用于数字政务的企业政策信息多重动态智能匹配推荐方法
文献发布时间:2023-06-19 10:54:12
技术领域
本发明涉及信息处理技术领域,特别涉及一种用于数字政务的企业政策信息多重动态智能匹配推荐方法。
背景技术
随着国家科技和经济的迅猛发展,为了鼓励企业和高校科研机构等的创新活动,国家各部门每年均会发布很多政策来支持和鼓励企业和高校科研机构的创新技术发展。但是由于政策的发布部门、发布时间、发布站点等均不相同,从而导致政策信息分散。用户想要了解本产业领域的政策信息,往往要通过搜索大量的网站信息,同时还要对获取的政策信息进行分析,来判断自身是否符合申报条件,这样繁琐的流程占用了企业等用户大量的时间。用户往往要从海量的政策中逐个分析才能获知自身适合申报的政策,占用大量人工时间,效率低。企业无法及时获取政策信息,也无法及时判断自身是否符合申报条件并完成申报流程,更无法及时获得政府项目的支持,错失了获得政策辅助的机会,从而阻碍了国家鼓励支持的进程。
因此,迫切需要研发一种可以连接企业和政策桥梁,实现企业数据和政策数据快速精准匹配的方法,以使得政策助力企业发展,为企业保驾护航。
发明内容
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的目的在于提出一种用于数字政务的企业政策信息多重动态智能匹配推荐方法,包括:
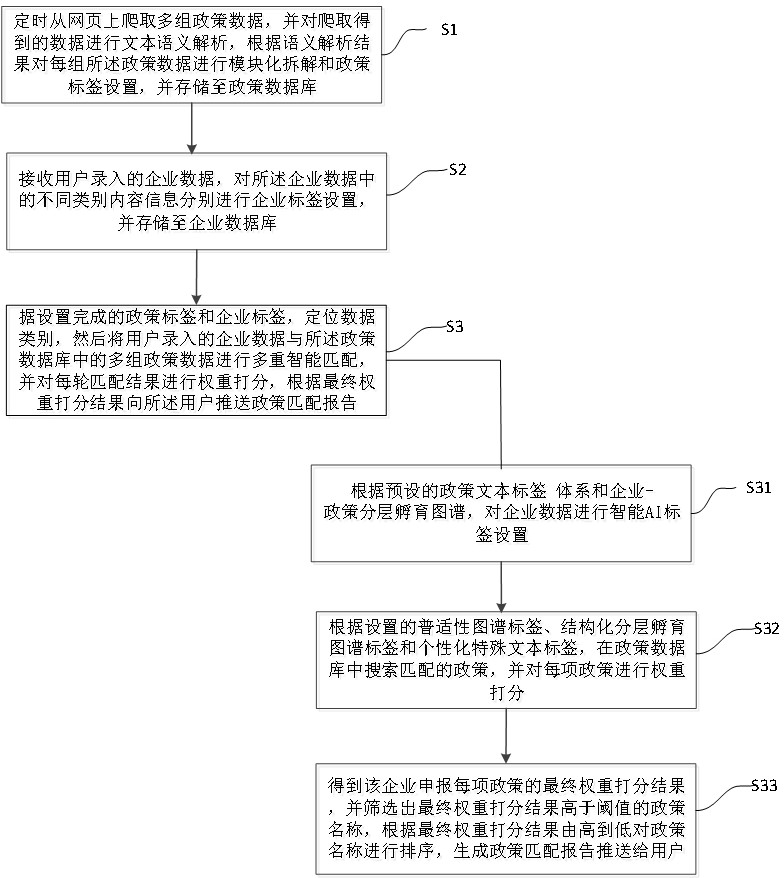
步骤S1,定时从网页上爬取多组政策数据,并对爬取得到的数据进行文本语义解析,根据语义解析结果对每组所述政策数据进行模块化拆解和政策标签设置,并存储至政策数据库;
步骤S2,接收用户录入的企业数据,对所述企业数据中的不同类别内容信息分别进行企业标签设置,并存储至企业数据库;其中,所述企业数据至少包括企业名称;
步骤S3,根据设置完成的政策标签和企业标签,定位数据类别,然后将用户录入的企业数据与所述政策数据库中的多组政策数据进行多重智能匹配,并对每轮匹配结果进行权重打分,根据最终权重打分结果向所述用户推送政策匹配报告;其中,所述多重智能匹配包括如下步骤:
步骤S31,根据预设的政策文本标签体系和企业-政策分层孵育图谱,对所述企业数据进行智能AI标签设置,其中,
所述政策文本标签体系包括:普适性图谱标签、结构化分层孵育图谱标签、个性化特殊文本标签和企业自定义标签,其中,
(1)普适性图谱标签
对所述企业数据进行分析,获取该企业的发展规模,根据企业的发展规模在所述政策数据库中匹配对应的普适性政策内容,为该企业数据设置相匹配的普适性图谱标签;
(2)结构化分层孵育图谱标签
预设结构化分层孵育图谱,所述结构化分层孵育图谱包括:政策类别与企业产业类别的分层匹配关系图谱,
对所述企业数据进行分析,获取该企业的产业类别,根据企业的产业类别从政策类别的分层数据中匹配对应的政策数据,为该企业数据设置相匹配的结构化分层孵育图谱标签;其中,所述结构化分层孵育图谱中预设有每个产业类别所对应可申报的政策内容;
(3)个性化特殊文本标签
(3.1)对所述企业数据和政策数据进行匹配,根据匹配结果中符合条件的政策、不符合条件但具有培育潜力的政策,分别为该企业数据设置相对应的个性化特殊文本标签;
(3.2)对所述用户的浏览行为进行后台记录,分析该企业用户的行为习惯,定位出对应的兴趣数据集合,将所述兴趣数据集合与所述政策数据进行匹配,为该企业用户设置相匹配的个性化特殊文本标签;
(4)企业自定义标签
接收企业用户主动录入的标签数据,对该标签数据与所述政策数据进行匹配,为该企业用户设置相匹配的企业自定义标签;
步骤S32,根据步骤S31中设置的普适性图谱标签、结构化分层孵育图谱标签、企业自定义标签和个性化特殊文本标签,在所述政策数据库中搜索匹配的政策,并对每项政策进行权重打分,包括:
