基于视线信息识别痴呆症的方法
文献发布时间:2024-01-17 01:17:49
技术领域
本发明涉及痴呆症识别方法,具体地,涉及利用基于测试的用户视线信息识别痴呆症的装置及其方法。
背景技术
阿尔茨海默病(AD,Alzheimer's Disease)作为随着衰老产生的脑部疾病,将导致进行性记忆障碍、认知缺陷、个人性格变化等。而且,痴呆症(dementia)是指正常生活的人因多种原因引起的大脑功能受损而导致整体认知能力持续下降的状态。其中,认知能力是指记忆力、语言能力、时空间掌握能力、判断能力及抽象思维能力等多种智力,各个认知能力与大脑的特定部位密切相关。最常见的痴呆症为阿尔茨海默病。
用于诊断阿尔茨海默病、痴呆症或轻度认知障碍的方法有多种。例如,已知有利用嗅觉组织的miR-206的表达水平诊断阿尔茨海默病或轻度认知障碍的方法、利用血液内特征性增加的生物标志物诊断痴呆症的方法。
但是,为了利用嗅觉组织的miR-206而需要用于组织检测的特殊设备或进行检验,而且,为了利用血液内的生物标记物而需要通过侵入方式采集患者的血液,因此,存在患者的反感相对较大的缺点。
所以,当前急需开发在没有特殊设备或进行检验的情况下几乎不会使患者感到反感的痴呆症诊断方法。
现有技术文献
专利文献
专利文献1:韩国专利申请号10-2019-0135908(申请日:2019年02月01日)
发明内容
本发明用于解决上述问题及其他问题。本发明的目的在于,提供通过使患者不会感到反感的方法精确诊断痴呆症的方法。
本发明所要实现的目的并不限定于以上提及的目的,本发明所属技术领域的普通技术人员可通过以下记载内容明确理解未提及的其他目的。
本发明实施例的痴呆症识别方法由装置的至少一个处理器执行,上述痴呆症识别模型学习方法可包括如下步骤:执行第一任务,在用户终端显示的画面中的第一区域上显示第一对象;以及执行第二任务,当满足预设条件时,使得至少一个对象显示在上述用户终端的上述画面,上述至少一个对象代替上述第一对象引导用户视线的移动。
根据本发明实施例,上述痴呆症识别模型学习方法还可包括如下步骤,按照预设次数执行上述第一任务及上述第二任务。
根据本发明实施例,上述痴呆症识别模型学习方法还可包括如下步骤:在按照上述预设次数执行上述第二任务的过程中,获得有关上述用户的视线信息;向痴呆症识别模型输入上述视线信息来计算分数值;以及基于上述分数值确定是否患有痴呆症。
根据本发明实施例,在按照上述预设次数执行上述第二任务的过程中,上述装置从上述用户终端接收包括上述用户的眼睛在内的影像后,上述装置通过分析上述影像来生成上述视线信息。
根据本发明实施例,上述视线信息作为上述装置从上述用户终端接收的信息,在按照上述预设次数执行上述第二任务的过程中,上述用户终端可通过分析包括上述用户的眼睛在内的影像来生成。
根据本发明实施例,上述视线信息可包括正确执行次数信息、错误执行次数信息、持续凝视信息、消耗时间信息、移动速度信息及正确凝视信息中的至少一个,上述正确执行次数信息为上述用户正确执行预设视线问题的次数,上述错误执行次数信息为上述用户错误执行上述预设视线问题的次数,上述持续凝视信息为上述用户的视线在预设时间内是否持续凝视特定位置的信息,上述消耗时间信息为上述用户的视线从显示包括上述至少一个对象在内的画面开始移动到上述至少一个对象中的一个对象的消耗时间,上述移动速度信息为上述用户的视线移动速度,上述正确凝视信息为上述用户的视线是否正确凝视上述预设视线问题相关位置的信息。
根据本发明实施例,上述至少一个对象包括文本、第二对象及第三对象,上述文本代替上述第一对象显示在上述第一区域上,上述第二对象及第三对象分别显示在不同于上述第一区域的第二区域及第三区域,上述第一区域位于上述第二区域与上述第三区域之间,上述预设视线问题可包括如下问题中的至少一个:在上述第二对象及上述第三对象中凝视与上述文本的含义有关的对象;在上述第二对象及上述第三对象中凝视与上述文本的含义无关的对象;在上述第二对象及上述第三对象中凝视与上述文本的颜色有关的对象;以及在上述第二对象及上述第三对象中凝视与上述文本的颜色无关的对象。
根据本发明实施例,上述至少一个对象包括视线引导对象,显示在不同于上述第一区域的第二区域及第三区域中的一个区域,上述第一区域位于上述第二区域与上述第三区域之间,上述预设视线问题可包括如下问题中的至少一个:凝视上述视线引导对象;以及凝视与上述视线引导对象的定位方向相反的方向。
根据本发明实施例,上述预设条件可以为通过分析在执行上述第一任务的过程中获得的影像来识别为上述用户在预设时间内凝视上述第一对象的情况。
根据本发明实施例,当识别上述用户的瞳孔焦点位置存在于预设区域内时,可满足上述预设条件。
根据本发明实施例,上述预设区域的尺寸可取决于上述瞳孔的尺寸。
根据本发明实施例,当上述用户的瞳孔坐标值在上述预设时间内具有预设坐标值时,可满足上述预设条件。
本发明实施例的计算机程序存储在计算机可读存储介质,当装置的至少一个处理器运行上述计算机程序时,执行痴呆症识别步骤,上述痴呆症识别步骤可包括如下步骤:执行第一任务,在用户终端显示的画面中的第一区域上显示第一对象;以及执行第二任务,当满足预设条件时,使得至少一个对象显示在上述用户终端的上述画面,上述至少一个对象代替上述第一对象引导用户视线的移动。
本发明实施例的痴呆症识别装置包括:存储部,用于存储至少一个程序指令;以及至少一个处理器,用于执行上述至少一个程序指令,上述至少一个处理器可执行如下步骤:执行第一任务,在用户终端显示的画面中的第一区域上显示第一对象;以及执行第二任务,当满足预设条件时,使得至少一个对象显示在上述用户终端的上述画面,上述至少一个对象代替上述第一对象引导用户视线的移动。
本发明所要实现的技术方案并不限定于以上提及的方案,本发明所属技术领域的普通技术人员可通过以下记载内容明确理解未提及的其他技术方案。
以下,对本发明的痴呆症识别技术相关效果进行说明。
根据本发明实施例,可通过使患者不会感到反感的方法精确诊断痴呆症。
可通过本发明获得的效果并不限定于以上提及的效果,本发明所属技术领域的普通技术人员可通过以下记载内容明确理解未提及的其他效果。
附图说明
以下,参照附图说明本发明多个实施例,其中,相似的附图标记概括表示相似的结构要素。在以下实施例中,为了说明层面上的便利性,多个特定细节用于整体理解一个以上实施例而提供。但应当理解的是,这种实施例也可在没有这种具体细节的前提下实施。
图1为用于说明本发明实施例的痴呆症识别系统的简图。
图2为用于说明本发明实施例的装置获得痴呆症识别影像的方法一例的流程图。
图3为用于说明本发明实施例的用户终端获得痴呆症识别影像时显示的画面一例的图。
图4为用于说明本发明实施例的用户终端的用户是否满足预设条件的识别方法一例的图。
图5及图6为用于说明本发明实施例的用户终端获得视线信息时显示的画面一例的图。
图7为用于说明本发明实施例的装置利用视线信息确定用户是否患有痴呆症的方法一例的流程图。
图8为用于说明本发明实施例的获得视线信息的方法一例的图。
具体实施方式
以下,参照附图详细说明有关本发明的装置及装置控制方法的多个实施例,与附图标记并无关联,对于相同或相似的结构要素赋予了相同的附图标记,因此,将省略对其的重复说明。
本发明的目的、效果及实现它们的技术结构可通过参照附图一并说明的实施例变得更加明确。在说明本发明多个实施例的过程中,当判断有关公知技术的具体说明有可能不必要地混淆本发明多个实施例的主旨时,将省略其详细说明。
