一种基于互信息的混合属性加权离群检测算法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明一种基于互信息的混合属性加权离群检测算法,属于基于互信息的混合属性加权离群检测算法技术领域。
背景技术
离群检测是在数据中发现不符合预期行为的模式,为用户深入分析和理解数据提供支持。离群值在很多情况下隐含着重要的信息。近年来,离群检测被广泛应用于信用卡、保险、医疗等领域的欺诈检测、网络安全的入侵检测、健康系统的故障检测等。但目前大部分离群检测算法针对的是数值型或类单一据。在实际应用中,当面对混合属性数据时,通常采用离散化方法将数值属性转换为分类属性。这些操作都可能带来信息损失,因此会影响检测性能。
通常离群检测算法都要计算数据对象的离群得分。为了计算混合属性数据的离群得分,目前很多文献大都分别计算数据对象值空间和类上的离群得,然后得出混合属性数据的最终离群分。但是数值空间和分类空间离群得分的计算通常采用不同的度量机制,存在量纲不同问题。因此,需要综合计算数值空间和分类空间并归一化,以更适合进行综合对比评价。
许多情况下,分类数据和数值数据作为不同的属性存在于同一个数据集中。这被称为混合属性数据集。在混合属性数据集中,离群点的属性值不管在数值空间还是分类空间中都明显与其他对象不一致。在实际应用中,当面对混合属性数据时,通常将数值Spark集群环境下的分类数据离群检测及应用属性离散化,将所有数据按分类数据处理,使分类离群点检测算法适用于整个数据集。然而,将数值离散化可能会带来噪声或信息损失。不适当的离散化会影响检测性能。
因此,本发明主要解决混合属性数据的离群检测问题,通过互信息对属性间的相关性来对不同类型的属性进行加权计算进分析,提出了基于互信息的混合属性加权离群检测算法。
发明内容
本发明为了克服现有技术中存在的不足,所要解决的技术问题为:提供一种基于互信息的混合属性加权离群检测算法的改进。
为了解决上述技术问题,本发明采用的技术方案为:一种基于互信息的混合属性加权离群检测算法,包括如下步骤:
步骤一:计算混合属性数据集数值空间和分类空间中各个属性的权值:
步骤1.1:互信息计算:分别计算混合属性数据集中的离散变量和连续变量的互信息;
步骤1.2:混合属性加权机制计算:给定一个混合属性数据集,定义任意属性的权值度量为该属性到其他属性互信息的平均值;
步骤二:计算每个数据对象在数值空间中的离群得分;
步骤三:计算每个数据对象在分类空间中的离群得分;
步骤四:通过步骤二和步骤三的离群得分综合得到每个混合属性数据对象的最终离群得分,并选出离群得分最高的离群数据对象。
所述步骤1.1中离散变量的互信息计算如下:
给定一个包含n个数据对象的数据集DS,每个对象都由m个特征表示,用MI(y
上式中:P
所述步骤1.1中连续变量的互信息计算步骤如下:
步骤12.1:用Parzen窗口估计法对随机变量的概率分布进行估计:定义数据集 X={x
上式中:δ(·)为pazen窗口函数,h为窗口宽度;
步骤12.2:根据Gaussian窗口函数计算概率密度,计算公式为:
上式中:m为数据集的维度,z=x-x
步骤12.3:对两个连续随机变量,取维度m=2,根据步骤12.1和步骤12.2计算的概率密度估计两个连续变量的互信息。
