估计机器学习模型系统和应用的最佳训练数据集大小
文献发布时间:2024-04-18 19:58:26
背景技术
机器学习模型在电子设备中被用于各种目的,例如图像分类、物体检测、分割、内容创建、导航和其他任务。机器学习模型通过使用训练数据对其进行训练来学习执行此类任务。在机器学习模型被部署到用户设备中之前,执行验证,以确保机器学习模型至少满足目标验证性能。例如,物体检测机器学习模型在被部署到安全关键应用之前,可能需要满足最小均值平均精度。
对于机器学习模型,其验证性能与训练中使用的训练数据量之间可以存在相关性。对于最初没有达到目标验证性能的模型,提高验证性能的常用技术是通过收集更多的训练数据以进一步训练模型。然而,收集和注释用于训练机器学习模型的数据可能既昂贵又耗时。例如,注释分割数据集可能需要,例如,每个对象15至40秒,这样注释一个由每张图像平均有10辆车的100,000张图像组成的驾驶数据集,花费的时间相当于170天至460天之间。因此,高估满足目标验证性能所需的附加数据量会导致设计者招致不必要的成本和工时,同时还需要大量的计算资源(例如,处理能力、存储等)。此外,过度训练机器学习模型会降低模型超过其训练数据的泛化能力。相反,低估满足目标验证性能所需的附加数据量会导致在后期阶段需要收集更多的数据,从而招致进一步地计算开销和工作流程延迟。因此,确定一个机器学习模型需要多少附加的训练数据以达到目标验证性能是很重要的。
发明内容
本公开的实施例涉及机器学习模型系统和应用的训练数据集大小估计。本公开的系统和方法可协助确定当机器学习模型在用初始训练数据集训练后测试低于目标验证性能时所需的附加训练数据量。
与传统系统相比,本公开呈现的系统和方法针对的是训练数据收集估计函数,该函数使用一个或更多个验证分数估计函数,给定训练数据集大小和模型性能之间的近似关系,估计训练机器学习模型的目标数据要求。验证分数估计函数可以包括,例如,凹形单调递增回归函数,例如但不限于幂律(power law)、反正切(arctan)、对数和/或代数根回归函数。为了得出对训练数据集进行校准的验证分数估计函数,从训练数据集生成回归数据集,并使用回归数据集的子集来训练机器学习模型。为每个子集计算验证分数,并使用验证分数来计算回归函数参数,以便对训练数据集进行所选回归函数曲线拟合。然后,针对
在一些实施例中,在计算
附图说明
下面参考所附附图详细描述用于机器学习模型系统和应用的训练数据集大小估计的本系统和方法,其中;
图1是根据本公开的一些实施例的机器学习模型训练系统的示例流程图的图示;
图2是根据本公开的一些实施例的用于计算附加训练样本的估计的示例流程的图示;
图3是根据本公开的一些实施例的图示用于机器学习模型的训练数据集大小估计的方法的流程图;
图4是根据本公开的一些实施例的用于计算真值(ground truth)的线性分数函数,以结合生成附加训练样本的估计的示例过程流的图示;
图5是根据本公开的一些实施例的用于计算附加训练样本的估计的边界集的示例过程流的图示;
图6是根据本公开的一些实施例的用于与生成附加训练样本的估计一起使用的显示在人机接口上的用户接口的图示;
图7是适合用于实现本公开内容的一些实施例的示例计算设备的框图;以及
图8是适合用于实施本公开内容的一些实施例的示例数据中心的框图。
具体实施方式
公开了与用于机器学习模型系统和应用的训练数据集大小估计有关的系统和方法。本公开内容涉及估计要收集的训练数据量,以训练机器学习模型,满足目标验证性能。机器学习模型的验证性能可能与性能指标有关,例如,但不限于,准确度、精度、召回率、交叉联合(IoU)或其他性能指标。本公开呈现的系统和方法可以帮助确定当机器学习模型在用初始训练数据集训练后测试低于目标验证性能时需要的附加训练数据量。在一些实施例中,至少可以基于从初始训练数据集中选择的样本计算回归函数,以得出一个或更多个验证分数估计函数,从中可以确定满足目标验证性能所需的附加训练样本数量的估计。
本公开呈现的系统和方法是针对训练数据收集估计函数--可在用户设备和/或云计算环境中执行--给定训练数据集大小和模型性能之间的近似关系,估计目标数据需求。这些估计可以使用一个或更多个验证分数估计函数来计算,例如幂律函数。训练数据收集估计函数预测训练数据收集预算,该预算被估计为在有限次数的几轮训练后返回目标模型验证分数。
例如,用于训练模型f的初始训练数据集
在一些实施例中,为了得出验证分数估计函数V
给定的计算的参数θ,验证分数估计函数V
在一些实施例中,随着收集的训练数据集的增长,
其中
在一些实施例中,在从验证分数估计函数计算
