一种基于超簇加权的集成聚类方法
文献发布时间:2023-06-19 09:33:52
技术领域
本发明涉及数据挖掘与模式识别技术领域,具体涉及一种基于超簇加权的 集成聚类方法。
背景技术
集成聚类通过对基聚类成员实施组合策略以得到更好的结果,现有的集成 聚类研究主要集中在两个方面:一是如何生成高质量的基聚类集合。二是如何 设计一致性函数得到集成结果。其中,生成高质量基聚类集合的方法主要有以 下两种,一种是使用不同的聚类算法或同一聚类算法在不同参数下生成的聚类 结果,另一种是对同一样本集进行非等值变形后使用同一聚类算法处理,非等 值变形包括对样本集采样、投影等。一致性函数指使用组合策略将基聚类有效 的组合起来,主要方法有共协矩阵、图分割、信息论等。
现有的集成聚类算法有K-means算法、谱聚类算法,密度聚类算法等, K-means算法实现简单,计算复杂度不高,但对于结构复杂的样本集,尤其是 对于边界不易区分、非球形分布以及高维数据来说,K-means不能产生较好的 聚类结果,而在大规模样本集上使用谱聚类,密度聚类等方法时,算法的时间 和空间复杂度显著提升,导致其计算效率较低,极大的限制了其应用。另外, 大多数集成聚类算法忽视了基聚类成员多样性的不同,平等地对待每个基聚类, 也降低了聚类效果。
鉴于现有的集成聚类方法具有上述运算效率低和聚类效果差的缺陷,无法 满足使用需求。
发明内容
本发明要解决的技术问题是提供一种基于超簇加权的集成聚类方法,能够 有效提升运算效率和聚类效果。
为了解决上述技术问题,本发明提供的技术方案如下:
一种基于超簇加权的集成聚类方法,包括以下步骤:
1)利用基于地标点表示的谱聚类方法对样本集进行聚类生成基聚类集合; 所述基聚类集合由多个基聚类成员集合构成,每个基聚类成员包括多个类簇, 每个类簇中包括样本集中的多个样本点;
2)对基聚类集合中的基聚类成员进行处理得到超簇集合,并计算出每个基 聚类成员的权重,以及根据超簇集合和计算出的权重计算出共协矩阵;
3)采用层次聚类方法对所述共协矩阵进行聚类得到聚类结果。
在其中一个实施方式中,所述步骤1)中利用基于地标点表示的谱聚类方 法对样本集进行聚类生成基聚类集合的方法包括以下步骤:
A1)从样本集中随机选出P’个候选点,对P’个候选点使用K-means算法 得出P个地标点;
A2)对P个地标点使用自适应谱聚类算法进行第一次聚类得到多个地标点 簇,每个地标点簇中包括多个地标点;
A3)将样本集中的每个样本点分别映射到与该样本点距离最近的地标点 上,以使得样本点划归到与该样本点距离最近的地标点所在的地标点簇中;
A4)重复步骤A2)-A3),直至完成M次聚类,得到M个基聚类成员,由多个 基聚类成员构成所述基聚类集合。
在其中一个实施方式中,所述步骤A3)中,将样本集中的每个样本点分别 映射到与该样本点距离最近的地标点上的方法为:先计算样本点与每个地标点 簇的中心点的距离,并根据计算结果选择与样本点距离最近的地标点簇作为最 近邻簇,再计算样本点与最近邻簇中各个地标点的距离,然后选择出最近邻簇 中与样本点距离最近的地标点,并将样本点映射到最近邻簇中与该样本点距离 最近的地标点上。
在其中一个实施方式中,所述步骤2)中对基聚类集合中的基聚类成员进 行处理得到超簇集合的方法为:先将所有基聚类成员进行相交生成相交簇集合, 相交簇集合包括多个相交簇,再对相交簇集合中的相交簇进行碎片化整理后得 到超簇集合。
在其中一个实施方式中,对相交簇集合中的相交簇进行碎片化整理的方法 为:
判断相交簇中样本点的数目是否不大于设定阈值,若判断为是,则表示该 相交簇为碎片对象,然后对碎片对象进行碎片化整理,否则,不做处理;
对碎片对象进行碎片化整理的方式为:计算相交簇集合中的相交簇之间的 相似度,然后将碎片对象合并到与该碎片对象最相似的相交簇中。
在其中一个实施方式中,定义基聚类集合为Π={π
所述步骤2)中计算每个基聚类成员的权重W(π
B1)利用以下公式计算出类簇C
其中,
B2)利用以下公式计算获得平均熵E(π
B3)利用以下公式计算出基聚类成员π
其中,a=min{E(π
在其中一个实施方式中,定义超簇集合为
其中,
