一种基于NKD-GNN的图文不匹配新闻检测方法
文献发布时间:2023-06-19 12:19:35
技术领域
本发明属于人工智能技术领域,涉及虚假信息检测,特别涉及一种基于NKD-GNN的图文不匹配新闻检测方法。
背景技术
随着互联网技术的快速发展,浏览网络新闻已经成为人们了解时事的主要渠道。有些不良媒体为了博取读者眼球,获得极高的新闻点击量,常常给新闻配很吸引人,但与新闻内容无关的配图。如果不及时处理这些图文不匹配的新闻,极易导致公众对事实产生误解,破坏网络新闻生态、损失媒体的公信力。通常,新闻文本中包括事件发生的地点类命名实体,事件涉及的人物类命名实体以及组织类命名实体,新闻配图则直观生动的展示新闻事件中关键的命名实体。新闻文本与新闻配图中命名实体是否一致,很大程度影响着新闻图文匹配性检测的结果。由于新闻文本中包含大量的命名实体,而提取图像特征算法却不能在新闻配图中直接提取出这些命名实体,造成了新闻文本与新闻配图之间存在巨大的语义差距。因此无法直接使用现有图文匹配性检测方法判断新闻文本和新闻配图的匹配性,需要生成带有命名实体的新闻配图描述。
发明内容
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于NKD-GNN的图文不匹配新闻检测方法。
为了实现上述目的,本发明采用的技术方案是:
一种基于NKD-GNN的图文不匹配新闻检测方法,包括:
步骤1,对新闻配图生成带有占位符的新闻配图描述;
步骤2,将命名实体按照连接规则构造为新闻知识图谱;
步骤3,基于新闻知识图谱驱动的图神经网络,选择与新闻配图相关的命名实体,插入到新闻配图描述中,从而生成带有命名实体的新闻配图描述;
步骤4,计算新闻文本与带有命名实体的新闻配图描述的匹配性,判断一则新闻是否图文匹配。
与现有技术相比,本发明在全面分析了新闻知识图谱中命名实体之间全部关联的基础上,还计算了新闻知识图谱中命名实体的重要程度并分析了相关新闻中核心命名实体,因此对新闻的图文匹配判断效果更好。
附图说明
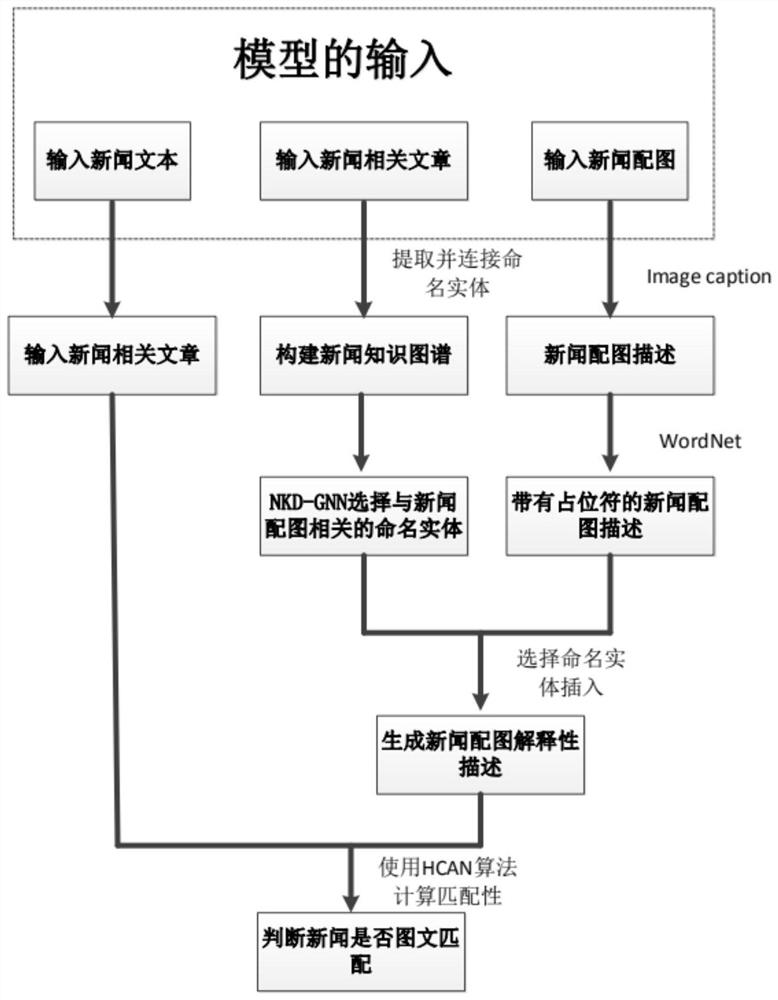
图1是本发明流程示意图。
图2是本发明实施例提供的两幅新闻配图及其检测过程、结论,两幅新闻配图各包含三篇相关文章。其中(a)为图文匹配的新闻,(b)为图文不匹配的新闻。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
如图1所示,本发明为一种基于NKD-GNN的图文不匹配新闻检测方法,步骤如下:
步骤1,对新闻配图,生成带有占位符的新闻配图描述。
新闻文本中存在大量命名实体,而现有生成图像描述的方法却不能直接生成带有命名实体的图像描述,所以新闻文本与新闻配图之间存在语义差距。直接计算二者匹配性存在一定困难。因此本发明将新闻配图生成带有占位符的新闻配图描述,将新闻文本与新闻配图统一到同一模态,并在后续的步骤中选择与新闻配图相关的命名实体插入其中。