为所述普适性图谱标签、结构化分层孵育图谱标签、个性化特殊文本标签和企业自定义标签分配不同的权重值;
根据标签类别在所述政策数据库中搜索相对应的所有政策内容,针对每项政策进行企业数据和政策数据的关键词多轮自动匹配,包括:计算每轮匹配度,根据所述匹配度对本轮匹配进行权重打分,得到该企业申报该政策的最终权重打分结果;其中,根据该轮政策匹配所对应的标签类别的权重值进行打分,然后将所有标签类别所对应的政策匹配结果的打分值进行累加,得到该政策的最终打分结果;
步骤S33,采用步骤S32的方式得到该企业申报每项政策的最终权重打分结果,并筛选出最终权重打分结果高于阈值的政策名称,根据最终权重打分结果由高到低对政策名称进行排序,生成政策匹配报告推送给用户。
进一步,在所述步骤S1中,包括如下步骤:
步骤S11,对所述政策数据进行文本语义解析,得到语义解析结果;根据多个预设模块主题对所述语义解析结果进行模块化拆解,其中所述预设模块主题包括:政策制定部门、政策有效时间、政策所属产业、政策所属地域、政策申报条件、政策申报流程和政策奖励内容;
步骤S12,对拆解后的模块化文字段落,分别设置对应的模块主题标签,作为所述政策标签;
步骤S13,以每组政策数据为单位存入至所述政策数据库,其中,每组所述政策数据包括设置有多个政策标签的模块化文字段落。
进一步,在所述步骤S2中,采用以下两种形式之一对企业数据设置标签:
(1)接收所述用户录入的企业说明全文本数据,对该全文本数据进行语义解析得到企业数据中的不同类别内容信息,并设置企业标签;
(2)向所述用户提供预设企业数据模板,所述企业数据模板中的每个主题分别对应一个企业标签,当用户根据所述企业数据模板录入完成后,自动为录入的企业数据设置企业标签。
进一步,在所述步骤S32中,多轮自动匹配中,采用正向匹配、反向条件、反向诊断三种方式:
(1)正向匹配
将所述企业数据与所述政策数据中的政策所属产业、政策所属地域、政策申报条件分别进行比对,当有多项符合条件时,则将符合条件的政策作为可申报政策进行权重打分;
(2)反向条件
将所述企业数据与所述政策数据中的政策所属产业、政策所属地域、政策申报条件分别进行比对,当判断所述企业数据不符合该政策数据中的至少一个硬性必要条件时,则不再向该企业用户推送该政策数据;其中,每项政策数据均预设有申报该政策的一个或多个硬性必要条件,只要有一个条件不符合,则不允许申报该政策;
(3)反向诊断
根据以下两个方向对该企业的政策申报进行反向分析诊断:
1)对所述企业数据中录入的已申报项目和企业基础数据进行分析,进行政策反向诊断,包括:诊断未申报但符合申报条件的政策;
2)对所述企业数据和政策数据进行匹配,对不符合申报条件,但与申报条件的差距在预设区间内的政策进行反向诊断,包括:诊断未申报但具有培育前景的政策。
进一步,在所述步骤S31中的个性化特殊文本标签设置中,自动记录每个用户的系统浏览记录数据,分析得到该用户浏览频次高的界面主题,生成用户兴趣数据集合;当检测到用户登录后,自动向该用户推荐与其用户兴趣数据集合相关联的政策信息。
进一步,在所述步骤S32中,为不同标签类型的政策设置相应的权重值,其中,
普适性图谱标签对应政策的权重值<结构化分层孵育图谱标签对应政策的权重值<企业自定义标签的权重值<个性化特殊文本标签的权重值。
进一步,本方法还包括如下步骤:在用户注册时,为该用户提供角色设置选项,包括:企业用户、渠道用户和政府机构用户,并为不同角色的用户设置对应的操作功能界面和权限;
针对同一企业用户,配置归属该企业用户的多个角色权限,每个角色权限根据登录角色的级别,为其分配不同的政策匹配查看权限范围。
