基于行列式点过程的数据服务推荐结果多样化方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于数据服务推荐领域,涉及一种面向云原生场景基于行列式点过程的数据服务推荐结果多样化方法。
背景技术
当下云原生时代,企业上云对许多公司来说已经变成一种默认行为。云原生概念的出现,使企业不再需要去构建基础设施。如何基于云组件做适配,如何合理使用云的弹性、计算存储分离等功能也变的至关重要。传统的厂商需要进行数字化转型,其面临的业务需要互联网化,要解决高并发、大吞吐等问题,势必要采用互联网架构。越来越多的企业选择提供以服务为基础的应用。随着数字化时代的到来,大量的数据被生成、收集和存储,这些数据对于组织和企业来说具有巨大的价值。数据服务的目标是通过提供有效的方法来管理、分析和利用这些数据,以满足用户的需求。"DAAS"是指"数据作为服务"(Data as aService)。它是一种云计算模式,其中数据提供商通过云平台向客户提供数据访问和管理的服务。它提供了一种新的方式来处理和管理数据,使得用户无需自己购买、配置和维护硬件和软件设施。数据作为服务的提供商将数据存储在云平台上,并通过网络提供数据访问和管理功能。以服务作为业务核心,为开发者提供计算与数据资源,并为企业提供成熟的云软件解决方案。利用开放服务平台,开发者可以通过对可重复使用的,可替换的第三方服务进行组合来快速满足用户的复杂需求。
Mashup服务是一种典型的服务组合模式,通过快速组合现有的Web Api,来生成新的Api,因其效率高、使用方便的特点得到开发者的青睐并快速发展。现存候选Api数量的快速增长以及大量相似功能的服务提升了组合服务开发者选择合适Api的难度。面对这些挑战,服务推荐技术应运而生。现有的服务推荐技术大多关注推荐的准确程度,以协同过滤为基础的推荐方法以使用者与项目间的交互信息来定义使用者的表现,以内容为基础的方法则关注项目间的相关性信息,实现以关联与替换为导向的推荐方法。这些方法本质是基于表现的相似性实现的推荐方法。然而,这些以相似度为基础的方法往往会导致次优结果,基于内容的推荐方法倾向于提供满足用户当前需求的项目信息而忽略项目主题的广度,协同过滤为主的方法会受到长尾问题的影响,为了满足准确度而选择流行度高的项目。现今,多样性(diversity)同样被认为是提高用户满意度的重要因素。多样化的推荐结果能拓展用户接触的项目广度,提升用户发现自己感兴趣项目的概率;另一方面,多样化结果可以帮助企业或服务提供方提高产品的可见程度并发掘潜在的用户兴趣。在真实的服务推荐场景中,多样化推荐的需求也是需要重视的。
对于多样化推荐来说,多样性可体现在个人层面(Individual level)与总体层面(Aggregate level)。对服务推荐来说,为提升服务调用者选择时的用户体验,需要考虑的应是个人层面,也就是单次推荐结果所包含的服务功能的多样性。通过提高个体多样性,来提高推荐列表中项目间的新颖程度,最终提升用户潜在希望项目曝光的概率。为了使已有的推荐列表中的项目排序在相关性和多样性之间取得平衡,最通用的方式即启发式的后处理(post-processing)方法,即根据服务功能信息对现有的服务推荐序列进行考虑同时相关性和多样性的重排序工作。
发明内容
为了克服现有技术的不足,为了更好地发现用户的潜在兴趣,在已有的服务推荐序列结果上,本发明提供了一种面向云原生场景基于行列式点过程的数据服务推荐结果多样化方法,首先基于现有的服务功能信息,设计了两个服务数据辅助矩阵;在此基础上,构建行列式点过程必须的核矩阵,并利用调节参数控制服务间的相关性与多样性;考虑行列式点过程在常规贪心计算策略下时间复杂度较高的问题,使用一种基于乔列斯基分解的快速迭代方法对服务推荐序列进行处理,完成服务推荐结果的多样化处理。
