一种双菌株全细胞催化一步法合成熊去氧胆酸的方法
文献发布时间:2023-06-19 19:23:34
技术领域
本发明属于生物技术领域,具体涉及一种双菌株全细胞催化一步法合成熊去氧胆酸的方法,该方法通过表达7α-HSDH/ADH的工程菌株和表达7β-HSDH/GDH的工程菌株联用,一步法催化CDCA为UDCA。
背景技术
熊去氧胆酸(Ursodeoxycholic acid,UDCA)是一种内源性胆汁酸,具有溶解胆结石,治疗反流性胃炎、胆源性胰腺炎、酒精性肝炎、原发性胆汁性肝硬化、药物性肝炎和改善肝移植效果的作用。到目前为止,熊去氧胆酸还是美国食品和药物管理局(FDA)唯一批准治疗原发性胆汁性肝硬化的药物。
在中国,熊去氧胆酸大多以熊胆粉形式使用,通过饲养黑熊,然后“活熊引流取胆”获得,这种方式获取的熊去氧胆酸规模小,并且一直存在争议;以原料药形式存在的UDCA(纯度一般高于80%)是国际上的主流产品,主要通过化学合成或生物转化合成。
化学合成法是国内外研究时间最长,并取得一定工业化应用的方法,但化学法合成UDCA需要大量使用有机溶剂和重金属、污染大,并且涉及高温高压、易制爆危险步骤,产物纯度较低(纯度80%左右),还远不能满足市场对UDCA用量及质量的需求;相对于化学法,生物转化法合成UDCA则具有高效和环境友好的特点,利用胆酸生物转化合成UDCA已是必然趋势。
现有生物转化合成UDCA主要通过酶转化或全细胞催化。两种方式都面临亟待解决的问题。利用酶法转化鹅去氧胆酸合成UDCA,只能使用低的底物浓度(4-40g/L),而且在40g/L的底物浓度下转化率只有90%。一般情况下,酶转化工艺使用100g/L或者更高底物浓度,且转化率要接近100%,才可视为具有工业化生产意义,故酶促反应离工业化大规模生产还有一定距离。此外,酶促反应依赖于鹅去氧胆酸的氧化再还原,反应使用游离酶,因而整个反应体系需要多种酶和辅酶,使得整个过程比较复杂,反应成本很高,而在工业化生产中难以实现。利用全细胞催化鹅去氧胆酸合成UDCA,在专利号为CN105368828B中公开了一种高效全细胞催化CDCA合成UDCA的方法;但是该方法提取UDCA比较繁琐,并且UDCA的转化率低,其它报道的全细胞催化方法中,大都仍需要添加昂贵辅酶辅助反应,或者需要分步反应、反应时间过长,效率低下。
发明内容
针对现有技术中存在的问题,本发明的目的是提供一种高效、绿色、低成本的双菌株全细胞催化一步法合成熊去氧胆酸的方法,本发明提供的制备方法仅仅利用底物CDCA、异丙醇和葡萄糖,通过工程大肠杆菌细胞生物转化,就能得到转化率大于99%的UDCA。
本发明通过构建的共表达7α-HSDH和ADH的重组大肠杆菌,以及构建的共表达7β-HSDH和GDH的重组大肠杆菌。本发明也包括上述酶基因序列、编码酶的蛋白序列、酶的排列组合方式,以及上述重组大肠杆菌全细胞在熊去氧胆酸合成中的用途。此外,本发明也包括使用上述全细胞合成UDCA的新方法。
为了实现上述目的,本发明所采用的具体技术方案为:
本发明首先提供了一种双酶表达菌株,通过表达7α-羟基类固醇脱氢酶(7α-HSDH)/醇脱氢酶(ADH)的工程菌株和表达7β-羟基类固醇脱氢酶(7β-HSDH)/葡萄糖脱氢酶(GDH)的工程菌株组成。
上述7α-HSDH来源于不同梭菌,基因序列如Seq ID NO: 1所示,编码的蛋白序列如Seq ID NO: 2所示,或来源于脆弱拟杆菌,基因序列如Seq ID NO: 3所示,编码的蛋白序列如Seq ID NO: 4所示;ADH来源于海洋念珠菌,基因序列如Seq ID NO: 5所示,编码的蛋白序列如Seq ID NO: 6所示,或来源于布氏热厌氧杆菌,基因序列如Seq ID NO: 7所示,编码的蛋白序列如Seq ID NO: 8所示;7β-HSDH来源于不同梭菌,基因序列如Seq ID NO: 9所示,编码的蛋白序列如Seq ID NO: 10所示,或来源于活泼瘤胃球菌,基因序列如Seq IDNO: 11所示,编码的蛋白序列如Seq ID NO: 12所示;GDH来源于巨大芽孢杆菌,基因序列如Seq ID NO: 13所示,编码的蛋白序列如Seq ID NO: 14所示,或来源于枯草芽孢杆菌,基因序列如Seq ID NO: 15所示,编码的蛋白序列如Seq ID NO: 16所示。
本发明构建的双酶表达菌株的工程菌株为大肠杆菌。
上述双酶表达菌株的具体构建方法为:
将Seq ID NO: 1或Seq ID NO: 3克隆进入pRSFDuet-1质粒(附图2)的MCS1或MCS2多克隆位点,则将Seq ID NO: 5或Seq ID NO: 7相应地克隆进入pRSFDuet-1的另外一个多克隆位点。将此重组质粒转化BL21(DE3)表达宿主菌,从而构建7α-HSDH和ADH共表达工程大肠杆菌。
