结合自适应权重的MPC-LSTM空气质量预测方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于空气质量预测技术领域,尤其涉及结合自适应权重的MPC-LSTM空气质量预测方法。
背景技术
在空气质量预测问题中,由于空气质量数据存在多元、多尺度的数据特征,且空气质量数据观测时间长,长期的预测需要考虑趋势信息;
目前在空气质量预测应用中,多数学者使用单一的预测模型进行预测,但是单一的预测模型往往存在自身的缺点,比如现有的RNN网络模型存在梯度消失和梯度爆炸的问题,LSTM网络存在模型复杂和训练时间长的问题,因此,亟需针对基于单一方法对空气质量预测时空气质量预测精度不佳的问题进行研究和改进,提出了一种新的组合网络模型预测方法。
发明内容
为解决上述技术问题,本发明提出了结合自适应权重的MPC-LSTM空气质量预测方法,此方法结合了多尺度并行卷积融合网络、长短记忆神经网络和注意力机制,针对LSTM网络不能提取非连续数据特征的缺点,利用多尺度并行卷积融合网络(提取空气质量数据局部特征,然后将提取到的局部特征数据以时间序列格式输入LSTM网络,此种设计实现了对数据潜在特征关系的进一步挖掘,最后引入注意力机制,采用时序注意力机制对其分配时间注意力权重,以增强关键历史时刻信息的表达,获得加权后的综合时序信息,强化模型对特征关键时序信息的提取能力并进行学习预测。
本发明提供了结合自适应权重的MPC-LSTM空气质量预测方法,包括:
构建空气质量样本的数据集,并对所述数据集进行预处理;
构建MPC-LSTM空气质量预测模型;
基于预处理后的所述数据集,对所述MPC-LSTM空气质量预测模型进行训练;
基于训练后的所述MPC-LSTM空气质量预测模型,对空气质量进行预测。
可选地,对所述数据集进行预处理包括:
对所述数据集进行异常数据处理;
将异常数据处理后的所述数据集进行归一化;
对归一化后的所述数据集进行数据重构。
可选地,所述异常数据处理包括:对所述数据集中的缺失数据进行填充,剔除掉异常数据和重复数据。
可选地,所述归一化为:
/>
其中,
可选地,对所述MPC-LSTM空气质量预测模型进行训练包括:
将所述数据集划分为训练集和测试集;
将所述训练集输入所述MPC-LSTM空气质量预测模型,对预测模型进行训练,并在每次训练结束后,利用预测模型对所述测试集进行预测,采用反向传播算法进行预测模型训练;
基于损失函数最小为训练目标,采用Adam优化器对所述MPC-LSTM空气质量预测模型中各层系数进行优化。
可选地,对所述MPC-LSTM空气质量预测模型中各层系数进行优化的方式为:
其中,N为训练样本数,n为多步预测步长,
可选地,所述MPC-LSTM空气质量预测模型包括:多尺度并行卷积融合模块、LSTM网络模块和自适应权重模块;
通过所述多尺度并行卷积融合模块提取空气质量数据的时序特征,将所述时序特征以时间序列格式输入所述LSTM网络模块,所述LSTM网络模块基于所述时序特征进行学习预测,并利用所述自适应权重模块通过深度学习,输出所述MPC-LSTM空气质量预测模型的最优权重。
可选地,所述多尺度并行卷积融合模块包括:两个一维卷积层和并行卷积层,其中所述并行卷积层的卷积核尺寸不同;
输入的数据经过所述并行卷积层进行数据特征的初步提取后,再使用ResNet的跳跃连接设计,使用第一一维卷积层将初步特征信息与并行卷积层信息融合并压缩,自适应提取特征信息,后将输出特征信息传递至第二一维卷积网络层。
可选地,所述自适应权重模块包括:Dense层和multiply层;
所述自适应权重模块通过所述Dense层为所述MPC-LSTM空气质量预测模型的初始输出赋予权重矩阵,获取经过自适应权重处理后的输出,然后通过所述multiply层将所述初始输出和经过自适应权重处理后的输出进行线性相乘获取最终的空气质量预测值。
