一种基于PCA-Transformer的设备剩余使用寿命预测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种设备剩余使用寿命预测方法,具体地,涉及一种基于主成分分析(PCA)和Transformer模型的设备剩余使用寿命预测方法。
背景技术
过去的几十年里,在人工智能的帮助下,许多工业领域取得了巨大的进步。包括基于状态的维修(Condition-BasedMaintenance,CBM)和预测性维修(PredictiveMaintenance,PM)在内的预测与健康管理(Prognostics and Health Management,PHM)作为工业智能的典型代表,在各个领域得到了广泛的应用,并引起了广泛的关注。特别是,对于停机时间和维护成本极其昂贵的相关安全组件或系统,例如航空航天设备和大型工业设备,十分有效。由于PHM是在系统/设备发生故障之前实施的,因此系统崩溃造成的损失可以显著减少,系统的可靠性可以提高。剩余使用寿命(Remaining Useful Life,RUL)预测任务,是PHM不可或缺的组成部分,它对产品的回收和再利用具有重要影响,有助于降低能耗和保护环境。通常,根据利用运行环境、实时风险或剩余使用寿命(RUL)等历史轨迹数据评估系统的状态。然而,在处理极其复杂的数据时,传统的预测算法,如基于模型的方法无法达到理想的结果。
近年来,深度学习已被证明是一种很有前途的方法,可以处理高度非线性和时序数据。卷积神经网络(Convolutional Neural Network,CNN)具有很强的学习能力,可以很好的提取数据的局部空间特征。但由于其特定时间步的感受野受限于卷积和的大小和层数,即捕获远距离信息的能力有限,导致CNN模型单独应用于RUL预测任务的测试效果并不理想。
传统的循环神经网络(Recurrent Neural Network,RNN)是一种对处理时间序列数据具有独特优势的网络,但因存在潜在的梯度消失或梯度爆炸可能,使得其无法获取时间序列的长期依赖。长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)基于RNN演变而来,通过门控机制缓解了RNN的极端梯度问题。但RNN及其各种变体均以顺序的方式处理时间序列数据,而并未使用并行计算,这导致更高的时间成本。
著名的Transformer最近被提出用于序列建模。它能够高效、高度并行地捕获长期依赖关系,并且可以轻松地适应不同的输入序列长度。与RNN和CNN不同,Transformer通过利用注意力机制一次处理一系列数据来访问历史数据的任何部分,无论距离有多远,这使得它拥有更强大的捕获长期依赖的能力。但标准点积自注意力机制使得Transformer在每个时间步提取的高级特征对其局部上下文不敏感,忽略了相邻时间序列数据的局部特征的重要性。
发明内容
本发明针对背景技术中存在的不足,提供了一种基于PCA-Transformer模型的设备剩余使用寿命预测方法。本发明采用NASA公开的涡轮风扇发动机退化仿真数据集来进行说明。
本发明包括以下步骤:
步骤1:对设备性能退化数据进行归一化处理,并利用主成分分析(PrincipalComponent Analysis,PCA)对其进行降维;
步骤2:构建设备剩余使用寿命预测模型,将步骤1处理后的设备性能退化数据采用一种新的滑动窗口法分批次输入到1D-CNN和Transformer模型中提取其不同的特征;
步骤3:将步骤2提取出的不同特征进行融合,并输入全连接层进行最终剩余使用寿命预测;
步骤4:采用两种评估方法对模型进行评估,验证模型的有效性。
进一步地,在步骤1中:
步骤1.1:采用z-score方法来对设备性能退化数据进行归一化处理,将数据中的各种参数大小限定在相同的区间内,z-score方法定义如下:
式中,μ
步骤1.2:经过步骤1.1后,采用PCA方法对归一化后的数据进行降维。
假设设备性能退化数据为(X1,X2,X3…Xn),其中每个向量有m个变量(维度),对应性能退化数据的传感器参数,变量组成一个初始数据集矩阵X,即