因此,数据收集比率可能是验证分数估计函数、训练目标验证分数V*和机器学习模型/任务/算法的函数。在评估一个特定的验证分数估计函数V
在一些实施例中,可以至少基于先前为单独但类似的任务收集的训练数据集来估计校正因数τ。例如,当前的任务可以涉及医学图像的分类。先前的训练数据集可以是为了对不同类型的医学图像的分类而收集,并且已知在类似的机器学习模型架构上产生合格的验证分数(例如,至少是V
在一些实施例中,估计所需的附加训练样本
训练数据收集估计函数及其相应的方法可以例如至少部分地在至少一个图形处理单元(GPU)上执行,该图形处理单元可以与在耦合到存储器的中央处理单元(CPU)上执行的软件一起操作。图形处理单元可被编程为执行与回归数据集一起使用的机器学习模型,以从回归数据集中导出验证分数估计函数V
本文描述的系统和方法可用于各种目的,通过示例和不限制的方式,用于机器控制、机器运动、机器驾驶、合成数据生成、模型训练、感知、增强现实、虚拟现实、混合现实、机器人学、安全和监视、模拟和数字孪生、自主或半自主机器应用、深度学习、环境模拟、物体或行为者模拟和/或数字孪生、数据中心处理、对话式人工智能、轻型运输模拟(例如,光线追踪、路径追踪等)、3D资产的协作内容创建、云计算和/或任何其他合适的应用。
所公开的实施例可包含在各种不同的系统中,例如汽车系统(例如,用于自主或半自主机器的控制系统、用于自主或半自主机器的感知系统)、使用机器人实现的系统、航空系统、医疗系统、船舶系统、智能区域监测系统、用于执行深度学习操作的系统、用于执行模拟操作的系统、用于执行数字孪生操作的系统、使用边缘设备实现的系统、包含一个或更多个虚拟机(VM)的系统、用于执行合成数据生成操作的系统、至少部分地在数据中心中实施的系统、用于执行对话式人工智能操作的系统、用于执行轻型运输模拟的系统、用于执行3D资产的协作内容创建的系统、至少部分地使用云计算资源实现的系统,和/或其他类型的系统。
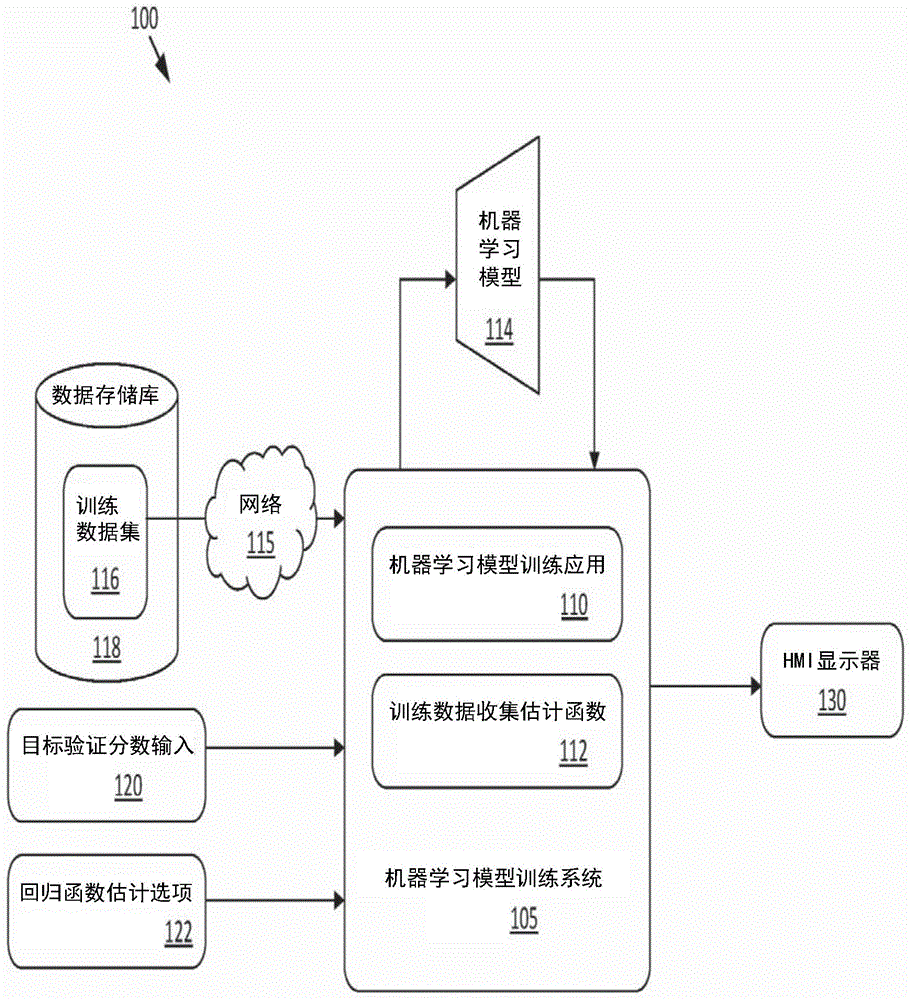
参考图1,图1是根据本公开内容的一些实施例的机器学习模型训练系统105的示例数据流程图100。应当理解,这里描述的这种和其他安排只是作为示例提出的。其他安排和元素(例如,机器、接口、功能、顺序、功能的分组等)可以用来补充或代替示出的那些,并且一些元素可以被完全省略。此外,图1和/或本文其他地方描述的许多元素是功能实体,可以作为离散的或分布的组件实现,或与其他组件一起实现,以任何合适的组合和位置来实现。本文描述的由实体执行的各种功能可以由硬件、固件和/或软件来执行。例如,各种功能可以由处理器执行存储在存储器中的指令来执行。在一些实施例中,系统105可以包括与图7的示例计算设备700和/或图8的示例数据中心800类似的组件、特征和/或功能性。
在未示出的其他组件中,操作环境100可以包括机器学习模型训练系统105,其包括可以耦合到机器学习模型114的机器学习模型训练应用110和训练数据收集估计函数112。机器学习模型114包括一个或更多个机器学习模型,这些模型正在通过机器学习模型训练系统105训练。机器学习模型114可以由机器学习模型训练系统105使用训练数据集116进行训练,训练数据集116在一些实施例中可以驻留在数据存储库118上。机器学习模型114不限于任何特定的机器学习模型架构或神经网络结构,并且可以包括例如但不限于使用线性回归、逻辑回归、决策树、支持向量机(SVM)、朴素贝叶斯、K最近邻(Knn)、K均值聚类、随机森林、降维算法、梯度提升算法、一个或更多个神经网络(例如,自动编码器、卷积、循环、感知器、长/短期记忆(LSTM)、霍普菲尔德(Hopfield)、波尔兹曼(Boltzmann)、深度信念、解卷积、生成对抗和/或液态机等),和/或其他类型的机器学习模型。
在一些实施例中,数据存储库118可以是机器学习模型训练系统105的元素。在一些实施例中,数据存储库118可以通过网络115耦合到机器学习模型训练系统105。举例来说,网络115可以包括一个或更多个广域网(WAN)、一个或更多个局域网(LAN)、一个或更多个公共网络,例如因特网,和/或一个或更多个专用网络。
图1所示的每个组件可以通过任何类型的计算设备来实现。特别是,机器学习模型训练应用110和训练数据收集估计函数112,可以由用户在本地或远程操作的任何类型的计算设备上实现。例如,在一些实施例中,机器学习模型训练系统105的一个或更多个方面可以由图7所示的计算设备700实现,和/或作为通过如图8所示的数据中心800的计算资源实现的组件。尽管为了简单起见,机器学习模型训练应用110和训练数据收集估计函数112被图示为单一实体,但在实践中,归因于此处这些元素的功能可以分布在一个或更多个应用中。在一些实施例中,训练数据收集估计函数112是机器学习模型训练应用110的组件。
