移除手写文档图像中涂抹的方法及相关产品
文献发布时间:2024-04-18 19:58:30
技术领域
本公开的非限制性和示例性的实施例一般涉及图像处理,并且具体涉及用于移除手写文档图像中涂抹的方法、装置、设备和机器可读存储介质。
背景技术
手写是人类表达知识和记载信息时最常用的方法。对手写文档图像的内容自动检测是数字文档分析领域的一个重要研究课题。尽管由于人类书写的多样性,这个问题非常有挑战性,但近年来随着例如基于卷积神经网络CNN(Convolutional Neural Network)的深度学习检测模型的发展和演进,检测效果取得了显著进步。
目前,大多数检测模型在对手写文档图像上的笔迹进行检测时,都假设图像上的笔迹是正常的,即在笔迹中不存在涂抹。
然而,在手写过程中,人们往往会发生错误,例如拼写错误、上下文不当的措辞、错误的数字或符号等。此外,写作过程中,作者的思想和观点可能会发展和变化,导致先前所写的内容变得不太有价值甚至是错误的。作者通常会涂抹这些错误或不需要的内容,并在旁边写下更正的内容。这些涂抹出现在各种手写文档中,例如信函、手稿和考卷上,而一旦被检测为正常字符就会产生谬误。
当前已存在对手写文档图像中的涂抹进行检测并移除的方案。例如,BBChaudhuri和C Adak在其论文“An approach for detecting and cleaning of struck-out handwritten text”(Pattern Recognition,vol.61,pp.282-294,2017年1月,doi:https://doi.org/10.1016/j.patcog.2016.07.032)中提出使用混合模型和支持向量机SVM和径向基函数RBF(Radial Basis Function)分类器来区分涂抹和正常文本,进而清除所检测的涂抹。专利申请CN110400309A公开了一种涂抹移除方法,包括利用例如神经网络来确定目标图像中的涂抹痕迹信息,并且对确定的涂抹痕迹进行清除处理或者覆盖处理。专利申请CN112052852A记载了一种剔除涂抹字符的方法,其中为解决涂抹字符检测的问题准备了高低质量两个数据集,分别训练了两个具有识别差异的卷积循环神经网络CRNN(Convolutional Recurrent Neural Network)模型,将相同的检测结果作为输出值,且利用数据集间的差异来剔除涂抹字符。
发明内容
当前已有的涂抹检测和移除方案存在检测精度不高和移除不准确的技术问题,其中检测精度不高可能导致将部分正常笔迹检测为涂抹笔迹和/或将涂抹笔迹检测为正常笔迹,而移除不准确可能导致在移除涂抹笔迹的过程中,将涂抹笔迹附近的正常笔迹一并移除。
本公开的一个目的在于消除或缓解上述移除不准确的技术问题。为了实现该目的,本公开的发明人想到在移除深度学习检测模型所检测的涂抹边界框内的涂抹时,考虑所述边界框内的笔迹和所述边界框之间的关系,以避免移除所述边界框内的正常笔迹(如果有的话)。
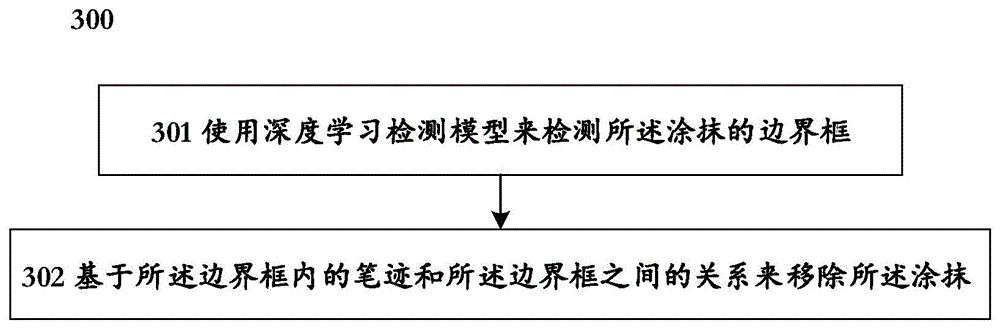
根据本公开的第一方面,上述目的通过一种用于移除手写文档图像中涂抹的方法来实现。所述方法包括:使用深度学习检测模型来检测所述涂抹的边界框;以及基于所述边界框内的笔迹和所述边界框之间的关系来移除所述涂抹。
根据本公开的第二方面,上述目的通过一种用于移除手写文档图像中涂抹的装置来实现。所述装置包括:检测部件,用于使用深度学习检测模型来检测所述涂抹的边界框;以及移除部件,用于基于所述边界框内的笔迹和所述边界框之间的关系来移除所述涂抹。
根据本公开的第三方面,上述目的通过一种用于移除手写文档图像中涂抹的设备来实现。所述设备包括处理器和已存储指令的存储器,其中所述指令在被所述处理器执行时使得所述设备执行根据所述第一方面的方法。
根据本公开的第四方面,上述目的通过一种机器可读存储介质来实现。所述机器可读存储介质已存储指令,所述指令在设备上被执行时使得所述设备执行根据所述第一方面的方法。