所述步骤1.2中混合属性加权机制的计算步骤如下:
步骤
其中,数值型属性有p个,分别为
分类型属性
混合属性数据集中的对象o
步骤1.22:对于任意属性yj,其属性权值度量定义为该属性到其他属性的互信息的平均值,计算公式为:
上式中:MI(y
所述步骤二中计算每个数据对象在数值空间中的离群得分的步骤为:
步骤2.1:使用k近邻计算数据对象在各个维度的离群程度;
步骤2.2:给定一个单维数据对象o
上式中:d表示两个数值一维数据对象之间的距离,knn
步骤2.3:推导定义一个将离群得分转换为可比较的、标准化的值或概率值的通用框架,通过应用线性变换将离群得分引入到标准化尺度,使发生的最小/最大值映射到[0,1],其中通用框架为
所述步骤三中计算每个数据对象在分类空间中的离群得分的计算公式为:
一个数据对象o
上式中:freq(o
所述步骤四中每个混合属性数据对象的最终离群得分的计算步骤为:
定义任一混合属性数据对象的加权离群得分为Score(o
本发明相对于现有技术具备的有益效果为:本发明提供的
附图说明
下面结合附图对本发明做进一步说明:
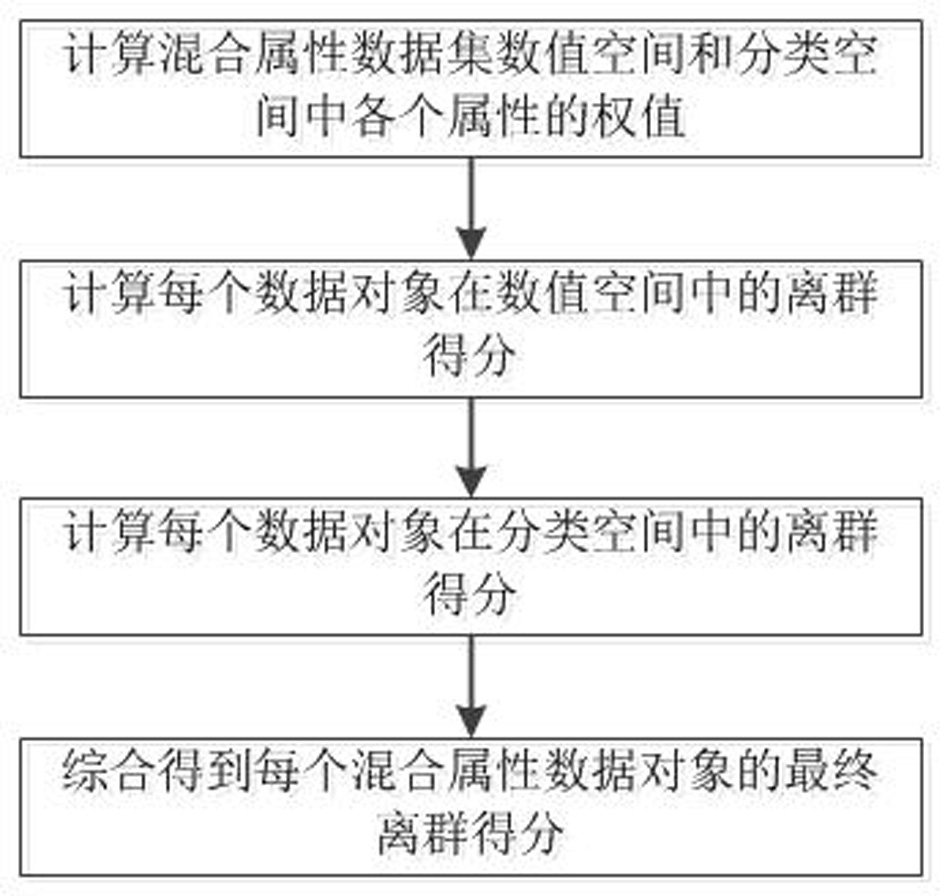
图1为本发明方法的流程图。
具体实施方式
如图1所示,本发明一种基于互信息的混合属性加权离群检测算法,包括如下步骤:
步骤一:计算混合属性数据集数值空间和分类空间中各个属性的权值:
步骤1.1:互信息计算:分别计算混合属性数据集中的离散变量和连续变量的互信息;
步骤1.2:混合属性加权机制计算:给定一个混合属性数据集,定义任意属性的权值度量为该属性到其他属性互信息的平均值;
步骤二:计算每个数据对象在数值空间中的离群得分;
步骤三:计算每个数据对象在分类空间中的离群得分;
步骤四:通过步骤二和步骤三的离群得分综合得到每个混合属性数据对象的最终离群得分,并选出离群得分最高的离群数据对象。
所述步骤1.1中离散变量的互信息计算如下:
给定一个包含n个数据对象的数据集DS,每个对象都由m个特征表示,用MI(y
上式中:P
所述步骤1.1中连续变量的互信息计算步骤如下:
步骤12.1:用Parzen窗口估计法对随机变量的概率分布进行估计:定义数据集 X={x
上式中:δ(·)为parzen窗口函数,h为窗口宽度;
步骤12.2:根据Gaussian窗口函数计算概率密度,计算公式为:
上式中:m为数据集的维度,z=x-x
步骤12.3:对两个连续随机变量,取维度m=2,根据步骤12.1和步骤12.2计算的概率密度估计两个连续变量的互信息。
所述步骤1.2中混合属性加权机制的计算步骤如下:
步骤1.21:给定一个混合属性数据集O,O={o
其中,数值型属性有p个,分别为
分类型属性
混合属性数据集中的对象o
步骤1.22:对于任意属性y
上式中:MI(y
所述步骤二中计算每个数据对象在数值空间中的离群得分的步骤为:
步骤2.1:使用k近邻计算数据对象在各个维度的离群程度;
步骤2.2:给定一个单维数据对象o
上式中:d表示两个数值一维数据对象之间的距离,knn
步骤2.3:推导定义一个将离群得分转换为可比较的、标准化的值或概率值的通用框架,通过应用线性变换将离群得分引入到标准化尺度,使发生的最小/最大值映射到[0,1],其中通用框架为