进一步,所述政策数据库具有自动更新功能,定时检测每组政策数据的政策有效时间标签,当判断时间为过去式时,则自动剔除该政策数据;
所述企业数据库具有更新提醒功能,定时提醒用户更新企业数据,并在检测到用户更新后,根据更新后的企业数据自动为所述用户生成最新的政策匹配报告。
进一步,当用户录入的企业信息仅为企业名称时,以所述企业名称为关键词获取该企业的当前已公开基础数据,根据所述当前已公开基础数据对企业进行政策匹配,生成初步匹配结果;
同时,向该用户发出非公开基础数据获取请求,以获取该企业与政策申报相关的非公开基础数据,将所述非公开基础数据和已公开基础数据进行结合,进行二次政策匹配,生成最终匹配结果。
进一步,所述政策匹配报告在向企业用户提供匹配政策列表的同时,进一步向所述企业用户提供是否有已申报的选择控件,对于已经申报过的项目,将不再向该企业用户推荐。
根据本发明实施例的用于数字政务的企业政策信息多重动态智能匹配推荐方法,具有以下有益效果:
(1)对爬取的政策数据进行文本语义解析和模块化拆解,从而可以快速的解析出政策文本内容,并抓取政策文本中的核心内容和关键主题,从而在后续与企业数据的匹配中可以利用主题实现数据快速匹配,而不需要对政策全文本进行匹配,大大提高了匹配效率;
(2)对企业数据进行分析和类别标签设置,抓取企业数据中的核心内容和属性主题,从而在后续与政策数据的匹配中可以利用主题实现数据快速匹配,而不需要对企业数据全文本进行匹配,大大提高了匹配效率。并且,本发明可以向企业用户提供企业信息调研表,由企业用户根据自身实际情况录入,从而可以实现对企业数据快速解析。
(3)建立智能AI标签体系,分为普适性图谱标签、结构化分层孵育图谱标签、企业自定义标签和个性化特殊文本标签,这种标签分层体系可以由浅至深逐步实现企业数据与政策数据的匹配,从普适性政策内容、企业产业类别、企业用户自定义标签、企业个性化数据等多个维度,逐步匹配缩小筛选政策池,从而使得最终的匹配结果精度更高,更符合企业用户的自身意愿和需求。
(4)提供采用正向匹配、反向条件、反向诊断三种方式,除了为用户推送相匹配的政策、屏蔽不匹配的政策外,本发明更创新的为企业用户提出反向诊断功能,即根据企业当前情况,匹配出企业当前虽然不符合但具有培育前景的政策,从而为用户提供长期的政策规划,给企业提供未来培养方向和培养进度。
(5)实现自动搜集各个网站上的政策信息并采用语义处理方式对政策信息进行分类标签,实现企业数据和政策数据的高效精准匹配,解决了目前企业或高校面对庞杂的政策信息,人工筛选匹配存在的效率低、准确率差的问题,为用户提供精准的政策智能匹配推送服务,为用户提供政策指导,使得用户及时获知自身可申报的政策、以及为用户提供政策培育指导建议。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的用于数字政务的企业政策信息多重动态智能匹配推荐方法的流程图;
图2为根据本发明实施例的智能AI标签体系的架构图;
图3为根据本发明实施例的政策信息的示例图;
图4为根据本发明实施例的政策匹配报告的界面图。
具体实施方式
下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
为了解决现有技术中存在的企业-政策匹配还停留在人工匹配阶段,导致的效率低、経度差的问题,本发明提出一种用于数字政务的企业政策信息多重动态智能匹配推荐方法,通过建立基于企业和政策的智能AI标签分层体系,实现对企业数据和政策数据的快速精准匹配,为企业用户提供政策申报规划,助力企业发展。
如图1所示,本发明实施例的用于数字政务的企业政策信息多重动态智能匹配推荐方法,包括如下步骤:
步骤S1,定时从网页上爬取多组政策数据,并对爬取得到的数据进行文本语义解析,根据语义解析结果对每组政策数据进行模块化拆解和政策标签设置,并存储至政策数据库。