本公开的另一目的在于消除或缓解上述检测精度不高的技术问题。为了实现该目的,本公开的发明人实际比较了多种检测模型,最后判定Swin-Transformer+CascadeMask-RCNN检测模型的效果最佳且将其用作所述深度学习检测模型。因此,在一些实施例中,采用Swin-Transformer+Cascade Mask-RCNN检测模型作为用于检测涂抹的深度学习检测模型,从而提高涂抹检测的精度。
本公开的另一目的在于为所述深度学习检测模型提供用于训练的样本图像。为了实现该目的,本公开的发明人想到拼接来自手写文档图像的多个子图以形成所述样本图像。因此,在一些实施例中,通过从手写文档图像内选取多个子图以及在空白图像上拼接所述多个子图来形成用于训练所述深度学习检测模型的样本图像,从而可以为该检测模型的训练有效增广学习数据样本。
附图说明
通过参考附图的以下详细描述,本公开的上述和其它方面、特征和益处将变得更加显而易见。在附图中,使用相同的参考数字或字母来表示相同或等效的元件。附图被示出是为了方便更好理解本公开的实施例,并且不一定按比例绘制,其中:
图1示出R-CNN的一个示例框架;
图2示出某数学考试的部分答卷示例图像;
图3是根据本公开实施例的用于移除手写文档图像中涂抹的方法的流程图;
图4在图2的部分答卷示例图像上进一步示出涂抹的边界框;
图5示出各深度学习检测模型进行涂抹检测的平均精度AP(Average Precision);
图6示出Swin-Transformer+Cascade Mask-RCNN检测模型的示例架构;
图7是边界框包括部分正常笔迹的示例图像;
图8示出移除边界框内的涂抹之前和之后的示例对比图像;
图9示意性示出根据本公开实施例来形成样本图像的示例过程;
图10是根据本公开实施例的装置的示意框图;
图11是根据本公开实施例的设备的示意框图。
具体实施方式
下文将参考附图更全面地描述本文的实施例。然而,本文的实施例可以以许多不同的形式来实施,并且不应被解释为限制所附权利要求的范围。
本文使用的术语仅用于描述特定实施例的目的,而非旨在进行限制。如本文所使用的,指示对象的名词可指单数个对象,也可指复数个对象,除非上下文另有明确指示。将进一步理解的是,术语“包括”、“包含”和/或“含有”在本文中使用时指定所述特征、步骤、操作、元件和/或组件的存在,但并不排除一个或多个其它特征、步骤、操作、元件、组件和/或其组合的存在或添加。
此外,在本文中使用诸如“第一”、“第二”和“第三”等序数词来修饰对象本身并不意味着一个对象相对于另一个对象的任何优先级、优先顺序或次序,也不意味着方法的动作被执行的时间顺序,而是仅用作将具有特定名称的一个对象与具有相同名称的另一对象进行区分的标签以区分这些对象。
除非另有定义,否则本文中使用的所有术语(包括技术术语和科学术语)具有与一般理解相同的含义。将进一步理解,本文中使用的术语应被解释为具有与其在本说明书和相关技术领域的上下文中的含义一致的含义,并且不应以限制性的意义被解读,除非在本文中明确如此被定义。
手写是人类表达知识和记载信息时最常用的方法。对手写文档图像的内容自动检测是数字文档分析领域的一个重要研究课题。尽管由于人类书写的多样性,这个问题非常有挑战性,但近年来随着例如基于卷积神经网络CNN(Convolutional Neural Network)的深度学习检测模型的发展和演进,检测效果取得了显著进步。
例如,基于区域的卷积神经网络R-CNN(Region-based Convolution NeuralNetwork)就是在卷积神经网络上应用区域推荐的策略所形成的自底向上的检测模型。R-CNN的一个示例框架在图1中被示出,其中左侧为所涉及到的技术,右侧为主要的检测阶段。
