基于HTTP代理的爬虫系统及其实现方法
文献发布时间:2023-06-19 10:58:46
技术领域
本发明涉及信息技术领域,具体地,涉及基于HTTP代理的爬虫系统及其实现方法。
背景技术
为了提高爬虫的隐蔽性,目前的许多爬虫技术方案选择将爬虫部署在浏览器内,由用户操作浏览器进行信息爬取。
可是这些方案的实施大部分需要在浏览器上进行大量人工操作,不适合大批量的数据获取。而像Web Scraper这样只需用户进行少量工作的自动化爬虫浏览器插件,也存在不适合与大批量数据爬取和无法应对网页的字体反爬措施的问题。
发明内容
针对现有技术中的缺陷,本发明的目的是提供一种基于HTTP代理的爬虫系统及其实现方法。
第一方面,本发明提供一种基于HTTP代理的爬虫系统,包括:爬虫任务创建模块、爬虫特征处理模块、爬虫任务执行模块、信息存储模块和浏览器,其中:
所述爬虫任务创建模块,用于根据爬虫任务种子信息确定爬虫任务,并构造对应的url;
所述爬虫任务执行模块,用于获取和执行所述爬虫任务,以及提取网站页面信息;
所述爬虫特征处理模块,用于在浏览器向网站服务器发送请求时,修改请求头信息;
所述信息存储模块,用于存储提取的网站页面信息。
可选地,所述爬虫任务创建模块包括:爬虫种子处理单元和爬虫任务创建单元,其中:
所述爬虫种子处理单元,用于存储爬虫任务种子和种子相关信息;
所述爬虫任务创建单元,用于根据爬虫任务种子和种子相关信息确定爬虫任务,并构造对应的url。
可选地,所述爬虫任务执行模块包括:爬虫任务获取单元、页面信息处理单元、信息存储单元和自动化单元,其中:
所述爬虫任务获取单元,用于从所述爬虫任务创建模块获取爬虫任务;
所述页面信息处理单元,用于提取网站页面信息,以及解析得到网站中的字体反爬机制;
所述信息存储获取单元,用于将提取后的网站网页信息传输给所述信息存储模块进行保存,所述网站网页信息包括:查重机制和查重最大上线机制;
所述自动化单元,用于在当前网页中镶嵌脚本,并寻找当前网页下的子网页url。
可选地,所述浏览器包括:标准版本浏览器,或者第三方无头浏览器。
可选地,所述信息存储模块采用MySQL数据库。
可选地,所述爬虫任务执行模块运行时采用HTTP代理脚本。
第二方面,本发明提供一种基于HTTP代理的爬虫实现方法,其特征在于,应用于第一方面中任一项所述的基于HTTP代理的爬虫系统,所述方法包括:
步骤1:开启HTTP代理,在HTTP代理中运行各个模块的脚本,所述脚本包括:爬虫特征处理脚本、获取爬虫任务脚本、页面信息处理脚本、信息存储脚本和网页自动化脚本;
步骤2:在HTTP代理地址下开启浏览器并定位到预设的标签页面;
步骤3:根据所述预设的标签页面,向服务请求任务网页;
步骤4:提取和保存网站网页信息。
可选地,所述步骤3包括:
步骤3.1:当HTTP代理中的爬虫任务脚本接受到标签页面的响应时,向爬虫任务创建单元请求爬虫任务,获取url;
步骤3.2:当接收到爬虫任务后,在标签页面中添加定位脚本;
步骤3.3:当浏览器接收到添加的定位脚本后,运行所述定位脚本,并向服务器请求任务网页。
可选地,所述步骤4包括:
步骤4.1:当接收到任务网页响应信息时,使用相关解析库提取网站网页信息;
步骤4.2:当网站网页信息中存在字体反爬机制时,通过字体反爬机制进行处理,得到处理后的信息;
步骤4.3:将处理后的信息发送到数据库;
步骤4.4:检查数据库中是否存在重复的信息,若存在重复的信息,则取消保存,并回复HTTP代理:已存在重复信息;若不存在重复的信息,则保存所述处理后的信息。
可选地,还包括:
步骤5:执行网页中镶嵌的自动化脚本,并通过浏览器判断页面中是否存在子网页url;若存在,则向网站服务器请求子网页,若不存在,则返回执行步骤2;
步骤6:当网站网页信息中提取到的重复信息超过限定次数,则在当前网页中镶嵌定位脚本,并返回执行步骤3;
步骤7:判断爬虫任务是否执行完毕后,若是,则整个爬虫结束,若否,则返回执行步骤3。
与现有技术相比,本发明具有如下的有益效果:
本发明提供的基于HTTP代理的爬虫系统及其实现方法,既可以对HTTP请求头中比较重要的信息进行修改,也可以在使用第三方无头浏览器时,隐藏第三方无头浏览器的特征,防止被网站检测,进一步提升浏览器爬虫的隐蔽性,并且可以简化浏览器操作,适用于大批量的爬取数据。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明实施例提供的基于HTTP代理的爬虫系统的结构示意图;
图2为本发明实施例提供的基于HTTP代理的爬虫实现方法的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本发明的目的在于提供一种基于HTTP代理的爬虫系统及其实现方法,旨在解决现有爬虫系统隐蔽性不强,以及人工操作较多的问题。
本发明中HTTP代理在这主要是是指普通代理,这种代理扮演的是中间人角色,对于连接到它的客户端来说,它是服务端;对于要连接的服务端来说,它是客户端。它就负责在两端之间来回传送HTTP报文。在本发明的HTTP代理中,代理的作用除了适时的查、记录其截获的数据之外,还可以定制脚本,在服务器或浏览器接受到请求和响应之前,完成修改报文的操作,从而可以引发服务端或客户端特定的行为。
统一资源定位符(Uniform Resource Locator,URL)是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
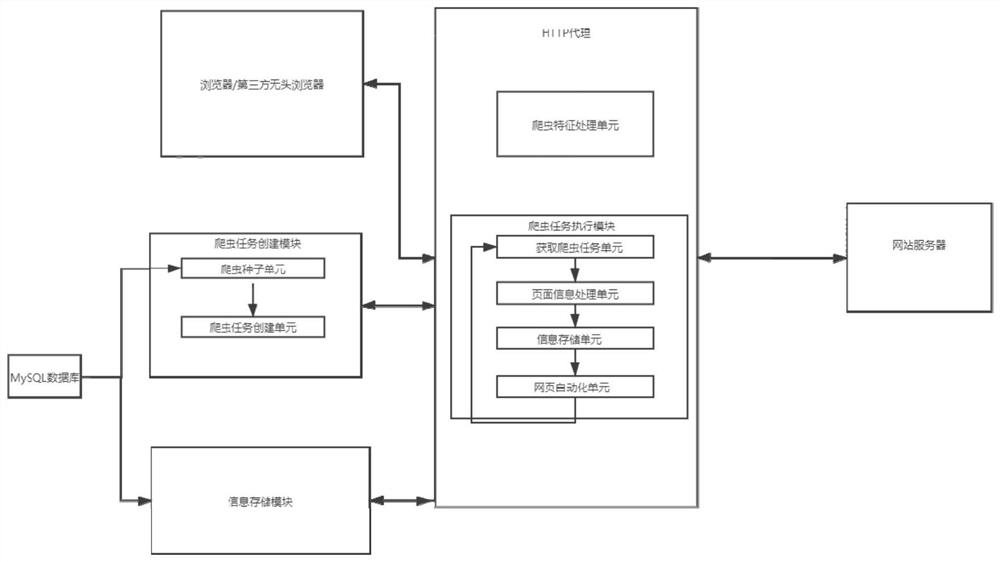
图1为本发明实施例提供的基于HTTP代理的爬虫系统的结构示意图,如图1所示,本实施例中的系统可以包括::爬虫任务创建模块、爬虫特征处理模块、爬虫任务执行模块、信息存储模块和浏览器,其中:爬虫任务创建模块,用于根据爬虫任务种子信息确定爬虫任务,并构造对应的url;爬虫任务执行模块,用于获取和执行爬虫任务,以及提取网站页面信息;爬虫特征处理模块,用于在浏览器向网站服务器发送请求时,修改请求头信息;信息存储模块,用于存储提取的网站页面信息。
示例性的,参见图1,爬虫任务创建模块包括:爬虫种子处理单元和爬虫任务创建单元,其中:爬虫种子处理单元,用于存储爬虫任务种子和种子相关信息;爬虫任务创建单元,用于根据爬虫任务种子和种子相关信息确定爬虫任务,并构造对应的url。
示例性的,参见图1,爬虫任务执行模块包括:爬虫任务获取单元、页面信息处理单元、信息存储单元和自动化单元,其中:爬虫任务获取单元,用于从爬虫任务创建模块获取爬虫任务;页面信息处理单元,用于提取网站页面信息,以及解析得到网站中的字体反爬机制;信息存储获取单元,用于将提取后的网站网页信息传输给信息存储模块进行保存,网站网页信息包括:查重机制和查重最大上线机制;自动化单元,用于在当前网页中镶嵌脚本,并寻找当前网页下的子网页url。
需要说明的是,本实施例中的浏览器可以采用标准版本浏览器,或者第三方无头浏览器。
示例性的,本实施例中信息存储模块可以采用MySQL数据库。
示例性的,本实施例中爬虫任务执行模块运行时均采用HTTP代理脚本。
本实施例的爬虫系统由于HTTP代理可以在网站服务器接收到请求和浏览器接收到响应之前接收到报文,所以既可以对HTTP请求中比较重要的信息(如Referer,User-Agent)进行修改,也可以在使用第三方无头浏览器时,隐藏第三方无头浏览器的特征,防止被网站检测,进一步提升浏览器爬虫的隐蔽性。
本实施例的爬虫系统在代理中定制脚本,若网页中有字体反爬措施,在HTTP代理脚本中也方便调用相应的库进行处理;在相应的网页源代码中镶嵌脚本,通过控制DOM的方法,在浏览器接收到响应后,自动请求该网页下的子网页,省去了在浏览器前的大量人工操作,适合大批量爬取数据。
图2为本发明实施例提供的基于HTTP代理的爬虫实现方法的流程图,如图2所示,本实施例中的方法可以包括:
步骤1:开启HTTP代理,在HTTP代理中运行各个模块的脚本,脚本包括:爬虫特征处理脚本、获取爬虫任务脚本、页面信息处理脚本、信息存储脚本和网页自动化脚本。