机器学习模型训练应用110通常可以是任何能够促进使用本文描述的技术和/或其他技术,无论是靠其自身,还是通过与其他元素的信息交换(例如,通过网络115)的训练机器学习模型114的应用。在一些实施方式中,机器学习模型训练应用110包括web应用,其可以在web浏览器中运行,并且可以至少部分地托管在环境100的服务器端,例如由数据中心800托管。此外,或者相反,机器学习模型训练应用110可以包括专用机器学习模型训练应用。
在一些实施例中,在操作中,机器学习模型训练应用110接收训练数据集116,并应用训练数据集116的训练样本以训练机器学习模型114,并计算训练后的机器学习模型114的验证分数(例如,使用交叉验证或其他验证技术)。在一些实施例中,验证分数是使用测试数据集计算的,该测试数据集包括训练数据集116的单独部分,训练样本是从该训练数据集中得到的。验证分数是一个指标,指示对机器学习模型在提供先前看到的输入数据时预期表现的良好程度的估计。例如,针对分类问题训练的机器学习模型将有一个指示该模型将正确分类图像的概率的验证分数。在一些实施例中,一旦验证分数由机器学习模型训练应用110计算出来,验证分数输出可由机器学习模型训练应用110生成,以便通过人机接口(HMI)显示器130(例如,如呈现组件718)显示给用户。
如上所述,在一些实施例中,训练机器学习模型114将产生低于目标验证性能(例如,目标验证分数)的验证性能。在这一点上,模型设计者(例如,机器学习模型训练系统105的用户)可能需要确定机器学习模型114满足目标验证分数所需的附加训练样本数(例如,
在图1的实施例中,机器学习模型114满足目标验证分数所需的附加训练样本数(例如,
现在参考图2,在200处显示了由训练数据收集估计函数112执行的用于计算附加训练样本的估计值
使用(S,V
在一些实施例中,在218处,训练数据收集估计函数112计算由用户选择的一个或更多个凹形单调递增回归函数的参数θ,如由回归函数估计选项122所指示的。也就是说,训练数据收集估计函数112可以接收幂律、Arctan、对数、代数根和/或其他回归函数的选择作为输入,并基于选择推导出至少一个验证分数估计函数V
给定来自218的计算的参数θ,验证分数估计函数V
现在参考图3,本文描述的方法300的每个框包括可以使用硬件、固件和/或软件的任何组合来执行的计算过程。例如,可以通过处理器执行存储在存储器中的指令来执行各种功能。方法也可以体现为存储在计算机存储介质上的计算机可用指令。方法可以由独立应用程序、服务或托管服务(独立地或与另一托管服务组合)或另一产品的插件提供,仅举几例。此外,作为示例,关于图1的系统描述了方法300,然而,这种方法可以附加地或替代地由任何一个系统或系统的任何组合执行,包括但不限于本文所述的那些。
图3是根据本公开的一些实施例的示出了用于机器学习模型的训练数据集大小估计的方法300的流程图。应该理解的是,这里描述的关于图3的方法300的特征和元素可以与这里讨论的任何其他实施例的元素结合、组合或被替代使用,反之亦然。此外,应该理解的是,图3中描述的实施例的元素的功能、结构和其他描述可以适用于跨越本文描述的任何图和/或实施例的相似或类似地命名或描述的元素,反之亦然。
方法300,在框B302,包括接收指示用于训练机器学习模型的目标验证分数的输入,并且,在框B304,包括接收包括第一数量的训练样本的第一训练数据集。如果在使用第一数量的训练样本训练机器学习模型之后,发现验证分数小于目标验证分数,然后可以计算满足目标验证分数的附加训练数据的附加样本点数目
因此,在一些实施例中,方法300包括,在框B306,至少基于使用回归数据集迭代地重新训练机器学习模型以计算多个验证分数,得出至少一个验证分数估计函数。回归数据集可以从第一训练数据集中取样。多个验证分数可以包括每次迭代的各自验证分数。在一些实施例中,至少一个验证分数估计函数的推导包括对多个验证分数进行曲线拟合以计算至少一个验证分数估计函数的一个或更多个参数。方法300包括,在框B308,至少基于目标验证分数求解至少一个验证分数估计函数,以确定第二附加训练样本数。第二附加训练样本数定义了
对于下一轮训练,可以收集
现在参考图4,显示了由训练数据收集估计函数112执行的用于计算真值的线性分数函数的示例过程流。在一些实施例中,随着训练数据集116的增长,每次收集更多的训练样本