本发明的术语作为考虑本发明中的功能而定义的术语,可基于使用人员、操作人员的意图或惯例等产生变化。并且,附图仅用于方便理解本发明的一个以上实施例,本发明的技术思想并不限定于附图,应理解为包括本发明的思想及技术范围内的所有变更、等同技术方案、代替技术方案。
在以下说明中,对于结构要素的后缀词“模块”及“部”仅为考虑编写本发明的便利性而赋予或混合使用的,其本身并没有相互区分的含义或作用。
虽然“第一”或“第二”等术语可用于说明多种结构要素,但是,上述结构要素并不限定于上述术语。上述术语仅用于对一个结构要素和其他结构要素进行区分。因此,以下提及的第一结构要素也可在本发明的技术思想范围内成为第二结构要素。
除非在文脉上明确表示其他含义,否则单数的表达包括复数的表达。即,除非另有说明或在文脉上未明确表示成单数,否则本发明和权利要求中的单数通常应解释为“一个或一个以上”的含义。
在本说明书中,“包括”、“包含”或“具备”等术语仅用于指定本说明书中所记载的特征、数字、步骤、工作、结构要素、部件或它们的组合的存在,并不预先排除一个或一个以上的其他特征、数字、步骤、工作、结构要素、部件或它们的组合的存在或附加可能性。
在本说明书中,术语“或”为内置含义的“或”,而并非排他含义的“或”。即,除非另有说明或在文脉上未明确表示的情况下,“X利用A或B”表示自然内置取代中的一种含义。即,表示“X利用A或X利用B或X利用A及B”的情况,“X利用A或B”可用于其中任一情况。并且,在本说明书中,应将所使用的术语“和/或”理解为包括可组合相关列出项目中的一个以上项目的所有组合。
在本说明书中,所使用的术语“信息”及“数据”可相互交换使用。
除非另有定义,否则在此使用的所有术语(包括技术术语及科学术语在内)与本发明所属技术领域的普通技术人员通常理解的含义相同。并且,除非在本说明书中明确定义,一般使用的词典中定义的术语不应过度解释。
然而,本发明并不限定于以下公开的实施例,可通过不同实施方式实现。本发明实施例仅用于本发明所属技术领域的普通技术人员能够完全理解本发明的范畴而提供,本发明仅限定于权利要求的范畴。因此,应基于本说明书的全文内容加以定义。
根据本发明实施例,装置的至少一个处理器(以下,称为“处理器”)可利用痴呆症识别模型确定用户是否患有痴呆症。具体地,在获得用户视线信息的情况下,处理器可向痴呆症识别模型输入视线信息来获得分数值。而且,处理器可基于分数值确定用户是否患有痴呆症。以下,参照图1至图8说明痴呆症识别方法。
图1为用于说明本发明实施例的痴呆症识别系统的简图。
参照图1,痴呆症识别系统可包括痴呆症识别装置100及识别痴呆症所需的用户的用户终端200。而且,装置100与用户终端200可通过有线网络/无线网络300连接通信。但是,在实现痴呆症识别系统的层面上,组成图1所示系统的结构要素并非必不可少,相比于以上提及的结构要素,可具有更多或更少的结构要素。
本发明的装置100可通过有线网络/无线网络(wire/wireless network)300与用户终端200配对或连接(pairing or connecting),由此,可收发规定数据。在此情况下,通过有线网络/无线网络300收发的数据可在收发前转换(converting)。其中,“有线网络/无线网络300”是指用于装置100与用户终端200之间的配对和/或为了收发数据而支持多种通信标准和通信协议的通信网络。这种有线网络/无线网络300包括当前或将来根据标准支持的所有通信网络,并且,可支持用于其的一种或一种以上的所有通信协议。
痴呆症识别装置100可包括处理器110、存储部120及通信部130。在实现装置100的层面上,图1所示的结构要素并非必不可少,因此,相比于以上提及的结构要素,本发明说明的装置100可包括更多或更少的结构要素。
在本发明的装置100中,根据实际实现的装置100规格,各个结构要素可被集成、添加或省略。即,根据需求,两个以上的结构要素可结合成一个结构要素或一个结构要素可分化成两个以上的结构要素。并且,各个模块执行的功能仅用于说明本发明实施例,其具体工作或装置并不限定本发明的发明要求保护范围。
本发明的装置100可包括执行发送和接收数据(data)、内容(content)、服务(service)及应用程序(application)等中的一项以上的所有设备。但并不限定于此。
例如,本发明的装置100可包括服务器(server)、个人计算机(PC,PersonalComputer)、微型处理器、大型计算机、数字处理器、设备控制器等固定型设备(standingdevice)及智能手机(Smart Phone)、平板电脑(Tablet PC)、笔记本电脑(Notebook)等移动设备(mobile device or handheld device)。但并不限定于此。
在本发明中,“服务器”为多种用户终端,即,是指通过客户端(client)提供数据或从客户端接收数据的装置或系统。例如,服务器可包括提供网页(web page)、网页内容或网页服务(web content or web service)的网页服务器(Web server)或门户服务器(portalserver)、提供广告数据(advertising data)的广告服务器(advertising server)、提供内容的内容服务器(content server)、提供社交网络服务(SNS,Social Network Service)的社交网络服务器、制造商(manufacturer)提供的服务服务器(service server)、用于提供视频点播(VoD,Video on Demand)或流式传输(streaming)服务的多通道视频节目分配器(MVPD,Multichannel Video Programming Distributor)、提供付费服务(pay service)的服务服务器等。
在本发明中,在被命名为装置100的情况下,其含义根据文脉是指服务器,但是,也可意味着固定型设备或移动设备,除非另有说明,否则也可包括所有含义。
在通常情况下,除应用程序相关工作外,处理器110可控制装置100的整体工作。处理器110可对通过装置100的结构要素输入或输出的信号、数据、信息等进行处理,或者,可通过驱动存储在存储部120的应用程序来提供或处理适当信息或功能。
为了驱动存储在存储部120的应用程序,处理器110可控制装置100的结构要素中的至少一部分。而且,为了驱动应用程序,处理器110可组合装置100包括的两个以上结构要素进行工作。
处理器110可由一个以上芯组成,可以为多种常用处理器中的任意处理器。例如,处理器110可包括装置的中央处理器(CPU,Central Processing Unit)、通用图形处理器(GPUGP,General Purpose Graphics Processing Unit)、张量处理器(TPU,TensorProcessing Unit)等。但并不限定于此。
本发明的处理器110可由双处理器或其他多处理器架构组成。但并不限定于此。
处理器110可读取存储在存储器120的计算机程序并利用本发明实施例的痴呆症识别模型来识别用户是否患有痴呆症。