本发明所采用的技术方案是:
一种基于行列式点过程的数据服务推荐结果多样化方法,所述方法包括以下步骤:
第一步,构建服务推荐分数辅助矩阵与服务功能相似度辅助矩阵;
第二步,构建行列式点过程计算所需服务信息核矩阵,处理行列式计算结果,优化计算过程,过程如下:
2.1行列式点过程是一种概率模型,用于建模具有排斥性质的离散点集,在核矩阵的基础上利用元素集合特征计算子集选择概率,利用服务推荐分数辅助矩阵H
其中exp表示对矩阵中的所有元素进行自然指数处理,
2.2设A′为待计算子集概率的Api集合,A′为整体候选Api集合A的子集。根据行列式点过程的计算思想,设定子集概率计算方式:
其中P表示概率信息,det()表示行列式计算过程,∝表示成正比,原始核矩阵
2.3对行列式结果取对数进行计算,以对子集概率进行大小比较:
其中log()表示10为底的对数操作,
2.4以步骤2.3给出的子集概率大小比较方法,给出对应的贪心策略每轮计算过程:
其中Ra
2.5将Da
2.6进行步骤2.4的计算过程,将每轮次输出的a
2.7重复步骤2.6,直到Da
第三步,使用乔列斯基分解,在贪心迭代过程中快速判断,生成多样化重排序的服务推荐结果。
进一步,所述第一步的过程如下:
1.1定义初始的服务推荐结果集,包括组合服务Mashup m和m对应的单条推荐结果Api集合Ra
1.2将Mashup m的特征表示设为se
1.3利用向量乘积,计算Mashup m与Api a之间的服务推荐分数:
f
其中T表示向量的转置操作;
1.4计算该Mashup组合服务调用序列对应的所有Api分数的平均值,并对所有分数值进行归一化处理:
1.5构建服务推荐分数辅助矩阵H
其中Diag表示对角矩阵,其对角元素为Mashup m与被推荐的Api a之间的归一化关联分数
1.6计算服务间的训练相似度,以两个Api或Mashup服务的嵌入向量的点乘作为相似度计算结果:
其中a
1.7计算服务间的先验信息相似度,以服务描述文档与服务功能标签为相似度计算的基础,计算服务描述文档之间的相似度,首先计算Api服务描述文档间的相似度,然后计算Mashup服务描述文档间的相似度:
其中cos()表示余弦相似度,
1.8分别计算Api服务标签间的相似度与Mashup服务标签间的相似度:
其中,m
1.9将功能描述相似度和标签相似度中较大的结果作为服务间的先验信息相似度:
其中
1.10将服务间训练相似度与先验信息相似度中较大的结果作为服务间的整体相似度信息:
1.11基于步骤1.10的相似度计算结果,构建Api间的服务相似度辅助矩阵
采用了柔性最大化方式对相似度信息进行归一化处理,将结果以
再进一步,所述第三步的过程如下:
3.1设置分解因子存储集合D,置为空集合;
3.2对单条推荐结果对应的Api集合Ra
3.3对a
3.4将
3.5设置行向量存储集合C,初始置为空集合;
3.6对Ra
3.7完成遍历,完成对集合C的初始化;
3.8设置多样化重排序列集合Da′
3.9设置每轮次最大序号j,初始化为1,设置增量集合E,初始化为空集合;
3.10遍历Ra
3.11对a
其中T表示向量转置,c
3.12完成遍历,输出增量值集合E;
3.13遍历集合E,将当前遍历增量值设为e
3.14根据e
c
其中[c
3.15结束遍历,完成更新;
3.16根据更新的分解因子,找到其对数值最大的结果:
其中Ra
3.17将步骤3.16输出的Api对应的序号赋值给j,将该Api存入序列集合Da′
3.18重复步骤3.10到步骤3.17,直到Da′
3.19输出服务推荐序列多样化重排结果Da′
