一种文本标签的确定方法和相关装置
文献发布时间:2024-01-17 01:13:28
技术领域
本申请涉及数据处理领域,特别是涉及一种文本标签的确定方法和相关装置。
背景技术
随着互联网的快速发展,移动社交的媒体时代应运而生。在媒体平台中存在大量不同用户发布的多媒体内容,对媒体平台而言,实时而精准的多媒体内容推送可以为用户带来更好的观看体验,也能提高用户的观看次数、忠诚度等。
多媒体内容的文本标签是媒体平台向用户进行精准推荐的重要依据。目前主要通过标准化人工标记的方式为多媒体内容设置对应的文本标签。
然而,这种方式导致文本标签覆盖不全面,进而影响推荐侧的使用体验。并且媒体平台中存在大量的多媒体内容,人工专门标记此类文本标签需要耗费大量的人力和时间,成本非常高,效率也非常低。
发明内容
为了解决上述技术问题,本申请提供了一种文本标签的确定方法,处理设备可以基于多媒体内容自身的文本信息和发布该内容的账号对应的账号信息这两个维度,对多媒体内容所对应的文本标签进行自动生成,在保障文本标签准确度的情况下提高了标签确定的效率。
本申请实施例公开了如下技术方案:
第一方面,本申请实施例公开了一种文本标签的确定方法,所述方法包括:
获取待处理多媒体内容的目标关键文本信息;
获取目标媒体账号的目标账号描述信息,所述目标媒体账号为发布所述待处理多媒体内容的媒体账号;
确定每个候选文本标签的标签向量、确定所述目标账号描述信息的账号特征向量,以及根据所述目标关键文本信息确定所述待处理多媒体内容的内容特征向量;
将所述账号特征向量和所述内容特征向量进行融合,得到融合特征向量;
根据所述融合特征向量和所述每个候选文本标签的标签向量之间的匹配度,确定所述待处理多媒体内容的目标文本标签。
第二方面,本申请实施例公开了一种文本标签的确定装置,所述装置包括第一获取单元、第二获取单元、第一确定单元、融合单元和第二确定单元:
所述第一获取单元,用于获取待处理多媒体内容的目标关键文本信息;
所述第二获取单元,用于获取目标媒体账号的目标账号描述信息,所述目标媒体账号为发布所述待处理多媒体内容的媒体账号;
所述第一确定单元,用于确定每个候选文本标签的标签向量、确定所述目标账号描述信息的账号特征向量,以及根据所述目标关键文本信息确定所述待处理多媒体内容的内容特征向量;
所述融合单元,用于将所述账号特征向量和所述内容特征向量进行融合,得到融合特征向量;
所述第二确定单元,用于根据所述融合特征向量和所述每个候选文本标签的标签向量之间的匹配度,确定所述待处理多媒体内容的目标文本标签。
在一种可能的实现方式中,所述第一确定单元具体用于:
通过标签预测模型中的标签提取子模型,确定所述每个候选文本标签的标签向量;
通过所述标签预测模型中的账号提取子模型,确定所述目标账号描述信息的账号特征向量;
通过所述标签预测模型中的内容提取子模型,根据所述目标关键文本信息确定所述内容特征向量。
在一种可能的实现方式中,所述融合单元具体用于:
通过所述标签预测模型中的特征融合子模型将所述账号特征向量和所述内容特征向量进行融合,得到所述融合特征向量;
所述第二确定单元具体用于:
通过所述标签预测模型中的匹配子模型,根据所述融合特征向量和所述每个候选文本标签的标签向量之间的匹配度,确定所述目标文本标签。
在一种可能的实现方式中,所述标签预测模型为双塔模型,所述标签提取子模型为所述双塔模型的第一模型分支;所述账号提取子模型、所述内容提取子模型和所述特征融合子模型构成所述双塔模型的第二模型分支。
在一种可能的实现方式中,所述装置还包括样本构建单元和训练单元:
所述样本构建单元,用于根据历史多媒体内容的历史关键文本信息和所述历史多媒体内容对应的历史账号描述信息构建训练样本,所述历史多媒体内容具有样本文本标签;
所述训练单元,用于根据所述训练样本对所述标签预测模型进行训练;
在训练过程中,通过所述标签提取子模型,确定每个所述候选文本标签的历史标签向量;通过所述账号提取子模型,确定所述历史账号描述信息的历史账号特征向量;通过所述内容提取子模型,根据所述历史关键文本信息确定所述历史多媒体内容的历史内容特征向量;通过所述特征融合子模型将所述历史账号特征向量和所述历史内容特征向量进行融合,得到历史融合特征向量;并通过所述匹配子模型,根据所述历史融合特征向量和每个所述历史标签向量之间的匹配度,确定历史文本标签;若所述历史文本标签与所述样本文本标签不一致,调整所述标签预测模型的模型参数。
在一种可能的实现方式中,所述装置还包括第三获取单元、聚类单元和第三确定单元:
所述第三获取单元,用于获取多个媒体账号分别发布的多媒体内容;
所述聚类单元,用于对所述多个媒体账号分别发布的多媒体内容进行聚类,得到多个聚类簇;
所述第三确定单元,用于根据所述多个聚类簇对应的多媒体内容,确定所述候选文本标签。
在一种可能的实现方式中,所述聚类单元具体用于:
确定不同媒体账号发布的多媒体内容之间的相似度;
将所发布多媒体内容之间的相似度满足第一预设阈值的媒体账号划分至同一个聚类簇,得到所述多个聚类簇,所述多个聚类簇为账号簇。
在一种可能的实现方式中,所述第二确定单元具体用于:
将所述每个候选文本标签按照对应的标签向量与所述融合特征向量之间的匹配度从高到低的顺序排列;
将排列在前N位的候选文本标签确定为所述目标文本标签,N为大于或者等于1的整数。
在一种可能的实现方式中,所述装置还包括第四确定单元:
所述第四确定单元,用于若所述目标媒体账号与已预测多媒体内容对应媒体账号相同,将所述已预测多媒体内容的文本标签确定为所述目标文本标签;
或者,若所述目标关键文本信息与所述已预测多媒体内容的关键文本信息之间的相似度达到第二预设阈值,将所述已预测多媒体内容的文本标签确定为所述目标文本标签;
或者,若所述目标账号描述信息与所述已预测多媒体内容对应的账号描述信息之间的相似度达到第三预设阈值,将所述已预测多媒体内容的文本标签确定为所述目标文本标签。
在一种可能的实现方式中,所述目标关键文本信息包括所述待处理多媒体内容的标题信息、所述待处理多媒体内容的内容文字识别信息和所述待处理多媒体内容的语音识别结果信息中一种或多种的组合。
在一种可能的实现方式中,所述装置还包括第五确定单元和执行单元:
所述第五确定单元,用于确定所述待处理多媒体内容的标题信息是否符合预设标题规则;
所述执行单元,用于若所述待处理多媒体内容的标题信息符合预设标题规则,执行确定每个候选文本标签的标签向量、确定所述目标账号描述信息的账号特征向量,以及根据所述目标关键文本信息确定所述待处理多媒体内容的内容特征向量的步骤。
第三方面,本申请实施例公开了一种计算机设备,所述设备包括处理器以及存储器:
所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
所述处理器用于根据所述程序代码中的指令执行第一方面中所述的文本标签的确定方法。
第四方面,本申请实施例公开了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行第一方面中所述的文本标签的确定方法。
第五方面,本申请实施例公开了一种包括指令的计算机程序产品,当其在计算机上运行时,使得所述计算机执行第一方面中所述的文本标签的确定方法。
由上述技术方案可以看出,为了在保障标签准确度的前提下提高标记文本标签的效率,可以从待处理多媒体内容自身对应的目标关键文本信息和发布多媒体内容账号的目标账号描述信息这两个维度出发,对该待处理多媒体内容的标签进行综合确定。通过基于上述内容生成的账号特征向量和内容特征向量,以及每一个候选文本标签所对应的标签向量,可以基于向量之间的匹配程度来从多个候选文本标签中选出与该待处理多媒体内容匹配的目标文本标签。由于发布多媒体内容的媒体账号通常会在昵称或账号简介等账号描述信息中添加一些能够吸引用户浏览自己内容的信息,而吸引用户的重点就在于能够引起观众的情感共鸣,因此,该账号描述信息有较大概率可以体现出该账号所发布多媒体内容的情感类型。从而,通过结合该账号描述信息来确定文本标签,在一定程度上可以提高所确定出的文本标签与待处理多媒体内容之间的匹配程度,使该多媒体内容在基于标签向用户推送时更容易引起用户的情感共鸣。此外,由于该标签确定过程无需人工进行标注,因此能够在保障标签准确度的前提下提高标签标注的效率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种实际应用场景中文本标签的确定方法的示意图;