具体的,步骤S11,对政策数据进行文本语义解析,得到语义解析结果;根据多个预设模块主题对语义解析结果进行模块化拆解,其中预设模块主题包括:政策制定部门、政策有效时间、政策所属产业、政策所属地域、政策申报条件、政策申报流程和政策奖励内容等。需要说明的是,模块主题不限于上述举例,还可以包括其他类型的主题,根据政策内容的变化进行设置,在此不再赘述。
以图3中的政策文本为例,爬取完该网页的政策文本进行进行文本语义解析,分析得到每段落文本的语义内容,然后进行模块化拆解。具体拆解为如下:
政策制定部门:xxxxxxxx;
政策有效时间:截止至2022年;
政策所属产业:新一代信息技术、先进制造、新能源、新材料、无人机;
政策所属地域:天津;
政策申报流程:依据实际需求填写《2021年xxxxxxxx需求征集表》(见附件),于2021年4月6日前将电子版发送至xxxxx;
政策申报条件:以重大经济价值、重大技术瓶颈、新兴产业培育、供应链安全为导向,聚焦需解决的关键核心技术问题,说明研究目的、意义和必要性,阐明主要研究内容,提出明确的考核目标,提出对揭榜单位的要求。揭榜制项目的需求主要由天津重点领域的龙头企业、科技型企业提出。
步骤S12,对拆解后的模块化文字段落,分别设置对应的模块主题标签,作为政策标签。
例如,参考图3,根据解析结果对“新一代信息技术、先进制造、新能源、新材料、无人机”这段文字设置“政策所属产业”的标签。
步骤S13,以每组政策数据为单位存入至政策数据库,其中,每组政策数据包括设置有多个政策标签的模块化文字段落。
需要说明的是,虽然对政策文本进行拆解为多段,但是在存入数据库时仍以每组政策为单位进行存储。即,拆分为段落是为了便于后续数据匹配,但是再向用户推送政策时仍以完整政策文本进行推送。
步骤S2,接收用户录入的企业数据,对企业数据中的不同类别内容信息分别进行企业标签设置,并存储至企业数据库。
在本步骤中,向用户提供企业信息调研表,由用户根据调研表中内容填写自身企业信息。例如,调研表中的企业数据包括:企业名称、企业类型、注册地址、主营业务、核心技术、财务状况、知识产权状况、已申报项目等信息。
需要说明的是,本发明中的企业数据至少包括企业名称。
当用户录入的企业信息仅为企业名称时,以企业名称为关键词获取该企业的当前已公开基础数据,根据当前已公开基础数据对企业进行政策匹配,生成初步匹配结果。同时,向该用户发出非公开基础数据获取请求,以获取该企业与政策申报相关的非公开基础数据,将非公开基础数据和已公开基础数据进行结合,进行二次政策匹配,生成最终匹配结果。
具体来说,用户可以仅提供企业名称,后台系统根据企业名称从已有企业数据库或网络信息中获取该企业的其他已公开基础数据,例如企业类型、注册地址、主营业务、核心技术、财务状况、知识产权状况等这些公开信息,然后根据上述数据进行政策匹配。但是由于部分政策项目要求除上述公开数据外的其他数据,例如财务数据等,由于这类数据是非公开的,需要用户提供。当用户提供上述非公开数据后,将非公开基础数据和已公开基础数据进行结合,进行二次政策匹配。
在本步骤中,采用以下两种形式之一对企业数据设置标签:
1、接收用户录入的企业说明全文本数据,对该全文本数据进行语义解析得到企业数据中的不同类别内容信息,并设置企业标签。
2、向用户提供预设企业数据模板,企业数据模板中的每个主题分别对应一个企业标签,当用户根据企业数据模板录入完成后,自动为录入的企业数据设置企业标签。
需要说明的是,本发明中的政策数据库和企业数据库均可以自动更新。
1、政策数据库具有自动更新功能,定时检测每组政策数据的政策有效时间标签,当判断时间为过去式时,则自动剔除该政策数据。