如图1所示,在R-CNN检测模型中,第一阶段是区域推荐(region proposal),即,给定一张图片,通过选择性搜索(selective search)算法产生并推荐1000~2000个候选框(代表候选区域),带有不同的形状和大小,这些框之间是可以互相重叠或互相包含的;第二阶段是特征提取,即,利用卷积神经网络CNN对每一个候选框提取特征;第三阶段是分类,即,利用线性支持向量机SVM(Support Vector Machine)对上一阶段提取的特征进行分类;第四阶段是去除重叠,即,将非极大值抑制算法应用于重叠的候选框,挑选出支持向量机得分较高的边界框(bounding box)。
然而,R-CNN候选区域缩放后的畸变问题和提取特征时的重复计算导致了模型性能和速度的瓶颈。为了解决这些问题,Fast R-CNN在R-CNN的卷积层和全连接层的衔接处加入网络层空间金字塔池化SPP(Spatial Pyramid Pooling)层,使得既能固定全连接层的输入维度又不让候选区域产生畸变,且解决了R-CNN重复计算的问题。
Fast R-CNN处理的第一步是对图像进行多次卷积核池化处理来获取卷积特征图。每个特征向量都会被输送到全连接层中,该全连接层分支成两个同级输出层。所述输出层之一的功能是进行分类,对目标关于K个对象类输出每一个候选区域的分类信息(softmax概率估计);另一层用于对每个候选区域输出四个实数值的定位信息,分别代表该区域的边界框的中心横坐标和纵坐标以及长度和宽度。
不过,Fast R-CNN依然采用传统的候选区域推荐算法(如选择性搜索),导致在实时性方面达不到要求。为了解决候选区域推荐这个瓶颈,进一步提出了Faster R-CNN模板检测模型。
Faster R-CNN主要包括两个模块:一个模块是区域推荐网络RPN(RegionProposal Network),其作为一种全卷积网络FCN(Fully-Convolutional Network),主要用于生成候选区域,也就是估计目标物体的位置和大小;另一个模块就是Fast R-CNN检测模型,使用RPN产生的候选区域进行分类与边框回归计算,并与RPN共享卷积层。可以简单理解Faster R-CNN是RPN和Fast R-CNN的结合,通过RPN代替选择性搜索来推荐候选区域,加快了运行速度。
在Faster R-CNN的基础上,又发展出Mask R-CNN,其在针对每个候选区域输出分类信息和定位信息的Faster R-CNN中再添加一个分支从而针对每个候选区域增加输出掩码(mask)信息以表示该区域内对象的掩码,也即由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN将二进制掩码与来自Faster R-CNN的分类和边界框组合,便产生了精确的图像分割。
Cascade R-CNN在Faster R-CNN基础上使用级联的检测模型,并在每个阶段采用递增的阈值,使得每个阶段都有足够数量的候选区域,且不会出现严重的过拟合现象。
Cascade Mask R-CNN是将Mask R-CNN与Cascade R-CNN结合,当前阶段会接收此阶段推荐的候选区域和上一个阶段回归得到的信息作为输入,用于计算新的输出信息,使检测效果进一步提升。
近年来,以ViT(Vision Transformer)来取代CNN进行图像特征提取得到越来越广泛的关注和应用。ViT是一种基于Transformer的图像处理算法,Transformer主要用于自然语言处理NLP(Natural Language Processing),其通过自注意力(self-attention)机制来对输入序列中的每个数据元素进行加权聚合,使得能够更好地提取数据特征。
ViT将Transformer用于处理图像分类问题的主要思路是将输入的图像像素块(patch)映射成一组向量序列,然后将这些向量作为Transformer的输入序列。为了能够捕捉到图像中的局部特征,ViT在输入图像之前通过块嵌入(patch embedding)操作将每个像素块映射成一个固定长度的向量表示。
除了块嵌入之外,ViT还引入了两个重要的模块:多头自注意力(multi-headself-attention)和前馈网络(feed-forwardnetwork)。多头自注意力允许在不同的位置和尺度上捕获不同的特征,而前馈网络则用于对特征进行加工和调整。