图2为本申请实施例提供的一种文本标签的确定方法的流程图;
图3为本申请实施例提供的一种双塔模型的示意图;
图4为本申请实施例提供的一种匹配层的示意图;
图5为本申请实施例提供的一种确定视频向量的示意图;
图6为本申请实施例提供的一种聚类方法的示意图;
图7为本申请实施例提供的一种具有文本标签预测功能的多媒体系统架构的示意图;
图8为本申请实施例提供的一种文本标签的确定装置的结构框图;
图9为本申请实施例提供的一种计算机设备的结构图;
图10为本申请实施例提供的一种服务器的结构图;
图11为本申请实施例提供的一种实际应用场景的示意图。
具体实施方式
下面结合附图,对本申请的实施例进行描述。
在当下的媒体时代,越来越多的用户成为了多媒体内容的制作者和发布者,例如依靠一些短视频软件来制作并发布短视频吸引其他用户进行观看。其中,为了使用户有良好的多媒体内容浏览体验,需要根据用户的喜好向用户推荐其容易感兴趣的多媒体内容。
在相关技术中,为了能够进行有效的内容推荐,相关人员需要人工分析各个多媒体内容所表达的情感内容,并人工添加该多媒体内容对应的文本标签,从而可以基于该文本标签向容易引起情感共鸣的用户推送相应的多媒体内容,使用户在浏览多媒体内容时能够有良好的情感体验。例如,当用户比较喜欢看亲情类的视频时,短视频软件可以将具有“母爱”、“父爱”等文本标签的短视频推荐给用户。
然而,由于多媒体内容数量众多、种类繁杂,只依靠人工去标记文本标签会耗费大量的人力和时间。在相关技术中,为了提高标记文本标签的效率,可以依靠设备对多媒体内容中的文本或图像进行分析,从而学习到如何自动添加相应的文本标签。但是,这种标记标签的方式所打出的文本标签通常只能够反应出该多媒体内容所包含的内容详情,难以从情感维度对多媒体内容进行概括,从而基于该文本标签所推荐的多媒体内容难以引起用户的情感共鸣,内容浏览体验较差。例如,针对一个内容为“鳄鱼妈妈给幼崽喂食”的视频,通过相关技术中的标签确定方法只能够确定出“鳄鱼”、“幼崽”等反映内容本质的标签,而无法确定出“母爱伟大”、“妈妈不容易”等能够引起用户情感共鸣、满足用户情感需求的标签。实际上这些标签才是向用户推荐优质内容的关键所在。
为了解决上述技术问题,本申请提供了一种文本标签的确定方法,处理设备可以基于多媒体内容自身的文本信息和发布该内容的账号对应的账号信息这两个维度,对多媒体内容所对应的文本标签进行自动生成,通过结合能够凸显所发布多媒体内容对应情感的账号描述信息,可以在保障文本标签准确度的情况下提高了标签确定的效率,同时使确定出的情感更容易引起用户的情感共鸣,改善用户的多媒体浏览体验。
可以理解的是,该方法可以应用于处理设备上,该处理设备为能够进行文本标签确定的处理设备,例如可以为具有文本标签确定功能的终端设备或服务器。该方法可以通过终端设备或服务器独立执行,也可以应用于终端设备和服务器通信的网络场景,通过终端设备和服务器配合执行。其中,终端设备可以为计算机、手机等设备。服务器可以理解为是应用服务器,也可以为Web服务器,在实际部署时,该服务器可以为独立服务器,也可以为集群服务器。
此外,本申请还涉及人工智能(Artificial Intelligence,AI)技术,人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习、自动驾驶、智慧交通等几大方向。本申请主要涉及其中计算机视觉技术、语音技术和机器学习技术。
计算机视觉技术(Computer Vision,CV)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取信息的人工智能系统。计算机视觉技术通常包括图像处理、图像识别、图像语义理解、图像检索、OCR、视频处理、视频语义理解、视频内容/行为识别、三维物体重建、3D技术、虚拟现实、增强现实、同步定位与地图构建、自动驾驶、智慧交通等技术,还包括常见的人脸识别、指纹识别等生物特征识别技术。
语音技术(Speech Technology)的关键技术有自动语音识别技术(ASR)和语音合成技术(TTS)以及声纹识别技术。让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音成为未来最被看好的人机交互方式之一。
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。
在本申请实施例中,可以通过语音技术对多媒体内容中的音频信息进行语音识别,确定出对应的文本信息;以及,可以通过计算机视觉技术识别视频类多媒体内容的视频图像中所包含的字幕信息;此外,处理设备还可以通过机器学习技术训练标签提取模型,使该标签提取模型能够精准的确定出待处理多媒体内容与多个候选文本标签之间的匹配程度。
为了便于理解本申请实施例提供的技术方案,接下来将结合一种实际应用场景,对本申请实施例提供的一种文本标签的确定方法进行介绍。
参见图1,图1为本申请实施例提供的一种实际应用场景中文本标签的确定方法的示意图,在该实际应用场景中,处理设备为具有标记文本标签功能的服务器101,待处理多媒体内容可以为待处理视频。
服务器101可以从该待处理视频自身对应的目标关键文本信息,和发布该待处理视频的媒体账号所对应的目标账号描述信息这两个信息维度出发,对该待处理视频对应的文本标签进行精确标记。如图1所示,该目标关键文本信息可以包括该待处理视频的标题信息,该目标账号描述信息可以为该媒体账号的账号昵称、账号简介等。其中,标题信息通常情况下可以精确概括出该待处理视频所要讲述的内容,同时,为了吸引更多的用户来观看自己发布的视频,视频发布者在自己媒体账号的账号描述信息中通常会添加一些与发布内容相关的、容易吸引用户观看的信息,而吸引用户观看的关键在于能够引起用户的情感共鸣,因此,在账号昵称、账号简介中有较大概率会包含一些贴合所发布视频内容,且能够引起用户情感共鸣的信息。
基于此,服务器101可以根据目标关键文本信息和目标账号描述信息分别确定出对应的内容特征向量和账号特征向量,以及可以根据多个候选文本标签确定出对应标签向量。在该实际应用场景中,候选文本标签包括“亲情”、“友情”和“爱情”。服务器101可以将内容特征向量和账号特征向量进行融合,得到能够从待处理视频内容本身以及发布视频的账号这两个信息维度体现该待处理视频情感内容的融合特征向量。基于该融合特征向量与各个标签向量之间的匹配度,服务器101可以从多个候选文本标签中确定出与该待处理视频匹配的文本标签。例如,由图1可见,在目标关键文本信息中包括“爸爸妈妈”等与“亲情”有关的关键词,在目标账号描述信息中包括“相亲相爱一家人”、“一家人”等相关信息,因此通过该方法可以较为准确的确定出“亲情”为该待处理视频对应的文本标签。
由于该目标关键文本信息能够对该待处理的视频内容进行准确表达,该目标账号描述信息能够生动体现出该待处理视频所体现的情感共鸣,因此结合两者所确定出的文本标签既能够贴合待处理视频的实际内容,又能够准确反映该待处理视频想要表达的情感,在节省人力的同时提高了标签确定的准确度。
接下来,将结合附图,对本申请实施例提供的一种文本标签的确定方法进行介绍。
参见图2,图2为本申请实施例提供的一种文本标签的确定方法的流程图,该方法包括:
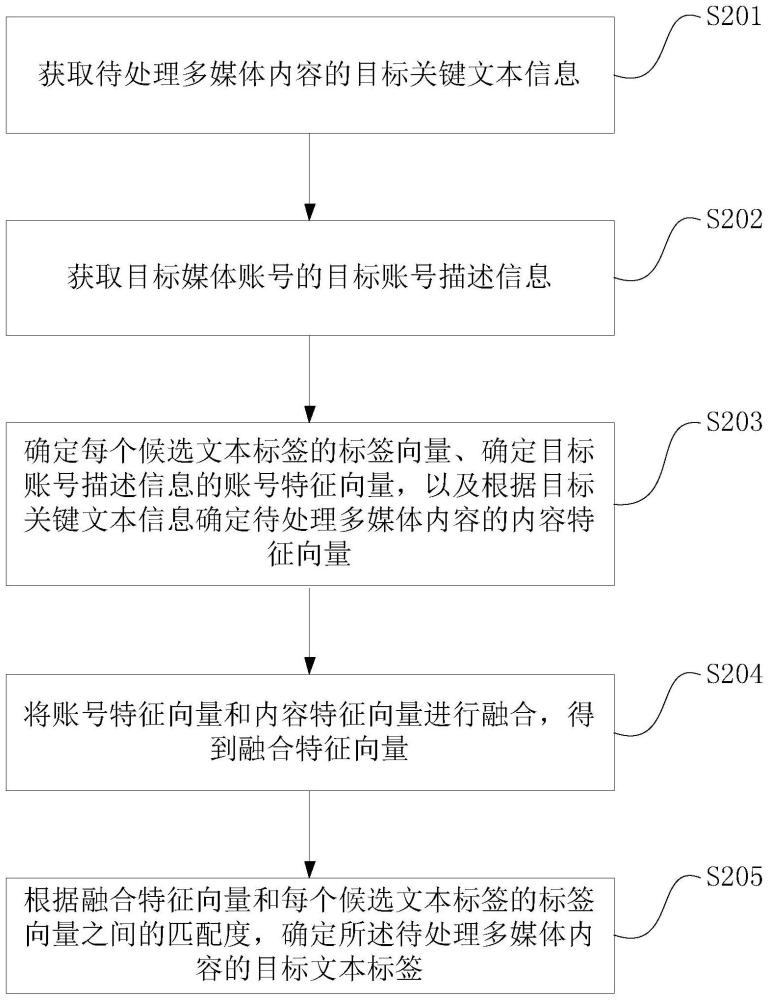
S201:获取待处理多媒体内容的目标关键文本信息。
在为多媒体内容添加相应的文本标签时,在理想情况下,该文本标签应当既能够体现出该多媒体内容所包含的具体信息,也能够反映出该多媒体内容想要带观众引起的情感共鸣,从而才能够根据该文本标签向用户推送其浏览意向较高、贴合用户多媒体浏览需求的多媒体内容。其中,多媒体内容的形式在本申请实施例中可以包括多种,例如可以为文章、图片、视频等。
基于此,在本申请实施例中,处理设备可以从能够体现多媒体内容自身信息和能够体现多媒体内容情感表达这两个维度出发,来确定该多媒体内容对应的文本标签,该文本标签为用于体现多媒体内容情感表达的标签,其标签的表达形式可以包含多种,既可以是一些表达情感的词汇,例如“母爱”、“父爱”、“兄弟情”等;也可以是一些非情感表达,但是能够引起用户情感共鸣的词汇,例如“解放军战士帮助老百姓”、“知名男星离婚”等,这里不做限制。
