一系列物质的存在的生物传感器。脂质双层可以是任何脂质双层。合适的脂质双层包含但不限于平面脂质双层、支持双层或脂质体。脂质双层优选地是平坦脂质双层。合适脂质双层公开于WO 2008/102121、WO 2009/077734和WO 2006/100484中。
用于形成脂质双层的方法在本领域中是已知的。脂质双层通常通过Montal和Mueller的方法(《美国国家科学院院刊(Proc.Natl.Acad.Sci.USA.)》,1972;69:3561-3566)来形成,其中脂质单层通过垂直于所述界面的开孔的任一侧承载在水溶液/空气界面上。通常通过首先将脂质溶解在有机溶剂中,并且然后使在开孔两侧上的水溶液的表面上蒸发一滴溶剂,来将脂质添加到水性电解质溶液的表面。一旦有机溶剂已蒸发,那么开孔两侧上的溶液/空气界面来回物理地移动通过开孔,直到形成双层为止。可以跨膜中的开孔或跨凹槽中的开口形成平面脂质双层。
Montal和Mueller的方法是常用的,这是因为是节约成本的,且是形成适合于蛋白孔插入的良好品质脂质双层的相对直接了当的方法。双层形成的其它常见方法包含脂质体双层的尖端浸没、双层涂刷和贴片夹持。
尖端浸没双层形成需要使孔隙表面(例如移液管尖端)接触到携载脂质单层的测试溶液的表面。同样,通过将溶解于有机溶剂中的一滴脂质在溶液表面处蒸发来首先在溶液/空气界面处产生脂质单层。接着,通过朗缪尔-沙佛(Langmuir-Schaefer)过程形成双层,并且需要机械自动以使开孔相对于溶液表面移动。
对于涂刷的双层,将溶解于有机溶剂中的一滴脂质直接应用于开孔,所述开孔浸没在水性测试溶液中。使用笔刷或等效物,使脂质溶液稀薄地扩散在开孔内。溶剂的稀化使得形成脂质双层。然而,从双层完全去除溶剂是非常困难的,并且因此通过这种方法形成的双层较不稳定且更倾向于在电化学测量期间具有噪声。
贴片夹持是在生物细胞膜研究中常用的。通过抽汲将细胞膜夹持到移液管的末端,并且膜贴片变为连接在开孔内。所述方法适用于通过夹持接着爆裂以离开密封在移液管的开孔内的脂质双层的脂质体来产生脂质双层。所述方法需要稳定的、巨大的且单层脂质体和在具有玻璃表面的材料中制造小开孔。
可通过超声处理、挤压或Mozafari方法来形成脂质体(Colas等人(2007年)《微米(Micron)》38:841–847)。
在一些实施例中,如国际申请第WO 2009/077734号中所描述形成脂质双层。在此方法中有利的是,由干燥脂质形成脂质双层。在一最优选实施例中,跨越开口形成脂质双层,如WO2009/077734中所描述。
由脂质的两个相对层形成脂质双层。两个脂质层被布置成使得其疏水尾部基团面朝彼此,形成疏水性的内部。脂质的亲水性头基朝外面向双层每侧上的水性环境。双层可存在于多种脂质阶段中,所述阶段包含但不限于液体无序阶段(液体片层)、液体有序阶段、固体有序阶段(片层凝胶阶段、交错结合的凝胶阶段)和平坦双层晶体(片层亚凝胶阶段、片层结晶阶段)。
可以使用形成脂质双层的任何脂质组合物。选择脂质组合物,使得脂质双层具有所需的特性,例如表面电荷、支持膜蛋白的能力、充填密度或所形成的机械特性。脂质组合物可以包括一种或多种不同脂质。例如,脂质组合物可以含有至多100种脂质。脂质组合物优选地含有1到10种脂质。脂质组合物可以包括天然存在的脂质和/或人工脂质。
脂质通常包括头基、界面部分和可相同或不同的两个疏水尾部基团。合适的头基包含(但不限于):中性头基,例如二酰基甘油酯(DG)和脑酰胺(CM);两性离子头基,如磷脂酰胆碱(PC)、磷脂酰乙醇胺(PE)和鞘磷脂(SM);带负电荷的头基,如磷脂酰甘油(PG);磷脂酰丝氨酸(PS)、磷脂酰肌醇(PI)、磷脂酸(PA)和心磷脂(CA);以及带正电荷的头基,如三甲基铵丙烷(TAP)。合适界面部分包含但不限于天然存在的界面部分,例如基于甘油或基于脑酰胺的部分。合适的疏水性尾基包含但不限于:饱和烃链,例如月桂酸(正十二烷酸)、肉豆蔻酸(正十四烷酸)、棕榈酸(正十六烷酸)、硬脂酸(正十八烷酸)和花生酸(正二十烷酸);不饱和烃链,如油酸(顺-9-十八烷酸);以及支链烃链,如植烷酰基。链的长度和不饱和烃链中的双键的位置和数量可以变化。链的长度和支链烃链中的支链(如甲基)的位置和数量可以变化。疏水性尾基可以作为醚或酯连接到界面部分。脂质可以是分枝菌酸。
脂质还可以进行化学修饰。脂质的头基或尾部基团可以进行化学修饰。头基已进行化学修饰的合适的脂质包含但不限于:经PEG修饰的脂质,如1,2-二酰基-sn-甘油-3-磷酸乙醇胺-N-[甲氧基(聚乙二醇)-2000];官能化PEG脂质,如1,2-二硬脂酰基-sn-甘油-3磷酸乙醇胺-N-[生物素基(聚乙二醇)2000];以及针对缀合修饰的脂质,如1,2-二油酰基-sn-甘油-3-磷酸乙醇胺-N-(琥珀酰基)和1,2-二棕榈酰基-sn-甘油-3-磷酸乙醇胺-N-(生物素基)。尾基已进行化学修饰的合适的脂质包含但不限于:可聚合脂质,如1,2-双(10,12-二十三碳二炔基)-sn-甘油-3-磷酸胆碱;氟化脂质,如1-棕榈酰基-2-(16-氟棕榈酰基)-sn-甘油-3-磷酸胆碱;氘化脂质,如1,2-二棕榈酰基-D62-sn-甘油-3-磷酸胆碱;以及醚连接的脂质,如1,2-二-O-植烷基-sn-甘油-3-磷酸胆碱。脂质可以进行化学修饰或官能化,以便于偶联多核苷酸。
两亲性层,例如脂质组合物,通常包括将影响层的特性的一种或多种添加剂。合适的添加剂包含但不限于:脂肪酸,如棕榈酸、肉豆蔻酸和油酸;脂肪醇,如棕榈醇、肉豆蔻醇和油醇;甾醇,如胆固醇、麦角固醇、羊毛甾醇、谷甾醇和豆甾醇;溶血磷脂,如1-酰基-2-羟基-sn-甘油-3-磷酸胆碱;以及神经酰胺。
在另一个实施例中,膜包括固态层。固态层可以由有机材料和无机材料两者形成,所述材料包含但不限于:微电子材料、绝缘材料(如Si
通常使用以下来实行本文公开的方法:(i)包括孔的人工两亲层,(ii)包括孔的分离的天然存在的脂质双层,或(iii)其中插入孔的细胞。通常使用人工两亲层(如人工三嵌段共聚物层)来执行方法。所述层可以包括其它跨膜和/或膜内蛋白质以及除孔以外的其它分子。以下论述了合适的设备和条件。通常在体外进行本发明的方法。
一般方法
如上所述,本文所提供的方法可以使用任何合适的检测器进行操作,并且因此可以使用用于检测多核苷酸的任何合适的设备。
在一些实施例中,可以使用适合于跨膜孔感测的任何设备进行本文所提供的方法。例如,所述设备可以包括包含水溶液的室和将室分成两段的屏障。屏障通常具有开孔,在开孔中形成含有孔的膜。本文描述了跨膜孔。
可以使用WO 2008/102120、WO 2010/122293或WO 00/28312中描述的设备进行方法。简言之,分子(例如,靶多核苷酸)在孔的通道中的结合将对通过孔的开放通道离子流产生影响,这是孔通道的“分子感测”的本质。可以使用合适的测量技术通过电流的变化来测量开放通道离子流的变化。通过电流的减少测量的离子流的减少程度与孔内或孔附近的障碍物的大小有关。因此,孔中或孔附近的感兴趣的分子(例如靶多核苷酸)的结合提供了可检测和可测量的事件,从而形成了“生物传感器”的基础。检测生物分子的存在可应用于个性化药物开发、医学、诊断、生命科学研究、环境监测以及安全和/或国防工业。
当用于表征多核苷酸时,确定靶多核苷酸的存在、不存在或一个或多个特性。所述方法可以用于确定至少一种靶多核苷酸的存在、不存在或一个或多个特性。方法可以涉及确定两种或更多种靶多核苷酸的存在、不存在或一个或多个特性。方法可以包括确定任何数量的靶多核苷酸(如2种、5种、10种、15种、20种、30种、40种、50种、100种或更多种靶多核苷酸)的存在、不存在或一个或多个特性。可以确定一种或多种靶多核苷酸的任何数量的特性,如1种、2种、3种、4种、5种、10种或更多种特性。适合于在本文所提供的方法中检测的特性包含多核苷酸的同一性或序列、多核苷酸的长度、多核苷酸是否被修饰等。在一些实施例中,本文所提供的方法是对靶多核苷酸进行测序的方法。在一些实施例中,可以通过将实时信号或碱基调用与已知参考比对来实时确定多核苷酸序列。确定多核苷酸序列的示例性方法在WO 2016/059427中描述,其以引用的方式并入本文中。
当用于表征多核苷酸时,所述方法可以涉及通常通过测量电流来测量流经孔的离子电流。可替代地,可以光学测量通过孔的离子流,如在Heron等人:《美国化学学会期刊》第9卷131,第5期,2009中所公开的。因此,设备还可以包括能够施加电位并且测量跨膜和孔的电信号的电路。可以使用膜片钳或电压钳来进行表征方法。表征方法优选地涉及电压钳的使用。
所述方法可以涉及测量光学信号,如Chen等人,《自然通讯(NatureCommunications)》(2018)9:1733中描述的,所述文献的全部内容特此通过引用并入。例如,可以使用如光学工程化纳米孔结构(例如,等离子体纳米狭缝)等纳米孔来局部启用单分子表面增强拉曼光谱(SERS)以允许通过直接拉曼光谱检测来表征多核苷酸。
方法可以在基于硅的孔阵列上进行,其中每个阵列包括128个、256个、512个、1024个、2000个、3000个、4000个、6000个、10000个、12000个、15000个或更多个孔。
本方法可以涉及测量流过孔的电流。所述方法通常在跨膜和孔施加电压的情况下进行。所使用的电压通常为+2V到-2V,通常为-400mV到+400mV。所使用的电压优选地处于具有下限和上限的范围内,所述下限选自-400mV、-300mV、-200mV、-150mV、-100mV、-50mV、-20mV和0mV,并且所述上限独立地选自+10mV、+20mV、+50mV、+100mV、+150mV、+200mV、+300mV和+400mV。所使用的电压更优选地处于100mV到240mV的范围内,并且最优选地处于120mV到220mV的范围内。通过使用增加的施加电位,可以通过孔增加不同核苷酸之间的区分度。
在所公开的方法的一些实施例中,具体地是涉及重新读取如本文所描述的靶多核苷酸的那些方法中,所述方法包括提供用于促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合和/或用于延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合的条件。
通常在存在任何电荷载流子的情况下进行方法,所述电荷载流子如金属盐,例如碱金属盐;卤盐,例如如碱金属氯化物盐等氯化物盐。电荷载流子可以包含离子液体或有机盐,例如四甲基氯化铵、三甲基苯基氯化铵、苯基三甲基氯化铵或1-乙基-3-甲基氯化咪唑鎓。在上文所讨论的示例性设备中,盐存在于室中的水溶液中。通常使用氯化钾(KCl)、氯化钠(NaCl)或氯化铯(CsCl)。KCl是优选的。该盐可以是碱土金属盐,如氯化钙(CaCl2)。盐浓度可以是饱和的。盐浓度可以是3M或更低,并且通常为0.1M到2.5M、0.3M到1.9M、0.5M到1.8M、0.7M到1.7M、0.9M到1.6M、或1M到1.4M。盐浓度优选地为150mM到1M。优选地使用至少0.3M的盐浓度进行方法,如至少0.4M,至少0.5M,至少0.6M,至少0.8M,至少1.0M,至少1.5M,至少2.0M,至少2.5M或至少3.0M。高盐浓度提供高信噪比,并允许在正常电流波动的背景下识别指示结合/无结合的电流。
在一些实施例中,提供所述条件包括提供盐浓度以增加所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合的速率。在一些实施例中,提供所述条件包括提供盐浓度以降低所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合的速率。鉴于本文的公开内容,确定合适的盐浓度以促进靶多核苷酸与马达蛋白的多核苷酸结合位点解结合和/或以用于延迟重新结合在本领域技术人员的能力范围内。
在一些实施例中,提供所述条件包括提供渗透压以增加所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合的速率。在一些实施例中,提供所述条件包括提供渗透压以降低所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合的速率。鉴于本文的公开内容,确定合适的渗透压以促进靶多核苷酸与马达蛋白的多核苷酸结合位点解结合和/或以用于延迟重新结合在本领域技术人员的能力范围内。
通常在存在缓冲液的情况下进行所述方法。在上文所讨论的示例性设备中,缓冲液存在于室中的水溶液中。可以使用任何合适的缓冲液。通常,缓冲液是HEPES。另一种合适的缓冲液是Tris-HCl缓冲液。通常在以下的pH下执行所述方法:4.0到12.0、4.5到10.0、5.0到9.0、5.5到8.8、6.0到8.7或7.0到8.8或7.5到8.5。所用pH优选地是约7.5。
可以在以下温度下进行所述方法:0℃至100℃、15℃至95℃、16℃至90℃、17℃至85℃、18℃至80℃、19℃至70℃或20℃至60℃。通常在室温下进行所述方法。任选地在支持酶功能的温度进行所述方法,如约37℃下进行。
在一些实施例中,提供所述条件包括提高温度以提高所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合的速率。在一些实施例中,提供所述条件包括提高温度以降低所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合的速率。不受任何理论束缚,本发明人认为提高温度可以通过例如提高马达蛋白与多核苷酸的解离速率来促进重新读取。鉴于本文的公开内容,确定合适的温度以促进靶多核苷酸与马达蛋白的多核苷酸结合位点解结合和/或以用于延迟重新结合在本领域技术人员的能力范围内。
本文提供了通过提供用于促进重新读取的温度来提供用于促进重新读取的条件的实例,例如参见实例11。在一些实施例中,提供用于促进靶多核苷酸与马达蛋白的多核苷酸结合位点解结合和/或用于延迟靶多核苷酸与马达蛋白的多核苷酸结合位点重新结合的条件可以包括提供以下温度:约20℃至约50℃,如约30℃至约45℃,例如约34℃至约40℃,例如约31℃、32℃、33℃、34℃、35℃、36℃、37℃、38℃或39℃。
所公开的方法的另外的方面
以下是所公开的方法的另外的方面:
1.一种表征靶多核苷酸的方法,所述方法包括:
(i)使检测器与结合有马达蛋白的所述靶多核苷酸接触,其中所述靶多核苷酸在所述马达蛋白的多核苷酸结合位点处与所述马达蛋白结合;
(ii)在所述马达蛋白控制所述靶多核苷酸在第一方向上相对于所述检测器的移动时对所述靶多核苷酸的特性进行一个或多个测量;
(iii)使所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合,使得所述靶多核苷酸在第二方向上相对于所述检测器移动;
(iv)将所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合;并且在所述马达蛋白控制所述靶多核苷酸在所述第一方向上相对于所述检测器的所述移动时对所述靶多核苷酸的特性进行一个或多个测量;
由此表征所述靶多核苷酸。
2.根据方面1所述的方法,其包括多次重复步骤(iii)和(iv)。
3.根据方面1或2所述的方法,其中在步骤(ii)中,所述马达蛋白控制所述靶多核苷酸的第一部分在所述第一方向上相对于所述检测器的所述移动;并且在步骤(iv)中,所述马达蛋白控制所述靶多核苷酸的第二部分在所述第一方向上相对于所述检测器的所述移动;并且其中所述第一部分与所述第二部分至少部分地重叠。
4.根据前述方面中任一项所述的方法,其中所述第一部分与所述第二部分相同。
5.根据前述方面中任一项所述的方法,其中在步骤(iii)中,所述靶多核苷酸相对于所述检测器移动的距离的长度为至少100个核苷酸。
6.根据前述方面中任一项所述的方法,其中所述检测器包括在具有第一开口和第二开口的结构中,或者包括具有第一开口和第二开口的跨膜纳米孔;并且步骤(i)包括用所述靶多核苷酸收缩所述第一开口。
7.根据方面6所述的方法,其中(i)所述马达蛋白控制所述靶多核苷酸在从所述第二开口到所述第一开口的方向上的所述移动;并且(ii)当所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合时,所述靶多核苷酸在从所述第一开口到所述第二开口的所述方向上移动。
8.根据前述方面中任一项所述的方法,其包括跨所述检测器施加力,并且其中所述马达蛋白控制所述靶多核苷酸在与所施加的力相反的方向上相对于所述检测器的所述移动。
9.根据前述方面中任一项所述的方法,其中所述检测器包括跨膜纳米孔,所述跨膜纳米孔跨越具有顺式侧和反式侧的膜,并且:
(i)所述纳米孔的所述第一开口位于所述膜的所述顺式侧处并且所述纳米孔的所述第二开口位于所述反式侧处;所述马达蛋白控制所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧穿过所述纳米孔的所述移动;并且当所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合时,所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧移动穿过所述纳米孔;或者
(ii)所述纳米孔的所述第一开口位于所述膜的所述反式侧处并且所述纳米孔的所述第二开口位于所述顺式侧处;所述马达蛋白控制所述靶多核苷酸从所述膜的所述顺式侧到所述反式侧穿过所述纳米孔的所述移动;并且当所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合时,所述靶多核苷酸从所述膜的所述反式侧到所述顺式侧移动穿过所述纳米孔。
10.根据前述方面中任一项所述的方法,其中所述靶多核苷酸与前导连接或包括前导,所述前导被配置成促进所述马达蛋白的所述多核苷酸结合位点与所述前导附近的所述靶多核苷酸解结合。
11.根据方面10所述的方法,其中当所述马达蛋白接触所述前导时,所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合。
12.根据方面10或方面11所述的方法,其中所述马达蛋白对所述前导的亲和力低于对所述靶多核苷酸的核苷酸的亲和力。
13.根据方面10至12中任一项所述的方法,其中所述前导包括与所述靶多核苷酸不同类型的核苷酸。
14.根据方面10至13中任一项所述的方法,其中(i)所述靶多核苷酸包括脱氧核糖核苷酸(DNA),并且所述前导包括一个或多个缺乏核碱基和糖部分(间隔子部分)两者的核苷酸、核糖核苷酸(RNA)、肽核苷酸(PNA)、甘油核苷酸(GNA)、苏糖核苷酸(TNA)、锁定核苷酸(LNA)、桥接核苷酸(BNA)、无碱基核苷酸或具有经修饰的磷酸键的核苷酸;或者(ii)所述靶多核苷酸包括核糖核苷酸(RNA),并且所述前导包括一个或多个缺乏核碱基和糖部分(间隔子部分)两者的核苷酸、脱氧核糖核苷酸(DNA)、肽核苷酸(PNA)、甘油核苷酸(GNA)、苏糖核苷酸(TNA)、锁定核苷酸(LNA)、桥接核苷酸(BNA)、无碱基核苷酸或具有经修饰的磷酸键的核苷酸。
15.根据方面10至14中任一项所述的方法,其中所述靶多核苷酸包括脱氧核糖核苷酸(DNA)并且所述前导包括一个或多个间隔子部分和/或一个或多个核糖核苷酸。
16.根据前述方面中任一项所述的方法,其中所述靶多核苷酸不与所述马达蛋白脱离。
17.根据前述方面中任一项所述的方法,其中所述马达蛋白被修饰为防止所述靶多核苷酸与所述靶多核苷酸脱离。
18.根据前述方面中任一项所述的方法,其中所述马达蛋白被修饰为促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合和/或延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合。
19.根据前述方面中方面任一项所述的方法,其中所述马达蛋白用闭合部分修饰以用于(i)拓扑闭合所述马达蛋白的在所述靶多核苷酸周围的所述多核苷酸结合位点并且(ii)促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合和/或延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合。
20.根据方面19所述的方法,其中所述马达蛋白被修饰为促进所述闭合部分与所述马达蛋白的连接。
21.根据方面20所述的方法,其中所述马达蛋白通过用所述马达蛋白中的至少一个氨基酸取代半胱氨酸或非天然氨基酸来修饰。
22.根据方面19至21中任一项所述的方法,其中所述闭合部分包括双官能交联剂。
23.根据方面19至22中任一项所述的方法,其中所述闭合部分使所述马达蛋白的两个氨基酸残基交联,其中由所述闭合部分交联的至少一个氨基酸是半胱氨酸或非天然氨基酸。
24.根据方面19至23中任一项所述的方法,其中所述闭合部分的长度为约
25.根据方面19至21中任一项所述的方法,其中所述闭合部分包括键,优选地二硫键。
26.根据方面19至24中任一项所述的方法,其中所述闭合部分包括式[A-B-C]的结构,其中A和C各自独立地是用于与所述马达蛋白中的氨基酸残基反应的反应性官能团,并且B是连接部分。
27.根据方面26所述的方法,其中A和C各自独立地是半胱氨酸反应性官能团。
28.根据方面26或27所述的方法,其中连接部分B包括直链或支链、未经取代的或经取代的亚烷基、亚烯基、亚炔基、亚芳基、亚杂芳基、亚碳环基或亚杂环基部分,所述部分任选地被一个或多个选自以下的原子或基团中断和/或终止于所述一个或多个原子或基团:O、N(R)、S、C(O)、C(O)NR、C(O)O、未经取代的或经取代的亚芳基、亚芳基-亚烷基、亚杂芳基、亚杂芳基-亚烷基、亚碳环基、亚碳环基-亚烷基、亚杂环基和亚杂环基-亚烷基;其中R选自H、未经取代的或经取代的烷基以及未经取代的或经取代的芳基。
29.根据方面26至28中任一项所述的方法,其中连接部分B包括亚烷基、氧化烯或聚氧化烯基团和/或其中A和C各自为马来酰亚胺基团。
30.根据方面19至25或26至29中任一项所述的方法,其中所述闭合部分的长度为约
31.根据前述方面中任一项所述的方法,其包括提供用于促进所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合和/或用于延迟所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点的重新结合的条件。
32.根据方面31所述的方法,其中提供所述条件包括提高温度以提高所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点解结合的速率。
33.根据方面31或32所述的方法,其中提供所述条件包括提高所述温度以降低所述靶多核苷酸与所述马达蛋白的所述多核苷酸结合位点重新结合的速率。
34.根据前述方面中任一项所述的方法,其中所述马达蛋白是解旋酶。
这些方面涉及本文更详细描述的特征。
多核苷酸衔接子
还提供了包括马达蛋白的多核苷酸衔接子。应当理解的是,本文公开的任何多核苷酸衔接子都可以应用于本文和上文讨论的方法的实施方式中。
在一个实施例中,本文提供了一种多核苷酸衔接子,其具有第一端和第二端,所述第一端包括用于与双链多核苷酸分析物连接的连接点;其中所述多核苷酸衔接子包括(i)在所述连接点的方向上以用于加工所述衔接子的朝向停靠在所述多核苷酸衔接子上的马达蛋白和(ii)定位于所述马达蛋白与所述衔接子的所述第二端之间的阻断部分。
在一个实施例中,所述多核苷酸衔接子是如本文更详细描述的多核苷酸衔接子。在一个实施例中,所述马达蛋白是如本文所描述的马达蛋白。在一个实施例中,所述阻断部分是如本文所描述的阻断部分。
马达蛋白被定向以在朝向衔接子上的用于与双链多核苷酸连接的连接点的方向上加工多核苷酸衔接子。马达蛋白可以定向在多核苷酸衔接子上以控制靶多核苷酸在反式-顺式方向上的移动。
马达蛋白定向在多核苷酸衔接子上以控制靶多核苷酸在朝向马达蛋白的方向上相对于检测器如纳米孔的移动;即,从检测器中移动出去,例如从如本文更详细描述的纳米孔中移动出去。
在一些实施例中,多核苷酸衔接子包括如本文所描述的停靠部分。在一些实施例中,多核苷酸衔接子包括如本文所描述的暂停部分。
试剂盒
还提供了包括多核苷酸衔接子和马达蛋白的试剂盒。应当理解的是,本文公开的任何多核苷酸衔接子都可以应用于本文和上文讨论的试剂盒的实施例中。
在一个实施例中,提供了一种用于修饰靶多核苷酸的试剂盒,所述试剂盒包括如本文所提供的第一多核苷酸衔接子;以及第二衔接子,所述第二衔接子包括在第一端处的单链前导序列和在第二端处的用于与双链多核苷酸分析物连接的连接点。
在一些实施例中,第二衔接子是如本文更详细描述的衔接子。
系统
还提供了包括多核苷酸衔接子、马达蛋白和纳米孔的系统。应当理解的是,本文公开的任何多核苷酸衔接子都可以应用于本文和上文讨论的系统的实施例中。
在一个实施例中,提供了一种用于表征靶双链多核苷酸的系统,所述系统包括:
-多核苷酸衔接子,所述多核苷酸衔接子包括停靠部分和任选地暂停部分;
-纳米孔,所述纳米孔用于在靶多核苷酸相对于所述纳米孔移动时表征所述靶多核苷酸;以及
-马达蛋白,所述马达蛋白用于使所述双链多核苷酸在第一方向上相对于所述纳米孔移动。
在一个实施例中,所述多核苷酸衔接子是如本文更详细描述的多核苷酸衔接子。在一个实施例中,所述马达蛋白是如本文所描述的马达蛋白。在一个实施例中,所述纳米孔是如本文所描述的纳米孔。所述系统可以进一步包括如本文所定义的膜;控制设备等。
应当理解,虽然本文已经针对根据本发明的方法讨论了特定实施例、特定构造以及材料和/或分子,但是可以在不脱离本发明的范围和精神的情况下在形式和细节上进行各种改变或修改。提供以下实例以更好地说明特定实施例,并且不应将其视为限制本申请。本申请仅由权利要求书限制。
实例
实例1
此实例展示了使用DNA马达使DNA多核苷酸链受控易位穿过纳米孔,所述DNA马达在它在ssDNA上易位5'-3'的同时使dsDNA解旋。DNA马达最初停靠在与多核苷酸连接的Y衔接子上。多核苷酸在不同阶段易位穿过纳米孔:(1)无酶阶段,在所述无酶阶段中,多核苷酸的3'端被纳米孔捕获,并且纳米孔在所施加的正电位下易位并分离双链体,直到其到达停靠在远侧5'端上的DNA马达;(2)‘解停靠’阶段,在所述解停靠阶段中,DNA马达最初无法在正偏压下移动越过停靠,但通过施加反向电位被激活(‘解停靠’);(3)DNA马达控制阶段,在所述阶段中,马达开始逆着所施加的电位使DNA 5'-3'从纳米孔中移动出去;(4)在到达多核苷酸的末端时,观察到恒定的阻断水平,可以通过逆转用于将链弹出的电位来清除所述水平。
通过PCR获得不对称的3.6千碱基双链DNA分析物(λ噬菌体DNA的片段;SEQ ID NO:20),并且通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NewEngland Biolabs,NEB))以及USER消化进行末端修复和dA加尾,以在一端处产生3'dA突出端,并且在另一端出留下3'AGGA突出端。
通过粘接DNA寡核苷酸(SEQ ID NO:21、SEQ ID NO:22)制备Y衔接子。将DNA马达(Dda解旋酶)加载到衔接子上。将单体traptavidin添加到衔接子中以作为阻断剂与5'生物素部分结合,以(1)防止DNA马达从5'端向后扩散和(2)防止纳米孔无意中捕获文库的5'端。