为克服ViT的计算复杂等缺点,又提出了Swin Transformer用于图像特征提取,其具有滑动窗口操作和分层设计。滑动窗口操作包括非重叠的局部窗口和重叠的交叉窗口。将注意力计算限制在一个窗口内既可以引入CNN卷积操作的定位性,又可以节省计算量。该算法仍然使用ViT中的patch思想。然而,与ViT中使用一个固定窗口(16×16像素)不同,Swin Transformer在第一个Transformer层中首先使用小的窗口,随后在较深的层中将这些合并为面积更大的patch。它将图像分割为4×4像素的patch,每个patch有3通道,总共48个特征维度,这些特征被线性转换为C维向量(96或192)。与ViT不同,Swin Transformer只在局部窗口内计算自注意力,减小了算法的复杂度,使得能够执行密集的识别任务。随后,输出通过一个合并层进行合并,将图像中2x2相邻patch组的向量连接起来。每次注意力窗口相对于上一层移动。例如,在第一层中,注意力仅限于这些区域的邻域,在下一层中,这些区域会发生移动(类似于步长卷积)。在第一层中落在不同窗口中且无法通信的patch,可以在第二层中进行通信。这些生成的patch由合并层合并。这个过程根据选择的层数重复进行。
当然,除了上面提到的深度学习检测模型之外,还存在其它许多检测模型。不过,大多数检测模型在对手写文档图像上的笔迹进行检测时,都假设图像上的笔迹是正常的,即在笔迹中不存在涂抹。
然而,在手写过程中,人们往往会发生错误,例如拼写错误、上下文不当的措辞、错误的数字或符号等。此外,写作过程中,作者的思想和观点可能会发展和变化,导致先前所写的内容变得不太有价值甚至是错误的。作者通常会涂抹这些错误或不需要的内容,并在旁边写下更正的内容。这些涂抹出现在各种手写文档中,例如信函、手稿和考卷上,而一旦被检测为正常字符就会产生谬误。例如,由于数学的复杂性和抽象性,涂抹在解答数学问题时更容易发生。被涂抹掉的文字、数字、符号很可能影响整个公式的意义和解析,会对公式检测造成严重干扰。图2示出某数学考试的部分答卷示例图像,从中可以发现涂抹频繁出现,而且类型繁多,不具备统一的特征。
可见,移除手写文档图像中的涂抹有助于精确检测该图像上有意义的文档内容。当然,在移除涂抹之前必须先检测涂抹,而上述深度学习检测模型在进行针对性的训练之后也可以用于检测涂抹。
当前已存在对手写文档图像中的涂抹进行检测并移除的方案。例如,BBChaudhuri和C Adak在其论文“An approach for detecting and cleaning of struck-out handwritten text”(Pattern Recognition,vol.61,pp.282-294,2017年1月,doi:https://doi.org/10.1016/j.patcog.2016.07.032)中提出使用混合模型和支持向量机SVM和径向基函数RBF(Radial Basis Function)分类器来区分涂抹和正常文本,进而清除所检测的涂抹。专利申请CN110400309A公开了一种涂抹移除方法,包括利用例如神经网络来确定目标图像中的涂抹痕迹信息,并且对确定的涂抹痕迹进行清除处理或者覆盖处理。专利申请CN112052852A记载了一种剔除涂抹字符的方法,其中为解决涂抹字符检测的问题准备了高低质量两个数据集,分别训练了两个具有识别差异的卷积循环神经网络CRNN(Convolutional Recurrent Neural Network)模型,将相同的检测结果作为输出值,且利用数据集间的差异来剔除涂抹字符。
当前已有的涂抹检测和移除方案存在检测精度不高和移除不准确的技术问题,其中检测精度不高可能导致将部分正常笔迹检测为涂抹笔迹和/或将涂抹笔迹检测为正常笔迹,而移除不准确可能导致在移除涂抹笔迹的过程中,将涂抹笔迹附近的正常笔迹一并移除。