可以理解的是,想要对多媒体内容所表达情感的准确理解,需要处理设备能够对多媒体内容所表达内容信息进行准确理解。因此,处理设备可以获取待处理多媒体内容对应的目标关键文本信息,该待处理多媒体内容是指需要进行文本标签标记的多媒体内容,该目标关键文本信息是指该待处理多媒体内容中所具有的文本信息,该目标关键文本信息能够较为显著的表现出该待处理多媒体内容所对应的内容信息。例如,在一种可能的实现方式中,该目标关键文本信息可以包括待处理多媒体内容的标题信息、待处理多媒体内容的内容文字识别信息和待处理多媒体内容的语音识别结果信息中一种或多种的组合。
其中,该内容文字识别信息是指从该待处理多媒体内容中的文字识别出的文本信息,例如当待处理多媒体内容为文章时,该内容文字识别信息可以为其中的一些关键句段;当待处理多媒体内容为视频时,该内容文字识别信息可以为从视频画面中识别出的字幕信息等。该语音识别结果信息是指通过识别该待处理多媒体内容的音频信息得到的文本信息,例如识别视频中的人物所说的话等。这些信息都能够在一定程度上体现出该待处理多媒体内容所想要表达的内容信息。
S202:获取目标媒体账号的目标账号描述信息。
可以理解的是,在媒体场景下,通常一个媒体账号所发布的多媒体内容都具有较为相似的情感类型,例如亲情类媒体账号所发布的内容通常为与家人的日常生活,友情类媒体账号所发布的内容通常为与朋友的生活经历等。该媒体账号的类型可以包括多种,例如可以包括社会化媒体账号、新媒体账号和自媒体账号等,其中自媒体账号和新媒体账号属于社会化媒体账号中的一种,自媒体具有平民化、自传播性和电子化的特点,例如自媒体账号可以为各类视频软件、微博软件上的账号等,通常为一些用户自己的账号;新媒体在自媒体的基础上还包括其他数字化的媒体,例如网络新闻等;社会化媒体在新媒体和自媒体的基础上还包括传统媒体,例如广播媒体等。
为了能够吸引更多的用户来浏览自己所发布的多媒体内容,同时能够让接触到自己账号的用户能够快速了解并对自己发布的多媒体内容产生兴趣,在,发布多媒体内容的用户通常会在自己的媒体账号相关信息中添加一些能够快速介绍所发布内容,以及能够快速引起浏览者情感共鸣的信息。例如,在图1所示的实际应用场景中,为了吸引用户来观看自己拍的亲情类视频,发布者在账号昵称中添加了“相亲相爱一家人”这种体现亲情、家人的词语,在账号简介中也明确说明了自己拍的是“一家人的日常生活”,这些信息都能够体现出该账号所发布的视频有较大概率对应“亲情”、“家人”等文本标签,从而能够有效的吸引对这类文本标签的多媒体内容有浏览需求的用户。
由此可见,用于描述媒体账号的账号描述信息在一定程度上能够体现出该媒体账号所发布多媒体内容的情感类型。基于此,在本申请实施例中,处理设备还可以获取目标媒体账号的目标账号描述信息,该目标媒体账号为发布待处理多媒体内容的媒体账号,该目标账号描述信息例如可以为账号昵称、账号简介等。处理设备可以综合该目标账号描述信息和该目标关键文本信息对待处理多媒体内容的文本标签进行确定,从而能够兼顾体现该待处理多媒体内容的内容信息以及准确反映该待处理多媒体内容的情感表达。
S203:确定每个候选文本标签的标签向量、确定目标账号描述信息的账号特征向量,以及根据目标关键文本信息确定待处理多媒体内容的内容特征向量。
为了能够解决因为人工标记所带来的文本标签确定效率低的问题,处理设备需要将获取到的信息转换为自身能够进行理解和处理的格式。在本申请实施例中,处理设备可以将获取到的信息转换为向量,例如将目标账号描述信息转换为账号特征向量,将目标关键文本信息转换为内容特征向量,这些向量可以更加突出的体现出这些信息所包含的内容信息和情感表达特点。
同时,为了能够确定出该待处理多媒体内容对应的文本标签,处理设备可以预先获取多个候选文本标签,这些候选文本标签可以为从历史多媒体内容中总结出的文本标签等。同样,处理设备可以确定每个候选文本标签对应的标签向量,该标签向量能够体现出所对应候选文本标签的情感表达特点。
S204:将账号特征向量和内容特征向量进行融合,得到融合特征向量。
上已述及,通过内容特征向量,能够在体现待处理多媒体内容所表达的内容信息的同时,从内容信息的层面反映出一定的情感表达;通过账号特征向量,能够反映出该媒体账号所发布多媒体内容的情感类型。因此,处理设备可以将该账号特征向量和内容特征向量进行融合,得到融合特征向量,该融合特征向量即能够从多媒体内容的内容信息层面和媒体账号发布内容的情感类型层面,综合体现出该待处理多媒体内容的情感表达。
S205:根据融合特征向量和每个候选文本标签的标签向量之间的匹配度,确定所述待处理多媒体内容的目标文本标签。
可以理解的是,由于融合特征向量能够准确的体现出该待处理多媒体内容的情感表达,该标签向量能够体现出所对应候选文本标签的情感表达特点,因此,通过融合特征向量和各个标签向量之间的匹配度,能够反映出待处理多媒体内容与各个候选文本标签在情感表达上的相似度,从而能够从多个候选文本标签中确定出能够准确体现该待处理多媒体内容情感表达的目标文本标签。
其中,文本标签可以有多种类型,例如,在一种可能的实现方式中,该目标文本标签可以包括目标情感标签,该目标情感标签可以用于体现待处理多媒体内容的情感表达,相较于普通的文本标签来说,情感标签可以更容易引起用户的情感共鸣,例如情感标签可以为“感人至深的母子情”、“分隔多年情侣相见”等。
可以理解的是,处理设备既可以为每一个待处理多媒体内容确定唯一的文本标签,以向用户进行最精准的内容推荐;也可以为待处理多媒体内容确定多个贴合其情感表达的文本标签,从而能够向用户进行多元化的内容推荐。
例如,在一种可能的实现方式中,处理设备可以将每个候选文本标签按照对应的标签向量与融合特征向量之间的匹配度从高到底的顺序排列,匹配度越高,则说明该候选文本标签越贴合该待处理多媒体内容的情感表达。处理设备可以将排列在前N位的候选文本标签确定为目标文本标签,N为大于或者等于1的整数,其中N的的取值可以根据上述需求等灵活调整,此处不作限定。
由上述技术方案可以看出,为了在保障标签准确度的前提下提高标记文本标签的效率,可以从待处理多媒体内容自身对应的目标关键文本信息和发布多媒体内容账号的目标账号描述信息这两个维度出发,对该待处理多媒体内容的标签进行综合确定。通过基于上述内容生成的账号特征向量和内容特征向量,以及每一个候选文本标签所对应的标签向量,可以基于向量之间的匹配程度来从多个候选文本标签中选出与该待处理多媒体内容匹配的目标文本标签。由于发布多媒体内容的媒体账号通常会在昵称或账号简介等账号描述信息中添加一些能够吸引用户浏览自己内容的信息,而吸引用户的重点就在于能够引起观众的情感共鸣,因此,该账号描述信息有较大概率可以体现出该账号所发布多媒体内容的情感类型。从而,通过结合该账号描述信息来确定文本标签,在一定程度上可以提高所确定出的文本标签与待处理多媒体内容之间的匹配程度,使该多媒体内容在基于标签向用户推送时更容易引起用户的情感共鸣。此外,由于该标签确定过程无需人工进行标注,因此能够在保障标签准确度的前提下提高标签标注的效率。
其中,为了保障所确定出的向量能够体现原信息中的关键内容,在一种可能的实现方式中,处理设备可以通过标签预测模型来进行向量提取和向量匹配,该标签预测模型用于为多媒体内容标记对应的文本标签。在本申请实施例中,该标签预测模型包括标签提取子模型、账号提取子模型、内容提取子模型、特征融合子模型和匹配子模型,下面将对各个子模型的作用进行介绍。
处理设备可以通过标签预测模型中的标签提取子模型,确定每个候选文本标签的标签向量;通过标签预测模型中的账号提取子模型,确定目标账号描述信息的账号特征向量;通过标签预测模型中的内容提取子模型,根据所述目标关键文本信息确定所述内容特征向量。以及,处理设备可以通过标签预测模型中的特征融合子模型将账号特征向量和内容特征向量进行融合,得到融合特征向量,然后通过标签预测模型中的匹配子模型,根据融合特征向量和每个候选文本标签的标签向量之间的匹配度,确定所述目标文本标签。
该标签预测模型从实现功能的角度出发,可以有多种模型结构,例如可以为双塔模型、神经网络模型等。其中,由于对融合特征向量的确定、对标签向量的确定以及对向量匹配度的确定都会影响到最终文本标签标记的准确度,因此,在一种可能的实现方式中,处理设备可以选择能够较为精准的进行上述过程的双塔模型作为标签预测模型。