本发明的有益效果主要表现在:(1)抓住服务推荐情景下的多样化需求,作为一种后处理方法,能在现有的服务推荐模型基础上进行多样化处理。(2)使用针对服务推荐优化的行列式点过程方法,设计基于两个辅助矩阵的服务信息核矩阵,同时考虑服务间的功能相关性与多样性。(3)利用优化的基于分解因子与行向量的求解方法,对多样化过程进行优化,减少每次迭代的计算消耗。(4)针对现有以推荐精度作为指标的服务推荐算法,进行多样性需求的推荐补充。
附图说明
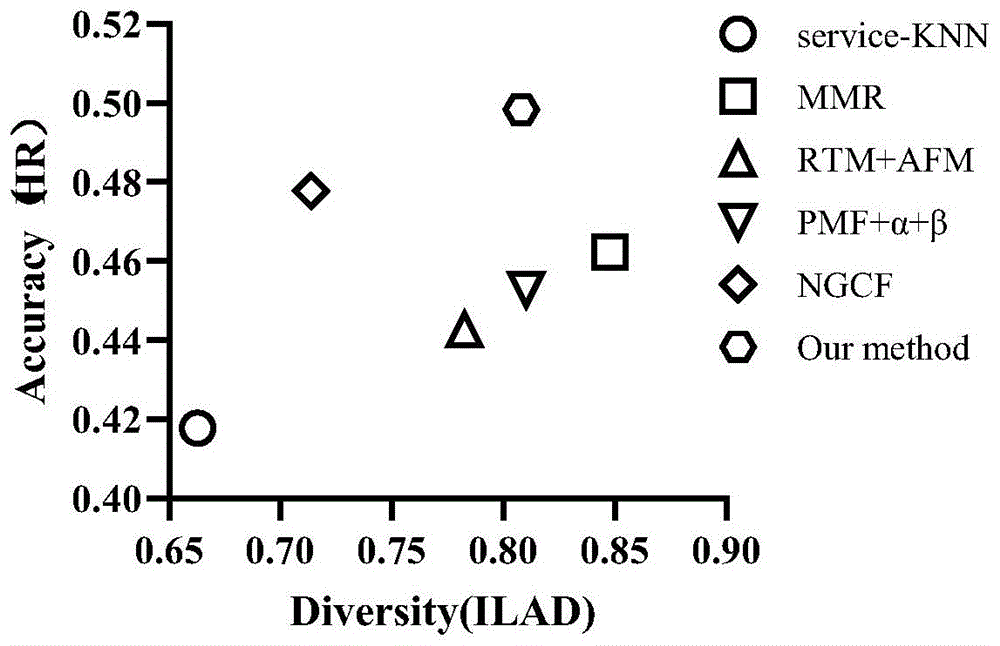
图1是多种服务推荐方法准确度与多样性结果坐标关系示意图
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1,一种基于行列式点过程的数据服务推荐结果多样化方法,所述方法包括以下步骤:
第一步、构建服务推荐分数辅助矩阵与服务功能相似度辅助矩阵,过程如下:
1.1定义初始的服务推荐结果集,包括组合服务Mashup m和m对应的单条推荐结果Api集合Ra
1.2基于精度的服务推荐模型能学习到服务的功能特征表示,通过步骤1.1中例举的服务推荐模型,可获取Mashup服务与Api的特征表示。将Mashup m的特征表示设为se
1.3利用向量乘积,计算Mashup m与Api a之间的服务推荐分数:
f
其中T表示向量的转置操作;
1.4计算该Mashup组合服务调用序列对应的所有Api分数的平均值,并对所有分数值进行归一化处理:
1.5构建服务推荐分数辅助矩阵H
其中Diag表示对角矩阵,其对角元素为Mashup m与被推荐的Api a之间的归一化关联分数
1.6计算服务间的训练相似度,以两个Api或Mashup服务的嵌入向量的点乘作为相似度计算结果:
其中a
1.7计算服务间的先验信息相似度,以服务描述文档与服务功能标签为相似度计算的基础,计算服务描述文档之间的相似度,首先计算Api服务描述文档间的相似度,然后计算Mashup服务描述文档间的相似度:
其中cos()表示余弦相似度,
1.8分别计算Api服务标签间的相似度与Mashup服务标签间的相似度:
其中,m
1.9将功能描述相似度和标签相似度中较大的结果作为服务间的先验信息相似度:
其中
1.10将服务间训练相似度与先验信息相似度中较大的结果作为服务间的整体相似度信息:
1.11基于步骤1.10的相似度计算结果,构建Api间的服务相似度辅助矩阵
采用了柔性最大化方式对相似度信息进行归一化处理,将结果以
第二步,构建行列式点过程计算所需服务信息核矩阵,处理行列式计算结果,优化计算过程,过程如下:
2.1行列式点过程是一种概率模型,用于建模具有排斥性质的离散点集,在核矩阵的基础上利用元素集合特征计算子集选择概率,利用步骤1.5生成的服务推荐分数辅助矩阵H
其中exp表示对矩阵中的所有元素进行自然指数处理,
2.2设A′为待计算子集概率的Api集合,A′为整体候选Api集合A的子集。根据行列式点过程的计算思想,设定子集概率计算方式:
其中P表示概率信息,det()表示行列式计算过程,∝表示成正比,原始核矩阵
2.3对行列式结果取对数进行计算,以对子集概率进行大小比较:
其中log()表示10为底的对数操作,
2.4以步骤2.3给出的子集概率大小比较方法,给出对应的贪心策略每轮计算过程:
其中Ra
2.5将Da
2.6进行步骤2.4的计算过程,将每轮次输出的a
2.7重复步骤2.6,直到Da
第三步,使用乔列斯基分解,在贪心迭代过程中快速判断,生成多样化重排序的服务推荐结果,过程如下:
3.1设置分解因子存储集合D,置为空集合;
3.2对单条推荐结果对应的Api集合Ra
3.3对a
3.4将
3.5设置行向量存储集合C,初始置为空集合;
3.6对Ra
