基于解耦知识蒸馏的个性化联邦学习方法
文献发布时间:2024-04-18 19:58:26
技术领域
本申请涉及人工智能与医学诊断领域,具体而言,涉及一种基于解耦知识蒸馏的个性化联邦学习方法.
背景技术
在过去的几年里,数字医疗数据大幅增长,当机器学习面对医学数据量大且分布广,很容易造成数据隐私的问题,而联邦学习是一种保护数据隐私的机器学习技术,它通过在模型学习的每轮迭代中传递本地模型更新,再利用私有数据在本地进行训练.但是,由于数据的独立不同分布的特性,服务器全局模型可能比基于私有数据进行训练的本地模型表现更差;其次,服务器端和客户端的训练目标可能不同,其中服务器追求通用模型,而客户端追求个性化模型;第三,客户端可能需要为各种场景和任务设计定制模型;因此,为解决在医学领域联邦学习本地个性化的这一难题,我们通过在本地客户端加入解耦知识蒸馏的方式来实现.
发明内容
为了解决上述技术问题,本发明的目的是提供一种基于解耦知识蒸馏的个性化联邦学习方法,实现了本地客户端合作训练全局模型和本地客户端独立训练个性化模型.包括以下步骤:
数据准备:本方法基于公开的计算机辅助胃肠道疾病检测的八分类图像数据集(Kvasir),它由8000张医学图像组成,其中每个类别包括1000张720*576图像(6000张用于训练,2000张用于测试).
客户端的划分:我们按照狄利克雷分布设置了两个数据分布方式,参数值分别为0.6和0.3.此外一共设置100个客户端,按照狄利克雷的分布方式获取不同类别的图像,其中狄利克雷的值越小,则客户端数据分布差异越大.
训练的网络:在这里我们构建卷积神经网络(LeNet),服务端跟客户端共用同一神经网络模型.选择将教师模型作为本地私有模型,只进行本地训练与跟学生模型的蒸馏交互,学生模型作为上传与接收服务器端模型,两个模型共用同一数据集.
模型的建立:在联邦学习框架当中,我们在每个客户端构建一个学生模型,一个教师模型,让学生模型代表联邦学习当中的本地模型,额外增加教师模型作为本地的私有模型.学生模型在每次的迭代过程中上传自己的模型参数到服务端当中,模型参数聚合后进行平均,再将新的全局模型参数分发给学生模型,教师模型并不上传服务端,只是在每次迭代过程中参与跟学生模型的知识蒸馏,让学生模型学习教师模型的本地私有知识,保持在每次用全局模型训练的过程中保持对本地知识的保留,通过这种方法达到本地个性化的目的.在这里我们为了更好的蒸馏学习过程,我们也设计一个目标特征提取器来将逻辑层特征分解为目标类特征以及非目标类特征,两者赋予相应的权重分开进行蒸馏.按照模型蒸馏以及本地模型训练,不断迭代,直到全局模型收敛.
联邦学习:客户端在各自的数据集上按照随机梯度下降的方式进行训练,在这里,我们通过用K表示每轮的客户端参与量,η代表学习率,每个客户端k计算当前模型参数w
中央服务器聚合这些梯度并更新参数w
训练过程由三个关键参数控制:Q表示每轮参与训练的客户端的比例;E表示每个客户端在每轮对其本地数据集进行的训练次数;B表示客户端本地更新的训练批量.
解耦知识蒸馏:我们将知识蒸馏分为成两部分的加权和,即目标类知识特征蒸馏与非目标类知识特征蒸馏,为了区分两部分的特征蒸馏的有效性,我们分别给特征赋予相应的权重,其中α与β分别代表目标类知识特征蒸馏与非目标类知识特征蒸馏的权重因子:
L
在这里TC=KL(b
L
加入解耦知识蒸馏的联邦学习:考虑到数据的异质性,我们将解耦知识蒸馏(DKD)加入到联邦学习当中,使其联邦学习在训练过程中,通过解耦知识蒸馏技术学习本地知识,也更灵活的解决本地个性化问题,我们称它为基于解耦知识蒸馏的个性化联邦学习方法(FMLDKD),算法伪代码在表1所示.
表1:DKDFL算法伪代码
在训练过程中,从一个初始的全局模型开始,该模型由服务端控制.同时,所有客户端都从一个初始的个性化(教师)模型开始,该模型由每个客户端定制或使用服务端提供的相同模型.然后,所有客户端将全局模型作为其学生模型,并进行本地更新.接下来,不是直接在全局模型分配的学生模型上进行训练,而是每个客户端的本地更新在学生模型和教师模型之间进行几回合的知识蒸馏.我们将教师模型以及学生模型的损失函数改写如下:
L
L
其中λ和μ是控制本地损失与学习其他知识损失比例的超参数,α和β是控制目标类蒸馏与非目标类蒸馏的权重.学生模型和教师模型之间的知识转移方向是双向的,学生模型将把服务器知识转移到教师模型,并从中获得反馈,它们都是通过私人数据进行训练的.最后,每个客户端将其经过训练的学生模型推送到服务器,服务器平均这些合并的学生模型得到新的全局模型.重复整个过程直到全局模型收敛.
