一种金融长文本复核系统
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及金融文本分析领域,尤其涉及一种金融长文本复核系统。
背景技术
金融长文本主要指年度报告、招股说明书、审计报告等财务数据文本,该些文本主要由文本段落、财务指标和表格数据等复杂元素组成,目前,金融机构或企业本身需要对金融长文本进行复核或其他处理挖掘潜在信息,但该些金融长文本主要依靠人工复核,由于数据量之大以及数据之间的关系复杂,造成人工复核的效率以及精准度低,甚至在发布出去的年度报告中存在数据不一致的问题,为了提高金融长文本的复核效率和精准度,基于计算机强大的计算能力,结合人工智能对自然语言处理技术的兴起,现提出一种金融长文本符合系统,以解决金融长文本符合效率低以及精准度低的问题。
发明内容
为了解决现有技术存在的缺点,本发明提供一种金融长文本复核系统,其通过解析金融长文本的文本内容,结合人工智能对文本内容的处理,实现金融长文本的高效率以及精准复核。
本发明提供一种金融长文本复核系统,其用于解析和审核非结构化金融数据长文本,其包括数据解析模块以及数据审核模块,所述数据解析模块将非结构化数据解析成结构化数据,该数据解析模块包括版面识别单元、表格语义分析单元以及表格语义解析单元,所述版面识别单元用于获取原始金融数据长文本对的文档篇章结构信息,所述表格语义分析单元用于分析版面识别单元获取的表格数据并按预定义的数据模型组织存储数据,所述文本语义解析用于解析版面识别单元获取的段落、标题数据并按预定义的数据模型组织存储数据;所述数据审核模块对结构化数据进行审核处理,该数据审核模块包括错别字审查单元、一致性审核单元、勾稽关系审核单元以及文本格式审核单元,所述错别字审查单元根据NLP模型检测潜在错别字得到候选字符及概率并结合领域字典针对段落、标题数据查找错别字提出纠正建议,所述一致性审核根据会计准则对表格数据进行审核,所述勾稽关系审核单元根据会计准则提取文本中存在的勾稽关系规则,并由该些勾稽关系规则进行数据审核;所述文本格式审核单元根据标题和文本的目录结构,根据序号连续性和关联序号规则进行格式审核。
优选的,所述非结构化金融数据长文本为PDF格式文本。
优选的,所述版面识别单元获取原始金融数据长文本对的文档篇章结构信息的具体步骤为:S10:将PDF格式文本按页转换为图片格式文本,并进行拉伸以及二值化预处理;S11:根据CV模型检测预处理后的图片格式文本,获取表格、页眉、页脚、图片、公式数据;S12:提取表格、页眉、页脚、图片、公式数据以外的文字数据,并将该些文字数据按页,行顺序组织;S13:根据NLP模型将提取的文字数据划分为段落数据和标题数据;S14:整合输出提取的数据保存至数据库中。
优选的,所述表格语义分析单元对表格数据分析的具体步骤为:S20:获取S14中的表格数据;S21:对表格数据进行预处理,包括:数据清洗和集合划分;S22:根据NLP模型解析预处理后的表格数据并提取表格数据关系;S23:将表格数据以及表格数据关系按预定义的数据模型组织输出并保存至数据库中;所述文本语义解析单元解析段落数据和标题数据的具体步骤为:S30:获取S14中的段落数据和标题数据;S31:对段落数据和标题数据进行预处理,包括:数据清洗、数据长度切割、定位数据提取位置,以及数据字型特征转换为预定义字型格式;S32:根据NLP模型解析预处理后的段落数据和标题数据,提取数据文本中的关键信息、相关必要信息以及关键信息之间的关联;S33:将解析后的段落数据和标题数据按预定义的数据模型组织输出并保存至数据库中。
优选的,所述一致性审核单元审核表格数据的具体步骤为:S50:读取S23中的表格数据;S51:将表格数据区分为财务摘要表、财务主表和财务附注表;S52:根据会计准则提取一致性审核规则,按规则进行数据匹配;S53:将匹配后的数据按预定格式输出并存保存至数据库并输出审核结果。
优选的,所述勾稽关系审核审核表格数据的具体步骤为:S60:读取S23中的表格数据和S33中的标题数据;S61:根据语义分析结果和标题数据,对表格数据进行归类;S62:根据表格数据勾稽关系规则,对表格数据进行关系勾稽;S63:将勾稽关系的表格数据按预定义格式输出保存至数据库并输出审核结果。