存储部120可存储支持装置100的多种功能的数据。存储部120可存储装置100驱动的多个应用程序(application program)或应用(application)、用于装置100工作的多种数据、多个指令、多个程序指令。这种应用程序中的至少一部分可通过无线通信从外部服务器下载。并且,为了实现装置100的基本功能,这种应用程序中的至少一部分可从出厂时就存在于装置100上。另一方面,应用程序存储在存储部120并设置在装置100上,可通过处理器110执行装置100的工作(或功能)。
存储部120可存储由处理器110生成或确定的任何类型的信息及通过通信部130接收的任何类型的信息。
存储部120可包括闪存型(flash memory type)、硬盘型(hard disk type)、固态盘型(SSD,Solid State Disk type)、硅磁盘驱动器型(SDD,Silicon Disk Drive type)、微型多媒体记忆卡(multimedia card micro type)、卡型的存储器(例如,SD卡或XD卡等)、随机存取存储器(RAM,random access memory)、静态随机存取存储器(SRAM,staticrandom access memory)、只读存储器(ROM,read-only memory)、带电可擦可编程只读存储器(EEPROM,electrically erasable programmable read-only memory)、可编程只读存储器(PROM,programmable read-only memory))、磁存储器、磁盘及光盘中的至少一种存储介质。装置100也可通过在互联网(internet)上执行存储部120的存储功能的网络存储进行工作。
通信部130可包括使得装置100与有线通信/无线通信系统之间、装置100与其他装置之间或装置100与外部服务器之间能够进行有线通信/无线通信的一个以上模块。并且,通信部130可包括使得装置100连接一个以上网络的一个以上模块。
通信部130是指用于有线网络连接/无线网络连接的模块,可内置或外置在装置100。通信部130可收发有线信号/无线信号。
通信部130可在用于移动通信的技术标准或通信方式(例如,GSM(Global Systemfor Mobile communication)、CDMA(Code Division Multi Access)、CDMA2000(CodeDivision Multi Access 2000)、EV-DO(Enhanced Voice-Data Optimized or EnhancedVoice-Data Only)、WCDMA(Wideband CDMA)、HSDPA(High Speed Downlink PacketAccess)、HSUPA(High Speed Uplink Packet Access)、LTE(Long Term Evolution)、LTE-A(Long Term Evolution-Advanced)等构建的移动通信网上与基站、外部终端及服务器中的一个收发无线信号。
例如,作为无线网络技术可利用WLAN(Wireless LAN)、Wi-Fi(Wireless-Fidelity)、Wi-Fi(Wireless Fidelity)Direct、DLNA(Digital Living NetworkAlliance)、WiBro(Wireless Broadband)、WiMAX(World Interoperability forMicrowave Access)、HSDPA(High Speed Downlink Packet Access)、HSUPA(High SpeedUplink Packet Access)、LTE(Long Term Evolution)、LTE-A(Long Term Evolution-Advanced)等。但是,通信部130可通过包括以上未示出的网路技术范围内的至少一种无线网络技术收发数据。
并且,通信部130也可通过近距离通信(Short range communication)收发信号。例如,通信部130可利用蓝牙(Bluetooth
本发明实施例的装置100可通过通信部130使得用户终端200与有线网络/无线网络300相连接。
在本发明中,用户终端200可通过有线网络/无线网络(wire/wireless network)300与存储痴呆症识别模型的装置100配对或连接(pairing or connecting),由此,可收发并显示规定数据。
本发明的用户终端200可包括执行发送、接收及显示数据(data)、内容(content)、服务(service)及应用程序(application)等中的一项以上的所有设备。而且,用户终端200是指需确认痴呆症的用户终端。但并不限定于此。
例如,本发明的用户终端200可包括手机、智能手机(smart phone)、平板电脑(tablet PC)、超极本(ultrabook)等移动终端(mobile device)。但并不限定于此,用户终端200还可包括个人计算机(PC,Personal Computer)、微型处理器、大型计算机、数字处理器、设备控制器等固定型设备(standing device)。
用户终端200可包括处理器210、存储部220、通信部230、影像获取部240、显示部250、声音输出部260。在实现用户终端200的层面上,图1所示的结构要素并非必不可少,相比于以上提及的结构要素,本发明的用户终端200可具有更多或更少的结构要素。
在本发明的用户终端200中,根据实际实现的用户终端200规格,各个结构要素可被集成、添加或省略。即,根据需求,两个以上的结构要素可结合成一个结构要素或一个结构要素可分化成两个以上的结构要素。并且,各个模块执行的功能仅用于说明本发明实施例,其具体工作或装置并不限定本发明的发明要求保护范围。
用户终端200的处理器210、存储部220及通信部230与装置100的处理器110、存储部120及通信部130属于相同结构要素,因此,将省略重复说明,并且,以下着重说明不同之处。
在本发明中,在显示用于识别痴呆症的画面之前,用户终端200的处理器210可控制显示部250在第一区域上显示第一对象。而且,当满足预设条件时,用户终端200可控制显示部250显示至少一个对象来代替第一对象引导用户视线的移动。对此,以下参照图2详细说明。
另一方面,为了执行利用痴呆症识别模型的运算而需要高处理速度及高运算能力,因此,痴呆症模型仅存储在装置100的存储部120,可未存储在用户终端200的存储部220。但并不限定于此。
影像获取部240可包括一个或多个摄像头。即,用户终端200可以为在前表面或后表面中的至少一个包括一个或多个摄像头的装置。
影像获取部240可处理通过图像传感器获得的静态影像或动态影像等的图像帧。被处理的图像帧可显示在显示部250或存储在存储部220。另一方面,设置在用户终端200的影像获取部240可使得多个摄像头匹配形成矩阵结构。可通过以这种方式形成矩阵结构的摄像头来使得用户终端200接收具有多种角度或焦点的多个影像信息。
本发明的影像获取部240可包括沿着至少一个线排列而成的多个镜头。多个镜头可被排列成行列(matrix)形式。这种摄像头可被命名为阵列摄像机。若影像获取部240为阵列摄像机,则可利用多个镜头按照多种方式拍摄影像,而且,可获得更高质量的影像。
