物体位姿识别的方法、装置及计算机存储介质
文献发布时间:2023-06-19 09:24:30
技术领域
本发明涉及人工智能领域,特别涉及一种物体位姿识别的方法、装置及计算机存储介质。
背景技术
随着深度相机的普及以及3D视觉研究的发展,机械臂开始承担如智能分拣、柔性上下料等复杂的任务。这些工作离不开对随机堆叠场景内的物体进行准确的位姿估计,需要解决的难题包括物体遮挡严重、视觉传感器获得的数据有噪声、识别的物体种类多等。其中,位姿是一个相对的概念,指的是两个坐标系之间的位移和旋转变换,而两个坐标系分别表示以物体上初始位置以及旋转、平移后的位置建立的坐标系。目前一些面向位姿识别的深度学习网络可以有效解决随机堆叠场景里物体的位姿识别问题。而深度学习网络的训练通常采用真实物体场景数据训练以及仿真环境训练,通过真实物体场景的数据往往存在数据量采集不够导致深度学习网络识别准确率不高,而仿真环境模拟的数据与真实的场景往往存在差异,从而导致仿真训练的深度学习网络识别无法直接应用到真实场景的识别,位姿识别准确率不高。
发明内容
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提供了一种物体位姿识别的方法、装置和计算机存储介质,可以提升位姿识别的准确率。
本发明第一方面提供一种物体位姿识别的方法,包括如下步骤:
将若干采样点云信息输入到待训练的点云神经网络中进行训练,得到训练好的点云神经网络,其中每一所述采样点云信息由仿真点云信息通过随机偏移函数处理后得到,所述仿真点云信息由若干第一物体进行仿真处理后得到的;
将待测点云信息输入到训练好的所述点云神经网络中,得到所述待测点云信息中每个点的第一预测质心坐标;
将所有所述第一预测质心坐标进行聚类处理,得到多个第一点云集合,其中每个所述第一点云集合中的点均属于同一个所述第一物体;
获取每一所述第一点云集合的每个点的第一预测欧拉角;
将每一所述第一预测欧拉角以及对应的每一所述第一预测质心坐标进行位姿获取处理,得到每一所述第一物体的第一质心坐标以及第一欧拉角。
根据本发明的上述实施例,至少具有如下有益效果:仿真点云信息结合随机偏移函数进行处理,可以模拟不同相机及工作环境对同一三维模型进行采样得到的采样点云信息,此时,待测点云信息可以对应到其中一个采样点云信息,同时,通过仿真环境进行模拟相对于真实环境的数据模拟效率更高,从而可以快速获得更好的鲁棒性的点云神经网络,从而提升位姿识别的准确率。
根据本发明第一方面的一些实施例,所述随机偏移函数中偏移值通过标准正态分布函数得到,所述标准正态分布函数的期望值为0、标准差为1。
根据本发明第一方面的一些实施例,所述将所有所述第一预测质心坐标进行聚类处理,得到多个第一点云集合,其中每个所述第一点云集合中的点均属于同一个所述第一物体,包括如下步骤:
获取第二点云集合以及所述第二点云集合所在的最小包围球的第二半径,所述第二点云集合的个数与所有所述第一预测质心坐标的个数的比值等于预设的第二比值;
将所述第二半径输入质心特征分布函数,得到第一聚类带宽;
将MeanShift算法的带宽的值设置为所述第一聚类带宽的值;并通过所述MeanShift算法对所有所述第一预测质心坐标进行个体分割,得到多个第一点云集合。
通过质心特征分布函数,可以无需人工调参就可以实现聚类处理,提升第一物体的位姿识别的效率。
根据本发明第一方面的一些实施例,所述质心特征分布函数的获取包括如下步骤:
获取多个不同的第二物体的第二真实点云信息,并获取每一所述第二真实点云信息中各点的第二预测质心坐标;
