一种多目标混合流水车间调度方法及系统
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及人工智能技术领域,尤其涉及一种多目标混合流水车间调度方法及系统。
背景技术
混合流水车间调度问题(Hybrid Flowshop Scheduling Problem,HFSP)作为流水车间调度问题的一个分支,因其重要的理论价值和实用价值引起了研究人员的广泛关注。HFSP常见于电子、家具、纺织、石化、制药等各种柔性制造车间中。HFSP要根据生产约束确定各阶段的作业顺序和机器分配,即使是在非常小规模的问题实例上,也被证明是NP(Non-deterministic Polynomial)困难的。
在目前大多数关于混合流水车间调度问题的研究中,作业是不能被分割的,即每个作业在某一特定阶段完成之前不能转移到下游阶段。然而,在许多现实场景中,这将对生产效率产生负面影响,在这些场景中,一个作业是由一系列相同的加工单元组成的。批量流技术能够缩短生产周期,但它也有实现成本,例如子批的运输和管理。也就是说,子批的数量越大,最大完工时间就可能越小,但相应的运输成本会增加。因此,考虑到实际中子批的运输成本,子批的总量会受到限制。总而言之,最大完工时间与子批总数之间通常存在着一种权衡关系,是流水车间调度的主要优化目标。
鉴于多目标流水车间调度优化问题带来的巨大挑战,人们提出了许多解决方案。其中,多目标进化算法(Multi-Objective Evolutionary Algorithms,MOEAs)备受关注,MOEAs有能力在一次运行中得到一组近似帕累托最优解,文献研究显示出了它们的优越性能。但是,不存在一种适用于所有优化问题的通用算法。因此,有必要针对当前问题对算法进行配置,以提高算法性能。众所周知,MOEA的性能高度依赖于算法参数的配置,包括数值参数和类别参数。一方面,由于传统的配置方法(手动或模拟调优)往往受到以往经验的限制,难以获得最优算法配置,研究算法组件如何交互也很困难。另一方面,整个过程可能是非常耗时和乏味的。因此,寻找一种高效的自动算法设计方法,消除从业者对先验知识的依赖,完成MOEA的自动配置具有重要的现实意义。而自动算法设计(Automated AlgorithmDesign,AAD)方法逐渐成为缓解这些局限性的研究领域。
F-Race方法是由Birattari等人提出的一种AAD方法,可以同时优化数值参数和类别参数。它的灵感来自Hoeffding Race,最初提出用于机器学习中的模型选择。F-Race在一系列测试实例中持续评估一组给定的算法配置,一旦获得足够的统计证据,就会消除劣质配置。在F-Race中,是通过全因子设计获得初始候选构型的。但是,当参数数量较多且每个参数取值范围较大时,全因子设计可能会变得不实用且计算量有限。为了缓解这个问题,Balaprakash等人提出了F-Race的迭代应用,称为迭代F-Race(Iterated F-Race,I/F-Race)。通过学习迭代过程中的有用信息和竞争机制,I/F-Race可以识别配置空间中的潜在区域,并找到最优的算法配置。
自提出以来,I/F-Race已经成为一种极具竞争力的AAD方法。基于不同的功能测试集,成功配置了高性能的连续优化求解器。也有人采用I/F-Race配置蚁群算法来解决不同的旅行商问题。
I/F-Race同样存在着局限性。在一次F-Race迭代中,给定一组测试实例,在统计学上比其它配置表现差的配置会被抛弃。已经使用过的测试实例在后续F-Race迭代中不能够继续使用。而我们知道,在一个实例上表现优异的配置可能在其它实例上表现不佳。因此,应该保留配置的历史评估信息,以便全面评估算法配置。
现有技术至少存在以下不足:
1.现有方法没有充分考虑可变分批这一特性,当不同批次间具有启动作业时,因为要频繁地进行切换,严重影响加工效率。
2.现有方法在一次F-Race迭代中,给定一组测试实例,已经使用过的测试实例在后续F-Race迭代中不能够继续使用,因此不能够找到全面匹配考虑可变分批的混合流水车间调度问题特性的算法配置。
发明内容
本发明致力于解决现有技术中存在的考虑变分批的多目标混合流水车间调度问题,同时优化最大完工时间和子批总数。本发明提供了一种多目标混合流水车间调度方法,根据可变分批以及实际混合流水车间地生产特点,建立了考虑变分批的多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;采用可配置的MOEA(CMOEA)框架,在后续F-Race迭代中在利用F-Race学习模型生成新的配置之前,首先使用之前F-race中评估的配置作为训练数据,构建CART(Class and Regression Tree)模型。为了利用历史信息提高采样质量,该模型随后被用于预测新配置的性能。只有那些被预测为有潜力的配置才能进入下一次F-Race迭代中。F-Race学习模型和CART模型均基于实时数据,共同承担着寻找最优算法配置的核心任务,实现最大完工时间和子批总数优化的调度目标。本发明利用实时数据,能够直观反映各参数对算法配置性能的影响。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