根据本发明实施例,影像获取部240可通过在用户终端200显示特定画面来获得包括用户终端的用户眼睛在内的影像。
显示部250可显示(输出)用户终端200处理的信息。例如,显示部250可显示用户终端200驱动的应用程序的运行画面信息或基于这种运行画面信息的用户界面(UI,UserInterface)、图形用户界面(GUI,Graphic User Interface)信息。
显示部250可包括液晶显示器(LCD,liquid crystal display)、薄膜晶体管液晶显示器(TFT LCD,thin film transistor-liquid crystal display)、有机发光二极管(OLED,organic light-emitting diode)、软性显示器(flexible display)、三维显示器(3D display)、电子墨水显示器(e-ink display)中的至少一个。但并不限定于此。
根据本发明实施例,当执行第一任务时,显示部250可在画面的第一区域上显示第一对象(例如,十字形对象)。而且,当执行第二任务时,显示部250可在画面的第一区域上显示至少一个对象来代替第一对象引导用户视线的移动。
声音输出部260可输出从通信部230接收或存储在存储部220的音频数据(或声音数据)。声音输出部260也可输出与用户终端200执行的功能相关的声音信号。
声音输出部260可包括接收器(receiver)、扬声器(speaker)、蜂鸣器(buzzer)等。即,声音输出部260可以为接收器(receiver),也可以为扩音器(loud speaker)。但并不限定于此。
根据本发明实施例,声音输出部260可通过执行第一任务、第二任务来输出预设声音(例如,对用户通过第一任务、第二任务执行的工作进行说明的语音)。但并不限定于此。
根据本发明实施例,装置100可从用户终端200获得包括用户眼睛在内的影像来确定用户是否患有痴呆症。但是,用户终端200为固定终端,当获得影像时,需要经过特殊任务。以下,参照图2说明用于获得包括用户眼睛在内的影像的方法。
图2为用于说明本发明实施例的装置获得痴呆症识别影像的方法一例的流程图,图3为用于说明本发明实施例的用户终端获得痴呆症识别影像时显示的画面一例的图,图4为用于说明本发明实施例的用户终端的用户是否满足预设条件的识别方法一例的图,图5及图6为用于说明本发明实施例的用户终端获得视线信息时显示的画面一例的图。在以下对于图2至图6的说明中,将省略参照图1说明的重复内容并着重说明不同之处。
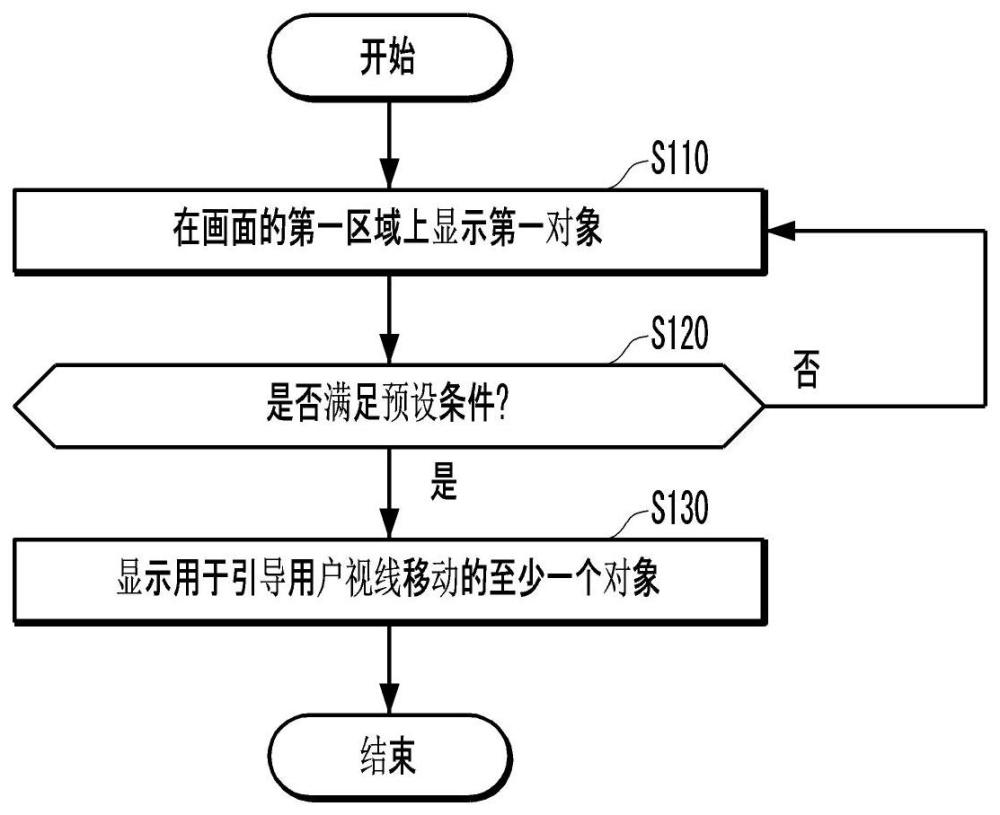
参照图2,装置100的处理器110可执行第一任务,使得用户终端200在显示画面的第一区域上显示第一对象(步骤S110)。
作为一例,装置100的处理器110可在第一区域上生成显示包括第一对象的画面并向用户终端200传输。在此情况下,用户终端200可显示在第一区域上包括第一对象的画面。
作为再一例,用户终端200的存储部220可存储在第一区域上包括第一对象的画面。当通过通信部230接收显示存储在存储部220的上述画面的信息时,用户终端200的处理器210可通过控制显示部250来在用户终端200显示上述画面。
作为另一例,第一对象的图像可存储在用户终端200的存储部220。在此情况下,若装置100的处理器110通过通信部130向用户终端200传输显示包括第一对象的画面的信号,则用户终端200的处理器210可在第一区域上生成显示包括第一对象的画面。
但是,上述示例仅为例示,本发明并不限定于上述示例。
参照图3,显示在用户终端200的画面可在第一区域R1包括第一对象O1。
第一对象O1可以为用于引导用户视线的对象,使得用户视线位于显示画面的中心。例如,第一对象O1可以为具有十字形状的对象。但并不限定于上述示例,第一对象O1可具有多种形状或轮廓。
第一区域R1可以为位于画面正中心的区域。因此,凝视第一对象O1的用户视线可位于画面的中心。但并不限定于此。
另一方面,根据本发明实施例,在用户终端200显示的画面可包括通过当前显示的画面通知用户需执行的工作是什么内容的消息M1。例如,消息M1可包如下内容,即,请凝视显示在当前画面的第一对象O1。并且,用户终端200可通过显示部250在画面上显示消息M1并通过声音输出部260输出有关消息M1的声音(例如,用于说明消息M1内容的语音)。如上所述,随着与消息M1一并输出声音,当向用户通知用户要执行的工作时,可使得用户明确理解当前要执行的工作。因此,可降低因简单失误而执行错误工作的可能性。
再次参照图2,在步骤S110中,当第一对象显示在画面的第一区域上时,装置100的处理器110可确定是否满足预设条件(步骤S120)。
作为一例,随着在显示画面的第一区域R1上显示第一对象O1(执行第一任务),用户终端200可通过影像获取部240获得包括用户终端的用户眼睛在内的影像。由此,可通过用户终端200分析影像来确定是否满足预设条件。而且,在用户终端200确定满足预设条件的情况下,用户终端200的处理器210可通过通信部230向装置100传输满足预设条件的信号。在此情况下,装置100可识别满足预设条件。
作为再一例,随着在显示画面的第一区域R1上显示第一对象O1(执行第一任务),用户终端200可通过影像获取部240获得包括用户终端的用户眼睛在内的影像。用户终端200可控制通信部230向装置100传输所获得的影像。当通过通信部130接收包括用户眼睛在内的影像时,装置100的处理器110可通过分析上述影像来确定是否满足预设条件。
但是,上述示例仅为例示,本发明并不限定于上述示例。
上述预设条件可以为通过分析在执行第一任务的过程中(即,在第一区域R1上显示第一对象O1的期间)获得的影像来识别第一用户在预设时间内凝视第一对象的情况。
作为一例,参照图4,预设条件可以为识别用户U的瞳孔E焦点M位置在预设区域R
具体地,装置100的处理器110可以仅利用所获得的影像包括的多个帧的各个RGB值中的B值来在多个帧中确定用户U的瞳孔E位置。即,处理器110可在多个帧中将具有大于预设临界值的B值的区域识别为瞳孔E定位区域。而且,当识别瞳孔E定位区域的中心点位置存在于预设区域R
作为再一例,预设条件可以为用户瞳孔E的坐标值在预设时间内具有预设坐标值的情况。其中,瞳孔E的坐标值可以为瞳孔E焦点M的坐标值,也可以为瞳孔E边缘的坐标值。而且,当用户凝视用户终端200的显示部的正中心时,预设坐标值可以为瞳孔E位置的坐标值。但并不限定于此。
根据本发明实施例,处理器110可从所获得的影像中区分瞳孔E和背景。而且,处理器110可将瞳孔E位置相应部分变更为黑色并将背景相应部分变更为白色来执行二值化(binarization)过程。而且,在经过二值化过程后,处理器110可应用洪水覆盖算法(floodfill)去除噪声。其中,洪水覆盖算法是指将黑色像素包括的白色像素变为黑色像素并将白色像素包括的黑色像素变为白色像素的工作。随后,处理器110可利用所获得的影像识别瞳孔的中心点位置是否位于预设区域R
根据本发明实施例,预设区域R
更具体地,当获得包括用户U眼睛在内的影像时,处理器110可通过分析影像来识别瞳孔E的尺寸。而且,处理器110可基于瞳孔E尺寸确定预设区域R