对所有所述第二预测质心坐标进行多次MeanShift算法聚类处理,得到若干第三点云集合以及与每一所述第三点云集合对应第二聚类带宽,其中第二聚类带宽的值等于MeanShift算法聚类处理时的带宽的值;
获取每一所述第三点云集合的点的个数与所述第二真实点云信息的点的个数的第一比值、每一所述第三点云集合所在的最小包围球的第一半径;并将所述第一比值与所述第二比值进行匹配处理;
根据匹配结果获得多组与所述第二比值对应的所述第一半径以及所述第二聚类带宽;
将多组所述第一半径与所述第二聚类带宽进行数据拟合,得到所述质心特征分布函数。
通过利用第一物体与第二物体通过同一点云神经网络获得的第一预测质心坐标与第二预测质心坐标具有相同的分布特征的特点,可以通过在不同场景下的第二物体进行多次聚类处理,从而获得聚类效果最好时对应的质心特征分布函数。
根据本发明第一方面的一些实施例,所述将每一所述第一预测欧拉角以及对应的每一所述第一预测质心坐标进行位姿获取处理,得到每一所述第一物体的第一质心坐标以及第一欧拉角,包括如下步骤:
对每一所述第一点云集合中每个点分别进行可信度处理,得到更新后的所述第一点云集合中每个点的所述第一预测欧拉角以及所述第一预测质心坐标;
获取每个可信度处理后的所有所述第一预测质心坐标的第一均值,将所述第一均值设置为所述第一质心坐标;
获取每个可信度处理后的所有所述第一预测欧拉角的第二均值,将所述第二均值设置为所述第一欧拉角。
通过对每一第一点云集合进行可信度处理,可以剔除掉预测误差较大的点,从而可以提升第一物体位姿预测的准确度。
根据本发明第一方面的一些实施例,所述对每一所述第一点云集合中每个点分别进行可信度处理,得到更新后的所述第一点云集合中每个点的所述第一预测欧拉角以及所述第一预测质心坐标,包括如下步骤:
对所述第一点云集合中每个点所述第一预测欧拉角以及所述第一预测质心坐标进行向量转化处理,得到第一特征向量;
将所述第一特征向量通过多层感知机以及二分类softmax层处理,得到所述第一点云集合中每个点的正可信度值以及负可信度值;
将与预设可信度值不匹配的所述正可信度值对应的所述第一点云集合中的点剔除,得到更新后的所述第一点云集合中每个点的所述第一预测欧拉角以及所述第一预测质心坐标。
通过二分类的处理方式,可以简化可信度剔除的处理,提升第一物体位姿识别的处理效率。
根据本发明第一方面的一些实施例,所述将所述第一特征向量通过多层感知机以及二分类softmax层处理,得到所述第一点云集合中每个点的正可信度值以及负可信度值,包括如下步骤:
获取所述第一点云集合中每个点对应在仿真环境中的二分类标签值,并将所述二分类softmax层的交叉熵函数的样本标签的值设置为所述二分类标签值;
通过所述交叉熵函数获得所述第一点云集合中每个点的正可信度值以及负可信度值;
其中,所述二分类标签值获取包括如下步骤:
获取每一所述采样点云信息中每个点的第二预测欧拉角的旋转误差以及第二预测质心坐标的平移误差;
将所述平移误差和所述旋转误差分别与预设平移误差和预设旋转误差的进行比较,并将两个所述比较结果进行与操作后的值设置为所述二分类标签值。
通过引入仿真环境中获得第二预测质心坐标与实际的质心坐标的误差值以及第二预测欧拉角的误差值到交叉熵损失函数中,进一步提升对第一点云集合中每个点的位姿误差率判断的准确性。
根据本发明第一方面的一些实施例,所述物体位姿识别的方法还包括如下步骤:
获取每一所述第一物体的可见像素点的第一数量以及所述第一物体的所有像素点的第二数量;