将Seq ID NO: 9或Seq ID NO: 11克隆进入pRSFDuet-1质粒的MCS1或MCS2多克隆位点,则将Seq ID NO: 13或Seq ID NO: 15相应地克隆进入另外一个多克隆位点。此重组质粒转化BL21(DE3)表达宿主,从而构建7β-HSDH和GDH共表达工程大肠杆菌。
本发明还提供了一种利用上述双酶表达菌株全细胞催化一步法合成熊去氧胆酸的方法,包括以下步骤:
(1)分别发酵表达7α-HSDH/ADH的工程菌株和表达7β-HSDH/GDH的工程菌株,得到7α-HSDH/ADH的工程菌株的发酵液、7β-HSDH/GDH的工程菌株的发酵液;
(2)称取鹅去氧氧胆酸悬浮在磷酸盐缓冲液中得鹅去氧氧胆酸悬浮液,调节pH,加入丙酮和葡萄糖,加入步骤(1)的发酵液进行反应,得产物。
进一步的,步骤(1)中,本发明所使用的发酵液通过以下步骤发酵而成:(a)摇瓶发酵工程大肠杆菌菌株
共表达7α-HSDH和ADH的工程大肠杆菌或共表达7β-HSDH和GDH的工程大肠杆菌在液体LB培养基(50μg/mL卡那霉素)中,37℃过夜培养,以5-10%接种量接种新鲜的LB培养基(50μg/mL卡那霉素),继续在37℃培养至OD
酶活测定体系和方法如下:
1)、7α-HSDH酶活测定
底物CDCA(pH8.0,50mM) 1.95ml
NAD+(5mg/ml) 50ul
酶液 2ul
2)、ADH酶活测定
PBS buffer(pH8.0) 1.75ml
丙酮(100mM) 200ul
NADH(5mg/ml) 50ul
酶液 2ul
3)、7β-HSDH酶活测定
底物7K-LCA(pH8.0,80mM) 1.95ml
NADPH(5mg/ml) 50ul
酶液 2ul
4)、GDH酶活测定
PBS buffer(pH8.0) 1.75ml
底物D-glucose(100mM) 200ul
NADP(5mg/ml) 50ul
酶液 2ul
检测温度35℃,计时2min
5)酶活计算方式:
酶活(U/mL)=△OD/min*Vt*df/(6.22*1.0*Vs)
Vt: 反应总体积 2.00 mL
Df::稀释倍数
6.22:NAD(P)H在340nm波长的消光系数
1.0:测量光程
Vs:酶液体积(0.002mL)
具体酶活检测结果如表1和表2所示:
表1 大肠杆菌共表达7α-HSDH和ADH的摇瓶发酵酶活
表2 大肠杆菌共表达7β-HSDH和GDH的摇瓶发酵酶活
(b)大肠杆菌工程菌株高密度发酵产酶
吸取共表达的单菌落接种液体LB培养基(50μg/mL卡那霉素),37℃震荡培养8-20小时后,以5-10%接种量转接10 L发酵罐培养。发酵罐配制5L TB培养基(50μg/mL卡那霉素)作为发酵起始培养基,TB培养基成分:12 g/L胰蛋白胨,24 g/L酵母提取物,16.4 g/LK
进一步的,步骤(2)中,所述鹅去氧氧胆酸悬浮液为1kg鹅去氧氧胆酸悬浮在8-10L 10 mM磷酸盐缓冲液中;所述磷酸盐缓冲液的pH为8.0。
进一步的,步骤(2)中,所述调节pH为8.0。
进一步的,步骤(2)中,所述丙酮、葡萄糖与鹅去氧氧胆酸的摩尔比均为1.5:1;加入发酵液后,终底物CDCA的终浓度为100 g/L。
进一步的,步骤(2)中,每1kg鹅去氧氧胆酸中,加入的7α-HSDH/ADH的工程菌株的发酵液内含湿细胞为80-100g; 7β-HSDH/GDH的工程菌株的发酵液内含湿细胞为105-125g。
进一步的,步骤(2)中,所述反应为35℃、350 rpm条件下反应4-8小时。
本发明最终经HPLC检测,CDCA转化率大于99.5%,其中,CDCA残留<0.5%,7-KLCA残留小于0.1%。
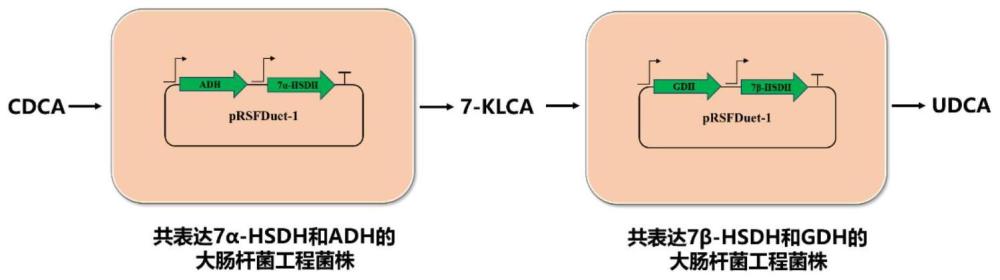
本发明提供的用于UDCA合成的方法如图1所示。通过共表达7α-HSDH和ADH的工程大肠杆菌将CDCA转化为3α-羟基-7-氧代-5β-胆烷酸(7-KLCA),这个过程中,通过ADH将丙酮转化为异丙醇实现辅酶NAD+的循环再生。进一步地,通过共表达7β-HSDH和GDH的工程大肠杆菌将7-KLCA还原成UDCA,这个过程中,使用GDH将葡萄糖转化为葡萄糖酸内酯实现NADP+的循环再生。两种工程大肠杆菌共用,能高效地、专一性地将CDCA转化成UDCA,实现UDCA的工业化生产。
本发明的有益效果为:
1、与现有熊去氧胆酸制备方法相比,本发明提供的方法操作简单,反应时间短,不使用有机溶剂,成本低廉。经实践证明,本发明的方法反应时长仅需6-8小时,对底物的转化率高达99.5%以上。
2、本发明合成熊去氧胆酸时,生产效率高,承载底物浓度高,可以转化10%-15%浓度CDCA,并且在高浓度底物时,仍具有高转化率。
3、本发明用表达7α-HSDH/ADH的大肠杆菌工程菌株和表达7β-HSDH/GDH的大肠杆菌工程菌株发酵液直接催化合成熊去氧胆酸,不需要分离菌体,不需要细胞破碎,从而大大简化了反应过程,并降低了细胞破碎过程中的酶活损失。