根据本发明实施例,当显示包括第一对象O1的画面时,用户终端200的处理器210可激活影像获取部240来获得包括用户眼睛在内的影像。在此情况下,处理器210可确定在影像内是否包括用户眼睛。若处理器210识别影像并不包括用户眼睛,则处理器210可持续获得影像并控制显示部250显示第一对象O1位于第一区域R1上的画面。但并不限定于此。
再次参照图2,当识别无法满足预设条件时(步骤S120,否),装置100的处理器110可在用户终端200显示画面的第一区域上持续显示第一对象(步骤S110)。
另一方面,当装置100识别满足预设条件时(步骤S120,是),装置100的处理器110可执行第二任务,使得至少一个对象显示在用户终端200的画面并代替第一对象引导用户视线的移动(步骤S130)。
作为有关步骤S130的一例,装置100的处理器110可执行子任务,使得用户终端200显示包括第二对象、第三对象及文本在内的画面。在此情况下,用户终端200可代替第一对象在第一区域上显示文本来向第二区域及第三区域分别显示第二对象及第三对象。即,至少一个对象可包括文本、第二对象及第三对象,上述文本代替第一对象显示在第一区域上,上述第二对象及第三对象分别显示在不同于第一区域的第二区域及第三区域。
更加具体地,参照图5,在满足预设条件的情况下,用户终端200显示的画面可在第一区域代替第一对象(图3的O1)包括文件T,可在不同于第一区域R1的第二区域R2及第三区域R3分别包括第二对象O2及第三对象O3。其中,包括第二对象O2、第三对象O3及文本T的画面可显示2000ms。但并不限定于此。
第二对象O2及第三对象O3具有相同形状(例如,直径0.2cm的圆形灯),仅颜色互不相同。在此情况下,第二对象O2及第三对象O3中的一个对象可具有表示文本T的颜色,其他对象可具有与文本T不同的颜色。但并不限定于此,第二对象O2及第三对象O3可具有不同形状,颜色也互不相同。
第一区域R1可位于第二区域R2与第三区域R3之间。即,第二区域R2及第三区域R3可位于以第一区域R1为正中心的两侧面。但并不限定于此。
文本T可以为表示颜色或形状的单词。但是,文本T的含义并不限定于上述示例。
若文本T的含义有关颜色,则文本T本身的颜色可以与文本T表示的颜色相同或不同。但并不限定于此。
另一方面,根据本发明实施例,可在用户终端200显示画面上显示通知用户需执行的预设视线问题是什么内容的消息M2。其中,预设视线问题可以为用户需凝视那种对象的问题。
根据实施例,预设视线问题可以为如下问题,即,在第二对象O2及第三对象O3中凝视与文本T含义有关的对象。在此情况下,文本T的含义可以与形状有所关联,也可以与颜色有所关联。但是,文本T的含义并不限定于上述示例。
作为一例,文本T表示红色,第二对象O2为红色,第三对象O3可以为蓝色。而且,显示在画面的消息M2可包括如下内容,即,请凝视与文本T表示颜色相关的对象。在此情况下,用户凝视第二对象O2可意味着用户正确执行预设问题。
作为再一例,虽未图示,文本T表示圆形,第二对象O2为圆形,第三对象O3可以为四边形。而且,显示在画面的消息M2可包括如下内容,即,请凝视与文本T表示形状相关的对象。在此情况下,用户凝视第二对象O2可意味着用户正确执行预设问题。
根据再一实施例,预设视线问题可以为如下问题,即,在第二对象O2及第三对象O3中凝视与文本T含义无关的对象。在此情况下,文本T的含义可以与形状有所关联,也可以与颜色有所关联。但是,文本T的含义并不限定于上述示例。
作为一例,文本T表示红色,第二对象O2为红色,第三对象O3可以为蓝色。而且,显示在画面的消息M2可包括如下内容,即,请凝视与文本T表示颜色无关的对象。在此情况下,用户凝视第三对象O3可意味着用户正确执行预设问题。
作为再一例,文本T表示圆形,第二对象O2为圆形,第三对象O3可以为四边形。而且,显示在画面的消息M2可包括如下内容,即,请凝视与文本T表示形状无关的对象。在此情况下,用户凝视第三对象O3可意味着用户正确执行预设问题.
根据再一实施例,预设视线问题可以为如下问题,即,在第二对象O2及第三对象O3中凝视与文本T本身颜色相关的对象。在此情况下,文本T本身的颜色可以与文本T的含义不同,也可以与文本T的含义相同。
作为一例,文本T表示红色,第二对象O2为红色,第三对象O3可以为蓝色。而且,显示在画面的消息M2可包括如下内容,即,请凝视与具有文本T颜色的对象。在此情况下,用户凝视第二对象O2可意味着用户正确执行预设问题。
作为再一例,文本T表示红色,文本T的颜色可以为与文本T含义不同的蓝色,第二对象O2为红色,第三对象O3可以为蓝色。而且,显示在画面的消息M2可包括如下内容,即,请凝视具有文本T颜色的对象。在此情况下,用户凝视第三对象O3可意味着用户正确执行预设问题。
根据再一实施例,预设视线问题可以为如下问题,即,在第二对象O2及第三对象O3中凝视与文本T本身颜色无关的对象。在此情况下,文本T本身的颜色可以与文本T的含义不同,也可以与文本T的含义相同。
作为一例,文本T表示红色,文本T的颜色可以为红色,第二对象O2为红色,第三对象O3可以为蓝色。而且,显示在画面的消息M2可包括如下内容,即,请凝视未具有文本T颜色的对象。在此情况下,用户凝视第三对象O3可意味着用户正确执行预设问题。
作为再一例,文本T表示红色,文本T的颜色可以为与文本T含义不同的蓝色,第二对象O2为红色,第三对象O3可以为蓝色。而且,显示在画面的消息M2可包括如下内容,即,请凝视未具有文本T颜色的对象。在此情况下,用户凝视第二对象O2可意味着用户正确执行预设问题。
另一方面,用户终端200通过显示部250在画面上显示消息M2并通过声音输出部260输出有关消息M2的声音(例如,用于说明消息M2内容的语音)。如上所述,随着与消息M2一并输出声音,当向用户通知用户要执行的预设视线问题时,可使得用户明确理解当前要执行的预设视线问题。因此,可降低因简单失误而执行错误工作的可能性。
结果,预设视线问题可包括如下问题中的至少一个:在上述第二对象及上述第三对象中凝视与上述文本的含义有关的对象;在上述第二对象及上述第三对象中凝视与上述文本的含义无关的对象;在上述第二对象及上述第三对象中凝视与上述文本的颜色有关的对象;以及在上述第二对象及上述第三对象中凝视与上述文本的颜色无关的对象。而且,显示在画面的消息M2可包括预设视线问题是什么的内容。
作为有关步骤S130的再一例,装置100的处理器110可执行子任务,使得用户终端200在不同于第一区域的第二区域及第三区域中的一个区域显示视线引导对象。在此情况下,用户终端200可代替显示第一对象在不同于第一区域的第二区域或第三区域显示视线引导对象。即,至少一个对象可包括视线引导对象,显示在不同于第一区域的第二区域及第三区域中的一个区域。
更加具体地,参照图6的(a)部分及(b)部分,在满足预设条件的情况下,用户终端200的显示画面可包括视线引导对象O4,显示在不同于图3的第一区域R1的第二区域R2及第三区域R3中的一个区域R2。其中,可随机选择第二区域R2及第三区域R3中的一个区域,包括视线引导对象O4的画面可显示2000ms。但并不限定于此。
视线引导对象O4可以为具有预设形状(例如,直径0.2cm的圆形等)和预设颜色(例如,红色)的对象。
第一区域R1可位于第二区域R2与第三区域R3之间。即,第二区域R2及第三区域R3可位于以第一区域R1为正中心的两侧面。但并不限定于此。