为了消除或缓解上述移除不准确以及检测精度不高的技术问题,本公开的发明人想到在移除深度学习检测模型所检测的涂抹边界框内的涂抹时,考虑所述边界框内的笔迹和所述边界框之间的关系,以避免移除所述边界框内的正常笔迹(如果有的话)。
图3是根据本公开实施例的用于移除手写文档图像中涂抹的方法300的流程图。该方法包括以下步骤:使用深度学习检测模型来检测所述涂抹的边界框的步骤301;以及基于所述边界框内的笔迹和所述边界框之间的关系来移除所述涂抹的步骤302。图4在图2的部分答卷示例图像上进一步示出通过执行方法300的步骤301之后所得到的涂抹的边界框。如图4所示,各处涂抹已被矩形边界框紧密包围,边界框之外的笔迹为正常笔迹。
接下来,方法300及其各个实施例将结合图5至图9被进一步描述。可理解的是,虽然图7-9示出关于数学答卷图像的示例,但是本公开方案所适用的手写文档图像不限于数学答卷图像,而可以是涵盖任何有意义的手写文档图像。本公开的方案在此方面没有限制。另外,虽然图7-9中示出的涂抹的边界框是矩形框,但是本公开方案可采用的边界框也可以是适合于紧密包围涂抹的其它形状的框,例如圆形框、三角形框、不规则形状框等。本公开的方案在此方面没有限制。
为了发现目前检测效果最好的深度学习检测模型,本公开的发明人使用多种主流深度学习检测模型进行了检测涂抹。图5示出各深度学习检测模型进行涂抹检测的平均精度AP,其中可以看到能够获得最高平均精度的检测模型是Swin-Transformer+CascadeMask-RCNN检测模型,即,使用Swin Transformer进行特征提取的Cascade Mask-RCNN检测模型。因此,在一个实施例中,使用Swin-Transformer+Cascade Mask-RCNN检测模型作为方法300中的深度学习检测模型。然而,其它深度学习检测模型也可被用于方法300中。本公开的方案在此方面没有限制。
Swin-Transformer+Cascade Mask-RCNN检测模型的示例架构600在图6中被示出。在该示例架构600中,区域推荐网络RPN 602接收手写文档图像601作为输入,并输出代表多个区域推荐的多个候选框603(即,候选的涂抹的边界框);这些候选框603接着由Swin-Transformer层604进行特征提取;当前阶段提取的特征605和上一阶段回归得到的边界框607被输入边界回归和候选框调整精练部分606得到当前阶段的调整的候选框607,直到达到预定义的精度;将边界回归和候选框调整精练部分606最终输出的精炼的候选框608进行非极大值抑制的后处理609,去除其中冗余的候选框,最后输出涂抹的边界框610作为检测结果。
值得注意的是,上述示例架构600仅使用了Swin-Transformer+Cascade Mask-RCNN检测模型中输出的定位信息来检测涂抹的边界框。如上所述,Cascade Mask-RCNN可以看成是级联的Mask R-CNN检测模型,其中Mask R-CNN可针对每个推荐区域输出分类信息、定位信息和掩码信息。本公开的发明人通过实验认识到,根据本公开实施例的方法300可以在不使用所述分类信息和掩码信息的情况下使用Swin-Transformer+Cascade Mask-RCNN检测模型来检测涂抹的边界框,使得该模型的计算更简便,同时不会降低所述检测的精度。因此,在一个实施例中,所述Swin-Transformer+Cascade Mask-RCNN检测模型中输出的分类信息和掩码信息被舍弃。然而,本领域技术人员可以领会到,根据本公开方案所针对的具体手写文档类型和具体应用要求,所述分类信息和/或掩码信息也可以被使用,例如,分类信息可用于例如对涂抹的形状进行具体分类、掩码信息可用于例如截取图像上的涂抹笔迹等等。本公开的方案在此方面没有限制。
在检测到涂抹的边界框之后,可进行边界框内的涂抹移除操作。一般来说,所述边界框不包含未涂抹的笔迹(即正常笔迹),但在上述检测的步骤中可能存在个别边界框的检测偏差,使得部分未涂抹的笔迹被囊括到所述边界框中。图7是边界框包括部分正常笔迹的示例图像,其中文字“由图”的顶部笔迹位于该边界框之内。