可以理解的是,双塔模型通常由两个模型分支和最终的匹配层构成,两个模型分支用于对需要匹配的信息进行预处理,匹配层用于确定通过两个分支确定出的信息之间的匹配程度。双塔模型具有整体性的特点,即在该模型的训练过程中,每一个模型分支的信息处理过程都可以基于最终模型匹配层的匹配结果来进行相应的调节,从而使各个模型分支都能够确定出有利于最终信息匹配的处理信息。在本申请实施例中,该标签提取子模型为双塔模型的第一模型分支,该账号提取子模型、内容提取子模型和特征融合子模型构成该双塔模型的第二模型分支。从而,通过该双塔模型所确定出的标签向量、内容特征向量、账号特征向量和融合特征向量都可以有助于模型准确确定融合特征向量与各个标签向量之间的匹配度,从而更为准确的从多个候选文本标签中确定出与该待处理多媒体内容匹配的文本标签。
可以理解的是,出于快速吸引用户浏览自己发布的多媒体内容等原因,部分多媒体内容可能会具有一些与自身内容关联程度不高,或过度修辞等不恰当的标题信息,这些标题信息可能存在一些对文本标签确定帮助效果较差、甚至误导处理设备进行文本标签标记的内容。例如,有些标题信息中可能具有“全世界都不知道”、“所有男人都”这类与多媒体内容具体的内容信息无关,也无法反应出多媒体内容情感表达的夸张修辞词语。
基于此,在一种可能的实现方式中,为了提高文本标签确定的准确度,处理设备可以预先设定一套用于对标题信息进行过滤的预设标题规则,该预设标题规则用于过滤掉对文本标签确定无法起到帮助的标题信息。若目标关键文本信息包括待处理多媒体内容的标题信息,处理设备在获取待处理多媒体内容的目标关键文本信息之后,可以先确定该待处理多媒体内容的标题信息是否符合该预设标题规则,若该待处理多媒体内容的标题信息符合该预设标题规则,则说明该标题信息有助于处理设备进行文本标签的确定,此时处理设备可以执行确定每个候选文本标签的标签向量、确定目标账号描述信息的账号特征向量,以及根据目标关键文本信息确定待处理多媒体内容的内容特征向量的步骤。若不符合,则说明该标题信息对文本标签的确定缺乏有益效果,甚至可能会干扰处理设备确定文本标签。此时,处理设备可以通过其他目标关键文本信息,如内容文字识别信息或语音识别结果信息等来确定文本标签。
例如,该预设标题规则可以如下所示,符合下述内容的标题信息可以视为不符合预设标题规则:
一、“标题党”标题信息
(一)标题夸张
1、夸张式标题:主要规则是标题将感受、范围、结果、程度等夸张夸大描述,造成耸人听闻的效果,如:
标题使用「震惊」、「惊爆」、「传疯」、「吓掉半条命」等,言过其实地表达情绪/状态/感受;
标题使用「全世界网友」、「所有男人都」、「某国人」、「99%」等,进行无依据的范围夸大;
标题使用「XX天见效」、「根治」、「立竿见影」等,对效果或结果做不符合常识的断言或保证;
标题使用「重磅」、「要命」、「就在刚刚」等,对事件的严重和紧急程度夸张形容,引起过度警觉和关注;
标题使用「世界之最」、「最高级」、「最佳」、「最烂」等,形容人事物在某些程度上达到极致,但违背事实和大众认知;
标题使用敏感,有诱导诱惑的词语。
2、悬念式标题:主要规则是标题滥用转折、隐藏关键性信息,营造悬念、故弄玄虚:
标题故意使用「竟然」、「竟是这样」、「结果却」、「没想到」等强转折词语,制造危机感和想象空间;
标题成分残缺,或隐藏关键信息,营造玄虚,如「竟然是……」、「而是……」、「不过……」等话说一半,通过省略号代替关键信息,或使用「内幕」、「揭秘」、「真相」等代替关键信息;
标题指代模糊,缺少主语或故意不点明主体,以概括一类别的笼统性指代词替换,如使用「它」、「他」、「她」、「一句话」、「下一秒」、「这种东西」等。
3、强迫式标题:标题采用挑衅恐吓、强迫建议等方式,诱导用户阅读,标题使用「胆小慎入」、「不看后悔一辈子」、「别怪我没提醒你」等表述,挑衅恐吓用户点击:
标题使用「不得不看」、「一定要看完」、「绝对要收藏」等命令式词语,要求或诱导用户阅读。
(二)标题与正文原意有偏差:
1、标题歧义:标题对易混淆的要素信息解释不清,或缺失主体信息,造成不对称,产生理解歧义,影视、游戏、小说、故事、段子、动漫、自制剧等内容,使用社会时政新闻类标题,造成歧义,标题直接用演员真名、职务代替剧中人物名,误导用户以为是明星花边。
2、题文不符:标题与内容对信息主体的某项特征描述不一致,形成冲突,造成信息传达错误,标题无中生有,捏造内容中不存在的人、物、情节,态度、言论、结果、场景等,标题描述为确定事件,但内容为猜测、谣传事件,或通过疑问的方式表达不确定或确定为假的消息,使用户产生误解。
3、封面与标题不符,让用户产生误解:封面图与内容完全不相关,或封面图结合标题易使读者产生误解。
二、标题格式不规范
1、标题未明确题材:影视、综艺、小说/故事、动漫、自制剧等题材的标题易产生歧义,对用户造成误导,需在标题中明确题材或剧名/书名等,如「小说:」、「影视:」等。
2、标题含有错别字或存在语病:标题含有错字、别字,以及标题不通顺等,影响阅读体验,包括但不限于以下情况:成分残缺:《或年初上市,于日本开卖》,用词不当:《十代雅阁年初上市,于日本贩卖》,语序不当:《十代雅阁上市年初,于日本开卖》,搭配不当:《十代雅阁年初上市,于日本开卖,吸引了一大批汽车爱好者的眼睛》,错别字:比如,《这就是爱情》→《这就是爱卿》等。
3、标题含有谩骂词:标题中含有侮辱谩骂词语,或对性别、地域、身份等恶意攻击,语言粗鄙,引起用户反感。
4、标题信息表达不全:标题过短,或无法体现内容,如使用数字、单个词语词组、无意义名称,社交账号倒流等,影响阅读,比如,谈判与口才系列更多精彩153555286,比如,文字:数字:符号=92.86%:0%:7.14%等等。
若处理设备检测到标题信息符合上述内容,则可以确定该标题信息容易对文本标签的确定产生干扰,从而不基于该标题信息确定文本标签。
为了能够获取上述用于文本标签确定的标签预测模型,处理设备可以预先进行相应的模型训练。在一种可能的实现方式中,处理设备可以根据历史多媒体内容的历史关键文本信息和该历史多媒体内容对应的历史账号描述信息构建训练样本,该历史多媒体内容具有样本文本标签。即,处理设备可以获取一些文本标签已知的历史多媒体内容来进行模型训练,该历史多媒体内容可以为在模型训练时文本标签已知的多媒体内容。
处理设备可以根据该训练样本对标签预测模型进行训练,在训练过程中,处理设备可以通过其中的标签提取子模型,确定每个候选文本标签的历史标签向量,该历史标签向量即为该标签提取子模型在训练结束前确定出的标签向量;通过账号提取子模型,处理设备可以确定历史账号描述信息的历史账号特征向量,该历史账号特征向量即为该账号提取子模型在训练结束前确定出的账号特征向量;通过内容提取子模型,处理设备可以根据历史关键文本信息确定历史多媒体内容的历史内容特征向量,该历史内容特征向量即为该内容提取子模型在训练结束前确定出的内容特征向量。
通过特征融合子模型,处理设备可以将历史账号特征向量和历史内容特征向量进行融合,得到历史融合特征向量,并通过匹配子模型,根据历史融合特征向量和每个历史标签向量之间的匹配度,确定历史文本标签。处理设备可以通过该历史文本标签与样本文本标签之间的差异,分析该标签预测模型的预测准确度,从而对该标签预测模型进行有针对性的调参。例如,若该历史文本标签与样本文本标签不一致,则说明该标签预测模型所确定出的文本标签不够准确,此时,处理设备可以调整该标签预测模型的模型参数,使其确定出的历史文本标签能够更加贴合样本文本标签。
例如,当该标签预测模型为双塔模型时,处理设备可以基于样本文本标签与历史文本标签之间的差异,调整标签提取子模型、账号提取子模型、内容提取子模型、特征融合子模型和匹配子模型分贝对应的模型参数,从而使这些子模型所确定出信息能够更加有助于确定出准确的文本标签,这也体现了双塔模型在调参上的整体性优势。
如图3所示,图3为本申请实施例提供的一种双塔模型的示意图,当待处理多媒体内容为待处理视频时,对于第一模型分支(即内容塔,content tower),处理设备可以将媒体作者所发布待处理视频对应的标题信息(title)和待处理视频的内容文字识别信息以及待处理视频的语音识别结果信息。通常媒体视频画面有字幕、内容介绍信息等可识别文字,视频中有用户的待处理视频通常可以进行语音识别,识别出对应的语音识别结果信息,基于这些信息可以确定出待处理视频的内容特征向量。此外,处理设备可以将发布待处理视频的媒体账号的账号昵称及账号简介信息输入第一模型分支,得到该待处理视频对应的账号特征向量,多个候选文本标签可以输入到第二模型分支(即标签塔,item tower)。