另一方面,根据本发明实施例,可在用户终端200的显示画面上显示通知用户需执行的预设视线问题是什么内容的消息M3、M4。其中,预设视线问题可以为用户需凝视那种对象的问题。
参照图6的(a)部分,预设视线问题可以为凝视视线引导对象O4。而且,显示在画面的消息M3可包括快速凝视视线引导对象O4的内容。在此情况下,用户凝视视线引导对象O4可意味着用户正确执行预设问题。
参照图6的(b)部分,预设视线问题可以为凝视与视线引导对象O4的定位方向相反的方向。而且,显示在画面的消息M4可包括快速凝视视线引导对象O4的内容。在此情况下,用户凝视与视线引导对象O4的定位方向相反的方向可意味着用户正确执行预设问题。
另一方面,用户终端200通过显示部250在画面上显示消息M3、M4并通过声音输出部260输出有关消息M3或消息M4的声音(例如,用于说明消息M3或消息M4内容的语音)。如上所述,随着与消息M3或消息M4一并输出声音,当向用户通知用户要执行的预设视线问题时,可使得用户明确理解当前要执行的预设视线问题。因此,可降低因简单失误而执行错误工作的可能性。
结果,预设视线问题可包括如下问题中的至少一个:凝视视线引导对象;以及凝视与视线引导对象的定位方向相反的方向。而且,显示在画面的消息M3或消息M4可包括预设视线问题是什么的内容。
再次参照图2,装置100的处理器110可按照预设次数(例如,5次)执行第一任务和第二任务。即,处理器110在用户终端200显示图3所示的画面后,若识别用户视线凝视中心,则可按照预设次数执行任务,使得图5或图6所示的画面显示在用户终端200。
在本发明执行任务之前(即,执行第二任务之前),当执行第一任务来使得用户视线移动到中心时,即使未向用户终端200添加额外结构要素,也可精确识别痴呆症。
另一方面,当非痴呆症患者的普通人未凝视中心而凝视显示在画面左侧或画面右侧的对象时,可因视线未快速移动而将非痴呆症患者确定为痴呆症。因此,凝视中心后,用户需凝视显示在画面左侧或画面右侧的对象才能提高识别痴呆症的精确度。因此,在执行第二任务之前,本发明应在中心显示包括第一对象的画面,以使得用户凝视中心。
另一方面,根据本发明实施例,在按照预设次数执行第二任务的过程中,装置100的处理器110可获得有关用户的视线信息。其中,视线信息可用作识别痴呆症的数字生物标记物(从数字装置获得的生物标记物)。
作为一例,在按照预设次数执行第二任务的过程中,用户终端200的处理器210可获得包括用户眼睛在内的影像。在此情况下,在按照预设次数执行第二任务的过程中,装置100的处理器110可通过通信部130从用户终端200接收包括用户眼睛在内的影像。在接收上述影像的情况下,处理器110可通过分析上述影像来生成视线信息。
作为再一例,在按照预设次数执行第二任务的过程中,用户终端200的处理器210可获得包括用户眼睛在内的影像。处理器210可通过分析所获得的影像来获得视线信息。而且,处理器210可控制通信部230向装置100传输所获得的视线信息。在此情况下,装置100的处理器110可通过通信部1130从用户终端200接收视线信息。
视线信息可包括正确执行次数信息、错误执行次数信息、持续凝视信息、消耗时间信息、移动速度信息及正确凝视信息中的至少一个,上述正确执行次数信息为用户正确执行预设视线问题的次数,上述错误执行次数信息为用户错误执行预设视线问题的次数,上述持续凝视信息为用户视线在预设时间内是否持续凝视特定位置的信息,上述消耗时间信息为用户视线从显示包括至少一个对象在内的画面开始移动到至少一个对象中的一个对象的消耗时间,上述移动速度信息为用户视线移动速度,上述正确凝视信息为用户视线是否正确凝视预设视线问题相关位置的信息。
在本发明中,视线信息可以为多种数字生物标记物中痴呆症识别相关系数较高的数字生物标记物。因此,在基于视线信息确定痴呆症的情况下,可提高识别痴呆症的精确度。
根据本发明实施例,处理器110可执行储备任务,在执行第一任务及第二任务之前,使得用户确定预设视线问题。其中,储备任务可按照与第一任务及第二任务相同的方式执行,因此,将省略其详细说明。
通过储备任务获得的视线信息无法用于通过痴呆症识别模型识别痴呆症。但并不限定于此,为了提高痴呆症识别模型的痴呆症识别精确度,也可将通过储备任务获得的视线信息输入于痴呆症识别模型。
另一方面,根据本发明实施例,在获得视线信息的情况下,处理器110可利用视线信息确定用户是否患有痴呆症。对此,以下参照图7详细说明。
图7为用于说明本发明实施例的装置利用视线信息确定用户是否患有痴呆症的方法一例的流程图。图7为用于说明本发明实施例的视线信息获得方法一例的图。在对于图7的说明中,将省略参照图1至图6说明的重复内容并着重说明不同之处。
参照图7,在按照预设次数执行第二任务的过程中,装置100的处理器110可获得有关用户的视线信息(步骤S210)。
具体地,在按照预设次数执行第二任务的过程中,处理器110可通过分析包括用户眼睛在内的影像来识别瞳孔。在识别瞳孔后,处理器110可计算瞳孔的坐标值。瞳孔的坐标值可以为瞳孔焦点的坐标值,也可以为瞳孔整体的坐标值。在本发明中,视线信息可基于瞳孔的坐标值生成。
视线信息可包括正确执行次数信息、错误执行次数信息、持续凝视信息、消耗时间信息、移动速度信息及正确凝视信息中的至少一个,上述正确执行次数信息为用户正确执行预设视线问题的次数,上述错误执行次数信息为用户错误执行预设视线问题的次数,上述持续凝视信息为用户视线在预设时间内是否持续凝视特定位置的信息,上述消耗时间信息为用户视线从显示包括至少一个对象在内的画面开始移动到至少一个对象中的一个对象的消耗时间,上述移动速度信息为用户视线移动速度,上述正确凝视信息为用户视线是否正确凝视预设视线问题相关位置的信息。但并不限定于此,视线信息可包括比上述信息更多或更少的信息。并且,为了提高痴呆症识别模型识别痴呆症的精确度,视线信息可包括上述全部信息。
根据本发明实施例,在按照预设次数执行第一任务及第二任务的情况下,处理器110可在预设次数中计算用户正确执行预设视线问题的次数及用户错误执行预设视线问题的次数。
用户视线在预设时间内是否持续凝视特定位置的信息可基于用户瞳孔在特定时间点是否移动到特定位置来计算。
作为一例,用户视线在预设时间内是否持续凝视特定位置的信息可基于显示第一对象的过程中用户瞳孔是否移动到特定位置来计算。其中,特定位置可以为瞳孔凝视第一对象时的所处位置,当瞳孔的坐标值大于预设临界值时,可判断为瞳孔曾移动。
作为再一例,用户视线在预设时间内是否持续凝视特定位置的信息可基于瞳孔在预设时间内是否停留在用户瞳孔最后移动的位置来计算。其中,特定位置可以为瞳孔凝视图5的第二对象O2或第三对象O3或者图6的视线引导对象O4时的所处位置,当瞳孔的坐标值大于预设临界值时,可判断瞳孔曾移动。
对于痴呆症患者而言,由于无法长时间凝视一个位置,因此,若将所获得的用户视线在预设时间内是否持续凝视特定位置的信息用作识别痴呆症的数字生物标记物,则可提高识别痴呆症的精确度。
另一方面,为了获得视线信息所包括的信息,以下参照图8进一步详细说明相关方法。
在图8中,x轴表示时间,y轴可表示视线移动距离或画面中心与用户凝视对象之间的距离。而且,第一线L1表示画面中心与用户凝视对象之间的距离随着时间变化的曲线,第二线L2表示用户视线移动距离随着时间变化的曲线。