可选地,所述数据集中的空气质量数据包括:AQI指数、CO、NO
与现有技术相比,本发明具有如下优点和技术效果:
本发明提出了结合自适应权重的MPC-LSTM空气质量预测方法,针对其他组合模型特征提取能力不强的缺点,构建了MPC-LSTM空气质量预测模型,包括多尺度并行卷积融合网络、长短记忆神经网络和注意力机制三部分,用多尺度并行卷积融合网络来提取时序特征,然后将提取到的局部特征数据以时间序列格式输入LSTM网络,实现了对数据潜在特征关系的进一步挖掘,并利用自适应权重模块通过深度学习,为MPC-LSTM模块的输出配权,选出最优权重,构建出最优的空气质量预测模型,从而提高空气质量预测精度。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本发明实施例的CNN模型预测效果示意图;
图2为本发明实施例的LSTM模型预测效果示意图;
图3为本发明实施例的RNN模型预测效果示意图;
图4为本发明实施例的CNN-LSTM模型预测效果示意图;
图5为本发明实施例的MPC-LSTM模型预测效果示意图;
图6为本发明实施例的CNN-LSTM-Attention模型预测效果示意图;
图7为本发明实施例的MPC-LSTM-Attention模型预测效果示意图;
图8为本发明实施例的结合自适应权重的MPC-LSTM模型结构示意图;
图9为本发明实施例的多尺度并行卷积融合网络(Multi-Scale ParallelConvolution Fusion,MPC)原理示意图;
图10为本发明实施例的自适应权重模块原理示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
本发明提出了结合自适应权重的MPC-LSTM空气质量预测方法,包括:
构建空气质量样本的数据集,并对数据集进行预处理;
构建MPC-LSTM空气质量预测模型;
基于预处理后的数据集,对MPC-LSTM空气质量预测模型进行训练;
基于训练后的MPC-LSTM空气质量预测模型,获取预测的空气质量数据。
进一步地,对数据集进行预处理包括:
对数据集进行异常数据处理;
将异常数据处理后的数据集进行归一化;
对归一化后的数据集进行数据重构。
进一步地,异常数据处理包括:对数据集中的缺失数据进行填充,剔除掉异常数据和重复数据;其中缺失的数据由前一个数据和后一个数据的平均值填补。
进一步地,对MPC-LSTM空气质量预测模型进行训练包括:
将数据集划分为训练集和测试集;
将训练集输入MPC-LSTM空气质量预测模型,对预测模型进行训练,并在每次训练结束后,利用预测模型对测试集进行预测,采用反向传播算法进行预测模型训练;
基于损失函数最小为训练目标,采用Adam优化器对MPC-LSTM空气质量预测模型中各层系数进行优化。
进一步地,MPC-LSTM空气质量预测模型包括:多尺度并行卷积融合模块、LSTM网络模块和自适应权重模块;
通过多尺度并行卷积融合模块提取空气质量数据的时序特征,将时序特征以时间序列格式输入LSTM网络模块,LSTM网络模块基于时序特征进行学习预测,并利用自适应权重模块通过深度学习,输出MPC-LSTM空气质量预测模型的最优权重。
进一步地,多尺度并行卷积融合模块包括:两个一维卷积层和并行卷积层,其中所述并行卷积层的卷积核尺寸不同;
输入的数据经过所述并行卷积层进行数据特征的初步提取后,再使用ResNet的跳跃连接设计,使用第一一维卷积层将初步特征信息与并行卷积层信息融合并压缩,自适应提取特征信息,后将输出特征信息传递至第二一维卷积层。
进一步地,自适应权重模块包括:Dense层和multiply层;