优选的,所述文本格式审核单元进行格式审核的具体步骤为:S70:读取文档的目录结构,以及S23的表格数据和S33的标题数据;S71:对标题数据进行层级格式化;S72:对格式化后的标题数据,进行连续性审核;S73:提取表格数据中引用的序号和标题格式化进行审核;S74:将审核后的数据按预定义格式输出保存至数据库并输出审核结果。
本发明提供的金融长文本复核系统,通过数据解析模块和数据审核模块两个模块配合实现金融长文本的复核,其中,数据解析模块负责将金融长文本拆分重新组织并转换为预定义的数据格式,其次,通过数据审核模块对对应修改格式后的数据进行数据处理,执行审核作业,完成审核同时输出审核结果,该人工智能审核的金融长文本复核系统极大地精简了人力重复对数据核查的工作,只需要针对审核结果进行比对判断,即可得到最终金融长文本存在的问题,高效率高精度地对金融长文本进行复核。
附图说明
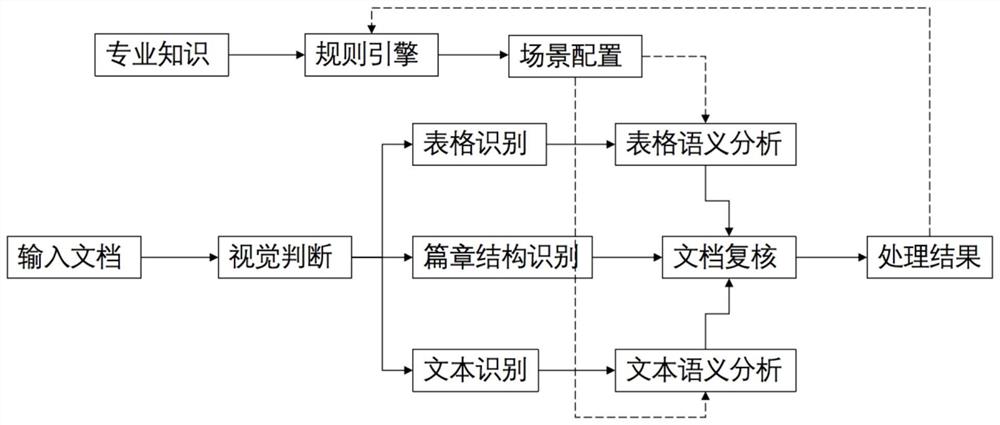
图1是本发明提供的金融长文本复核系统的功能逻辑结构图;
图2是本发明提供的版面识别单元获取原始金融数据长文本对的文档篇章结构信息的具体步骤图;
图3是本发明提供的表格语义分析单元对表格数据分析的具体步骤图;
图4是本发明提供的文本语义解析单元解析段落数据和标题数据的具体步骤图;
图5是本发明提供的错别字审查单元对段落数据和标题数据中错别字查找的具体步骤图;
图6是一致性审核单元审核表格数据的具体步骤图;
图7是勾稽关系审核审核表格数据的具体步骤图;
图8是文本格式审核单元进行格式审核的具体步骤图。
具体实施方式
下面结合附图对本发明所提供的一种金融长文本复核系统作进一步说明,需要指出的是,下面仅以一种最优化的技术方案对本发明的技术方案以及设计原理进行详细阐述。
本发明提供的金融长文本复核系统,其用于解析和审核非结构化金融数据长文本,其包括数据解析模块以及数据审核模块,所述数据解析模块将非结构化数据解析成结构化数据,该数据解析模块包括版面识别单元、表格语义分析单元以及表格语义解析单元,所述版面识别单元用于获取原始金融数据长文本对的文档篇章结构信息,所述表格语义分析单元用于分析版面识别单元获取的表格数据并按预定义的数据模型组织存储数据,所述文本语义解析用于解析版面识别单元获取的段落、标题数据并按预定义的数据模型组织存储数据;所述数据审核模块对结构化数据进行审核处理,该数据审核模块包括错别字审查单元、一致性审核单元、勾稽关系审核单元以及文本格式审核单元,其中,所述错别字审查单元根据NLP模型检测潜在错别字得到候选字符及概率并结合领域字典针对段落、标题数据查找错别字提出纠正建议,所述一致性审核根据会计准则对表格数据进行审核,所述勾稽关系审核单元根据会计准则提取文本中存在的勾稽关系规则,并由该些勾稽关系规则进行数据审核;所述文本格式审核单元根据标题和文本的目录结构,根据序号连续性和关联序号规则进行格式审核,结合图1,该复核系统通过数据解析模块进行视觉判断,实现表格识别与分析、篇章结构识别以及文本识别与分析并对数据进行结构化处理,基于结构化处理后的数据,由数据审核模块结合对专业知识自学习后的规则引擎和场景配置对文档进行复核输出处理结果。
其中,在篇章结构识别的过程中,该系统先使用语言模型在大规模通用领域语料以及金融领域语料训练,使模型学到字在上下文中含有丰富语义信息的表征。除此之外还设计了基于规则的特征抽取模块抽取可以表示某行文本位置,相邻文本,对齐方式等特点的特征,最后将语言模型和特征抽取模块抽取的特征拼接后使用fusion层融合并分类,最后将无序的字符串还原出实际的结构;在语义分析过程中,先将原文输入在大规模通用语料和金融语料上训练的预训练模型获取字基本的表征,再融合候选字信息,然后使用训练好的纠错模型预测对应位置正确字符;最后还根据现有词典,领域词库等外部知识对预测结果进行纠正进一步提高纠错效果;在关键信息抽取方面,先使用训练的实体识别模型抽取对应实体,将抽出的实体输入事件抽取模型组合成具体事件;另外,在原始表格存在冗余信息,不能直接使用,还需要使用模型抽取关键信息,去除冗余信息,我们先使用预先训练好的表格识别模型,将表格结构以及表格内单元格的文字提取出来,再将表格结构信息例如标题,单元格位置等等输入表格信息抽取模型,最后得到下游任务可直接使用的表格信息。