在412,机器学习模型114被重新初始化,并使用i组评估样本中的每一个重新训练,并且在414,为i组评估样本D
从这个真值的线性分数函数中,可以计算出n
在一些实施例中,训练数据收集估计函数112可以计算误差
在至少一个实施例中,用户(例如,设计者)可以选择(例如,使用HMI显示器130上呈现的用户接口)一个或更多个选项来生成合成训练数据和/或增强现有训练数据集116。例如,在一些实施例中,机器学习模型训练系统105可以使用一种或多种数据集增强技术和/或合成训练数据生成技术来生成
现在参考图5,使用训练数据收集估计函数112执行的过程500的示例过程流,用于计算附加训练样本
现在参考图6,图6示出了,在600,示例用户接口610可由机器学习训练应用110生成并呈现,例如呈现在HMI显示器130上。在620,用户接口610包括一个或更多个用户输入元素。例如,用户输入元素620可以接收用户输入622以输入目标验证分数,接收用户输入624用于输入校正因数,和/或接收用户输入626用于输入其他回归函数估计选项,例如选择由训练数据收集估计函数112用作验证分数估计函数的一个或更多个回归函数以估计
用户接口610可以进一步显示估计结果,如630所示。在一些实施例中,估计结果630包括对于用户通过估计选项用户输入626选择的每个验证分数估计函数满足或超过在用户输入622处显示的目标验证分数(受制于在用户输入624处输入的任何校正因数)所需的附加数据样本数的估计
在一些实施例中,用户接口610可以进一步包括图形显示640,该图形显示610包括针对每个验证分数估计函数(在本示例中示出为V
示例计算设备
图7为适合用于实现本公开一些实施例的示例计算设备700的框图,诸如但不限于机器学习模型训练系统105。计算设备700可以包括直接或间接耦合下列设备的互连系统702:存储器704,一个或更多个中央处理单元(CPU)706,一个或更多个图形处理单元(GPU)708,通信接口710,输入/输出(I/O)端口712,输入/输出组件714,电源716,一个或更多个呈现组件718(例如,显示器,诸如HMI显示器130)和一个或更多个逻辑单元720。在至少一个实施例中,计算设备700可以包括一个或更多个虚拟机(VM),和/或其任何组件可以包括虚拟组件(例如,虚拟硬件组件)。对于非限制性示例,一个或更多个GPU 708可以包括一个或更多个vGPU,一个或更多个CPU 706可以包括一个或更多个vCPU,和/或一个或更多个逻辑单元720可以包括一个或更多个虚拟逻辑单元。因此,计算设备700可以包括分立组件(例如,专用于计算设备700的完整GPU)、虚拟组件(例如,专用于计算设备700的GPU的一部分),或其组合。
尽管图7的各个框被示为经由具有线路的互连系统702连接,但是这并不意图是限制性的,并且仅仅为了清楚起见。例如,在一些实施例中,诸如显示设备之类的呈现组件718可以被认为是I/O组件714(例如如果显示器为触摸屏)。作为另一个示例,CPU 706和/或GPU708可以包括存储器(例如,存储器704可以表示除了GPU 708、CPU 706和/或其他组件的存储器以外的存储设备)。换言之,图7的计算设备仅仅是说明性的。在诸如“工作站”、“服务器”、“膝上型电脑”、“台式机”、“平板电脑”、“客户端设备”、“移动设备”、“手持式设备”、“游戏控制台”、“电子控制单元(ECU)”、“虚拟现实系统”和/或其他设备或系统类型之类的类别之间不进行区分,因为所有这些都被考虑在图7的计算设备的范围内。
互连系统702可以表示一条或更多条链路或总线,例如地址总线、数据总线、控制总线或者其组合。互连系统702可以包括一种或更多种链路或总线类型,例如行业标准架构(ISA)总线、扩展行业标准架构(EISA)总线、视频电子标准协会(VESA)总线、外围组件互连(PCI)总线、外围组件互连快速(PCIe)总线,和/或另一种类型的总线或链路。在一些实施例中,组件之间存在直接连接。作为示例,CPU 706可以直接连接到存储器704。此外,CPU 706可以直接连接到GPU 708。在组件之间存在直接或点对点连接的情况下,互连系统702可以包括PCIe链路来执行该连接。在这些示例中,计算设备700中不需要包括PCI总线。
存储器704可以包括各种各样的计算机可读介质中的任何介质。计算机可读介质可以是可以由计算设备700访问的任何可用介质。计算机可读介质可以包括易失性和非易失性介质以及可移除和不可移除介质。举例而言且非限制性地,计算机可读介质可以包括计算机存储介质和通信介质。
