基于样本生成的小样本图像分类方法、设备及存储介质
文献发布时间:2024-04-18 19:53:47
技术领域
本发明涉及小样本图像分类技术领域,具体涉及一种基于样本生成的小样本图像分类方法。
背景技术
随着整个社会信息化的发展,数字化数据的产生速度以前所未有的速度在推进。这些数据以文本、图像、声音、视频等形式存在,以结构化或者非结构化的形式存储。大量产生的数据促进了近些年人工智能方向的繁荣发展,特别是深度学习方向。归功于大量的数据、高效的算法和高性能的硬件设备,深度学习取得了巨大的成功。然而,依赖于大数据的深度学习技术依然面临着巨大的挑战。传统的深度学习需要有大量带有标签的样本来进行训练,当有标签的样本量不足时,会造成过拟合问题,模型的性能严重下降。现实情况中,建立大规模标准数据集需要花费大量人力和物力资源,且并不是所有任务下都能获得大量有标签的样本。因而,小样本图像分类方法成为一个热点研究问题。
小样本图像分类任务中存在的主要问题在于每一类的样本数量过少而从导致无法较好的表达每一类样本的分布情况。因此,利用每一类少量有标签的支持集样本进行数据扩充,或者为无标签的查询集样本预测伪标签进行样本扩充的方法成为了解决该问题的有效方式。例如wang等(Wang Y X, Girshick R, Hebert M, et al. Low-shot learningfrom imaginary data[C]//Proceedings of the IEEE conference on computer visionand pattern recognition. 2018: 7278-7286.)作者提出了一种小样本图像分类方法,首先通过对支持集样本加入噪声生成新的样本,从而进行样本扩充,然后对包括生成器和分类器的模型进行端到端优化,同步更新生成器和分类器参数,使得生成器生成易于分类的样本;Zhang等(Zhang H, Zhang J, Koniusz P. Few-shot learning via saliency-guided hallucination of samples[C]//Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition. 2019: 2770-2779.)作者在关系网络的基础上利用显著性目标检测算法,将图像分割成前景与背景,再将不同图片的前景和背景进行组合,组成更多的合成图像,以此实现数据集的扩充;Mengye等(Mengye Ren, SachinRavi, Eleni Triantafillou, Jake Snell, Kevin Swersky, Josh B. Tenenbaum, HugoLarochelle, and Richard S. Zemel. Meta-learning for semi-supervised few-shotclassification[C]//In International Conference on Learning Representations,2018.)作者对原型网络进行了扩展。作者首先利用初始的类别原型,为每个无标记查询样本数据分配一个属于各个类别的概率,即每个查询样本以不同的概率作为各类别的扩充样本,更新各个类别的类别原型;Hariharan等(Hariharan B,Girshick,R..Low-shot visualrecognition by shrinking and hallucinating features[C]/Proceedings of theIEEE International Conference on ComputerVision,Venice,Italy,2017:3018-3027.)