4、双菌发酵后的发酵液继续作为熊去氧胆酸合成的反应液继续使用,大大降低了UDCA生产过程中用水量及废水产生量,提升了环保质量。
5、反应时,利用菌体自身辅酶循环系统,不需要额外添加反应所需昂贵辅酶NAD+和NADP+,大大降低了生产成本,适合大规模的工业化生产。
附图说明
图1为双菌株全细胞催化CDCA合成UDCA示意图。
图2为pRSFDuet-1质粒图谱。
图3为 共表达的7α-HSDH/ADH和7β-HSDH/GDH酶蛋白的SDS-PAGE图。
图4 为双菌株全细胞催化一步法合成UDCA的高效液相色谱图,反应时间0,1,2,3,4小时取样HPLC检测图谱。
具体实施方式
下面将结合实施例和附图详细说明本发明,这些实施例和附图仅起说明性作用,并不局限于本发明的应用范围。本发明不限于下述实施方式或实施例,凡不违背本发明精神所做出的修改或变形,均应包括在本发明范围之内。
实施例1 全基因合成7α-HSDH和ADH、7β-HSDH和GDH
基因序列优化后的来自于来源于不同梭菌的7α-HSDH基因序列如Seq ID NO: 1所示,来源于脆弱拟杆菌的7α-HSDH,基因序列如Seq ID NO: 3所示;来源于海洋念珠菌的ADH基因序列如Seq ID NO: 5所示,来源于布氏热厌氧杆菌的ADH基因序列如Seq ID NO: 7所示。上述密码子优化后的基因序列由金斯瑞生物科技股份有限公司进行全基因合成。
实施例2 全基因合成7β-HSDH和葡萄糖脱氢酶
基因序列优化后的来源于不同梭菌的7β-HSDH基因序列如Seq ID NO: 9所示,来源于活泼瘤胃球菌的7β-HSDH基因序列如Seq ID NO: 11所示;来自巨大芽孢杆菌的GDH基因序列如Seq ID NO: 13所示,来源于枯草芽孢杆菌的GDH基因序列如Seq ID NO: 15所示。上述密码子优化后的基因序列由金斯瑞生物科技股份有限公司进行全基因合成。
实施例3 7α-HSDH和ADH共表达
实施例1中的基因全基因合成后,与表达载体pRSFDuet-1连接、转化,在大肠杆菌BL21(DE3)中表达:将Seq ID NO: 1或Seq ID NO: 3克隆进入pRSFDuet-1质粒(图1)的MCS1或MCS2多克隆位点,则将Seq ID NO: 5或Seq ID NO: 7相应地克隆进入pRSFDuet-1的另外一个多克隆位点。此重组质粒转化BL21(DE3)表达宿主,从而构建7α-HSDH和ADH共表达工程大肠杆菌。构建成功的大肠杆菌工程菌按5%转接新鲜液体LB培养基(50μg/mL卡那霉素),220 rpm,37℃培养,待OD600达到0.4,温度调整到30℃,加入0.5 mM IPTG诱导3小时生产相应酶蛋白。
实施例4 7β-HSDH和GDH共表达
实施例2中的基因全基因合成后,与表达载体pRSFDuet-1连接、转化,在大肠杆菌BL21(DE3)中表达:将Seq ID NO: 9或Seq ID NO: 11克隆进入pRSFDuet-1质粒(图1)的MCS1或MCS2多克隆位点,则将Seq ID NO: 13或Seq ID NO: 15相应地克隆进入pRSFDuet-1的另外一个多克隆位点。此重组质粒转化BL21(DE3)表达宿主,从而构建7β-HSDH和GDH共表达工程大肠杆菌。构建成功的大肠杆菌工程菌按5%转接新鲜液体LB培养基(50μg/mL卡那霉素),220 rpm,37℃培养,待OD600达到0.4,温度调整到25℃,加入0.8 mM IPTG诱导8小时,诱导大肠杆菌产生酶蛋白。
实施例5 7α-HSDH和ADH共表达菌株发酵罐发酵
吸取实施例3共表达7α-HSDH和ADH的大肠杆菌单菌落,接种液体LB培养基,37℃过夜培养后,5%量接种5 L 发酵培养基(50μg/mL卡那霉素、12 g/L胰蛋白胨 ,24 g/L酵母提取物,16.4 g/L K
实施例6 7β-HSDH和GDH共表达菌株发酵罐发酵
吸取实施例4共表达7β-HSDH和GDH的大肠杆菌单菌落,接种液体LB培养基,37℃过夜培养后,5%量接种5 L 发酵培养基(50μg/mL卡那霉素、12 g/L胰蛋白胨 ,24 g/L酵母提取物,16.4 g/L K
实施例7
划取平板上培养的共表达7α-HSDH和ADH的大肠杆菌单菌落,接种液体LB培养基,37℃过夜培养后,5%量接种20 L TB培养基,控制温度37℃,pH 7.0,溶氧≥20%进行培养,待OD600值达到6.0,即刻转接200 L发酵罐进行发酵培养。200 L发酵罐配置TB起始培养基,接种后,控制温度37℃,pH 7.0,溶氧≥20%进行培养,起始培养基营养成分耗尽后,添加补料培养基(50 g/L酵母粉,50 g/L蛋白胨,500 g/L甘油,3.4g/L MgSO
实施例8
使用和实施例6同样的方法对共表达7β-HSDH和GDH的工程菌进行发酵,总诱导时间16小时,细胞湿重达到113 g/L。量取50 mL发酵液直接进行超声破碎,获得混合酶液。7β-HSDH和葡萄糖脱氢酶酶活分别是196.4U/mL、1014.8U/mL。