以图3为例,当检测当前日期超过2021年4月6日时,则判断该政策为过期政策,从政策数据库中自动剔除该政策数据。
2、企业数据库具有更新提醒功能,定时提醒用户更新企业数据,并在检测到用户更新后,根据更新后的企业数据自动为用户生成最新的政策匹配报告。
具体来说,由于企业自身在不断发展,其企业数据也在变化中,如果仍以初始的企业数据进行政策匹配,会导致匹配不准确的问题。为此,本发明设置预设周期时间,例如6个月,每隔6个月自动提醒在系统中已注册的企业用户,是否需要更新企业数据。如果检测到用户更新企业数据,则以该更新后的企业数据进行政策匹配,从而保障政策匹配的精度。
步骤S3,根据设置完成的政策标签和企业标签,定位数据类别,然后将用户录入的企业数据与政策数据库中的多组政策数据进行多重智能匹配,并对每轮匹配结果进行权重打分,根据最终权重打分结果向用户推送政策匹配报告,如图4所示。
步骤S31,根据预设的政策文本标签 体系和企业-政策分层孵育图谱,对企业数据进行智能AI标签设置。
如图2所示,政策文本标签体系包括:普适性图谱标签、结构化分层孵育图谱标签、个性化特殊文本标签和企业自定义标签。下面分别对各类标签进行说明。
(1)普适性图谱标签
对企业数据进行分析,获取该企业的发展规模,根据企业的发展规模在政策数据库中匹配对应的普适性政策内容,为该企业数据设置相匹配的普适性图谱标签。
具体来说,不同政策项目对企业规模有不同的申报要求,例如A类政策的申报条件要求企业注册资本高于100万,B类政策的申报条件要求企业注册资本在100万~500万之间,C类政策的申报条件要求企业注册资本在500万~1000万之间等等。
因此,需要对企业数据进行分析,当判断该企业的注册资本在100万~500万之间,则将申报条件在该区间内的政策进行筛选,得到普适性筛选政策池。
(2)结构化分层孵育图谱标签
预设结构化分层孵育图谱,结构化分层孵育图谱包括:政策类别与企业产业类别的分层匹配关系图谱。
对企业数据进行分析,获取该企业的产业类别,根据企业的产业类别从政策类别的分层数据中匹配对应的政策数据,为该企业数据设置相匹配的结构化分层孵育图谱标签;其中,结构化分层孵育图谱中预设有每个产业类别所对应可申报的政策内容。
具体来说,不同政策项目对企业产业类别有不同的申报要求。例如A类政策的申报条件要求企业产业类别为新能源和新材料,B类政策的申报条件要求企业产业类别为互联网新技术,C类政策的申报条件要求要求企业产业类别为生物与新医药技术等等。
因此,需要对企业数据进行分析,当判断该企业产业类别为新能源时,则从上述得到的普适性筛选政策池中筛选“政策所属产业”为新能源的政策信息,得到结构化筛选政策池。
(3)个性化特殊文本标签
(3.1)对企业数据和政策数据进行匹配,根据匹配结果中符合条件的政策、不符合条件但具有培育潜力的政策,分别为该企业数据设置相对应的个性化特殊文本标签。
具体来说,“符合条件的政策”是指企业数据与政策数据中的申报条件的关键词相同或相近,则判断符合申报条件。
“不符合条件但具有培育潜力的政策”是指企业数据政策数据中的申报条件的关键词不同,但通过语义分析发现,通过对企业进行若干时间的培育,可以达到符合该条件。
例如:某项政策申报条件要求企业的核心技术人员有5名博士、有15项已授权的专利。但企业目前只有3名博士、2项已授权专利。通过分析发现该企业经过引进人才,申请知识产权,在明年是可以达到申报条件的。
(3.2)对企业用户的浏览行为进行后台记录,分析该企业用户的行为习惯,定位出对应的兴趣数据集合,将兴趣数据集合与政策数据进行匹配,为该企业用户设置相匹配的企业自定义标签。
在本发明的实施例中,自动记录每个用户的系统浏览记录数据,分析得到该用户浏览频次高的界面主题,生成用户兴趣数据集合;当检测到用户登录后,自动向该用户推荐与其用户兴趣数据集合相关联的政策信息。