利用自动编码器对基类中同类别不同样本之间的差异建立模型,然后将这种差异迁移到小样本类别中,将差异跟小样本类别中的样本融合,生成更多小样本类别中的新样本,实现数据集的扩充;Li等(Li K,ZhangY,Li K,Fu Y, Adversarial feature hallucinationnetworks for few-shot learning[C]// Proceedings ofthe 33rd IEEE Conference onComputer Vision and Pattern Recognition.Piscataway,NJ,USA:IEEE Press,2020:2020:13467-13476.)提出了一种基于条件Wasserstein生成对抗网络的小样本学习算法,通过生成器与判别器互相博弈,生成符合小样本类别真实分布的新样本,扩充训练数据集;Jian(Jian Y, Torresani L. Label hallucination for few-shot classification[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(6): 7005-7014.)等人则是利用新类别(即小样本类别)上训练的线性分类器对整个基类数据集上的数据标注伪标签。对于每个新类别,都从基类数据中得到了大量伪标记样本数据。然后使用伪标签基类数据集上的蒸馏损失和新类别数据集上的标准交叉熵损失对整个模型进行微调。
然而,上述方法往往采用了直接加入噪声或者采用生成对抗网络生成样本的方法,实现对支持集进行样本的扩充,但是在小样本分类问题中,由于支持集的样本非常稀少,直接根据支持集样本进行样本生成会导致生成的样本不具有多样性,而且支持集和查询集样本中可能存在对象的不同部分,这将导致视觉特征分布差异显著,为了解决上述问题,本发明提供了一种基于样本生成的小样本图像分类方法、设备及存储介质。
发明内容
本发明提出的一种基于样本生成的小样本图像分类方法,可至少解决上述技术问题之一。
为实现上述目的,本发明采用了以下技术方案:
一种基于样本生成的小样本图像分类方法,包括利用预先构建好的图像分类模型对图像数据进行分类;所述图像分类模型构建步骤如下,
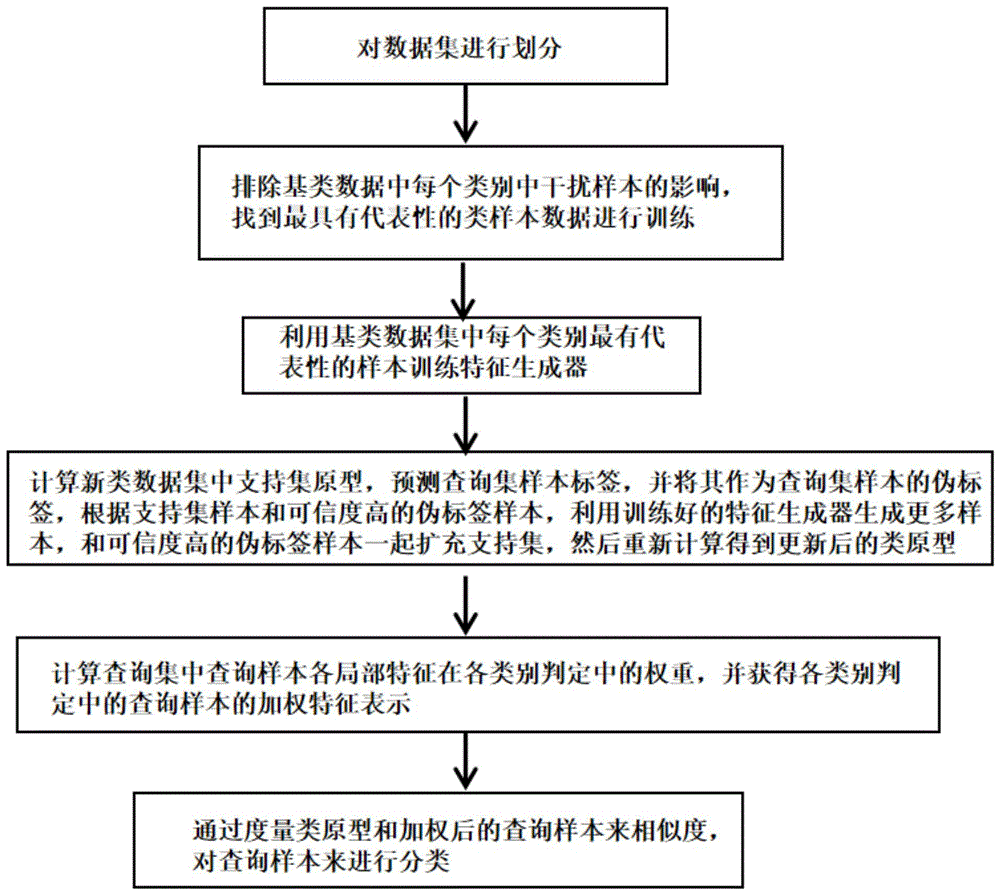
S1、对数据集划分出基类数据集和新类数据集,基类数据集包含带标记的样本,用来训练特征生成器;新类数据集用来模拟构建小样本分类任务,每个小样本任务上包括支持集和查询集;
S2、排除基类数据集中每个类别中干扰样本的影响,找到最具有代表性的样本数据;
S3、利用基类数据集中每个类别最有代表性的样本数据训练特征生成器;
S4、计算新类数据集中支持集类原型,预测查询集样本标签,并将其作为查询集样本的伪标签;根据支持集样本和可信度满足要求的伪标签,利用训练好的特征生成器生成设定数量的样本,和可信度满足要求的伪标签样本一起扩充支持集,然后重新计算得到更新后的类原型;
S5、计算查询集中的查询样本各局部特征在各类别判定中的权重,并获得各类别判定中的加权的查询样本特征;
S6、通过度量类原型和加权后的查询样本特征相似度,对查询样本来进行分类。
进一步的,所述步骤S1具体包括:
对数据集划分出需要处理的基类数据集
为了训练小样本图像分类模型,在新类数据集上构建小样本图像分类任务,每个小样本图像分类任务中包含