划取平板上培养的共表达7β-HSDH和GDH的大肠杆菌单菌落,接种液体LB培养基,37℃过夜培养后,5%量接种20 L TB培养基,控制温度37℃,pH 7.0,溶氧≥20%进行培养,待OD600值达到6.0,即刻转接200 L发酵罐进行发酵培养。200 L发酵罐配置TB起始培养基,接种后,控制温度37℃,pH 7.0,溶氧≥20%进行培养,起始培养基营养成分耗尽后,添加补料培养基(50 g/L酵母粉,50 g/L蛋白胨,500 g/L甘油,3.4g/L MgSO
实施例9
称取1kg鹅去氧氧胆酸悬浮在10 mM磷酸盐缓冲液(pH 8.0)中,用2 NaOH调节pH8.0,加入与CDCA1.5倍摩尔比的丙酮和葡萄糖,加入实施例5和实施例6制备的发酵液,内含湿细胞分别80g和105g,终底物终浓度100g/L。在35℃、350 rpm和pH 8.0条件下反应8小时。HPLC检测,转化率大于99.5%,其中,CDCA残留<1%,7-KLCA残留小于0.1%。
序列表
<110> 聊城大学
<120>一种双菌株全细胞催化一步法合成熊去氧胆酸的方法
<160> 16
<210> 1
<211> 789
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 1
ATGAAAAGATTAGAAGGAAAAGTCGCAATAGTAACATCATCTACTAGAGGAATAGGACGTGCATCTGCAGAAGCATTAGCAAAAGAAGGTGCTTTAGTATATCTAGCAGCACGTTCAGAGGAATTAGCTAATGAAGTTATAGCAGATATAAAAAAGCAAGGTGGAGTAGCTAAGTTTGTTTACTTTAATGCTAGAGAAGAAGAAACTTACACTTCAATGGTAGAAAAAGTTGCTGAAGCTGAAGGCAGGATAGATATATTAGTTAATAACTACGGTGGAACAAATGTTAATTTAGATAAGAACTTAACTGCTGGAGATACAGATGAATTCTTTAGAATATTAAAAGATAACGTTCAAAGTGTATACTTACCAGCAAAAGCTGCTATACCACATATGGAAAAAGTAGGCGGTGGAAGCATAGTTAATATCTCAACTATAGGATCAGTTGTTCCAGATATATCAAGAATAGCTTACTGTGTATCAAAATCCGCTATAAACTCTTTAACTCAAAACATAGCATTACAATATGCAAGAAAGAATATCAGATGTAATGCAGTATTACCTGGTTTAATAGGAACTAGAGCAGCACTCGAAAATATGACTGATGAATTTAGAGACTCATTCTTAGGACATGTTCCTTTAAATAGAGTAGGAAGACCAGAAGATATAGCAAATGCAGTTTTATACTATGCCTCTGATGATTCAGGTTATGTAACAGGAATGATTCATGAAGTTGCAGGAGGTTTTGCATTAGG
AACTCCTCAATATTCAGAATACTGTCCAAGATAA
<210> 2
<211> 262
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 2
MKRLEGKVAIVTSSTRGIGRASAEALAKEGALVYLAARSEELANEVIADIKKQGGVAKFVYFNAREEETYTSMVEKVAEAEGRIDILVNNYGGTNVNLDKNLTAGDTDEFFRILKDNVQSVYLPAKAAIPHMEKVGGGSIVNISTIGSVVPDISRIAYCVSKSAINSLTQNIALQYARKNIRCNAVLPGLIGTRAALENMTDEFRDSFLGHVPLNRVGRPEDIANAVLYYASDDSGYVTGMIHEVAGGFALGTP
QYSEYCPR
<210> 3
<211> 780
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 3