计算机存储介质可以包括易失性和非易失性介质和/或可移除和不可移除介质,其以用于存储诸如计算机可读指令、数据结构、程序模块和/或其他数据类型之类的信息的任何方法或技术实现。例如,存储器704可以存储计算机可读指令(例如其表示程序和/或程序元素,例如操作系统)。计算机存储介质可以包括但不限于RAM、ROM、EEPROM、闪存或者其他存储技术、CD-ROM、数字多功能盘(DVD)或其他光盘存储装置、磁带盒、磁带、磁盘存储装置或其他磁存储设备,或者可以用来存储期望的信息且可以由计算设备700访问的任何其他介质。当在本文使用时,计算机存储介质并不包括信号本身。
计算机存储介质可以在诸如载波之类的调制数据信号或其他传输机制中包含计算机可读指令、数据结构、程序模块和/或其他数据类型,并且包括任何信息输送介质。术语“调制数据信号”可以指这样的信号,该信号使它的特性中的一个或更多个以这样的将信息编码到该信号中的方式设置或改变。举例而言且非限制性地,计算机存储介质可以包括诸如有线网络或直接有线连接之类的有线介质,以及诸如声音、RF、红外和其他无线介质之类的无线介质。任何以上所述的组合也应当包含在计算机可读介质的范围内。
CPU 706可以被配置为执行计算机可读指令中的至少一些,以便控制计算设备700的一个或更多个组件执行本文描述的方法和/或过程中的一个或更多个。CPU 706中的每一个可以包括能够同时处理大量软件线程的一个或更多个核(例如一个、两个、四个、八个、二十八个、七十二个等等)。CPU 706可以包括任何类型的处理器,并且可以包括不同类型的处理器,这取决于实现的计算设备700的类型(例如具有用于移动设备的较少核的处理器以及具有用于服务器的更多核的处理器)。例如,取决于计算设备700的类型,处理器可以是使用精简指令集计算(RISC)实现的高级RISC机制(ARM)处理器或者使用复杂指令集计算(CISC)实现的x86处理器。除了一个或更多个微处理器或者诸如数学协处理器之类的补充协处理器之外,计算设备700还可以包括一个或更多个CPU 706。
除了或替代CPU 706,GPU 708还可以被配置为执行至少一些计算机可读指令,以控制计算设备700的一个或更多个组件执行一个或更多个本文所述的方法和/或过程。在一些实施例中,机器学习模型114由一个或更多个GPU 708实现。一个或更多个GPU 708可以是集成GPU(例如,具有一个或更多个CPU 706)和/或一个或更多个GPU 708可以是离散GPU。在实施例中,一个或更多个GPU 708可以是一个或更多个CPU 706的协处理器。计算设备700可以使用GPU 708来渲染图形(例如,3D图形)或执行通用计算。例如,GPU 708可用于GPU上的通用计算(GPGPU)。GPU708可以包括能够同时处理数百或数千个软件线程的数百或数千个核。GPU 708可以响应于渲染命令(例如经由主机接口接收的来自CPU 706的渲染命令)而生成用于输出图像的像素数据。GPU 708可以包括诸如显示存储器之类的用于存储像素数据或任何其他合适的数据(例如GPGPU数据)的图形存储器。显示存储器可以作为存储器704的部分而被包括。GPU708可以包括(例如经由链路)并行操作的两个或更多GPU。链路可以直接连接GPU(例如,使用NVLINK),也可以通过交换机(例如,使用NVSwitch)连接GPU。当组合在一起时,每个GPU 708可以生成用于输出的不同部分或者用于不同输出的像素数据或GPGPU数据(例如,第一GPU用于第一图像,第二GPU用于第二图像)。每个GPU可以包括它自己的存储器,或者可以与其他GPU共享存储器。在一些实施例中,用于由HMI显示器130显示的用户接口(例如,诸如图6的用户接口610)由GPU708生成。
除了或替代CPU 706和/或GPU 708,逻辑单元720可以被配置为执行至少一些计算机可读指令,以控制计算设备700的一个或更多个组件来执行本文描述的一种或更多种方法和/或过程。在实施例中,CPU 706、GPU708和/或逻辑单元720可以离散地或联合地执行方法、过程和/或其部分的任何组合。一个或更多个逻辑单元720可以是一个或更多个CPU 706和/或一个或更多个GPU 708的一部分和/或集成在其中和/或一个或更多个逻辑单元720可以是CPU 706和/或GPU 708的离散组件或以其他方式在其外部。在实施例中,一个或更多个逻辑单元720可以是一个或更多个CPU706和/或一个或更多个GPU 708的处理器。