对数据集X去中心化,即每一位特征减去各自的平均值。
计算去中心化后的数据集X的协方差矩阵,即:
对协方差矩阵C
对特征值从大到小进行排序,将其对应特征向量组成特征向量矩阵U。
利用特征向量矩阵U数据集矩阵X进行线性变换,得到各主成分向量Y,即:
Y=U
再计算得到其全部主成分向量的累计贡献率,即:
最后根据设定的阈值选取相应前k个主成分,k即为主成分分析降维后的数据的维度,保留k个主成分向量的数据进行数据重构,实现高维数据向低维数据的映射。
进一步地,在步骤2中:
步骤2.1:对步骤一中经过处理的性能退化数据利用滑动窗口法将其分批次的输入到该步骤所构建的设备剩余使用寿命预测模型中。
退化仿真数据集train_FD001中,包含100个发动机的性能退化数据。本发明对不同的发动机性能退化数据单独使用滑动窗口来获取输入样本,而并非将100个发动机的全部数据综合起来进行窗口大小取样,避免了不同发动机数据之间的污染。在性能退化数据中,假设某一发动机的总运行循环数为T,窗口大小为s,步长为p,传感器数量为n,则每个时间窗口的大小为s×n。窗口沿着T方向以步长p向前滑动,直至最后一个窗口内的最后一条数据为第T条数据。
步骤2.2:选用1D-CNN、Tranformer两种网络结构来构建剩余使用寿命预测模型,两种网络采用并行结构,分别利用其不同的网络优势来对性能退化数据进行特征提取。
Transformer多用于序列建模,利用注意力机制能够有效且高度并行捕获序列的长期依赖关系,并且可以轻松适应不同的输入序列长度。本发明采用基于编码器的简化Transformer模型来对设备性能退化数据提取时序上的依赖关系。Transformer是基于注意力机制的模型,对相邻数据的局部特征并不敏感,然而CNN有着提取复杂数据深层特征的能力,因此本发明采用1D-CNN来提取退化数据的空间特征以强调局部特征的重要性。在模型中,本发明使用Dropout机制来降低过拟合,提高模型的拟合效果。
进一步地,在步骤3中:
步骤3.1:对步骤2中的1D-CNN和Transformer分别提取的特征采用Tensorflow中的concat方法进行融合,融合为时空特征。
步骤3.2:将步骤3.1中融合后的时空特征输入三层全连接层进行运算,最后一层全连接层只有一个输出值,即为发动机剩余使用寿命的预测值。
进一步地,在步骤4中:
采用均方根误差(Root Mean Square Error,RMSE)和评分函数(Score)对步骤3中剩余使用寿命预测值进行评估,来评价模型的预测能力。RMSE评价模型无偏估计的能力,Score加大了滞后预测的惩罚权重,RMSE和Score表达式如下:
式中,E
与现有方法相比,本发明具有以下有益效果:
采用了一种新的滑动窗口方法对多个发动机的性能退化数据进行采样处理。相较于其他对不同发动机退化数据综合进行采样的滑动窗口方法,本发明的滑动窗口方法则是针对单个发动机退化数据来进行采样,这样有效的避免了不同发动机退化数据的误用,对生成的批次数据减少了污染。
将Transformer并行优势和CNN提取局部特征优势集中于一种模型之中,同时获取局部空间特征与长期时序依赖,实现模型对性能退化数据特征的充分挖掘以及更高的计算效率。
附图说明
图1为train_FD001数据展示;
图2为滑动窗口示例;
图3为原生Transformer模型结构;
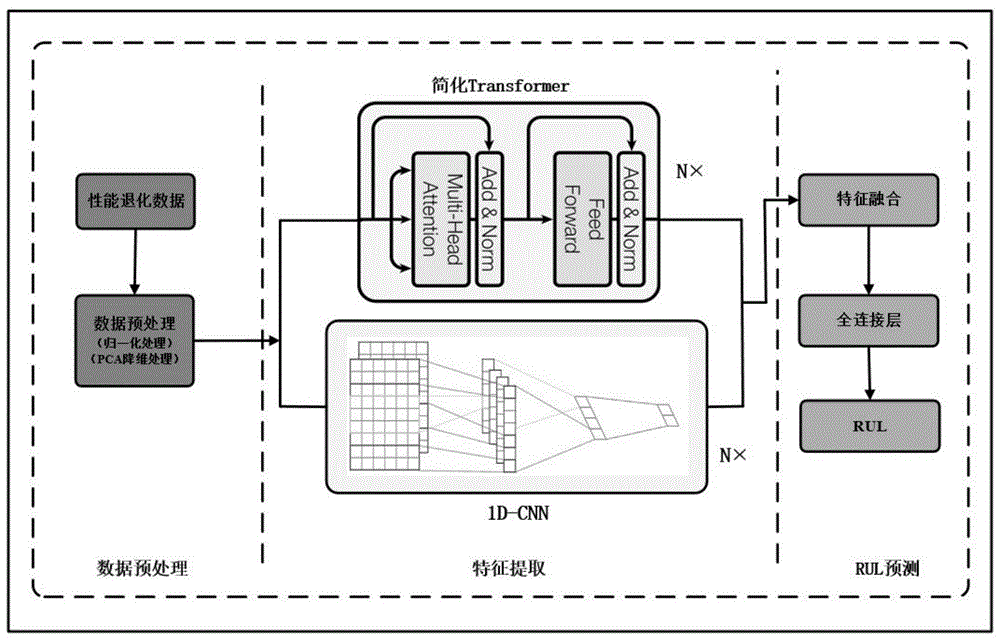
图4为PCA-Transformer模型结构。
具体实施方式
下面结合附图对本发明一种基于PCA-Transformer模型的设备剩余使用寿命预测方法作进一步说明。本发明采用NASA公开的涡轮风扇发动机退化仿真数据集(CMAPSS),主要使用其中train_FD001数据来进行说明,train_FD001中包含100个发动机的性能退化数据。
步骤一:数据预处理
将train_FD001中的数据进行归一化处理,并使用PCA方法对其进行降维处理。