ATGAACAGATTTGAAAATAAGATAATCATTATCACGGGAGCTGCCGGTGGAATCGGCGCATCAACCACACGCCGCATTGTATCTGAAGGCGGCAAAGTAGTTATTGCTGACTATTCAAGAGAAAAAGCAGACCAATTTGCTGCCGAGCTTAGTAATTCGGGAGCAGATGTACGTCCGGTTTATTTTTCTGCTACAGAATTGAAAAGCTGCAAAGAACTAATCACCTTTACAATGAAGGAATACGGACAGATCGATGTACTGGTAAACAATGTAGGAGGTACAAATCCCAGACGGGACACAAACATCGAAACTCTGGATATGGATTATTTTGACGAAGCCTTTCATCTGAATTTATCTTGTACCATGTATTTGTCCCAACTGGTTATCCCCATTATGAGCACACAAGGTGGTGGAAATATTGTAAACGTAGCCTCAATAAGTGGAATCACGGCCGATTCGAATGGTACTCTTTATGGAGCCAGCAAAGCAGGAGTCATCAATCTGACCAAATACATTGCCACCCAAACGGGAAAGAAAAACATCCGTTGCAATGCAGTAGCACCAGGATTGATCCTGACCCCGGCCGCACTGAATAATCTTAATGAAGAGGTACGCAAAATATTTCTCGGGCAATGTGCGACACCCTATTTAGGTGAACCGCAAGACGTTGCCGCGACCATCGCTTTTTTAGCCTCCGAAGATGCACGTTACATTACCGGACAGACCATAGTAGTAGATGGCGGATTGACAATACACAATCCGACAATAAACTTAGTATAA
<210> 4
<211> 259
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 4
MNRFENKIIIITGAAGGIGASTTRRIVSEGGKVVIADYSREKADQFAAELSNSGADVRPVYFSATELKSCKELITFTMKEYGQIDVLVNNVGGTNPRRDTNIETLDMDYFDEAFHLNLSCTMYLSQLVIPIMSTQGGGNIVNVASISGITADSNGTLYGASKAGVINLTKYIATQTGKKNIRCNAVAPGLILTPAALNNLNEEVRKIFLGQCATPYLGEPQDVAATIAFLASEDARYITGQTIVVDGGLTIHNPTINLV
<210> 5
<211> 765
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 5
ATGTCCTACAATTTTGCCAACAAAGTTCTTATTGTGACCGGAGGTCTGTCCGGTATTGGACTTGCAGTTGCAAAGAAGTTTCTTCAACTCGGGGCCAAAGTGACAATTTCTGATATTTCTGCCACTGAAAAGTACAACACGGTTGTAGGTGAGTTCAAAACCGAGGGCATTGATGTCAAGAATGTTCAGTATATTCAGGCCGATGCAAGCAAAGAGGCCGACAACGAGAAGCTCATCTCCGAGACACTGTCTGCTTTCGGTGATCTCGACTACGTGTGCGCAAATGCTGGAATTGCCACTTTCACACAGACTACAGATATCTCCTACGACGTCTGGAGGAAGGTAACCAGCATTAATCTTGACGGTGTTTTCATGCTTGATAAACTAGCTGCACAATACTTTTTGAGCAAGAACAAGCCAGGTGCTATTGTCAACATGGGTTCCATTCACTCGTATGTGGCCGCTCCTGGACTTTCTCACTACGGTGCGGCCAAAGGAGGTCTGAAGCTACTGACTCAGACCATGGCCCTTGAGTATGCCGCAAAAGGTATAAGAGTTAACTCGGTCAATCCTGGTTACATCAAGACACCATTGCTTGATATTTGCCCTAAAGAACACATGGATTACCTTATCACTCAGCATCCAATTGGACGTCTCGGAAAGCCTGAAGAGATTGCAAGTGCTGTTGCATTTCTGTGCTCTGACGAGGCTACATTTATCAACGGAATCTCCTTGTTGGTAGACGGTGGTTATACCGCAAGATAA
<210> 6
<211> 254
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 6
MSYNFANKVLIVTGGLSGIGLAVAKKFLQLGAKVTISDISATEKYNTVVGEFKTEGIDVKNVQYIQADASKEADNEKLISETLSAFGDLDYVCANAGIATFTQTTDISYDVWRKVTSINLDGVFMLDKLAAQYFLSKNKPGAIVNMGSIHSYVAAPGLSHYGAAKGGLKLLTQTMALEYAAKGIRVNSVNPGYIKTPLLDICPKEHMDYLITQHPIGRLGKPEEIASAVAFLCSDEATFINGISLLVDGGYTAR
<210> 7
<211> 1065
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 7