其中,内容文字识别信息可以为光学字符识别(Optical CharacterRecognition,简称OCR)信息,OCR是指电子设备(例如扫描仪或数码相机)检查图像上的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术,在本申请实施例中主要是通过视频抽帧,通过视频帧识别视频内容中的文字信息。
语音识别结果信息可以为自动语音识别(Automatic Speech Recognition,简称ASR)信息,也就是俗称的“语音听写机”,是实现“声音”到“文字”转换的技术。自动语音识别也称为语音识别(Speech Recognition)或计算机语音识别(Computer SpeechRecognition)。其基本原理包括:训练(Training):预先分析出语音特征参数,制作语音模板,并存放在语音参数库中。识别(Recognition):待识语音经过与训练时相同的分析,得到语音参数。将它与库中的参考模板一一比较,并采用判决的方法找出最接近语音特征的模板,得出识别结果。失真测度(Distortion Measures):在进行比较时要有个标准,这就是计量语音特征参数矢量之间的“失真测度”。主要识别框架:基于模式匹配的动态时间规整法(DTW)和基于统计模型的隐马尔可夫模型法(HMM)。本申请实施例中可以利用ASR识别的结果作为语音识别结果信息输入到模型中进行匹配。
处理设备可以通过模型中的全连接层(Fully Connected Layer,简称FC)来进行特征融合,得到基于账号特征向量和内容特征向量确定出的特征融合向量,以及通过语言表征模型(Bidirectional Encoder Representation from Transformers,简称Bert)来确定账号昵称、账号简介等账号描述信息所对应的账号特征向量和各个候选文本标签对应的标签向量,最后通过匹配层可以确定出融合特征向量与各个标签向量之间的匹配度。
在模型训练过程中,以视频内容距离,处理设备可以获取视频平台上的已发布视频内容对应的标题信息,内容文字识别信息OCR,和语音识别结果新ASR构造训练样本,该已发布视频内容具有对应的样本文本标签。在模型的第二模型分支采用的是候选文本标签的BERT向量作为标签向量,BERT的核心是双向编码器(Transformer Encoder)。在训练过程当中,12层BERT的训练效果显然优于2层BERT,但是训练速度、推理速度也远慢于2层模型。综合模型效果与效率两方面考虑,选择2层模型作为实际模型,在损失少量精度的前提下,大幅提高推理速度,更符合实际场景和产品落地的需求。处理设备可以根据确定出的历史文本标签与样本文本标签之间的差异,对各个子模型(例如Bert模型等)进行调参。
在进行文本标签预测时,该匹配层可以通过邻近算法(k-NearestNeighbor,简称KNN)来确定融合特征向量与各个标签向量之间的匹配度。处理设备可以先将自身存储的多个候选文本标签对应的标签向量输入到KNN算法中,该标签向量可以通过图中的BERT模型来生成,然后对于需要确定文本标签的视频内容,可以获取其对应的标题信息、从视频内容中识别出的内容文字识别信息和从视频的语音中识别出的语音识别结果信息(比如OCR识别和ASR抽取的结果),用第一模型分支的前馈网络生成内容特征向量(doc vectors),以及根据账号昵称、账号简介等信息生成账号特征向量,基于这两个向量得到特征融合向量,然后去匹配层的KNN算法中召回最相关的文本标签,从而完成对该视频内容文本标签的确定。KNN算法是数据挖掘分类技术中常用的方法之一,在该算法中,每个样本都可以用它最接近的k个邻近值来代表。KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该算法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。在本申请实施例中可以通过KNN算法确定出匹配度,然后召回匹配度处于topN的文本标签作为目标文本标签,具体可以依据业务策略选择N为1或者大于1的整数。如图4所示,图4为本申请实施例提供的一种匹配层的示意图,该匹配层可以基于融合特征向量和标签向量确定出匹配度,例如可以为KNN算法中的最邻近指数(Nearest neighbor index),该最邻近指数能够体现出融合特征向量与各个标签向量之间的相似性,然后基于匹配度确定出topN的文本标签作为目标文本标签。
其中,为了保障模型训练时样本的准确性,处理设备需要保障历史多媒体内容所对应的样本文本标签能够准确的反映出该历史多媒体内容的情感表达。因此,在本申请实施例中,处理设备可以通过人工标注的方式来为历史多媒体内容进行文本标签的标记,以保证训练样本的准确性。
然而,想要训练出有效的标签预测模型,就要有充足的样本数据量,若通过人工为历史多媒体内容逐一标注文本标签会耗费大量的时间和精力,标记效率较低。可以理解的是,在缺乏标签预测模型时,虽然处理设备无法精准的确定出多媒体内容对应的文本标签,但是处理设备可以对不同多媒体内容之间的相似度进行较为准确的识别。通常情况下,内容相似程度较高的多媒体内容所表达的情感也具有一定的相似性,例如,同属于亲情类的视频中,视频画面中通常都具有多个人物角色,以及通常都为住宅内场景。
基于此,在一种可能的实现方式中,为了提高相关人员对多媒体内容进行文本标签标记的效率,处理设备可以先获取多个媒体账号分别发布的多媒体内容,然后对该多个媒体账号分别发布的多媒体内容进行聚类,得到聚类簇,其中对应于同一个聚类簇的多媒体内容的内容相似度较高。从而,处理设备可以根据多个聚类簇对应的多媒体内容,确定候选文本标签,使同一文本标签能够准确的标记在具有相似情感表达的多媒体内容上。例如,处理设备可以获取相关人员针对每一个聚类簇对应的多媒体内容所确定出的文本标签,将该文本标签确定为该聚类簇对应所有多媒体内容的文本标签,从而能够在保障文本标签准确度的同时,提高了标签标记的效率,即只需要针对一个聚类簇对应的所有多媒体内容确定一次文本标签即可,无需逐一进行标签标记。
除了内容相似度较高的多媒体内容在情感表达上较为接近外,上已述及,同一媒体账号所发布的多媒体内容在情感表达上同样具有一定的相似性。因此,在一种可能的实现方式中,为了进一步提高聚类的准确度,处理设备除了可以基于内容相似度维度进行聚类,还可以在此基础上结合账号维度进行聚类。
在进行聚类时,处理设备可以确定不同媒体账号发布的多媒体内容之间的相似度,然后将所发布多媒体内容之间的相似度满足第一预设阈值的媒体账号划分至同一个聚类簇,得到多个聚类簇,其中多个聚类簇为账号簇。从而,处理设备可以将所发布内容之间较为相似的媒体账号进行聚类,从而既保障了内容相似度,也保障了同一个聚类簇对应的多媒体内容的情感表达在账号维度上有较高的相似性,使同一聚类簇对应的多媒体内容在情感表达上更加接近,有助于确定更加准确的文本标签。
例如,在一种可能的实现方式中,当多媒体内容为视频内容时,处理设备可以通过视频抽帧比较的方式来确定视频内容之间的相似度。首先,处理设备可以确定各个视频内容对应的视频向量,视频内容的向量就是用一个低维的向量表示一个视频,两个向量的“距离”代表两个视频内容之间的距离,进而可以计算视频内容的相似度。
如图5所示,处理设备可以先输入视频内容,这里可以输入视频帧序列,从中抽取部分有代表性的视频帧,然后通过时间段网络(Temporal Segment Networks,简称TSN)算法等图像特征提取模型提取各个视频帧所对应的图像特征,最后通过特征向量确定模型,例如Youtub8M-NeXtVLad网络比赛中的比赛模型的中间层确定多个图像特征分别对应的图像特征向量,然后用图像特征向量加和平均得到视频内容对应的视频向量。如图6所示,处理设备可以先获取多个媒体账号A1~A_n所发布的视频,然后基于视频内容的相似度,将多个所发布视频内容之间相似度较高的媒体账号归为同一账号簇中,最后通过人工对账号簇进行核查,并标记上对应的文本标签,在保障了文本标签标记的合理性同时提高了标签标记的效率。