本发明生成带有占位符的新闻配图描述的具体步骤如下:
步骤1.1:使用开源预训练好的图像生成描述模型生成新闻配图描述,该模型遵从Encoder-Decoder设计思想,在编码阶段使用CNN提取图像特征,在解码阶段使用RNN生成新闻配图描述;
步骤1.2:对于生成的新闻配图描述,采用WordNet工具,将新闻配图描述中与’Person’在同一语义树的词汇使用
步骤2,构建新闻知识图谱。
在选择命名实体插入到带有占位符的新闻配图描述中时,需要分析新闻文章中命名实体之间存在统计学上的关联,为准确反应新闻场景中命名实体之间的关联。本发明构建了新闻知识图谱,将命名实体按照连接规则构造为新闻知识图谱,为后续分析实体之间的关联奠定了基础。
本发明构造新闻知识图谱的具体步骤如下:
步骤2.1:使用SpaCy’s命名实体识别器提取新闻的相关文章的命名实体,保留Person、Organization、Location、Building四类命名实体;
步骤2.2:保留的命名实体构成实体集合V={v
其中e∈E,H
步骤3,生成带有命名实体的新闻配图描述。
在步骤2中构造的新闻知识图谱包含新闻文章中所有的命名实体,其中存在一些与新闻配图无关的命名实体。为了完全分析新闻知识图谱中实体之间的关联,并排除新闻知识图谱中噪声干扰,从而选择出与新闻配图相关的命名实体。本发明提出了新闻知识图谱驱动的图神经网络(News knowledge graph driven graph neural network,NKD-GNN),在完全分析新闻知识图谱中命名实体之间关联的基础上,选择与新闻配图相关的命名实体插入到新闻配图描述中,从而生成带有命名实体的新闻配图描述。
本发明生成带有命名实体的新闻配图描述的具体步骤如下:
步骤3.1:使用图神经网络聚合新闻知识图谱中所有边和所有节点信息,从而得到每一个节点向量v。
具体地,新闻知识图谱中节点v
其中
公式(2)反映了新闻知识图谱中节点v
步骤3.2:新闻知识图谱中边最多的节点是相关文本中的核心实体,反映着新闻配图相关新闻的关键信息。本发明将新闻知识图谱中边最多的命名实体设置为重要节点v
具体地,由于每个节点对新闻知识图谱全局向量的影响不同,具有不同的优先级,因而首先采用注意机制对每个节点向量进行加权,再求和得到新闻知识图谱的全局知识向量N
α
其中α
步骤3.3:将节点v
其中
然后使用交叉熵损失函数,并使用基于时间的反向传播算法训练NKD-GNN模型,进行核心实体预测,交叉熵损失函数如下式所示:
其中y
步骤3.4:将NKD-GNN预测的核心实体插入到带有占位符的新闻配图描述。
具体地,取每一类命名实体中概率最大的,按照实体类型插入到对应的占位符中,得到带有命名实体的新闻配图描述;当带有占位符的新闻配图的占位符没有对应插入的命名实体时,使用占位符中的类型来替换它们,例如使用词汇“PERSON”来替换插槽
步骤4,计算新闻文本与带有命名实体的新闻配图描述的匹配性。