将所述第一数量与所述第二数量的比值设置为所述第一物体的可见度;
根据所述可见度的值的大小设置抓取排序。
通过优先抓取可见度高的第一物体,可以有效提高抓取的成功率和效率。
本发明第二方面提供一种物体位姿识别的装置,所述物体位姿识别的装置包括:
图像采集模块,用于采集真实场景的堆叠图像并输出第一物体的待测点云信息;
神经网络训练模块,用于根据仿真点云信息进行点云神经网络训练,输出训练好的所述点云神经网络训练以及每个所述仿真点云信息中每个点对应的二分类标签;
聚类分割模块,用于将所述待测点云信息进行个体分割,得到若干第一点云集合;
位姿处理模块,用于将所述第一点云集合进行位姿处理,得到每一所述第一物体的第一质心坐标以及第一欧拉角。
由于第二方面的物体位姿识别的装置应用第一方面任一项的物体位姿识别的方法,因此具有本发明第一方面的所有有益效果。
根据本发明第三方面提供的一种计算机存储介质,包括存储有计算机可执行指令,所述计算机可执行指令用于执行第一方面任一项所述的物体位姿识别的方法。
由于第三方面的计算机存储介质可执行第一方面任一项的物体位姿识别的方法,因此具有本发明第一方面的所有有益效果。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明实施例的物体位姿识别的方法的主要步骤图;
图2是本发明实施例的物体位姿识别的方法的聚类处理的步骤图;
图3是本发明实施例的物体位姿识别的方法的质心特征分布函数获取的步骤图;
图4是本发明实施例的物体位姿识别的方法的位姿信息获取的步骤图;
图5是本发明实施例的物体位姿识别的方法的可信度处理的步骤图;
图6是本发明实施例的物体位姿识别的装置的结构示意图。
附图标记:
图像采集模块100、神经网络训练模块200、聚类分割模块300、位姿处理模块400。
具体实施方式
本发明的描述中,除非另有明确的限定,设置、安装、连接等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。此外,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
下面参照图1至图6描述本发明的物体位姿识别的方法、装置、系统及计算机存储介质。
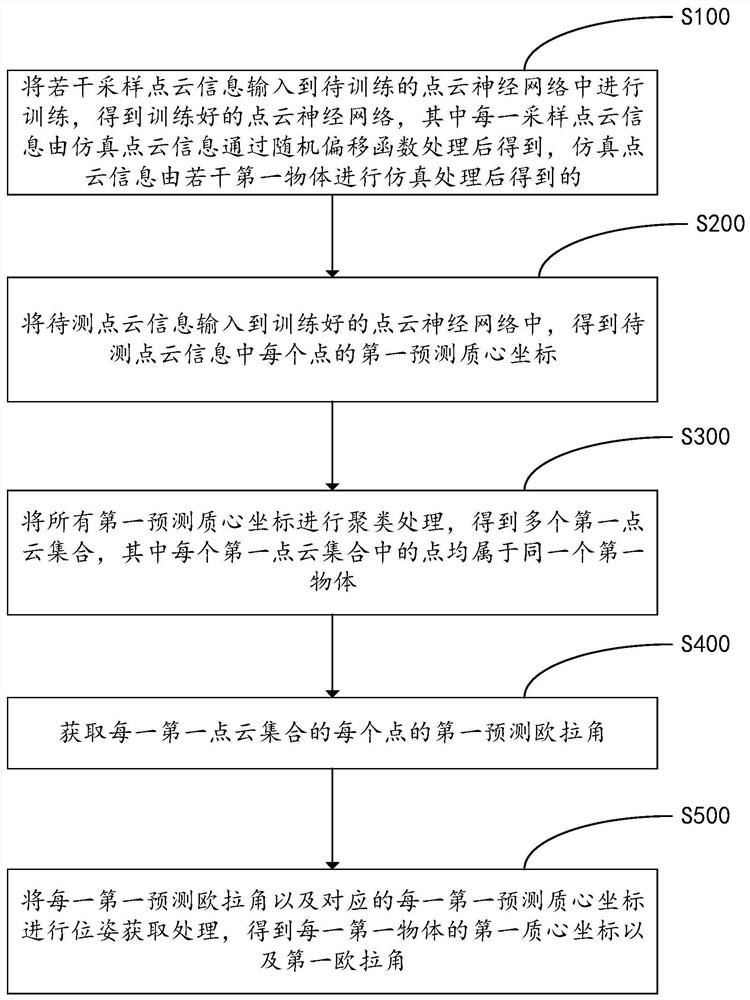
如图1所示,根据本发明第一方面实施例的一种物体位姿识别的方法,包括如下步骤:
步骤S100、将若干采样点云信息输入到待训练的点云神经网络中进行训练,得到训练好的点云神经网络,其中每一采样点云信息由仿真点云信息通过随机偏移函数处理后得到,仿真点云信息由若干第一物体进行仿真处理后得到的。
应理解的是,将仿真点云信息经过随机偏移函数处理后,可以得到同一个物体在不同精度相机和不同工作环境下的仿真情况,从而使得真实场景下的第一物体为仿真环境中的一种特例,以增强点云神经网络的鲁棒性。
步骤S200、将待测点云信息输入到训练好的点云神经网络中,得到待测点云信息中每个点的第一预测质心坐标。
应理解的是,待测点云信息为组成第一物体的若干坐标点的集合信息。
步骤S300、将所有第一预测质心坐标进行聚类处理,得到多个第一点云集合,其中每个第一点云集合中的点均属于同一个第一物体。
步骤S400、获取每一第一点云集合的每个点的第一预测欧拉角。
步骤S500、将每一第一预测欧拉角以及对应的每一第一预测质心坐标进行位姿获取处理,得到每一第一物体的第一质心坐标以及第一欧拉角。