附图说明
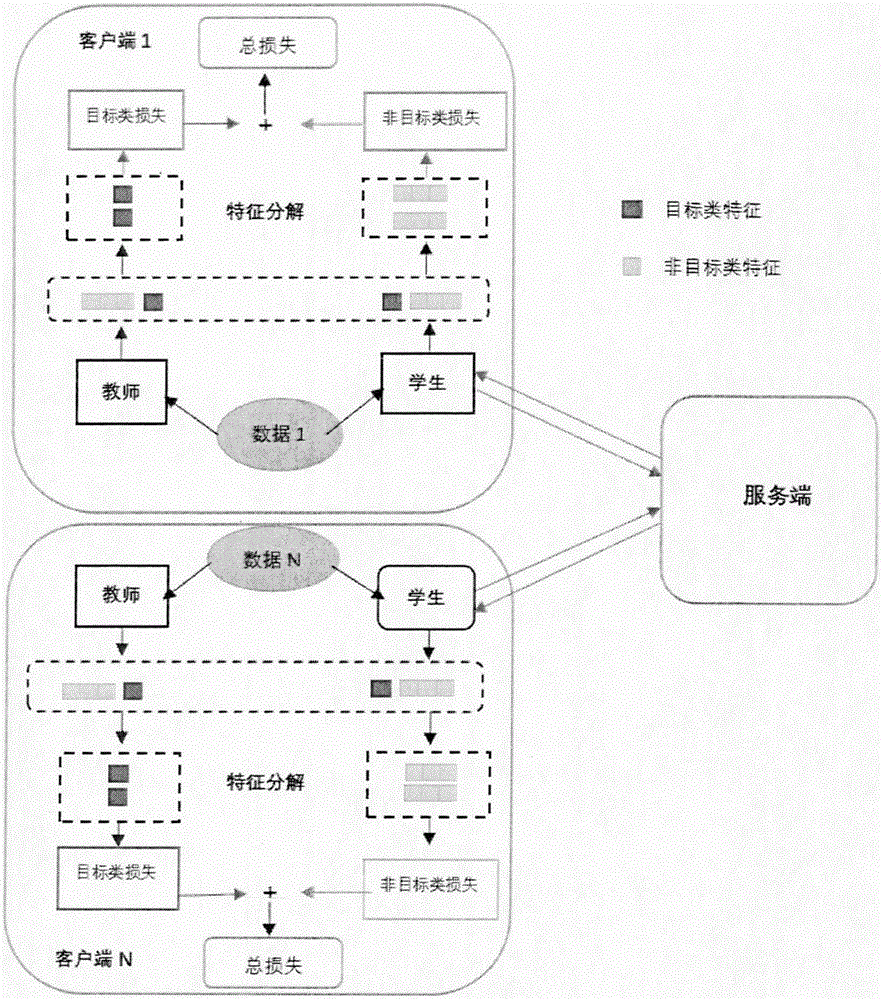
图1解耦蒸馏联邦学习的框架
图2医院中的解耦知识蒸馏联邦学习架构
具体实施方式
下面结合图1和具体实施例对本发明做进一步的详细说明.下面所描述的实施例仅为本发明的一部分,不应理解为局限在上述方式的全部范例.
图1大致包括两部分,第一部分是服务端,第二部分是客户端,客户端有1,2...,N个,图中展示两个客户端1与客户端N.在技术上主要分为三部分,包括联邦学习,与解耦知识蒸馏以及两者的结合.
在联邦学习部分,包括模型与数据,其中数据只是客户端私有的,并不上传其他模型上.模型分为教师模型、学生模型以及全局模型,以客户端1为例,教师模型作为客户端1的私有模型,而学生模型拿到服务器端发来的全局模型作为初始模型,教师模型与学生模型进行蒸馏,两者相互学习,最后学生模型在一轮结束后,将训练好的模型参数发送到服务器端,服务端通过合并客户端1,2,...,N发来的模型参数进行平均,将得到的全局模型发送给每一个客户端的学生模型,整个过程依次重复,直到全局模型收敛.
在解耦知识蒸馏部分,具体的蒸馏过程,图1也有所展示,教师模型跟学生模型分别在逻辑回归层(logits)分解为目标类与非目标类,之后再将目标类进行蒸馏,非目标类进行蒸馏,两者的损失也作为教师模型跟学生模型损失的一部分,这样处理蒸馏,能使得我们更好的平衡目标类的影响,以及非目标类的影响,增强了模型的灵活性.
在两者结合的部分,主要任务就是每一轮训练结束,学生模型上传自己的模型参数到服务器端,服务器就开始对其进行合并平均,将处理之后的参数发送给学生模型,作为学生模型的新一轮训练参数,在这里,本地客户端因为多了一个教师模型能更好的保持本地的个性化,也最终实现了我们的目的.
图2是本发明应用到医院的整体架构,包括医院端,服务端,医院端包括学生模型,教师模型以及自己的本地私有数据,本地训练的过程中,两个模型在本地私有数据上依次进行解耦知识蒸馏,一轮结束后,将学生模型参数发送给服务端,服务端进行聚合平均操作,并将处理好的参数,传给学生模型,重复此步骤,直至模型收敛.
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 基于合作博弈和知识蒸馏的个性化联邦学习方法
- 基于聚类和知识蒸馏的可信个性化联邦学习方法和装置