上已述及,多媒体内容的内容相似度和媒体账号的账号相似度在一定程度上都能够反应出情感表达的相似,基于此,当已经通过上述方式预测出一些多媒体内容对应的文本标签后,处理设备可以基于待处理多媒体内容和已预测多媒体内容在内容和账号这两个维度上的相似性,来根据已预测多媒体内容的文本标签确定待处理多媒体内容的文本标签,其中已预测多媒体内容为已经预测出对应文本标签的多媒体内容。
在一种可能的实现方式中,若目标媒体账号与已预测多媒体内容对应媒体账号相同,说明该待处理多媒体内容与已预测多媒体内容是同一媒体账号所发布的,由于同一媒体账号所发布的内容通常具有相似的情感表达,因此可以将已预测多媒体内容的文本标签确定为该目标文本标签。
同理,若目标关键文本信息与已预测多媒体内容的关键文本信息之间的相似度达到第二预设阈值,或者,若目标账号描述信息与已预测多媒体内容的账号描述信息之间的相似度达到第三预设阈值,则分别可以说明该待处理多媒体内容与已预测多媒体内容在内容维度和账号维度上的相似度较高,进而可以说明该待处理多媒体内容与已预测多媒体内容在情感表达上也较为相似,处理设备也可以将已预测多媒体内容的文本标签确定为目标文本标签。通过该方式,处理设备可以无需将每一个待处理多媒体都通过向量提取、模型预测等方式来进行文本标签的标记,从而在保障标签预测准确性的基础上,进一步提高标签预测的效率。
为了便于理解本申请实施例提供的技术方案,接下来,将结合一种实际应用场景,对本申请实施例提供的一种文本标签确定方法进行介绍。
参见图7,图7为本申请实施例提供的一种具有文本标签预测功能的多媒体系统架构的示意图。在该实际应用场景中,文本标签为情感标签,多媒体内容可以为视频内容、图像内容、文章内容等,处理设备为具有图示系统架构的多媒体系统,该系统中可以包括例如上下行内容接口服务器、情感标签预测服务器等多个服务器,以及可以包括用于发布者上传或浏览视频内容的终端。
该多媒体系统架构如下所述:
一.内容生产端701和内容消费端702
(1)专业生产内容(Professionally-generated Content,简称PGC)或者用户原创内容(User Generated Content,简称UGC),多频道网络(Multi-Channel Network,简称MCN)或者专业用户生产内容(Professional User Generated Content,简称PUGC)的内容生产者,通过移动端或者后端接口系统,提供本地或者拍摄的图文内容,视频或者图集内容,这些都是分发内容的主要内容来源。
(2)通过和上下行内容接口服务器703的通讯,先获取上传服务器接口地址,然后在上传本地文件,拍摄过程当中本地图文内容可以选择搭配的音乐,滤镜模板和图文的美化功能等等。
(3)作为消费者,和上下行内容接口服务器703通讯,获取访问图文或者视频文件的索引信息,然后下载对应的流媒体文件并且通过本地播放器来播放观看。
(4)同时将上传和下载过程当中用户播放的行为数据,卡顿,加载时间,播放点击等上报给服务器。
二.上下行内容接口服务器703
(1)和内容生产端701直接通讯,从前端提交的内容,通常是内容的标题,发布者,摘要,封面图,发布时间,或者是拍摄的多媒体内容直接通过该服务器进入服务端,把文件存入内容数据库704。
(2)将多媒体内容的元信息,比如多媒体内容文件大小,封面图链接,码率,文件格式,标题,发布时间,作者等信息写入内容数据库704。
(3)将上传的多媒体内容文件提交给调度中心服务器705,进行后续的内容处理和流转。
三.内容数据库704
(1)内容的核心数据库,所有生产者所发布多媒体内容的元信息都保存在数据库704当中,重点是内容本身的元信息文件大小,封面图链接,码率,文件格式,标题,发布时间,作者,是否原创或者首发,还包括人工审核过程中对内容的分类(包括一,二,三级别分类和标签信息,比如一个讲解手机的视频,一级分科是科技,二级分类是智能手机,三级分类是国内手机,标签信息可以是手机品牌、手机型号等)。
(2)上下行内容接口服务器703在收到视频文件的时候对内容进行标准的转码操作,转码完成后异步返回元信息(主要包括文件大小,码率,规格,截取封面图等),这些信息都会保存在内容数据库704当中。
(3)人工审核过程当中会会读取内容数据库704当中的信息,同时人工审核的结果和状态也会回传进入内容数据库704,来更新内容数据库704中内容的元信息。
(4)调度中心服务器705对内容处理主要包括机器处理和人工审核处理,这里机器处理核心就是调用内容排重服务706确定出完全重复和相似的内容,排重的结果会写入内容数据库704,完全重复的内容不会给人工进行重复的二次处理。
四.调度中心服务器705
(1)负责内容流转的整个调度过程,通过上下行内容接口服务器703接收入库的内容,然后从内数据库704中获取元信息。
(2)调度人工审核系统707和机器处理系统,控制调度的顺序和优先级。
(3)对于多媒体内容,先和召回检索服务通讯,然后和判重服务通讯,过滤掉不必要的重复相似内容。
(4)没有达到重复过滤的内容,输出内容相似度和相似关系链,供推荐系统打散使用。
(5)最后通过人工审核系统707的内容启用通过内容出口分发服务,通常是推荐引擎或者搜索引擎,或者运营直接的展示页面提供给终端的内容消费者。
(6)负责和情感标签预测服务器708通讯,完成对视频内容的情感标签预测和补充调度处理;
五.人工审核系统707
(1)需要读取内容数据库704中多媒体内容本身的原始信息,该人工审核系统707通常是一个业务复杂的基于web数据库开发的系统,通过人工来对内容是否涉及敏感信息等特性进行一轮初步过滤。
(2)在初步审核的基础之上,对内容进行二次审核,主要是对内容进行分类和标签的标注或者确认,由于视频内容本身完全通过机器学习比如深度学习还不完全成熟,所以需要通过在机器处理的机器上进行二次的人工审核处理,通过人机协作,提升视频本身标注的准确性和效率。
六.内容排重服务器706
(1)提供视频内容的排重服务,主要通过将视频内容进行向量化,然后建立向量的索引,然后通过比较向量之间的距离来确定相似程度。可以理解的是,该内容排重服务器706所确定出的视频向量和视频向量相似度可以用于进行账号簇的生成。
(2)由于同时发布的内容很多,这里主要实现海量去重服务的工程并行化能力,主要避免重复的内容启用。
七.下载文件系统709
(1)从内容存储服务器710下载和获取原始的视频内容,控制下载的速度和进度,通常是一组并行的服务器,有相关的任务调度和分发集群构成。
(2)下载完成的文件调用抽帧服务从视频源文件当中获取必要的视频文件关键帧,作为后续对视频的内容文字识别OCR和进行视频的语音识别ASR过程当中进行语音分离的预处理服务。
八.视频内容文字识别和视频语音识别服务器711
该服务器可以使用OCR技术和ASR技术确定视频内容对应的内容文字识别信息和语音识别结果信息,作为双塔模型中的关键文本信息输入,增加对视频内容理解的更多维度的输入。
九.内容存储服务器710
(1)通常是一组分布范围很广的存储服务器,通常外围还有内容分发网络(Content Delivery Network,简称CDN)加速服务器进行分布式缓存加速,通过上下行内容接口服务器703将内容生产者上传的视频和图片内容保存起来。
(2)终端消费者在获取内容索引信息后,也可以直接访问视频内容存储服务器710下载对应的内容。
(3)除了作为对外服务的数据源以外,还作为对内服务的数据源,供下载文件系统709获取原始的视频数据进行相关的处理,内外数据源的通路通常是分开部署的,避免相互影响。
十.情感标签预测服务器708
服务器708可以将上面描述的标签预测模型712服务化,和调动中心服务器705通讯,完成内容流程主链路上内容情感标签的挖掘和补充。
对于情感标签预测服务,可以增加一个环节(不是必须的)给人工复核,人工复核通过的情感标签则可以直接使用。当模型进行预测的情感标签的准确率达到一定阀值之后,可以去掉这个环节,直接进行自动预测。
十一.标签预测模型712
读取内容数据库704当中的待处理视频内容,以及待处理视频内容对应的内容文字识别信息和语音识别结果信息,以及视频内容发布者的媒体账号对应的账号描述信息,通过上述内容中所介绍的标签预测过程确定该待处理视频内容对应的情感标签。