本公开的发明人注意到,如果直接将边界框中的笔迹全部清除,则会伤害边界框内的正常笔迹(如果有的话),导致相关笔迹的识别错误。因此,本公开的发明人想到基于所述边界框内的笔迹和所述边界框之间的关系来移除所述涂抹,由此避免移除所述边界框内的正常笔迹(如果有的话)。这种关系可以是例如以下关系中的一项或多项:笔迹是否与边界框接触、笔迹是否靠近边界框的边缘、笔迹是否靠近边界框的中心、笔迹是否延伸出边界框等等。本领域技术人员可以根据本公开方案所针对的具体手写文档类型和具体应用要求,将涂抹的移除基于笔迹和边界框之间的各种适当关系。本公开的方案在此方面没有限制。
例如,针对如数学答卷之类的手写文档,本公开的发明人观察到绝大部分涂抹都具有连续的较长涂抹曲线,且都落在边界框的中心位置,而边界框内孤立的且与边界框接触的笔迹都是正常笔迹。因此,在一个实施例中,基于所述边界框内的笔迹和所述边界框之间的关系来移除所述涂抹包括:保留所述边界框内与所述边界框接触的孤立笔迹,并移除所述边界框内的其它笔迹。
在进一步的实施例中,方法300使用基于连通域的启发式算法来识别所述孤立笔迹。例如,可以将边界框内的笔迹二值化,然后采用连通域算法将笔迹进行聚类。
在进一步的实施例中,所述启发式算法将所述边界框内的笔迹划分到第一连通域、第二连通域和第三连通域中,并将所述第三连通域中的笔迹识别为所述孤立笔迹,其中所述第一连通域不接触所述边界框,所述第二连通域接触所述边界框且中心靠近所述边界框的中心,以及所述第三连通域接触所述边界框且中心远离所述边界框的中心。
图8示出移除边界框内的涂抹之前和之后的示例对比图像。从图8可以看出,虽然其中的边界框包含了部分正常笔迹(参见图8的左半边),但是由于方法300在移除时考虑了笔迹和边界框的关系,从而仅移除了该边界框中的涂抹,保留了延伸到该边界框内的正常笔迹(参见图8的右半边),从而保留了未被涂抹的有价值内容。具体而言,图8的与边界框接触的孤立的笔迹
本公开的发明人还认识到,为了训练各类深度学习检测模型,都会对通过原数据进行裁剪、缩放、填充、亮暗、对比度来增广用于训练的样本数据,但是这些增广对文字的效果有限,并不能有效地产生和原数据差异较大的有效样本数据。因此,在一个实施例中,对于方法300所使用的深度学习检测模型,本公开的发明人提出通过从所述手写文档图像内选取多个子图、以及在空白图像上拼接所述多个子图以形成用于训练所述深度学习检测模型的样本图像,由此来增广上述深度学习检测模型的训练数据。
在进一步的实施例中,所述多个子图各自通过在所述手写文档图像内随机选取一个矩形区域而被选取。例如,对于所述手写文档图像,随机选取一个坐标作为中心,随机选取一个长度和宽度。使用该中心横坐标和纵坐标以及所述长度和宽度这四个变量来定位该图像上的一个区域作为一个子图。
在进一步的实施例中,所述矩形区域的长宽比的范围是0.5到10之间。
在一个实施例中,其中所选取的子图的边缘不穿过所述手写文档图像上的笔迹和所述边界框,由此确保选取的子图内不会有部分的笔迹,也确保涂抹的边界框将完全位于选取的子图内或完全位于选取的子图之外。如果所选取的子图的边缘穿过所述手写文档图像上的笔迹和/或所述边界框,则可以放弃该子图,重新进行所述选取。
在一个实施例中,在所述空白图像上拼接所述多个子图包括对所述多个子图的每个子图执行以下操作:使该子图进行变形;以及在所述空白图像上的不同随机位置粘贴该变形的子图,直到所述粘贴未导致重叠的笔迹。也就是说,在所述空白图像上粘贴变形的子图,如果该粘贴导致该子图和所述空白图像上已粘贴的子图产生重叠的笔迹,则在所述空白图像上的不同随机位置重新粘贴该子图,否则接受该粘贴,这确保了不会因为笔迹重叠而在样本图像中产生新的类涂抹笔迹。
在进一步的实施例中,所述变形是指随机的缩放、拉伸和高斯模糊。
在进一步的实施例中,所述变形对于不包含所述边界框的子图还包括随机-5°至+5°的旋转。