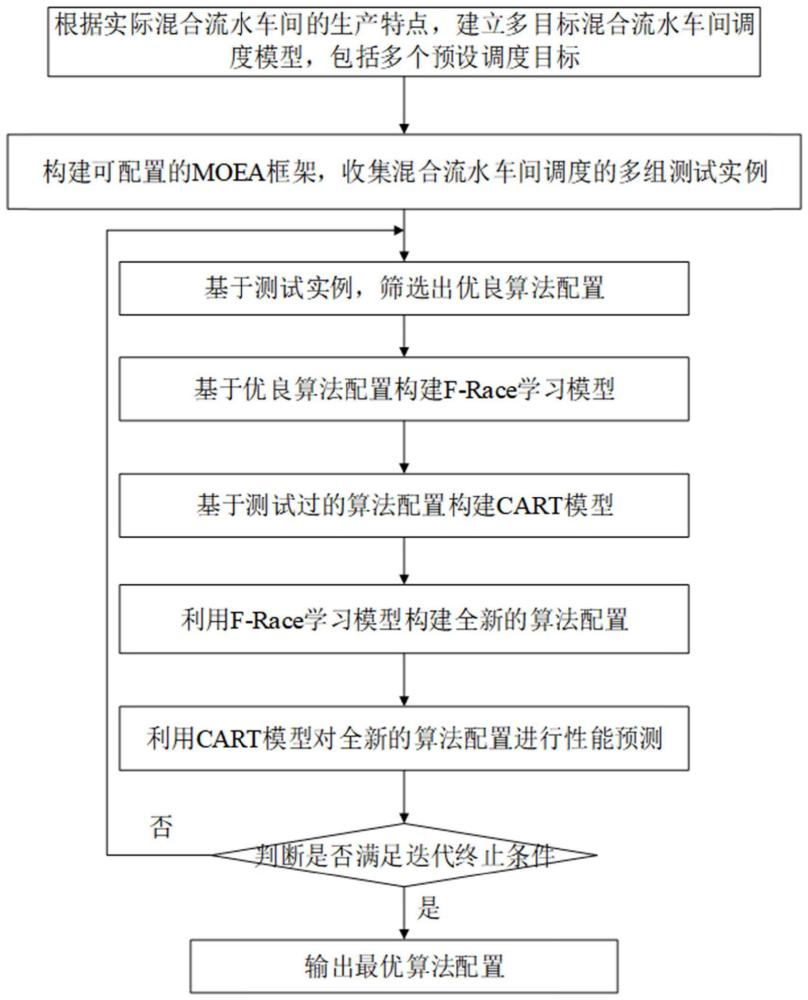
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
优选地,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
优选地,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
优选地,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
优选地,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量。
优选地,根据配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群,具体包括:
根据配置的适应度值评估方法的不同,通过对种群中选择的交配个体进行可配置的协同方法,产生一个大小为预设种群规模ps的子代种群,具体为:
如果适应度值评估方法为基于分解的方法DBM,则每个个体在邻域大小为预设邻域规模ns的邻域中选择交配对象,执行可配置的协同方法产生后代,直至产生一个大小为预设种群规模ps的子代种群;
如果适应度值评估方法为基于非支配排序的方法NSBM和基于指标的方法IBM,则在预设锦标赛规模ts的锦标赛规则中选择两个交配个体,执行协同方法产生后代,重复该过程预设种群规模ps次,产生一个大小为预设种群规模ps的子代种群。
优选地,利用解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对配置的适应度值评估方法的不同,进行相应的种群评估,具体包括:
利用可配置的解码方法获得种群P和子代种群OP中个体的目标值;
根据配置的适应度值评估方法的不同使用对应的适应度值评估方法为其分配适应度值:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM进行适应度值评估;
如果适应度值评估方法为基于非支配排序的方法NSBM,则采用基于非支配排序的方法NSBM进行适应度值评估;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM进行适应度值评估;
优选地,针对配置的适应度值评估方法的不同,进行相应的环境选择,具体为根据配置的适应度值评估方法的不同通过对应的不同环境选择方法,利用子代种群OP更新种群P,具体包括:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM利用子代种群OP更新种群P,将子代种群OP中每个个体与种群P中具有相同权重向量及其邻域个体进行比较,如果子代种群OP中的个体具有更好的适应度值,则将种群P中的个体更新为子代种群OP中的个体;
如果适应度值评估方法为基于非支配排序的方法NSBM,则将子代种群OP合并到种群P中,按快速非支配排序方法对种群中的个体进行排序,保留前预设种群规模ps个个体在种群P中;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM,将子代种群OP合并到种群P中,将适应度值最低的个体依次去除,直到种群P中剩余预设种群规模ps个个体。
优选地,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
本发明提供了一种多目标混合流水车间调度系统,使用上述的任一多目标混合流水车间调度方法,包括多台流水车间待调度设备和控制调度模块;
控制调度模块,根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;基于测试实例,筛选优良算法,基于优良算法配置构建F-Race学习模型;基于测试过的算法配置构建CART模型;利用F-Race学习模型构建全新的算法配置;利用CART模型对全新的算法配置进行性能预测;基于预测为优良的算法反复进行迭代,得到最优算法配置;根据最优算法配置选择流水车间待调度设备,发出调度指令;
流水车间待调度设备收到控制调度模块发出的调度指令后执行相应的操作。
与现有技术相对比,本发明的有益效果如下:
(1)本发明将可变分批引入到HFSP中,除了考虑批次顺序和机器分配之外,同时考虑了每个批次的批次分割(即子批数量和子批规模),实现了同时优化最大化完工时间和子批总数。
(2)本发明在可配置算法框架的基础上,引入了CART增强的I/F-Race模型自动构造高性能的MOEA,通过与其它方法的对比,自动生成的MOEA的表现是非常突出的,能够使最大完工时间和子批总数达到更好的平衡。