本发明最终在弥补新闻文本与新闻配图之间语义差距的基础上,通过计算新闻文本与带有命名实体的新闻配图描述的匹配性,判断一则新闻是否图文匹配。带有命名实体的新闻配图描述与新闻文本仍然存在句式差异与结构差异。在计算二者匹配性时,不仅要分析二者的句式结构相似度,还需要计算二者关键词的相似度。为此本发明提出采用混合共同注意网络(Hybrid Co-Attention Network,HCAN)方法计算二者的匹配性,在计算时,分析二者的句式结构相似度并计算二者关键词的相似度,首先将新闻的文本划分为若干单句,如果存在一个单句与带有命名实体的新闻配图描述匹配,则认为该新闻为图文匹配的新闻。
本发明匹配性的具体计算方法如下:
步骤4.1:使用Word2vec工具生成待比较的两个句子词向量,每一个句子由若干词向量组成,两个待比较的句子向量分别为U
步骤4.2:将两个句子的每一个词向量做乘积得到一个相似矩阵
步骤4.3:对矩阵S∈R
Max(S)为所有最大池化的集合;
步骤4.4:计算U
o=soft max(O
综上,本发明的检测方法,输入是新闻配图、新闻文本以及与新闻配图相关的文章,输出是新闻文本与新闻配图的匹配性。下面通过一个具体的实施例来说明本发明方法整体执行过程。
本实施例建立在一个云计算平台上,该平台由15台服务器组成,包括Vmware Esxi5,20T磁盘阵列和1000M网络交换机,并部署了一个Hadoop的集群,提供了两幅新闻配图,如图2所示,两幅新闻配图各包含三篇相关文章。其中(a)为图文匹配的新闻,(b)为图文不匹配的新闻。(a)新闻讲述的是欧冠的体育赛事,配图中Timo Werner在踢足球,相关文章中共有8个命名实体,涉及人物、地点、组织三类实体。将这些实体构造为新闻知识图谱,(a)的新闻知识图谱中的核心命名实体为Timo Werner,经过NKD-GNN打分。Person类实体中得分最高的为Timo Werner,Place类实体中得分最高的为Cologne。因此将这两个实体插入到带有占位符的新闻配图描述中,得到该配图的解释性描述
(a)新闻文本中描述的实体与带有命名实体的新闻配图描述中实体一致,所以检测结果为匹配,检测正确。(b)新闻文本中讲述的是Norton Western University大学教授Piotr Dworczak讲述消费者行为的变化。配图是联邦警察在维护社会秩序。根据(b)新闻配图的相关文章生成的带有命名实体的新闻配图描述为Federal agent standing in theWashington behind the fire,与新闻文本完全不相关,经过计算认为此则新闻图文不匹配,检测正确。
通过这一实例,可以看出一种基于新闻知识驱动的图文不匹配新闻检测方法,通过生成带有命名实体的新闻配图描述,缩小了新闻文本与新闻配图的语义差异,从而准确计算二者的匹配性。
- 一种基于NKD-GNN的图文不匹配新闻检测方法
- 基于语义内容摘要的新闻内容图文不符鉴别系统及鉴别方法