免疫兼容型人多能干细胞、其制备方法及应用
文献发布时间:2024-04-18 20:01:55
技术领域
本发明属于生物技术领域,更具体地,本发明涉及一种可逃逸移植受体免疫排斥的免疫兼容型人多能干细胞、其制备方法及应用。
背景技术
细胞移植治疗是把某些具有特定功能的细胞的特性,采用生物工程方法获取和/或通过体外扩增、特殊培养等处理后,产生的特异性功能强大的细胞移植到患者体内,以修复、补充、替换、调节或去除受损或病变细胞/组织,从而达到治愈疾病的目的。因此细胞技术的应用可以治疗各种疾病,如神经系统、骨骼疾病、糖尿病、心脑血管疾病等退行性和损伤性疾病等许多传统疗法难治性病变或与传统疗法形成互补,具有广阔的应用前景。然而,移植受体会对非自身细胞产生免疫排斥,使得移植细胞难以长期在移植受体体内存活。即便是接收经过人白细胞抗原(human leukocyte antigen,HLA)匹配的合适供体组织器官,由于无法做到全部HLA的匹配,受体患者依然需长期服用免疫排斥药物,加重患者负担,同时也带来感染/癌症风险。
免疫排斥的本质是细胞表面的同种异型抗原诱导的一种免疫应答,在人体中主要由HLA所介导。HLA具有极高的多态性,HLA匹配可降低移植受体对移植细胞的免疫排斥作用。基于免疫排斥机制,现有如下方法减轻免疫排斥:
1、HLA配型。主要用于器官及造血干细胞移植中,通过供体/受体的HLA配型降低排斥作用。然而,由于合适供体的稀少及HLA存在极高的多态性,寻找合适供体难度很大,难以满足器官移植病人的需求的。
2、自体诱导多能干细胞(induced pluripotent stem cells,iPSCs)。iPSCs来源于自身体细胞重编程,具备和供体完全一致的HLA基因,在理论上iPSCs及其衍生细胞也可逃逸自体免疫排斥。然而,自体iPSCs及其衍生细胞制备周期长、质控难、成本高,在时效性强、治疗时间窗口窄的疾病中应用难度较大,使用人群非常有限。其次,对于遗传疾病病人,其iPSCs源细胞存在功能异常,进而带来安全隐患。并且,不少退行性和损伤性疾病好发于高年龄段人群,如心肌梗死、帕金森氏症等,此类人群建立iPSCs难度较高。
3、建立可覆盖大部分人群的HLA配型iPSCs库。由于HLA的极高多态性,建立和维持iPSCs配型库的成本极高,周期很长,短时间内仍难以应用。而且不同iPSCs细胞株来源的组织细胞,如心肌细胞之间也存在差异,使用非均一化的细胞可能对后续治疗产生不利影响。
以上方法均存在获取难度大、成本高、难以质控的缺点,因此,建立通用型低免疫原性的供体细胞是本领域的迫切需求。
通过对目前已发表及公布的文献和专利的检索,已获得通用型细胞的技术路线有如下几种:(1)通过敲除一条染色体上的关键HLA分子,构建伪HLA纯合子细胞,增加所获细胞的普适性;(2)通过敲除HLA I家族HLA-A,-B,-C和HLA II家族分子,并辅以过表达“don’teat me”信号CD47分子,膜定位HLAG分子及T细胞抑制因子PD-L1,逃逸免疫细胞的识别与杀伤作用;(3)通过完全敲除HLA I家族和HLA II家族分子,并辅以“don’t eat me”信号CD47分子的过表达,逃逸T细胞和巨噬细胞的识别与杀伤作用;(4)通过敲除介导抗原呈递的经典HLA I分子并过表达具有免疫抑制作用的HLA-G1与分泌型HLA-G5分子,逃逸细胞毒性T细胞及自然杀伤细胞(NK细胞)的识别与杀伤作用,如本发明中共同发明人章小清等申请的国家发明专利申请(CN113528448A)。对比上述4种技术路线,第(1)种不仅难度极高,需要多个HLA分子的单个等位基因进行精确操控,而且增加了基因组发生突变的风险;第(2)种需要引起大范围(大于13kb)的基因组缺失才能达到敲除-A,-B,-C的结果,对基因组带来潜在的不稳定性;第(3)种选择的免疫抑制信号单一,主要作用靶标为巨噬细胞,相比之下HLAG具备广谱免疫抑制作用,可能是更好的选择。不同的免疫抑制因子的作用对象、作用效果均存在差异,因此这种免疫抑制因子的选择是不同技术路线的关键。本发明的共同发明人采用同时过表达膜定位HLA-G1与可溶性HLA-G5构建了B2Mm/sHLAG胚胎干细胞(humanembryonic stem cells,hESCs)系,降低了人胚胎干细胞的免疫原性,其中探讨了胚胎干细胞而未涉及hPSCs、且还有待进一步扩展其应用环境。
发明内容
本发明提供了一种免疫兼容型人多能干细胞、其制备方法及应用,其具有更为广泛的应用。
在本发明的第一方面,提供一种制备免疫兼容型人多能干细胞的方法,包括改造人多能干细胞,使之:
(a)不表达游离B2M蛋白,表达(包括过表达)HLA-G1与分泌型HLA-G5;以及(b)不表达CIITA蛋白。
在一种或多种实施方式中,所述(a)中,改造人多能干细胞的基因组,将编码HLA-G1的多核苷酸与人多能干细胞中内源性的B2M基因融合,从而表达B2M-HLA-G1融合蛋白且不表达游离B2M蛋白;较佳地,将HLA-G1的编码基因引入到内源B2M外显子3中终止密码子前的位置,或以HLA-G1的编码基因替换位于内源B2M基因外显子3中的终止密码子;更佳地,通过基因编辑方法进行所述改造。
在一种或多种实施方式中,所述(a)中,在人多能干细胞中引入外源的编码B2M-HLA-G5融合蛋白的多核苷酸,所述B2M-HLA-G5融合蛋白包括B2M和HLA-G5;较佳地,利用重组载体(如病毒载体,更具体如慢病毒载体)引入所述外源的编码B2M-HLA-G5融合蛋白的多核苷酸。
在一种或多种实施方式中,所述B2M-HLA-G1融合蛋白中,还包括位于B2M和HLA-G1之间的柔性连接肽,优选如SEQ ID NO:3所示的柔性连接肽;和/或,所述B2M-HLA-G1融合蛋白自N端至C端依次包括:B2M和HLA-G1;较佳地,所述B2M-HLA-G1融合蛋白的氨基酸序列如SEQ ID NO:4所示;更佳地,所述B2M-HLA-G1融合蛋白的核酸序列如SEQ ID NO:9所示。
在一种或多种实施方式中,所述B2M-HLA-G5融合蛋白中,还包括位于B2M和HLA-G5之间的柔性连接肽,优选如SEQ ID NO:3所示的柔性连接肽;和/或,所述B2M-HLA-G5融合蛋白自N端至C端依次包括:B2M和HLA-G5;较佳地,所述B2M-HLA-G5融合蛋白的氨基酸序列如SEQ ID NO:8所示;更佳地,所述B2M-HLA-G5融合蛋白的核酸序列如SEQ ID NO:10所示。
在一种或多种实施方式中,所述(b)中,针对人多能干细胞基因组中CIITA基因的外显子3进行敲除;较佳地,通过基因编辑方法进行敲除;更佳地,以SEQ ID NO:11所示核苷酸序列的gRNA(GGGAGGCTTATGCCAATAT)进行基因编辑。
在一种或多种实施方式中,所述制备方法包括如下的A-D中的一个或多个:
A、所述HLA-G1包括:氨基酸序列如SEQ ID NO:1所示的多肽;或,氨基酸序列与SEQID NO:1具有90%以上序列同一性且具有SEQ ID NO:1所示的多肽的功能的衍生多肽(包括活性片段、活性变体);
B、所述B2M包括:氨基酸序列如SEQ ID NO:2所示的多肽;或,氨基酸序列与SEQ IDNO:2具有90%以上序列同一性且具有SEQ ID NO:2所示的多肽的功能的衍生多肽(包括活性片段、活性变体);
C、所述CIITA蛋白包括:氨基酸序列如SEQ ID NO:5所示的多肽;或,氨基酸序列与SEQ ID NO:5具有90%以上序列同一性且具有SEQ ID NO:5所示的多肽的功能的衍生多肽(包括活性片段、活性变体);
D、所述HLA-G5包括:氨基酸序列如SEQ ID NO:6所示的多肽;或,氨基酸序列与SEQID NO:6具有90%以上序列同一性且具有SEQ ID NO:6所示的多肽的功能的多肽片段。
在一种或多种实施方式中,所述“90%以上序列同一性”包括:91%以上、92%以上、93%以上、94%以上、95%以上、96%以上、97%以上、98%以上或99%以上的序列同一性。
在本发明的第二方面,提供一种免疫兼容型人多能干细胞,其(a)不表达游离B2M蛋白,表达HLA-G1与分泌型HLA-G5;以及(b)不表达CIITA蛋白。作为本发明优选的一种或多种实施方式,所述人多能干细胞:基因组中内源性的B2M基因与编码HLA-G1的多核苷酸融合;包含外源的编码B2M-HLA-G5融合蛋白的多核苷酸;且,基因组中CIITA基因被敲除。
在一种或多种实施方式中,所述免疫兼容型人多能干细胞,由本发明所述的制备免疫兼容型人多能干细胞的方法构建获得。
在本发明的第三方面,提供一种免疫兼容型人多能干细胞的应用,用于通过诱导分化制备适于移植的细胞;较佳地,所述适于移植的细胞为组织或器官细胞;更佳地,所述组织或器官细胞包括(但不限于):心血管前体细胞、心肌细胞、内皮细胞、平滑肌细胞、神经细胞、造血干细胞、髓系细胞(包括粒细胞、单核细胞、巨噬细胞、红细胞、血小板)、淋系细胞(包括自然杀伤细胞、T细胞、B细胞)、视网膜色素上皮细胞、胰岛B细胞、肝脏细胞(包括肝细胞,胆管细胞,肝内皮细胞,肝星状细胞,Kupffer细胞,间皮细胞)、角质形成细胞、骨骼肌细胞、脂肪细胞、骨细胞、软骨细胞、间充质干细胞。
在本发明的第四方面,提供一种制备适于移植的细胞的方法,包括:(a)以本发明所述的制备免疫兼容型人多能干细胞的方法制备获得免疫兼容型人多能干细胞;(b)将(a)的细胞进一步进行诱导分化,获得适于移植的细胞;较佳地,所述适于移植的细胞为组织或器官细胞;更佳地,所述组织或器官细胞包括(但不限于):心血管前体细胞、心肌细胞、内皮细胞、平滑肌细胞、神经细胞、造血干细胞、髓系细胞(包括粒细胞、单核细胞、巨噬细胞、红细胞、血小板)、淋系细胞(包括自然杀伤细胞、T细胞、B细胞)、视网膜色素上皮细胞、胰岛B细胞、肝脏细胞(包括肝细胞,胆管细胞,肝内皮细胞,肝星状细胞,Kupffer细胞,间皮细胞)、角质形成细胞、骨骼肌细胞、脂肪细胞、骨细胞、软骨细胞、间充质干细胞。
在一种或多种实施方式中,所述制备适于移植的细胞的方法中,所述组织或器官细胞为心肌细胞,采用先后以CHIR99021、IWR-1诱导的方法制备;或所述组织或器官细胞为内皮细胞,采用先后以CHIR99021、bFGF、VEGF+BMP4诱导的方法制备。
在一种或多种实施方式中,所述CHIR99021、IWR-1、bFGF、VEGF或BMP4还包括它们的同功能分子。
在一种或多种实施方式中,所述CHIR99021为终浓度6μM,所述终浓度可在50%内上下浮动,较佳地可在40%内上下浮动,较佳地可在30%内上下浮动,较佳地可在20%内上下浮动,较佳地可在10%内上下浮动。较佳地,所述CHIR99021处理2±0.5天。
在一种或多种实施方式中,所述IWR-1为终浓度5μM,所述终浓度可在50%内上下浮动,较佳地可在40%内上下浮动,较佳地可在30%内上下浮动,较佳地可在20%内上下浮动,较佳地可在10%内上下浮动。较佳地,所述IWR-1处理2±0.5天。
在一种或多种实施方式中,所述bFGF为终浓度50ng/ml,所述终浓度可在50%内上下浮动,较佳地可在40%内上下浮动,较佳地可在30%内上下浮动,较佳地可在20%内上下浮动,较佳地可在10%内上下浮动。较佳地,所述bFGF处理1±0.25天。
在一种或多种实施方式中,所述VEGF为终浓度50ng/ml,所述终浓度可在50%内上下浮动,较佳地可在40%内上下浮动,较佳地可在30%内上下浮动,较佳地可在20%内上下浮动,较佳地可在10%内上下浮动。
在一种或多种实施方式中,所述BMP4为终浓度50ng/ml,所述终浓度可在50%内上下浮动,较佳地可在40%内上下浮动,较佳地可在30%内上下浮动,较佳地可在20%内上下浮动,较佳地可在10%内上下浮动。
在一种或多种实施方式中,所述VEGF+BMP4处理2±0.5天。
在本发明的第五方面,提供一种心肌细胞或内皮细胞,由本发明所述的制备免疫兼容型人多能干细胞的方法制备获得的免疫兼容型人多能干细胞或由本发明所述的免疫兼容型人多能干细胞衍生获得。
在本发明的第六方面,提供所述的心肌细胞在制备用于治疗心脏相关的疾病或病症的组合物或药物中的用途;较佳地,所述心脏相关的疾病或病症是心肌损伤、心肌梗死、心肌缺血、缺血再灌注损伤或其他心脏损伤;更佳地,所述心脏相关的疾病或病症是缺血/再灌注损伤。
本发明的其它方面由于本文的公开内容,对本领域的技术人员而言是显而易见的。
附图说明
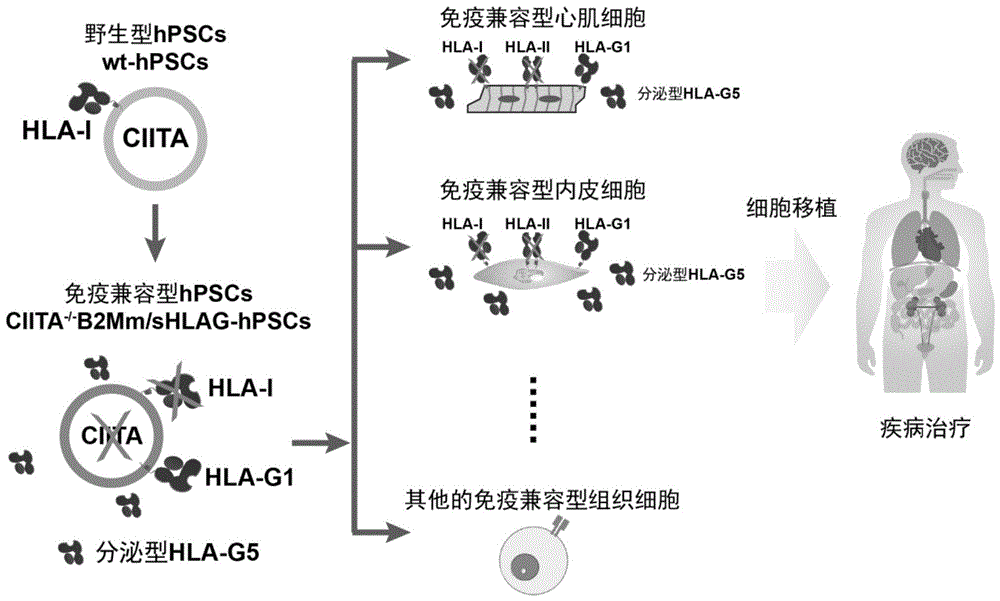
图1、免疫兼容型细胞的构建及获取策略。
图2、免疫兼容型细胞的构建及获取策略。A,在B2M的Exon2位置及CIITA的Exon3位置设计gRNA,将gRNA表达质粒与Cas9表达质粒共转染到hPSCs中,之后挑取单克隆,并进行PCR测序验证。存在移码突变的克隆为B2M与CIITA双敲除克隆。B,首先构建B2Mm/sHLAGhPSCs(参见CN113528448A),然后共转染gRNA与Cas9质粒,挑取单克隆后进行PCR测序验证,存在移码突变的克隆为CIITA
图3、流式细胞术鉴定wt-hPSCs,DKO-hPSCs和CIITA
图4、免疫荧光鉴定wt-hPSCs,DKO-hPSCs和CIITA
图5、HLA家族分子表达鉴定。A,流式鉴定HLA I代表性分子HLA-A/B/C的表达。B,流式鉴定HLA-G1分子表达。C,流式鉴定HLA-DR在细胞膜上富集程度,n=3。D,免疫印迹鉴定分泌型HLA-G5在细胞上清中对的表达。*p<0.05。
图6、分化的内皮细胞及心肌细胞鉴定。A,分化的内皮细胞形态及内皮细胞纯度鉴定。纯度鉴定通过流式细胞术鉴定内皮标志物CD144表达比例。比例尺=100μm。n=3。B,分化的心肌细胞形态及纯度鉴定。纯度鉴定通过流式细胞术鉴定心肌细胞标志物cTNT表达比例。比例尺=100μm。n=3。C,免疫荧光鉴定肌节蛋白α-ACTININ和间隙蛋白Connexin-43在分化的心肌细胞中的表达。比例尺=10μm。
图7、免疫细胞对CIITA