以下,对本发明在显示图5所示的上述画面时获得视线信息的方法进行说明。
在本发明中,第一时间点t1可以为显示包括文本、第二对象及第三对象在内的画面的时间点。
而且,在显示包括文本、第二对象及第三对象在内的画面后,用户视线开始向第二对象或第三对象移动的时间点可以为第二时间点t2。其中,第二时间点t2可以为瞳孔坐标从停止状态开始移动的时间点。但并不限定于此。
在本发明中,第一时间点t1作为显示包括第二对象及第三对象在内的画面的时间点,第二时间点t2作为用户视线开始向第二对象或第三对象移动的时间点,用户反应延迟时间可意味着第一时间点t1与第二时间点t2的时间差。
另一方面,用户视线是否正确凝视预设视线问题相关位置(即,第二对象或第三对象)的信息可基于用户视线移动距离D2和从文本T到预设视线问题相关位置(第二对象O2或第三对象O3、用户凝视对象)的距离D1来计算。其中,用户视线移动距离D2可基于瞳孔初始坐标值(瞳孔移动之前,瞳孔所处位置的坐标值)和瞳孔最终坐标值(瞳孔移动后,最后停留位置的坐标值)来计算。
具体地,用户视线是否正确凝视预设视线问题相关位置(第二对象或第三对象)的信息(即,是否正确凝视用户凝视对象的信息)可通过第二距离D2除以第一距离D1得出的值来计算。其中,随着上述值越接近1,可表示用户视线正确凝视预设视线问题相关位置(第二对象或第三对象)。
另一方面,在显示图6所示画面的情况下,为了获得视线信息,以下详细说明相关方法。
在本发明中,第一时间点t1可以为显示包括视线引导对象在内的画面的时间点。
而且,在显示包括视线引导对象在内的画面后,用户视线开始移动的时间点可以为第二时间点t2。其中,第二时间点t2可以为瞳孔坐标从停止状态开始移动的时间点。但并不限定于此。
在本发明中,第一时间点t1作为显示包括视线引导对象在内的画面的时间点,第二时间点t2作为用户视线开始移动的时间点,用户反应延迟时间可意味着第一时间点t1与第二时间点t2的时间差。
另一方面,用户视线是否正确凝视预设视线问题相关位置(即,第二对象或第三对象)的信息可基于用户视线移动距离D2和从第一区域R1到预设视线问题相关位置(用户凝视的位置)的距离D1来计算。其中,用户视线移动距离D2可基于瞳孔初始坐标值(瞳孔移动之前,瞳孔所处位置的坐标值)和瞳孔最终坐标值(瞳孔移动后,最后停留位置的坐标值)来计算。
具体地,用户视线是否正确凝视视线引导对象或视线引导对象的相对面的任意位置的信息(即,是否正确凝视用户凝视对象的信息)可通过第二距离D2除以第一距离D1得出的值来计算。其中,随着上述值越接近1,可表示用户视线正确凝视预设视线问题相关位置。
在本发明中,用户视线的移动速度可通过微分图8所示的位置轨迹还原速度值来计算。但并不限定于此,可基于用户瞳孔从中心到目标位置的移动距离相关信息和用户瞳孔从中心移动到目标位置的消耗时间相关信息来计算,处理器110可通多种方法计算用户视线的移动速度。
另一方面,再次参照图7,在步骤S210获得视线信息的情况下,处理器110可向痴呆症识别模型输入视线信息来计算分数值(步骤S220)。其中,当输入视线信息时,为了计算分数值,痴呆症识别模型可以为具有预学习的神经网络结构的人工智能模型。而且,分数值可以为基于大小识别痴呆症的值。
根据本发明实施例,装置100的存储部120可存储预学习的痴呆症识别模型。
痴呆症识别模型可基于如下方法学习,即,通过反向传播(back propagation)标记在学习数据中的标签数据与痴呆症识别模型输出的预测数据之间的差值来更新神经网络的加权值。
在本发明中,学习数据可以为多个测试用户通过自身测试装置执行上述第一任务及第二任务获得的视线信息。
在本发明中,测试用户可包括患有轻度认知障碍的用户、患有阿尔茨海默病的用户、正常用户等。但并不限定于此。
在本发明中,测试装置是指确保学习数据时使得多个测试用户进行测试的装置。其中,测试装置可以为与用于识别痴呆症的用户终端200相同的手机、智能手机(smartphone)、平板电脑(tablet PC)、超极本(ultrabook)等移动终端(mobile device)。但并不限定于此。
在本发明中,标签数据可以为用于识别患者是否正常、是否患有阿尔茨海默病及是否患有轻度认知障碍的分数值。但并不限定于此。
痴呆症识别模型可以由能够通常称为节点的相互连接的计算单元构成。上述节点也可被称为神经元(neuron)。神经网络可包括至少一个节点。构成神经网络的节点(或神经元)可通过一个以上链接相连接。
在痴呆症识别模型内,通过链接连接的一个以上节点可相对形成输入节点及输出节点的关系。输入节点及输出节点作为相对概念,相对于一个节点的输出节点关系中的任何节点均可能与其他节点关系中存在输入节点关系,反之亦然。如上所述,输入节点对输出节点关系可基于链接生成。一个输出节点可通过链接与一个输入节点相连接,反之亦然。
在通过一个链接连接的输入节点及输出节点关系中,输出节点的数据可基于输入节点输入的数据确定其值。其中,使得输入节点与输出节点相连接的链接可具有加权值(weight)。加权值作为可变的,可为了执行神经网络所期望的功能而由用户或算法改变。
例如,当一个以上输入节点通过各个链接与一个输出节点相连接时,输出节点可基于输入于与上述输出节点相连接的输入节点的值及通过分别对应于输入节点的链接设定的加权值确定输出节点值。
如上所述,痴呆症识别模型可通过一个以上链接与一个以上节点相连接来在神经网络内形成输入节点及输出节点关系。可基于痴呆症识别模型内的与多个节点的链接数量、与多个节点与多个链接之间的相关关系、分别赋予多个链接的加权值确定痴呆症识别模型的特性。
痴呆症识别模型可由一个节点的集合构成。构成痴呆症识别模型的多个节点的部分集合可构成层(layer)。构成痴呆症识别模型的多个节点中的一部分可基于从初始输入节点的距离来构成一个层(layer)。例如,从初始输入节点的距离为n的节点集合可构成n层。从初始输入节点的距离可基于为了从初始输入节点到达相应节点而需要经过的链接的最少数量来定义。但是,上述层仅为了说明层面上的便利而随机定义的,因此,痴呆症识别模型内的层数可按照不同于上述方法的方式定义。例如,节点的层也可定义为从最终输出节点的距离。
初始输入节点是指不经过神经网络内的多个节点与其他节点的关系中的链接而直接输入数据(即,视线信息)的一个以上节点。或者,在痴呆症识别模型内以链接为基准的节点之间的关系层面上不具有通过链接连接的其他输入节点的节点。与此类似地,最终输出节点是指神经网络内的多个节点与其他节点的关系中不具有输出节点的一个以上节点。并且,隐藏节点是指构成神经网络的节点中除初始输入节点及最终输出节点之外的节点。
在本发明实施例的痴呆症识别模型中,输入层的节点数量可大于输出层的节点数量,随着输入层发展成隐藏层,可形成节点数量逐渐减少的神经网络。而且,可向输入层的各个节点输入正确执行次数信息、错误执行次数信息、持续凝视信息、消耗时间信息、移动速度信息及正确凝视信息,上述正确执行次数信息为用户正确执行预设视线问题的次数,上述错误执行次数信息为用户错误执行预设视线问题的次数,上述持续凝视信息为用户的视线在预设时间内是否持续凝视特定位置的信息,上述消耗时间信息为上述用户的视线从显示包括上述至少一个对象在内的画面开始移动到上述至少一个对象中的一个对象的消耗时间,上述移动速度信息为上述用户的视线移动速度,上述正确凝视信息为上述用户的视线是否正确凝视上述预设视线问题相关位置的信息。但并不限定于此。