使用来自牛津纳米孔技术公司(Oxford Nanopore Technologies)测序试剂盒SKQ-LSK109(本文中也被称为LSK-SQK109;参见https://community.nanoporetech.com/protocols/gDNA-sqk-lsk109/v/gde_9063_v109_revt_14aug2019了解详细信息)的LNB和T4 DNA连接酶(NEB)将双链DNA分析物与Y衔接子的dA加尾端连接。使用Agencourt AMPureXP(贝克曼库尔特公司(Beckman Coulter))珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH 8.0)中,产生‘DNA文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1200μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加50nM的DNA系链,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库、0.7μL过量的单体traptavidin(约100nM四聚体)和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
制备了定制的测序脚本来控制所施加的电位,如下所示:10秒捕获阶段(+120mV);0.5秒解停靠阶段(0mV);85.5秒测序(+120mV);弹出阶段(在0mV与-120mV之间变化,1秒;-120mV,3秒)。这个施加电位序列被重复多次。
使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
图6示出了在此实例中使用的衔接子。图7示出了与双链多核苷酸分析物连接的衔接子。图8示出了此实例中的实验示意图,所述实验示意图示出了捕获、解停靠和表征多核苷酸分析物所需的施加电位的模式。图9示出了此实例的示例电流对时间迹线。数据示出了纳米孔对多核苷酸分析物的捕获,然后通过将施加的电位降低到0与-120mV之间,在它‘解停靠’之后,将DNA受控、逐步地从纳米孔中移动出去。记录了在-40mV的解停靠电位以上的很少的酶介导事件,这表明在0与-40mV之间,单链在解停靠阶段保留在纳米孔中。
实例2
此实例展示了使用DNA马达使DNA多核苷酸双链体的两条链受控易位穿过纳米孔,所述DNA马达在它在ssDNA上易位5'-3'的同时使dsDNA解旋。DNA马达最初停靠在与多核苷酸连接的Y衔接子上。模板链和补体链通过发夹部分连接在一起。多核苷酸在不同阶段易位穿过纳米孔:(1)无酶阶段,在所述无酶阶段中,多核苷酸的3'端被纳米孔捕获,并且纳米孔在所施加的正电位下易位并分离双链体,首先通过补体链,然后是模板链,直到其到达停靠在远侧5'端上的DNA马达;(2)‘解停靠’阶段,在所述解停靠阶段中,DNA马达最初无法在正偏压下移动越过停靠,但通过施加反向电位被激活(‘解停靠’);(3)DNA马达控制阶段,在所述阶段中,马达开始逆着所施加的电位使DNA 5'-3'从纳米孔中移动出去;DNA马达最初在模板链之上移动,经过发夹,然后在补体链之上移动;(4)在到达多核苷酸的末端时,观察到恒定的阻断水平,可以通过逆转用于将链弹出的电位来清除所述水平。
通过PCR获得不对称的3.6千碱基双链DNA分析物(λ噬菌体DNA的片段;SEQ ID NO:20),并且通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NewEngland Biolabs,NEB))以及USER消化进行末端修复和dA加尾,以在一端处产生3'dA突出端,并且在另一端出留下3'AGGA突出端。
通过粘接DNA寡核苷酸(SEQ ID NO:21;SEQ ID NO:22)制备Y衔接子。将DNA马达(Dda解旋酶)加载到衔接子上。将单体traptavidin添加到衔接子中以作为阻断剂与5'生物素部分结合,以(1)防止DNA马达从5'端向后扩散和(2)防止纳米孔无意中捕获文库的5'端。
通过将DNA寡核苷酸(SEQ ID NO:23)在双链体退火缓冲液(整合DNA技术公司(Integrated DNA Technologies,Inc.))中以1μM加热至95℃持续2分钟,然后在湿冰上快速冷却来制备带有3'-TCCT突出端的发夹。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB和T4 DNA连接酶(NEB)将双链DNA分析物和发夹与Y衔接子连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH 8.0)中,产生‘DNA文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1200μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加50nM的DNA系链,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库、0.7μL过量的单体traptavidin(约100nM四聚体)和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
制备了定制的测序脚本来控制所施加的电位,如下所示:10秒捕获阶段(+120mV);0.5秒解停靠阶段(根据实验是可变的,在0mV至-120mV的范围内);85.5秒测序(+120mV);弹出阶段(0mV,1秒;-120mV,3秒)。这个施加电位序列被重复多次。
使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
图10示出了此实例中使用的组分:发夹(A)、衔接子(B)和多核苷酸分析物(C);(D)示出了连接在一起的所有组分。图11示出了此实例中的实验示意图,所述实验示意图示出了捕获、解停靠和表征发夹衍生的多核苷酸分析物所需的施加电位的模式。图12a示出了此实例的若干示例电流对时间迹线。数据示出了纳米孔对多核苷酸分析物的捕获,然后在它‘解停靠’之后,将DNA受控、逐步地从纳米孔中移动出去。解停靠电位在0mV与-120mV之间变化;然而,在-60mV以上没有观察到酶介导的事件,这表明在反式隔室中折叠的发夹在解停靠期间向弹出赋予了至多-60mV电位的抗性,并且与单独的单链DNA相比具有另外的抗性(根据实例1)。图12b示出了将状态A至G分配给图11中的示例电流迹线。当与实例1相比时,在图12b中观察到了另外的状态E,这可以归因于酶介导的多核苷酸的补体部分从纳米孔中出去的移动,紧随模板部分D。
实例3
此实例展示了通过‘主动解停靠’过程控制DNA马达的解停靠。DNA多核苷酸双链体的一条或两条链使用DNA马达通过纳米孔,所述马达在它在ssDNA上易位5'-3'的同时使dsDNA解旋。DNA马达最初停靠在与多核苷酸连接的Y衔接子上。任选地,在多核苷酸的远侧端,模板链和补体链通过发夹部分连接;在其它方面,模板链和补体链通过省略发夹而未连接。多核苷酸在不同阶段易位穿过纳米孔:(1)无酶阶段,在所述无酶阶段中,多核苷酸的3'端被纳米孔捕获,并且纳米孔易位并分离双链体,直到其到达停靠在远侧5'端上的DNA马达;(2)主动‘解停靠’阶段,在所述解停靠阶段中,DNA马达最初无法在正偏压下移动越过停靠,但通过重复施加弹出电位,然后返回到测序电位被激活(‘解停靠’);(3)DNA马达控制阶段,在所述阶段中,马达开始逆着所施加的电位使DNA 5'-3'从纳米孔中移动出去;以及(4)在到达多核苷酸的末端时,观察到恒定的阻断水平,可以通过逆转用于将链弹出的电位来清除所述水平。
通过PCR获得不对称的3.6千碱基双链DNA分析物(λ噬菌体DNA的片段;SEQ ID NO:20),并且通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NewEngland Biolabs,NEB))以及USER消化进行末端修复和dA加尾,以在一端处产生3'dA突出端,并且在另一端出留下3'AGGA突出端。
通过PCR获得对称的3.6千碱基双链DNA分析物(λ噬菌体DNA的片段;SEQ ID NO:20),并且通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NEB))进行末端修复和dA加尾,以两端处产生3'dA突出端。
通过粘接DNA寡核苷酸(SEQ ID NO:21、SEQ ID NO:22)制备Y衔接子。将DNA马达(Dda解旋酶)加载到衔接子上。将单体traptavidin添加到衔接子中以作为阻断剂与5'生物素部分结合,以(1)防止DNA马达从5'端向后扩散和(2)防止纳米孔无意中捕获文库的5'端。
通过将DNA寡核苷酸(SEQ ID NO:23)在双链体退火缓冲液(整合DNA技术公司(Integrated DNA Technologies,Inc.))中以1μM加热至95℃持续2分钟,然后在湿冰上快速冷却来制备带有3'-TCCT突出端的发夹。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB和T4 DNA连接酶(NEB)将对称的双链DNA分析物与Y衔接子连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH 8.0)中,产生‘1D DNA文库’。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB和T4 DNA连接酶(NEB)将对称的双链DNA分析物与Y衔接子和发夹连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH8.0)中,产生‘2DDNA文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1200μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加50nM的DNA系链,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL 1D文库或2D DNA文库、0.7μL过量的单体traptavidin(约100nM四聚体)和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用MinION的有源解锁电路制备了定制测序脚本以控制所施加的电位。测序电压设置为120mV,并且有源解锁电位(‘主动解停靠’阶段;阶段(2),如上文所描述)针对1D文库设置为-12mV,并且针对2D文库设置为-48mV。停靠水平和链(测序)水平的分类被编程到MinKNOW仪器控制软件中的配置文件中,所述软件使得能够检测停靠的物种并施加不会导致链完全弹出的解锁电位,使用来自实例1和2的静态解锁电势的知识。所述脚本的功能如下:如果MinKNOW检测到链处于停靠水平,它将首先施加解锁电位持续5秒,然后返回到120mV的测序电位以检查五次主动测序链。如果停靠水平仍然存在,它将再施加解锁电位持续另外25秒,并重复五次。每次解锁尝试之间都包含3秒的休息期。如果在返回测序电位时,MinKNOW检测到主动测序链,它将停止尝试解锁并仅施加测序电位。如果这整个过程没有产生主动测序链,MinKNOW将关闭通道。每隔15分钟,应用“mux扫描”来重置系统,这会在120mV下全局解锁流通池上的所有通道并检查活性纳米孔。
使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
图7和10,D示出了此实例中使用的多核苷酸分析物。这些的制备在实例1和2中描述。图13示出了1D DNA文库(A)和2D DNA文库(B)的示例电流迹线。进行解停靠尝试的部分用星号标记。数据示出了1D和2D文库都可以使用这些方法解停靠,并且可以反复进行若干尝试以使酶解停靠,并且然后检查多核苷酸从纳米孔中出去的酶控制移动。
实例4
此实例展示了可以如何使用来自易位(3'-5')穿过纳米孔的DNA的初始无酶部分的信号的持续时间来估计双链DNA分子的大小,所述双链DNA分子的模板链和补体链是由发夹部分连接,然后远侧端上的5'-3'DNA马达主动将DNA链在相反方向上从纳米孔中易位出去。另外地,此实例示出了可以如何使用添加到发夹中的标志物来划分信号。
DNA马达最初停靠在与多核苷酸连接的Y衔接子上。根据实例2,模板链和补体链通过发夹部分连接在一起。任选地,发夹部分含有庞大的荧光团基团或无碱基基团,和/或另外的寡核苷酸与发夹杂交。
使用引物(其中一个引物含有多个dUTP碱基)通过PCR获得不对称的3.6千碱基双链DNA分析物(λ噬菌体DNA的片段;SEQ ID NO:20),并且通过NEBNext末端修复和NEBNextdA加尾模块(新英格兰生物实验室(NEB))然后通过NEB USER消化进行末端修复和dA加尾,以在一端处产生3'dA突出端,并且在另一端出留下3'AGGA突出端。
通过将通用衔接子与已使用Covaris gTube剪切至约20kb的剪切大小的大肠杆菌SCS110DNA连接并通过PCR扩增来产生大肠杆菌双链DNA的随机文库。通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NEB))对片段进行末端修复和dA加尾,以在两端处产生3'dA突出端。
通过粘接DNA寡核苷酸(SEQ ID NO:21、SEQ ID NO:22)制备Y衔接子。将DNA马达(Dda解旋酶)加载到衔接子上。将单体traptavidin添加到衔接子中以作为阻断剂与5'生物素部分结合,以(1)防止DNA马达从5'端向后扩散和(2)防止纳米孔无意中捕获文库的5'端。
带有3'-TCCT或3'-T突出端的发夹是通过在双链体退火缓冲液(整合DNA技术公司)中将DNA SEQ ID NO:24、SEQ ID NO:25或SEQ ID NO:26以1μM加热至95℃持续2分钟,然后在湿冰上快速冷却来制备的。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB和T4 DNA连接酶(NEB)将不对称的3.6千碱基双链DNA分析物和发夹(SEQ ID NO:24或SEQ ID NO:26)与Y衔接子连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH 8.0)中,产生‘3.6kb DNA文库’。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB以及T4 DNA连接酶(NEB)将大肠杆菌双链DNA和发夹(SEQ ID NO:25)与Y衔接子连接。使用Agencourt AMPureXP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH8.0)中,产生‘随机大肠杆菌测试文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1200μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加50nM的DNA系链,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL的3.6kb文库或随机大肠杆菌测试文库、0.7μL过量的单体traptavidin(约100nM四聚体)和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。还以50nM向反应的一部分中添加寡核苷酸SEQ ID NO:27。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
两个库使用不同的运行脚本进行了测试。使用定制测序脚本运行3.6kb文库,以控制所施加的电位如下:10秒捕获阶段(+120mV);0.5秒解停靠阶段(-40mV);85.5秒测序(+120mV);弹出阶段(0mV,1秒;-120mV,3秒)。这个施加电位序列被重复多次。使用实例3中描述的定制主动解停靠脚本运行随机大肠杆菌测试文库,其中捕获/测序电压为120mV,并且弹出电压为-48mV。
使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
图14示出了此实例中使用的发夹和寡核苷酸组合。3.6kb DNA文库用于首先表征捕获阶段信号。图15示出了预期在无酶和酶介导易位的电测量中检测到的中间体的示意图。通过与图11比较,在初始无酶捕获期间,预期会出现两个另外的状态A1和A2,分别对应于纳米孔中的庞大基团和纳米孔顶部的阻断寡核苷酸(如图15所示)。预期在酶介导的易位的模板(D)阶段与补体(E)阶段之间会出现另外的状态D1,对应于酶在发夹部分中的庞大基团之上易位。图16a至16d示出了每个发夹-寡核苷酸组合的示例迹线。仅发夹部分(图16a)表现出相对平坦但可检测的捕获阶段(由星号标记)。添加与发夹部分杂交的寡核苷酸引入了另外的上升中间体(在图16b中标记为A2),并且三个庞大的荧光素-dT碱基引入了下降(在图16c中标记为A1)。与发夹和荧光素-dT碱基杂交的寡核苷酸的组合引入了两种类型的信号(参见图16d)。另外的信号的引入使得能够测量多核苷酸的无酶捕获/进入阶段的持续时间(在图16a-d中通过星号表示)。
使用图16b所示方案(发夹加杂交的寡核苷酸)的实例用于测量随机大肠杆菌测试文库的无酶捕获阶段(图16e)。图16e,i示出了四个实例的简化(事件拟合)原始数据。60pA的阈值用于测量状态A与A2之间的无酶捕获持续时间,通过星号表示。图16e、ii示出了针对三十个分子的捕获持续时间绘制的酶介导的易位持续时间。线性回归分析表明,无酶捕获持续时间与酶介导的链持续时间相关,证实可以在解码其序列之前使用此方法估计链的大小。
实例5
此实例展示了使用DNA马达使DNA多核苷酸链受控易位穿过纳米孔,所述DNA马达在它在ssDNA上易位5'-3'的同时使dsDNA解旋。此实例描述了先前实例中描述的替代性衔接子配置。DNA马达最初停靠在与多核苷酸连接的Y衔接子上。多核苷酸在不同阶段易位穿过纳米孔:(1)无酶阶段,在所述无酶阶段中,多核苷酸的3'端被纳米孔捕获,并且纳米孔在所施加的正电位下易位并分离双链体,直到其到达停靠在远侧5'端上的DNA马达;(2)‘解停靠’阶段,在所述解停靠阶段中,DNA马达最初无法在正偏压下移动越过停靠,但通过施加反向电位被激活(‘解停靠’);(3)DNA马达控制阶段,在所述阶段中,马达开始逆着所施加的电位使DNA 5'-3'从纳米孔中移动出去;(4)在到达多核苷酸的末端时,观察到恒定的阻断水平,可以通过逆转用于将链弹出的电位来清除所述水平。
Y衔接子是通过粘接DNA寡核苷酸(SEQ ID NO:28、SEQ ID NO:29、SEQ ID NO:30和SEQ ID NO:31)制备的。将DNA马达(Dda解旋酶)加载到衔接子上。与先前的实例相比,寡核苷酸SEQ ID NO:31替代了生物素-链霉亲和素复合物的功能:寡核苷酸在酶的后面形成了双链体区,这两者都阻止了酶从它所加载的链的5'端向后扩散,并防止5'末端链被纳米孔捕获。寡核苷酸SEQ ID NO:30充当用于使酶在溶液中停靠的前向阻断剂。此衔接子的示意图如图17a所示。
通过PCR获得对称的3.6千碱基双链DNA分析物(λ噬菌体DNA的片段;SEQ ID NO:20),并且通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NEB))进行末端修复和dA加尾,以两端处产生3'dA突出端。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB以及T4 DNA连接酶(NEB)将双链DNA分析物与Y衔接子的dA加尾端连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH8.0)中,产生‘DNA文库’。文库的示意图如图17b所示。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1170μL FB中添加30μL的FLT(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)),产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
实例3中描述的定制测序脚本用于控制酶的解停靠,其中测序电压为120mV,并且弹出电压为12mV。使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
图17c示出了在多核苷酸的捕获和酶的解停靠期间预期看到的中间步骤的示意图。与实例1相比,预期会有另外的中间体(纳米孔顶部的阻断剂链,随后通过纳米孔去除阻断剂;图17c中的状态B)。图17d示出了代表性电流-时间迹线(i)。加框部分(ii)对应于捕获/进入阶段。在所示实例中,酶在第二次五秒解停靠尝试(D)时解停靠,并且酶在E期间控制多核苷酸从纳米孔中移动出去(在iii中扩展)。数据表明,(a)可以(a)用寡核苷酸‘反向阻断剂’替代实例1中描述的生物素-traptavidin键的功能,并且(b)酶阻断剂寡核苷酸作为被纳米孔去除的单独的片段存在。
实例6
此实例展示了使用DNA马达使DNA多核苷酸链受控易位穿过纳米孔,所述DNA马达在它在ssDNA上易位5'-3'的同时使dsDNA解旋。DNA马达最初停靠在与多核苷酸连接的Y衔接子上。与先前的实例相比,Y衔接子含有寡核苷酸,所述寡核苷酸带有一个带有三十个3'端C3间隔子残基的前导。多核苷酸在不同阶段易位穿过纳米孔:(1)无酶阶段,在所述无酶阶段中,多核苷酸的3'端被纳米孔捕获,并且纳米孔在所施加的正电位下易位并分离双链体,直到其到达停靠在远侧5'端上的DNA马达;(2)‘解停靠’阶段,在所述解停靠阶段中,DNA马达最初无法在正偏压下移动越过停靠,但通过施加反向电位被激活(‘解停靠’);(3)DNA马达控制阶段,在所述阶段中,马达开始逆着所施加的电位使DNA 5'-3'从纳米孔中移动出去;(4)在到达多核苷酸的末端时,可以观察到与先前实例中的poly(dT)水平明显不同的可以通过逆转用于将链弹出的电位来清除的恒定阻塞水平;以及偶尔(5)在由于所施加的测序电位产生的力下,酶会自发地向后滑动,与上游DNA重新结合,并从步骤(3)开始重复。
Y衔接子是通过粘接DNA寡核苷酸(SEQ ID NO:28、SEQ ID NO:33、SEQ ID NO:30和SEQ ID NO:32)来制备的。将DNA马达(Dda解旋酶)加载到衔接子上。SEQ ID NO:33寡核苷酸含有上文所描述的C3间隔子残基。
通过使用SnaBI和BamHI限制性酶消化λ噬菌体DNA得到七片段DNA文库,并且通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NEB))进行末端修复和dA加尾以在每个片段的两端处产生3'dA突出端。
使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB以及T4 DNA连接酶(NEB)将七片段DNA文库与Y衔接子的dA加尾端连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH8.0)中,产生‘DNA文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1170μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加30μL的FLT,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用定制测序脚本运行DNA文库以控制所施加的电位如下:55秒捕获阶段(+120mV);5秒解停靠阶段(-20mV);55秒测序(+120mV);弹出阶段(0mV,1秒;-120mV,3秒)。这个施加电位序列被重复多次。使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
图18a示出了实验的示意图。与图17c相比,此实验引入了另外的‘重新读取’步骤(RR),其中酶解结合并从3'C3(非DNA)前导滑动返回DNA链(E)上的较早位置并再一次使5'易位到3',导致同一DNA链的多次读取。在重新读取之间看不到开孔水平,这意味着分子不太可能从纳米孔中弹出。图18b示出了被读取两次(i和ii)的分子的示例电流-时间迹线。训练隐马尔可夫模型(Hidden Markov Model)以将酶控制部分与每个限制性片段的参考进行映射(图18c)。数据显示读段映射到参考文献中的同一片段,并且记录的实例部分地映射了两次或三次,证实了所述链被多次读取。
实例7
此实例展示了可以如何使用所施加的电压来使用DNA马达控制DNA多核苷酸链穿过纳米孔的易位速度,所述DNA马达在它在ssDNA上易位5'-3'的同时使dsDNA解旋,所述施加的电压与电场施加在DNA上的力相反。
Y衔接子是通过粘接DNA寡核苷酸(SEQ ID NO:28、SEQ ID NO:33、SEQ ID NO:30和SEQ ID NO:32)来制备的。将DNA马达(Dda解旋酶)加载到衔接子上。
根据实例6制备七片段λ噬菌体文库。使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB以及T4 DNA连接酶(NEB)将文库与Y衔接子的dA加尾端连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH 8.0)中,产生‘DNA文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1170μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加30μL的FLT,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用以下定制测序脚本运行DNA文库以控制所施加的电位如下:55秒捕获阶段(+120至+200mV);5秒解停靠阶段(-20mV);55秒测序(+120mV);弹出阶段(0mV,1秒;-120mV,3秒)。这个施加电位序列被重复多次。使用MinKNOW软件(牛津纳米孔技术公司)在批量FAST5文件中收集原始数据。
实验方案在图17c中描述;在此实例中,捕获/定序电压在120mV与200mV之间变化。使用实例6中描述的HMM模型映射数据。图19a-d示出了在120mV、140mV和160mV下收集的数据的16个示例读段的数据的HMM映射。所述映射用于估计酶在酶控制的易位阶段期间的速度。在120mV时,酶的中值速度为319碱基对/秒;在140mV时为259碱基对/秒;并且在160mV时为196碱基对/秒。数据证明,所施加的电位的增加可以用于将酶的速度降低到理论上为零。