图8、人源化小鼠心梗后移植hPSCs源心肌细胞后细胞驻留评价。A,研究示意图。B,移植后第28天心脏切片免疫荧光图。α-ACTININ:肌丝结构蛋白。hu-KU80:人KU80蛋白,此处所用抗体只对人KU80蛋白有结合,对小鼠KU80没有交叉反应。比例尺=500μm。C,细胞驻留统计结果(以面积计算)。雌鼠,n=3-7;雄鼠,n=3。D,细胞驻留统计结果(以qRT-PCR计算),雌鼠,n=4-5;雄鼠,n=3。*p<0.05,**p<0.01,***p<0.001。
图9、Hu-mice心梗心脏再肌肉化评价。A,移植后第28天小鼠心脏切片Masson染色。比例尺=1mm。B,小鼠心脏再肌肉化比例统计。雌鼠,n=3-7;雄鼠,n=3。*p<0.05,**p<0.01,***p<0.001。
具体实施方式
本发明人在应用B2Mm/sHLAG hESCs的过程中发现,其在免疫兼容性方面还需改进。当将B2Mm/sHLAG hESCs主要应用于退行性疾病的细胞治疗,此时运行较好。但当其在某些其它移植环境中时,仍有免疫细胞(包括抗原呈递细胞)激活的现象。例如,当本发明人将其应用于急性损伤的细胞治疗中,如梗死心脏损伤部位的炎症水平高。在临床上,移植的外源细胞需要植入损伤或临近损伤部位发挥治疗作用,而损伤组织常伴随病变处炎症反应的过度激活,使得病变处组织细胞炎症因子水平较高。当移植hESC诱导分化的组织/器官细胞时,对此类细胞的免疫排斥反应增强。经过广泛的实验研究,分析了大量与此类现象可能相关的分子后,本发明人确定了进一步改造的靶点。基于此,本发明也揭示了一种进一步改造的免疫兼容型细胞,其具有更为广泛的应用环境。
术语
术语“多能干细胞(pluripotent stem cells,PSCs)”是指能够在保持未分化状态的同时自我更新和增殖并且可以在适当条件下被诱导分化成特化细胞类型的细胞。如本文所用,“多能干细胞”包括多能干细胞和其他类型的干细胞,包括胚胎、羊膜或体干细胞。如本文所用,人多能干细胞(hPSCs)可以是人胚胎干细胞(human embryonic stem cells,hESCs),其是利用未经过体内发育的受精14天以内的人类胚胎分离或者获取的。示例性人干细胞系包括H9人多能干细胞系,例如,可以是商用的H9 hESC细胞系。另外的示例性干细胞系包括可通过National Institutes of Health Human Embryonic Stem CellRegistry和Howard Hughes Medical Institute HUES集合获得的那些(如Cowan,C.A.等人,New England J.Med.350:13.(2004))所述。
如本文所用,“多能干细胞”具有分化成如下三个胚层中任何一个的潜力:内胚层(例如胃连接、胃肠道、肺等)、中胚层(例如肌肉、骨骼、血液、泌尿生殖组织等)或外胚层(例如表皮组织和神经系统组织)。如本文所用的术语“多能干细胞”还包括“诱导性多能干细胞”、“iPS”、“iPSC”或“iPSCs”,一种衍生自非多能细胞的多能干细胞。亲本细胞的实例包括已通过各种方式重编程以诱导性多能性、未分化表型的体细胞。这种“iPS”、“iPSC”或“iPSCs”细胞可以通过诱导某些调节基因的表达或通过某些蛋白质的外源应用来产生。诱导iPS细胞的方法是本领域已知的。如本文所用,“hiPSC”、“hiPSCs”、“hPSC”或“hPSCs”是人诱导性多能干细胞,“miPSC”、“miPSCs”、“mPSC”或“mPSCs”是鼠诱导性多能干细胞。
术语“多能干细胞特征”是指将多能干细胞与其他细胞区分开的细胞特征。产生能够在适当条件下分化成共同显示与来自所有三个生发层(内胚层、中胚层和外胚层)的细胞谱系相关的特征的细胞类型的后代的能力是多能干细胞特征。分子标志物的某些组合的表达或非表达也是多能干细胞特征。例如,人多能干细胞表达来自以下非限制性列表的至少几种和在一些实施方案中所有标志物:SSEA-3、SSEA-4、TRA-1-60、TRA-1-81、TRA-2-49/6E、ALP、Sox2、E-钙粘蛋白、UTF-1、Oct4、Rex1和Nanog。与多能干细胞相关的细胞形态也是多能干细胞特征。如本文所述,细胞不需要通过多能性以被重编程为内胚层祖细胞和/或肝细胞。
术语“多能(multipotent)”或“多能细胞(multipotent cell)”是指可以产生有限数量的其他特定细胞类型的细胞类型。例如,诱导性多能细胞能够形成内胚层细胞。此外,多能血液干细胞可以将自身分化为几种类型的血细胞,包括淋巴细胞、单核细胞、中性粒细胞等。术语“寡能”是指成体干细胞分化成仅少数不同细胞类型的能力。例如,淋巴或骨髓干细胞能够分别形成淋巴或骨髓谱系的细胞。术语“单能”是指细胞形成单细胞类型的能力。例如,精原干细胞只能形成精子细胞。
术语“非多能细胞”是指不是多能细胞的哺乳动物细胞。此类细胞的实例包括分化细胞以及祖细胞。分化细胞的实例包括但不限于来自选自骨髓、皮肤、骨骼肌、脂肪组织和外周血的组织的细胞。示例性细胞类型包括但不限于成纤维细胞、肝细胞、成肌细胞、神经元、成骨细胞、破骨细胞和T细胞。用于产生诱导性多能细胞、内胚层祖细胞和肝细胞的起始细胞可以是非多能细胞。分化的细胞包括但不限于多能细胞、寡能细胞、单能细胞、祖细胞和终末分化细胞。在特定的实施方案中,相对于更多能的细胞,较低能的细胞被认为是“分化的”。
术语“体细胞”是形成生物体的细胞。体细胞包括构成生物体内器官、皮肤、血液、骨骼和结缔组织的细胞,但不包括生殖细胞。细胞可以来自例如人或非人哺乳动物。示例性的非人哺乳动物包括但不限于小鼠、大鼠、猫、狗、兔、豚鼠、仓鼠、羊、猪、马、牛和非人灵长类动物。在一些实施方案中,细胞来自成年人或非人哺乳动物。在一些实施方案中,细胞来自新生儿、成年人或非人哺乳动物。
如本文所用,术语“受试者”或“患者”是指任何动物,例如驯养动物、动物园动物或人。“受试者”或“患者”可以是哺乳动物,如狗、猫、鸟、牲畜,也包括人。“受试者”和“患者”的具体实例包括但不限于具有与肝脏、心脏、肺、肾、胰腺、脑、神经组织、血液、骨骼、骨髓等相关的疾病或病症的个体(特别是人)。哺乳动物细胞可以来自人或非人哺乳动物。示例性的非人哺乳动物包括但不限于小鼠、大鼠、猫、狗、兔、豚鼠、仓鼠、羊、猪、马、牛和非人灵长类动物(例如,黑猩猩、猕猴和猿类)。
术语“HLA”或“人白细胞抗原”复合物是编码人主要组织相容性复合物(MHC)蛋白质的基因复合物。构成HLA复合物的这些细胞表面蛋白质负责调节对抗原的免疫应答。在人中,存在两种HLA:I类和II类,“HLA I”和“HLA II”。HLA I至少包括三种蛋白,HLA-A、HLA-B和HLA-C,它们从细胞内部呈递肽。HLA II至少包括五种蛋白,HLA-DP、HLA-DM、HLA-DOB、HLA-DQ和HLA-DR,其将来自细胞外的抗原呈递给T淋巴细胞。应当理解,“MHC”或“HLA”的使用并不意味着限制,因为它取决于基因是来自人(HLA)还是鼠(MHC)。因此,当涉及哺乳动物细胞时,这些术语在本文中可互换使用。
术语“基因敲除”是指使特定基因在其所在的宿主细胞中无活性的过程,其导致不产生目的蛋白质或无活性形式。如本领域技术人员所理解和下文进一步描述的,这可以通过多种不同方式实现,包括从基因中去除全部或部分核酸序列,或用其他序列中断序列,去除或改变调节组分(例如启动子)使得基因不被转录,改变阅读框,通过与mRNA的结合阻止翻译,或改变核酸的调节成分等。例如,可以去除或用“无义”序列替换目的基因的全部或部分编码区,可以去除或替换全部或部分调节序列(例如启动子),可以去除或替换翻译起始序列等。通常,敲除在基因组DNA水平上进行,使得细胞的后代也永久地携带敲除。
术语“基因敲入/引入”是指向宿主细胞添加遗传功能的过程。这导致编码蛋白质水平增加。如本领域技术人员所理解的,这可以通过几种方式实现,包括将一种或多种额外的基因拷贝添加到宿主细胞中或改变内源基因的调节组分,从而增加蛋白质的表达。这可以通过修饰启动子、添加不同的启动子、添加增强子或修饰其他基因表达序列来实现通常,敲入技术导致转基因的额外拷贝整合到宿主细胞中。
术语“β-2微球蛋白”或“β2M”或“B2M”蛋白可以是指具有下文SEQ ID NO:2所示的氨基酸序列,或与SEQ ID NO:2所示的氨基酸序列具有90%以上的序列同一性且具有与其类似的生物活性的人β2M蛋白。术语“CIITA”蛋白可以是指具有下文SEQ ID NO:5所示的氨基酸序列,或与SEQ ID NO:5所示的氨基酸序列具有90%以上的序列同一性且具有与其类似的生物活性的人CIITA蛋白质。
在细胞的上下文中,“野生型”是指在自然界中发现的细胞。然而,在多能干细胞的背景下,如本文所用,它还意指可能含有导致多能性的核酸变化但不经历本发明的基因编辑程序以实现低免疫原性的iPSCs。
术语“同种异体”是指宿主生物和细胞移植的遗传差异,其中产生免疫应答。
本文中的“B2M
如本文所用,“m/sHLAG”为膜(m)定位HLA-G1与可溶性(s)HLA-G5的简称。
如本文所用,“B2Mm/sHLAG hPSCs”细胞系为同时过表达膜定位HLA-G1与可溶性HLA-G5的细胞系。
如本文所用,所述的“表达”包括了“过表达”、“重组表达”。所述“过表达”例如与野生型中表达量相比,表达量发生显著性增加,如增加到野生型的1.2、1.5、2、3、5、8、10、15、20、30、50倍以上或更高。
如本文所用,所述的“不表达”是相对而言的,也涵盖“低表达”、“极低表达”,例如与野生型中表达量相比,经改造的细胞的表达被降低至野生型的15%以下、10%以下、8%以下、5%以下、3%以下、2%以下、1%以下或更低。
如本文所用,术语“含有”表示各种成分可一起应用于本发明的混合物或组合物中。因此,术语“主要由...组成”和“由...组成”包含在术语“含有”中。如本文所用,术语“有效量”或“有效剂量”是指可对受试者产生功能或活性的且可被人和/或动物所接受的量。
如本文所用,“药学上可接受的”的成分是适用于受试者而无过度不良副反应(如毒性、刺激和变态反应)的,即具有合理的效益/风险比的物质。术语“药学上可接受的载体”指用于治疗剂给药的载体,包括各种赋形剂和稀释剂。
本说明书中给出的每个最大数值限制都包括每个较低的数值限制,如同这些较低的数值限制在本文中明确写出一样。在整个说明书中给出的每个最小数值限制将包括每个更高的数值限制,如同在此明确写出这样的更高数值限制一样。本说明书中给出的每个数值范围将包括落入这样更宽的数值范围内的每个较窄的数值范围,如同这些较窄的数值范围都在本文中明确写出。
本发明的细胞及其用途
本发明提供了一种人多能干细胞,其由于本发明的遗传操作从而避免宿主免疫应答。具体而言,所述人多能干细胞的基因组经由改造而:不表达游离B2M蛋白,不表达CIITA蛋白,但表达(外源的)HLA-G1与分泌型HLA-G5。本领域技术人员可以理解,通过本发明所述的构建方法构建获得的人多能干细胞也在本发明的保护范围以内。
所述人多能干细胞允许衍生用于产生特定的组织和器官的“现成的”细胞产品。能够在人患者中使用所述人多能干细胞的衍生物从而产生显著益处,包括避免通常在移植中看到的长期辅助免疫抑制治疗和药物使用的能力,比如,所述细胞衍生的心肌细胞可避免人免疫细胞对其的识别与杀伤,在心脏缺血/再灌注损伤模型中具备更好的驻留效果。它还可以显著节省成本,因为可以使用细胞疗法而无需为每位患者进行单独治疗。因此,所述人多能干细胞具有免疫兼容性(避免宿主免疫应答),能用于更广的患者群体,可以作为产生普遍接受的衍生物的通用细胞来源。
本发明提供了一种人多能干细胞,其由于本发明中所述的几种遗传操作从而避免宿主免疫应答。所述细胞缺乏引发免疫应答的主要免疫抗原,并且经过改造以逃逸免疫细胞的识别与杀伤作用。
具体的,本发明所述的人多能干细胞不表达游离B2M蛋白和CIITA蛋白,但是,作为优选的一种方式,其可以成功表达分泌型B2M-HLA-G5融合蛋白。在一些实施方案中,本发明所述的人多能干细胞通过在所述人多能干细胞的基因组中整合重组核酸的方式实现。
示例性遗传操作的技术包括同源重组、敲入、ZFN(锌指核酸酶)、TALEN(转录激活因子样效应核酸酶)、CRISPR(成簇规律间隔短回文重复序列)/Cas9以及其他位点特异性核酸酶技术。存在大量基于CRISPR/Cas9的技术,参见例如Doudna and Charpentier,Sciencedoi:10.1126/science.1258096,其通过引用并入本文。这些技术使得能够在所需的基因座位点处进行双链DNA断裂。这些受控的双链断裂促进特定基因座位点的同源重组。该过程集中于用核酸内切酶靶向核酸分子的特定序列,例如染色体,所述核酸内切酶识别并结合序列并在核酸分子中诱导双链断裂。通过易错的非同源末端连接(NHEJ)或通过同源重组(HR)修复双链断裂。
如本领域技术人员所理解的,可以使用许多不同的技术来改造本发明的多能干细胞,以及如本文所述的使人多能干细胞缺乏引发免疫应答的主要免疫抗原,并且经过改造以逃逸免疫细胞的识别与杀伤作用。
通常,这些技术可以单独使用或组合使用。例如,在人多能干细胞的构建中,CRISPR可用于降低改造细胞中活性B2M和/或CIITA蛋白的表达,并用病毒技术(例如慢病毒)实现基因的稳定转导。此外,如本领域技术人员所理解的,尽管一个实施方案顺序地利用CRISPR/Cas9技术敲除B2M,然后通过CRISPR/Cas9技术敲除CIITA,但这些基因可以使用不同的技术以不同的顺序操作。
对于所有这些技术,使用公知的重组技术来产生如本文所述的重组核酸。在某些实施方案中,重组核酸(编码所需多肽例如B2M-HLA-G1融合蛋白或CIITA蛋白)可以与表达构建体中的一个或多个调节核苷酸序列可操作地连接。调节核苷酸序列通常适合宿主细胞和待治疗的受试者。本领域已知多种类型的合适表达载体和合适的调节序列用于多种宿主细胞。通常,一种或多种调节核苷酸序列可包括但不限于启动子序列、前导序列或信号序列、核糖体结合位点、转录起始和终止序列、翻译起始和终止序列、以及增强子或激活子序列。还考虑了本领域已知的组成型或诱导型启动子。启动子可以是天然存在的启动子,或组合多于一种启动子的元件的杂合启动子。表达构建体可以在细胞中存在于附加体(例如质粒)上,或者表达构建体可以插入染色体中。在一个具体实施方案中,表达载体包括选择标记基因以允许选择转化的宿主细胞。某些实施方案包括表达载体,其包含与至少一种调节序列可操作地连接的编码变体多肽的核苷酸序列。用于本文的调节序列包括启动子、增强子和其他表达控制元件。在某些实施方案中,设计表达载体用于选择待转化的宿主细胞、期望表达的特定变体多肽、载体的拷贝数、控制该拷贝数的能力或由载体编码的任何其他蛋白质如抗生素标志物的表达。