因此,仿真点云信息结合随机偏移函数处理,可以模拟不同相机及工作环境对同一三维模型进行采样得到的采样点云信息,此时,待测点云信息可以对应到其中一个采样点云信息,同时,通过仿真环境进行模拟相对于真实环境的数据模拟效率更高,从而可以快速获得更好的鲁棒性的点云神经网络,从而提升位姿识别的准确率。
在本发明第一方面的一些实施例中,随机偏移函数中偏移值通过标准正态分布函数得到,标准正态分布函数的期望值为0、标准差为1。
应理解的是,假设仿真点云信息中每个点坐标表示{x
Δx
Δy
Δz
此时,随机偏移函数
在本发明第一方面的一些实施例中,如图2所示,步骤S300包括如下步骤:
步骤S310、获取第二点云集合以及第二点云集合所在的最小包围球的第二半径,第二点云集合的个数与所有第一预测质心坐标的个数的比值等于预设的第二比值。
应理解的是,第二点云集合为待测点云信息的子集。
步骤S320、将第二半径输入质心特征分布函数,得到第一聚类带宽。
步骤S330、将MeanShift算法的带宽的值设置为第一聚类带宽的值;并通过MeanShift算法对所有第一预测质心坐标进行个体分割,得到多个第一点云集合。
通过质心特征分布函数,可以无需人工调参就可以实现聚类处理,提升第一物体的位姿识别的效率。
在本发明第一方面的一些实施例中,如图3所示,质心特征分布函数的获取包括如下步骤:
步骤S321、获取多个不同的第二物体的第二真实点云信息,并获取每一第二真实点云信息中各点的第二预测质心坐标。
步骤S322、对所有第二预测质心坐标进行多次MeanShift算法聚类处理,得到若干第三点云集合以及与每一第三点云集合对应第二聚类带宽,其中第二聚类带宽的值等于MeanShift算法聚类处理时的带宽的值。
应理解的是,每一个第三点云集合表示一次MeanShift算法聚类处理得到的总数据集。
步骤S323、获取每一第三点云集合的点的个数与第二真实点云信息的点的个数的第一比值、每一第三点云集合所在的最小包围球的第一半径;并将第一比值与第二比值进行匹配处理。
应理解的是,在一些实施例中,第二比值设置为80%。需说明的是,MeanShift算法的带宽的选择与数据分布特性密切相关,当数据分布密度大时采用小带宽,当数据分布密度小时采用小带宽。因此,当通过MeanShift算法可以得到多个个体后,每个个体的第二预测质心坐标的个数可以映射第二预测质心坐标的分布情况。而每个个体的第二预测质心坐标存在相似的数据分布特性,因此可以通过第一比值可以衡量所有第二预测质心坐标的分布特征。
步骤S324、根据匹配结果获得多组与第二比值对应的第一半径以及第二聚类带宽。
步骤S325、将多组第一半径与第二聚类带宽进行数据拟合,得到质心特征分布函数。
应理解的是,质心特征分布函数通过分析若干个具有大小、形状差异的物体进行聚类分割后的效果与真实效果的关系获得。
因此,通过利用第一物体与第二物体通过同一点云神经网络获得的第一预测质心坐标与第二预测质心坐标具有相同的分布特征的特点,可以通过在不同场景下的第二物体进行多次聚类处理,从而获得聚类效果最好时对应的质心特征分布函数。
在本发明第一方面的一些实施例中,如图4所示,步骤S500包括如下步骤:
步骤S510、对第一点云集合中每个点分别进行可信度处理,得到更新后的第一点云集合中每个点的第一预测欧拉角以及第一预测质心坐标。
步骤S520、获取每个可信度处理后的所有第一预测质心坐标的第一均值,将第一均值设置为第一质心坐标。
步骤S530、获取每个可信度处理后的所有第一预测欧拉角的第二均值,将第二均值设置为第一欧拉角。