将train_FD001中的数据进行可视化处理,结果如图1所示,从图中可以看出setting_3、s_1、s_5、s_10、s_16、s_18、s_19的值为固定值,本发明将无变化的传感器数据删除,将剩余数据采用z-score方法进行归一化处理,将数据中的各种参数大小限定在相同的区间内,防止不同的量纲对预测结果造成影响,z-score方法定义如下:
式中,μ
对归一化后的数据进行PCA降维处理。假设设备性能退化数据为(X1,X2,X3…Xn),其中每个向量有m个变量(维度),对应性能退化数据的传感器参数,变量组成一个初始数据集矩阵X,即
对数据集X去中心化,即每一位特征减去各自的平均值。
计算去中心化后的数据集X的协方差矩阵,即:
对协方差矩阵C
对特征值从大到小进行排序,将其对应特征向量组成特征向量矩阵U。
利用特征向量矩阵U数据集矩阵X进行线性变换,得到各主成分向量Y,即:
Y=U
再计算得到其全部主成分向量的累计贡献率,即:
最后根据设定的阈值选取相应前k个主成分,k即为主成分分析降维后的数据的维度,保留k个主成分向量的数据进行数据重构,实现高维数据向低维数据的映射。
步骤二:构建设备剩余使用寿命预测模型,提取数据中的隐藏特征
对步骤一中经过处理的性能退化数据利用滑动窗口法将其分批次的输入到该步骤所构建的设备剩余使用寿命预测模型中。
退化仿真数据集train_FD001中,包含100个发动机的性能退化数据。本发明对不同发动机的性能退化数据单独使用滑动窗口来获取输入样本,而并非将100个发动机的全部数据综合起来进行窗口大小取样,避免了不同发动机数据之间的污染。如图2所示,在性能退化数据中,假设某一发动机的总运行循环数为T,窗口大小为s,步长为p,传感器数量为n,则每个时间窗口的大小为s×n。窗口沿着T方向以步长p向前滑动,直至最后一个窗口内的最后一条数据为第T条数据。
选用1D-CNN、Tranformer两种网络结构来构建剩余使用寿命预测模型,两种网络采用并行结构,分别利用其不同的网络优势来对性能退化数据进行特征提取。
Transformer模型如图3所示,利用注意力机制能够有效且高度并行捕获序列的长期依赖关系,可以轻松适应不同的输入序列长度。本发明对原生的Transformer模型进行了改动,采用基于编码器的简化Transformer模型来对设备性能退化数据提取时序上的依赖关系。Transformer是基于注意力机制的模型,对相邻数据的局部特征并不敏感,然而CNN有着提取复杂数据深层特征的能力,因此本发明采用1D-CNN来提取退化数据的空间特征以强调局部特征的重要性。在模型中,本发明使用Dropout机制来降低过拟合,提高模型的拟合效果。
步骤三:进行特征融合
如图4所示,性能退化数据经过预处理后分别输入到简化Transformer和1D-CNN模型中进行特征提取,在本步骤中将对步骤二中1D-CNN和Transformer分别提取的特征采用Tensorflow中的concat方法进行融合,融合为时空特征。将融合后的时空特征输入三层全连接层进行运算,最后一层全连接层只有一个神经元,输出结果为发动机剩余使用寿命的预测值。
步骤四:对模型进行评估
本发明使用两种评估标准,均方根误差(RMSE)和评分函数(Score)。第n个预测误差E
E
评分函数对于异常值较为敏感,由于没有对预测误差进行归一化,一个异常值便可极大的改变评分函数的值,因此同时采用RMSE来评价算法无偏估计的能力:
将性能退化数据经过归一化和主成分分析后输入所构建的设备剩余使用寿命预测模型中,对所测试设备剩余使用寿命进行预测,利用RMSE和Score两种评价指标来进行性能的验证,两种评价指标数值越小表明预测结果越好。
以上对本发明所提出的一种基于PCA-Transformer剩余使用寿命预测方法进行了介绍,对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;对于本领域的技术人员来说,在不脱离本发明思想的前提下,在具体实施方式及应用上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。