本发明具有以下有益效果:本发明的基于超簇加权的集成聚类方法,采用 基于地标点表示的谱聚类方法对样本集进行聚类生成基聚类集合,对基聚类成 员赋予权重并以超簇为操作单元来计算共协矩阵,有效降低了运算复杂度、提 升了运算效率和聚类效果。
附图说明
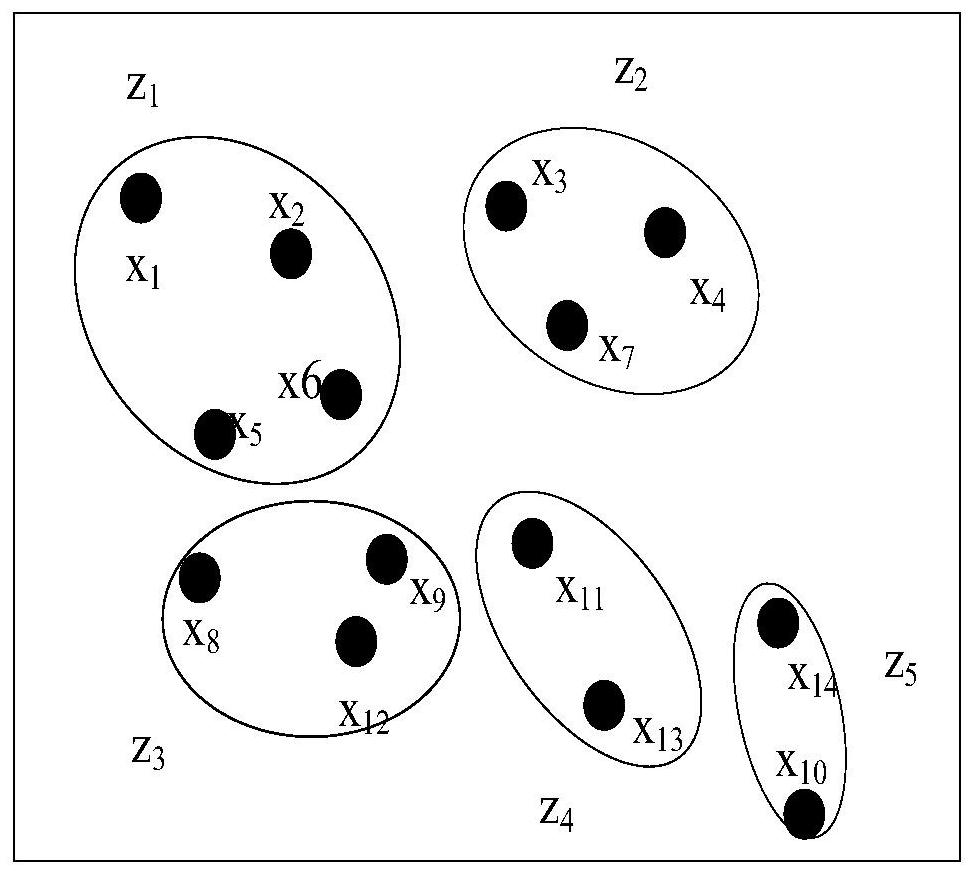
图1为本发明的基于超簇加权的集成聚类方法中生成超簇集合的示意图;
图2为本发明的集成聚类方法中生成相交簇集合的示意图;
图3为本发明的集成聚类方法中选取地标点的示意图;
图4为本发明的集成聚类方法中寻找样本点的最近邻地标点的示意图;
图5为本发明的集成聚类方法在人造样本集上的聚类表现示意图;
图6为不同集成聚类方法在不同M值下的NMI值的示意图;
图7为不同集成聚类方法在不同M值下的ARI值的示意图;
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人 员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
定义样本集为X={x
本实施例公开了一种基于超簇加权的集成聚类方法,包括以下步骤:
1)利用基于地标点表示的谱聚类方法对样本集X进行聚类生成基聚类集 合Π={π
其中,Π={π
2)对基聚类集合Π中的基聚类成员π
3)采用层次聚类方法对共协矩阵WECA进行聚类得到聚类结果。
在其中一个实施方式中,步骤1)中利用基于地标点表示的谱聚类方法对 样本集进行聚类生成基聚类集合的方法包括以下步骤:
A1)如图3中(a)、(b)、(c)所示,从样本集X中随机选出P’个候选点, 对P’个候选点使用K-means算法得出P个地标点;
A2)如图4中(a)、(b)所示,对P个地标点使用自适应谱聚类算法(SSC) 进行第一次聚类得到多个地标点簇,每个地标点簇中包括多个地标点;
A3)将样本集X中的每个样本点分别映射到与该样本点距离最近的地标 点上,以使得样本点划归到与该样本点距离最近的地标点所在的地标点簇中;
A4)重复步骤A2)-A3),直至完成M次聚类,得到M个基聚类成员,由多个 基聚类成员构成所述基聚类集合Π={π
在其中一个实施方式中,如图4中(a)、(b)、(c)、(d)、(e)、(f)所示, 步骤A3)中,将样本集中的每个样本点分别映射到与该样本点距离最近的地标 点上的方法为:先计算样本点x
上述基于地标点表示的谱聚类方法中,是采用随机与K-means结合的方法 选取地标点,避免直接采用随机方式或直接采用K-means方法获取地标点,大 大降低了算法的时间和空间复杂度,提升了谱聚类算法的扩展性。
在其中一个实施方式中,步骤2)中对基聚类集合中的基聚类成员进行处 理得到超簇集合的方法为:先将所有基聚类成员进行相交生成相交簇集合IO, 相交簇集合IO包括多个相交簇,再对相交簇集合IO中的相交簇进行碎片化整 理后得到超簇集合。
其中,相交簇为基聚类集合中,划分到同一类簇的样本点的集合。生成相 交簇的方式为现有技术中的常规方式,相交簇集合IO是多个相交簇的集合,相 交簇集合IO中两两相交簇互不相交,且相交簇中样本点的集合即为样本集中的 所有样本点的集合。例如,若
例如,若基聚类集合Π={π
在其中一个实施方式中,对相交簇集合中的相交簇进行碎片化整理的方法 为:
判断相交簇中样本点的数目是否小于或等于设定阈值,若判断为是,则表 示该相交簇为碎片对象,然后对碎片对象进行碎片化整理,否则,不做处理;
对碎片对象进行碎片化整理的方式为:计算相交簇集合中的相交簇之间的 相似度,然后将碎片对象合并到与该碎片对象最相似的相交簇中。
例如,若设定阈值为λ,λ>0,相交簇集合
在其中一个实施方式中,步骤2)中计算每个基聚类成员的权重W(π
B1)利用以下公式计算出类簇C
其中,
B2)利用以下公式计算获得平均熵E(π
例如,若基聚类集合Π={π
B3)利用以下公式计算出基聚类成员π
其中,a=min{E(π
通过上述权重的计算方式,能够依据基聚类成员的不确定性对其赋予权值, 基聚类成员的不确定性越高,表示该基聚类成员与其他基聚类成员的差别越大, 则对该基聚类赋予更高的权重,该加权方式能够有效降低特征间单位和尺度差 异的影响。
在其中一个实施方式中,定义超簇集合为
其中,