接下来,具体介绍每一单元对数据处理的具体步骤,在本实施例中,输入文档以PDF格式文档为例。
参阅图2,所述版面识别单元获取原始金融数据长文本对的文档篇章结构信息的具体步骤为:S10:将PDF格式文本按页转换为图片格式文本,并进行拉伸以及二值化预处理;S11:根据CV模型检测预处理后的图片格式文本,获取表格、页眉、页脚、图片、公式数据;S12:提取表格、页眉、页脚、图片、公式数据以外的文字数据,并将该些文字数据按页,行顺序组织;S13:根据NLP模型将提取的文字数据划分为段落数据和标题数据;S14:整合输出提取的数据保存至数据库中。
参阅图3,所述表格语义分析单元对表格数据分析的具体步骤为:S20:获取S14中的表格数据;S21:对表格数据进行预处理,包括:数据清洗和集合划分;S22:根据NLP模型解析预处理后的表格数据并提取表格数据关系;
S23:将表格数据以及表格数据关系按预定义的数据模型组织输出并保存至数据库中;
参阅图4,所述文本语义解析单元解析段落数据和标题数据的具体步骤为:S30:获取S14中的段落数据和标题数据;S31:对段落数据和标题数据进行预处理,包括:数据清洗、数据长度切割、定位数据提取位置,以及数据字型特征转换为预定义字型格式;S32:根据NLP模型解析预处理后的段落数据和标题数据,提取数据文本中的关键信息、相关必要信息以及关键信息之间的关联;S33:将解析后的段落数据和标题数据按预定义的数据模型组织输出并保存至数据库中。
参阅图5,所述错别字审查单元对段落数据和标题数据中错别字查找的具体步骤为:S40:读取S33中的段落数据和标题数据;S41:对段落数据和标题数据进行预处理,包括:数据清洗,非敏感文本数据提取;S42:根据NLP模型检测潜在错别字得到候选字符以及候选字符概率并输出错别字模型;S43:根据金融领域的领域字典以及错别字模型,筛选错别字以及提出纠正建议并输出;S44:将输出数据处理为预定义格式数据并展示。
参阅图6,所述一致性审核单元审核表格数据的具体步骤为:S50:读取S23中的表格数据;S51:将表格数据区分为财务摘要表、财务主表和财务附注表;S52:根据会计准则提取一致性审核规则,按规则进行数据匹配;S53:将匹配后的数据按预定格式输出并存保存至数据库并输出审核结果。
参阅图7,所述勾稽关系审核审核表格数据的具体步骤为:S60:读取S23中的表格数据和S33中的标题数据;S61:根据语义分析结果和标题数据,对表格数据进行归类;S62:根据表格数据勾稽关系规则,对表格数据进行关系勾稽;S63:将勾稽关系的表格数据按预定义格式输出保存至数据库并输出审核结果。
参阅图8,所述文本格式审核单元进行格式审核的具体步骤为:S70:读取文档的目录结构,以及S23的表格数据和S33的标题数据;S71:对标题数据进行层级格式化;S72:对格式化后的标题数据,进行连续性审核;S73:提取表格数据中引用的序号和标题格式化进行审核;S74:将审核后的数据按预定义格式输出保存至数据库并输出审核结果。
本发明提供的金融长文本复核系统,基于计算机视觉算法可解析各种类型的复杂表格,其中,该些复杂表格的形式包括word、pdf以及图片格式的表格,通用性强,基于NLP深度学习模型进行文本信息提取,在实现多维度信息提取的同时提高系统鲁棒性。
本发明提供的金融长文本复核系统,可供企业对自身的财务指标报告进行自行复核,另外,其他金融机构也可以从现有材料中下载各个公司的年度报告等进行解析以深入研究获取投资信息。
以上仅是本发明的优选实施方式,应当指出的是,上述优选实施方式不应视为对本发明的限制,本发明的保护范围应当以权利要求所限定的范围为准。对于本技术领域的普通技术人员来说,在不脱离本发明的精神和范围内,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种金融长文本复核系统
- 一种基于BERT-CNN的金融文本分类方法及系统