实例8
此实例展示了来自易位(3'-5')穿过纳米孔的DNA的最初的无酶部分的信号的持续时间可以如何用于在双链DNA分子被完全表征之前仅基于捕获/进入阶段的持续时间来估计其一条链的大小。
Y衔接子是通过粘接DNA寡核苷酸(SEQ ID NO:28、SEQ ID NO:33、SEQ ID NO:30和SEQ ID NO:32)来制备的。将DNA马达(Dda解旋酶)加载到衔接子上。
通过PCR从噬菌体λ获得10kb片段。噬菌体λDNA(约48kb)和T4 DNA(约169kb)是从商业来源获得的。通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NEB))对这些双链分析物进行末端修复和dA加尾,以在每个片段的两端处产生3'dA突出端。使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB以及T4 DNA连接酶(NEB)将每个样品(单独地)与Y衔接子的dA加尾端连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物洗脱到10mM Tris-Cl、50mM NaCl(pH8.0)中,产生‘10kb文库’、‘λ文库’和‘T4文库’。
电测量结果是在来自牛津纳米孔技术公司的FLO-MIN106 MinION流通池和MinIONMk1b上获取的。向1170μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加30μL的FLT,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用类似于实例3中描述的定制脚本收集数据,其中捕获/测序电压为120mV。
图20a示出了实验示意图,类似于上文的实例5的实验示意图(图17c)。手动测量无酶捕获阶段作为开孔水平(A)与停靠水平(C)之间的带星号周期,在图20b,底图中更详细地示出。捕获阶段可通过其独特的噪声和中值电流水平特性来辨别。还测量了酶介导的易位时间(E)。图20b示出了上文所描述的在单独的流通池上获取的三个文库中的每个文库的代表性电流-时间迹线。例如,10kb文库的无酶捕获持续时间为1.6秒,并且酶介导的易位时间为35.3秒。尽管T4文库获得了长捕获,但没有记录全长实例,这可能是由于在链中遇到缺口的可能性增加。图20c示出了捕获持续时间(A至C)的对数相对于酶介导的易位持续时间的对数的绘图。从31个实例中,获得了线性相关性(R2=0.74),证实了可以在解码其序列之前使用此方法估计链的大小。
实例9
此实例证明了如何使用具有不同二硫键闭合连接子长度的马达蛋白多次重新读取天然DNA分析物。
带有含有30个C3间隔子单元的前导臂的Y衔接子是通过粘接具有序列SEQ ID NO:67、SEQ ID NO:68、SEQ ID NO:69和SEQ ID NO:70的四个DNA寡核苷酸来制备的。将DNA马达(Dda解旋酶)加载到每个衔接子上,并且二硫化物通过与以下连接子之一反应来闭合:二酰胺(TMAD)、BMOE(1,2-双马来酰亚胺乙烷)、BMOP(1,3-双马来酰亚胺丙烷)、BMB(1,4-双马来酰亚胺基丁烷)、BM(PEG)
使用Qiagen基因组尖端试剂盒从大肠杆菌细胞中提取大肠杆菌K12 PCR DNA,使用Covaris gTube剪切至约10kb截止值,使用Ultra II末端修复和dA加尾试剂盒(新英格兰生物实验室)进行末端修复和dA加尾,与PCR衔接子(PCA;牛津纳米孔技术公司)连接,并且使用LongAmp Taq进行PCR扩增。通过NEBNext末端修复和NEBNext dA加尾模块(新英格兰生物实验室(NEB))对所得双链分析物进行末端修复和dA加尾,以在每个片段的两端处产生3'dA突出端。使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LNB以及T4 DNA连接酶将样品与Y衔接子的T突出端连接。使用Agencourt AMPure XP(贝克曼库尔特公司)珠粒纯化样品,并且使用来自牛津纳米孔技术公司测序试剂盒(LSK-SQK109)的LFB进行两次洗涤。将连接的底物从同一试剂盒中洗脱到洗脱缓冲液(EB)中,从而产生‘DNA文库’。如上文所描述,使用携带用二硫键连接子闭合的Dda解旋酶的衔接子分别制备DNA文库。
电测量结果是在其中插入了CsgG纳米孔的定制MinION流通池和来自牛津纳米孔技术公司的MinION Mk1b上获取的。向1170μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加30μL的FLT,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用类似于实例3中描述的定制脚本收集数据,其中捕获/测序电压为180mV,除了当检测到酶停靠水平时,通过使通道断开连接5秒将电压切换为零来使马达蛋白解停靠。主动解锁被设置为在识别与末端C3水平、链、开孔和酶停靠水平无关的阻断水平时触发。
在C3水平之后立即发生的来自单通道数据的链水平事件(“C3”,如图18b中标记)被评分为潜在的重新读段(例如,“ii”,如图18b中标记)。这些重新读段通过碱基调用和将重新读段的序列与原始读段的序列进行比较来确认(例如,“i”,如图18b中标记的),其发生在开孔和解停靠事件之后,如实例6中所描述。处于相同读段朝向且在原始读段范围内的事件被归类为重新读段。重新读取效率通过两种方式定量:(i)在到达C3前导的30秒内回落和重新读取的读段的比例,和(ii)回落距离,即重新读段的长度,即酶从C3前导推动返回的距离。
下表示出了此实验的结果。结果证明了所有测试的连接子的重新读取,并且显示连接子长度的增加使得在到达C3前导的30秒内伴随重新读取的读段比例增加。
实例10
此实例展示了可以如何使用具有前导的不同序列的衔接子多次重新读取天然DNA分析物,所述衔接子在经测序的链的3'端遇到Dda解旋酶。
带有含有RNA或C3前导化学的前导臂的Y衔接子是通过粘接具有序列SEQ ID NO:67、SEQ ID NO:68和SEQ ID NO:69的四个DNA寡核苷酸以及选自SEQ ID NO:70、SEQ ID NO:71和SEQ ID NO:72的前导寡核苷酸制备的。将DNA马达(Dda解旋酶)加载到每个衔接子上,并且二硫化物通过与1,2-双马来酰亚胺乙烷(BMOE)反应闭合。
通过将上述Y衔接子与如实例9中所描述制备的大肠杆菌DNA连接来制备DNA文库。
电测量结果是在其中插入了CsgG纳米孔的定制MinION流通池和来自牛津纳米孔技术公司的MinION Mk1b上获取的。向1170μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加30μL的FLT,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用类似于实例3中描述的定制脚本收集数据,其中捕获/测序电压为180mV,除了当检测到酶停靠水平时,通过使通道断开连接5秒将电压切换为零来使马达蛋白解停靠。主动解锁被设置为在识别与末端C3水平、链、开孔或酶停靠水平无关的阻断水平时触发。
根据实例9对重新读取事件进行评分,但有一些例外:在前导含有RNA的情况下,重新读取从链水平发生。
下表示出了此实验的结果。结果证明用所有测试的前导寡核苷酸进行重新读取,并显示当使用前导寡核苷酸SEQ ID NO:72时获得了最佳重新读取效率,如这通过重新读取之间的中值时间减少来判断。
实例11
此实例展示了可以如何在多种不同的测序运行温度下多次重新读取天然DNA分析物。
带有含有C3前导化学的前导臂的Y衔接子是通过粘接具有序列SEQ ID NO:67、SEQID NO:68、SEQ ID NO:69和SEQ ID NO:70的四个DNA寡核苷酸来制备的。将DNA马达(Dda解旋酶)加载到衔接子上,并且二硫化物通过与1,2-双马来酰亚胺乙烷(BMOE)反应闭合。
通过将上述Y衔接子与如实例9中所描述制备的大肠杆菌DNA连接来制备DNA文库。
电测量结果是在其中插入了CsgG纳米孔的定制MinION流通池和来自牛津纳米孔技术公司的MinION Mk1b上获取的。向1170μL FB(来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109))中添加30μL的FLT,产生系链混合物。将800μL系链混合物流过系统,然后等待5分钟,然后在SpotON端口打开的情况下再流过另外200μL系链混合物。将来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的37.5μL SQB、15μL DNA文库和来自牛津纳米孔技术公司测序试剂盒(SQK-LSK109)的22.5μL LB混合,产生“测序混合物”。通过SpotON流通池端口将75μL测序混合物添加到MinION流通池中。
使用类似于实例3中描述的定制脚本收集数据,其中捕获/测序电压为180mV,除了当检测到酶停靠水平时,通过使通道断开连接5秒将电压切换为零来使马达蛋白解停靠。主动解锁被设置为在识别与末端C3水平、链、开孔或酶停靠水平无关的阻断水平时触发。根据实例9对重新读取事件进行评分。
下表示出了此实验的结果。结果证明在所有测试温度下进行重新读取,并显示重新读取效率随着温度增加而增加,如通过在到达C3前导的30秒内重新读取的读段比例的增加以及中值回落距离来判断的。
序列表说明
SEQ ID NO:1示出了来自大肠杆菌的(六组氨酸标记的)核酸外切酶I(EcoExo I)的氨基酸序列。
SEQ ID NO:2示出了来自大肠杆菌的核酸外切酶III酶的氨基酸序列。
SEQ ID NO:3示出了来自嗜热栖热菌的RecJ酶(TthRecJ-cd)的氨基酸序列。
SEQ ID NO:4示出了噬菌体λ核酸外切酶的氨基酸序列。所述序列是组装成三聚体的三个完全相同亚基中的之一。(http://www.neb.com/nebecomm/products/productM0262.asp)。
SEQ ID NO:5示出了来自枯草芽孢杆菌(Bacillus subtilis)噬菌体Phi29的Phi29 DNA聚合酶的氨基酸序列。
SEQ ID NO:6示出了Trwc Cba(深洋柠檬色微菌(Citromicrobiumbathyomarinum))解旋酶的氨基酸序列。
SEQ ID NO:7示出了Hel308 Mbu(布氏拟甲烷球菌(Methanococcoidesburtonii))解旋酶的氨基酸序列。
SEQ ID NO:8示出了来自肠杆菌噬菌体T4的Dda解旋酶1993的氨基酸序列。
SEQ ID NO:20-33示出了实例中讨论的DNA链的核苷酸序列。
SEQ ID NO:40示出了优选的HhH结构域的氨基酸序列。
SEQ ID NO:41示出了来自噬菌体RB69的ssb的由gp32基因编码的氨基酸序列。
SEQ ID NO:42示出了来自噬菌体T7的ssb的由gp2.5基因编码的氨基酸序列。
SEQ ID NO:43示出了来自疱疹病毒1的UL42进行性因子的氨基酸序列。
SEQ ID NO:44示出了PCNA的亚基1的氨基酸序列。
SEQ ID NO:45示出了PCNA的亚基2的氨基酸序列。
SEQ ID NO:46示出了PCNA的亚基3的氨基酸序列。
SEQ ID NO:47示出了来自疱疹病毒1的UL42进行性因子的氨基酸序列(1至319)。
SEQ ID NO:48示出了(HhH)2结构域的氨基酸序列。
SEQ ID NO:49示出了(HhH)2-(HhH)2结构域的氨基酸序列。
SEQ ID NO:50示出了人线粒体SSB(HsmtSSB)的氨基酸序列。
SEQ ID NO:51示出了来自Phi29 DNA聚合酶的p5蛋白的氨基酸序列。
SEQ ID NO:52示出了来自大肠杆菌的野生型SSB的氨基酸序列。
SEQ ID NO:53示出了来自噬菌体T4的ssb的由gp32基因编码的氨基酸序列。
SEQ ID NO:54示出了拓扑异构酶V Mka(坎德勒氏甲烷嗜热菌)的氨基酸序列。
SEQ ID NO:55示出了拓扑异构酶V Mka(坎德勒氏甲烷嗜热菌)的结构域H-L的氨基酸序列。
SEQ ID NO:56示出了突变体S(大肠杆菌)的氨基酸序列。
SEQ ID NO:57示出了Sso7d(硫磺矿硫化叶菌)的氨基酸序列。
SEQ ID NO:58示出了Sso10b1(硫磺矿硫化叶菌P2)的氨基酸序列。
SEQ ID NO:59示出了Sso10b2(硫磺矿硫化叶菌P2)的氨基酸序列。
SEQ ID NO:60示出了色氨酸阻遏物(大肠杆菌)的氨基酸序列。
SEQ ID NO:61示出了λ阻遏物(肠杆菌噬菌体λ)的氨基酸序列。
SEQ ID NO:62示出了Cren7(组蛋白泉古菌Cren7 Sso)的氨基酸序列。
SEQ ID NO:63示出了人组蛋白(智人)的氨基酸序列。
SEQ ID NO:64示出了dsbA(肠杆菌噬菌体T4)的氨基酸序列。
SEQ ID NO:65示出了Rad51(智人)的氨基酸序列。
SEQ ID NO:66示出了PCNA滑动夹(深洋柠檬色微菌JL354)的氨基酸序列。
SEQ ID NO:67至72示出了实例9至11中所描述的寡核苷酸的多核苷酸序列。
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
/>
序列表
<110> 牛津纳米孔技术有限公司(OXFORD NANOPORE TECHNOLOGIES LIMITED)
<120> 表征移动穿过纳米孔的多核苷酸的方法
<130> N419290WO
<150> GB2107194.9
<151> 2021-05-19
<150> GB2009335.7
<151> 2020-06-18
<160> 72
<170> PatentIn 3.5版
<210> 1
<211> 485
<212> PRT
<213> 大肠杆菌(Escherichia coli)
<400> 1
Met Met Asn Asp Gly Lys Gln Gln Ser Thr Phe Leu Phe His Asp Tyr
1 5 1015
Glu Thr Phe Gly Thr His Pro Ala Leu Asp Arg Pro Ala Gln Phe Ala
202530
Ala Ile Arg Thr Asp Ser Glu Phe Asn Val Ile Gly Glu Pro Glu Val
354045
Phe Tyr Cys Lys Pro Ala Asp Asp Tyr Leu Pro Gln Pro Gly Ala Val
505560
Leu Ile Thr Gly Ile Thr Pro Gln Glu Ala Arg Ala Lys Gly Glu Asn
65707580
Glu Ala Ala Phe Ala Ala Arg Ile His Ser Leu Phe Thr Val Pro Lys
859095
Thr Cys Ile Leu Gly Tyr Asn Asn Val Arg Phe Asp Asp Glu Val Thr
100 105 110
Arg Asn Ile Phe Tyr Arg Asn Phe Tyr Asp Pro Tyr Ala Trp Ser Trp
115 120 125
Gln His Asp Asn Ser Arg Trp Asp Leu Leu Asp Val Met Arg Ala Cys
130 135 140
Tyr Ala Leu Arg Pro Glu Gly Ile Asn Trp Pro Glu Asn Asp Asp Gly
145 150 155 160
Leu Pro Ser Phe Arg Leu Glu His Leu Thr Lys Ala Asn Gly Ile Glu
165 170 175
His Ser Asn Ala His Asp Ala Met Ala Asp Val Tyr Ala Thr Ile Ala
180 185 190
Met Ala Lys Leu Val Lys Thr Arg Gln Pro Arg Leu Phe Asp Tyr Leu
195 200 205
Phe Thr His Arg Asn Lys His Lys Leu Met Ala Leu Ile Asp Val Pro
210 215 220
Gln Met Lys Pro Leu Val His Val Ser Gly Met Phe Gly Ala Trp Arg
225 230 235 240
Gly Asn Thr Ser Trp Val Ala Pro Leu Ala Trp His Pro Glu Asn Arg
245 250 255
Asn Ala Val Ile Met Val Asp Leu Ala Gly Asp Ile Ser Pro Leu Leu
260 265 270
Glu Leu Asp Ser Asp Thr Leu Arg Glu Arg Leu Tyr Thr Ala Lys Thr
275 280 285
Asp Leu Gly Asp Asn Ala Ala Val Pro Val Lys Leu Val His Ile Asn
290 295 300
Lys Cys Pro Val Leu Ala Gln Ala Asn Thr Leu Arg Pro Glu Asp Ala
305 310 315 320
Asp Arg Leu Gly Ile Asn Arg Gln His Cys Leu Asp Asn Leu Lys Ile
325 330 335
Leu Arg Glu Asn Pro Gln Val Arg Glu Lys Val Val Ala Ile Phe Ala
340 345 350
Glu Ala Glu Pro Phe Thr Pro Ser Asp Asn Val Asp Ala Gln Leu Tyr
355 360 365
Asn Gly Phe Phe Ser Asp Ala Asp Arg Ala Ala Met Lys Ile Val Leu
370 375 380
Glu Thr Glu Pro Arg Asn Leu Pro Ala Leu Asp Ile Thr Phe Val Asp
385 390 395 400
Lys Arg Ile Glu Lys Leu Leu Phe Asn Tyr Arg Ala Arg Asn Phe Pro
405 410 415
Gly Thr Leu Asp Tyr Ala Glu Gln Gln Arg Trp Leu Glu His Arg Arg
420 425 430
Gln Val Phe Thr Pro Glu Phe Leu Gln Gly Tyr Ala Asp Glu Leu Gln
435 440 445
Met Leu Val Gln Gln Tyr Ala Asp Asp Lys Glu Lys Val Ala Leu Leu
450 455 460
Lys Ala Leu Trp Gln Tyr Ala Glu Glu Ile Val Ser Gly Ser Gly His
465 470 475 480
His His His His His
485
<210> 2
<211> 268
<212> PRT
<213> 大肠杆菌(Escherichia coli)
<400> 2
Met Lys Phe Val Ser Phe Asn Ile Asn Gly Leu Arg Ala Arg Pro His
1 5 1015
Gln Leu Glu Ala Ile Val Glu Lys His Gln Pro Asp Val Ile Gly Leu
202530
Gln Glu Thr Lys Val His Asp Asp Met Phe Pro Leu Glu Glu Val Ala
354045
Lys Leu Gly Tyr Asn Val Phe Tyr His Gly Gln Lys Gly His Tyr Gly
505560
Val Ala Leu Leu Thr Lys Glu Thr Pro Ile Ala Val Arg Arg Gly Phe
65707580
Pro Gly Asp Asp Glu Glu Ala Gln Arg Arg Ile Ile Met Ala Glu Ile
859095
Pro Ser Leu Leu Gly Asn Val Thr Val Ile Asn Gly Tyr Phe Pro Gln
100 105 110
Gly Glu Ser Arg Asp His Pro Ile Lys Phe Pro Ala Lys Ala Gln Phe
115 120 125
Tyr Gln Asn Leu Gln Asn Tyr Leu Glu Thr Glu Leu Lys Arg Asp Asn
130 135 140
Pro Val Leu Ile Met Gly Asp Met Asn Ile Ser Pro Thr Asp Leu Asp
145 150 155 160
Ile Gly Ile Gly Glu Glu Asn Arg Lys Arg Trp Leu Arg Thr Gly Lys
165 170 175
Cys Ser Phe Leu Pro Glu Glu Arg Glu Trp Met Asp Arg Leu Met Ser
180 185 190
Trp Gly Leu Val Asp Thr Phe Arg His Ala Asn Pro Gln Thr Ala Asp
195 200 205
Arg Phe Ser Trp Phe Asp Tyr Arg Ser Lys Gly Phe Asp Asp Asn Arg
210 215 220
Gly Leu Arg Ile Asp Leu Leu Leu Ala Ser Gln Pro Leu Ala Glu Cys
225 230 235 240
Cys Val Glu Thr Gly Ile Asp Tyr Glu Ile Arg Ser Met Glu Lys Pro
245 250 255
Ser Asp His Ala Pro Val Trp Ala Thr Phe Arg Arg
260 265
<210> 3
<211> 425
<212> PRT
<213> 嗜热栖热菌(Thermus thermophilus)
<400> 3
Met Phe Arg Arg Lys Glu Asp Leu Asp Pro Pro Leu Ala Leu Leu Pro
1 5 1015
Leu Lys Gly Leu Arg Glu Ala Ala Ala Leu Leu Glu Glu Ala Leu Arg
202530
Gln Gly Lys Arg Ile Arg Val His Gly Asp Tyr Asp Ala Asp Gly Leu
354045
Thr Gly Thr Ala Ile Leu Val Arg Gly Leu Ala Ala Leu Gly Ala Asp
505560
Val His Pro Phe Ile Pro His Arg Leu Glu Glu Gly Tyr Gly Val Leu
65707580
Met Glu Arg Val Pro Glu His Leu Glu Ala Ser Asp Leu Phe Leu Thr
859095
Val Asp Cys Gly Ile Thr Asn His Ala Glu Leu Arg Glu Leu Leu Glu
100 105 110
Asn Gly Val Glu Val Ile Val Thr Asp His His Thr Pro Gly Lys Thr
115 120 125
Pro Pro Pro Gly Leu Val Val His Pro Ala Leu Thr Pro Asp Leu Lys
130 135 140
Glu Lys Pro Thr Gly Ala Gly Val Ala Phe Leu Leu Leu Trp Ala Leu
145 150 155 160
His Glu Arg Leu Gly Leu Pro Pro Pro Leu Glu Tyr Ala Asp Leu Ala
165 170 175
Ala Val Gly Thr Ile Ala Asp Val Ala Pro Leu Trp Gly Trp Asn Arg
180 185 190
Ala Leu Val Lys Glu Gly Leu Ala Arg Ile Pro Ala Ser Ser Trp Val
195 200 205
Gly Leu Arg Leu Leu Ala Glu Ala Val Gly Tyr Thr Gly Lys Ala Val
210 215 220
Glu Val Ala Phe Arg Ile Ala Pro Arg Ile Asn Ala Ala Ser Arg Leu
225 230 235 240
Gly Glu Ala Glu Lys Ala Leu Arg Leu Leu Leu Thr Asp Asp Ala Ala
245 250 255
Glu Ala Gln Ala Leu Val Gly Glu Leu His Arg Leu Asn Ala Arg Arg
260 265 270
Gln Thr Leu Glu Glu Ala Met Leu Arg Lys Leu Leu Pro Gln Ala Asp
275 280 285
Pro Glu Ala Lys Ala Ile Val Leu Leu Asp Pro Glu Gly His Pro Gly
290 295 300
Val Met Gly Ile Val Ala Ser Arg Ile Leu Glu Ala Thr Leu Arg Pro
305 310 315 320
Val Phe Leu Val Ala Gln Gly Lys Gly Thr Val Arg Ser Leu Ala Pro
325 330 335
Ile Ser Ala Val Glu Ala Leu Arg Ser Ala Glu Asp Leu Leu Leu Arg
340 345 350
Tyr Gly Gly His Lys Glu Ala Ala Gly Phe Ala Met Asp Glu Ala Leu
355 360 365
Phe Pro Ala Phe Lys Ala Arg Val Glu Ala Tyr Ala Ala Arg Phe Pro
370 375 380
Asp Pro Val Arg Glu Val Ala Leu Leu Asp Leu Leu Pro Glu Pro Gly
