一种点评文本标签的自动提取方案
文献发布时间:2023-06-19 10:58:46
技术领域
本申请涉及一种自动提取方案,具体是一种点评文本标签的自动提取方案。
背景技术
文本,是指书面语言的表现形式,从文学角度说,通常是具有完整、系统含义的一个句子或多个句子的组合,一个文本可以是一个句子、一个段落或者一个篇章,广义“文本”:任何由书写所固定下来的任何话语,狭义“文本”:由语言文字组成的文学实体,代指“作品”,相对于作者、世界构成一个独立、自足的系统。
业界的已知的技术方案:由运营人员手动给文本打上标签、基于规则的文本匹配和基于词频统计的tf-idf方案,不同的不足之处在于:随时海量文本的发布,工作量大,成本过高、需要不断手工添加规则,个人主观随意性较大和无法发掘文本中的词语的内在语义关系。因此,针对上述问题提出一种点评文本标签的自动提取方案。
发明内容
本申请的目的就在于为了解决上述问题而提供一种点评文本标签的自动提取方案。
本申请通过以下技术方案来实现上述目的,一种点评文本标签的自动提取方案,包括如下步骤:
步骤一、分词模块:对点评文本进行分词;
步骤二、词嵌入模型:根据海量文本训练处词语的embedding向量表示;
步骤三、情感极性模型:判断文本的情感分类,以正向、负向、中性标记;
步骤四、得出点评结果。
优选的,所述步骤一中分词将连续的字序列按照一定的规范重新组合成词序列的过程,且分词分为英文分词和中文分词。
优选的,所述中文分词技术为机械分词技术、基于统计的序列标注技术和隐式马尔科夫模型技术,优选隐式马尔科夫模型作为分词模块的主引擎。
优选的,所述隐式马尔科夫模型基本思想为根据观测值序列找到真正的隐藏状态值序列,并手工收集部分特有词语集合,使用条件随机场,进行分词后的顺序校对。
优选的,所述词嵌入模型机制如下:
(1)先是获取大量文本数据;
(2)然后我们建立一个可以沿文本滑动的窗;
(3)利用这样的滑动窗就能为训练模型生成大量样本数据。
优选的,所述步骤二中词嵌入模型把自然语言中的每一个词,表示成一个统一意义统一维度的短向量,若遇到生僻的词时,则利用Word2Vec进行词汇捕捉获取。
优选的,所述Word2Vec训练出的词嵌入有两个特点如下:
(1)体现了语义相似关系,如计算距离“red”最近的词嵌入,结果就是“white”,“black”等表示颜色的单词。
(2)体现了语义平移关系,如计算距离“woman”-“man”+“king”最近的词嵌入,结果就是“queen”。
优选的,所述步骤三中情感极性模型按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析,基于新闻评论的情感分析对舆情监控和信息预测,基于产品评论的情感分析帮助用户了解某一产品在大众心目中的口碑。
优选的,所述情感极性模型的情感极性分析方法分为基于情感词典和基于机器学习,使用基于机器学习方法,采用双向长短时神经网络作为情感分类的主引擎。
优选的,所述双向长短时神经网络包括前向LSTM与后向LSTM两个部分,两个部分在自然语言处理任务中均用来建模上下文信息,拼接向量后用于情感分类。
本申请.的有益效果是:使用了机器学习的方式,自动化提取点评文本的文本标签,在保证正确性的基础上大大减少了人工标注的工作量,同时可挖掘词语的内在语义含义,通过对分散的文本标签进行聚类,减少文本标签的类别数,增强数据的准确性,通过文本情感极性模型的引入,可以直观地对文本进行情感分类,并通过点评文本和标签文本的情感极性判断,完善点评文本和标签文本的匹配效果。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
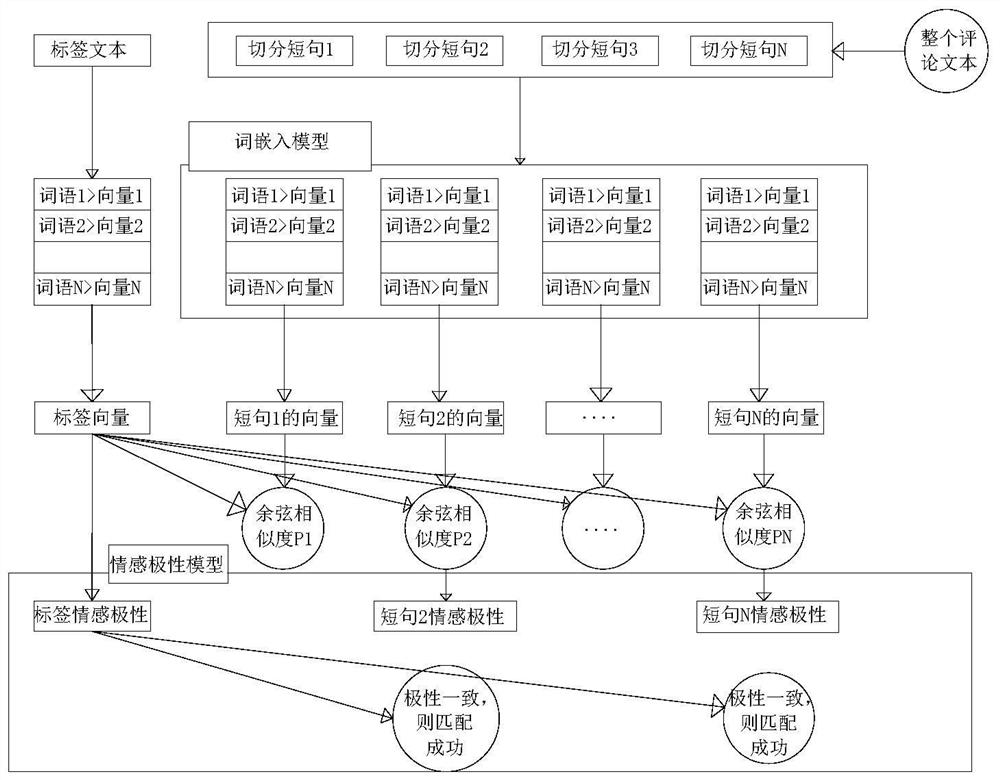
图1为本申请的设计架构示意图。
具体实施方式
下面将,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
实施例一:
如图1所示,一种点评文本标签的自动提取方案,包括如下步骤:
步骤一、分词模块:对点评文本进行分词;
步骤二、词嵌入模型:根据海量文本训练处词语的embedding向量表示;
步骤三、情感极性模型:判断文本的情感分类,以正向、负向、中性标记;