所述步骤三中计算每个数据对象在分类空间中的离群得分的计算公式为:
一个数据对象o
上式中:freq(o
所述步骤四中每个混合属性数据对象的最终离群得分的计算步骤为:
定义任一混合属性数据对象的加权离群得分为Score(o
本发明提供的一种基于互信息的混合属性离群检测方法,主要解决混合属性数据的离群检测问题,通过互信息对属性间的相关性进行计算和分析,提出了基于互信息的混合属性加权离群检测算法。由于很多属性加权离群检测方法只针对单一类型数据,在混合属性数据应用中很局限。本发明所提出的算法首先在互信息机制下给出了针对混合属性统一的属性加权方法,能够更加客观地度量属性的重要性;其次分别定义了数值型数据、分类型数据以及混合属性数据的离群得分,并进行了规范化处理,为了更客观地度量混合属性数据中数据对象之间的相似度,其范围也被统一到了[0,1]之间;最后在不同类型数据集上验证了所提出算法的有效性。
本发明在计算离群得分之前先进行基于互信息的混合属性相关性度量及加权机制,互信息计算包括离散变量的互信息计算和连续变量的互信息计算,其中离散变量的互信息计算如下:在信息论中,熵和互信息可以代表相互依赖的信息度量,这是反映特征组的特征之间相互关系的最显著的特征。
给定一个包含n个数据对象的数据集DS,每个对象都由m个特征表示。使用H(y
其中P
MI(y
其中概率P
分别利用熵和互信息来度量任意两个特征之间的相关性有一个缺点,即当可能的特征值增加时,熵和互信息值都会增加。为了解决这个问题,使用互信息和熵的比值来度量两个特征之间的特征关系,即特征之间的相关性。
给定特征y
如果特征关系FR等于1,即FR(y
为了计算连续变量的互信息,必须先对随机变量的概率分布进行估计。Parzen窗口估计法可以用已知的样本对总体样本的概率密度进行估计,该方法是一种非参数估计方法。概率密度函数可以用Parzen窗口估计法来进行估计。
假设一个数据集X={x
其中,δ(·)为parzen窗口函数,h为窗口宽度。
parzen证明了通过选择合理的δ(·)和h,
其中,m为数据集的维度,z=x-x
对于两个连续随机变量,取维度m=2,再利用公式(4.1)、(4.2),就可以估计两个连续变量的互信息。
混合属性加权机制:给定一个混合属性数据集O,O={o
其中,数值型属性有p个,分别为
混合属性数据集中的对象o
对于任一属性y
由公式可以得出,一个属性到其他属性的互信息平均值越大,表明该属性和其他属性之间的相关性越大,该属性的重要性也就越大,权值就高;反之,某个属性到其他属性的互信息平均值取值越小,表明该属性和其他属性之间的相关性越小,该属性的重要性也就越小,相应的权值就小。
混合属性离群检测的任务是通过检测数据对象每个属性维度的离群得分来判别数据对象是否离群。首先计算每个数据对象在数值空间中的一个离群得分,然后在分类空间计算另一个离群得分。每个混合属性数据对象的最终离群得分由前面得到的两部分综合计算而来。
数值空间离群得分:人们普遍认为离群值是与其余数据对象明显不同的数据点。通常情况下,离群对象的大多数属性值都与正常数据对象的属性值相差很远。为了检测数据对象的离群程度,在数值空间中,使用近邻计算数据对象在各个维度的离群程度。
给定一个单维数据对象o