本申请实施例还提供了一种文本标签识别的实际应用场景,参见图11,在该实际应用场景中包括短视频播放终端和标签识别服务器,该短视频播放终端用于播放短视频内容,该短视频内容即为该应用场景中的多媒体内容。在该短视频播放终端上安装有短视频播放软件,负责审核短视频内容的用户在浏览短视频的过程中,可以通过点击视频下方的“识别标签”虚拟按钮来自动识别该短视频对应的文本标签。
当检测到用户针对该按钮的点击操作后,终端可以向标签识别服务器发送标签识别请求,该标签识别服务器用于识别短视频对应的文本标签。标签识别服务器可以获取该短视频对应的标题信息、根据该短视频画面中人物的发言确定出的语音识别结果信息,以及发布该短视频的账号对应的账号昵称和账号简介信息,基于上述信息可以分别生成该短视频对应的内容特征向量和账号特征向量,经过融合可以得到融合特征向量。在与“亲情”、“友情”和“爱情”三个候选文本标签进行匹配后,可以确定出匹配度最高的“亲情”标签作为该短视频对应的文本标签。如图11所示,标签识别服务器可以将该文本标签添加到该短视频中,从而该短视频软件可以将该短视频推荐给喜欢看亲情类视频的用户,实现短视频内容的精确推送。
基于上述实施例提供的文本标签的确定方法,本申请实施例还提供了一种文本标签的确定装置,参见图8,图8为本申请实施例提供的一种文本标签的确定装置800的结构框图,该装置800包括:第一获取单元801、第二获取单元802、第一确定单元803、融合单元804和第二确定单元805:
所述第一获取单元801,用于获取待处理多媒体内容的目标关键文本信息;
所述第二获取单元802,用于获取目标媒体账号的目标账号描述信息,所述目标媒体账号为发布所述待处理多媒体内容的媒体账号;
所述第一确定单元803,用于确定每个候选文本标签的标签向量、确定所述目标账号描述信息的账号特征向量,以及根据所述目标关键文本信息确定所述待处理多媒体内容的内容特征向量;
所述融合单元804,用于将所述账号特征向量和所述内容特征向量进行融合,得到融合特征向量;
所述第二确定单元805,用于根据所述融合特征向量和所述每个候选文本标签的标签向量之间的匹配度,确定所述待处理多媒体内容的目标文本标签。
在一种可能的实现方式中,所述第一确定单元803具体用于:
通过标签预测模型中的标签提取子模型,确定所述每个候选文本标签的标签向量;
通过所述标签预测模型中的账号提取子模型,确定所述目标账号描述信息的账号特征向量;
通过所述标签预测模型中的内容提取子模型,根据所述目标关键文本信息确定所述内容特征向量。
在一种可能的实现方式中,所述融合单元804具体用于:
通过所述标签预测模型中的特征融合子模型将所述账号特征向量和所述内容特征向量进行融合,得到所述融合特征向量;
所述第二确定单元具体805用于:
通过所述标签预测模型中的匹配子模型,根据所述融合特征向量和所述每个候选文本标签的标签向量之间的匹配度,确定所述目标文本标签。
在一种可能的实现方式中,所述标签预测模型为双塔模型,所述标签提取子模型为所述双塔模型的第一模型分支;所述账号提取子模型、所述内容提取子模型和所述特征融合子模型构成所述双塔模型的第二模型分支。
在一种可能的实现方式中,装置800还包括样本构建单元和训练单元:
所述样本构建单元,用于根据历史多媒体内容的历史关键文本信息和所述历史多媒体内容对应的历史账号描述信息构建训练样本,所述历史多媒体内容具有样本文本标签;
所述训练单元,用于根据所述训练样本对所述标签预测模型进行训练;
在训练过程中,通过所述标签提取子模型,确定每个所述候选文本标签的历史标签向量;通过所述账号提取子模型,确定所述历史账号描述信息的历史账号特征向量;通过所述内容提取子模型,根据所述历史关键文本信息确定所述历史多媒体内容的历史内容特征向量;通过所述特征融合子模型将所述历史账号特征向量和所述历史内容特征向量进行融合,得到历史融合特征向量;并通过所述匹配子模型,根据所述历史融合特征向量和每个所述历史标签向量之间的匹配度,确定历史文本标签;若所述历史文本标签与所述样本文本标签不一致,调整所述标签预测模型的模型参数。
在一种可能的实现方式中,装置800还包括第三获取单元、聚类单元和第三确定单元:
所述第三获取单元,用于获取多个媒体账号分别发布的多媒体内容;
所述聚类单元,用于对所述多个媒体账号分别发布的多媒体内容进行聚类,得到多个聚类簇;
所述第三确定单元,用于根据所述多个聚类簇对应的多媒体内容,确定所述候选文本标签。
在一种可能的实现方式中,所述聚类单元具体用于:
确定不同媒体账号发布的多媒体内容之间的相似度;
将所发布多媒体内容之间的相似度满足第一预设阈值的媒体账号划分至同一个聚类簇,得到所述多个聚类簇,所述多个聚类簇为账号簇。
在一种可能的实现方式中,所述第二确定单元805具体用于:
将所述每个候选文本标签按照对应的标签向量与所述融合特征向量之间的匹配度从高到低的顺序排列;
将排列在前N位的候选文本标签确定为所述目标文本标签,N为大于或者等于1的整数。
在一种可能的实现方式中,装置800还包括第四确定单元:
所述第四确定单元,用于若所述目标媒体账号与已预测多媒体内容对应媒体账号相同,将所述已预测多媒体内容的文本标签确定为所述目标文本标签;
或者,若所述目标关键文本信息与所述已预测多媒体内容的关键文本信息之间的相似度达到第二预设阈值,将所述已预测多媒体内容的文本标签确定为所述目标文本标签;
或者,若所述目标账号描述信息与所述已预测多媒体内容对应的账号描述信息之间的相似度达到第三预设阈值,将所述已预测多媒体内容的文本标签确定为所述目标文本标签。
在一种可能的实现方式中,所述目标关键文本信息包括所述待处理多媒体内容的标题信息、所述待处理多媒体内容的内容文字识别信息和所述待处理多媒体内容的语音识别结果信息中一种或多种的组合。
在一种可能的实现方式中,所述装置800还包括第五确定单元和执行单元:
所述第五确定单元,用于确定所述待处理多媒体内容的标题信息是否符合预设标题规则;
所述执行单元,用于若所述待处理多媒体内容的标题信息符合预设标题规则,执行确定每个候选文本标签的标签向量、确定所述目标账号描述信息的账号特征向量,以及根据所述目标关键文本信息确定所述待处理多媒体内容的内容特征向量的步骤。
本申请实施例还提供了一种计算机设备,下面结合附图对该设备进行介绍。请参见图9所示,本申请实施例提供了一种设备,该设备还可以是终端设备,该终端设备可以为包括手机、平板电脑、个人数字助理(Personal Digital Assistant,简称PDA)、销售终端(Point of Sales,简称POS)、车载电脑等任意智能终端,以终端设备为手机为例:
图9示出的是与本申请实施例提供的终端设备相关的手机的部分结构的框图。参考图9,手机包括:射频(Radio Frequency,简称RF)电路910、存储器920、输入单元930、显示单元940、传感器950、音频电路960、无线保真(Wireless Fidelity,简称WiFi)模块970、处理器980、以及电源990等部件。本领域技术人员可以理解,图9中示出的手机结构并不构成对手机的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图9对手机的各个构成部件进行具体的介绍:
RF电路910可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器980处理;另外,将设计上行的数据发送给基站。通常,RF电路910包括但不限于天线、至少一个放大器、收发信机、耦合器、低噪声放大器(Low NoiseAmplifier,简称LNA)、双工器等。此外,RF电路910还可以通过无线通信与网络和其他设备通信。上述无线通信可以使用任一通信标准或协议,包括但不限于全球移动通讯系统(Global System of Mobile communication,简称GSM)、通用分组无线服务(GeneralPacket Radio Service,简称GPRS)、码分多址(Code Division Multiple Access,简称CDMA)、宽带码分多址(Wideband Code Division Multiple Access,简称WCDMA)、长期演进(Long Term Evolution,简称LTE)、电子邮件、短消息服务(Short Messaging Service,简称SMS)等。