步骤四、得出点评结果。
进一步地,所述步骤一中分词将连续的字序列按照一定的规范重新组合成词序列的过程,且分词分为英文分词和中文分词。
进一步地,所述中文分词技术为机械分词技术、基于统计的序列标注技术和隐式马尔科夫模型技术,优选隐式马尔科夫模型作为分词模块的主引擎。
进一步地,所述隐式马尔科夫模型基本思想为根据观测值序列找到真正的隐藏状态值序列,并手工收集部分特有词语集合,使用条件随机场,进行分词后的顺序校对。
进一步地,所述词嵌入模型机制如下:
(1)先是获取大量文本数据;
(2)然后我们建立一个可以沿文本滑动的窗;
(3)利用这样的滑动窗就能为训练模型生成大量样本数据。
进一步地,所述步骤二中词嵌入模型把自然语言中的每一个词,表示成一个统一意义统一维度的短向量,若遇到生僻的词时,则利用Word2Vec进行词汇捕捉获取。
进一步地,所述Word2Vec训练出的词嵌入有两个特点如下:
(1)体现了语义相似关系,如计算距离“red”最近的词嵌入,结果就是“white”,“black”等表示颜色的单词。
(2)体现了语义平移关系,如计算距离“woman”-“man”+“king”最近的词嵌入,结果就是“queen”。
进一步地,所述步骤三中情感极性模型按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析,基于新闻评论的情感分析对舆情监控和信息预测,基于产品评论的情感分析帮助用户了解某一产品在大众心目中的口碑。
进一步地,所述情感极性模型的情感极性分析方法分为基于情感词典和基于机器学习,使用基于机器学习方法,采用双向长短时神经网络作为情感分类的主引擎。
进一步地,所述双向长短时神经网络包括前向LSTM与后向LSTM两个部分,两个部分在自然语言处理任务中均用来建模上下文信息,拼接向量后用于情感分类。
该点评文本标签的自动提取方案有益之处在于:使用隐式马尔科夫模型作为分词模块的主引擎,其基本思想为根据观测值序列找到真正的隐藏状态值序列,并手工收集部分特有词语集合以提升分词的准确性,此外,使用条件随机场,进行分词后的顺序校对,提升多歧义分词时的合理性。
实施例二:
如图1所示,一种点评文本标签的自动提取方案,包括如下步骤:
步骤一、分词模块:对点评文本进行分词;
步骤二、词嵌入模型:根据海量文本训练处词语的embedding向量表示;
步骤三、情感极性模型:判断文本的情感分类,以正向、负向、中性标记;
步骤四、得出点评结果。
进一步地,所述步骤一中分词将连续的字序列按照一定的规范重新组合成词序列的过程,且分词分为英文分词和中文分词。
进一步地,所述中文分词技术为机械分词技术、基于统计的序列标注技术和隐式马尔科夫模型技术,优选隐式马尔科夫模型作为分词模块的主引擎。
进一步地,所述隐式马尔科夫模型基本思想为根据观测值序列找到真正的隐藏状态值序列,并手工收集部分特有词语集合,使用条件随机场,进行分词后的顺序校对。
进一步地,所述词嵌入模型机制如下:
(1)先是获取大量文本数据;
(2)然后我们建立一个可以沿文本滑动的窗;
(3)利用这样的滑动窗就能为训练模型生成大量样本数据。
进一步地,所述步骤二中词嵌入模型把自然语言中的每一个词,表示成一个统一意义统一维度的短向量,若遇到生僻的词时,则利用Word2Vec进行词汇捕捉获取。
进一步地,所述步骤三中情感极性模型按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析,基于新闻评论的情感分析对舆情监控和信息预测,基于产品评论的情感分析帮助用户了解某一产品在大众心目中的口碑。
进一步地,所述情感极性模型的情感极性分析方法分为基于情感词典和基于机器学习,使用基于机器学习方法,采用双向长短时神经网络作为情感分类的主引擎。
进一步地,所述双向长短时神经网络包括前向LSTM与后向LSTM两个部分,两个部分在自然语言处理任务中均用来建模上下文信息,拼接向量后用于情感分类。
该点评文本标签的自动提取方案有益之处在于:使用了机器学习的方式,自动化提取点评文本的文本标签,在保证正确性的基础上大大减少了人工标注的工作量。
实施例三:
如图1所示,一种点评文本标签的自动提取方案,包括如下步骤:
步骤一、分词模块:对点评文本进行分词;