逻辑单元720的示例包括一个或更多个处理核心和/或其组件,例如数据处理单元(DPU)、张量核心(TC)、张量处理单元(TPU)、像素视觉核心(PVC)、视觉处理单元(VPU)、图形处理集群(GPC)、纹理处理集群(TPC)、流式多处理器(SM)、树遍历单元(TTU)、人工智能加速器(AIA)、深度学习加速器(DLA)、算术逻辑单元(ALU))、专用集成电路(ASIC)、浮点单元(FPU)、输入/输出(I/O)元件、外围组件互连(PCI)或外围组件互连快速(PCIe)元件等。
通信接口710可以包括一个或更多个接收器、发送器和/或收发器,其使得计算设备700能够经由电子通信网络与其他计算设备通信,包括有线和/或无线通信。在一些实施例中,机器学习模型训练系统的一个或更多个组件可以由通信接口710耦合到网络115。通信接口710可以包括使能通过若干不同网络中的任何网络进行通信的组件和功能,所述网络例如无线网络(例如Wi-Fi、Z波、蓝牙、蓝牙LE、ZigBee等等)、有线网络(例如通过以太网或InfiniBand通信)、低功率广域网(例如LoRaWAN、SigFox等等)和/或因特网。在一个或更多个实施例中,逻辑单元720和/或通信接口710可以包括一个或更多个数据处理单元(DPU)以将通过网络和/或通过互连系统702接收的数据直接传输到一个或更多个GPU 708(例如,一个或更多个GPU 708的存储器)。
I/O端口712可以使得计算设备700能够逻辑地耦合到包括I/O组件714、呈现组件718和/或其他组件在内的其他设备,其中一些可以内置到(例如集成到)计算设备700中。说明性I/O组件714包括麦克风、鼠标、键盘、操纵杆、游戏垫、游戏控制器、碟形卫星天线、浏览仪、打印机、无线设备等等。I/O组件714可以提供处理用户生成的空中手势、语音或其他生理输入的自然用户接口(NUI)。在一些实例中,输入可以传输至适当的网络元件以便进一步处理。NUI可以实现语音识别、手写笔识别、面部识别、生物特征识别、屏幕上和邻近屏幕的手势识别、空中手势、头部和眼睛跟踪以及与计算设备700的显示器关联的触摸识别(如下文更详细地描述的)的任意组合。计算设备700可以包括诸如立体相机系统之类的深度相机、红外相机系统、RGB相机系统、触摸屏技术以及这些的组合,以用于手势检测和识别。此外,计算设备700可以包括使能运动检测的加速度计或陀螺仪(例如作为惯性测量单元(IMU)的部分)。在一些示例中,加速度计或陀螺仪的输出可以由计算设备700用来渲染沉浸式增强现实或者虚拟现实。
电源716可以包括硬接线电源、电池电源或者其组合。电源716可以向计算设备700供电以使得计算设备700的组件能够操作。
呈现组件718可以包括显示器(例如监视器、触摸屏、电视屏幕、平视显示器(HUD)、其他显示器类型或者其组合)、扬声器和/或其他呈现组件。呈现组件718可以接收来自其他组件(例如GPU 708、CPU 706、DPU等等)的数据,并且输出该数据(例如作为图像、视频、声音等等)。
示例数据中心
图8示出了示例数据中心800,其可用于本公开的至少一个实施例中。数据中心800可以包括数据中心基础设施层810、框架层820、软件层830和应用层840。
如图8所示,数据中心基础设施层810可以包括资源协调器812、分组计算资源814和节点计算资源(“节点C.R.”)816(1)-816(N),其中“N”代表任何完整的正整数。在至少一个实施例中,节点C.R.816(1)-816(N)可以包括但不限于任何数量的中央处理单元(“CPU”)或其他处理器(包括DPU、加速器、现场可编程门阵列(FPGA)、图形处理器或图形处理单元(GPU)等),存储器设备(例如动态只读存储器),存储设备(例如固态硬盘或磁盘驱动器),网络输入/输出(“NW I/O”)设备,网络交换机,虚拟机(“VM”),电源模块和冷却模块等。在一些实施例中,节点C.R.816(1)-816(N)中的一个或更多个节点C.R.可以对应于具有一个或更多个上述计算资源的服务器。此外,在一些实施例中,节点C.R.816(1)-816(N)可以包括一个或更多个虚拟组件,例如vGPU、vCPU等,和/或节点C.R.816(1)-816(N)中的一个或更多个可以对应于虚拟机(VM)。