385 390 395 400
Leu Leu Pro Gln Val Phe Arg Glu Leu Ala Leu Leu Glu Pro Tyr Gly
405 410 415
Glu Gly Asn Pro Glu Pro Leu Phe Leu
420 425
<210> 4
<211> 226
<212> PRT
<213> 噬菌体λ(Bacteriophage lambda)
<400> 4
Met Thr Pro Asp Ile Ile Leu Gln Arg Thr Gly Ile Asp Val Arg Ala
1 5 1015
Val Glu Gln Gly Asp Asp Ala Trp His Lys Leu Arg Leu Gly Val Ile
202530
Thr Ala Ser Glu Val His Asn Val Ile Ala Lys Pro Arg Ser Gly Lys
354045
Lys Trp Pro Asp Met Lys Met Ser Tyr Phe His Thr Leu Leu Ala Glu
505560
Val Cys Thr Gly Val Ala Pro Glu Val Asn Ala Lys Ala Leu Ala Trp
65707580
Gly Lys Gln Tyr Glu Asn Asp Ala Arg Thr Leu Phe Glu Phe Thr Ser
859095
Gly Val Asn Val Thr Glu Ser Pro Ile Ile Tyr Arg Asp Glu Ser Met
100 105 110
Arg Thr Ala Cys Ser Pro Asp Gly Leu Cys Ser Asp Gly Asn Gly Leu
115 120 125
Glu Leu Lys Cys Pro Phe Thr Ser Arg Asp Phe Met Lys Phe Arg Leu
130 135 140
Gly Gly Phe Glu Ala Ile Lys Ser Ala Tyr Met Ala Gln Val Gln Tyr
145 150 155 160
Ser Met Trp Val Thr Arg Lys Asn Ala Trp Tyr Phe Ala Asn Tyr Asp
165 170 175
Pro Arg Met Lys Arg Glu Gly Leu His Tyr Val Val Ile Glu Arg Asp
180 185 190
Glu Lys Tyr Met Ala Ser Phe Asp Glu Ile Val Pro Glu Phe Ile Glu
195 200 205
Lys Met Asp Glu Ala Leu Ala Glu Ile Gly Phe Val Phe Gly Glu Gln
210 215 220
Trp Arg
225
<210> 5
<211> 608
<212> PRT
<213> 枯草芽孢杆菌(Bacillus subtilis)
<400> 5
Met Lys His Met Pro Arg Lys Met Tyr Ser Cys Ala Phe Glu Thr Thr
1 5 1015
Thr Lys Val Glu Asp Cys Arg Val Trp Ala Tyr Gly Tyr Met Asn Ile
202530
Glu Asp His Ser Glu Tyr Lys Ile Gly Asn Ser Leu Asp Glu Phe Met
354045
Ala Trp Val Leu Lys Val Gln Ala Asp Leu Tyr Phe His Asn Leu Lys
505560
Phe Asp Gly Ala Phe Ile Ile Asn Trp Leu Glu Arg Asn Gly Phe Lys
65707580
Trp Ser Ala Asp Gly Leu Pro Asn Thr Tyr Asn Thr Ile Ile Ser Arg
859095
Met Gly Gln Trp Tyr Met Ile Asp Ile Cys Leu Gly Tyr Lys Gly Lys
100 105 110
Arg Lys Ile His Thr Val Ile Tyr Asp Ser Leu Lys Lys Leu Pro Phe
115 120 125
Pro Val Lys Lys Ile Ala Lys Asp Phe Lys Leu Thr Val Leu Lys Gly
130 135 140
Asp Ile Asp Tyr His Lys Glu Arg Pro Val Gly Tyr Lys Ile Thr Pro
145 150 155 160
Glu Glu Tyr Ala Tyr Ile Lys Asn Asp Ile Gln Ile Ile Ala Glu Ala
165 170 175
Leu Leu Ile Gln Phe Lys Gln Gly Leu Asp Arg Met Thr Ala Gly Ser
180 185 190
Asp Ser Leu Lys Gly Phe Lys Asp Ile Ile Thr Thr Lys Lys Phe Lys
195 200 205
Lys Val Phe Pro Thr Leu Ser Leu Gly Leu Asp Lys Glu Val Arg Tyr
210 215 220
Ala Tyr Arg Gly Gly Phe Thr Trp Leu Asn Asp Arg Phe Lys Glu Lys
225 230 235 240
Glu Ile Gly Glu Gly Met Val Phe Asp Val Asn Ser Leu Tyr Pro Ala
245 250 255
Gln Met Tyr Ser Arg Leu Leu Pro Tyr Gly Glu Pro Ile Val Phe Glu
260 265 270
Gly Lys Tyr Val Trp Asp Glu Asp Tyr Pro Leu His Ile Gln His Ile
275 280 285
Arg Cys Glu Phe Glu Leu Lys Glu Gly Tyr Ile Pro Thr Ile Gln Ile
290 295 300
Lys Arg Ser Arg Phe Tyr Lys Gly Asn Glu Tyr Leu Lys Ser Ser Gly
305 310 315 320
Gly Glu Ile Ala Asp Leu Trp Leu Ser Asn Val Asp Leu Glu Leu Met
325 330 335
Lys Glu His Tyr Asp Leu Tyr Asn Val Glu Tyr Ile Ser Gly Leu Lys
340 345 350
Phe Lys Ala Thr Thr Gly Leu Phe Lys Asp Phe Ile Asp Lys Trp Thr
355 360 365
Tyr Ile Lys Thr Thr Ser Glu Gly Ala Ile Lys Gln Leu Ala Lys Leu
370 375 380
Met Leu Asn Ser Leu Tyr Gly Lys Phe Ala Ser Asn Pro Asp Val Thr
385 390 395 400
Gly Lys Val Pro Tyr Leu Lys Glu Asn Gly Ala Leu Gly Phe Arg Leu
405 410 415
Gly Glu Glu Glu Thr Lys Asp Pro Val Tyr Thr Pro Met Gly Val Phe
420 425 430
Ile Thr Ala Trp Ala Arg Tyr Thr Thr Ile Thr Ala Ala Gln Ala Cys
435 440 445
Tyr Asp Arg Ile Ile Tyr Cys Asp Thr Asp Ser Ile His Leu Thr Gly
450 455 460
Thr Glu Ile Pro Asp Val Ile Lys Asp Ile Val Asp Pro Lys Lys Leu
465 470 475 480
Gly Tyr Trp Ala His Glu Ser Thr Phe Lys Arg Ala Lys Tyr Leu Arg
485 490 495
Gln Lys Thr Tyr Ile Gln Asp Ile Tyr Met Lys Glu Val Asp Gly Lys
500 505 510
Leu Val Glu Gly Ser Pro Asp Asp Tyr Thr Asp Ile Lys Phe Ser Val
515 520 525
Lys Cys Ala Gly Met Thr Asp Lys Ile Lys Lys Glu Val Thr Phe Glu
530 535 540
Asn Phe Lys Val Gly Phe Ser Arg Lys Met Lys Pro Lys Pro Val Gln
545 550 555 560
Val Pro Gly Gly Val Val Leu Val Asp Asp Thr Phe Thr Ile Lys Ser
565 570 575
Gly Gly Ser Ala Trp Ser His Pro Gln Phe Glu Lys Gly Gly Gly Ser
580 585 590
Gly Gly Gly Ser Gly Gly Ser Ala Trp Ser His Pro Gln Phe Glu Lys
595 600 605
<210> 6
<211> 970
<212> PRT
<213> 深洋柠檬色微菌(Citromicrobium bathyomarinum)
<400> 6
Met Leu Ser Val Ala Asn Val Arg Ser Pro Ser Ala Ala Ala Ser Tyr
1 5 1015
Phe Ala Ser Asp Asn Tyr Tyr Ala Ser Ala Asp Ala Asp Arg Ser Gly
202530
Gln Trp Ile Gly Asp Gly Ala Lys Arg Leu Gly Leu Glu Gly Lys Val
354045
Glu Ala Arg Ala Phe Asp Ala Leu Leu Arg Gly Glu Leu Pro Asp Gly
505560
Ser Ser Val Gly Asn Pro Gly Gln Ala His Arg Pro Gly Thr Asp Leu
65707580
Thr Phe Ser Val Pro Lys Ser Trp Ser Leu Leu Ala Leu Val Gly Lys
859095
Asp Glu Arg Ile Ile Ala Ala Tyr Arg Glu Ala Val Val Glu Ala Leu
100 105 110
His Trp Ala Glu Lys Asn Ala Ala Glu Thr Arg Val Val Glu Lys Gly
115 120 125
Met Val Val Thr Gln Ala Thr Gly Asn Leu Ala Ile Gly Leu Phe Gln
130 135 140
His Asp Thr Asn Arg Asn Gln Glu Pro Asn Leu His Phe His Ala Val
145 150 155 160
Ile Ala Asn Val Thr Gln Gly Lys Asp Gly Lys Trp Arg Thr Leu Lys
165 170 175
Asn Asp Arg Leu Trp Gln Leu Asn Thr Thr Leu Asn Ser Ile Ala Met
180 185 190
Ala Arg Phe Arg Val Ala Val Glu Lys Leu Gly Tyr Glu Pro Gly Pro
195 200 205
Val Leu Lys His Gly Asn Phe Glu Ala Arg Gly Ile Ser Arg Glu Gln
210 215 220
Val Met Ala Phe Ser Thr Arg Arg Lys Glu Val Leu Glu Ala Arg Arg
225 230 235 240
Gly Pro Gly Leu Asp Ala Gly Arg Ile Ala Ala Leu Asp Thr Arg Ala
245 250 255
Ser Lys Glu Gly Ile Glu Asp Arg Ala Thr Leu Ser Lys Gln Trp Ser
260 265 270
Glu Ala Ala Gln Ser Ile Gly Leu Asp Leu Lys Pro Leu Val Asp Arg
275 280 285
Ala Arg Thr Lys Ala Leu Gly Gln Gly Met Glu Ala Thr Arg Ile Gly
290 295 300
Ser Leu Val Glu Arg Gly Arg Ala Trp Leu Ser Arg Phe Ala Ala His
305 310 315 320
Val Arg Gly Asp Pro Ala Asp Pro Leu Val Pro Pro Ser Val Leu Lys
325 330 335
Gln Asp Arg Gln Thr Ile Ala Ala Ala Gln Ala Val Ala Ser Ala Val
340 345 350
Arg His Leu Ser Gln Arg Glu Ala Ala Phe Glu Arg Thr Ala Leu Tyr
355 360 365
Lys Ala Ala Leu Asp Phe Gly Leu Pro Thr Thr Ile Ala Asp Val Glu
370 375 380
Lys Arg Thr Arg Ala Leu Val Arg Ser Gly Asp Leu Ile Ala Gly Lys
385 390 395 400
Gly Glu His Lys Gly Trp Leu Ala Ser Arg Asp Ala Val Val Thr Glu
405 410 415
Gln Arg Ile Leu Ser Glu Val Ala Ala Gly Lys Gly Asp Ser Ser Pro
420 425 430
Ala Ile Thr Pro Gln Lys Ala Ala Ala Ser Val Gln Ala Ala Ala Leu
435 440 445
Thr Gly Gln Gly Phe Arg Leu Asn Glu Gly Gln Leu Ala Ala Ala Arg
450 455 460
Leu Ile Leu Ile Ser Lys Asp Arg Thr Ile Ala Val Gln Gly Ile Ala
465 470 475 480
Gly Ala Gly Lys Ser Ser Val Leu Lys Pro Val Ala Glu Val Leu Arg
485 490 495
Asp Glu Gly His Pro Val Ile Gly Leu Ala Ile Gln Asn Thr Leu Val
500 505 510
Gln Met Leu Glu Arg Asp Thr Gly Ile Gly Ser Gln Thr Leu Ala Arg
515 520 525
Phe Leu Gly Gly Trp Asn Lys Leu Leu Asp Asp Pro Gly Asn Val Ala
530 535 540
Leu Arg Ala Glu Ala Gln Ala Ser Leu Lys Asp His Val Leu Val Leu
545 550 555 560
Asp Glu Ala Ser Met Val Ser Asn Glu Asp Lys Glu Lys Leu Val Arg
565 570 575
Leu Ala Asn Leu Ala Gly Val His Arg Leu Val Leu Ile Gly Asp Arg
580 585 590
Lys Gln Leu Gly Ala Val Asp Ala Gly Lys Pro Phe Ala Leu Leu Gln
595 600 605
Arg Ala Gly Ile Ala Arg Ala Glu Met Ala Thr Asn Leu Arg Ala Arg
610 615 620
Asp Pro Val Val Arg Glu Ala Gln Ala Ala Ala Gln Ala Gly Asp Val
625 630 635 640
Arg Lys Ala Leu Arg His Leu Lys Ser His Thr Val Glu Ala Arg Gly
645 650 655
Asp Gly Ala Gln Val Ala Ala Glu Thr Trp Leu Ala Leu Asp Lys Glu
660 665 670
Thr Arg Ala Arg Thr Ser Ile Tyr Ala Ser Gly Arg Ala Ile Arg Ser
675 680 685
Ala Val Asn Ala Ala Val Gln Gln Gly Leu Leu Ala Ser Arg Glu Ile
690 695 700
Gly Pro Ala Lys Met Lys Leu Glu Val Leu Asp Arg Val Asn Thr Thr
705 710 715 720
Arg Glu Glu Leu Arg His Leu Pro Ala Tyr Arg Ala Gly Arg Val Leu
725 730 735
Glu Val Ser Arg Lys Gln Gln Ala Leu Gly Leu Phe Ile Gly Glu Tyr
740 745 750
Arg Val Ile Gly Gln Asp Arg Lys Gly Lys Leu Val Glu Val Glu Asp
755 760 765
Lys Arg Gly Lys Arg Phe Arg Phe Asp Pro Ala Arg Ile Arg Ala Gly
770 775 780
Lys Gly Asp Asp Asn Leu Thr Leu Leu Glu Pro Arg Lys Leu Glu Ile
785 790 795 800
His Glu Gly Asp Arg Ile Arg Trp Thr Arg Asn Asp His Arg Arg Gly
805 810 815
Leu Phe Asn Ala Asp Gln Ala Arg Val Val Glu Ile Ala Asn Gly Lys
820 825 830
Val Thr Phe Glu Thr Ser Lys Gly Asp Leu Val Glu Leu Lys Lys Asp
835 840 845
Asp Pro Met Leu Lys Arg Ile Asp Leu Ala Tyr Ala Leu Asn Val His
850 855 860
Met Ala Gln Gly Leu Thr Ser Asp Arg Gly Ile Ala Val Met Asp Ser
865 870 875 880
Arg Glu Arg Asn Leu Ser Asn Gln Lys Thr Phe Leu Val Thr Val Thr
885 890 895
Arg Leu Arg Asp His Leu Thr Leu Val Val Asp Ser Ala Asp Lys Leu
900 905 910
Gly Ala Ala Val Ala Arg Asn Lys Gly Glu Lys Ala Ser Ala Ile Glu
915 920 925
Val Thr Gly Ser Val Lys Pro Thr Ala Thr Lys Gly Ser Gly Val Asp
930 935 940
Gln Pro Lys Ser Val Glu Ala Asn Lys Ala Glu Lys Glu Leu Thr Arg
945 950 955 960
Ser Lys Ser Lys Thr Leu Asp Phe Gly Ile
965 970
<210> 7
<211> 760
<212> PRT
<213> 布氏拟甲烷球菌(Methanococcoides burtonii)
<400> 7
Met Met Ile Arg Glu Leu Asp Ile Pro Arg Asp Ile Ile Gly Phe Tyr
1 5 1015
Glu Asp Ser Gly Ile Lys Glu Leu Tyr Pro Pro Gln Ala Glu Ala Ile
202530
Glu Met Gly Leu Leu Glu Lys Lys Asn Leu Leu Ala Ala Ile Pro Thr
354045
Ala Ser Gly Lys Thr Leu Leu Ala Glu Leu Ala Met Ile Lys Ala Ile
505560
Arg Glu Gly Gly Lys Ala Leu Tyr Ile Val Pro Leu Arg Ala Leu Ala
65707580
Ser Glu Lys Phe Glu Arg Phe Lys Glu Leu Ala Pro Phe Gly Ile Lys
859095
Val Gly Ile Ser Thr Gly Asp Leu Asp Ser Arg Ala Asp Trp Leu Gly
100 105 110
Val Asn Asp Ile Ile Val Ala Thr Ser Glu Lys Thr Asp Ser Leu Leu
115 120 125
Arg Asn Gly Thr Ser Trp Met Asp Glu Ile Thr Thr Val Val Val Asp
130 135 140
Glu Ile His Leu Leu Asp Ser Lys Asn Arg Gly Pro Thr Leu Glu Val
145 150 155 160
Thr Ile Thr Lys Leu Met Arg Leu Asn Pro Asp Val Gln Val Val Ala
165 170 175
Leu Ser Ala Thr Val Gly Asn Ala Arg Glu Met Ala Asp Trp Leu Gly
180 185 190
Ala Ala Leu Val Leu Ser Glu Trp Arg Pro Thr Asp Leu His Glu Gly
195 200 205
Val Leu Phe Gly Asp Ala Ile Asn Phe Pro Gly Ser Gln Lys Lys Ile
210 215 220
Asp Arg Leu Glu Lys Asp Asp Ala Val Asn Leu Val Leu Asp Thr Ile
225 230 235 240
Lys Ala Glu Gly Gln Cys Leu Val Phe Glu Ser Ser Arg Arg Asn Cys
245 250 255
Ala Gly Phe Ala Lys Thr Ala Ser Ser Lys Val Ala Lys Ile Leu Asp
260 265 270
Asn Asp Ile Met Ile Lys Leu Ala Gly Ile Ala Glu Glu Val Glu Ser
275 280 285
Thr Gly Glu Thr Asp Thr Ala Ile Val Leu Ala Asn Cys Ile Arg Lys
290 295 300
Gly Val Ala Phe His His Ala Gly Leu Asn Ser Asn His Arg Lys Leu
305 310 315 320
Val Glu Asn Gly Phe Arg Gln Asn Leu Ile Lys Val Ile Ser Ser Thr
325 330 335
Pro Thr Leu Ala Ala Gly Leu Asn Leu Pro Ala Arg Arg Val Ile Ile
340 345 350
Arg Ser Tyr Arg Arg Phe Asp Ser Asn Phe Gly Met Gln Pro Ile Pro
355 360 365
Val Leu Glu Tyr Lys Gln Met Ala Gly Arg Ala Gly Arg Pro His Leu
370 375 380
Asp Pro Tyr Gly Glu Ser Val Leu Leu Ala Lys Thr Tyr Asp Glu Phe
385 390 395 400
Ala Gln Leu Met Glu Asn Tyr Val Glu Ala Asp Ala Glu Asp Ile Trp
405 410 415
Ser Lys Leu Gly Thr Glu Asn Ala Leu Arg Thr His Val Leu Ser Thr
420 425 430
Ile Val Asn Gly Phe Ala Ser Thr Arg Gln Glu Leu Phe Asp Phe Phe
435 440 445
Gly Ala Thr Phe Phe Ala Tyr Gln Gln Asp Lys Trp Met Leu Glu Glu
450 455 460
Val Ile Asn Asp Cys Leu Glu Phe Leu Ile Asp Lys Ala Met Val Ser
465 470 475 480
Glu Thr Glu Asp Ile Glu Asp Ala Ser Lys Leu Phe Leu Arg Gly Thr
485 490 495
Arg Leu Gly Ser Leu Val Ser Met Leu Tyr Ile Asp Pro Leu Ser Gly
500 505 510
Ser Lys Ile Val Asp Gly Phe Lys Asp Ile Gly Lys Ser Thr Gly Gly
515 520 525
Asn Met Gly Ser Leu Glu Asp Asp Lys Gly Asp Asp Ile Thr Val Thr
530 535 540
Asp Met Thr Leu Leu His Leu Val Cys Ser Thr Pro Asp Met Arg Gln
545 550 555 560