(3)本发明开发的CART模型用于预测生成的新配置的性能,只有当新的配置的性能预测为“优良”时,它才会有机会被选中。否则,如果其性能预测为“劣质”,则不予理会。所开发的方法有两方面的优点:一是充分利用优化过程中产生的实时数据,二是直观反映参数设置对配置性能的影响,能够挖掘考虑可变分批的混合流水车间调度问题特性。
(4)本发明在局部搜索阶段,采用可变邻域下降策略,如果个体连续更新失败的次数达到预设的最大连续更新失败次数,这意味着当前的邻域结构可能没有再被利用的潜力,那么它将在下一代切换到邻域结构集中的下一个结构,本发明能够系统地在各个邻域结构之间进行切换,从而充分利用各个邻域结构,避免浪费计算资源,能够针对考虑可变分批的混合流水车间调度问题解空间进行快速、全面、高效地搜索。
(5)本发明在在种群重启阶段,当通过协作方法和局部搜索方法进行多次连续更新而未能成功更新种群中的个体时,使用重启方法来生成替换个体的替代品。否则,个体保持不变,能够帮助个体跳出局部最优僵局,能够跳出考虑可变分批的混合流水车间调度问题的局部最优解。
附图说明
图1是本发明的一个实施例的多目标混合流水车间调度方法流程图。
具体实施方式
下面结合附图1,对本发明的具体实施方式作详细的说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
根据本发明的一个具体实施方案,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
根据本发明的一个具体实施方案,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
根据本发明的一个具体实施方案,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
根据本发明的一个具体实施方案,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量。
根据本发明的一个具体实施方案,根据配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群,具体包括:
根据配置的适应度值评估方法的不同,通过对种群中选择的交配个体进行可配置的协同方法,产生一个大小为预设种群规模ps的子代种群,具体为:
如果适应度值评估方法为基于分解的方法DBM,则每个个体在邻域大小为预设邻域规模ns的邻域中选择交配对象,执行可配置的协同方法产生后代,直至产生一个大小为预设种群规模ps的子代种群;
如果适应度值评估方法为基于非支配排序的方法NSBM和基于指标的方法IBM,则在预设锦标赛规模ts的锦标赛规则中选择两个交配个体,执行协同方法产生后代,重复该过程预设种群规模ps次,产生一个大小为预设种群规模ps的子代种群。
根据本发明的一个具体实施方案,利用解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对配置的适应度值评估方法的不同,进行相应的种群评估,具体包括:
利用可配置的解码方法获得种群P和子代种群OP中个体的目标值;
根据配置的适应度值评估方法的不同使用对应的适应度值评估方法为其分配适应度值:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM进行适应度值评估;
如果适应度值评估方法为基于非支配排序的方法NSBM,则采用基于非支配排序的方法NSBM进行适应度值评估;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM进行适应度值评估;
根据本发明的一个具体实施方案,针对配置的适应度值评估方法的不同,进行相应的环境选择,具体为根据配置的适应度值评估方法的不同通过对应的不同环境选择方法,利用子代种群OP更新种群P,具体包括:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM利用子代种群OP更新种群P,将子代种群OP中每个个体与种群P中具有相同权重向量及其邻域个体进行比较,如果子代种群OP中的个体具有更好的适应度值,则将种群P中的个体更新为子代种群OP中的个体;
如果适应度值评估方法为基于非支配排序的方法NSBM,则将子代种群OP合并到种群P中,按快速非支配排序方法对种群中的个体进行排序,保留前预设种群规模ps个个体在种群P中;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM,将子代种群OP合并到种群P中,将适应度值最低的个体依次去除,直到种群P中剩余预设种群规模ps个个体。
根据本发明的一个具体实施方案,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