自适应权重模块通过Dense层为MPC-LSTM空气质量预测模型的初始输出赋予权重矩阵,获取经过自适应权重处理后的输出,然后通过multiply层将所述初始输出和经过自适应权重处理后的输出进行线性相乘获取最终的空气质量预测值。
进一步地,数据集中的空气质量数据包括:AQI指数、CO、NO
实施例
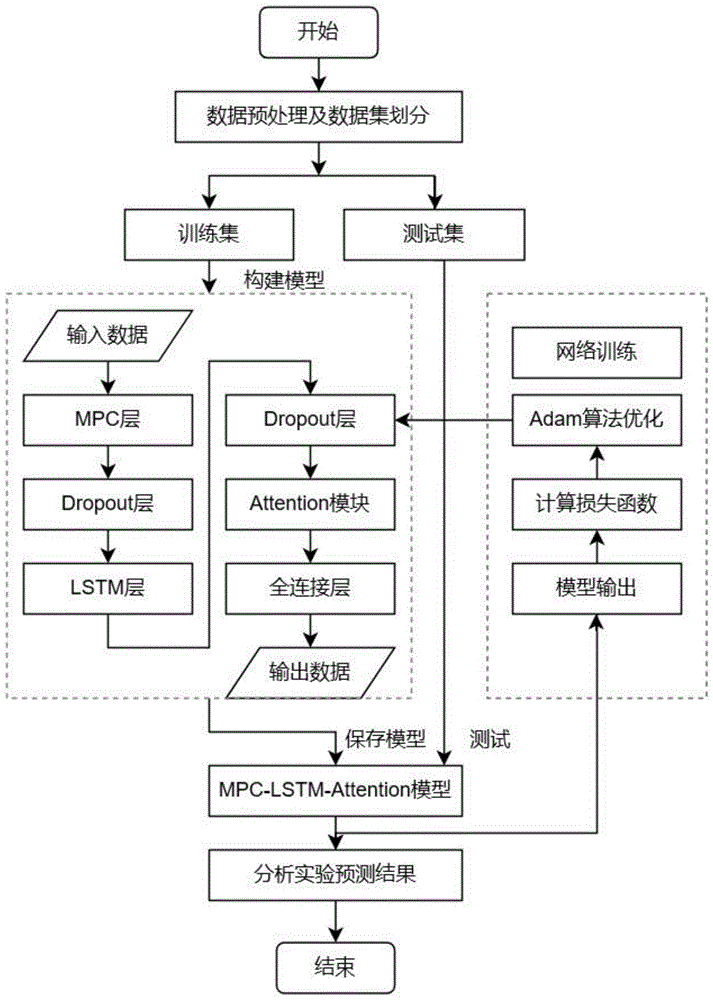
如图8所示,本实施例提供了结合自适应权重的MPC-LSTM空气质量预测方法,该模型由多尺度并行卷积融合网络(MPC)、长短记忆神经网络(LSTM)和注意力机制(Attention)三部分组成。针对其他组合模型特征提取能力不强的缺点,本模型提出用多尺度并行卷积融合网络(MPC)来提取时序特征,然后将提取到的局部特征数据以时间序列格式输入LSTM网络,此种设计实现了对数据潜在特征关系的进一步挖掘,并利用自适应权重模块通过深度学习,为MPC-LSTM模块的输出配权,选出最优权重,构建出最优的空气质量预测模型,从而提高空气质量预测精度。
空气质量预测方法主要分为三个部分,第一个部分为初始数据处理部分、第二个部分为空气质量数据训练及预测部分、第三个部分为空气质量预测评估部分。
本实施例测试使用的样本数据来源于中国环境监测总站的全国城市空气质量实时发布平台发布的长沙市空气质量历史数据,选取的样本数据为长沙市天心区环保局于2020年1月1日到2021年12月31日每小时采集一次的空气污染物数据,共计17447组数据,表1给出该数据集的5条空气质量数据样本,本文将样本分为训练和预测样本,即前80%测试样本,后20%为预测样本,选取每小时的AQI指数、CO、NO
表1
初始数据处理模块分为三个步骤,第一个步骤为异常数据数据处理。在对监测地点监测获得空气质量初始数据后,对空气质量数据中的缺失数据进行填充,剔除掉异常数据和重复数据。由于数据的监测和储存过程中会存在数据异常和数据缺失问题,这些异常数据会对模型的预测精度造成一定的影响,因此需要对异常数据进行清洗。数据清理主要剔除数据原始数据中的非正常数据,包括重复数据、缺失数据和异常数据。重复空气数据保留监测的第一次数据,删除剩余重复数据。缺失的数据由该数据的前一个数据和后一个数据的平均值填补,计算公式如下:
式中:x
异常数据是指数值过大或者过小的数据,它也被替换为前一小时数据和下一小时数据的平均值。
例如以下表2这组数据中,AQI、PM2.5和SO
表2
使用上述算法对缺失数据进行补全,补全后的数据如下表3所示。
表3
/>
第二个步骤为数据归一化,把所有数据映射到0-1之间。将数据集划分为训练集(前80%的数据)、测试集两个部分(剩下的20%数据),利用算法对数据进行归一化,在预测结束后对预测结果进行反归一化。由于不同气象特征数据量纲不同,为了防止不同量纲对模型学习造成影响,同时提高模型的训练速度与收敛性,需要对特征数据进行线性归一化处理,即:
式中:
考虑到空气质量指数的物理意义,需要在预测结束后对预测结果进行反归一化,即:
式中:
第三个步骤为输入数据重构。将训练集、测试集两个部分选择对应宽度的滑动窗口逐步向后滚动,将原始数据进行分批重构。重构后的输入数据为X=[x
完成以上对空气质量数据的预处理后,我们把训练集的数据输入预测模型中进行学习训练,用训练集对预测模型进行训练,并在每次训练结束后对测试集数据进行预测,采用反向传播算法进行预测模型训练。以实现损失函数最小的训练目标,并采用Adam优化器对模型中各层系数进行迭代更新,得到最终的结合自适应权重的MPC-LSTM组合空气质量预测模型。模型系数优化算法如下式所示:
/>
式中:N为训练样本数;