Leu Tyr Leu Arg Asn Thr Asp Tyr Thr Ile Val Asn Glu Tyr Ile Val
565 570 575
Ala His Ser Asp Glu Phe His Glu Ile Pro Asp Lys Leu Lys Glu Thr
580 585 590
Asp Tyr Glu Trp Phe Met Gly Glu Val Lys Thr Ala Met Leu Leu Glu
595 600 605
Glu Trp Val Thr Glu Val Ser Ala Glu Asp Ile Thr Arg His Phe Asn
610 615 620
Val Gly Glu Gly Asp Ile His Ala Leu Ala Asp Thr Ser Glu Trp Leu
625 630 635 640
Met His Ala Ala Ala Lys Leu Ala Glu Leu Leu Gly Val Glu Tyr Ser
645 650 655
Ser His Ala Tyr Ser Leu Glu Lys Arg Ile Arg Tyr Gly Ser Gly Leu
660 665 670
Asp Leu Met Glu Leu Val Gly Ile Arg Gly Val Gly Arg Val Arg Ala
675 680 685
Arg Lys Leu Tyr Asn Ala Gly Phe Val Ser Val Ala Lys Leu Lys Gly
690 695 700
Ala Asp Ile Ser Val Leu Ser Lys Leu Val Gly Pro Lys Val Ala Tyr
705 710 715 720
Asn Ile Leu Ser Gly Ile Gly Val Arg Val Asn Asp Lys His Phe Asn
725 730 735
Ser Ala Pro Ile Ser Ser Asn Thr Leu Asp Thr Leu Leu Asp Lys Asn
740 745 750
Gln Lys Thr Phe Asn Asp Phe Gln
755 760
<210> 8
<211> 439
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> Dda解旋酶
<400> 8
Met Thr Phe Asp Asp Leu Thr Glu Gly Gln Lys Asn Ala Phe Asn Ile
1 5 1015
Val Met Lys Ala Ile Lys Glu Lys Lys His His Val Thr Ile Asn Gly
202530
Pro Ala Gly Thr Gly Lys Thr Thr Leu Thr Lys Phe Ile Ile Glu Ala
354045
Leu Ile Ser Thr Gly Glu Thr Gly Ile Ile Leu Ala Ala Pro Thr His
505560
Ala Ala Lys Lys Ile Leu Ser Lys Leu Ser Gly Lys Glu Ala Ser Thr
65707580
Ile His Ser Ile Leu Lys Ile Asn Pro Val Thr Tyr Glu Glu Asn Val
859095
Leu Phe Glu Gln Lys Glu Val Pro Asp Leu Ala Lys Cys Arg Val Leu
100 105 110
Ile Cys Asp Glu Val Ser Met Tyr Asp Arg Lys Leu Phe Lys Ile Leu
115 120 125
Leu Ser Thr Ile Pro Pro Trp Cys Thr Ile Ile Gly Ile Gly Asp Asn
130 135 140
Lys Gln Ile Arg Pro Val Asp Pro Gly Glu Asn Thr Ala Tyr Ile Ser
145 150 155 160
Pro Phe Phe Thr His Lys Asp Phe Tyr Gln Cys Glu Leu Thr Glu Val
165 170 175
Lys Arg Ser Asn Ala Pro Ile Ile Asp Val Ala Thr Asp Val Arg Asn
180 185 190
Gly Lys Trp Ile Tyr Asp Lys Val Val Asp Gly His Gly Val Arg Gly
195 200 205
Phe Thr Gly Asp Thr Ala Leu Arg Asp Phe Met Val Asn Tyr Phe Ser
210 215 220
Ile Val Lys Ser Leu Asp Asp Leu Phe Glu Asn Arg Val Met Ala Phe
225 230 235 240
Thr Asn Lys Ser Val Asp Lys Leu Asn Ser Ile Ile Arg Lys Lys Ile
245 250 255
Phe Glu Thr Asp Lys Asp Phe Ile Val Gly Glu Ile Ile Val Met Gln
260 265 270
Glu Pro Leu Phe Lys Thr Tyr Lys Ile Asp Gly Lys Pro Val Ser Glu
275 280 285
Ile Ile Phe Asn Asn Gly Gln Leu Val Arg Ile Ile Glu Ala Glu Tyr
290 295 300
Thr Ser Thr Phe Val Lys Ala Arg Gly Val Pro Gly Glu Tyr Leu Ile
305 310 315 320
Arg His Trp Asp Leu Thr Val Glu Thr Tyr Gly Asp Asp Glu Tyr Tyr
325 330 335
Arg Glu Lys Ile Lys Ile Ile Ser Ser Asp Glu Glu Leu Tyr Lys Phe
340 345 350
Asn Leu Phe Leu Gly Lys Thr Ala Glu Thr Tyr Lys Asn Trp Asn Lys
355 360 365
Gly Gly Lys Ala Pro Trp Ser Asp Phe Trp Asp Ala Lys Ser Gln Phe
370 375 380
Ser Lys Val Lys Ala Leu Pro Ala Ser Thr Phe His Lys Ala Gln Gly
385 390 395 400
Met Ser Val Asp Arg Ala Phe Ile Tyr Thr Pro Cys Ile His Tyr Ala
405 410 415
Asp Val Glu Leu Ala Gln Gln Leu Leu Tyr Val Gly Val Thr Arg Gly
420 425 430
Arg Tyr Asp Val Phe Tyr Val
435
<210> 9
<400> 9
000
<210> 10
<400> 10
000
<210> 11
<400> 11
000
<210> 12
<400> 12
000
<210> 13
<400> 13
000
<210> 14
<400> 14
000
<210> 15
<400> 15
000
<210> 16
<400> 16
000
<210> 17
<400> 17
000
<210> 18
<400> 18
000
<210> 19
<400> 19
000
<210> 20
<211> 3595
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 噬菌体λ片段
<400> 20
gccatcagat tgtgtttgtt agtcgctgcc atcagattgt gtttgttagt cgcttttttt 60
ttttggaatt ttttttttgg aatttttttt ttgcgctaac aacctcctgc cgttttgccc 120
gtgcatatcg gtcacgaaca aatctgatta ctaaacacag tagcctggat ttgttctatc 180
agtaatcgac cttattccta attaaataga gcaaatcccc ttattggggg taagacatga 240
agatgccaga aaaacatgac ctgttggccg ccattctcgc ggcaaaggaa caaggcatcg 300
gggcaatcct tgcgtttgca atggcgtacc ttcgcggcag atataatggc ggtgcgttta 360
caaaaacagt aatcgacgca acgatgtgcg ccattatcgc ctagttcatt cgtgaccttc 420
tcgacttcgc cggactaagt agcaatctcg cttatataac gagcgtgttt atcggctaca 480
tcggtactga ctcgattggt tcgcttatca aacgcttcgc tgctaaaaaa gccggagtag 540
aagatggtag aaatcaataa tcaacgtaag gcgttcctcg atatgctggc gtggtcggag 600
ggaactgata acggacgtca gaaaaccaga aatcatggtt atgacgtcat tgtaggcgga 660
gagctattta ctgattactc cgatcaccct cgcaaacttg tcacgctaaa cccaaaactc 720
aaatcaacag gcgccggacg ctaccagctt ctttcccgtt ggtgggatgc ctaccgcaag 780
cagcttggcc tgaaagactt ctctccgaaa agtcaggacg ctgtggcatt gcagcagatt 840
aaggagcgtg gcgctttacc tatgattgat cgtggtgata tccgtcaggc aatcgaccgt 900
tgcagcaata tctgggcttc actgccgggc gctggttatg gtcagttcga gcataaggct 960
gacagcctga ttgcaaaatt caaagaagcg ggcggaacgg tcagagagat tgatgtatga 1020
gcagagtcac cgcgattatc tccgctctgg ttatctgcat catcgtctgc ctgtcatggg 1080
ctgttaatca ttaccgtgat aacgccatta cctacaaagc ccagcgcgac aaaaatgcca 1140
gagaactgaa gctggcgaac gcggcaatta ctgacatgca gatgcgtcag cgtgatgttg 1200
ctgcgctcga tgcaaaatac acgaaggagt tagctgatgc taaagctgaa aatgatgctc 1260
tgcgtgatga tgttgccgct ggtcgtcgtc ggttgcacat caaagcagtc tgtcagtcag 1320
tgcgtgaagc caccaccgcc tccggcgtgg ataatgcagc ctccccccga ctggcagaca 1380
ccgctgaacg ggattatttc accctcagag agaggctgat cactatgcaa aaacaactgg 1440
aaggaaccca gaagtatatt aatgagcagt gcagatagag ttgcccatat cgatgggcaa 1500
ctcatgcaat tattgtgagc aatacacacg cgcttccagc ggagtataaa tgcctaaagt 1560
aataaaaccg agcaatccat ttacgaatgt ttgctgggtt tctgttttaa caacattttc 1620
tgcgccgcca caaattttgg ctgcatcgac agttttcttc tgcccaattc cagaaacgaa 1680
gaaatgatgg gtgatggttt cctttggtgc tactgctgcc ggtttgtttt gaacagtaaa 1740
cgtctgttga gcacatcctg taataagcag ggccagcgca gtagcgagta gcattttttt 1800
catggtgtta ttcccgatgc tttttgaagt tcgcagaatc gtatgtgtag aaaattaaac 1860
aaaccctaaa caatgagttg aaatttcata ttgttaatat ttattaatgt atgtcaggtg 1920
cgatgaatcg tcattgtatt cccggattaa ctatgtccac agccctgacg gggaacttct 1980
ctgcgggagt gtccgggaat aattaaaacg atgcacacag ggtttagcgc gtacacgtat 2040
tgcattatgc caacgccccg gtgctgacac ggaagaaacc ggacgttatg atttagcgtg 2100
gaaagatttg tgtagtgttc tgaatgctct cagtaaatag taatgaatta tcaaaggtat 2160
agtaatatct tttatgttca tggatatttg taacccatcg gaaaactcct gctttagcaa 2220
gattttccct gtattgctga aatgtgattt ctcttgattt caacctatca taggacgttt 2280
ctataagatg cgtgtttctt gagaatttaa catttacaac ctttttaagt ccttttatta 2340
acacggtgtt atcgttttct aacacgatgt gaatattatc tgtggctaga tagtaaatat 2400
aatgtgagac gttgtgacgt tttagttcag aataaaacaa ttcacagtct aaatcttttc 2460
gcacttgatc gaatatttct ttaaaaatgg caacctgagc cattggtaaa accttccatg 2520
tgatacgagg gcgcgtagtt tgcattatcg tttttatcgt ttcaatctgg tctgacctcc 2580
ttgtgttttg ttgatgattt atgtcaaata ttaggaatgt tttcacttaa tagtattggt 2640
tgcgtaacaa agtgcggtcc tgctggcatt ctggagggaa atacaaccga cagatgtatg 2700
taaggccaac gtgctcaaat cttcatacag aaagatttga agtaatattt taaccgctag 2760
atgaagagca agcgcatgga gcgacaaaat gaataaagaa caatctgctg atgatccctc 2820
cgtggatctg attcgtgtaa aaaatatgct taatagcacc atttctatga gttaccctga 2880
tgttgtaatt gcatgtatag aacataaggt gtctctggaa gcattcagag caattgaggc 2940
agcgttggtg aagcacgata ataatatgaa ggattattcc ctggtggttg actgatcacc 3000
ataactgcta atcattcaaa ctatttagtc tgtgacagag ccaacacgca gtctgtcact 3060
gtcaggaaag tggtaaaact gcaactcaat tactgcaatg ccctcgtaat taagtgaatt 3120
tacaatatcg tcctgttcgg agggaagaac gcgggatgtt cattcttcat cacttttaat 3180
tgatgtatat gctctctttt ctgacgttag tctccgacgg caggcttcaa tgacccaggc 3240
tgagaaattc ccggaccctt tttgctcaag agcgatgtta atttgttcaa tcatttggtt 3300
aggaaagcgg atgttgcggg ttgttgttct gcgggttctg ttcttcgttg acatgaggtt 3360
gccccgtatt cagtgtcgct gatttgtatt gtctgaagtt gtttttacgt taagttgatg 3420
cagatcaatt aatacgatac ctgcgtcata attgattatt tgacgtggtt tgatggcctc 3480
cacgcacgtt gtgatatgta gatgataatc attatcactt tacgggtcct ttccggtgaa 3540
aaaaaaggta ccaaaaaaaa catcgtcgtg agtagtgaac cgtaagcatg tagga 3595
<210> 21
<211> 38
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'生物素,通过TEG连接子
<220>
<221> misc_feature
<222> (10)..(11)
<223> iSp18
<400> 21
tttttttttt aatgtacttc gttcagttac gtattgct 38
<210> 22
<211> 65
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<220>
<221> misc_feature
<222> (23)..(23)
<223> 桥接核酸
<220>
<221> modified_base
<222> (24)..(24)
<223> m5c
<220>
<221> misc_feature
<222> (24)..(24)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (25)..(25)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (26)..(26)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> 桥接核酸
<400> 22
gcaatacgta actgaacgaa gtacattttt gaggcgagcg gtcaattttt tttttttttt 60
ttttt 65
<210> 23
<211> 60
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 发夹寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<400> 23
tgcaatacgt aactgaacga agtacattaa tgtacttcgt tcagttacgt attgcatcct 60
<210> 24
<211> 91
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 发夹寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<400> 24
tgcaatacgt aactgaacga agtacatttt tttgaagata gagcgatttt tttttttttt 60
ttgtacttcg ttcagttacg tattgcatcc t 91
<210> 25
<211> 88
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 发夹寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<400> 25
tgcaatacgt aactgaacga agtacatttt tttgaagata gagcgatttt tttttttttt 60
ttgtacttcg ttcagttacg tattgcat 88
<210> 26
<211> 92
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 发夹寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<220>
<221> misc_feature
<222> (52)..(52)
<223> 5'荧光素
<220>
<221> misc_feature
<222> (53)..(53)
<223> 5'荧光素
<220>
<221> misc_feature
<222> (54)..(54)
<223> 5'荧光素
<400> 26
tgcaatacgt aactgaacga agtacatttt tttgaagata gagcgatttt tttttttttt 60
tttgtacttc gttcagttac gtattgcatc ct 92
<210> 27
<211> 13
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 桥接核酸
<220>
<221> modified_base
<222> (2)..(2)
<223> m5c
<220>
<221> misc_feature
<222> (2)..(2)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (3)..(3)
<223> 桥接核酸
<220>
<221> modified_base
<222> (4)..(4)
<223> m5c
<220>
<221> misc_feature
<222> (4)..(4)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (5)..(5)
<223> 桥接核酸
<400> 27
tcgctctatc ttc 13
<210> 28
<211> 89
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<220>
<221> misc_feature
<222> (35)..(36)
<223> iSp18
<400> 28
gttattcaag acttctttaa tacacttttt tttttaatgt acttcgttca gttacgtatt 60
gctttggcgt ctgcttgggt gtttaacct 89
<210> 29
<211> 61
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<400> 29
ggttaaacac ccaagcagac gcctttgagg cgagcggtca attttttttt tttttttttt 60
t 61
<210> 30
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<220>
<221> misc_feature
<222> (23)..(23)
<223> 桥接核酸
<220>
<221> modified_base
<222> (24)..(24)
<223> m5c
<220>
<221> misc_feature
<222> (24)..(24)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (25)..(25)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (26)..(26)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (27)..(27)
<223> 桥接核酸
<400> 30
gcaatacgta actgaacgaa gtacatt 27
<210> 31
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (2)..(2)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (3)..(3)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (4)..(4)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (5)..(5)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (23)..(23)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (24)..(24)
<223> 桥接核酸
<220>
<221> modified_base
<222> (25)..(25)
<223> m5c
<220>
<221> misc_feature
<222> (25)..(25)
<223> 桥接核酸
<400> 31
gtgtattaaa gaagtcttga ataac 25
<210> 32
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> Y衔接子寡核苷酸
<400> 32
gtgtattaaa gaagtcttga ataac 25
<210> 33
<211> 41
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> C3间隔子寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<220>
<221> misc_feature
<222> (41)..(41)
<223> 30iSpC3
<400> 33
ggttaaacac ccaagcagac gcctttgagg cgagcggtca a 41
<210> 34
<400> 34
000
<210> 35
<400> 35
000
<210> 36