根据本发明实施例,痴呆症识别模型可具有深度神经网络结构。
深度神经网络(DNN,deep neural network)是指包括除输入层及输出层外的多个隐藏层的神经网络。若利用深度神经网络,则可掌握数据的潜结构(latent structures)。
深度神经网络可包括卷积神经网络(CNN,convolutional neural network)、循环神经网络(RNN,recurrent neural network)、自编码器(auto encoder)、生成对抗网络(GAN,Generative Adversarial Networks)、受限玻尔兹曼机(RBM,restricted boltzmannmachine)、深度信念网络(DBN,deep belief network)、Q网络、U网络、连体网络、生成对抗网络(GAN,Generative Adversarial Network)等。但是,上述深度神经网络仅为示例,本发明并不限定于此。
本发明的痴呆症识别模型可通过监督学习(supervised learning)方式学习。但并不限定于此,痴呆症识别模型也可通过无监督学习(unsupervised learning)、半监督学习(semi supervised learning)或强化学习(reinforcement learning)中的至少一种方式学习。
痴呆症识别模型的学习可以为如下过程,即,为了使得痴呆症识别模型执行识别痴呆症的工作而将知识应用于神经网络。
痴呆症识别模型可按照最小化输出错误的方向学习。痴呆症识别模型的学习为如下过程,即,向痴呆症识别模型反复输入学习数据(用于学习的测试结果数据)并计算痴呆症识别模型对于学习数据的输出(通过神经网络预测的分数值)和目标(用作标签数据的分数值)错误以减少错误的方向将痴呆症识别模型的错误从痴呆症识别模型的输出层反向传播(back propagation)到输入层方向来更新痴呆症识别模型的各个节点的加权值。
更新的各个节点的连接加权值可基于学习率(learning rate)确定变化量。痴呆症识别模型对于输入数据的计算和错误的反向传播可构成一个学习周期(epoch)。学习率可基于痴呆症识别模型的学习周期反复次数产生变化。例如,在痴呆症识别模型的学习初期,可使用高学习率使得痴呆症识别模型快速确保规定水平性能来提高效率性,在学习后期,可使用低学习率提高精确度。
在痴呆症识别模型的学习中,学习数据可以为实际数据的部分集合(即,利用已学习的痴呆症识别模型要处理的数据),因此,虽然减少学习数据的错误,但对于实际数据,存在增加错误的学习周期。过度拟合(overfitting)是指因对学习数据进行过度学习而导致对于实际数据的错误增加的现象。
过度拟合可导致机器学习算法的错误增加。为了防止这种过度拟合,可使用多种优化方法。为了防止过度拟合,可应用增加学习数据、调节(regularization)、在学习过程中未激活网络的部分节点的丢失(dropout)、利用批量归一化(batch normalizationlayer)等方法。
另一方面,在通过步骤S220获得分数值的情况下,处理器110可基于分数值确定是否患有痴呆症(步骤S230)。
具体地,处理器110可基于分数值是否大于预设临界值来确定是否患有痴呆症。
作为一例,若痴呆症识别模型输出的分数值大于预设临界值,则处理器110可确定用户患有痴呆症。
作为再一例,若痴呆症识别模型输出的分数值为预设临界值以下,则处理器110可确定用户未患有痴呆症。
上述示例仅为一例示,本发明并不限定于上述示例。
根据本发明实施例,装置100的处理器110可在执行上述第一任务及第二任务之前获得用户识别信息。其中,用户识别信息可包括用户的年龄信息、性别信息、名字、地址信息等。而且,用户识别信息的至少一部分可以与视线信息一并用作痴呆症识别模型的输入数据。具体地,年龄信息及性别信息可以与视线信息一并用作痴呆症识别模型的输入数据。如上所述,随着用户识别信息的至少一部分与视线信息一并输入于痴呆症识别模型,在获得分数值的情况下,可进一步提高识别痴呆症的精确度。在此情况下,痴呆症识别模型可以为基于用户识别信息的至少一部分与视线信息完成学习的模型。
针对认知正常组120人和认知低下组9人进行通过用户终端识别是否患有痴呆症的实验。本实验的目的在于,确认已学习的痴呆症识别模型相关精确度。具体地,装置100可基于向本发明的痴呆症识别模型输入通过第一任务、第二任务获得的视线信息生成的分数值判断是否患有痴呆症。可通过上述实验确认到计算分类的精确度为80%以上。
根据以上本发明实施例中的至少一个实施例,可通过使患者不会感到反感的方法精确诊断痴呆症。
本发明的装置100并不用于限定以上实施例的结构及方法,为了使得上述实施例实现多种变形,可选择性地组合各个实施例的一部分或全部。
本发明的多个实施例可通过软件、硬件或它们的组合实现在计算机或与此相似的设备可读记录介质内。
在由硬件实现的情况下,其中说明的实施例可由专用集成电路(ASICs,application specific integrated circuits)、数字信号处理器(DSPs,digital signalprocessors)、数字信号处理设备(DSPDs,digital signal processing devices)、可编程逻辑器件(PLDs,programmable logic devices)、现场可编程门阵列(FPGAs,fieldprogrammable gate arrays)、处理器、控制器、微型控制器(micro-controllers)、微型处理器(microprocessors)及用于执行其他功能的电子单元中的至少一个来实现。在部分情况下,本发明实施例可由至少一个处理器实现。
在由软件实现的情况下,本发明说明的步骤及功能等实施例可由额外的软件模块实现。软件模块可分别用于执行本发明说明的一个以上功能、任务及工作。可通过由适当的编程语言编写的软件应用程序实现软件代码(software code)。其中,软件代码存储在存储部120,可由至少一个处理器110执行。即,至少一个程序指令可存储在存储部120,至少一个程序指令可由至少一个处理器110执行。
在本发明实施例的装置100中,至少一个处理器110利用痴呆症识别模型识别痴呆症的方法可在设置于装置100的至少一个处理器110可读取的记录介质由至少一个处理器可读取的代码实现。至少一个处理器可读取的记录介质包括存储有至少一个处理器110可读取数据的所有类型的记录设备。作为一例,至少一个处理器可读取的记录介质包括只读存储器(ROM,Read Only Memory)、随机存取存储器(RAM,Random Access Memory)、只读光盘存储器(CD-ROM)、磁带、软盘、光学数据存储设备等。
以上,虽然参照附图说明了本发明,但是,这仅为实施例,本发明并不限定于特定实施例,可通过本发明所属技术领域的普通技术人员变形实施的多种内容均属于发明要求保护范围。并且,这种变形实施例不应与本发明的技术思想分开理解。
- 一种基于序贯图像识别的信息码导引识别方法
- 基于比特位面内分块互信息的手背静脉识别方法及识别系统
- 基于视频视线识别对电梯媒体收视信息进行采集的方法
- 一种基于视线角信息与前置导引信息的复合制导方法