本发明中,也提供了从所述人多能干细胞衍生的心肌细胞,然后将其移植到需要的患者中,从而避免人免疫细胞对其的识别与杀伤,还提供了所述的衍生的心肌细胞在制备用于治疗心脏相关的疾病或病症的组合物或药物中的用途。
如本领域技术人员所理解的,人多能干细胞允许衍生用于产生特定的组织和器官的“现成的”细胞产品。能够在人患者中使用所述人多能干细胞的衍生物从而产生显著益处,包括避免通常在移植中看到的长期辅助免疫抑制治疗和药物使用的能力,比如,所述细胞衍生的心肌细胞可避免人免疫细胞对其的识别与杀伤,在心脏缺血/再灌注损伤模型中具备更好的驻留效果。它还可以显著节省成本,因为可以使用细胞疗法而无需为每位患者进行单独治疗。因此,所述人多能干细胞具有免疫兼容性,能用于更广的患者群体,可以作为产生普遍接受的衍生物的通用细胞来源。
本发明也提供一种人多能干细胞,其由于本发明中所述的几种遗传操作从而具有良好的免疫兼容性(避免宿主免疫应答)。所述细胞缺乏引发免疫应答的主要免疫抗原,并且经过改造而具有更好的免疫兼容性(避免宿主免疫应答)。本领域技术人员可以理解,通过本发明所述的构建方法构建获得的人多能干细胞也在本发明的保护范围以内。
提供从所述人多能干细胞衍生的心肌细胞,然后将其移植到需要的患者中,从而避免人免疫细胞对其的识别与杀伤,还提供了所述的衍生的心肌细胞在制备用于治疗心脏相关的疾病或病症的组合物或药物中的用途,优选的,所述心脏相关的疾病或病症是心肌损伤、心肌梗死、心肌缺血、缺血再灌注损伤或其他心脏损伤;更优选的,所述心脏相关的疾病或病症是缺血/再灌注损伤。也可以说,本发明提供了所述人多能干细胞衍生的心肌细胞在促进心肌梗死后的心肌修复、改善心肌梗死后的心功能、保护心肌缺血损伤的组合物或药物中的应用。
在优选的实施方式中,所述心脏相关的疾病或病症是心肌损伤、心肌梗死、心肌缺血、缺血再灌注损伤或其他心脏损伤;更优选的,所述心脏相关的疾病或病症是缺血/再灌注损伤。也可以说,本发明提供了所述人多能干细胞衍生的心肌细胞在促进心肌梗死后的心肌修复、改善心肌梗死后的心功能、保护心肌缺血损伤的组合物或药物中的应用。
从另一角度讲,本发明提供了从所述人多能干细胞衍生的心肌细胞,然后将其移植到需要的患者中,从而避免人免疫细胞对其的识别与杀伤,还提供了所述人多能干细胞衍生的心肌细胞在制备用于治疗心脏相关的疾病或病症的组合物或药物中的用途。作为本发明优选的一种方式,所述心脏相关的疾病或病症是心肌损伤、心肌梗死、心肌缺血、缺血再灌注损伤或其他心脏损伤。作为本发明更优选的一种方式,所述心脏相关的疾病或病症是缺血/再灌注损伤。也可以说,本发明提供了所述人多能干细胞衍生的心肌细胞在制备用于促进心肌梗死后的心肌修复、改善心肌梗死后的心功能、保护心肌缺血损伤的组合物或药物中的用途。
从治疗的角度,也可以说,本发明提供了所述人多能干细胞衍生的心肌细胞用于治疗心脏相关的疾病或病症。例如,用于治疗心肌损伤、心肌梗死、心肌缺血、缺血再灌注损伤等疾病或病症。作为本发明优选的一种方式,本发明提供了所述人多能干细胞衍生的心肌细胞用于改善心肌梗死后的心肌修复、改善心肌梗死后的心功能、保护心肌缺血损伤。
本发明还提供了一种组合物,它含有有效量的所述的衍生的心肌细胞,以及药学上可接受的载体。这类载体包括(但并不限于):盐水、缓冲液、葡萄糖、水、甘油、乙醇、及其组合。通常药物制剂应与给药方式相匹配,本发明的药物组合物可以被制成针剂形式,例如用生理盐水或含有葡萄糖和其他辅剂的水溶液通过常规方法进行制备。所述的药物组合物宜在无菌条件下制造。活性成分的给药量是治疗有效量。本发明的组合物可直接用于促进心肌梗死后的心肌修复、改善心肌梗死后的心功能、保护心肌缺血损伤。此外,还可同时与其它治疗剂或辅剂联合使用。
通常,可将这些物质配制于无毒的、惰性的和药学上可接受的水性载体介质中,其中pH通常约为5-8,较佳地,pH约为6-8。
本发明所述的衍生的心肌细胞的有效量可随给药的模式和待治疗的疾病的严重程度等而变化。优选的有效量的选择可以由本领域普通技术人员根据各种因素来确定(例如通过临床试验)。所述的因素包括但不限于:药代动力学参数例如生物利用率、代谢、半衰期等;患者所要治疗的疾病的严重程度、患者的体重、患者的免疫状况、给药的途径等。本发明的衍生的心肌细胞的给药方式没有特别的限制,可以是全身的或局部的。例如,本发明的衍生的心肌细胞可通过局部组织注射的方式给予,优选地为心肌注射。此外,其它方式的注射也是可以的,例如包括但不限于腹腔注射、静脉注射、口服、皮下注射、脊髓鞘内注射、皮内注射等的方式给予受试者。
本发明的方法
本发明也提供一种所述人多能干细胞的构建方法,包括:改造人多能干细胞,使之:不表达游离B2M蛋白,表达HLA-G1与分泌型HLA-G5;以及不表达CIITA蛋白。
本发明所提供的构建方法中,所述HLA-G1片段的编码基因可以包括HLA-G1的重链阅读框的编码序列,所述HLA-G1片段可以包括:
a)氨基酸序列如SEQ ID NO:1所示的多肽片段;或,
b)氨基酸序列与SEQ ID NO:1具有90%以上序列同一性且具有a)限定的多肽片段的功能的多肽片段。
HLA-G1重链序列(HLA-G1片段)的氨基酸序列:
GSHSMRYFSAAVSRPGRGEPRFIAMGYVDDTQFVRFDSDSACPRMEPRAPWVEQEGPEYWEEETRNTKAHAQTDRMNLQTLRGYYNQSEASSHTLQWMIGCDLGSDGRLLRGYEQYAYDGKDYLALNEDLRSWTAADTAAQISKRKCEAANVAEQRRAYLEGTCVEWLHRYLENGKEMLQRADPPKTHVTHHPVFDYEATLRCWALGFYPAEIILTWQRDGEDQTQDVELVETRPAGDGTFQKWAAVVVPSGEEQRYTCHVQHEGLPEPLMLRWKQSSLPTIPIMGIVAGLVVLAAVVTGAAVAAVLWRKKSSD*(SEQ ID NO:1)
具体的,所述b)中的氨基酸序列具体指:如SEQ ID NO:1所示的氨基酸序列经过取代、缺失或者添加一个或多个(具体可以是1-50、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,或者在N-末端和/或C-末端添加一个或多个(具体可以是1-50个、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,且具有氨基酸如SEQ ID NO:1所示的多肽片段的功能的多肽片段。例如,所述HLA-G1片段通常具有完整的α重链结构,与经典型HLA I分子不同,其主要具有免疫抑制的功能(例如,可以与抑制性受体相结合从而可以调控B细胞、T细胞、NK细胞和APC细胞介导的免疫反应等,这些抑制性受体主要包括ILT2/CD85j/LILRB1,ILT4/CD85d/LILRB2,和KIR2DL4/CD158d等)。所述b)中的氨基酸序列可与SEQ ID NO:1具有90%、93%、95%、97%、或99%以上的同一性。所述HLA-G1片段通常来源于人。
本发明所提供的构建方法中,所述第一B2M片段可以包括:c)氨基酸序列如SEQ IDNO:2所示的多肽片段;或,d)氨基酸序列与SEQ ID NO:2具有90%以上序列同一性且具有c)限定的多肽片段的功能的多肽片段。
内源性B2M蛋白质(第一B2M片段)的氨基酸序列:
MSRSVALAVLALLSLSGLEAIQRTPKIQVYSRHPAENGKSNFLNCYVSGFHPSDIEVDLLKNGERIEKVEHSDLSFSKDWSFYLLYYTEFTPTEKDEYACRVNHVTLSQPKIVKWDRDM(SEQ ID NO:2)
具体的,所述d)中的氨基酸序列具体指:如SEQ ID NO:2所示的氨基酸序列经过取代、缺失或者添加一个或多个(具体可以是1-50、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,或者在N-末端和/或C-末端添加一个或多个(具体可以是1-50个、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,且具有氨基酸如SEQ ID NO:2所示的多肽片段的功能的多肽片段。例如,所述第一B2M片段通常具有β折叠的片状结构,其主要具有与主要组织相容性复合物I类重链通过非共价键结合的功能。所述d)中的氨基酸序列可与SEQ ID NO:2具有90%、93%、95%、97%、或99%以上的同一性。所述第一B2M片段通常来源于人。
本发明所提供的构建方法中,所述B2M-HLA-G1融合蛋白还可以包括第一柔性连接肽段,所述第一柔性连接肽段通常位于HLA-G1片段和第一B2M片段之间。所述第一柔性连接肽段通常可以为一段长度合适的由甘氨酸(G)、丝氨酸(S)和/或丙氨酸(A)构成的柔性多肽,从而使相邻的蛋白质结构域可相对于彼此自由移动,例如,所述第一柔性连接肽段的氨基酸序列可以包括如(GS)
柔性(G
GlyGlyGlyGlySerGlyGlyGlyGlySerGlyGlyGlyGlySerGlyGlyGlyGlySer(SEQ IDNO:3)
B2M-HLA-G1融合蛋白的氨基酸序列:
编码B2M-HLA-G1融合蛋白的核酸序列,其中,内源性B2M基因外显子DNA序列加粗,内含子DNA序列加下划线:
本发明所提供的构建方法中,将人多能干细胞的基因组中整合外源的编码B2M-HLA-G1融合蛋白的核酸的方法具体可以包括:将HLA-G1片段的编码基因与人多能干细胞中内源性的B2M基因融合。在本发明的一些具体实施例中,可以将HLA-G1片段的编码基因替换位于内源B2M基因外显子3中的终止密码子。
本发明所提供的构建方法中,所述CIITA片段可以包括:e)氨基酸序列如SEQ IDNO:5所示的多肽片段;或,f)氨基酸序列与SEQ ID NO:5具有90%以上序列同一性且具有e)限定的多肽片段的功能的多肽片段。
具体的,所述f)中的氨基酸序列具体指:如SEQ ID NO:5所示的氨基酸序列经过取代、缺失或者添加一个或多个(具体可以是1-50、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,或者在N-末端和/或C-末端添加一个或多个(具体可以是1-50个、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,且具有氨基酸如SEQ ID NO:5所示的多肽片段的功能的多肽片段。例如,所述CIITA片段通常具有双或多功能结构域,其主要充当转录激活物,并在主要组织相容性复合物(MHC)II类基因的表达中起关键作用。所述f)中的氨基酸序列可与SEQ ID NO:5具有90%、93%、95%、97%、或99%以上的同一性。所述CIITA片段通常来源于人。
CIITA蛋白的氨基酸序列:
MRCLAPRPAGSYLSEPQGSSQCATMELGPLEGGYLELLNSDADPLCLYHFYDQMDLAGEEEIELYSEPDTDTINCDQFSRLLCDMEGDEETREAYANIAELDQYVFQDSQLEGLSKDIFKHIGPDEVIGESMEMPAEVGQKSQKRPFPEELPADLKHWKPAEPPTVVTGSLLVRPVSDCSTLPCLPLPALFNQEPASGQMRLEKTDQIPMPFSSSSLSCLNLPEGPIQFVPTISTLPHGLWQISEAGTGVSSIFIYHGEVPQASQVPPPSGFTVHGLPTSPDRPGSTSPFAPSATDLPSMPEPALTSRANMTEHKTSPTQCPAAGEVSNKLPKWPEPVEQFYRSLQDTYGAEPAGPDGILVEVDLVQARLERSSSKSLERELATPDWAERQLAQGGLAEVLLAAKEHRRPRETRVIAVLGKAGQGKSYWAGAVSRAWACGRLPQYDFVFSVPCHCLNRPGDAYGLQDLLFSLGPQPLVAADEVFSHILKRPDRVLLILDGFEELEAQDGFLHSTCGPAPAEPCSLRGLLAGLFQKKLLRGCTLLLTARPRGRLVQSLSKADALFELSGFSMEQAQAYVMRYFESSGMTEHQDRALTLLRDRPLLLSHSHSPTLCRAVCQLSEALLELGEDAKLPSTLTGLYVGLLGRAALDSPPGALAELAKLAWELGRRHQSTLQEDQFPSADVRTWAMAKGLVQHPPRAAESELAFPSFLLQCFLGALWLALSGEIKDKELPQYLALTPRKKRPYDNWLEGVPRFLAGLIFQPPARCLGALLGPSAAASVDRKQKVLARYLKRLQPGTLRARQLLELLHCAHEAEEAGIWQHVVQELPGRLSFLGTRLTPPDAHVLGKALEAAGQDFSLDLRSTGICPSGLGSLVGLSCVTRFRAALSDTVALWESLQQHGETKLLQAAEEKFTIEPFKAKSLKDVEDLGKLVQTQRTRSSSEDTAGELPAVRDLKKLEFALGPVSGPQAFPKLVRILTAFSSLQHLDLDALSENKIGDEGVSQLSATFPQLKSLETLNLSQNNITDLGAYKLAEALPSLAASLLRLSLYNNCICDVGAESLARVLPDMVSLRVMDVQYNKFTAAGAQQLAASLRRCPHVETLAMWTPTIPFSVQEHLQQQDSRISLR(SEQ ID NO:5)
本发明所提供的构建方法中,所述不表达CIITA的方法具体可以包括:针对人多能干细胞基因组中CIITA基因的外显子3进行敲除;较佳地,通过基因编辑方法进行敲除;更佳地,以SEQ ID NO:11所示核苷酸序列的gRNA(GGGAGGCTTATGCCAATAT)进行基因编辑。