<400> 36
000
<210> 37
<400> 37
000
<210> 38
<400> 38
000
<210> 39
<400> 39
000
<210> 40
<211> 65
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> HhH结构域
<400> 40
Gly Thr Gly Ser Gly Ala Trp Lys Glu Trp Leu Glu Arg Lys Val Gly
1 5 1015
Glu Gly Arg Ala Arg Arg Leu Ile Glu Tyr Phe Gly Ser Ala Gly Glu
202530
Val Gly Lys Leu Val Glu Asn Ala Glu Val Ser Lys Leu Leu Glu Val
354045
Pro Gly Ile Gly Asp Glu Ala Val Ala Arg Leu Val Pro Gly Gly Ser
505560
Ser
65
<210> 41
<211> 299
<212> PRT
<213> 噬菌体(Bacteriophage)RB69
<400> 41
Met Phe Lys Arg Lys Ser Thr Ala Asp Leu Ala Ala Gln Met Ala Lys
1 5 1015
Leu Asn Gly Asn Lys Gly Phe Ser Ser Glu Asp Lys Gly Glu Trp Lys
202530
Leu Lys Leu Asp Ala Ser Gly Asn Gly Gln Ala Val Ile Arg Phe Leu
354045
Pro Ala Lys Thr Asp Asp Ala Leu Pro Phe Ala Ile Leu Val Asn His
505560
Gly Phe Lys Lys Asn Gly Lys Trp Tyr Ile Glu Thr Cys Ser Ser Thr
65707580
His Gly Asp Tyr Asp Ser Cys Pro Val Cys Gln Tyr Ile Ser Lys Asn
859095
Asp Leu Tyr Asn Thr Asn Lys Thr Glu Tyr Ser Gln Leu Lys Arg Lys
100 105 110
Thr Ser Tyr Trp Ala Asn Ile Leu Val Val Lys Asp Pro Gln Ala Pro
115 120 125
Asp Asn Glu Gly Lys Val Phe Lys Tyr Arg Phe Gly Lys Lys Ile Trp
130 135 140
Asp Lys Ile Asn Ala Met Ile Ala Val Asp Thr Glu Met Gly Glu Thr
145 150 155 160
Pro Val Asp Val Thr Cys Pro Trp Glu Gly Ala Asn Phe Val Leu Lys
165 170 175
Val Lys Gln Val Ser Gly Phe Ser Asn Tyr Asp Glu Ser Lys Phe Leu
180 185 190
Asn Gln Ser Ala Ile Pro Asn Ile Asp Asp Glu Ser Phe Gln Lys Glu
195 200 205
Leu Phe Glu Gln Met Val Asp Leu Ser Glu Met Thr Ser Lys Asp Lys
210 215 220
Phe Lys Ser Phe Glu Glu Leu Asn Thr Lys Phe Asn Gln Val Leu Gly
225 230 235 240
Thr Ala Ala Leu Gly Gly Ala Ala Ala Ala Ala Ala Ser Val Ala Asp
245 250 255
Lys Val Ala Ser Asp Leu Asp Asp Phe Asp Lys Asp Met Glu Ala Phe
260 265 270
Ser Ser Ala Lys Thr Glu Asp Asp Phe Met Ser Ser Ser Ser Ser Asp
275 280 285
Asp Gly Asp Leu Asp Asp Leu Leu Ala Gly Leu
290 295
<210> 42
<211> 232
<212> PRT
<213> 噬菌体T7
<400> 42
Met Ala Lys Lys Ile Phe Thr Ser Ala Leu Gly Thr Ala Glu Pro Tyr
1 5 1015
Ala Tyr Ile Ala Lys Pro Asp Tyr Gly Asn Glu Glu Arg Gly Phe Gly
202530
Asn Pro Arg Gly Val Tyr Lys Val Asp Leu Thr Ile Pro Asn Lys Asp
354045
Pro Arg Cys Gln Arg Met Val Asp Glu Ile Val Lys Cys His Glu Glu
505560
Ala Tyr Ala Ala Ala Val Glu Glu Tyr Glu Ala Asn Pro Pro Ala Val
65707580
Ala Arg Gly Lys Lys Pro Leu Lys Pro Tyr Glu Gly Asp Met Pro Phe
859095
Phe Asp Asn Gly Asp Gly Thr Thr Thr Phe Lys Phe Lys Cys Tyr Ala
100 105 110
Ser Phe Gln Asp Lys Lys Thr Lys Glu Thr Lys His Ile Asn Leu Val
115 120 125
Val Val Asp Ser Lys Gly Lys Lys Met Glu Asp Val Pro Ile Ile Gly
130 135 140
Gly Gly Ser Lys Leu Lys Val Lys Tyr Ser Leu Val Pro Tyr Lys Trp
145 150 155 160
Asn Thr Ala Val Gly Ala Ser Val Lys Leu Gln Leu Glu Ser Val Met
165 170 175
Leu Val Glu Leu Ala Thr Phe Gly Gly Gly Glu Asp Asp Trp Ala Asp
180 185 190
Glu Val Glu Glu Asn Gly Tyr Val Ala Ser Gly Ser Ala Lys Ala Ser
195 200 205
Lys Pro Arg Asp Glu Glu Ser Trp Asp Glu Asp Asp Glu Glu Ser Glu
210 215 220
Glu Ala Asp Glu Asp Gly Asp Phe
225 230
<210> 43
<211> 324
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> UL42进行性因子
<400> 43
Met Asp Ser Pro Gly Gly Val Ala Pro Ala Ser Pro Val Glu Asp Ala
1 5 1015
Ser Asp Ala Ser Leu Gly Gln Pro Glu Glu Gly Ala Pro Cys Gln Val
202530
Val Leu Gln Gly Ala Glu Leu Asn Gly Ile Leu Gln Ala Phe Ala Pro
354045
Leu Arg Thr Ser Leu Leu Asp Ser Leu Leu Val Met Gly Asp Arg Gly
505560
Ile Leu Ile His Asn Thr Ile Phe Gly Glu Gln Val Phe Leu Pro Leu
65707580
Glu His Ser Gln Phe Ser Arg Tyr Arg Trp Arg Gly Pro Thr Ala Ala
859095
Phe Leu Ser Leu Val Asp Gln Lys Arg Ser Leu Leu Ser Val Phe Arg
100 105 110
Ala Asn Gln Tyr Pro Asp Leu Arg Arg Val Glu Leu Ala Ile Thr Gly
115 120 125
Gln Ala Pro Phe Arg Thr Leu Val Gln Arg Ile Trp Thr Thr Thr Ser
130 135 140
Asp Gly Glu Ala Val Glu Leu Ala Ser Glu Thr Leu Met Lys Arg Glu
145 150 155 160
Leu Thr Ser Phe Val Val Leu Val Pro Gln Gly Thr Pro Asp Val Gln
165 170 175
Leu Arg Leu Thr Arg Pro Gln Leu Thr Lys Val Leu Asn Ala Thr Gly
180 185 190
Ala Asp Ser Ala Thr Pro Thr Thr Phe Glu Leu Gly Val Asn Gly Lys
195 200 205
Phe Ser Val Phe Thr Thr Ser Thr Cys Val Thr Phe Ala Ala Arg Glu
210 215 220
Glu Gly Val Ser Ser Ser Thr Ser Thr Gln Val Gln Ile Leu Ser Asn
225 230 235 240
Ala Leu Thr Lys Ala Gly Gln Ala Ala Ala Asn Ala Lys Thr Val Tyr
245 250 255
Gly Glu Asn Thr His Arg Thr Phe Ser Val Val Val Asp Asp Cys Ser
260 265 270
Met Arg Ala Val Leu Arg Arg Leu Gln Val Gly Gly Gly Thr Leu Lys
275 280 285
Phe Phe Leu Thr Thr Pro Val Pro Ser Leu Cys Val Thr Ala Thr Gly
290 295 300
Pro Asn Ala Val Ser Ala Val Phe Leu Leu Lys Pro Gln Lys His His
305 310 315 320
His His His His
<210> 44
<211> 251
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> PCNA的亚基1
<400> 44
Met Phe Lys Ile Val Tyr Pro Asn Ala Lys Asp Phe Phe Ser Phe Ile
1 5 1015
Asn Ser Ile Thr Asn Val Thr Asp Ser Ile Ile Leu Asn Phe Thr Glu
202530
Asp Gly Ile Phe Ser Arg His Leu Thr Glu Asp Lys Val Leu Met Ala
354045
Ile Met Arg Ile Pro Lys Asp Val Leu Ser Glu Tyr Ser Ile Asp Ser
505560
Pro Thr Ser Val Lys Leu Asp Val Ser Ser Val Lys Lys Ile Leu Ser
65707580
Lys Ala Ser Ser Lys Lys Ala Thr Ile Glu Leu Thr Glu Thr Asp Ser
859095
Gly Leu Lys Ile Ile Ile Arg Asp Glu Lys Ser Gly Ala Lys Ser Thr
100 105 110
Ile Tyr Ile Lys Ala Glu Lys Gly Gln Val Glu Gln Leu Thr Glu Pro
115 120 125
Lys Val Asn Leu Ala Val Asn Phe Thr Thr Asp Glu Ser Val Leu Asn
130 135 140
Val Ile Ala Ala Asp Val Thr Leu Val Gly Glu Glu Met Arg Ile Ser
145 150 155 160
Thr Glu Glu Asp Lys Ile Lys Ile Glu Ala Gly Glu Glu Gly Lys Arg
165 170 175
Tyr Val Ala Phe Leu Met Lys Asp Lys Pro Leu Lys Glu Leu Ser Ile
180 185 190
Asp Thr Ser Ala Ser Ser Ser Tyr Ser Ala Glu Met Phe Lys Asp Ala
195 200 205
Val Lys Gly Leu Arg Gly Phe Ser Ala Pro Thr Met Val Ser Phe Gly
210 215 220
Glu Asn Leu Pro Met Lys Ile Asp Val Glu Ala Val Ser Gly Gly His
225 230 235 240
Met Ile Phe Trp Ile Ala Pro Arg Leu Leu Glu
245 250
<210> 45
<211> 245
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> PCNA的亚基2
<400> 45
Met Lys Ala Lys Val Ile Asp Ala Val Ser Phe Ser Tyr Ile Leu Arg
1 5 1015
Thr Val Gly Asp Phe Leu Ser Glu Ala Asn Phe Ile Val Thr Lys Glu
202530
Gly Ile Arg Val Ser Gly Ile Asp Pro Ser Arg Val Val Phe Leu Asp
354045
Ile Phe Leu Pro Ser Ser Tyr Phe Glu Gly Phe Glu Val Ser Gln Glu
505560
Lys Glu Ile Ile Gly Phe Lys Leu Glu Asp Val Asn Asp Ile Leu Lys
65707580
Arg Val Leu Lys Asp Asp Thr Leu Ile Leu Ser Ser Asn Glu Ser Lys
859095
Leu Thr Leu Thr Phe Asp Gly Glu Phe Thr Arg Ser Phe Glu Leu Pro
100 105 110
Leu Ile Gln Val Glu Ser Thr Gln Pro Pro Ser Val Asn Leu Glu Phe
115 120 125
Pro Phe Lys Ala Gln Leu Leu Thr Ile Thr Phe Ala Asp Ile Ile Asp
130 135 140
Glu Leu Ser Asp Leu Gly Glu Val Leu Asn Ile His Ser Lys Glu Asn
145 150 155 160
Lys Leu Tyr Phe Glu Val Ile Gly Asp Leu Ser Thr Ala Lys Val Glu
165 170 175
Leu Ser Thr Asp Asn Gly Thr Leu Leu Glu Ala Ser Gly Ala Asp Val
180 185 190
Ser Ser Ser Tyr Gly Met Glu Tyr Val Ala Asn Thr Thr Lys Met Arg
195 200 205
Arg Ala Ser Asp Ser Met Glu Leu Tyr Phe Gly Ser Gln Ile Pro Leu
210 215 220
Lys Leu Arg Phe Lys Leu Pro Gln Glu Gly Tyr Gly Asp Phe Tyr Ile
225 230 235 240
Ala Pro Arg Ala Asp
245
<210> 46
<211> 246
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> PCNA的亚基3
<400> 46
Met Lys Val Val Tyr Asp Asp Val Arg Val Leu Lys Asp Ile Ile Gln
1 5 1015
Ala Leu Ala Arg Leu Val Asp Glu Ala Val Leu Lys Phe Lys Gln Asp
202530
Ser Val Glu Leu Val Ala Leu Asp Arg Ala His Ile Ser Leu Ile Ser
354045
Val Asn Leu Pro Arg Glu Met Phe Lys Glu Tyr Asp Val Asn Asp Glu
505560
Phe Lys Phe Gly Phe Asn Thr Gln Tyr Leu Met Lys Ile Leu Lys Val
65707580
Ala Lys Arg Lys Glu Ala Ile Glu Ile Ala Ser Glu Ser Pro Asp Ser
859095
Val Ile Ile Asn Ile Ile Gly Ser Thr Asn Arg Glu Phe Asn Val Arg
100 105 110
Asn Leu Glu Val Ser Glu Gln Glu Ile Pro Glu Ile Asn Leu Gln Phe
115 120 125
Asp Ile Ser Ala Thr Ile Ser Ser Asp Gly Phe Lys Ser Ala Ile Ser
130 135 140
Glu Val Ser Thr Val Thr Asp Asn Val Val Val Glu Gly His Glu Asp
145 150 155 160
Arg Ile Leu Ile Lys Ala Glu Gly Glu Ser Glu Val Glu Val Glu Phe
165 170 175
Ser Lys Asp Thr Gly Gly Leu Gln Asp Leu Glu Phe Ser Lys Glu Ser
180 185 190
Lys Asn Ser Tyr Ser Ala Glu Tyr Leu Asp Asp Val Leu Ser Leu Thr
195 200 205
Lys Leu Ser Asp Tyr Val Lys Ile Ser Phe Gly Asn Gln Lys Pro Leu
210 215 220
Gln Leu Phe Phe Asn Met Glu Gly Gly Gly Lys Val Thr Tyr Leu Leu
225 230 235 240
Ala Pro Lys Val Leu Glu
245
<210> 47
<211> 318
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> UL42进行性因子
<400> 47
Thr Asp Ser Pro Gly Gly Val Ala Pro Ala Ser Pro Val Glu Asp Ala
1 5 1015
Ser Asp Ala Ser Leu Gly Gln Pro Glu Glu Gly Ala Pro Cys Gln Val
202530
Val Leu Gln Gly Ala Glu Leu Asn Gly Ile Leu Gln Ala Phe Ala Pro
354045
Leu Arg Thr Ser Leu Leu Asp Ser Leu Leu Val Met Gly Asp Arg Gly
505560
Ile Leu Ile His Asn Thr Ile Phe Gly Glu Gln Val Phe Leu Pro Leu
65707580
Glu His Ser Gln Phe Ser Arg Tyr Arg Trp Arg Gly Pro Thr Ala Ala
859095
Phe Leu Ser Leu Val Asp Gln Lys Arg Ser Leu Leu Ser Val Phe Arg
100 105 110
Ala Asn Gln Tyr Pro Asp Leu Arg Arg Val Glu Leu Ala Ile Thr Gly
115 120 125
Gln Ala Pro Phe Arg Thr Leu Val Gln Arg Ile Trp Thr Thr Thr Ser
130 135 140
Asp Gly Glu Ala Val Glu Leu Ala Ser Glu Thr Leu Met Lys Arg Glu
145 150 155 160
Leu Thr Ser Phe Val Val Leu Val Pro Gln Gly Thr Pro Asp Val Gln
165 170 175
Leu Arg Leu Thr Arg Pro Gln Leu Thr Lys Val Leu Asn Ala Thr Gly
180 185 190
Ala Asp Ser Ala Thr Pro Thr Thr Phe Glu Leu Gly Val Asn Gly Lys
195 200 205
Phe Ser Val Phe Thr Thr Ser Thr Cys Val Thr Phe Ala Ala Arg Glu
210 215 220
Glu Gly Val Ser Ser Ser Thr Ser Thr Gln Val Gln Ile Leu Ser Asn
225 230 235 240
Ala Leu Thr Lys Ala Gly Gln Ala Ala Ala Asn Ala Lys Thr Val Tyr
245 250 255
Gly Glu Asn Thr His Arg Thr Phe Ser Val Val Val Asp Asp Cys Ser
260 265 270
Met Arg Ala Val Leu Arg Arg Leu Gln Val Gly Gly Gly Thr Leu Lys
275 280 285
Phe Phe Leu Thr Thr Pro Val Pro Ser Leu Cys Val Thr Ala Thr Gly
290 295 300
Pro Asn Ala Val Ser Ala Val Phe Leu Leu Lys Pro Gln Lys
305 310 315
<210> 48
<211> 55
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> (HhH)2结构域
<400> 48
Trp Lys Glu Trp Leu Glu Arg Lys Val Gly Glu Gly Arg Ala Arg Arg
1 5 1015
Leu Ile Glu Tyr Phe Gly Ser Ala Gly Glu Val Gly Lys Leu Val Glu
202530
Asn Ala Glu Val Ser Lys Leu Leu Glu Val Pro Gly Ile Gly Asp Glu
354045
Ala Val Ala Arg Leu Val Pro
5055
<210> 49
<211> 107
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> (HhH)2-(HhH)2结构域
<400> 49
Trp Lys Glu Trp Leu Glu Arg Lys Val Gly Glu Gly Arg Ala Arg Arg
1 5 1015
Leu Ile Glu Tyr Phe Gly Ser Ala Gly Glu Val Gly Lys Leu Val Glu
202530
Asn Ala Glu Val Ser Lys Leu Leu Glu Val Pro Gly Ile Gly Asp Glu
354045
Ala Val Ala Arg Leu Val Pro Gly Tyr Lys Thr Leu Arg Asp Ala Gly
505560
Leu Thr Pro Ala Glu Ala Glu Arg Val Leu Lys Arg Tyr Gly Ser Val
65707580
Ser Lys Val Gln Glu Gly Ala Thr Pro Asp Glu Leu Arg Glu Leu Gly
859095
Leu Gly Asp Ala Lys Ile Ala Arg Ile Leu Gly
100 105
<210> 50
<211> 132
<212> PRT
<213> 智人(Homo sapiens)
<400> 50
Glu Ser Glu Thr Thr Thr Ser Leu Val Leu Glu Arg Ser Leu Asn Arg
1 5 1015
Val His Leu Leu Gly Arg Val Gly Gln Asp Pro Val Leu Arg Gln Val
202530
Glu Gly Lys Asn Pro Val Thr Ile Phe Ser Leu Ala Thr Asn Glu Met
354045
Trp Arg Ser Gly Asp Ser Glu Val Tyr Gln Leu Gly Asp Val Ser Gln
505560
Lys Thr Thr Trp His Arg Ile Ser Val Phe Arg Pro Gly Leu Arg Asp
65707580
Val Ala Tyr Gln Tyr Val Lys Lys Gly Ser Arg Ile Tyr Leu Glu Gly
859095
Lys Ile Asp Tyr Gly Glu Tyr Met Asp Lys Asn Asn Val Arg Arg Gln
100 105 110
Ala Thr Thr Ile Ile Ala Asp Asn Ile Ile Phe Leu Ser Asp Gln Thr
115 120 125
Lys Glu Lys Glu
130
<210> 51
<211> 123
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> p5蛋白
<400> 51