本发明提供了一种多目标混合流水车间调度系统,使用上述的任一多目标混合流水车间调度方法,包括多台流水车间待调度设备和控制调度模块;
控制调度模块,根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;基于测试实例,筛选优良算法,基于优良算法配置构建F-Race学习模型;基于测试过的算法配置构建CART模型;利用F-Race学习模型构建全新的算法配置;利用CART模型对全新的算法配置进行性能预测;基于预测为优良的算法反复进行迭代,得到最优算法配置;根据最优算法配置选择流水车间待调度设备,发出调度指令;
流水车间待调度设备收到控制调度模块发出的调度指令后执行相应的操作。
实施例1
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
实施例2
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
其中,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
其中,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对可配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
实施例3
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
其中,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
其中,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对可配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
其中,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
其中,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量;
其中,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
实施例4
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
其中,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
其中,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对可配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
其中,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
其中,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量;
其中,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
其中,根据配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群,具体包括:
根据配置的适应度值评估方法的不同,通过对种群中选择的交配个体进行可配置的协同方法,产生一个大小为预设种群规模ps的子代种群,具体为:
如果适应度值评估方法为基于分解的方法DBM,则每个个体在邻域大小为预设邻域规模ns的邻域中选择交配对象,执行可配置的协同方法产生后代,直至产生一个大小为预设种群规模ps的子代种群;
如果适应度值评估方法为基于非支配排序的方法NSBM和基于指标的方法IBM,则在预设锦标赛规模ts的锦标赛规则中选择两个交配个体,执行协同方法产生后代,重复该过程预设种群规模ps次,产生一个大小为预设种群规模ps的子代种群。
实施例5
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
其中,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
其中,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对可配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
其中,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
其中,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量;
其中,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