在至少一个实施例中,分组计算资源814可以包括容纳在一个或更多个机架内的节点C.R.816的单独分组(未示出),或者容纳在各个地理位置的数据中心内的许多机架(也未示出)。分组计算资源814内的节点C.R.816的单独分组可以包括可以被配置或分配为支持一个或更多个工作负载的分组的计算、网络、存储器或存储资源。在至少一个实施例中,可以将包括CPU、GPU、DPU和/或其他处理器的几个节点C.R.816分组在一个或更多个机架内,以提供计算资源来支持一个或更多个工作负载。一个或更多个机架还可以包括以任意组合的任何数量的电源模块、冷却模块和/或网络交换机。
资源协调器812可以配置或以其他方式控制一个或更多个节点C.R.816(1)-816(N)和/或分组计算资源814。在至少一个实施例中,资源协调器812可以包括用于数据中心800的软件设计基础结构(“SDI”)管理实体。资源协调器812可以包括硬件、软件或其某种组合。
在至少一个实施例中,如图8所示,框架层820可以包括作业调度器822、配置管理器834、资源管理器836和分布式文件系统838。框架层820可以包括支持软件层830的软件832和/或应用层840的一个或更多个应用程序842的框架。软件832或应用程序842可以分别包括基于Web的服务软件或应用程序,例如由Amazon Web Services,Google Cloud和Microsoft Azure提供的服务软件或应用程序。框架层820可以是但不限于一种免费且开源的软件网络应用框架,例如可以利用分布式文件系统838来进行大规模数据处理(例如“大数据”)的Apache Spark
在至少一个实施例中,包括在软件层830中的软件832可以包括由节点C.R.816(1)-816(N)的至少部分,分组计算资源814和/或框架层820的分布式文件系统838使用的软件。一种或更多种类型的软件可以包括但不限于Internet网页搜索软件、电子邮件病毒浏览软件、数据库软件和流视频内容软件。
在至少一个实施例中,应用层840中包括的一个或更多个应用程序842可以包括由节点C.R.816(1)-816(N)的至少部分、分组的计算资源814和/或框架层820的分布式文件系统838使用的一种或更多种类型的应用程序。一种或更多种类型的应用程序可以包括但不限于任何数量的基因组学应用程序,认知计算和机器学习应用程序,包括训练或推理软件,机器学习框架软件(例如PyTorch、TensorFlow、Caffe等)和/或其他与一个或更多个实施例结合使用的机器学习应用程序。
在至少一个实施例中,配置管理器834、资源管理器836和资源协调器812中的任何一个可以基于以任何技术上可行的方式获取的任何数量和类型的数据来实现任何数量和类型的自我修改动作。自我修改动作可以减轻数据中心800的数据中心操作员做出可能不好的配置决定并且可以避免数据中心的未充分利用和/或行差的部分。
数据中心800可以包括工具、服务、软件或其他资源,用于根据本文所述的一个或更多个实施例来训练一个或更多个机器学习模型或者使用一个或更多个机器学习模型来预测或推理信息。例如,用于训练一个或更多个学习模型的这些工具、服务、软件或其他资源可以包括机器学习模型系统105的一个或更多个组件,诸如机器学习模型训练应用110和/或训练数据收集估计函数112。例如,可以通过使用上文关于数据中心800描述的软件、机器学习模型训练应用110和/或计算资源,根据神经网络架构计算权重参数来训练机器学习模型,诸如机器学习模型114。在至少一个实施例中,通过使用通过一种或更多种训练技术计算出的权重参数,可以使用上面与关于数据中心800所描述的资源,使用对应于一个或更多个神经网络的经训练的机器学习模型来推理或预测信息,例如但不限于本文所述的那些。
在至少一个实施例中,数据中心800可以使用CPU、专用集成电路(ASIC)、GPU、FPGA和/或其他硬件(或与之对应的虚拟计算资源)来使用上述资源来执行训练和/或推理。此外,上述的一个或更多个软件和/或硬件资源可以配置成一种服务,以允许用户训练或执行信息推理,例如图像识别、语音识别或其他人工智能服务。
示例网络环境
适用于实现本公开的实施例的网络环境可以包括一个或更多个客户端设备、服务器、网络附加存储(NAS)、其他后端设备和/或其他设备类型。客户端设备、服务器和/或其他设备类型(例如,每个设备)可以在图7的计算设备700的一个或更多个实例上实现—例如,每个设备可以包括计算设备700的类似组件、特征和/或功能。此外,在实现后端设备(例如,服务器、NAS等)的情况下,后端设备可以是作为数据中心800的一部分而被包括的,其示例在此关于图8更详细地描述。