上述过程,以超簇为操作单元进行共协矩阵的计算,避免了传统算法中以 以样本或相交簇为操作单元计算共协矩阵带来的较大的计算负担,传统算法中, 在得到基聚类集合后,大多数集成算法是通过计算两两样本出现在同一个类簇 中的次数,得到基于样本的共协矩阵,随着样本数的增加,算法的时间和空间 复杂度显著增加,而直接以相交簇为操作单元计算共协矩阵时,共协矩阵即表 示两个相交簇在基聚类中出现在同一类簇中的概率,当基聚类的数目较多时, 算法的复杂度依旧很高,而本实施例的上述方式以超簇为操作单元进行共协矩 阵的计算,则有效降低了算法复杂度,提升了运算速度。
为验证本发明的有效性和优良性能,从人工样本集和真实样本集两个方面 对上述所提实施例进行验证,本实施例实验平台为Intel Core i7-8565U CPU@1.80GHz1.99GHz,Windows10,Matlab2019a等。
一、基于人造样本集的验证
下述实验是在表1所示的4组人造样本集上进行实验。
表1人造样本集
其中,样本集Smile2由两个团状簇,一个环状簇和一个流行簇组成,样本 集2d-4c-2由4个团状簇组成,样本集dartboard1由4个环状簇组成,样本集 Banana由两个流行簇组成。概率轨迹累积(PTA,Probability Trajectory Accumulation)算法是基于相交簇的集成聚类算法,将本申请的上述基于超簇加 权的集成聚类方法记为ECWSC算法。本节使用PTA算法与ECWSC算法进行对比。
为了保证实验的公平性,PTA算法与ECWSC算法的集成规模M均设置为10, 均采用不同的形状来区分聚类的类别。其中,样本集Smile2、2d-4c-2和Banana 地标点的数目设置为300,Dartboard1地标点的数目设置为600。而实验结果 表明,PTA算法不能得到正确的聚类结果。而ECWSC算法将Smile2、2d-4c-2、 dartboard1聚类为4类,将Banana聚类为两类,得到了正确的聚类结果,如 图5所示。
二、基于真实样本集的验证
下述实验是在表2所示的7组真实样本集上进行实验。7组真实样本集分 别是Semeion、Landsat、Image Segmentation(IS)、Isolet、Pen Digit(PD)、Usps和Letters。
表2真实样本集
实验将ECWSC算法在表2中的7个真实样本集上,与6种实验算法进行对 比,对比实验算法分别为概率轨迹累积(PTA,Probability Trajectory Accumulation)、概率轨迹图划分(PTGP,Probability Trajectory Based Graph Partitioning)、局部加权证据累积(LWEA,Locally Weighted Evidence Accumulation)、局部加权图划分(LWGP,LocallyWeighted Graph Partitioning)、传播聚类相似性(ECPCS-HC,Propagating Cluster-WiseSimilarities,)、证据累积聚类(EAC,Evidence Accumulation Clustering)。
实验采用标准化互信息(NMI)以及调整兰德系数(ARI)两个指标对聚类结果 进行评价。NMI是从信息论的角度评估两个类之间的相似性,取值范围为[0,1], ARI是衡量两个数据分布的吻合程度,取值范围为[-1,1]。二者的结果均为越 接近1的效果越好。
为保证实验的公平性,在使用基于地标点表示的谱聚类方法生成基聚类成 员时,地标点的个数P均设置为1000,6个对比实验的基聚类生成方法均为随 机K值生成。为减少参数的设置,随机候选点的数目P’=10P,将碎片对象的 阈值λ设置为5。集成规模M=20,实验结果均为运行20次得到的平均值和标准 方差。
实验结果如表3所示,每个样本集对应效果最好的两个算法的数据均已加 粗显示,当算法的运行结果超出内存时,值使用N/A标记。
表3不同算法在样本集上的表现(M=20)
从实验结果可以可知,大部分情况下,ECWSC算法的标准方差要小于其他 实验效果较好的对比算法,这表明使用基于超簇加权的集成聚类算法的稳定性 相比于其他的算法有一定的优势。例如,真实样本集Semeion中ESWSC算法得 到的NMI中平均值为64.73%,标准方差为0.64,该标准方差要小于其他6种对 比实验。