其中,k近邻计算时,查询对象同其它对象之间的距离作为判断依据,其中最小的k个距离值对应的数据对象是当前查询对象的k个最近邻居,这里距离的计算采用欧式距离。k最近邻的计算需要多次计算两两数据对象之间的距离,但在本发明的算法中是对数据对象具体某一维上的k近邻计算。对于具体的某个维,knn
基于混合属性的考虑,首先推导出一个将离群得分转换为可比较的、标准化的值甚至概率值的通用框架。将离群得分引入到标准化尺度的最简单方法是应用线性变换,使发生的最小(最大)值映射到[0,1]。
分类空间离群得分:分类属性空间中的离群对象是那些与正常数据对象相比在所有维度上具有罕见属性值。这意味着离群对象在每个维度的属性值在分类属性空间上也是罕见的,而正常数据对象在分类属性空间所有维度上出现的频率更高。基于这样的一个理论,一个数据对象o
其中,freq(o
混合属性加权离群检测算法:基于公式4.4、4.5、4.6和4.7,任一混合属性数据对象的加权离群得分Score(o
由公式4.8可知,在互信息机制下给出了针对混合属性数据统一的加权离群得分计算方法,而且不同类型属性下的离群得分的范围都在[0,1]之间。
O={o
实施例:
本实施例为了评估处理混合属性离群检测算法的有效性,使用Java实现了本发明的方法和其它比较算法。在英特尔酷睿i7-4713MQ CPU@2.3GHz处理器和4GB内存的工作站上对算法进行了评估。实验所使用数据均来自UCI数据集,分别选取了数值型、分类型和混合型3种不同类型的数据集进行了测试。为了获得用于离群检测的数据集,将每个数据集中离群值的数量大约设置为原始数据集大小的2%,由于知道测试数据集中每个对象所属的真实类,所以将小类中的对象定义为异常对象。为了保持数据集的不平衡性,删除了一些小类中的数据对象。所有数据集都是用同样的策略构建的,实验中使用的数据集汇总在表4.1中。
表4.1列出了实验所用的10个数据集信息描述,其中包括4个混合型数据集、3个数值型数据集和3个分类型数据集。
表4.1 UCI数据集描述
为了对离群检测的有效性进行评价,本实施例采用离群检测率(Detection rate)和假阳性率(False positive rate)这两个评价指标对离群检测结果评价。离群检测率反映了正确检测的离群点的数量,假阳性率是错误地将正常点检测为离群点的数目占正常点总数目的比率。
混合属性数据离群检测分析
本实施例的目的是为了评估处理混合属性数据中离群检测方法的有效性。将本发明的方法的性能与ODMAD算法相比较,ODMAD方法是混合属性空间中检测异常值的经典方法。
本发明提出的算法和ODMAD算法在混合属性数据中离群检测结果如表4.2所示。从表中可以看到,本发明的方法在所有被检测的数据集中获得了较高的离群检测率和较低的假阳性率。实际上,该方法的平均检测率为83.6%,假阳性率为0.33%。而ODMAD的平均检测率为80.5%,假阳性率为0.39%。总体而言,本发明提出的方法优于ODMAD算法。
表4.2混合数据集的离群检测结果
混合属性数据集的离群检测的运行时间如表4.3所示,从表中可以看出本发明所提出的方法离群检测运行时间也要快得多。例如,ODMAD算法在56.8秒完成了对Abalone数据集的检测,而本发明的算法在29.73秒内就处理了相同的任务。这主要是因为ODMAD算法需要查看单个分类值及其连续对应值的平均值。