通过对每一第一点云集合进行可信度处理,可以剔除掉预测误差较大的点,从而可以提升第一物体位姿预测的准确度。
在本发明第一方面的一些实施例中,如图5所示,步骤S510包括如下步骤:
步骤S511、对第一点云集合中每个点第一预测欧拉角以及第一预测质心坐标进行向量转化处理,得到第一特征向量。
步骤S512、将第一特征向量通过多层感知机以及二分类softmax层处理,得到第一点云集合中每个点的正可信度值以及负可信度值。
需说明的是,正可信度值以及负可信度值之和为1,其中正可信度值对应平移误差小于预设的平移误差以及旋转误差小于预设的旋转误差值时的概率。
步骤S513、将与预设可信度值不匹配的正可信度值对应的第一点云集合中的点剔除,得到更新后的第一点云集合中每个点的第一预测欧拉角以及第一预测质心坐标。
应理解的是,正可信度值越大表示第一预测欧拉角以及第一预测质心坐标越接近第一欧拉角以及第一质心坐标。预设可信度值可以根据实际情况进行设定。
通过二分类的处理方式,可以简化可信度剔除的处理,提升第一物体位姿识别的处理效率。
根据本发明第一方面的一些实施例,步骤S512包括如下步骤:
获取第一点云集合中每个点的对应在仿真环境中的二分类标签值,并将二分类softmax层的交叉熵函数的样本标签的值设置为二分类标签值。
通过交叉熵函数获得第一点云集合中每个点的正可信度值以及负可信度值。
其中,二分类标签值获取,包括如下步骤:
获取每一采样点云信息中每个点的第二预测欧拉角的旋转误差以及第二预测质心坐标的平移误差。
应理解的是,在仿真环境中,每一采样点云信息对应的三维模型的真实位姿信息是可知的,因此,可以通过将每一个第二预测质心坐标和第二预测欧拉角分别与真实位姿信息中的第二质心坐标和第二欧拉角进行距离计算得到平移误差以及旋转误差。
将平移误差和旋转误差分别与预设平移误差和预设旋转误差的进行比较,并将两个比较结果进行与操作后的值设置为二分类标签值。
应理解的是,在一些时候实施例中,假设对于每个第一物体仿真环境中均由n个坐标点表示,每个坐标点平移误差为L
此时,两个比较结果进行与操作后的值为
通过引入仿真环境中获得第二预测质心坐标与实际的质心坐标的误差值以及第二预测欧拉角的误差值到交叉熵损失函数中,进一步提升对第一点云集合中每个点的位姿误差率判断的准确性。
在本发明第一方面的一些实施例,物体位姿识别的方法还包括如下步骤:
获取每一第一物体的可见像素点的第一数量以及第一物体的所有像素点的第二数量。
应理解的是,第一物体的所有像素点可以通过仿真环境中对应的三维模型获取。第一物体的可见像素点通过摄像头等视频采集设备获取。
将第一数量与第二数量的比值设置为第一物体的可见度。
根据可见度的值的大小设置抓取排序。
通过优先抓取可见度高的第一物体,可以有效提高抓取的成功率和效率。
在本发明第二方面提供的一种物体位姿识别的装置中,如图6所示,物体位姿识别的装置包括:
图像采集模块100,用于采集真实场景的堆叠图像并输出第一物体的待测点云信息;
神经网络训练模块200,用于根据仿真点云信息进行点云神经网络训练,输出训练好的点云神经网络训练以及每个所述仿真点云信息中每个点对应的二分类标签;
聚类分割模块300,用于将待测点云信息进行个体分割,得到若干第一点云集合;
位姿处理模块400,用于将第一点云集合进行位姿处理,每一第一物体的第一质心坐标以及第一欧拉角。
由于第二方面的物体位姿识别的装置应用第一方面任一项的物体位姿识别的方法,因此具有本发明第一方面的所有有益效果。