此外,当LWEA和LWGP算法在Letters样本集上运行超出内存时,ECWSC 算法仍可以运行出较好的结果,表明ECWSC算法在时间和空间上占据了一定的 优势。
从实验数据可知,相比其他算法,ECWSC算法的NMI和ARI均有显著提升, 提升最为显著的是Usps样本集,其NMI值提高了24.25,ARI值提升了24.14。
为进一步研究集成规模M与聚类结果的关系,本节选取了4个真实样本集, 分别是Semeion、IS、Isolet和PD样本集进行实验。为了降低实验结果的偶然 性,所有的实验均为运行20次求的NMI、ARI的平均值。图6和图7中的横坐 标均表示集成规模的变化,集成规模M的值由10增长为50,步长设置为10。 图6中的纵坐标表示NMI的值随M的变化,图7中的纵坐标表示ARI的值随M 的变化,其中‘*’表示基于超簇加权的集成聚类方法(ECWSC算法)的集成聚 类结果。
从图6和图7的实验结果可见,对于同一个M,无论是从NMI或是ARI的 比较上,相对于几个对比实验的表现,ECWSC算法都具有较大的优势。
综上所述,本实施例的基于超簇加权的集成聚类方法,采用基于地标点表 示的谱聚类方法对样本集进行聚类生成基聚类集合,有效降低了计算复杂度、 提升了聚类效果和聚类速度;对基聚类成员赋予权重并以超簇为操作单元来计 算共协矩阵,充分考虑了每个基聚类成员稳定性的不同对聚类结果的影响,提 升了聚类效果,同时以超簇为操作单元来计算共协矩阵,也大大减少了运算量, 提升了计算速度;整体运算效率和聚类效果都得到了有效提升。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计 算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结 合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包 含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、 CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品 的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/ 或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或 方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式 处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机 或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流 程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备 以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的 指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流 程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使 得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处 理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个 流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的 保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或 变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 一种基于超簇加权的集成聚类方法
- 一种簇特征加权的模糊紧致散布聚类方法