ATGGGCATGAAAGGATTTGCTATGCTATCAATAGGGAAAGTCGGATGGATTGAGAAGGAGAAACCGGCGCCTGGTCCGTTTGATGCCATCGTTCGTCCGCTGGCGGTGGCACCGTGTACCAGCGATATCCACACCGTGTTCGAAGGCGCGATCGGTGAGCGCCACAACATGATCCTGGGTCATGAAGCAGTCGGCGAGGTGGTTGAAGTTGGTTCCGAAGTTAAGGACTTCAAACCGGGTGATCGTGTTGTTGTCCCGGCAATCACTCCGGATTGGCGTACCTCCGAAGTGCAACGTGGTTATCATCAGCATAGCGGTGGCATGTTAGCGGGCTGGAAATTCAGCAATGTGAAGGACGGTGTGTTCGGTGAATTTTTTCACGTAAACGATGCGGACATGAACTTGGCGCACCTGCCGAAGGAGATCCCGCTGGAGGCAGCCGTTATGATCCCGGATATGATGACCACGGGTTTCCACGGCGCGGAACTGGCGGACATCGAGTTGGGCGCGACGGTCGCCGTTCTGGGCATTGGTCCGGTGGGTCTGATGGCTGTTGCGGGCGCTAAACTGCGTGGCGCGGGCCGTATTATCGCTGTGGGCTCTCGTCCGGTGTGCGTAGACGCGGCTAAGTATTACGGCGCGACCGATATCGTGAACTACAAGGACGGCCCGATTGAAAGCCAGATTATGAACCTGACGGAAGGTAAAGGCGTGGACGCGGCGATTATCGCCGGTGGTAATGCAGACATTATGGCTACCGCAGTGAAGATCGTGAAGCCGGGCGGTACAATTGCTAATGTTAACTACTTCGGCGAGGGCGAGGTTTTACCGGTTCCGAGATTGGAATGGGGTTGCGGTATGGCGCACAAAACCATTAAGGGTGGTCTTTGCCCAGGTGGCCGTCTGCGCATGGAACGTCTCATTGATTTGGTTTTTTATAAGCGCGTGGACCCGTCGAAACTGGTGACCCATGTTTTCCGCGGTTTTGATAATATCGAGAAGGCATTTATGCTGATGAAAGACAAACCAAAAGACTTGATCAAGCCCGTGGTTATTCTGGCGTAA
<210> 8
<211> 352
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 8
MKGFAMLSIGKVGWIEKEKPAPGPFDAIVRPLAVAPCTSDIHTVFEGAIGERHNMILGHEAVGEVVEVGSEVKDFKPGDRVVVPAITPDWRTSEVQRGYHQHSGGMLAGWKFSNVKDGVFGEFFHVNDADMNLAHLPKEIPLEAAVMIPDMMTTGFHGAELADIELGATVAVLGIGPVGLMAVAGAKLRGAGRIIAVGSRPVCVDAAKYYGATDIVNYKDGPIESQIMNLTEGKGVDAAIIAGGNADIMATAVKIVKPGGTIANVNYFGEGEVLPVPRLEWGCGMAHKTIKGGLCPGGRLRMERLIDLVFYKRVDPSKLVTHVFRGFDNIEKAFMLMKDKPKDLIKPVVILA
<210> 9
<211> 786
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 9
ATGAATTTTAGAGAAAAATATGGACAATGGGGAATTGTTTTAGGGGCAACAGAAGGAATTGGTAAAGCTAGTGCTTTTGAATTAGCTAAAAGAGGGATGGATGTTATTTTAGTTGGAAGAAGAAAAGAAGCATTAGAAGAGTTAGCTAAGGCAATACATGAAGAAACAGGAAAAGAAATCAGAGTATTACCACAAGATTTATCTGAATATGATGCTGCAGAAAGATTAATAGAAGCAACTAAAGATTTAGATATGGGAGTCATTGAGTATGTTGCATGTCTACATGCAATGGGACAATATAATAAAGTTGACTACGCTAAATATGAACAAATGTATAGAGTTAATATAAGAACATTCTCAAAATTATTACATCACTATATAGGTGAATTCAAAGAAAGAGATAGAGGTGCATTCATAACAATAGGATCTTTATCAGGATGGACATCATTACCATTCTGTGCAGAATATGCAGCAGAAAAAGCTTATATGATGACAGTAACAGAAGGAGTTGCTTACGAATGTGCAAATACTAATGTTGACGTAATGCTTTTATCAGCGGGTTCAACAATCACACCTACTTGGTTAAAAAATAAACCATCAGATCCTAAGGCGGTTGCAGCAGCAATGTATCCAGAAGATGTTATAAAAGATGGATTTGAACAATTAGGAAAGAAATTTACTTATTTAGCTGGAGAGTTAAATAGAGAAAAAATGAAGGAAAATAATGCAATGGATAGAAATGATTTAATTGCAAAACTAGGAAAAAT
