一种基于策略迭代的伺服电机自适应智能控制方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于自适应控制领域,具体提供一种基于策略迭代的伺服电机自适应智能控制方法,这种方法能够在没有系统模型的情况下获得伺服电机系统的最优反馈控制并且最小化伺服电机的损失函数。
背景技术
从强化学习概念的提出至今已有非常多的理论成果,但是由于强化学习方法计算量大,计算复杂度较高,并且缺乏需高速运算设备的支持,所以很难将强化学习的方法引入到实际的运动控制系统当时中。但是,随着计算机科学技术的高速发展,计算机和单片机的运算速度大幅度提高,提高了在实际运动控制系统运用强化学习算法解决最优反馈控制问题的可行性。
针对解决最优反馈控制问题,传统的技术方法是首先对系统进行模型辨识,得到系统的模型,进而设计最优反馈控制器,传统的控制器有H
发明内容
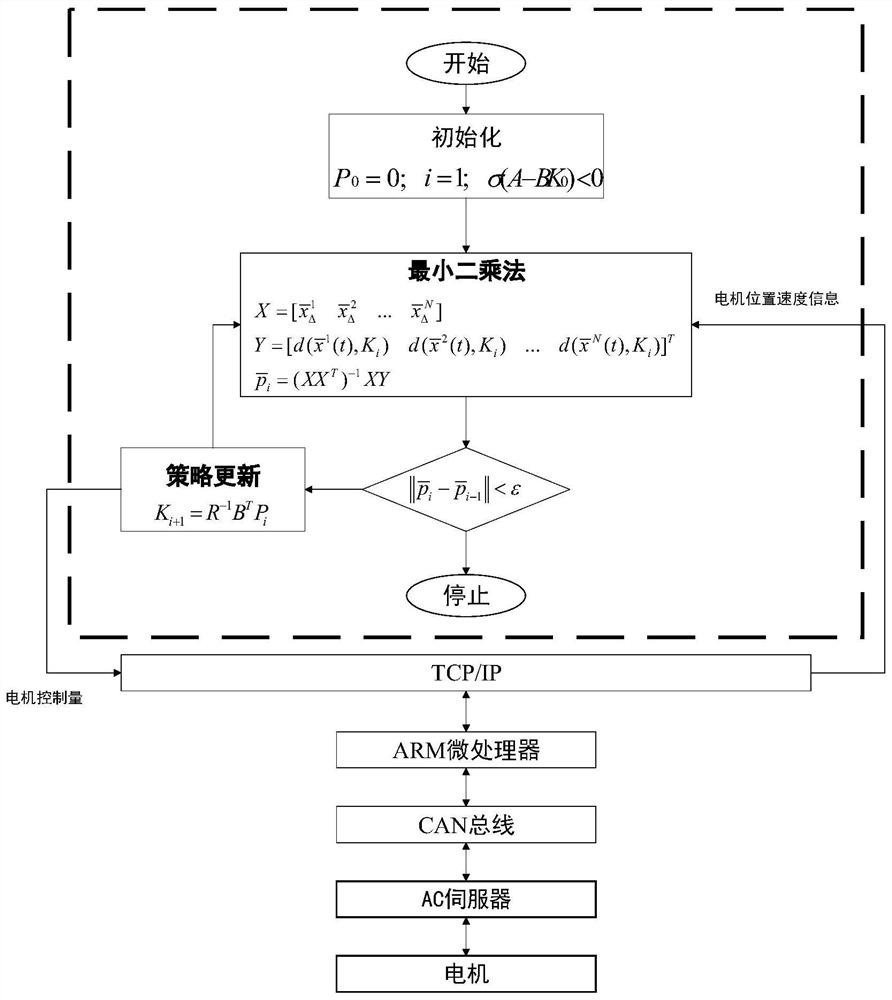
本发明专利所考虑的具有物理特征的实体对象如图1所示,其主要由上位机、ARM微处理器、AC伺服系统、伺服电机、电源及开关和CAN总线组成。其中,上位机主要的工作是通过TCP/IP协议接收来自ARM微处理器的数据,并运行内嵌的控制算法,随后发送控制指令至ARM微处理器。ARM微处理器作为数据的中转站,通过CAN总线从伺服系统中获得伺服电机的速度、位置、力矩等信息,并将这些信息传输给上位机,同时接收上位机的控制指令并将其下发至伺服系统,伺服控制系统中数据信号的传递过程如图2所示。AC伺服系统具体型号为台达ASDA-A2系列的高性能通讯型伺服驱动器,其作用是实时响应PC机的控制指令,驱动伺服电机执行相应的动作。电源及开关则负责系统的上电断电。
为了获取伺服电机的最佳控制策略,本发明提供了一种基于策略迭代的伺服电机自适应智能控制方法,具体地说,本发明提供的方法基于策略迭代的半无模型的算法来解决线性、连续、时不变系统系统的最优控问题。在不需要知道系统内部动态模型的情况下在线解决LQR问题。
本发明为解决上述技术问题提供了如下技术方案:
一种基于策略迭代的伺服电机自适应智能控制方法,包括以下步骤:
步骤1),对伺服电机进行模型辨识,确定系统传递函数,伺服电机的系统模型仅用于在仿真时获取伺服电机下一时刻的位置和速度信息:
通过辨识系统,得到了伺服电机的传递函数如式(1)所示:
其中G(s)为伺服电机的传递函数,K
步骤2),建立运动控制系统状态空间方程并离散化,过程如下:
在步骤1)的基础上将其转化为状态空间方程,如式(2):
其中
将上述的状态空间方程离散化,如式(3):
其中A为系统的状态矩阵,B为输入矩阵,x表示系统状态量,u为系统输入。
步骤3),从伺服电机中采集当前电机的位置和速度,并计算当前时刻电机位置和速度相比上一时刻的增量以及系统在当前时刻的损失函数,最后通过最小二乘法计算当前状态下的最优的权值矩阵P,过程如下:
设计新的策略迭代方法:在(A,B)稳定的假设下,令K是(2)式的一个稳定性反馈增益,因此
其中P是李雅普诺夫方程的一个实对称正定解,Q和是R是正定参数,
(A-BK)
V(x(t))作为(1)式系统状态方程带有反馈控制K的李雅普诺夫函数,因此损失函数表示为
基于上式(6),用x
K
上式(7)、(8)制定了新的迭代策略,并且在迭代过程中不需要涉及系统矩阵A。
步骤4),寻找损失函数最小的参数P矩阵以及相关联的控制策略K
步骤5),判断状态的增量是否小于ε,若不满足条件则继续更新策略K进行状态反馈,过程如下:
系统中存在一个评价函数用来计算伺服电机当前位置和速度与上一时刻位置和速度之间的差值,当差值小于设定的阈值时,系统的控制策略将不再更新,反之则继续更新策略K。
进一步,所述步骤4)的过程为:
4.1)将系统价值函数表示为向量乘积的形式,过程如下:
将系统的价值函数x
4.2)计算系统的价值函数在时间[t,t+T]上的积分:
式(7)表示为
在这个方程中,
是通过系统状态在时间[t,t+T]上的积分得到的;
4.3)通过最小二乘法来计算最优的P
首先沿着系统的单一状态轨迹采集到足够的位置和速度信息,对这些位置和速度信息进行处理后得到系统的值函数
其中,
本发明的有益效果为:基于策略迭代的半无模型的算法来解决线性、连续、时不变系统系统的智能控问题。在不需要知道系统内部动态模型的情况下在线解决LQR问题。
附图说明
图1是伺服控制系统数据信号传递过程框图;
图2是系统的权值矩阵参数变化仿真图;
图3是系统的状态变化仿真图;
图4是系统的反馈输入仿真图;
图5是自适应控制下系统损失函数变化图;
图6是实际运动系统的权值参数变化图;
图7是实际运动系统的状态变化图;
图8是实际运动系统的输入变化图;
图9是固定反馈增益下的系统状态图;
图10是固定反馈增益下系统损失函数变化图。
具体实施方式
为使本发明的目的、技术方案和优点更加清晰,下面结合附图和实际实验对本发明的技术方案作进一步描述。
参照图1~图10,一种基于策略迭代的伺服电机自适应智能控制方法,首先对伺服电机系统进行系统辨识,确定其传递函数,该步骤仅用于在仿真时获取伺服电机下一时刻的位置和速度信息;然后根据系统的传递函数建立伺服电机的状态空间方程并离散化。给定伺服电机一个初始速度,并从伺服电机的单一轨迹中采集系统的位置和速度信息,对采集到的位置和速度信息处理之后进行最小二乘,得到使系统损失函数最小的参数向量
本实施例的基于策略迭代的伺服电机自适应智能控制方法,包括以下步骤:
1)确定伺服电机的传递函数;
2)建立伺服电机系统的状态空间方程并离散化;
3)通过最小二乘法计算当前状态下的最优的权值矩阵P;
4)寻找损失函数最小的权值矩阵P以及相关联的控制策略K
5)计算电机位置和速度的增量并判断是否继续更新策略。
进一步,所述步骤1)中,确定伺服电机系统的传递函数,过程如下:
伺服电机的系统模型仅用于在仿真时获取伺服电机下一时刻的位置和速度信息。通过系统辨识,确定伺服电机的传递函数如式(1)所示:
其中G(s)为伺服电机的传递函数,K
进一步,所述步骤2)中,建立伺服电机的状态空间方程并离散化,过程如下:
将上述传递函数转换为状态空间方程
其中状态矩阵
并对其离散化,如式(2)所示:
伺服电机系统的采样时间T设置为0.05s,则离散化后的系统状态矩阵
进一步,所述步骤3)中,从运动控制系统中采集伺服电机当前的位置和速度信息,并计算位置和速度的增量以及系统在当前时刻的价值函数,最后通过最小二乘法计算当前状态下的最优的权值矩阵P,具体过程如下:
3.1)设计新的策略迭代方法:
在(A,B)稳定的假设下,令K
其中P是李雅普诺夫方程的一个实对称正定解,Q和是R是正定参数,
(A-BK)
V(x(t))作为(1)式系统状态方程带有反馈控制K的李雅普诺夫函数,因此损失函数可以表示为
基于上式,用x
K
上式(8)制定了新的迭代策略,并且在迭代过程中不需要涉及系统矩阵A。
步骤4),寻找损失函数最小的参数P矩阵以及相关联的控制策略K
4.1)根据电机的位置速度信息计算出基向量
将系统的价值函数x
首先,上位机给伺服电机下发一个初始速度,并使电机保持初始速度运行10s,从第10s开始加入反馈控制,加入反馈控制之后,伺服系统需要沿着电机的单一状态轨迹每隔0.05s采集一次的伺服电机位置和速度信息,并将位置和速度信息上传给上位机。上位机得到3组电机位置和速度信息之后需要更新一次电机的反馈控制增益。所以,每次采集伺服电机的位置和速度信息之后,需要进行数据的处理,变成二次多项式的基向量
4.2)计算系统的损失函数在时间[t,t+T]上的积分:
式(7)可以表示为
在这个方程中,
伺服电机系统将电机的位置和速度信息发给上位机,上位机每隔0.05s需要计算一次
4.3)通过最小二乘法来计算最优的P
当上位机得到伺服系统传来的3组数据之后,对上述步骤中得到的X和Y矩阵进行最小二乘,计算出使伺服电机系统损失函数最小化的参数向量
其中,
当系统收敛时的参数矩阵
步骤5),在伺服电机的上位机控制程序之中设定一个判断阈值ε=10
从实验结果可以看出,本发明能够在没有给定伺服电机初始反馈控制增益的情况下,系统能够自动更新到最佳的反馈控制增益,并得到最小的损失函数。相比与固定反馈增益下的系统有更好的动态性能,调节时间更快,系统损失函数减小更加迅速,从实际的能量损耗方面看,自适应反馈控制下的系统相比固定反馈增益的系统而言,能够使用更少的能量来到达很好的系统性能。自适应反馈控制的这种优势对实际的电机伺服系统具有重要的意义。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 一种基于策略迭代的伺服电机自适应智能控制方法
- 一种基于值迭代的伺服电机智能优化控制方法