具体来说,后台系统自动实时记录所有已注册用户的在系统上的浏览记录数据,然后对这些数据进行分析。例如,当记录得到A企业用户连续一周浏览高新技术企业认定的网页内容,则后台自动在该用户登录后,向其推送与高新技术企业认定相关的政策内容。
(4)企业自定义标签
接收企业用户主动录入的标签数据,对该标签数据与政策数据进行匹配,为该企业用户设置相匹配的个性化特殊文本标签。即,本发明支持用户自定义输入标签数据,主动为自身设置标签,例如企业自身经营内容为软件互联网,但也部分技术属于机电控制类,则可以自己设置“机电控制”对标签,以便于后续有相关“机电控制”的政策匹配。
步骤S32,根据步骤S31中设置的普适性图谱标签、结构化分层孵育图谱标签、企业自定义标签和个性化特殊文本标签,在政策数据库中搜索匹配的政策,并对每项政策进行权重打分,包括:
(1)为普适性图谱标签、结构化分层孵育图谱标签、个性化特殊文本标签和企业自定义标签分配不同的权重值。
在本发明的实施例中,普适性图谱标签对应政策的权重值<结构化分层孵育图谱标签对应政策的权重值<企业自定义标签的权重值<个性化特殊文本标签的权重值。
由于“企业自定义标签”和“个性化特殊文本标签”均为基于用户自身意愿的数据,因此这两者的标签权重值要高于政策类别划分用的“普适性图谱标签”、“结构化分层孵育图谱标签”,这样的权重值分配,可以使得最终政策匹配报告更符合企业自身的意愿和需求,用户的体验感更高。
(2)根据上述标签类别在政策数据库中搜索相对应的所有政策内容,针对每项政策进行企业数据和政策数据的关键词多轮自动匹配,包括:计算每轮匹配度,根据匹配度对本轮匹配进行权重打分,得到该企业申报该政策的最终权重打分结果。
其中,根据该轮政策匹配所对应的标签类别的权重值进行打分,然后将所有标签类别所对应的政策匹配结果的打分值进行累加,得到该政策的最终打分结果。即,针对该轮政策匹配,将普适性图谱标签、结构化分层孵育图谱标签、企业自定义标签和个性化特殊文本标签分别匹配后的打分进行累加,得到最终的打分结果。
具体的,在步骤S32中,多轮自动匹配中,采用正向匹配、反向条件、反向诊断三种方式:
(1)正向匹配
将企业数据与政策数据中的政策所属产业、政策所属地域、政策申报条件分别进行比对,当有多项符合条件时,则将符合条件的政策作为可申报政策进行权重打分。
(2)反向条件
将企业数据与政策数据中的政策所属产业、政策所属地域、政策申报条件分别进行比对,当判断企业数据不符合该政策数据中的至少一个硬性必要条件时,则不再向该企业用户推送该政策数据;其中,每项政策数据均预设有申报该政策的一个或多个硬性必要条件,只要有一个条件不符合,则不允许申报该政策。
例如:某项政策申报条件要求企业的营收达到1000万。但该企业目前营收只有100万。通过分析发现该企业短期内明显无法将营收提到到申报条件,则自动筛选掉该政策,不向用户进行推送,以免浪费用户时间。
(3)反向诊断
根据以下两个方向对该企业的政策申报进行反向分析诊断:
1)对企业数据中录入的已申报项目和企业基础数据进行分析,进行政策反向诊断,包括:诊断未申报但符合申报条件的政策。
例如,企业数据符合申报高新技术企业认定的条件,但在该企业录入的已申报项目中没有该项,则判断该政策属于“诊断未申报但符合申报条件”,向用户进行推送。
2)对企业数据和政策数据进行匹配,对不符合申报条件,但与申报条件的差距在预设区间内的政策进行反向诊断,包括:诊断未申报但具有培育前景的政策。
例如:某项政策申报条件要求企业的核心技术人员有5名博士、有15项已授权的专利。但企业目前只有3名博士、2项已授权专利。通过分析发现该企业经过引进人才,申请知识产权,在明年是可以达到申报条件的。判断该政策属于“诊断未申报但具有培育前景”,向用户进行推送。在向用户推送政策内容的同时,进一步向用户推送申报培育建议。在建议中向用户明确列出:与申报条件的差距、未来需要培育的方向和规划,由此可以为用户提供全流程的政策申报规划服务。