Glu Asn Thr Asn Ile Val Lys Ala Thr Phe Asp Thr Glu Thr Leu Glu
1 5 1015
Gly Gln Ile Lys Ile Phe Asn Ala Gln Thr Gly Gly Gly Gln Ser Phe
202530
Lys Asn Leu Pro Asp Gly Thr Ile Ile Glu Ala Asn Ala Ile Ala Gln
354045
Tyr Lys Gln Val Ser Asp Thr Tyr Gly Asp Ala Lys Glu Glu Thr Val
505560
Thr Thr Ile Phe Ala Ala Asp Gly Ser Leu Tyr Ser Ala Ile Ser Lys
65707580
Thr Val Ala Glu Ala Ala Ser Asp Leu Ile Asp Leu Val Thr Arg His
859095
Lys Leu Glu Thr Phe Lys Val Lys Val Val Gln Gly Thr Ser Ser Lys
100 105 110
Gly Asn Val Phe Phe Ser Leu Gln Leu Ser Leu
115 120
<210> 52
<211> 177
<212> PRT
<213> 大肠杆菌(Escherichia coli)
<400> 52
Ala Ser Arg Gly Val Asn Lys Val Ile Leu Val Gly Asn Leu Gly Gln
1 5 1015
Asp Pro Glu Val Arg Tyr Met Pro Asn Gly Gly Ala Val Ala Asn Ile
202530
Thr Leu Ala Thr Ser Glu Ser Trp Arg Asp Lys Ala Thr Gly Glu Met
354045
Lys Glu Gln Thr Glu Trp His Arg Val Val Leu Phe Gly Lys Leu Ala
505560
Glu Val Ala Ser Glu Tyr Leu Arg Lys Gly Ser Gln Val Tyr Ile Glu
65707580
Gly Gln Leu Arg Thr Arg Lys Trp Thr Asp Gln Ser Gly Gln Asp Arg
859095
Tyr Thr Thr Glu Val Val Val Asn Val Gly Gly Thr Met Gln Met Leu
100 105 110
Gly Gly Arg Gln Gly Gly Gly Ala Pro Ala Gly Gly Asn Ile Gly Gly
115 120 125
Gly Gln Pro Gln Gly Gly Trp Gly Gln Pro Gln Gln Pro Gln Gly Gly
130 135 140
Asn Gln Phe Ser Gly Gly Ala Gln Ser Arg Pro Gln Gln Ser Ala Pro
145 150 155 160
Ala Ala Pro Ser Asn Glu Pro Pro Met Asp Phe Asp Asp Asp Ile Pro
165 170 175
Phe
<210> 53
<211> 301
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 来自噬菌体T4的ssb
<400> 53
Met Phe Lys Arg Lys Ser Thr Ala Glu Leu Ala Ala Gln Met Ala Lys
1 5 1015
Leu Asn Gly Asn Lys Gly Phe Ser Ser Glu Asp Lys Gly Glu Trp Lys
202530
Leu Lys Leu Asp Asn Ala Gly Asn Gly Gln Ala Val Ile Arg Phe Leu
354045
Pro Ser Lys Asn Asp Glu Gln Ala Pro Phe Ala Ile Leu Val Asn His
505560
Gly Phe Lys Lys Asn Gly Lys Trp Tyr Ile Glu Thr Cys Ser Ser Thr
65707580
His Gly Asp Tyr Asp Ser Cys Pro Val Cys Gln Tyr Ile Ser Lys Asn
859095
Asp Leu Tyr Asn Thr Asp Asn Lys Glu Tyr Ser Leu Val Lys Arg Lys
100 105 110
Thr Ser Tyr Trp Ala Asn Ile Leu Val Val Lys Asp Pro Ala Ala Pro
115 120 125
Glu Asn Glu Gly Lys Val Phe Lys Tyr Arg Phe Gly Lys Lys Ile Trp
130 135 140
Asp Lys Ile Asn Ala Met Ile Ala Val Asp Val Glu Met Gly Glu Thr
145 150 155 160
Pro Val Asp Val Thr Cys Pro Trp Glu Gly Ala Asn Phe Val Leu Lys
165 170 175
Val Lys Gln Val Ser Gly Phe Ser Asn Tyr Asp Glu Ser Lys Phe Leu
180 185 190
Asn Gln Ser Ala Ile Pro Asn Ile Asp Asp Glu Ser Phe Gln Lys Glu
195 200 205
Leu Phe Glu Gln Met Val Asp Leu Ser Glu Met Thr Ser Lys Asp Lys
210 215 220
Phe Lys Ser Phe Glu Glu Leu Asn Thr Lys Phe Gly Gln Val Met Gly
225 230 235 240
Thr Ala Val Met Gly Gly Ala Ala Ala Thr Ala Ala Lys Lys Ala Asp
245 250 255
Lys Val Ala Asp Asp Leu Asp Ala Phe Asn Val Asp Asp Phe Asn Thr
260 265 270
Lys Thr Glu Asp Asp Phe Met Ser Ser Ser Ser Gly Ser Ser Ser Ser
275 280 285
Ala Asp Asp Thr Asp Leu Asp Asp Leu Leu Asn Asp Leu
290 295 300
<210> 54
<211> 984
<212> PRT
<213> 坎德勒氏甲烷嗜热菌(Methanopyrus kandleri)
<400> 54
Met Ala Leu Val Tyr Asp Ala Glu Phe Val Gly Ser Glu Arg Glu Phe
1 5 1015
Glu Glu Glu Arg Glu Thr Phe Leu Lys Gly Val Lys Ala Tyr Asp Gly
202530
Val Leu Ala Thr Arg Tyr Leu Met Glu Arg Ser Ser Ser Ala Lys Asn
354045
Asp Glu Glu Leu Leu Glu Leu His Gln Asn Phe Ile Leu Leu Thr Gly
505560
Ser Tyr Ala Cys Ser Ile Asp Pro Thr Glu Asp Arg Tyr Gln Asn Val
65707580
Ile Val Arg Gly Val Asn Phe Asp Glu Arg Val Gln Arg Leu Ser Thr
859095
Gly Gly Ser Pro Ala Arg Tyr Ala Ile Val Tyr Arg Arg Gly Trp Arg
100 105 110
Ala Ile Ala Lys Ala Leu Asp Ile Asp Glu Glu Asp Val Pro Ala Ile
115 120 125
Glu Val Arg Ala Val Lys Arg Asn Pro Leu Gln Pro Ala Leu Tyr Arg
130 135 140
Ile Leu Val Arg Tyr Gly Arg Val Asp Leu Met Pro Val Thr Val Asp
145 150 155 160
Glu Val Pro Pro Glu Met Ala Gly Glu Phe Glu Arg Leu Ile Glu Arg
165 170 175
Tyr Asp Val Pro Ile Asp Glu Lys Glu Glu Arg Ile Leu Glu Ile Leu
180 185 190
Arg Glu Asn Pro Trp Thr Pro His Asp Glu Ile Ala Arg Arg Leu Gly
195 200 205
Leu Ser Val Ser Glu Val Glu Gly Glu Lys Asp Pro Glu Ser Ser Gly
210 215 220
Ile Tyr Ser Leu Trp Ser Arg Val Val Val Asn Ile Glu Tyr Asp Glu
225 230 235 240
Arg Thr Ala Lys Arg His Val Lys Arg Arg Asp Arg Leu Leu Glu Glu
245 250 255
Leu Tyr Glu His Leu Glu Glu Leu Ser Glu Arg Tyr Leu Arg His Pro
260 265 270
Leu Thr Arg Arg Trp Ile Val Glu His Lys Arg Asp Ile Met Arg Arg
275 280 285
Tyr Leu Glu Gln Arg Ile Val Glu Cys Ala Leu Lys Leu Gln Asp Arg
290 295 300
Tyr Gly Ile Arg Glu Asp Val Ala Leu Cys Leu Ala Arg Ala Phe Asp
305 310 315 320
Gly Ser Ile Ser Met Ile Ala Thr Thr Pro Tyr Arg Thr Leu Lys Asp
325 330 335
Val Cys Pro Asp Leu Thr Leu Glu Glu Ala Lys Ser Val Asn Arg Thr
340 345 350
Leu Ala Thr Leu Ile Asp Glu His Gly Leu Ser Pro Asp Ala Ala Asp
355 360 365
Glu Leu Ile Glu His Phe Glu Ser Ile Ala Gly Ile Leu Ala Thr Asp
370 375 380
Leu Glu Glu Ile Glu Arg Met Tyr Glu Glu Gly Arg Leu Ser Glu Glu
385 390 395 400
Ala Tyr Arg Ala Ala Val Glu Ile Gln Leu Ala Glu Leu Thr Lys Lys
405 410 415
Glu Gly Val Gly Arg Lys Thr Ala Glu Arg Leu Leu Arg Ala Phe Gly
420 425 430
Asn Pro Glu Arg Val Lys Gln Leu Ala Arg Glu Phe Glu Ile Glu Lys
435 440 445
Leu Ala Ser Val Glu Gly Val Gly Glu Arg Val Leu Arg Ser Leu Val
450 455 460
Pro Gly Tyr Ala Ser Leu Ile Ser Ile Arg Gly Ile Asp Arg Glu Arg
465 470 475 480
Ala Glu Arg Leu Leu Lys Lys Tyr Gly Gly Tyr Ser Lys Val Arg Glu
485 490 495
Ala Gly Val Glu Glu Leu Arg Glu Asp Gly Leu Thr Asp Ala Gln Ile
500 505 510
Arg Glu Leu Lys Gly Leu Lys Thr Leu Glu Ser Ile Val Gly Asp Leu
515 520 525
Glu Lys Ala Asp Glu Leu Lys Arg Lys Tyr Gly Ser Ala Ser Ala Val
530 535 540
Arg Arg Leu Pro Val Glu Glu Leu Arg Glu Leu Gly Phe Ser Asp Asp
545 550 555 560
Glu Ile Ala Glu Ile Lys Gly Ile Pro Lys Lys Leu Arg Glu Ala Phe
565 570 575
Asp Leu Glu Thr Ala Ala Glu Leu Tyr Glu Arg Tyr Gly Ser Leu Lys
580 585 590
Glu Ile Gly Arg Arg Leu Ser Tyr Asp Asp Leu Leu Glu Leu Gly Ala
595 600 605
Thr Pro Lys Ala Ala Ala Glu Ile Lys Gly Pro Glu Phe Lys Phe Leu
610 615 620
Leu Asn Ile Glu Gly Val Gly Pro Lys Leu Ala Glu Arg Ile Leu Glu
625 630 635 640
Ala Val Asp Tyr Asp Leu Glu Arg Leu Ala Ser Leu Asn Pro Glu Glu
645 650 655
Leu Ala Glu Lys Val Glu Gly Leu Gly Glu Glu Leu Ala Glu Arg Val
660 665 670
Val Tyr Ala Ala Arg Glu Arg Val Glu Ser Arg Arg Lys Ser Gly Arg
675 680 685
Gln Glu Arg Ser Glu Glu Glu Trp Lys Glu Trp Leu Glu Arg Lys Val
690 695 700
Gly Glu Gly Arg Ala Arg Arg Leu Ile Glu Tyr Phe Gly Ser Ala Gly
705 710 715 720
Glu Val Gly Lys Leu Val Glu Asn Ala Glu Val Ser Lys Leu Leu Glu
725 730 735
Val Pro Gly Ile Gly Asp Glu Ala Val Ala Arg Leu Val Pro Gly Tyr
740 745 750
Lys Thr Leu Arg Asp Ala Gly Leu Thr Pro Ala Glu Ala Glu Arg Val
755 760 765
Leu Lys Arg Tyr Gly Ser Val Ser Lys Val Gln Glu Gly Ala Thr Pro
770 775 780
Asp Glu Leu Arg Glu Leu Gly Leu Gly Asp Ala Lys Ile Ala Arg Ile
785 790 795 800
Leu Gly Leu Arg Ser Leu Val Asn Lys Arg Leu Asp Val Asp Thr Ala
805 810 815
Tyr Glu Leu Lys Arg Arg Tyr Gly Ser Val Ser Ala Val Arg Lys Ala
820 825 830
Pro Val Lys Glu Leu Arg Glu Leu Gly Leu Ser Asp Arg Lys Ile Ala
835 840 845
Arg Ile Lys Gly Ile Pro Glu Thr Met Leu Gln Val Arg Gly Met Ser
850 855 860
Val Glu Lys Ala Glu Arg Leu Leu Glu Arg Phe Asp Thr Trp Thr Lys
865 870 875 880
Val Lys Glu Ala Pro Val Ser Glu Leu Val Arg Val Pro Gly Val Gly
885 890 895
Leu Ser Leu Val Lys Glu Ile Lys Ala Gln Val Asp Pro Ala Trp Lys
900 905 910
Ala Leu Leu Asp Val Lys Gly Val Ser Pro Glu Leu Ala Asp Arg Leu
915 920 925
Val Glu Glu Leu Gly Ser Pro Tyr Arg Val Leu Thr Ala Lys Lys Ser
930 935 940
Asp Leu Met Arg Val Glu Arg Val Gly Pro Lys Leu Ala Glu Arg Ile
945 950 955 960
Arg Ala Ala Gly Lys Arg Tyr Val Glu Glu Arg Arg Ser Arg Arg Glu
965 970 975
Arg Ile Arg Arg Lys Leu Arg Gly
980
<210> 55
<211> 299
<212> PRT
<213> 坎德勒氏甲烷嗜热菌(Methanopyrus kandleri)
<400> 55
Ser Gly Arg Gln Glu Arg Ser Glu Glu Glu Trp Lys Glu Trp Leu Glu
1 5 1015
Arg Lys Val Gly Glu Gly Arg Ala Arg Arg Leu Ile Glu Tyr Phe Gly
202530
Ser Ala Gly Glu Val Gly Lys Leu Val Glu Asn Ala Glu Val Ser Lys
354045
Leu Leu Glu Val Pro Gly Ile Gly Asp Glu Ala Val Ala Arg Leu Val
505560
Pro Gly Tyr Lys Thr Leu Arg Asp Ala Gly Leu Thr Pro Ala Glu Ala
65707580
Glu Arg Val Leu Lys Arg Tyr Gly Ser Val Ser Lys Val Gln Glu Gly
859095
Ala Thr Pro Asp Glu Leu Arg Glu Leu Gly Leu Gly Asp Ala Lys Ile
100 105 110
Ala Arg Ile Leu Gly Leu Arg Ser Leu Val Asn Lys Arg Leu Asp Val
115 120 125
Asp Thr Ala Tyr Glu Leu Lys Arg Arg Tyr Gly Ser Val Ser Ala Val
130 135 140
Arg Lys Ala Pro Val Lys Glu Leu Arg Glu Leu Gly Leu Ser Asp Arg
145 150 155 160
Lys Ile Ala Arg Ile Lys Gly Ile Pro Glu Thr Met Leu Gln Val Arg
165 170 175
Gly Met Ser Val Glu Lys Ala Glu Arg Leu Leu Glu Arg Phe Asp Thr
180 185 190
Trp Thr Lys Val Lys Glu Ala Pro Val Ser Glu Leu Val Arg Val Pro
195 200 205
Gly Val Gly Leu Ser Leu Val Lys Glu Ile Lys Ala Gln Val Asp Pro
210 215 220
Ala Trp Lys Ala Leu Leu Asp Val Lys Gly Val Ser Pro Glu Leu Ala
225 230 235 240
Asp Arg Leu Val Glu Glu Leu Gly Ser Pro Tyr Arg Val Leu Thr Ala
245 250 255
Lys Lys Ser Asp Leu Met Arg Val Glu Arg Val Gly Pro Lys Leu Ala
260 265 270
Glu Arg Ile Arg Ala Ala Gly Lys Arg Tyr Val Glu Glu Arg Arg Ser
275 280 285
Arg Arg Glu Arg Ile Arg Arg Lys Leu Arg Gly
290 295
<210> 56
<211> 853
<212> PRT
<213> 大肠杆菌(Escherichia coli)
<400> 56
Met Ser Ala Ile Glu Asn Phe Asp Ala His Thr Pro Met Met Gln Gln
1 5 1015
Tyr Leu Arg Leu Lys Ala Gln His Pro Glu Ile Leu Leu Phe Tyr Arg
202530
Met Gly Asp Phe Tyr Glu Leu Phe Tyr Asp Asp Ala Lys Arg Ala Ser
354045
Gln Leu Leu Asp Ile Ser Leu Thr Lys Arg Gly Ala Ser Ala Gly Glu
505560
Pro Ile Pro Met Ala Gly Ile Pro Tyr His Ala Val Glu Asn Tyr Leu
65707580
Ala Lys Leu Val Asn Gln Gly Glu Ser Val Ala Ile Cys Glu Gln Ile
859095
Gly Asp Pro Ala Thr Ser Lys Gly Pro Val Glu Arg Lys Val Val Arg
100 105 110
Ile Val Thr Pro Gly Thr Ile Ser Asp Glu Ala Leu Leu Gln Glu Arg
115 120 125
Gln Asp Asn Leu Leu Ala Ala Ile Trp Gln Asp Ser Lys Gly Phe Gly
130 135 140
Tyr Ala Thr Leu Asp Ile Ser Ser Gly Arg Phe Arg Leu Ser Glu Pro
145 150 155 160
Ala Asp Arg Glu Thr Met Ala Ala Glu Leu Gln Arg Thr Asn Pro Ala
165 170 175
Glu Leu Leu Tyr Ala Glu Asp Phe Ala Glu Met Ser Leu Ile Glu Gly
180 185 190
Arg Arg Gly Leu Arg Arg Arg Pro Leu Trp Glu Phe Glu Ile Asp Thr
195 200 205
Ala Arg Gln Gln Leu Asn Leu Gln Phe Gly Thr Arg Asp Leu Val Gly
210 215 220
Phe Gly Val Glu Asn Ala Pro Arg Gly Leu Cys Ala Ala Gly Cys Leu
225 230 235 240
Leu Gln Tyr Ala Lys Asp Thr Gln Arg Thr Thr Leu Pro His Ile Arg
245 250 255
Ser Ile Thr Met Glu Arg Glu Gln Asp Ser Ile Ile Met Asp Ala Ala
260 265 270
Thr Arg Arg Asn Leu Glu Ile Thr Gln Asn Leu Ala Gly Gly Ala Glu
275 280 285
Asn Thr Leu Ala Ser Val Leu Asp Cys Thr Val Thr Pro Met Gly Ser
290 295 300
Arg Met Leu Lys Arg Trp Leu His Met Pro Val Arg Asp Thr Arg Val
305 310 315 320
Leu Leu Glu Arg Gln Gln Thr Ile Gly Ala Leu Gln Asp Phe Thr Ala
325 330 335
Gly Leu Gln Pro Val Leu Arg Gln Val Gly Asp Leu Glu Arg Ile Leu
340 345 350
Ala Arg Leu Ala Leu Arg Thr Ala Arg Pro Arg Asp Leu Ala Arg Met
355 360 365
Arg His Ala Phe Gln Gln Leu Pro Glu Leu Arg Ala Gln Leu Glu Thr
370 375 380
Val Asp Ser Ala Pro Val Gln Ala Leu Arg Glu Lys Met Gly Glu Phe
385 390 395 400
Ala Glu Leu Arg Asp Leu Leu Glu Arg Ala Ile Ile Asp Thr Pro Pro
405 410 415
Val Leu Val Arg Asp Gly Gly Val Ile Ala Ser Gly Tyr Asn Glu Glu
420 425 430
Leu Asp Glu Trp Arg Ala Leu Ala Asp Gly Ala Thr Asp Tyr Leu Glu
435 440 445
Arg Leu Glu Val Arg Glu Arg Glu Arg Thr Gly Leu Asp Thr Leu Lys
450 455 460
Val Gly Phe Asn Ala Val His Gly Tyr Tyr Ile Gln Ile Ser Arg Gly
465 470 475 480
Gln Ser His Leu Ala Pro Ile Asn Tyr Met Arg Arg Gln Thr Leu Lys
485 490 495
Asn Ala Glu Arg Tyr Ile Ile Pro Glu Leu Lys Glu Tyr Glu Asp Lys