步骤二、词嵌入模型:根据海量文本训练处词语的embedding向量表示;
步骤三、情感极性模型:判断文本的情感分类,以正向、负向、中性标记;
步骤四、得出点评结果。
进一步地,所述步骤一中分词将连续的字序列按照一定的规范重新组合成词序列的过程,且分词分为英文分词和中文分词。
进一步地,所述中文分词技术为机械分词技术、基于统计的序列标注技术和隐式马尔科夫模型技术,优选隐式马尔科夫模型作为分词模块的主引擎。
进一步地,所述隐式马尔科夫模型基本思想为根据观测值序列找到真正的隐藏状态值序列,并手工收集部分特有词语集合,使用条件随机场,进行分词后的顺序校对。
进一步地,所述步骤二中词嵌入模型把自然语言中的每一个词,表示成一个统一意义统一维度的短向量,若遇到生僻的词时,则利用Word2Vec进行词汇捕捉获取。
进一步地,所述Word2Vec训练出的词嵌入有两个特点如下:
(1)体现了语义相似关系,如计算距离“red”最近的词嵌入,结果就是“white”,“black”等表示颜色的单词。
(2)体现了语义平移关系,如计算距离“woman”-“man”+“king”最近的词嵌入,结果就是“queen”。
进一步地,所述步骤三中情感极性模型按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析,基于新闻评论的情感分析对舆情监控和信息预测,基于产品评论的情感分析帮助用户了解某一产品在大众心目中的口碑。
进一步地,所述情感极性模型的情感极性分析方法分为基于情感词典和基于机器学习,使用基于机器学习方法,采用双向长短时神经网络作为情感分类的主引擎。
进一步地,所述双向长短时神经网络包括前向LSTM与后向LSTM两个部分,两个部分在自然语言处理任务中均用来建模上下文信息,拼接向量后用于情感分类。
该点评文本标签的自动提取方案有益之处在于:可挖掘词语的内在语义含义,通过对分散的文本标签进行聚类,减少文本标签的类别数,增强数据的准确性。
实施例四:
如图1所示,一种点评文本标签的自动提取方案,包括如下步骤:
步骤一、分词模块:对点评文本进行分词;
步骤二、词嵌入模型:根据海量文本训练处词语的embedding向量表示;
步骤三、情感极性模型:判断文本的情感分类,以正向、负向、中性标记;
步骤四、得出点评结果。
进一步地,所述步骤一中分词将连续的字序列按照一定的规范重新组合成词序列的过程,且分词分为英文分词和中文分词。
进一步地,所述中文分词技术为机械分词技术、基于统计的序列标注技术和隐式马尔科夫模型技术,优选隐式马尔科夫模型作为分词模块的主引擎。
进一步地,所述隐式马尔科夫模型基本思想为根据观测值序列找到真正的隐藏状态值序列,并手工收集部分特有词语集合,使用条件随机场,进行分词后的顺序校对。
进一步地,所述步骤三中情感极性模型按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析,基于新闻评论的情感分析对舆情监控和信息预测,基于产品评论的情感分析帮助用户了解某一产品在大众心目中的口碑。
进一步地,所述情感极性模型的情感极性分析方法分为基于情感词典和基于机器学习,使用基于机器学习方法,采用双向长短时神经网络作为情感分类的主引擎。
进一步地,所述双向长短时神经网络包括前向LSTM与后向LSTM两个部分,两个部分在自然语言处理任务中均用来建模上下文信息,拼接向量后用于情感分类。
该点评文本标签的自动提取方案有益之处在于:通过文本情感极性模型的引入,可以直观地对文本进行情感分类,并通过点评文本和标签文本的情感极性判断,完善点评文本和标签文本的匹配效果。
对于本领域技术人员而言,显然本申请不限于上述示范性实施例的细节,而且在不背离本申请的精神或基本特征的情况下,能够以其他的具体形式实现本申请。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本申请的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本申请内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 一种点评文本标签的自动提取方案
- 一种基于监督主题模型的文本标签推荐方法