进一步的,所述步骤S2、排除基类数据集中每个类别中干扰样本的影响,找到最具有代表性的样本数据;具体包括,
S21、假设基类的特征遵循高斯分布,估计每个类的高斯分布的参数,计算基类
其中
S22、则第
S23、根据计算所得的高斯分布的参数,计算第
其中
S24、设置一个阈值
。
进一步的,所述S3中具体包括基于条件变分自编码器结构的特征生成器的学习训练;
条件变分自编码器结构由一个编码器
对于类
其中第一项为隐变量的后验分布
特征生成器训练的总损失函数
其中
进一步的,所述步骤S4包括用支持集样本特征初始化新类中各类别原型,然后利用各类别原型预测查询集样本的伪标签,选择可信度高的伪标签样本和支持集样本一起构成种子样本集,并利用训练好的特征生成器生成更多的样本,更新新类中各类别原型;
样本特征表示为
具体包括:
首先,对支持集
其中
然后,利用计算获得的类原型预测查询集样本
其中
之后,利用得到的伪标签查询集样本,计算伪标签样本和对应的类原型之间的可信度得分
最后,每一个类别选择置信度最高的前
然后利用训练好的特征生成器根据每个种子样本生成
进一步的,所述步骤S5、计算查询集中的查询样本各局部特征在各类别判定中的权重,并获得各类别判定中的加权的查询样本特征,具体包括,
首先将第
由于查询样本中会存在一些类别无关的干扰信息,并且同一局部特征在不同类别的判定中所发挥的重要性并不相同,所以计算了查询样本的局部特征和类原型的各局部特征之间的余弦相似性从而获得该局部特征的权重
其中
=/>
表示哈达玛积。
进一步的,所述步骤6具体包括得到计算好各类别原型
由上述技术方案可知,本发明的基于样本生成的小样本图像分类方法,能够在小样本类别支持集样本数量不足的情况下,通过计算预测查询样本的伪标签,并选择可信度高的伪标签样本和支持集样本一起构成种子样本集,利用基类数据训练好的特征生成器,为每个小样本类别生成更多的新样本,并与可信度高的伪标签样本一起构造扩充的支持集,同时更新各小样本类别的类别原型。由于支持集和查询集样本存在分布差异,因而会导致查询集样本的分类偏差,降低分类性能。为了缓解这个问题,本发明通过计算查询样本各局部特征在不同类别判定中的权重,并获得不同类别判定中的查询样本的加权特征表示。然后通过度量类别原型和查询样本在该类别上加权后的特征表示之间的距离进行分类。本发明在只有少量有标签的支持集样本的情况下,可以生成大量符合支持集样本分布的且具有多样性的新的有标签样本数据,实现小样本数据扩充,同时计算无标签查询样本的局部特征在各类别判定时的重要性,加权修正查询样本在各类别判定时的特征表示,有效缓解支持集和查询集之间的分布差异导致的分类偏差,从而提高小样本图像分类性能。
具体来说,本发明的有益效果如下:
1、由于在小样本图像分类问题中,核心问题便是可以利用的带有标签的数据样本非常的稀少,会导致模型出现过拟合的现象,从而使得网络模型对新类别样本的分类能力较差,而本发明通过通过样本生成,生成更多新类的标记样本,参与模型的训练,缓解由于训练样本不足导致的过拟合问题。
2、本发明是通过利用高可信度的伪标签样本和初始的支持集样本作为种子样本集进行样本生成,而不是直接采用大量的伪标签样本对数据集进行扩充,因为这些伪标签样本会包含一些可信度低的伪标签样本,从而不可避免的引入了噪声样本。而本发明中利用特征生成器进行样本生成则大大降低了这一问题出现的可能性。