本发明所提供的构建方法中,所述第二B2M片段可以包括:g)氨基酸序列如SEQ IDNO:2所示的多肽片段;或,h)氨基酸序列与SEQ ID NO:2具有90%以上序列同一性且具有g)限定的多肽片段的功能的多肽片段。
第二B2M片段的氨基酸序列:
MSRSVALAVLALLSLSGLEAIQRTPKIQVYSRHPAENGKSNFLNCYVSGFHPSDIEVDLLKNGERIEKVEHSDLSFSKDWSFYLLYYTEFTPTEKDEYACRVNHVTLSQPKIVKWDRDM(SEQ ID NO:2)
具体的,所述h)中的氨基酸序列具体指:如SEQ ID NO:2所示的氨基酸序列经过取代、缺失或者添加一个或多个(具体可以是1-50、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,或者在N-末端和/或C-末端添加一个或多个(具体可以是1-50个、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,且具有氨基酸如SEQ ID NO:2所示的多肽片段的功能的多肽片段。例如,所述第二B2M片段通常具有β折叠的片状结构,其主要具有与主要组织相容性复合物I类重链通过非共价键结合的功能。所述h)中的氨基酸序列可与SEQ ID NO:2具有90%、93%、95%、97%、或99%以上的同一性。所述第二B2M片段通常来源于人。
本发明所提供的构建方法中,所述HLA-G5片段包括:i)氨基酸序列如SEQ ID NO:6所示的多肽片段;或,j)氨基酸序列与SEQ ID NO:6具有90%以上序列同一性且具有i)限定的多肽片段的功能的多肽片段。
HLA-G5重链序列的氨基酸序列:
GSHSMRYFSAAVSRPGRGEPRFIAMGYVDDTQFVRFDSDSACPRMEPRAPWVEQEGPEYWEEETRNTKAHAQTDRMNLQTLRGYYNQSEASSHTLQWMIGCDLGSDGRLLRGYEQYAYDGKDYLALNEDLRSWTAADTAAQISKRKCEAANVAEQRRAYLEGTCVEWLHRYLENGKEMLQRADPPKTHVTHHPVFDYEATLRCWALGFYPAEIILTWQRDGEDQTQDVELVETRPAGDGTFQKWAAVVVPSGEEQRYTCHVQHEGLPEPLMLRWSKEGDGGIMSVRESRSLSEDL*(SEQ ID NO:6)
具体的,所述j)中的氨基酸序列具体指:如SEQ ID NO:6所示的氨基酸序列经过取代、缺失或者添加一个或多个(具体可以是1-50、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,或者在N-末端和/或C-末端添加一个或多个(具体可以是1-50个、1-30个、1-20个、1-10个、1-5个、1-3个、1个、2个、或3个)氨基酸而得到的,且具有氨基酸如SEQ ID NO:6所示的多肽片段的功能的多肽片段。例如,所述HLA-G5片段通常具有完整的α重链胞外结构,与经典型HLA I分子不同,其主要具有免疫抑制的功能(例如,可以与抑制性受体相结合从而可以调控B细胞、T细胞、NK细胞和APC细胞介导的免疫反应等,这些抑制性受体主要包括ILT2/CD85j/LILRB1,ILT4/CD85d/LILRB2,和KIR2DL4/CD158d等)。所述j)中的氨基酸序列可与SEQ ID NO:6具有90%、93%、95%、97%、或99%以上的同一性(Sequence identity)。所述HLA-G5片段通常来源于人。
本发明所提供的构建方法中,所述B2M-HLA-G5融合蛋白还可以包括第二柔性连接肽段,所述第二柔性连接肽段通常位于HLA-G5片段和第二B2M片段之间。所述第二柔性连接肽段通常可以为一段长度合适的由甘氨酸(G)、丝氨酸(S)和/或丙氨酸(A)构成的柔性多肽,从而使相邻的蛋白质结构域可相对于彼此自由移动,例如,所述第二柔性连接肽段的氨基酸序列可以包括如(GS)n、(GGS)n、(GGSG)n、(GGGS)nA、(GGGGS)nA、(GGGGA)nA、(GGGGG)nA等序列,其中,n选自1-10之间的整数。在本发明的一些具体实施例中,所述第二柔性连接肽段的氨基酸序列的长度可以为5-26。在本发明的一些具体实施例中,所述第二柔性连接肽段可以包括氨基酸序列如SEQ ID NO:5所示的多肽片段。在本发明另一具体实施例中,所述B2M-HLA-G5融合蛋白自N端至C端依次包括第二B2M片段和HLA-G5片段,所述B2M-HLA-G5融合蛋白包括氨基酸序列如SEQ ID NO:8所示的多肽片段。
柔性(G4S)4连接肽段(第二柔性连接肽段)的氨基酸序列:
GlyGlyGlyGlySerGlyGlyGlyGlySerGlyGlyGlyGlySerGlyGlyGlyGlySer(SEQ IDNO:3)
B2M-HLA-G5融合蛋白的氨基酸序列:
编码B2M-HLA-G5融合蛋白的核酸序列:
ATGTCTCGCtccgtggccttagctgtgctcgcgctactctctctttctggcctggaggctatccagcg
本发明所提供的构建方法中,将人多能干细胞的基因组中整合外源的编码B2M-HLA-G5融合蛋白的核酸的方法具体可以包括:通过慢病毒载体将编码B2M-HLA-G5融合蛋白的核酸整合入人多能干细胞的基因组,使其可以表达B2M-HLA-G5融合蛋白。
本发明所提供的人多能干细胞的构建方法可以成功地在人类多能干细胞的两个内源性B2M位点整合了HLA-G1片段序列,敲除CIITA片段序列,并且通过慢病毒载体将编码B2M-HLA-G5融合蛋白的序列整合入了人多能干细胞的基因组中。构建获得的人多能干细胞细胞系内源性HLA-A,-B,-C蛋白无法到达细胞膜表面。同时,还进行了CIITA的敲除,获得免疫兼容性非常优异、且多能性以及增殖的能力并未受到影响的多能干细胞;进一步地,该多能干细胞可作为细胞移植的目的细胞来源。
在一些实施方案中,破坏多能干细胞中基因的表达在本文中通常称为基因“敲除”。通常,完成两个破坏的技术是相同的。可以实现基因敲除的手段包括但不限于ZFN、TALEN和CRISPR/Cas9技术。其中,特别有用的实施方案是使用CRISPR/Cas9技术破坏基因。在一些情况下,CRISPR/Cas9技术用于将小的缺失/插入引入基因的编码区,使得不产生功能性蛋白,例如发生移码突变,其导致终止密码子的产生,使得产生截短的、非功能性蛋白质。
为了使得CIITA或B2M作为目的基因不表达,其它一些下调目的基因表达的技术也是可选的。作为一种可选方式,利用目的基因特异性的干扰RNA分子(如siRNA、shRNA、miRNA等),根据本发明中提供的CIITA或B2M序列信息,可以制备获得此类干扰RNA分子。所述的干扰RNA可通过采用适当的转染试剂被输送到细胞内,或还可采用本领域已知的多种技术被输送到细胞内。siRNAs的长度通常约为21个核苷酸(例如21-23个核苷酸)。在将小RNA或RNAi导入细胞后,该序列被传递到称为RISC(RNA诱导沉默复合物)的酶复合物,RISC识别目标并用核酸内切酶切割它。作为另一种可选方式,利用shRNA技术进行干扰作用。shRNA是一种RNA序列,它可以使一个紧密的发夹旋转,可以用来沉默基因表达通过RNA干扰。shRNA使用导入细胞的载体并利用启动子(如U6)来确保shRNA始终被表达。作为另一种可选方式,利用与目的基因特异性杂交的反义化合物来调节目的基因表达。寡聚物与其靶核酸的特异性杂交干扰了核酸的正常功能。这种通过与靶核酸特异性杂交的化合物对靶核酸功能的调节通常被称为“反义”。作为另一种可选方式,可采用同源重组的方法,特异性地靶向于目的基因,使之发生表达缺陷或缺失表达。尽管如此,基于CRISPR的方案为优选的实施方案。本领域技术人员可以理解,由本发明所提供的人多能干细胞的构建方法构建获得的人多能干细胞也可以被包含在本发明中。
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件如J.萨姆布鲁克等编著,分子克隆实验指南,第三版,科学出版社,中所述的条件,或按照制造厂商所建议的条件。
除非另外说明,以下数据统计采用Graphpad软件进行,两组数据之间比较采用t检验方法检验是否具有统计学意义;3-4组数据之间的比较采用单因素方差分析(one-wayANOVA),事后检验采用Dunnett方法。P值小于0.05被认为具有差异具有统计学意义。
实施例1、B2M/CIITA双敲除hPSCs(DKO-hPSCs)的构建
本发明的后续实施例中,所用hPSCs来自于人胚胎干细胞,为H9株系。
为比较CIITA
根据B2M与CIITA基因转录本信息,经过分析研究,本发明人优化了适合基因编辑位置的序列,基于此设计靶向该基因组位置的gRNA,gRNA序列见表1。分别将gRNA构建到U6启动子启动的质粒上,获得gRNA表达质粒gRNA-B2M与gRNA-CIITA。在构建DKO-hPSCs中先将gRNA-B2M质粒与Cas9-T2A-GFP(Addgene#44719)质粒一起转入hPSCs,培养4天后进行低密度单细胞铺板,单克隆生长后手动挑取并进行基因组DNA PCR及测序分析,选取存在非3整倍数碱基缺失或插入的克隆为B2M敲除hPSCs。
在此基础上进一步构建CIITA敲除hPSCs,方法同上,但将gRNA质粒换成gRNA-CIITA质粒,并进一步挑取CIITA敲除的单克隆。通过以上方法构建经敲除的hPSCs。获得发生非3倍数碱基移码突变的克隆,作为B2M/CIITA双敲除hPSCs(DKO-hPSCs)(图2A)。
表1、靶向于B2M、CIITA位点的gRNA序列
实施例2、CIITA
构建CIITA
在野生型hPSCs中采用CRISPR/Cas9基因编辑方法在B2M基因编码框终止密码子之前插入有编码柔性(G
进一步地,利用基因编辑方法(本实施例中采用CRISPR/Cas9体系)敲除CIITA基因,通过LONZA nucleofection转染gRNA-CIITA质粒(其中gRNA序列如表1)与Cas9-T2A-GFP质粒,并挑取单克隆进行DNA PCR测序,选择发生非3倍数碱基移码突变的克隆,获得CIITA敲除的B2Mm/sHLAG hPSCs,构建免疫兼容型hPSCs,命名为CIITA
该细胞可进一步利用组织特异性细胞系分化为如心肌细胞、内皮细胞、神经细胞、NK细胞等免疫兼容型功能细胞。
实施例3、多能性标志物鉴定
为了鉴定DKO-hPSCs和CIITA
流式细胞术鉴定方法:
培养的wt-hPSCs,DKO-hPSCs和CIITA-/-B2Mm/sHLAG-hPSCs生长至70%汇合度,Accutase消化成单细胞,离心收集细胞后固定、破膜并用hPSCs多能性细胞标志物OCT4及SSEA4抗体孵育,然后利用APC荧光基团偶联的二抗染色,采用流式细胞术分析。对照组采用同型对照抗体。检测结果见图3。
细胞免疫荧光鉴定方法:
培养的wt-hPSCs,DKO-hPSCs和CIITA-/-B2Mm/sHLAG-hPSCs克隆生长至合适大小,吸去培养基后固定、破膜并用多能性细胞标志物OCT4及SOX2抗体孵育,然后利用Alexa 488荧光基团偶联的二抗染色,采用激光共聚焦显微镜进行图像采集。检测结果见图4。
如图3所示,三种细胞中多能性标志物OCT4及SSEA4表达阳性率均在98%以上;如图4所示,多能性标志物OCT4和SOX2均有良好的核定位特征。
以上数据证明,所获得的DKO-hPSCs及CIITA
实施例4、HLA分子表达鉴定
为了鉴定利用以上方法构建的细胞是否表达HLA分子,本发明人首先采用流式细胞术进行鉴定。
流式细胞术鉴定方法:
wt-hPSCs,DKO-hPSCs和CIITA
HLA-A,-B,-C是经典HLA I家族分子成员,比较wt-hPSCs、DKO-hPSCs及CIITA
利用免疫印迹方法鉴定分泌型HLA-G5分子表达。
免疫印迹鉴定分泌型HLA-G5表达方法:
wt-hPSCs,DKO-hPSCs和CIITA
结果证明CIITA
实施例5、内皮细胞及心肌细胞的诱导分化和鉴定
hPSCs可以通过体外诱导方法获得多种组织类型细胞,在本实施例中,本发明人将hPSCs向内皮和心肌细胞分化。
1、内皮细胞的分化
wt-hPSCs,DKO-hPSCs和CIITA
取分化的细胞(内皮细胞,第6天;心肌细胞,第14天),Accutase消化为单细胞,采用70μm滤网过滤去掉细胞团块。内皮细胞采用APC偶联的CD144抗体直接与细胞孵育进行检测;心肌细胞经过固定、破膜,用心肌细胞标志物cTNT抗体作为一抗,APC偶联的抗小鼠IgG抗体作为二抗进行检测。
结果显示,在内皮细胞分化中,经过纯化后的内皮细胞具备良好的内皮细胞形态及极高纯度的内皮细胞标志物CD144表达比例(图6A)。因此,分化获得免疫兼容型内皮细胞。
2、心肌细胞的分化
wt-hPSCs,DKO-hPSCs和CIITA
心肌细胞的细胞免疫荧光鉴定方法同实施例3所述的hPSCs多能性标志物检测方法,将一抗替换为心肌细胞标志物cTNT抗体与间隙连接Connexin 43抗体。
在分化的心肌细胞中,通过肌节蛋白alpha-ACTININ染色,三种hPSCs来源的心肌细胞均具备良好的肌丝结构,而且细胞之间形成良好的间隙连接(Connexin-43)(图6B)。免疫荧光鉴定肌节蛋白α-ACTININ和间隙蛋白Connexin-43在分化的心肌细胞中的表达如图6C。
因此,分化获得免疫兼容型心肌细胞(CIITA
实施例6、免疫识别与杀伤作用
为探究CIITA
1、T细胞激活标志物检测
T细胞会被不匹配的HLA分子激活,因此利用wt-CMs作为对照和CIITA
2、T细胞增殖检测
前期处理同“T细胞激活标志物检测”,共培养之前将PBMCs标记上CFSE荧光标记后再与心肌细胞共培养,培养时间为7天,之后收集PBMCs,孵育T细胞标志物CD3抗体,然后流式细胞检测。CFSE在标记细胞中不会从细胞中泄露,但会随着细胞分裂稀释,因此增殖的T细胞中CFSE荧光信号降低,通过比较低CFSE信号的细胞占全部CD3阳性细胞的比例比较wt-CMs和CIITA