3.7完成遍历,完成对集合C的初始化;
3.8设置多样化重排序列集合Da′
3.9设置每轮次最大序号j,初始化为1。设置增量集合E,初始化为空集合;
3.10遍历Ra
3.11对a
其中T表示向量转置,c
3.12完成遍历,输出增量值集合E;
3.13遍历集合E,将当前遍历增量值设为e
3.14根据e
c
其中[c
3.15结束遍历,完成更新;
3.16根据更新的分解因子,找到其对数值最大的结果:
其中Ra
3.17将步骤3.16输出的Api对应的序号赋值给j,将该Api存入序列集合Da′
3.18重复步骤3.10到步骤3.17,直到Da′
3.19输出服务推荐序列多样化重排结果Da′
下面以具体服务数据,分析发明的实际效果,步骤如下:
1)选取Mashup组合与Api数据集,数据集包含内容具体如表1所示。包括1423个Mashup以及与其拥有调用关系的1032个候选Api。对每个Mashup和Api,收集对应的功能描述文档和标签等信息,并对描述信息进行预先的分词操作,利用BERT预训练语言模型转为稠密向量。
表1
2)使用交叉验证(cross-validation)方法,利用20%的Mashup服务数量将所有服务分为5份,每次将其中一份作为测试集进行验证。
3)采用多种指标进行服务推荐效果评估。命中率(Hit rate,HR):
其中RecA
/>
其中N表示被推荐的服务数量,n表示推荐列表中按序第n位置的服务,IDCG为对所有推荐结果得到的DCG值进行求和的结果。列表内平均距离(intra-list averagedistance,ILAD),通过计算推荐列表中所有项目功能不相似程度的平均值,来反映整体的多样化程度。计算表示如下:
其中mean表示平均取值,Ra为对应的推荐列表,Sim则表示一化后的Api间相似度。通过1-Sim的计算来表示列表中项目的多样性程度。列表内最小距离(intra-listminimaldistance,ILMD)则通过计算每个列表的项目不相似程度的最小值,来评估推荐列表的多样化下限。计算表示如下:
其中min表示取最小值。
4)给出基本的对比方法,以评估本发明中方法的效果。
service-KNN:使用语言模型对服务功能描述进行向量化,利用相似度计算方法进行推荐,是一种典型的similarity-based的推荐方法。
MMR:最大边界相关算法,对服务推荐结果中项目的顺序进行修改,以考虑相关性与多样性的平衡。
RTM+AFM:利用因子分解积配合关系主题模型(Relation Topic Model)实现对服务间关联信息与特征表示的学习。
PMF+α+β:该方法同时考虑Api间关系,Mashup与Api之间关系与Api间的多样化程度三部分,并利用两个超参数α与β来控制各部分在目标函数中的强度。
NGCF:基于协同过滤与图神经网络的推荐方法,模型训练目标为更高的推荐准确度。
5)表2中给出本发明在各项指标上的效果。
表2
本发明所提的方法取得了较好的效果。相较于同样学习了图结构信息的NGCF,本发明提出的多样性优化方法大幅提高了推荐结果的多样性程度,在ILAD与ILMD指标上分别提升了11.6%与13.9%,同时在HR与NDCG指标上仍有4.2%与4.5%的提升,证明了本发明模型的特征学习能力。
为更直观地表现效果,图1给出了各方法在准确性和多样性上的指标坐标图,其中横坐标为ILAD值以表现多样性,纵坐标为HR值以表现准确度。本发明方法对应的结果坐标点在图中右上方,表示方法在多样性和准确度都能取得不错的效果,并在两种指标上都保持较好的平衡能力。
- 一种基于信息熵和改进行列式点过程的光谱波段选择方法
- 一种基于LSTM和多样化集束搜索的多样化API推荐方法及装置
- 基于行列式点过程学习的空域资源分配方法