表4.3混合属性数据集的运行时间(以秒为单位)
综上所述,混合属性离群检测的实验结果表明,本发明所提出的方法在四个不同的混合属性数据集上表现良好。此外,本发明的方法还能够处理单类型(数值型或分类型)属性数据中的异常值,而不需要进行任何特征转换。接下来将使用仅具有数值属性或分类属性的UCI 实际数据集进行实验验证。
数值型数据离群检测分析
当数据只包含数值型属性时,每个对象的离群得分按照公式4.5和4.6进行计算。为了评估处理数值型数据中离群检测方法的有效性,将本发明提出的方法与KNNW算法相比较, KNNW方法是应用较广的数值型属性空间中检测异常值的方法。离群检测的结果及运行时间的比较如表4.4和表4.5所示。
表4.4数值型数据离群检测结果
表4.5数值型数据检测时间(以秒为单位)
分类型数据离群检测分析
当数据只包含分类型属性时,每个数据对象的离群得分按照公式4.7进行计算。本实施例中针对分类型数据将本发明的算法与分类算法AVF和GA进行了比较,如下表4.6和4.7 所示。
表4.6分类型数据离群检测结果
表4.7分类型数据处理时间(以秒为单位)
通过对3个分类型UCI数据集进行实验测试,本发明的算法及其比较算法的离群检测结果及运行时间如表4.6和表4.7所示。表4.6表明,对于AVF算法,本发明的算法在Mushroom,Chess和Connect-4这3个分类型数据集的检测率分别提高了42.9%、25.8%和35.9%。同样地,对于GA算法分别提高了39.7%,51.6%和39.1%。而平均检测率比AVF算法和GA算法高出很多,假阳性率比两个比较算法也低很多。
表4.7实验结果表明,本发明的算法和AVF算法效率相差不大,但比GA算法效率高出很多,主要因为GA算法每检测一个离群值都要扫描一次数据集,比较费时。本实验验证了所提出的算法适用于分类型数据集的离群检测。
目前大部分离群检测算法针对的是数值型或分类型的单一类型数据。而在实际应用中存在很多混合属性数据。目前通常采用离散化方法将数值属性转换为分类属性,或者将分类属性转换为数值属性。这些操作都可能带来信息损失,因此会影响检测性能。本发明提出了基于互信息的混合属性离群检测方法,首先利用互信息给出了混合数据的属性加权机制,其次定义了混合属性数据的离群得分,并进行了规范化处理。此外,该方法还能够处理单类型 (数值型或分类型)属性数据中的异常值,而不需要进行任何特征转换。最后在不同类型UCI 数据集上验证了算法的有效性。
关于本发明具体结构需要说明的是,本发明采用的各部件模块相互之间的连接关系是确定的、可实现的,除实施例中特殊说明的以外,其特定的连接关系可以带来相应的技术效果,并基于不依赖相应软件程序执行的前提下,解决本发明提出的技术问题,本发明中出现的部件、模块、具体元器件的型号、连接方式除具体说明的以外,均属于本领域技术人员在申请日前可以获取到的已公开专利、已公开的期刊论文、或公知常识等现有技术,无需赘述,使得本案提供的技术方案是清楚、完整、可实现的,并能根据该技术手段重现或获得相应的实体产品。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 一种基于互信息的混合属性加权离群检测算法
- 一种基于KNN离群点检测算法的网络入侵检测方法及系统