应理解的是,上文中装置可以被实施为软件、固件、硬件及其适当的组合。某些物理组件或所有物理组件可以被实施为由处理器,如中央处理器、数字信号处理器或微处理器执行的软件,或者被实施为硬件,或者被实施为集成电路,如专用集成电路。
根据本发明第三方面提供的一种计算机存储介质,包括存储有计算机可执行指令,计算机可执行指令用于执行第一方面任一项的物体位姿识别的方法。
由于第三方面的计算机存储介质执行第一方面任一项的物体位姿识别的方法,因此具有本发明第一方面的所有有益效果。
应理解的是,术语计算机存储介质包括在用于存储信息(诸如计算机可读指令、数据结构、程序模块或其他数据)的任何方法或技术中实施的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于RAM、ROM、EEPROM、闪存或其他存储器技术、CD-ROM、数字多功能盘(DVD)或其他光盘存储、磁盒、磁带、磁盘存储或其他磁存储装置、或者可以用于存储期望的信息并且可以被计算机访问的任何其他的介质。
下面参考图1和图6以一个具体的实施例详细描述根据本发明实施例应用真实物体位姿。值得理解的是,下述描述仅是示例性说明,而不是对发明的具体限制。
如图1步骤S100所示,神经网络训练模块200将若干采样点云信息输入到待训练点云神经网络中进行训练,得到训练好的点云神经网络,其中每一采样点云信息由仿真点云信息通过随机偏移函数处理后得到,仿真点云信息由若干第一物体进行仿真处理后得到的。
具体的,在仿真环境中,通过物理引擎Bullet设置容纳堆叠物体的物料框,然后调用待抓取物体的Mesh文件,往物料框内自由落体扔一个第一物体,记录该第一物体的位姿和类别信息后删除场景,每次增加一个第一物体重复以上自由落体的堆叠过程,直到所扔个数达到最大堆叠个数。渲染引擎根据每个堆叠场景的物体位姿信息,调用物体的Mesh文件在渲染仿真环境中恢复堆叠场景,利用仿真相机获得该场景的视角点云。此时,可以获得未进行随机函数处理后的仿真点云信息。进一步,将该仿真点云信息输入待训练的点云神经网络中进行训练,并将仿真点云信息进行多次随机偏移函数后得到的采样点云信息输入到待训练的点云神经网络中进行训练。
具体的,随机偏移函数中偏移值通过标准正态分布函数RandomStandardNormal()得到,标准正态分布函数的期望值为0、标准差为1。
假设仿真点云信息中每个点的坐标表示{x
Δx
Δy
Δz
则随机偏移函数
此时,可以获取每一采样点云信息的每个点的第二预测质心坐标、第二预测欧拉角以及每一采样点云信息的第二质心坐标、第二欧拉角。
进一步,神经网络训练模块200通过如下步骤获得采样点云信息中每个点对应的二分类标签。
获取每一采样点云信息中每个点的第二预测欧拉角的旋转误差以及第二预测质心坐标的平移误差。
将平移误差和旋转误差分别与预设平移误差和预设旋转误差的进行比较,并将两个比较结果进行与操作后的值设置为二分类标签值。
具体的,假设对于每个第一物体仿真环境中均由n个坐标点表示,每个坐标点平移误差为L
此时,两个比较结果进行与操作后的值为
进一步,如步骤S200所示,图像采集模块100将待测点云信息输入到点云神经网络中,得到待测点云信息中每个点的第一预测质心坐标。
进一步,如步骤S300所示,聚类分割模块300将所有第一预测质心坐标进行聚类处理,得到多个第一点云集合,其中每个第一点云集合中的点均属于同一个第一物体。