在步骤1中,开启HTTP代理,在代理中运行所有脚本,包括爬虫特征处理脚本,获取爬虫任务脚本,页面信息处理脚本,信息存储脚本和网页自动化脚本。其中爬虫特征处理脚本在每一次请求和响应中执行,用于在每一次请求中修改请求头信息和每一次响应中在网页注入脚本隐藏第三方无头浏览器的特征,防止被当前网页自带的检测脚本检测。
步骤2:在HTTP代理地址下开启浏览器并定位到预设的标签页面。
在步骤2中,在代理地址下开启浏览器,可由用户自己登录访问标签页面,也可以使用第三方无头浏览器,自动登录网站,并且定位到设定好的标签页面。
步骤3:根据预设的标签页面,向服务请求任务网页。
在步骤3中,当HTTP代理中的爬虫任务脚本接受到标签页面的响应时,向爬虫任务创建单元请求爬虫任务,获取url;当接收到爬虫任务后,在标签页面中添加定位脚本;当浏览器接收到添加的定位脚本后,运行定位脚本,并向服务器请求任务网页。
步骤4:提取和保存网站网页信息。
在步骤4中,当接收到任务网页响应信息时,使用相关解析库提取网站网页信息;当网站网页信息中存在字体反爬机制时,通过字体反爬机制进行处理,得到处理后的信息;将处理后的信息发送到数据库;检查数据库中是否存在重复的信息,若存在重复的信息,则取消保存,并回复HTTP代理:已存在重复信息;若不存在重复的信息,则保存处理后的信息。
本实施例中,当代理中的页面信息处理单元接收到任务网页响应信息后,使用相关解析库提取网页信息,若该网页有字体反爬机制,则交由字体反爬机制处理。然后将处理后的信息发送到数据库,若数据存储模块检查存在重复信息则取消保存,并回复HTTP代理重复信息,若不存在则保存数据。
示例性的,上述方法还可以包括:
步骤5:执行网页中镶嵌的自动化脚本,并通过浏览器判断页面中是否存在子网页url;若存在,则向网站服务器请求子网页,若不存在,则返回执行步骤2。
在步骤5中,当信息存储单元结束后,代理中的网页自动化单元会在目标网页中镶嵌自动化脚本,再发送给浏览器,通过控制DOM的方法,浏览器接收后会检测当前页面中的是否有所设定的子网页url。若有,便向网站服务器请求子网页,若没有,重新请求到标签网页。当代理中的爬虫任务脚本接受到标签页面的响应时,向爬虫任务创建单元请求新任务。
步骤6:当网站网页信息中提取到的重复信息超过限定次数,则在当前网页中镶嵌定位脚本,并返回执行步骤3。
在步骤6中,若目标网页重复信息超过限定次数,代理中的网页自动化单元会在当前网页中镶嵌定位脚本,使浏览器接受后请求到标签页面,当代理中的爬虫任务脚本接受到标签页面的响应时,向爬虫任务创建单元请求新任务。
步骤7:判断爬虫任务是否执行完毕后,若是,则整个爬虫结束,若否,则返回执行步骤3。
在步骤7中,当爬虫任务创建单元已无任务,或者在爬虫任务获取单元所设定的任务都执行完毕后,整个爬虫结束。
本实施例,由于HTTP代理可以在网站服务器接收到请求和浏览器接收到响应之前接收到报文,所以既可以对HTTP请求头中比较重要的信息进行修改,也可以在使用第三方无头浏览器时,隐藏第三方无头浏览器的特征,防止被网站检测,进一步提升浏览器爬虫的隐蔽性。本实施例的爬虫系统在代理中定制脚本,若网页中有字体反爬措施,在HTTP代理脚本中也方便调用相应的库进行处理;在相应的网页源代码中镶嵌脚本,通过控制DOM的方法,在浏览器接收到响应后,自动请求该网页下的子网页,省去了在浏览器前的大量人工操作,适合大批量爬取数据。
需要说明的是,本发明提供的基于HTTP代理的爬虫实现方法中的步骤,可以利用基于HTTP代理的爬虫系统中对应的模块、装置、单元等予以实现,本领域技术人员可以参照系统的技术方案实现方法的步骤流程,即,系统中的实施例可理解为实现方法的优选例,在此不予赘述。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 基于HTTP代理的爬虫系统及其实现方法
- 实现HTTPS透明代理的方法和系统