3、在小样本图像分类任务中,支持集中的每个类别仅包含少量图像,需要根据支持集样本训练模型,然后对查询集图像进行分类。但是支持集和查询集样本存在分布差异,例如目标对象在支持集和查询集上的位置往往是不一致的,在支持集的图像中左边有着完整的一只狗,而在查询集图像可能只有右边有狗的头部,为了更加关注到查询集中关于狗的部分,本发明提出了一个有效缓解差异,通过计算查询集样本各局部特征表示在给定类别的判定中的权重,获取给定类别的加权后的查询集样本,提高对目标对象区域的关注程度,减少对其他无关区域的关注,从而提升小样本图像分类性能。
附图说明
图1是本发明实施例的流程图;
图2是本发明实施例的结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
如图1和图2所示,本实施例所述的基于样本生成的小样本图像分类方法,包括以下步骤,
S1:对数据集划分出需要处理的基类数据集
为了训练小样本图像分类模型,在新类数据集上构建小样本图像分类任务,每个小样本图像分类任务中包含
S2:本发明在基类数据集上训练出一个特征生成器,并利用训练好的特征生成器为新类生成更多的样本数据,为了更好地训练特征生成器,排除基类数据集中每个类别中干扰样本的影响,找到最具有代表性的类样本数据进行训练,具体包括,
(1)假设基类的特征遵循高斯分布,估计每个类的高斯分布的参数,计算基类
其中
(2)则第
(3)根据计算所得的高斯分布的参数,计算第
其中
(4)设置一个阈值
S3:为了生成更多的样本,本发明在包含有大量标记样本的基类上训练一个基于条件变分自编码器结构的特征生成器。条件变分自编码器结构由一个编码器
其中第一项为隐变量的后验分布
特征生成器训练的总损失函数
其中
S4:用支持集样本特征初始化新类中各类别原型,然后利用各类别原型预测查询集样本的伪标签,选择可信度高的伪标签样本和支持集样本一起构成种子样本集,并利用训练好的特征生成器生成更多的样本,更新新类中各类别原型。样本特征可以表示为
(1)对支持集
其中
(2)利用计算获得的类原型预测查询集样本
其中
(3)利用得到的伪标签查询集样本,计算伪标签样本和对应的类原型之间的可信度得分
(4)每一个类别选择置信度最高的前
。
S5:在小样本图像分类任务中,支持集中的每个类别仅包含少量图像,需要根据支持集样本训练模型,然后对查询集图像进行分类。但是支持集和查询集样本存在分布差异,导致分类偏差。为了缓解这个问题,本发明提出了通过计算查询集样本各局部特征表示在给定类别的判定中的权重,获取给定类别的加权后的查询集样本,提高对目标对象区域的关注程度,减少对其他无关区域的关注,从而提升小样本图像分类性能。具体包括,
首先将第
其中
=/>
表示哈达玛积。
7.获得计算好各类别原型
。
以下举例来说明本发明实施例的技术效果:
表1:在CIFAR-FS和CUB上的对比实验结果(%)
表1是本发明(FSL-BPSG)的实验结果和其他的主流的方法对比的结果。从表中可以看出,在CIFAR-FS和CUB两个主流数据集上,在
又一方面,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述任一方法的步骤。
再一方面,本发明还公开一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如上述任一方法的步骤。
在本申请提供的又一实施例中,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述实施例中任一方法的步骤。
可理解的是,本发明实施例提供的系统与本发明实施例提供的方法相对应,相关内容的解释、举例和有益效果可以参考上述方法中的相应部分。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 一种回缩自毁式一次性注射器
- 一种回缩式针头自毁一次性注射器