具体的,如图2所示,如步骤S310,聚类分割模块300获取第二点云集合以及第二点云集合所在的最小包围球的第二半径,第二点云集合的个数与所有第一预测质心坐标的个数的比值等于预设的第二比值。
如步骤S320,聚类分割模块300将第二半径输入质心特征分布函数,得到第一聚类带宽。
具体的,如图3所示,聚类分割模块300通过如下步骤处理得到质心特征分布函数。
如步骤S321,获取多个不同的第二物体的第二真实点云信息,并获取每一第二真实点云信息中各点的第二预测质心坐标。
如步骤S322,对所有第二预测质心坐标进行多次MeanShift算法聚类处理,得到若干第三点云集合以及与每一第三点云集合对应第二聚类带宽,其中第二聚类带宽的值等于MeanShift算法聚类处理时的带宽的值。
如步骤S323,获取每一第三点云集合的点的个数与第二真实点云信息的点的个数的第一比值、每一第三点云集合所在的最小包围球的第一半径;并将第一比值与第二比值进行匹配处理。
具体的,第二比值设置为80%。
如步骤S324,根据匹配结果获得多组与第二比值对应的第一半径以及第二聚类带宽。
如步骤S325,将多组第一半径与第二聚类带宽进行数据拟合,得到质心特征分布函数。
进一步,如步骤S330,聚类分割模块300将MeanShift算法的带宽的值设置为第一聚类带宽的值;并通过MeanShift算法对所有第一预测质心坐标进行个体分割,得到多个第一点云集合。
进一步,如步骤S400所示,位姿处理模块500获取每一第一点云集合的每个点的第一预测欧拉角。
进一步,如图4中步骤S500所示,位姿处理模块500将每一第一点云集合的每个点的第一预测欧拉角以及第一预测质心坐标进行位姿获取处理,得到每一第一物体的第一质心坐标以及第一欧拉角。
具体的,如图5所示,步骤S510所示可信度处理包括如下步骤:
步骤S511、对第一点云集合中每个点第一预测欧拉角以及第一预测质心坐标进行向量转化处理,得到第一特征向量。
步骤S512、将第一特征向量通过多层感知机以及二分类softmax层处理,得到第一点云集合中每个点的正可信度值以及负可信度值。
具体的,位姿处理模块500获取第一点云集合中每个点的对应在仿真环境中的二分类标签值,并将二分类softmax层的交叉熵函数的样本标签的值设置为二分类标签值。则此时,交叉熵函数的样本标签的值为Label
进一步,位姿处理模块500通过交叉熵函数获得第一点云集合中每个点的正可信度值以及负可信度值。
此时,第一点云集合中每个点的均有正可信度值以及负可信度值。
进一步,如步骤S513所示,位姿处理模块500将与预设可信度值不匹配的正可信度值对应的第一点云集合中的点剔除,得到更新后的第一点云集合中每个点的第一预测欧拉角以及第一预测质心坐标。
进一步,如图4中步骤S520所示,位姿处理模块500获取每个可信度处理后的所有第一预测质心坐标的第一均值,将第一均值设置为第一质心坐标。
进一步,如步骤S530所示,位姿处理模块500获取每个可信度处理后的所有第一预测欧拉角的第二均值,将第二均值设置为第一欧拉角。
进一步,位姿处理模块500获取每一第一物体的可见像素点的第一数量以及第一物体的所有像素点的第二数量。
进一步,位姿处理模块500将第一数量与第二数量的比值设置为第一物体的可见度。
进一步,位姿处理模块500根据可见度的值的大小设置抓取排序。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 物体位姿识别的方法、装置及计算机存储介质
- 物体位姿识别方法及装置、视觉处理设备和可读存储介质