3、T细胞对靶细胞的杀伤作用检测
前期处理同“T细胞激活标志物检测”,PBMCs与wt-CMs或CIITA
4、PBMC分泌的IFN-γ检测
前期处理同“T细胞激活标志物检测”,PBMCs与wt-CMs或CIITA
5、NK细胞对靶细胞的识别与杀伤检测
NK细胞可识别无HLA分子表达的细胞,因此在本实施例中采用DKO-CMs作为对照。将DKO-CMs和CIITA
6、NK细胞分泌的IFN-γ检测
细胞前期处理同“NK细胞对靶细胞的识别与杀伤检测”,共培养3-4天后收集共培养上清,300g离心3分钟去除细胞与细胞碎片,然后利用IFN-γ检测试剂盒检测上清中IFN-γ的含量。
将人PBMCs与心肌细胞共培养,并鉴定早期T细胞激活标志物CD69表达。结果显示,相比wt心肌细胞(wt-CMs),免疫兼容型心肌细胞(CIITA
为检验CIITA
以上数据证明,CIITA
实施例7、心梗后移植hPSCs源心肌细胞后细胞驻留鉴定
为进一步探究在体损伤环境下CIITA
移植后第28天对小鼠心脏进行收样,通过免疫荧光及qRT-PCR鉴定移植细胞驻留。移植细胞驻留检测方法如下:
细胞移植后28天,收集小鼠心脏并进行OCT包埋。将小鼠心脏按照一定的间距从心尖到结扎点分为12层,并对每层细胞进行冰冻切片,然后利用免疫荧光鉴定移植细胞,同时利用Masson染色统计移植细胞区域占疤痕区域的比例。
免疫荧光:冰冻切片后将组织固定、通透及封闭,然后共孵育肌节蛋白α-ACTININ抗体与人KU80抗体(C48E7,CST)。利用荧光显微镜采集图像并进行统计。
qRT-PCR:收集细胞移植后28天Hu-mice心脏样本,抽提RNA后翻转为cDNA,利用人cTNT引物通过荧光定量PCR鉴定细胞驻留。
通过比较细胞驻留面积发现,在雌性与雄性小鼠中,CIITA
以上数据证明,CIITA
实施例8、移植细胞对心梗区域的修复作用
进一步,本发明人利用Masson染色探究移植细胞驻留对小鼠心脏损伤区域的修复作用。
Masson染色方法:冰冻切片后将组织固定,然后利用碧云天Masson染色试剂盒染色,统计再肌肉化面积及疤痕面积,计算再肌肉化比例。
再肌肉化比例=再肌肉面积/疤痕面积
结果显示,小鼠心脏损伤后损伤部位细胞逐渐死亡,形成疤痕组织。比较三种细胞移植后小鼠心脏切片发现,CIITA
统计结果显示,CIITA
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。同时,在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。
序列表
<110> 中国科学院上海营养与健康研究所
上海市东方医院(同济大学附属东方医院)
同济大学
<120> 免疫兼容型人多能干细胞、其制备方法及应用
<130> 223664
<160> 11
<170> SIPOSequenceListing 1.0
<210> 1
<211> 314
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(314)
<223> HLA-G1重链序列
<400> 1
Gly Ser His Ser Met Arg Tyr Phe Ser Ala Ala Val Ser Arg Pro Gly
1 5 1015
Arg Gly Glu Pro Arg Phe Ile Ala Met Gly Tyr Val Asp Asp Thr Gln
202530
Phe Val Arg Phe Asp Ser Asp Ser Ala Cys Pro Arg Met Glu Pro Arg
354045
Ala Pro Trp Val Glu Gln Glu Gly Pro Glu Tyr Trp Glu Glu Glu Thr
505560
Arg Asn Thr Lys Ala His Ala Gln Thr Asp Arg Met Asn Leu Gln Thr
65707580
Leu Arg Gly Tyr Tyr Asn Gln Ser Glu Ala Ser Ser His Thr Leu Gln
859095
Trp Met Ile Gly Cys Asp Leu Gly Ser Asp Gly Arg Leu Leu Arg Gly
100 105 110
Tyr Glu Gln Tyr Ala Tyr Asp Gly Lys Asp Tyr Leu Ala Leu Asn Glu
115 120 125
Asp Leu Arg Ser Trp Thr Ala Ala Asp Thr Ala Ala Gln Ile Ser Lys
130 135 140
Arg Lys Cys Glu Ala Ala Asn Val Ala Glu Gln Arg Arg Ala Tyr Leu
145 150 155 160
Glu Gly Thr Cys Val Glu Trp Leu His Arg Tyr Leu Glu Asn Gly Lys
165 170 175
Glu Met Leu Gln Arg Ala Asp Pro Pro Lys Thr His Val Thr His His
180 185 190
Pro Val Phe Asp Tyr Glu Ala Thr Leu Arg Cys Trp Ala Leu Gly Phe
195 200 205
Tyr Pro Ala Glu Ile Ile Leu Thr Trp Gln Arg Asp Gly Glu Asp Gln
210 215 220
Thr Gln Asp Val Glu Leu Val Glu Thr Arg Pro Ala Gly Asp Gly Thr
225 230 235 240
Phe Gln Lys Trp Ala Ala Val Val Val Pro Ser Gly Glu Glu Gln Arg
245 250 255
Tyr Thr Cys His Val Gln His Glu Gly Leu Pro Glu Pro Leu Met Leu
260 265 270
Arg Trp Lys Gln Ser Ser Leu Pro Thr Ile Pro Ile Met Gly Ile Val
275 280 285
Ala Gly Leu Val Val Leu Ala Ala Val Val Thr Gly Ala Ala Val Ala
290 295 300
Ala Val Leu Trp Arg Lys Lys Ser Ser Asp
305 310
<210> 2
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<221> PEPTIDE
<222> (1)..(119)
<223> B2M蛋白
<400> 2
Met Ser Arg Ser Val Ala Leu Ala Val Leu Ala Leu Leu Ser Leu Ser
1 5 1015
Gly Leu Glu Ala Ile Gln Arg Thr Pro Lys Ile Gln Val Tyr Ser Arg
202530
His Pro Ala Glu Asn Gly Lys Ser Asn Phe Leu Asn Cys Tyr Val Ser
354045
Gly Phe His Pro Ser Asp Ile Glu Val Asp Leu Leu Lys Asn Gly Glu
505560
Arg Ile Glu Lys Val Glu His Ser Asp Leu Ser Phe Ser Lys Asp Trp
65707580
Ser Phe Tyr Leu Leu Tyr Tyr Thr Glu Phe Thr Pro Thr Glu Lys Asp
859095
Glu Tyr Ala Cys Arg Val Asn His Val Thr Leu Ser Gln Pro Lys Ile
100 105 110
Val Lys Trp Asp Arg Asp Met
115
<210> 3
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<221> PEPTIDE
<222> (1)..(20)
<223> 柔性(G4S)4连接肽段
<400> 3
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 1015
Gly Gly Gly Ser
20
<210> 4
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<221> PEPTIDE
<222> (1)..(453)
<223> B2M-HLA-G1融合蛋白的氨基酸序列
<400> 4
Met Ser Arg Ser Val Ala Leu Ala Val Leu Ala Leu Leu Ser Leu Ser
1 5 1015
Gly Leu Glu Ala Ile Gln Arg Thr Pro Lys Ile Gln Val Tyr Ser Arg
202530
His Pro Ala Glu Asn Gly Lys Ser Asn Phe Leu Asn Cys Tyr Val Ser
354045
Gly Phe His Pro Ser Asp Ile Glu Val Asp Leu Leu Lys Asn Gly Glu
505560
Arg Ile Glu Lys Val Glu His Ser Asp Leu Ser Phe Ser Lys Asp Trp
65707580
Ser Phe Tyr Leu Leu Tyr Tyr Thr Glu Phe Thr Pro Thr Glu Lys Asp
859095
Glu Tyr Ala Cys Arg Val Asn His Val Thr Leu Ser Gln Pro Lys Ile
100 105 110
Val Lys Trp Asp Arg Asp Met Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Ser His Ser Met
130 135 140
Arg Tyr Phe Ser Ala Ala Val Ser Arg Pro Gly Arg Gly Glu Pro Arg
145 150 155 160
Phe Ile Ala Met Gly Tyr Val Asp Asp Thr Gln Phe Val Arg Phe Asp
165 170 175
Ser Asp Ser Ala Cys Pro Arg Met Glu Pro Arg Ala Pro Trp Val Glu
180 185 190
Gln Glu Gly Pro Glu Tyr Trp Glu Glu Glu Thr Arg Asn Thr Lys Ala
195 200 205
His Ala Gln Thr Asp Arg Met Asn Leu Gln Thr Leu Arg Gly Tyr Tyr
210 215 220
Asn Gln Ser Glu Ala Ser Ser His Thr Leu Gln Trp Met Ile Gly Cys
225 230 235 240
Asp Leu Gly Ser Asp Gly Arg Leu Leu Arg Gly Tyr Glu Gln Tyr Ala
245 250 255
Tyr Asp Gly Lys Asp Tyr Leu Ala Leu Asn Glu Asp Leu Arg Ser Trp
260 265 270
Thr Ala Ala Asp Thr Ala Ala Gln Ile Ser Lys Arg Lys Cys Glu Ala
275 280 285
Ala Asn Val Ala Glu Gln Arg Arg Ala Tyr Leu Glu Gly Thr Cys Val
290 295 300
Glu Trp Leu His Arg Tyr Leu Glu Asn Gly Lys Glu Met Leu Gln Arg
305 310 315 320
Ala Asp Pro Pro Lys Thr His Val Thr His His Pro Val Phe Asp Tyr
325 330 335
Glu Ala Thr Leu Arg Cys Trp Ala Leu Gly Phe Tyr Pro Ala Glu Ile
340 345 350
Ile Leu Thr Trp Gln Arg Asp Gly Glu Asp Gln Thr Gln Asp Val Glu
355 360 365
Leu Val Glu Thr Arg Pro Ala Gly Asp Gly Thr Phe Gln Lys Trp Ala
370 375 380
Ala Val Val Val Pro Ser Gly Glu Glu Gln Arg Tyr Thr Cys His Val
385 390 395 400
Gln His Glu Gly Leu Pro Glu Pro Leu Met Leu Arg Trp Lys Gln Ser
405 410 415
Ser Leu Pro Thr Ile Pro Ile Met Gly Ile Val Ala Gly Leu Val Val
420 425 430
Leu Ala Ala Val Val Thr Gly Ala Ala Val Ala Ala Val Leu Trp Arg
435 440 445
Lys Lys Ser Ser Asp
450
<210> 5
<211> 1130
<212> PRT
<213> Artificial Sequence
<220>
<221> PEPTIDE
<222> (1)..(1130)
<223> CIITA蛋白的氨基酸序列
<400> 5