其中,利用解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对配置的适应度值评估方法的不同,进行相应的种群评估,具体包括:
利用可配置的解码方法获得种群P和子代种群OP中个体的目标值;
根据配置的适应度值评估方法的不同使用对应的适应度值评估方法为其分配适应度值:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM进行适应度值评估;
如果适应度值评估方法为基于非支配排序的方法NSBM,则采用基于非支配排序的方法NSBM进行适应度值评估;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM进行适应度值评估。
实施例6
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
其中,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
其中,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对可配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
其中,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
其中,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量;
其中,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
其中,针对配置的适应度值评估方法的不同,进行相应的环境选择,具体为根据配置的适应度值评估方法的不同通过对应的不同环境选择方法,利用子代种群OP更新种群P,具体包括:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM利用子代种群OP更新种群P,将子代种群OP中每个个体与种群P中具有相同权重向量及其邻域个体进行比较,如果子代种群OP中的个体具有更好的适应度值,则将种群P中的个体更新为子代种群OP中的个体;
如果适应度值评估方法为基于非支配排序的方法NSBM,则将子代种群OP合并到种群P中,按快速非支配排序方法对种群中的个体进行排序,保留前预设种群规模ps个个体在种群P中;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM,将子代种群OP合并到种群P中,将适应度值最低的个体依次去除,直到种群P中剩余预设种群规模ps个个体。
实施例7
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度方法进行详细说明。
本发明提供了一种多目标混合流水车间调度方法,包括如下步骤:
根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;
构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;
按照以下过程进行迭代,得到最优算法配置:
步骤01:基于测试实例,筛选出优良算法配置;根据优化指标的预设阈值确定算法的优良;
步骤02:基于优良算法配置构建F-Race学习模型;
步骤03:基于测试过的算法配置构建CART模型;
步骤04:利用F-Race学习模型构建全新的算法配置;
步骤05:利用CART模型对全新的算法配置进行性能预测;
步骤06:判断是否满足迭代终止条件,如果满足,输出最优算法配置;如果不满足,则基于预测为性能优良的算法配置进入下一次迭代,执行步骤01;
其中,F-Race学习模型用于生成新的算法配置,CART模型用于预测新算法配置的性能。两种模型共同承担着优化算法配置的任务;
其中,可配置的MOEA框架根据当前配置的适应度评估算法,选用种群进化方法,并采用协同搜索、局部搜索和种群重启策略,输出当前实例的帕累托最优解;适应度评估算法包括:基于分解的方法DBM、基于非支配排序的方法NSBM和基于指标的方法IBM。
其中,根据优化过程中产生的实时数据实例构建CART模型包括:以评估过的算法配置为训练数据,以参数值为特征,评估结果为标签,根据优化指标的预设阈值,确定标签类型,标签类型包括:“优良”和“劣质”。
其中,可配置MOEA框架算法包括如下步骤:
根据可配置的初始化方法初始化种群P;
迭代过程包括:
根据可配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群OP;
利用可配置的解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对可配置的适应度值评估方法的不同,进行相应的种群评估;