500 505 510
Val Leu Thr Ser Lys Gly Lys Ala Leu Ala Leu Glu Lys Gln Leu Tyr
515 520 525
Glu Glu Leu Phe Asp Leu Leu Leu Pro His Leu Glu Ala Leu Gln Gln
530 535 540
Ser Ala Ser Ala Leu Ala Glu Leu Asp Val Leu Val Asn Leu Ala Glu
545 550 555 560
Arg Ala Tyr Thr Leu Asn Tyr Thr Cys Pro Thr Phe Ile Asp Lys Pro
565 570 575
Gly Ile Arg Ile Thr Glu Gly Arg His Pro Val Val Glu Gln Val Leu
580 585 590
Asn Glu Pro Phe Ile Ala Asn Pro Leu Asn Leu Ser Pro Gln Arg Arg
595 600 605
Met Leu Ile Ile Thr Gly Pro Asn Met Gly Gly Lys Ser Thr Tyr Met
610 615 620
Arg Gln Thr Ala Leu Ile Ala Leu Met Ala Tyr Ile Gly Ser Tyr Val
625 630 635 640
Pro Ala Gln Lys Val Glu Ile Gly Pro Ile Asp Arg Ile Phe Thr Arg
645 650 655
Val Gly Ala Ala Asp Asp Leu Ala Ser Gly Arg Ser Thr Phe Met Val
660 665 670
Glu Met Thr Glu Thr Ala Asn Ile Leu His Asn Ala Thr Glu Tyr Ser
675 680 685
Leu Val Leu Met Asp Glu Ile Gly Arg Gly Thr Ser Thr Tyr Asp Gly
690 695 700
Leu Ser Leu Ala Trp Ala Cys Ala Glu Asn Leu Ala Asn Lys Ile Lys
705 710 715 720
Ala Leu Thr Leu Phe Ala Thr His Tyr Phe Glu Leu Thr Gln Leu Pro
725 730 735
Glu Lys Met Glu Gly Val Ala Asn Val His Leu Asp Ala Leu Glu His
740 745 750
Gly Asp Thr Ile Ala Phe Met His Ser Val Gln Asp Gly Ala Ala Ser
755 760 765
Lys Ser Tyr Gly Leu Ala Val Ala Ala Leu Ala Gly Val Pro Lys Glu
770 775 780
Val Ile Lys Arg Ala Arg Gln Lys Leu Arg Glu Leu Glu Ser Ile Ser
785 790 795 800
Pro Asn Ala Ala Ala Thr Gln Val Asp Gly Thr Gln Met Ser Leu Leu
805 810 815
Ser Val Pro Glu Glu Thr Ser Pro Ala Val Glu Ala Leu Glu Asn Leu
820 825 830
Asp Pro Asp Ser Leu Thr Pro Arg Gln Ala Leu Glu Trp Ile Tyr Arg
835 840 845
Leu Lys Ser Leu Val
850
<210> 57
<211> 64
<212> PRT
<213> 硫磺矿硫化叶菌(Sulfolobus solfataricus)
<400> 57
Met Ala Thr Val Lys Phe Lys Tyr Lys Gly Glu Glu Lys Glu Val Asp
1 5 1015
Ile Ser Lys Ile Lys Lys Val Trp Arg Val Gly Lys Met Ile Ser Phe
202530
Thr Tyr Asp Glu Gly Gly Gly Lys Thr Gly Arg Gly Ala Val Ser Glu
354045
Lys Asp Ala Pro Lys Glu Leu Leu Gln Met Leu Glu Lys Gln Lys Lys
505560
<210> 58
<211> 99
<212> PRT
<213> 硫磺矿硫化叶菌P2
<400> 58
Glu Lys Met Ser Ser Gly Thr Pro Thr Pro Ser Asn Val Val Leu Ile
1 5 1015
Gly Lys Lys Pro Val Met Asn Tyr Val Leu Ala Ala Leu Thr Leu Leu
202530
Asn Gln Gly Val Ser Glu Ile Val Ile Lys Ala Arg Gly Arg Ala Ile
354045
Ser Lys Ala Val Asp Thr Val Glu Ile Val Arg Asn Arg Phe Leu Pro
505560
Asp Lys Ile Glu Ile Lys Glu Ile Arg Val Gly Ser Gln Val Val Thr
65707580
Ser Gln Asp Gly Arg Gln Ser Arg Val Ser Thr Ile Glu Ile Ala Ile
859095
Arg Lys Lys
<210> 59
<211> 88
<212> PRT
<213> 硫磺矿硫化叶菌P2
<400> 59
Thr Glu Lys Leu Asn Glu Ile Val Val Arg Lys Thr Lys Asn Val Glu
1 5 1015
Asp His Val Leu Asp Val Ile Val Leu Phe Asn Gln Gly Ile Asp Glu
202530
Val Ile Leu Lys Gly Thr Gly Arg Glu Ile Ser Lys Ala Val Asp Val
354045
Tyr Asn Ser Leu Lys Asp Arg Leu Gly Asp Gly Val Gln Leu Val Asn
505560
Val Gln Thr Gly Ser Glu Val Arg Asp Arg Arg Arg Ile Ser Tyr Ile
65707580
Leu Leu Arg Leu Lys Arg Val Tyr
85
<210> 60
<211> 107
<212> PRT
<213> 大肠杆菌(Escherichia coli)
<400> 60
Ala Gln Gln Ser Pro Tyr Ser Ala Ala Met Ala Glu Gln Arg His Gln
1 5 1015
Glu Trp Leu Arg Phe Val Asp Leu Leu Lys Asn Ala Tyr Gln Asn Asp
202530
Leu His Leu Pro Leu Leu Asn Leu Met Leu Thr Pro Asp Glu Arg Glu
354045
Ala Leu Gly Thr Arg Val Arg Ile Val Glu Glu Leu Leu Arg Gly Glu
505560
Met Ser Gln Arg Glu Leu Lys Asn Glu Leu Gly Ala Gly Ile Ala Thr
65707580
Ile Thr Arg Gly Ser Asn Ser Leu Lys Ala Ala Pro Val Glu Leu Arg
859095
Gln Trp Leu Glu Glu Val Leu Leu Lys Ser Asp
100 105
<210> 61
<211> 237
<212> PRT
<213> 肠杆菌噬菌体λ(Enterobacteria phage lambda)
<400> 61
Met Ser Thr Lys Lys Lys Pro Leu Thr Gln Glu Gln Leu Glu Asp Ala
1 5 1015
Arg Arg Leu Lys Ala Ile Tyr Glu Lys Lys Lys Asn Glu Leu Gly Leu
202530
Ser Gln Glu Ser Val Ala Asp Lys Met Gly Met Gly Gln Ser Gly Val
354045
Gly Ala Leu Phe Asn Gly Ile Asn Ala Leu Asn Ala Tyr Asn Ala Ala
505560
Leu Leu Ala Lys Ile Leu Lys Val Ser Val Glu Glu Phe Ser Pro Ser
65707580
Ile Ala Arg Glu Ile Tyr Glu Met Tyr Glu Ala Val Ser Met Gln Pro
859095
Ser Leu Arg Ser Glu Tyr Glu Tyr Pro Val Phe Ser His Val Gln Ala
100 105 110
Gly Met Phe Ser Pro Glu Leu Arg Thr Phe Thr Lys Gly Asp Ala Glu
115 120 125
Arg Trp Val Ser Thr Thr Lys Lys Ala Ser Asp Ser Ala Phe Trp Leu
130 135 140
Glu Val Glu Gly Asn Ser Met Thr Ala Pro Thr Gly Ser Lys Pro Ser
145 150 155 160
Phe Pro Asp Gly Met Leu Ile Leu Val Asp Pro Glu Gln Ala Val Glu
165 170 175
Pro Gly Asp Phe Cys Ile Ala Arg Leu Gly Gly Asp Glu Phe Thr Phe
180 185 190
Lys Lys Leu Ile Arg Asp Ser Gly Gln Val Phe Leu Gln Pro Leu Asn
195 200 205
Pro Gln Tyr Pro Met Ile Pro Cys Asn Glu Ser Cys Ser Val Val Gly
210 215 220
Lys Val Ile Ala Ser Gln Trp Pro Glu Glu Thr Phe Gly
225 230 235
<210> 62
<211> 60
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> Cren7
<400> 62
Met Ser Ser Gly Lys Lys Pro Val Lys Val Lys Thr Pro Ala Gly Lys
1 5 1015
Glu Ala Glu Leu Val Pro Glu Lys Val Trp Ala Leu Ala Pro Lys Gly
202530
Arg Lys Gly Val Lys Ile Gly Leu Phe Lys Asp Pro Glu Thr Gly Lys
354045
Tyr Phe Arg His Lys Leu Pro Asp Asp Tyr Pro Ile
505560
<210> 63
<211> 136
<212> PRT
<213> 智人(Homo sapiens)
<400> 63
Met Ala Arg Thr Lys Gln Thr Ala Arg Lys Ser Thr Gly Gly Lys Ala
1 5 1015
Pro Arg Lys Gln Leu Ala Thr Lys Ala Ala Arg Lys Ser Ala Pro Ala
202530
Thr Gly Gly Val Lys Lys Pro His Arg Tyr Arg Pro Gly Thr Val Ala
354045
Leu Arg Glu Ile Arg Arg Tyr Gln Lys Ser Thr Glu Leu Leu Ile Arg
505560
Lys Leu Pro Phe Gln Arg Leu Val Arg Glu Ile Ala Gln Asp Phe Lys
65707580
Thr Asp Leu Arg Phe Gln Ser Ser Ala Val Met Ala Leu Gln Glu Ala
859095
Ser Glu Ala Tyr Leu Val Gly Leu Phe Glu Asp Thr Asn Leu Cys Ala
100 105 110
Ile His Ala Lys Arg Val Thr Ile Met Pro Lys Asp Ile Gln Leu Ala
115 120 125
Arg Arg Ile Arg Gly Glu Arg Ala
130 135
<210> 64
<211> 89
<212> PRT
<213> 肠杆菌噬菌体(Enterobacteria phage)T4
<400> 64
Met Ala Lys Lys Glu Met Val Glu Phe Asp Glu Ala Ile His Gly Glu
1 5 1015
Asp Leu Ala Lys Phe Ile Lys Glu Ala Ser Asp His Lys Leu Lys Ile
202530
Ser Gly Tyr Asn Glu Leu Ile Lys Asp Ile Arg Ile Arg Ala Lys Asp
354045
Glu Leu Gly Val Asp Gly Lys Met Phe Asn Arg Leu Leu Ala Leu Tyr
505560
His Lys Asp Asn Arg Asp Val Phe Glu Ala Glu Thr Glu Glu Val Val
65707580
Glu Leu Tyr Asp Thr Val Phe Ser Lys
85
<210> 65
<211> 339
<212> PRT
<213> 智人(Homo sapiens)
<400> 65
Met Ala Met Gln Met Gln Leu Glu Ala Asn Ala Asp Thr Ser Val Glu
1 5 1015
Glu Glu Ser Phe Gly Pro Gln Pro Ile Ser Arg Leu Glu Gln Cys Gly
202530
Ile Asn Ala Asn Asp Val Lys Lys Leu Glu Glu Ala Gly Phe His Thr
354045
Val Glu Ala Val Ala Tyr Ala Pro Lys Lys Glu Leu Ile Asn Ile Lys
505560
Gly Ile Ser Glu Ala Lys Ala Asp Lys Ile Leu Ala Glu Ala Ala Lys
65707580
Leu Val Pro Met Gly Phe Thr Thr Ala Thr Glu Phe His Gln Arg Arg
859095
Ser Glu Ile Ile Gln Ile Thr Thr Gly Ser Lys Glu Leu Asp Lys Leu
100 105 110
Leu Gln Gly Gly Ile Glu Thr Gly Ser Ile Thr Glu Met Phe Gly Glu
115 120 125
Phe Arg Thr Gly Lys Thr Gln Ile Cys His Thr Leu Ala Val Thr Cys
130 135 140
Gln Leu Pro Ile Asp Arg Gly Gly Gly Glu Gly Lys Ala Met Tyr Ile
145 150 155 160
Asp Thr Glu Gly Thr Phe Arg Pro Glu Arg Leu Leu Ala Val Ala Glu
165 170 175
Arg Tyr Gly Leu Ser Gly Ser Asp Val Leu Asp Asn Val Ala Tyr Ala
180 185 190
Arg Ala Phe Asn Thr Asp His Gln Thr Gln Leu Leu Tyr Gln Ala Ser
195 200 205
Ala Met Met Val Glu Ser Arg Tyr Ala Leu Leu Ile Val Asp Ser Ala
210 215 220
Thr Ala Leu Tyr Arg Thr Asp Tyr Ser Gly Arg Gly Glu Leu Ser Ala
225 230 235 240
Arg Gln Met His Leu Ala Arg Phe Leu Arg Met Leu Leu Arg Leu Ala
245 250 255
Asp Glu Phe Gly Val Ala Val Val Ile Thr Asn Gln Val Val Ala Gln
260 265 270
Val Asp Gly Ala Ala Met Phe Ala Ala Asp Pro Lys Lys Pro Ile Gly
275 280 285
Gly Asn Ile Ile Ala His Ala Ser Thr Thr Arg Leu Tyr Leu Arg Lys
290 295 300
Gly Arg Gly Glu Thr Arg Ile Cys Lys Ile Tyr Asp Ser Pro Cys Leu
305 310 315 320
Pro Glu Ala Glu Ala Met Phe Ala Ile Asn Ala Asp Gly Val Gly Asp
325 330 335
Ala Lys Asp
<210> 66
<211> 375
<212> PRT
<213> 深洋柠檬色微菌JL354
<400> 66
Met Lys Ala Thr Ile Glu Arg Ala Thr Leu Leu Arg Cys Leu Ser His
1 5 1015
Val Gln Ser Val Val Glu Arg Arg Asn Thr Ile Pro Ile Leu Ser Asn
202530
Val Leu Ile Asp Ala Asp Ala Gly Gly Gly Val Lys Val Met Ala Thr
354045
Asp Leu Asp Leu Gln Val Val Glu Thr Met Thr Ala Ala Ser Val Glu
505560
Ser Ala Gly Ala Ile Thr Val Ser Ala His Leu Leu Phe Asp Ile Ala
65707580
Arg Lys Leu Pro Asp Gly Ser Gln Val Ser Leu Glu Thr Ala Asp Asn
859095
Arg Met Val Val Lys Ala Gly Arg Ser Arg Phe Gln Leu Pro Thr Leu
100 105 110
Pro Arg Asp Asp Phe Pro Val Ile Val Glu Gly Glu Leu Pro Thr Ser
115 120 125
Phe Glu Leu Pro Ala Arg Glu Leu Ala Glu Met Ile Asp Arg Thr Arg
130 135 140
Phe Ala Ile Ser Thr Glu Glu Thr Arg Tyr Tyr Leu Asn Gly Ile Phe
145 150 155 160
Leu His Val Ser Asp Glu Ala Arg Pro Val Leu Lys Ala Ala Ala Thr
165 170 175
Asp Gly His Arg Leu Ala Arg Tyr Thr Leu Asp Arg Pro Glu Gly Ala
180 185 190
Glu Gly Met Pro Asp Val Ile Val Pro Arg Lys Ala Val Gly Glu Leu
195 200 205
Arg Lys Leu Leu Glu Glu Ala Leu Asp Ser Asn Val Gln Ile Asp Leu
210 215 220
Ser Ala Ser Lys Ile Arg Phe Ala Leu Gly Gly Glu Gly Gly Val Val
225 230 235 240
Leu Thr Ser Lys Leu Ile Asp Gly Thr Phe Pro Asp Tyr Ser Arg Val
245 250 255
Ile Pro Thr Gly Asn Asp Lys Leu Leu Arg Leu Asp Pro Lys Ala Phe
260 265 270
Phe Gln Gly Val Asp Arg Val Ala Thr Ile Ala Thr Glu Lys Thr Arg
275 280 285
Ala Val Lys Met Gly Leu Asp Glu Asp Lys Val Thr Leu Ser Val Thr
290 295 300
Ser Pro Asp Asn Gly Thr Ala Ala Glu Glu Ile Ala Ala Glu Tyr Lys
305 310 315 320
Ala Glu Gly Phe Glu Ile Gly Phe Asn Ala Asn Tyr Leu Lys Asp Ile
325 330 335
Leu Gly Gln Ile Asp Ser Asp Thr Val Glu Leu His Leu Ala Asp Ala
340 345 350
Gly Ala Pro Thr Leu Ile Arg Arg Asp Glu Asn Ser Pro Ala Leu Tyr
355 360 365
Val Leu Met Pro Met Arg Val
370 375
<210> 67
<211> 89
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 寡核苷酸
<220>
<221> misc_feature
<222> (35)..(36)
<223> iSp9
<400> 67
gttattcaag acttctttaa tacacttttt tttttaatgt acttcgttca gttacgtatt 60
gctttggcgt ctgcttgggt gtttaacct 89
<210> 68
<211> 43
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 寡核苷酸
<400> 68
gtgtattaaa gaagtcttga ataactttga ggcgagcggt caa 43
<210> 69
<211> 30
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 寡核苷酸
<220>
<221> misc_feature
<222> (26)..(26)
<223> 桥接核酸
<220>
<221> modified_base
<222> (27)..(27)
<223> m5c
<220>
<221> misc_feature
<222> (27)..(27)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (28)..(28)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (29)..(29)
<223> 桥接核酸
<220>
<221> misc_feature
<222> (30)..(30)
<223> 桥接核酸
<400> 69
tttgcaatac gtaactgaac gaagtacatt 30
<210> 70
<211> 26
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 前导寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<220>
<221> misc_feature
<222> (26)..(26)
<223> 30iSpC3
<400> 70
ggttaaacac ccaagcagac gccttt 26
<210> 71
<211> 32
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 前导寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<220>
<221> modified_base
<222> (27)..(27)
<223> t
<220>
<221> modified_base
<222> (28)..(28)
<223> t
<220>
<221> modified_base
<222> (29)..(29)
<223> t
<220>
<221> modified_base
<222> (30)..(30)
<223> t
<220>
<221> modified_base
<222> (31)..(31)
<223> t
<220>
<221> misc_feature
<222> (32)..(32)
<223> 30iSpC3
<220>
<221> modified_base
<222> (32)..(32)
<223> t
<400> 71
ggttaaacac ccaagcagac gcctttuuuu uu 32
<210> 72
<211> 25
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 前导寡核苷酸
<220>
<221> misc_feature
<222> (1)..(1)
<223> 5'磷酸
<220>
<221> modified_base
<222> (24)..(24)
<223> t
<220>
<221> modified_base
<222> (25)..(25)
<223> t
<220>
<221> misc_feature
<222> (25)..(25)
<223> 30iSpC3
<400> 72
ggttaaacac ccaagcagac gccuu 25
- 纳米孔,使用纳米孔的方法,制备纳米孔的方法和用纳米孔表征生物分子的方法
- 重复移动双链多核苷酸通过纳米孔的方法