存储器920可用于存储软件程序以及模块,处理器980通过运行存储在存储器920的软件程序以及模块,从而执行手机的各种功能应用以及数据处理。存储器920可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器920可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
输入单元930可用于接收输入的数字或字符信息,以及产生与手机的用户设置以及功能控制有关的键信号输入。具体地,输入单元930可包括触控面板931以及其他输入设备932。触控面板931,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板931上或在触控面板931附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板931可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器980,并能接收处理器980发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板931。除了触控面板931,输入单元930还可以包括其他输入设备932。具体地,其他输入设备932可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
显示单元940可用于显示由用户输入的信息或提供给用户的信息以及手机的各种菜单。显示单元940可包括显示面板941,可选的,可以采用液晶显示器(Liquid CrystalDisplay,简称LCD)、有机发光二极管(Organic Light-Emitting Diode,简称OLED)等形式来配置显示面板941。进一步的,触控面板931可覆盖显示面板941,当触控面板931检测到在其上或附近的触摸操作后,传送给处理器980以确定触摸事件的类型,随后处理器980根据触摸事件的类型在显示面板941上提供相应的视觉输出。虽然在图10中,触控面板931与显示面板941是作为两个独立的部件来实现手机的输入和输入功能,但是在某些实施例中,可以将触控面板931与显示面板941集成而实现手机的输入和输出功能。
手机还可包括至少一种传感器950,比如光传感器、运动传感器以及其他传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示面板941的亮度,接近传感器可在手机移动到耳边时,关闭显示面板941和/或背光。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于手机还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
音频电路960、扬声器961,传声器962可提供用户与手机之间的音频接口。音频电路960可将接收到的音频数据转换后的电信号,传输到扬声器961,由扬声器961转换为声音信号输出;另一方面,传声器962将收集的声音信号转换为电信号,由音频电路960接收后转换为音频数据,再将音频数据输出处理器980处理后,经RF电路910以发送给比如另一手机,或者将音频数据输出至存储器920以便进一步处理。
WiFi属于短距离无线传输技术,手机通过WiFi模块970可以帮助用户收发电子邮件、浏览网页和访问流式媒体等,它为用户提供了无线的宽带互联网访问。虽然图10示出了WiFi模块970,但是可以理解的是,其并不属于手机的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。
处理器980是手机的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器920内的软件程序和/或模块,以及调用存储在存储器920内的数据,执行手机的各种功能和处理数据,从而对手机进行整体监控。可选的,处理器980可包括一个或多个处理单元;优选的,处理器980可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解的是,上述调制解调处理器也可以不集成到处理器980中。
手机还包括给各个部件供电的电源990(比如电池),优选的,电源可以通过电源管理系统与处理器980逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。
尽管未示出,手机还可以包括摄像头、蓝牙模块等,在此不再赘述。
在本实施例中,该终端设备所包括的处理器980还具有以下功能:
获取待处理多媒体内容的目标关键文本信息;
获取目标媒体账号的目标账号描述信息,所述目标媒体账号为发布所述待处理多媒体内容的媒体账号;
确定每个候选文本标签的标签向量、确定所述目标账号描述信息的账号特征向量,以及根据所述目标关键文本信息确定所述待处理多媒体内容的内容特征向量;
将所述账号特征向量和所述内容特征向量进行融合,得到融合特征向量;
根据所述融合特征向量和所述每个候选文本标签的标签向量之间的匹配度,确定所述待处理多媒体内容的目标文本标签。
本申请实施例还提供一种服务器,请参见图10所示,图10为本申请实施例提供的服务器1000的结构图,服务器1000可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(Central Processing Units,简称CPU)1022(例如,一个或一个以上处理器)和存储器1032,一个或一个以上存储应用程序1042或数据1044的存储介质1030(例如一个或一个以上海量存储设备)。其中,存储器1032和存储介质1030可以是短暂存储或持久存储。存储在存储介质1030的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器1022可以设置为与存储介质1030通信,在服务器1000上执行存储介质1030中的一系列指令操作。
服务器1000还可以包括一个或一个以上电源1026,一个或一个以上有线或无线网络接口1050,一个或一个以上输入输出接口1058,和/或,一个或一个以上操作系统1041,例如Windows Server
上述实施例中由服务器所执行的步骤可以基于图10所示的服务器结构。
本申请实施例还提供一种计算机可读存储介质,用于存储计算机程序,该计算机程序用于执行前述各个实施例所述的文本标签的确定方法中的任意一种实施方式。
本申请实施例还提供了一种包括指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述任意一项实施例提供的文本标签的确定方法。
可以理解的是,在本申请的具体实施方式中,涉及到用户信息(如用户的媒体账号的账号描述信息)等相关的数据,当本申请以上实施例运用到具体产品或技术中时,需要获得用户许可或者同意,且相关数据的收集、使用和处理需要遵守相关国家和地区的相关法律法规和标准。
上述各个附图对应的流程或结构的描述各有侧重,某个流程或结构中没有详述的部分,可以参见其他流程或结构的相关描述。
本申请的说明书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-Only Memory,简称ROM)、随机存取存储器(Random Access Memory,简称RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术成员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 一种神经网络模型训练方法及装置、文本标签确定方法及装置
- 一种相机姿态信息确定的方法及相关装置
- 一种物料出库数据确定的方法以及相关装置
- 一种物料位置确定的方法以及相关装置
- 一种确定数据相关性的方法及装置
- 文本标签的确定方法及相关装置
- 一种神经网络模型训练方法及装置、文本标签确定方法及装置