针对配置的适应度值评估方法的不同,进行相应的环境选择;
采用可变邻域下降策略进行局部搜索,如果使用邻域结构的连续失败更新次数达到预设的最大连续更新失败次数,则邻域结构将切换到下一个领域;
如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法;
若达到迭代终止条件,则迭代结束,输出进化过程中找到的帕累托非支配解,否则返回迭代过程。
其中,对于F-Race学习模型产生的新配置,采用CART模型预测配置性能,具体包括如下步骤:
步骤S001:根据评估过的算法配置构建CART模型;
步骤S002:对F-Race学习模型进行采样,生成一系列新的算法配置;
步骤S003:利用CART模型对新的算法配置进行预测,预测为“优良”的算法配置保留,预测为“劣质”的算法配置抛弃;
步骤S004:挖掘预测为“优良”的算法配置信息,生产新的F-Race学习模型。
其中,初始化种群过程中,如果适应度值评估方法为基于分解的方法DBM,则生成一组均匀分布的权重向量,并且给每个个体分配一个唯一的权向量;
其中,如果使用协作搜索和邻域结构的连续失败更新次数小于最大连续更新失败次数,对种群P中的每个个体执行种群重启方法,具体为使用可配置的种群重启方法来生成替换种群P中的每个个体的替代品,否则,种群P中的个体保持不变。
其中,根据配置的适应度值评估方法的不同,在不同邻域内选择交配个体生成子代种群,具体包括:
根据配置的适应度值评估方法的不同,通过对种群中选择的交配个体进行可配置的协同方法,产生一个大小为预设种群规模ps的子代种群,具体为:
如果适应度值评估方法为基于分解的方法DBM,则每个个体在邻域大小为预设邻域规模ns的邻域中选择交配对象,执行可配置的协同方法产生后代,直至产生一个大小为预设种群规模ps的子代种群;
如果适应度值评估方法为基于非支配排序的方法NSBM和基于指标的方法IBM,则在预设锦标赛规模ts的锦标赛规则中选择两个交配个体,执行协同方法产生后代,重复该过程预设种群规模ps次,产生一个大小为预设种群规模ps的子代种群。
其中,利用解码方法通过协同搜索获得种群P和子代种群OP中个体的目标值,并针对配置的适应度值评估方法的不同,进行相应的种群评估,具体包括:
利用可配置的解码方法获得种群P和子代种群OP中个体的目标值;
根据配置的适应度值评估方法的不同使用对应的适应度值评估方法为其分配适应度值:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM进行适应度值评估;
如果适应度值评估方法为基于非支配排序的方法NSBM,则采用基于非支配排序的方法NSBM进行适应度值评估;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM进行适应度值评估。
其中,针对配置的适应度值评估方法的不同,进行相应的环境选择,具体为根据配置的适应度值评估方法的不同通过对应的不同环境选择方法,利用子代种群OP更新种群P,具体包括:
如果适应度值评估方法为基于分解的方法DBM,则采用基于分解的方法DBM利用子代种群OP更新种群P,将子代种群OP中每个个体与种群P中具有相同权重向量及其邻域个体进行比较,如果子代种群OP中的个体具有更好的适应度值,则将种群P中的个体更新为子代种群OP中的个体;
如果适应度值评估方法为基于非支配排序的方法NSBM,则将子代种群OP合并到种群P中,按快速非支配排序方法对种群中的个体进行排序,保留前预设种群规模ps个个体在种群P中;
如果适应度值评估方法为基于指标的方法IBM,则采用基于指标的方法IBM,将子代种群OP合并到种群P中,将适应度值最低的个体依次去除,直到种群P中剩余预设种群规模ps个个体。
实施例8
根据本发明的一个具体实施方案,结合附图,对本发明的多目标混合流水车间调度系统进行详细说明。
本发明提供了一种多目标混合流水车间调度系统,使用上述的任一多目标混合流水车间调度方法,包括多台流水车间待调度设备和控制调度模块;
控制调度模块,根据实际混合流水车间的生产特点,建立多目标混合流水车间调度模型,包括最大完工时间和子批总数两个目标;构建可配置的MOEA框架,收集混合流水车间调度的多组测试实例;基于测试实例,筛选优良算法,基于优良算法配置构建F-Race学习模型;基于测试过的算法配置构建CART模型;利用F-Race学习模型构建全新的算法配置;利用CART模型对全新的算法配置进行性能预测;基于预测为优良的算法反复进行迭代,得到最优算法配置;根据最优算法配置选择流水车间待调度设备,发出调度指令;
流水车间待调度设备收到控制调度模块发出的调度指令后执行相应的操作。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均包含在本发明的保护范围之内。
- 一种多目标混合零空闲置换流水车间调度方法及系统
- 一种多目标分布式混合流水车间调度方法