GTTTGATCATATGGCATAA
<210> 10
<211> 261
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 10
MNFREKYGQWGIVLGATEGIGKASAFELAKRGMDVILVGRRKEALEELAKAIHEETGKEIRVLPQDLSEYDAAERLIEATKDLDMGVIEYVACLHAMGQYNKVDYAKYEQMYRVNIRTFSKLLHHYIGEFKERDRGAFITIGSLSGWTSLPFCAEYAAEKAYMMTVTEGVAYECANTNVDVMLLSAGSTITPTWLKNKPSDPKAVAAAMYPEDVIKDGFEQLGKKFTYLAGELNREKMKENNAMDRN
DLIAKLGKMFDHMA
<210> 11
<211> 792
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 11
ATGACATTGAGAGAAAAATATGGAGAATGGGGAATTATTTTAGGCGCTACTGAAGGTGTCGGAAAAGCATTTTGTGAAAGGCTTGCCAAAGAAGGTATGAATGTCGTAATGGTCGGACGCCGTGAAGAAAAATTAAAAGAGCTCGGTGAGGAACTAAAAAACACTTATGAGATTGATTATAAAGTCGTAAAAGCAGACTTTTCGCTGCCAGATGCTACTGACAAAATTTTTGCTGCAACAGAAAATCTGGATATGGGATTTATGGCCTATGTAGCCTGCTTACACTCTTTTGGCAAAATCCAGGATACACCTTGGGAAAAGCATGAGGCAATGATCAACGTAAACGTTGTTACATTTATGAAATGCTTCTATCACTATATGAAAATCTTTGCTGCACAGGATCGCGGTGCTGTCATCAACGTATCTTCTATGACTGGAATTTCCAGTTCACCATGGAATGGCCAATATGGTGCAGGAAAGGCATTCATTTTAAAAATGACAGAGGCTGTTGCCTGTGAAACGGAAAAGACCAATGTTGATGTGGAAGTCATCACTTTGGGAACTACTCTGACACCAAGTCTTTTAAGCAACCTGCCTGGCGGACCACAGGGGGAAGCTGTTATGAAGACTGCTCAAACACCGGAAGAAGTTGTGGACGAAGCTTTTGAAAAATTAGGAAAAGAACTGTCTGTCATTTCCGGAGAGCGTAATAAAGCCAGCGTCCATGACTGGAAAGCGAATCATACAGAAGATGACTATATCCGCTATAT
GGGATCTTTCTATCAAGAATAA
<210> 12
<211> 263
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 12
MTLREKYGEWGIILGATEGVGKAFCERLAKEGMNVVMVGRREEKLKELGEELKNTYEIDYKVVKADFSLPDATDKIFAATENLDMGFMAYVACLHSFGKIQDTPWEKHEAMINVNVVTFMKCFYHYMKIFAAQDRGAVINVSSMTGISSSPWNGQYGAGKAFILKMTEAVACETEKTNVDVEVITLGTTLTPSLLSNLPGGPQGEAVMKTAQTPEEVVDEAFEKLGKELSVISGERNKASVHDWKANHTEDDYIRYMGSFYQE
<210> 13
<211> 786
<212> DNA
<213> 人工序列(artiartificial sequence)
<400> 13