图9示意性示出根据本公开实施例来形成样本图像的示例过程,其形成的样本图像和原图像差异较大,可用于有效地训练深度学习检测模型,从而可以为该检测模型的训练有效增广学习数据样本。将通过这些实施例增广的样本图像数据用于训练上述Swin-Transformer+Cascade Mask-RCNN检测模型,可进一步提升其检测精度(参见图5的最后一行)。
在一个实施例中,所述手写文档图像是手写数学答卷的图像。然而,本公开的方案适用于任何有意义的手写文档图像。本公开的方案在此方面没有限制。
图10是根据本公开实施例的装置1000的示意框图。该装置用于移除手写文档图像中的涂抹,并且包括:用于使用深度学习检测模型来检测所述涂抹的边界框的检测部件1001;以及用于基于所述边界框内的笔迹和所述边界框之间的关系来移除所述涂抹的移除部件1002。装置1000的各个实施例与上述方法的各个实施例相对应,因此不在此重复描述。
可以领会的是,本文所述的装置1000可以由各种部件来实现,使得实现上述实施例所述的一个或多个功能的装置1000不仅可以包括图10中所示的部件,还可以包括用于实现其一个或更多其它功能的其它部件。此外,装置1000可以包括被配置为执行两个或多个功能的单个部件,或者用于各自相应功能的分开部件。此外,这些部件可以在硬件、固件、软件或其任意组合中被实现。
应当理解,框图和/或流程图图示的框以及框图和/或者流程图图示中的框的组合可以通过计算机程序指令来实现。这些计算机程序指令可以被提供给通用计算机、专用计算机和/或其它可编程数据处理设备的处理器,使得经由所述计算机和/或者所述其它可编程的数据处理设备的处理器而被执行的所述指令创建用于实现框图和/或流程图的框中指定的功能/动作的部件。
还应理解,流程图的框中所示的功能/动作可能并不以图示中所示顺序的顺序来发生。例如,取决于所涉及的功能/动作,连续显示的两个框可能实际上基本同时被执行,或者这些框有时可能以相反的顺序被执行。尽管一些图可能包括通信路径上的箭头以示出通信的主要方向,但是应当理解,通信可能在与所描绘的箭头相反的方向上发生。
此外,本公开的方案可以采取存储器上的计算机程序的形式,所述存储器具有在介质中实施的计算机可用或计算机可读程序代码,以供指令执行系统使用或与指令执行系统结合使用。在本文档的上下文中,存储器可以是可包含、存储或适于传送程序以供指令执行系统、设备或装置使用或与之结合使用的任何介质。
因此,本公开还提供了包括处理器1101和存储器1102的设备1100,用于移除手写文档图像中的涂抹,其示意框图如图11所示。在设备1100中,存储器1102存储指令,所述指令在由处理器1101执行时使得设备1100执行上述用于移除手写文档图像中涂抹的方法。
本公开还提供了一种其上已存储指令的机器可读存储介质(未示出),所述指令在处理器上被执行时使得所述处理器执行上述用于移除手写文档图像中涂抹的方法。
虽然本说明书包含许多特定的实现细节,但这些细节不应被解释为对任何实现的范围或可能要求保护的内容的限制,而是对可能特定于具体实现的具体实施例的特征的描述。本说明书中在各个实施例的上下文中描述的某些特征也可以在单个实施例中被组合实现。相反,在单个实施例的上下文中描述的各种特征也可以单独地或以任何合适的子组合在多个实施例中被实现。此外,尽管特征在上文中可能被描述为在某些组合中起作用,甚至在最初被要求权利时也是如此,但是在某些情况下,来自所要求权利的组合的一个或多个特征可以从该组合中被删除,并且所要求权利的组合可以针对子组合或子组合的变体。
对本领域技术人员来说显而易见的是,随着技术的进步,本发明构思可以以各种方式来实现。给出上述实施例是为了描述而不是限制本公开,并且应当理解,在不偏离本公开的精神和范围的情况下,可以进行修改和变化,正如本领域技术人员容易领会的。这样的修改和变化被认为在本公开和所附权利要求的范围内。本公开的保护范围由随附的权利要求来限定。
- 用于去除文档图像中干扰信息的方法及相关产品
- 一种文档图像中手写内容的擦除优化方法和装置