网络环境的组件可以通过网络(例如,诸如网络115)彼此通信,网络可以是有线、无线或两者。网络可以包括多个网络,或者多个网络中的网络。举例来说,网络可以包括一个或更多个广域网(WAN)、一个或更多个局域网(LAN)、一个或更多个公共网络(例如因特网和/或公共交换电话网(PSTN))、和/或一个或更多个专用网络。在网络包括无线电信网络的情况下,诸如基站、通信塔或甚至接入点(以及其他组件)之类的组件可以提供无线连接。
兼容的网络环境可以包括一个或更多个对等网络环境(在这种情况下服务器可能不包括在网络环境中),以及一个或更多个客户端-服务器网络环境(在这种情况下一个或更多个服务器可以包含在网络环境中)。在对等网络环境中,本文描述的关于服务器的功能可以在任意数量的客户端设备上实现。
在至少一个实施例中,网络环境可以包括一个或更多个基于云的网络环境、分布式计算环境、它们的组合等。基于云的网络环境可以包括框架层、作业调度器、资源管理器,以及在一个或更多个服务器上实现的分布式文件系统,这些服务器可以包括一个或更多个核心网络服务器和/或边缘服务器。框架层可以包括用于支持软件层的软件和/或应用层的一个或更多个应用程序的框架。软件或应用程序可分别包括基于网络的服务软件或应用程序。在实施例中,一个或更多个客户端设备可以使用基于网络的服务软件或应用程序(例如,通过经由一个或更多个应用程序编程接口(API)访问服务软件和/或应用程序)。框架层可以是但不限于一种类型的免费且开源软件网络应用程序框架,例如可以使用分布式文件系统进行大规模数据处理(例如,“大数据”)。
基于云的网络环境可以提供执行本文描述的计算和/或数据存储功能(或其一个或更多个部分)的任何组合的云计算和/或云存储。例如,在一些实施例中,在这样的基于云网络环境中数据存储库118可以被实现为云存储。这些各种功能中的任何一个都可以分布在来自(例如,可以分布在州、地区、国家、全球等地的一个或更多个数据中心的)中央或核心服务器的多个位置。如果到用户(例如,客户端设备)的连接相对靠近边缘服务器,则核心服务器可以将功能的至少一部分指定给边缘服务器。基于云的网络环境可以是私有的(例如,仅限于单个组织),可以是公共的(例如,对许多组织可用),和/或其组合(例如,混合云环境)。
客户端设备可以包括本文关于图7描述的示例计算设备700的至少一些组件、特征和功能。作为示例而非限制,客户端设备可以体现为个人计算机(PC)、膝上型计算机、移动设备、智能手机、平板计算机、智能手表、可穿戴计算机、个人数码助理(PDA)、MP3播放器、虚拟现实头戴式显示器、全球定位系统(GPS)或设备、视频播放器、摄像机、监视设备或系统、车辆、船只、飞行器、虚拟机器、无人机、机器人、手持通信设备、医院设备、游戏设备或系统、娱乐系统、车载计算机系统、嵌入式系统控制器、遥控器、电器、消费电子设备、工作站、边缘设备、这些描述设备的任意组合或任何其他合适的设备。
本公开可以在由计算机或者诸如个人数字助理或其他手持式设备之类的其他机器执行的、包括诸如程序模块之类的计算机可执行指令的机器可使用指令或者计算机代码的一般背景下进行描述。通常,包括例程、程序、对象、组件、数据结构等等的程序模块指的是执行特定任务或者实现特定抽象数据类型的代码。本公开可以在各种各样的系统配置中实践,这些配置包括手持式设备、消费电子器件、通用计算机、更专业的计算设备等等。本公开也可以在其中任务由通过通信网络链接的远程处理设备执行的分布式计算环境中实践。
如在本文中使用的,“和/或”关于两个或更多元素的叙述应当解释为仅指一个元素或者元素组合。例如,“元素A、元素B和/或元素C”可以包括仅仅元素A,仅仅元素B,仅仅元素C,元素A和元素B,元素A和元素C,元素B和元素C,或者元素A、B和C。此外,“元素A或元素B中的至少一个”可以包括元素A中的至少一个,元素B中的至少一个,或者元素A中的至少一个和元素B中的至少一个。进一步,“元素A和元素B中的至少一个”可以包括元素A中的至少一个,元素B中的至少一个,或者元素A中的至少一个和元素B中的至少一个。
这里详细地描述了本公开的主题以满足法定要求。然而,描述本身并非意在限制本公开的范围。相反地,本发明人已经设想到,要求保护的主题也可以以其他的方式具体化,以包括与本文中结合其他当前或未来技术描述的步骤不同的步骤或者相似的步骤的组合。而且,尽管术语“步骤”和/或“块”在本文中可以用来隐含采用的方法的不同元素,但是这些术语不应当被解释为暗示本文公开的各个步骤之中或之间的任何特定顺序,除非明确描述了各步骤的顺序。
- 一种面向大规模机器学习系统的机器学习模型训练方法
- 用于训练机器学习模型和用于提供患者的估计内部图像的系统和方法
- 一种机器学习模型的训练数据集均匀化处理方法