Met Arg Cys Leu Ala Pro Arg Pro Ala Gly Ser Tyr Leu Ser Glu Pro
1 5 1015
Gln Gly Ser Ser Gln Cys Ala Thr Met Glu Leu Gly Pro Leu Glu Gly
202530
Gly Tyr Leu Glu Leu Leu Asn Ser Asp Ala Asp Pro Leu Cys Leu Tyr
354045
His Phe Tyr Asp Gln Met Asp Leu Ala Gly Glu Glu Glu Ile Glu Leu
505560
Tyr Ser Glu Pro Asp Thr Asp Thr Ile Asn Cys Asp Gln Phe Ser Arg
65707580
Leu Leu Cys Asp Met Glu Gly Asp Glu Glu Thr Arg Glu Ala Tyr Ala
859095
Asn Ile Ala Glu Leu Asp Gln Tyr Val Phe Gln Asp Ser Gln Leu Glu
100 105 110
Gly Leu Ser Lys Asp Ile Phe Lys His Ile Gly Pro Asp Glu Val Ile
115 120 125
Gly Glu Ser Met Glu Met Pro Ala Glu Val Gly Gln Lys Ser Gln Lys
130 135 140
Arg Pro Phe Pro Glu Glu Leu Pro Ala Asp Leu Lys His Trp Lys Pro
145 150 155 160
Ala Glu Pro Pro Thr Val Val Thr Gly Ser Leu Leu Val Arg Pro Val
165 170 175
Ser Asp Cys Ser Thr Leu Pro Cys Leu Pro Leu Pro Ala Leu Phe Asn
180 185 190
Gln Glu Pro Ala Ser Gly Gln Met Arg Leu Glu Lys Thr Asp Gln Ile
195 200 205
Pro Met Pro Phe Ser Ser Ser Ser Leu Ser Cys Leu Asn Leu Pro Glu
210 215 220
Gly Pro Ile Gln Phe Val Pro Thr Ile Ser Thr Leu Pro His Gly Leu
225 230 235 240
Trp Gln Ile Ser Glu Ala Gly Thr Gly Val Ser Ser Ile Phe Ile Tyr
245 250 255
His Gly Glu Val Pro Gln Ala Ser Gln Val Pro Pro Pro Ser Gly Phe
260 265 270
Thr Val His Gly Leu Pro Thr Ser Pro Asp Arg Pro Gly Ser Thr Ser
275 280 285
Pro Phe Ala Pro Ser Ala Thr Asp Leu Pro Ser Met Pro Glu Pro Ala
290 295 300
Leu Thr Ser Arg Ala Asn Met Thr Glu His Lys Thr Ser Pro Thr Gln
305 310 315 320
Cys Pro Ala Ala Gly Glu Val Ser Asn Lys Leu Pro Lys Trp Pro Glu
325 330 335
Pro Val Glu Gln Phe Tyr Arg Ser Leu Gln Asp Thr Tyr Gly Ala Glu
340 345 350
Pro Ala Gly Pro Asp Gly Ile Leu Val Glu Val Asp Leu Val Gln Ala
355 360 365
Arg Leu Glu Arg Ser Ser Ser Lys Ser Leu Glu Arg Glu Leu Ala Thr
370 375 380
Pro Asp Trp Ala Glu Arg Gln Leu Ala Gln Gly Gly Leu Ala Glu Val
385 390 395 400
Leu Leu Ala Ala Lys Glu His Arg Arg Pro Arg Glu Thr Arg Val Ile
405 410 415
Ala Val Leu Gly Lys Ala Gly Gln Gly Lys Ser Tyr Trp Ala Gly Ala
420 425 430
Val Ser Arg Ala Trp Ala Cys Gly Arg Leu Pro Gln Tyr Asp Phe Val
435 440 445
Phe Ser Val Pro Cys His Cys Leu Asn Arg Pro Gly Asp Ala Tyr Gly
450 455 460
Leu Gln Asp Leu Leu Phe Ser Leu Gly Pro Gln Pro Leu Val Ala Ala
465 470 475 480
Asp Glu Val Phe Ser His Ile Leu Lys Arg Pro Asp Arg Val Leu Leu
485 490 495
Ile Leu Asp Gly Phe Glu Glu Leu Glu Ala Gln Asp Gly Phe Leu His
500 505 510
Ser Thr Cys Gly Pro Ala Pro Ala Glu Pro Cys Ser Leu Arg Gly Leu
515 520 525
Leu Ala Gly Leu Phe Gln Lys Lys Leu Leu Arg Gly Cys Thr Leu Leu
530 535 540
Leu Thr Ala Arg Pro Arg Gly Arg Leu Val Gln Ser Leu Ser Lys Ala
545 550 555 560
Asp Ala Leu Phe Glu Leu Ser Gly Phe Ser Met Glu Gln Ala Gln Ala
565 570 575
Tyr Val Met Arg Tyr Phe Glu Ser Ser Gly Met Thr Glu His Gln Asp
580 585 590
Arg Ala Leu Thr Leu Leu Arg Asp Arg Pro Leu Leu Leu Ser His Ser
595 600 605
His Ser Pro Thr Leu Cys Arg Ala Val Cys Gln Leu Ser Glu Ala Leu
610 615 620
Leu Glu Leu Gly Glu Asp Ala Lys Leu Pro Ser Thr Leu Thr Gly Leu
625 630 635 640
Tyr Val Gly Leu Leu Gly Arg Ala Ala Leu Asp Ser Pro Pro Gly Ala
645 650 655
Leu Ala Glu Leu Ala Lys Leu Ala Trp Glu Leu Gly Arg Arg His Gln
660 665 670
Ser Thr Leu Gln Glu Asp Gln Phe Pro Ser Ala Asp Val Arg Thr Trp
675 680 685
Ala Met Ala Lys Gly Leu Val Gln His Pro Pro Arg Ala Ala Glu Ser
690 695 700
Glu Leu Ala Phe Pro Ser Phe Leu Leu Gln Cys Phe Leu Gly Ala Leu
705 710 715 720
Trp Leu Ala Leu Ser Gly Glu Ile Lys Asp Lys Glu Leu Pro Gln Tyr
725 730 735
Leu Ala Leu Thr Pro Arg Lys Lys Arg Pro Tyr Asp Asn Trp Leu Glu
740 745 750
Gly Val Pro Arg Phe Leu Ala Gly Leu Ile Phe Gln Pro Pro Ala Arg
755 760 765
Cys Leu Gly Ala Leu Leu Gly Pro Ser Ala Ala Ala Ser Val Asp Arg
770 775 780
Lys Gln Lys Val Leu Ala Arg Tyr Leu Lys Arg Leu Gln Pro Gly Thr
785 790 795 800
Leu Arg Ala Arg Gln Leu Leu Glu Leu Leu His Cys Ala His Glu Ala
805 810 815
Glu Glu Ala Gly Ile Trp Gln His Val Val Gln Glu Leu Pro Gly Arg
820 825 830
Leu Ser Phe Leu Gly Thr Arg Leu Thr Pro Pro Asp Ala His Val Leu
835 840 845
Gly Lys Ala Leu Glu Ala Ala Gly Gln Asp Phe Ser Leu Asp Leu Arg
850 855 860
Ser Thr Gly Ile Cys Pro Ser Gly Leu Gly Ser Leu Val Gly Leu Ser
865 870 875 880
Cys Val Thr Arg Phe Arg Ala Ala Leu Ser Asp Thr Val Ala Leu Trp
885 890 895
Glu Ser Leu Gln Gln His Gly Glu Thr Lys Leu Leu Gln Ala Ala Glu
900 905 910
Glu Lys Phe Thr Ile Glu Pro Phe Lys Ala Lys Ser Leu Lys Asp Val
915 920 925
Glu Asp Leu Gly Lys Leu Val Gln Thr Gln Arg Thr Arg Ser Ser Ser
930 935 940
Glu Asp Thr Ala Gly Glu Leu Pro Ala Val Arg Asp Leu Lys Lys Leu
945 950 955 960
Glu Phe Ala Leu Gly Pro Val Ser Gly Pro Gln Ala Phe Pro Lys Leu
965 970 975
Val Arg Ile Leu Thr Ala Phe Ser Ser Leu Gln His Leu Asp Leu Asp
980 985 990
Ala Leu Ser Glu Asn Lys Ile Gly Asp Glu Gly Val Ser Gln Leu Ser
995 10001005
Ala Thr Phe Pro Gln Leu Lys Ser Leu Glu Thr Leu Asn Leu Ser Gln
101010151020
Asn Asn Ile Thr Asp Leu Gly Ala Tyr Lys Leu Ala Glu Ala Leu Pro
1025103010351040
Ser Leu Ala Ala Ser Leu Leu Arg Leu Ser Leu Tyr Asn Asn Cys Ile
104510501055
Cys Asp Val Gly Ala Glu Ser Leu Ala Arg Val Leu Pro Asp Met Val
106010651070
Ser Leu Arg Val Met Asp Val Gln Tyr Asn Lys Phe Thr Ala Ala Gly
107510801085
Ala Gln Gln Leu Ala Ala Ser Leu Arg Arg Cys Pro His Val Glu Thr
109010951100
Leu Ala Met Trp Thr Pro Thr Ile Pro Phe Ser Val Gln Glu His Leu
1105111011151120
Gln Gln Gln Asp Ser Arg Ile Ser Leu Arg
11251130
<210> 6
<211> 295
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(295)
<223> HLA-G5重链序列的氨基酸序列
<400> 6
Gly Ser His Ser Met Arg Tyr Phe Ser Ala Ala Val Ser Arg Pro Gly
1 5 1015
Arg Gly Glu Pro Arg Phe Ile Ala Met Gly Tyr Val Asp Asp Thr Gln
202530
Phe Val Arg Phe Asp Ser Asp Ser Ala Cys Pro Arg Met Glu Pro Arg
354045
Ala Pro Trp Val Glu Gln Glu Gly Pro Glu Tyr Trp Glu Glu Glu Thr
505560
Arg Asn Thr Lys Ala His Ala Gln Thr Asp Arg Met Asn Leu Gln Thr
65707580
Leu Arg Gly Tyr Tyr Asn Gln Ser Glu Ala Ser Ser His Thr Leu Gln
859095
Trp Met Ile Gly Cys Asp Leu Gly Ser Asp Gly Arg Leu Leu Arg Gly
100 105 110
Tyr Glu Gln Tyr Ala Tyr Asp Gly Lys Asp Tyr Leu Ala Leu Asn Glu