在完成对空气质量预测模型的训练后,就进入到空气质量预测阶段,将测试集的空气质量数据输入已经训练完成的结合自适应权重的MPC-LSTM组合空气质量预测模型中,预测出与测试集数据量相等的空气质量数据,并对预测的数据进行数据反归一化,最后对预测效果进行评价。
为了评估预测模型预测效果,本实施例使用平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R
式中:y
式中:
最后通过计算评价指标的值来评估该预测模型的预测准确度。
以下为结合自适应权重的MPC-LSTM组合空气质量预测模型的模型介绍:
结合自适应权重的MPC-LSTM组合空气质量预测模型分为三个模块,分别是多尺度并行卷积融合网络(Multi-Scale Parallel Convolution Fusion,MPC)、LSTM网络模块和自适应权重模块。
多尺度并行卷积融合网络(Multi-Scale Parallel Convolution Fusion)是预测模型的第一个模块,如图9所示,并行卷积结构能够在同一层级提取到不同时间尺度的潜在时间特征,提高模型对不同时间尺度数据特征的提取精度,然后将不同尺度的信息融合传递至下一层,可以在提高精度的同时灵活地平衡计算量和模型能力。
多尺度并行卷积融合网络包含2个一维卷积层和3个并行卷积层。3个并行卷积操作的卷积核尺寸分别为1×1,2×2和3×3,在本实施例输入的数据经过3个并行卷积层进行数据特征的初步提取后,再使用ResNet的跳跃连接设计,使用第一一维卷积层,即3×3卷积将初步特征信息与三个并行卷积层信息融合并压缩,网络将自适应从这些层次中提取有用的特征信息,后将输出特征信息传递至第二一维卷积层,第二一维卷积层的卷积核为3×3。
LSTM网络是第二个模块,LSTM网络中加入的细胞记忆单元,使得LSTM网络具有良好的记忆能力,被广泛应用在时间序列预测当中。将该网络置于MPC网络的下一层,针对LSTM网络不能挖掘非连续数据间潜在联系的缺点,在LSTM网络之前加入MPC局部特征提取模块。利用MPC网络提取数据局部特征、LSTM网络提取数据的时序特征并进行学习预测。
自适应权重模块是该预测模型的最后一个模块,如图10所示,全面考虑影响空气质量的气象因素,选择AQI、CO、NO
α作为组合预测模型的参数,在组合模型学习训练的同时得出最优值,其寻优公式为:
式中:y
为了进一步提高空气质量预测精度,针对目前单一模型难以获得最优预测结果的问题,证明所提出组合预测模型的有效性,该模型将于与CNN、RNN、LSTM、BiLSTM、CNN-LSTM、CNN-BiLSTM、BiLSTM-Attention和CNN-BiLSTM使用相同的训练集和测试集数据在相同的操作环境下进行对比分析。为了避免单次实验的偶然性,保证实验结果的可信性,在相同条件下分别对测试集进行10次实验。结果如表4所示;
表4
由表4可以看出,所提组合模型性能最优,而CNN神经网络预测效果最差。所提组合预测模型相较于CNN、LSTM、RNN单一预测模型,RMSE分别降低了42.66%、12.48%、21.25%;MAE分别降低了45.72%、16.38%、25.58%;MAPE分别降低了41.60%、12.07%、31.30%;决定系数R
取预测数据最后的100组来观测预测值与真实值得对比,将上述测试模型的效果一一展示来观察预测准确度。
以上,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 交叉点存储器结构阵列和形成交叉点存储器结构阵列的方法
- TDDB渗透电流诱导电熔丝结构及其编程方法
- 具有嵌埋位线的存储器阵列及形成存储器阵列的方法
- 非易失性存储器装置和包括其的存储器系统及其编程方法
- 反熔丝阵列结构、编程方法、读取方法及存储器
- 反熔丝结构及其制备方法、反熔丝阵列结构、存储器