步骤S33,采用步骤S32的方式得到该企业申报每项政策的最终权重打分结果,并筛选出最终权重打分结果高于阈值的政策名称,根据最终权重打分结果由高到低对政策名称进行排序,生成政策匹配报告推送给用户。
参考图4,在政策匹配报告中,根据打分结果将政策内容、政策类别、政策归口单位等信息呈现给用户,用户可以通过点击选中,选择查看政策的具体详细内容。同时,在政策匹配报告中还会向用户提供政策匹配分析结果和政策匹配建议等内容。
在本发明的实施例中,政策匹配报告在向企业用户提供匹配政策列表的同时,进一步向企业用户提供是否有已申报的选择控件,对于检测到用户选择的已经申报过的项目,将不再向该企业用户推荐。
此外,在用户注册时,为该用户提供角色设置选项,包括:企业用户、渠道用户和政府机构用户,并为不同角色的用户设置对应的操作功能界面和权限。针对同一企业用户,配置归属该企业用户的多个角色权限,每个角色权限根据登录角色的级别,为其分配不同的政策匹配查看权限范围。即,同一个企业用户可以关联多个注册id,每个id需要选择对应的角色,例如:法人、财务、法务、技术等。本发明为不同的用户分别不同的权限。当不同角色id登录后,根据其所对应的权限为其展示相应的推送页面,从而满足不同角色对政策的精准需求,提高用户体验度。
根据本发明实施例的用于数字政务的企业政策信息多重动态智能匹配推荐方法,具有以下有益效果:
(1)对爬取的政策数据进行文本语义解析和模块化拆解,从而可以快速的解析出政策文本内容,并抓取政策文本中的核心内容和关键主题,从而在后续与企业数据的匹配中可以利用主题实现数据快速匹配,而不需要对政策全文本进行匹配,大大提高了匹配效率;
(2)对企业数据进行分析和类别标签设置,抓取企业数据中的核心内容和属性主题,从而在后续与政策数据的匹配中可以利用主题实现数据快速匹配,而不需要对企业数据全文本进行匹配,大大提高了匹配效率。并且,本发明可以向企业用户提供企业信息调研表,由企业用户根据自身实际情况录入,从而可以实现对企业数据快速解析。
(3)建立智能AI标签体系,分为普适性图谱标签、结构化分层孵育图谱标签、企业自定义标签和个性化特殊文本标签,这种标签分层体系可以由浅至深逐步实现企业数据与政策数据的匹配,从普适性政策内容、企业产业类别、企业用户自定义标签、企业个性化数据等多个维度,逐步匹配缩小筛选政策池,从而使得最终的匹配结果精度更高,更符合企业用户的自身意愿和需求。
(4)提供采用正向匹配、反向条件、反向诊断三种方式,除了为用户推送相匹配的政策、屏蔽不匹配的政策外,本发明更创新的为企业用户提出反向诊断功能,即根据企业当前情况,匹配出企业当前虽然不符合但具有培育前景的政策,从而为用户提供长期的政策规划,给企业提供未来培养方向和培养进度。
(5)实现自动搜集各个网站上的政策信息并采用语义处理方式对政策信息进行分类标签,实现企业数据和政策数据的高效精准匹配,解决了目前企业或高校面对庞杂的政策信息,人工筛选匹配存在的效率低、准确率差的问题,为用户提供精准的政策智能匹配推送服务,为用户提供政策指导,使得用户及时获知自身可申报的政策、以及为用户提供政策培育指导建议。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、 “示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求及其等同限定。
- 用于数字政务的企业政策信息多重动态智能匹配推荐方法
- 用于数字政务的企业政策信息多重动态智能匹配推荐方法