115 120 125
Asp Leu Arg Ser Trp Thr Ala Ala Asp Thr Ala Ala Gln Ile Ser Lys
130 135 140
Arg Lys Cys Glu Ala Ala Asn Val Ala Glu Gln Arg Arg Ala Tyr Leu
145 150 155 160
Glu Gly Thr Cys Val Glu Trp Leu His Arg Tyr Leu Glu Asn Gly Lys
165 170 175
Glu Met Leu Gln Arg Ala Asp Pro Pro Lys Thr His Val Thr His His
180 185 190
Pro Val Phe Asp Tyr Glu Ala Thr Leu Arg Cys Trp Ala Leu Gly Phe
195 200 205
Tyr Pro Ala Glu Ile Ile Leu Thr Trp Gln Arg Asp Gly Glu Asp Gln
210 215 220
Thr Gln Asp Val Glu Leu Val Glu Thr Arg Pro Ala Gly Asp Gly Thr
225 230 235 240
Phe Gln Lys Trp Ala Ala Val Val Val Pro Ser Gly Glu Glu Gln Arg
245 250 255
Tyr Thr Cys His Val Gln His Glu Gly Leu Pro Glu Pro Leu Met Leu
260 265 270
Arg Trp Ser Lys Glu Gly Asp Gly Gly Ile Met Ser Val Arg Glu Ser
275 280 285
Arg Ser Leu Ser Glu Asp Leu
290 295
<210> 7
<211> 19
<212> DNA/RNA
<213> Artificial Sequence
<220>
<221> misc_RNA
<222> (1)..(19)
<223> B2M位点的gRNA序列
<400> 7
aagattcagg tttactcac 19
<210> 8
<211> 434
<212> PRT
<213> Artificial Sequence
<220>
<221> CHAIN
<222> (1)..(434)
<223> B2M-HLA-G5融合蛋白的氨基酸序列
<400> 8
Met Ser Arg Ser Val Ala Leu Ala Val Leu Ala Leu Leu Ser Leu Ser
1 5 1015
Gly Leu Glu Ala Ile Gln Arg Thr Pro Lys Ile Gln Val Tyr Ser Arg
202530
His Pro Ala Glu Asn Gly Lys Ser Asn Phe Leu Asn Cys Tyr Val Ser
354045
Gly Phe His Pro Ser Asp Ile Glu Val Asp Leu Leu Lys Asn Gly Glu
505560
Arg Ile Glu Lys Val Glu His Ser Asp Leu Ser Phe Ser Lys Asp Trp
65707580
Ser Phe Tyr Leu Leu Tyr Tyr Thr Glu Phe Thr Pro Thr Glu Lys Asp
859095
Glu Tyr Ala Cys Arg Val Asn His Val Thr Leu Ser Gln Pro Lys Ile
100 105 110
Val Lys Trp Asp Arg Asp Met Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Ser His Ser Met
130 135 140
Arg Tyr Phe Ser Ala Ala Val Ser Arg Pro Gly Arg Gly Glu Pro Arg
145 150 155 160
Phe Ile Ala Met Gly Tyr Val Asp Asp Thr Gln Phe Val Arg Phe Asp
165 170 175
Ser Asp Ser Ala Cys Pro Arg Met Glu Pro Arg Ala Pro Trp Val Glu
180 185 190
Gln Glu Gly Pro Glu Tyr Trp Glu Glu Glu Thr Arg Asn Thr Lys Ala
195 200 205
His Ala Gln Thr Asp Arg Met Asn Leu Gln Thr Leu Arg Gly Tyr Tyr
210 215 220
Asn Gln Ser Glu Ala Ser Ser His Thr Leu Gln Trp Met Ile Gly Cys
225 230 235 240
Asp Leu Gly Ser Asp Gly Arg Leu Leu Arg Gly Tyr Glu Gln Tyr Ala
245 250 255
Tyr Asp Gly Lys Asp Tyr Leu Ala Leu Asn Glu Asp Leu Arg Ser Trp
260 265 270
Thr Ala Ala Asp Thr Ala Ala Gln Ile Ser Lys Arg Lys Cys Glu Ala
275 280 285
Ala Asn Val Ala Glu Gln Arg Arg Ala Tyr Leu Glu Gly Thr Cys Val
290 295 300
Glu Trp Leu His Arg Tyr Leu Glu Asn Gly Lys Glu Met Leu Gln Arg
305 310 315 320
Ala Asp Pro Pro Lys Thr His Val Thr His His Pro Val Phe Asp Tyr
325 330 335
Glu Ala Thr Leu Arg Cys Trp Ala Leu Gly Phe Tyr Pro Ala Glu Ile
340 345 350
Ile Leu Thr Trp Gln Arg Asp Gly Glu Asp Gln Thr Gln Asp Val Glu
355 360 365
Leu Val Glu Thr Arg Pro Ala Gly Asp Gly Thr Phe Gln Lys Trp Ala
370 375 380
Ala Val Val Val Pro Ser Gly Glu Glu Gln Arg Tyr Thr Cys His Val
385 390 395 400
Gln His Glu Gly Leu Pro Glu Pro Leu Met Leu Arg Trp Ser Lys Glu
405 410 415
Gly Asp Gly Gly Ile Met Ser Val Arg Glu Ser Arg Ser Leu Ser Glu
420 425 430
Asp Leu
<210> 9
<211> 5798
<212> DNA/RNA
<213> Artificial Sequence
<220>
<221> gene
<222> (1)..(5798)
<223> 编码B2M-HLA-G1融合蛋白的核酸序列
<400> 9
atgtctcgct ccgtggcctt agctgtgctc gcgctactct ctctttctgg cctggaggct 60
atccagcgtg agtctctcct accctcccgc tctggtcctt cctctcccgc tctgcaccct 120
ctgtggccct cgctgtgctc tctcgctccg tgacttccct tctccaagtt ctccttggtg 180
gcccgccgtg gggctagtcc agggctggat ctcggggaag cggcggggtg gcctgggagt 240
ggggaagggg gtgcgcaccc gggacgcgcg ctacttgccc ctttcggcgg ggagcagggg 300
agacctttgg cctacggcga cgggagggtc gggacaaagt ttagggcgtc gataagcgtc 360
agagcgccga ggttggggga gggtttctct tccgctcttt cgcggggcct ctggctcccc 420
cagcgcagct ggagtggggg acgggtaggc tcgtcccaaa ggcgcggcgc tgaggtttgt 480
gaacgcgtgg aggggcgctt ggggtctggg ggaggcgtcg cccgggtaag cctgtctgct 540
gcggctctgc ttcccttaga ctggagagct gtggacttcg tctaggcgcc cgctaagttc 600
gcatgtccta gcacctctgg gtctatgtgg ggccacaccg tggggaggaa acagcacgcg 660
acgtttgtag aatgcttggc tgtgatacaa agcggtttcg aataattaac ttatttgttc 720
ccatcacatg tcacttttaa aaaattataa gaactacccg ttattgacat ctttctgtgt 780
gccaaggact ttatgtgctt tgcgtcattt aattttgaaa acagttatct tccgccatag 840
ataactacta tggttatctt ctgcctctca cagatgaaga aactaaggca ccgagatttt 900
aagaaactta attacacagg ggataaatgg cagcaatcga gattgaagtc aagcctaacc 960
agggcttttg cgggagcgca tgccttttgg ctgtaattcg tgcatttttt tttaagaaaa 1020
acgcctgcct tctgcgtgag attctccaga gcaaactggg cggcatgggc cctgtggtct 1080
tttcgtacag agggcttcct ctttggctct ttgcctggtt gtttccaaga tgtactgtgc 1140
ctcttacttt cggttttgaa aacatgaggg ggttgggcgt ggtagcttac gcctgtaatc 1200
ccagcactta gggaggccga ggcgggagga tggcttgagg tccgtagttg agaccagcct 1260
ggccaacatg gtgaagcctg gtctctacaa aaaataataa caaaaattag ccgggtgtgg 1320
tggctcgtgc ctgtggtccc agctgctccg gtggctgagg cgggaggatc tcttgagctt 1380
aggcttttga gctatcatgg cgccagtgca ctccagcgtg ggcaacagag cgagaccctg 1440
tctctcaaaa aagaaaaaaa aaaaaaaaga aagagaaaag aaaagaaaga aagaagtgaa 1500
ggtttgtcag tcaggggagc tgtaaaacca ttaataaaga taatccaaga tggttaccaa 1560
gactgttgag gacgccagag atcttgagca ctttctaagt acctggcaat acactaagcg 1620
cgctcacctt ttcctctggc aaaacatgat cgaaagcaga atgttttgat catgagaaaa 1680
ttgcatttaa tttgaataca atttatttac aacataaagg ataatgtata tatcaccacc 1740
attactggta tttgctggtt atgttagatg tcattttaaa aaataacaat ctgatattta 1800
aaaaaaaatc ttattttgaa aatttccaaa gtaatacatg ccatgcatag accatttctg 1860
gaagatacca caagaaacat gtaatgatga ttgcctctga aggtctattt tcctcctctg 1920
acctgtgtgt gggttttgtt tttgttttac tgtgggcata aattaatttt tcagttaagt 1980
tttggaagct taaataactc tccaaaagtc ataaagccag taactggttg agcccaaatt 2040
caaacccagc ctgtctgata cttgtcctct tcttagaaaa gattacagtg atgctctcac 2100
aaaatcttgc cgccttccct caaacagaga gttccaggca ggatgaatct gtgctctgat 2160
ccctgaggca tttaatatgt tcttattatt agaagctcag atgcaaagag ctctcttagc 2220
ttttaatgtt atgaaaaaaa tcaggtcttc attagattcc ccaatccacc tcttgatggg 2280
gctagtagcc tttccttaat gatagggtgt ttctagagag atatatctgg tcaaggtggc 2340
ctggtactcc tccttctccc cacagcctcc cagacaagga ggagtagctg ccttttagtg 2400