ATGTATACAGATTTAAAAGATAAAGTAGTAGTTGTAACAGGCGGATCAAAAGGATTGGGTCGCGCAATGGCCGTTCGTTTTGGTCAAGAGCAGTCAAAAGTGGTTGTAAACTACCGCAGCAATGAAGAAGAAGCGCTAGAAGTAAAAAAAGAAATTGAACAAGCTGGCGGCCAAGCAATTATTGTTCGAGGCGACGTAACAAAAGAGGAAGACGTTGTGAATCTTGTAGAGACAGCTGTTAAAGAGTTTGGCACATTAGACGTTATGATTAACAATGCTGGTGTTGAAAACCCGGTTCCTTCACATGAATTATCGTTAGAAAACTGGAATCAAGTAATCGATACAAACTTAACAGGCGCGTTTTTAGGAAGCCGCGAAGCGATTAAATATTTTGTTGAAAATGATATTAAAGGAAACGTTATTAACATGTCCAGCGTTCACGAGATGATTCCTTGGCCACTATTTGTTCACTATGCAGCAAGTAAAGGCGGTATGAAACTAATGACAGAAACATTGGCTCTTGAATATGCGCCAAAAGGTATCCGCGTAAATAACATTGGACCAGGCGCGATCGATACGCCAATCAACGCTGAAAAATTCGCAGATCCGGAACAGCGTGCAGACGTAGAAAGCATGATTCCAATGGGCTACATCGGCAACCCGGAAGAAATTGCATCAGTTGCAGCATTCTTAGCATCGTCACAAGCAAGCTACGTAACAGGTATTACACTATTTGCTGATGGCGGTATGACAAAATATCCTTCTTTCCAAGCGGGAAGAGGTTAA
<210> 14
<211> 261
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 14
MYKDLEGKVVVITGSSTGLGKAMAIRFATEKAKVVVNYRSKEEEANSVLEEIKKVGGEAIAVKGDVTVESDVINLVQSSIKEFGKLDVMINNAGMENPVSSHEMSLSDWNKVIDTNLTGAFLGSREAIKYFVENDIKGTVINMSSVHEKIPWPLFVHYAASKGGMKLMTETLALEYAPKGIRVNNIGPGAINTPINAEKFADPEQRADVESMIPMGYIGEPEEIAAVAAWLASSEASYVTGITLFADGGMTQ
YPSFQAGRG
<210> 15
<211> 783
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 15
ATGTATCCGGATTTAAAAGGAAAAGTCGTCGCTATTACAGGAGCTGCTTCAGGGCTCGGAAAGGCGATGGCCATTCGCTTCGGCAAGGAGCAGGCAAAAGTGGTTATCAACTATTATAGTAATAAACAAGATCCGAACGAGGTAAAAGAAGAGGTCATCAAGGCGGGCGGTGAAGCTGTTGTCGTCCAAGGAGATGTCACGAAAGAGGAAGATGTAAAAAATATCGTGCAAACGGCAATTAAGGAGTTCGGCACACTCGATATTATGATTAATAATGCCGGTCTTGAAAATCCTGTGCCATCTCACGAAATGCCGCTCAAGGATTGGGATAAAGTCATCGGCACGAACTTAACGGGTGCCTTTTTAGGAAGCCGTGAAGCGATTAAATATTTCGTAGAAAACGATATCAAGGGAAATGTCATTAACATGTCCAGTGTGCACGCGTTTCCTTGGCCGTTATTTGTCCACTATGCGGCAAGTAAAGGCGGGATAAAGCTGATGACAGAAACATTAGCGTTGGAATACGCGCCGAAGGGCATTCGCGTCAATAATATTGGGCCAGGTGCGATCAACACGCCAATCAATGCTGAAAAATTCGCTGACCCTAAACAGAAAGCTGATGTAGAAAGCATGATTCCAATGGGATATATCGGCGAACCGGAGGAGATCGCCGCAGTAGCAGCCTGGCTTGCTTCGAAGGAAGCCAGCTACGTCACAGGCATCACGTTATTCGCGGACGGCGGTATGACACAATATCCTTCATTCCAGGCAGGCCGCGGTTAA
<210> 16
<211> 260
<212> AA
<213> 人工序列(artiartificial sequence)
<400> 16
MYPDLKGKVVAITGAASGLGKAMAIRFGKEQAKVVINYYSNKQDPNEVKEEVIKAGGEAVVVQGDVTKEEDVKNIVQTAIKEFGTLDIMINNAGLENPVPSHEMPLKDWDKVIGTNLTGAFLGSREAIKYFVENDIKGNVINMSSVHAFPWPLFVHYAASKGGIKLMTETLALEYAPKGIRVNNIGPGAINTPINAEKFADPKQKADVESMIPMGYIGEPEEIAAVAAWLASKEASYVTGITLFADGGM
TQYPSFQAGRG