atcatgtacc ctgaatataa gtgtatttaa aagaatttta tacacatata tttagtgtca 2460
atctgtatat ttagtagcac taacacttct cttcattttc aatgaaaaat atagagttta 2520
taatattttc ttcccacttc cccatggatg gtctagtcat gcctctcatt ttggaaagta 2580
ctgtttctga aacattaggc aatatattcc caacctggct agtttacagc aatcacctgt 2640
ggatgctaat taaaacgcaa atcccactgt cacatgcatt actccatttg atcataatgg 2700
aaagtatgtt ctgtcccatt tgccatagtc ctcacctatc cctgttgtat tttatcgggt 2760
ccaactcaac catttaaggt atttgccagc tcttgtatgc atttaggttt tgtttctttg 2820
ttttttagct catgaaatta ggtacaaagt cagagagggg tctggcatat aaaacctcag 2880
cagaaataaa gaggttttgt tgtttggtaa gaacatacct tgggttggtt gggcacggtg 2940
gctcgtgcct gtaatcccaa cactttggga ggccaaggca ggctgatcac ttgaagttgg 3000
gagttcaaga ccagcctggc caacatggtg aaatcccgtc tctactgaaa atacaaaaat 3060
taaccaggca tggtggtgtg tgcctgtagt cccaggaatc acttgaaccc aggaggcgga 3120
ggttgcagtg agctgagatc tcaccactgc acactgcact ccagcctggg caatggaatg 3180
agattccatc ccaaaaaata aaaaaataaa aaaataaaga acataccttg ggttgatcca 3240
cttaggaacc tcagataata acatctgcca cgtatagagc aattgctatg tcccaggcac 3300
tctactagac acttcataca gtttagaaaa tcagatgggt gtagatcaag gcaggagcag 3360
gaaccaaaaa gaaaggcata aacataagaa aaaaaatgga aggggtggaa acagagtaca 3420
ataacatgag taatttgatg ggggctatta tgaactgaga aatgaacttt gaaaagtatc 3480
ttggggccaa atcatgtaga ctcttgagtg atgtgttaag gaatgctatg agtgctgaga 3540
gggcatcaga agtccttgag agcctccaga gaaaggctct taaaaatgca gcgcaatctc 3600
cagtgacaga agatactgct agaaatctgc tagaaaaaaa acaaaaaagg catgtataga 3660
ggaattatga gggaaagata ccaagtcacg gtttattctt caaaatggag gtggcttgtt 3720
gggaaggtgg aagctcattt ggccagagtg gaaatggaat tgggagaaat cgatgaccaa 3780
atgtaaacac ttggtgcctg atatagcttg acaccaagtt agccccaagt gaaataccct 3840
ggcaatatta atgtgtcttt tcccgatatt cctcaggtac tccaaagatt caggtttact 3900
cacgtcatcc agcagagaat ggaaagtcaa atttcctgaa ttgctatgtg tctgggtttc 3960
atccatccga cattgaagtt gacttactga agaatggaga gagaattgaa aaagtggagc 4020
attcagactt gtctttcagc aaggactggt ctttctatct cttgtactac actgaattca 4080
cccccactga aaaagatgag tatgcctgcc gtgtgaacca tgtgactttg tcacagccca 4140
agatagttaa gtggggtaag tcttacattc ttttgtaagc tgctgaaagt tgtgtatgag 4200
tagtcatatc ataaagctgc tttgatataa aaaaggtcta tggccatact accctgaatg 4260
agtcccatcc catctgatat aaacaatctg catattggga ttgtcaggga atgttcttaa 4320
agatcagatt agtggcacct gctgagatac tgatgcacag catggtttct gaaccagtag 4380
tttccctgca gttgagcagg gagcagcagc agcacttgca caaatacata tacactctta 4440
acacttctta cctactggct tcctctagct tttgtggcag cttcaggtat atttagcact 4500
gaacgaacat ctcaagaagg tataggcctt tgtttgtaag tcctgctgtc ctagcatcct 4560
ataatcctgg acttctccag tactttctgg ctggattggt atctgaggct agtaggaagg 4620
gcttgttcct gctgggtagc tctaaacaat gtattcatgg gtaggaacag cagcctattc 4680
tgccagcctt atttctaacc attttagaca tttgttagta catggtattt taaaagtaaa 4740
acttaatgtc ttcctttttt ttctccactg tctttttcat agatcgagac atgggtggag 4800
gtggaagtgg tggaggtgga agtggtggag gtggaagtgg tggaggtgga agtggctccc 4860
actccatgag gtatttcagc gccgccgtgt cccggcccgg ccgcggggag ccccgcttca 4920
tcgccatggg ctacgtggac gacacgcagt tcgtgcggtt cgacagcgac tcggcgtgtc 4980
cgaggatgga gccgcgggcg ccgtgggtgg agcaggaggg gccggagtat tgggaagagg 5040
agacacggaa caccaaggcc cacgcacaga ctgacagaat gaacctgcag accctgcgcg 5100
gctactacaa ccagagcgag gccagttctc acaccctcca gtggatgatt ggctgcgacc 5160
tggggtccga cggacgcctc ctccgcgggt atgaacagta tgcctacgat ggcaaggatt 5220
acctcgccct gaacgaggac ctgcgctcct ggaccgcagc ggacactgcg gctcagatct 5280
ccaagcgcaa gtgtgaggcg gccaatgtgg ctgaacaaag gagagcctac ctggagggca 5340
cgtgcgtgga gtggctccac agatacctgg agaacgggaa ggagatgctg cagcgcgcgg 5400
acccccccaa gacacacgtg acccaccacc ctgtctttga ctatgaggcc accctgaggt 5460
gctgggccct gggcttctac cctgcggaga tcatactgac ctggcagcgg gatggggagg 5520
accagaccca ggacgtggag ctcgtggaga ccaggcctgc aggggatgga accttccaga 5580
agtgggcagc tgtggtggtg ccttctggag aggagcagag atacacgtgc catgtgcagc 5640
atgaggggct gccggagccc ctcatgctga gatggaagca gtcttccctg cccaccatcc 5700
ccatcatggg tatcgttgct ggcctggttg tccttgcagc tgtagtcact ggagctgcgg 5760
tcgctgctgt gctgtggaga aagaagagct cagattga 5798
<210> 10
<211> 1305
<212> DNA/RNA
<213> Artificial Sequence
<220>
<221> gene
<222> (1)..(1305)
<223> 编码B2M-HLA-G5融合蛋白的核酸序列
<400> 10
atgtctcgct ccgtggcctt agctgtgctc gcgctactct ctctttctgg cctggaggct 60
atccagcgta ctccaaagat tcaggtttac tcacgtcatc cagcagagaa tggaaagtca 120
aatttcctga attgctatgt gtctgggttt catccatccg acattgaagt tgacttactg 180
aagaatggag agagaattga aaaagtggag cattcagact tgtctttcag caaggactgg 240
tctttctatc tcttgtacta cactgaattc acccccactg aaaaagatga gtatgcctgc 300
cgtgtgaacc atgtgacttt gtcacagccc aagatagtta agtgggatcg agacatgggt 360
ggaggtggaa gtggtggagg tggaagtggt ggaggtggaa gtggtggagg tggaagtggc 420
tcccactcca tgaggtattt cagcgccgcc gtgtcccggc ccggccgcgg ggagccccgc 480
ttcatcgcca tgggctacgt ggacgacacg cagttcgtgc ggttcgacag cgactcggcg 540
tgtccgagga tggagccgcg ggcgccgtgg gtggagcagg aggggccgga gtattgggaa 600
gaggagacac ggaacaccaa ggcccacgca cagactgaca gaatgaacct gcagaccctg 660
cgcggctact acaaccagag cgaggccagt tctcacaccc tccagtggat gattggctgc 720
gacctggggt ccgacggacg cctcctccgc gggtatgaac agtatgccta cgatggcaag 780
gattacctcg ccctgaacga ggacctgcgc tcctggaccg cagcggacac tgcggctcag 840
atctccaagc gcaagtgtga ggcggccaat gtggctgaac aaaggagagc ctacctggag 900
ggcacgtgcg tggagtggct ccacagatac ctggagaacg ggaaggagat gctgcagcgc 960
gcggaccccc ccaagacaca cgtgacccac caccctgtct ttgactatga ggccaccctg 1020
aggtgctggg ccctgggctt ctaccctgcg gagatcatac tgacctggca gcgggatggg 1080
gaggaccaga cccaggacgt ggagctcgtg gagaccaggc ctgcagggga tggaaccttc 1140
cagaagtggg cagctgtggt ggtgccttct ggagaggagc agagatacac gtgccatgtg 1200
cagcatgagg ggctgccgga gcccctcatg ctgagatgga gtaaggaggg agatggaggc 1260
atcatgtctg ttagggaaag caggagcctc tctgaagacc tttaa 1305
<210> 11
<211> 19
<212> DNA/RNA
<213> Artificial Sequence
<220>
<221> misc_RNA
<222> (1)..(19)
<223> 靶向于CIITA位点的gRNA序列
<400> 11
gggaggctta tgccaatat 19
- 工件组装装置、工件组装装置的控制方法以及工件组装装置的控制程序及记录介质
- 一种用于转子一体化组装的扇叶组装机构
- 一种用于履轨一体化转运平台的拐点自适应装置及使用方法
- 自适应的ICI载波间干扰消除方法及装置
- 自适应的ICI载波间干扰消除方法及装置
- 叶间工况自适应一体化装置及其组装方法
- 异种金属结构间电绝缘监测装置及工况下异种金属结构间电绝缘状态监测方法