一种面向机械臂多任务长程决策的强化学习系统
文献发布时间:2024-04-18 20:01:30
技术领域
本公开涉及计算机图像处理与机器学习技术领域,具体地,涉及一种面向机械臂多任务长程决策的强化学习系统。
背景技术
机械臂控制能够用于实现各种复杂任务,例如物体抓取、装配或者操作等任务。传统的机械臂控制方法主要基于预先定义的规则和算法,难以应对多任务长程决策的挑战。
近年来,强化学习成为解决多任务长程决策的有效方法,并逐渐应用于机械臂控制领域。多任务长程决策强化学习旨在控制机械臂学会在复杂环境下做出一系列决策,以完成一系列任务,而不仅仅是单个任务。
在多任务长程决策强化学习中,机械臂通过与环境的交互来学习如何在不同的任务之间进行决策。通过设计适当的奖励函数和状态表示,机械臂能够学会根据当前环境状态和目标任务来选择合适的动作,以实现更长远的目标。
多任务长程决策强化学习在机械臂控制中具有多种优势。首先,其能够控制机械臂在面对多个任务时做出灵活的决策,提高了机械臂的自主性和适应性。其次,通过学习长远决策,机械臂能够在多个任务之间做出优化的权衡,实现更高效的操作。此外,多任务长程决策强化学习还能够减少对领域专家知识的依赖,控制机械臂能够自主学习和改进控制策略。
多任务长程决策强化学习为机械臂控制带来新的机遇。通过让机械臂学会在多任务环境下做出长远决策,能够提高机械臂的智能性和适应性,推动机械臂控制技术的发展。这一方法为机械臂在各个领域的应用提供了更大的潜力,使其能够应对更加复杂和多样化的任务需求。
发明内容
针对现有技术中的缺陷,本公开的目的是提供一种面向机械臂多任务长程决策的强化学习系统。
为实现上述目的,根据本公开的一个方面,提供一种面向机械臂多任务长程决策的强化学习系统,包括:
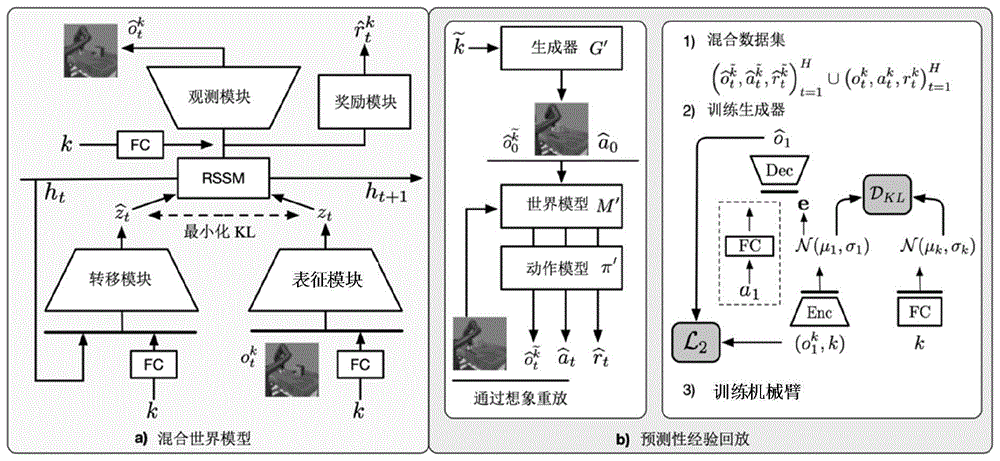
混合世界模型模块,将当前时刻的视觉观测、执行的动作以及当前任务的第一分类任务变量作为输入,采用高斯混合变量获取隐空间视觉动力学和输入/输出的观测空间中空间外观的多模态分布,输出重建的图像;
预测性经验回放模块,将第二分类任务变量作为输入,采用上一任务的生成模型副本、世界模型副本以及动作模型副本进行轨迹重演,并采用重演轨迹和当前轨迹对当前任务的生成器和机械臂进行训练,确定训练完成的生成器和机械臂。
可选地,所述混合世界模型模块包括:
表征模块,将所述当前时刻的视觉观测、所述执行的动作作为输入,输出第一隐状态;
转移模块,将所述第一分类任务变量作为输入,输出预测的第二隐状态;
观测模块,将所述第一分类任务变量和所述第一隐状态作为输入,输出重建图像;
奖励模块,将所述第一分类任务变量和所述第一隐状态作为输入,输出预测的奖励。
可选地,所述表征模块和所述转移模块之间采用KL散度进行联合优化,学习第一隐状态的先验分布和后验分布。
可选地,所述混合世界模块还将所述第一分类任务变量作为额外输入,处理输入空间中的协变量偏移。
可选地,所述第一隐状态和所述第二隐状态为以所述第一分类任务变量为条件的高斯混合分布形式。
可选地,所述预测性经验回放模块还用于将所述第二分类任务变量输入所述上一任务的生成模型副本中,输出上一任务的轨迹的初始帧。
可选地,所述预测性经验回放模块还用于根据所述上一任务的轨迹的初始帧,确定所述上一任务的轨迹的零初始化动作。
可选地,所述预测性经验回放模块还用于将所述上一任务的轨迹的初始帧和所述上一任务的轨迹的零初始化动作输入所述上一任务的世界模型副本和动作模型副本,生成所述上一任务的重演轨迹。
可选地,所述预测性经验回放模块还用于将所述重演轨迹和真实轨迹进行混合,生成混合轨迹,并采用所述混合轨迹训练所述当前任务的生成模型和所述机械臂,确定训练完成的所述生成模型和所述机械臂。
可选地,所述预测性经验回放模块还用于根据上一任务的生成模型、世界模型和动作模型更新当前任务的生成模型副本、世界模型副本以及动作模型副本。
与现有技术相比,本公开实施例具有如下至少一种有益效果:
通过上述技术方案,基于第一分类任务变量和第二分类任务变量,学习混合高斯先验,获取当前任务的隐动力学,采用上一任务的生成模型副本作为额外的生成模型重现历史任务的初始视频帧,并采用世界模型副本和动作模型副本进行轨迹重演,混合重演轨迹和真实轨迹,以对当前任务的生成模型和机械臂进行训练,确定训练完成的生成模型和机械臂,训练过程和轨迹重演过程交替进行。通过本公开。能够控制机械臂实现高效记忆的数据重演,克服世界模型的灾难性遗忘,以在机械臂多任务长程决策场景中面对多个任务时,能够灵活地做出决策,提高机械臂的自主性和适应性,具有广泛的应用前景和价值。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本公开的其它特征、目的和优点将会变得更明显:
图1是根据一示例性实施例示出的一种面向机械臂多任务长程决策的强化学习系统的示意图。
图2是根据一示例性实施例示出的一种面向机械臂多任务长程决策的强化学习过程的示意图。
具体实施方式
下面结合具体实施例对本公开进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本公开,但不以任何形式限制本公开。应当指出的是,对本领域的普通技术人员来说,在不脱离本公开构思的前提下,还可以做出若干变形和改进。这些都属于本公开的保护范围。
图1是根据一示例性实施例示出的一种面向机械臂多任务长程决策的强化学习系统的示意图。
如图1所示,本公开提供一种面向机械臂多任务长程决策的强化学习系统,包括混合世界模型模块和预测性经验回放模块。
混合世界模型模块,将当前时刻的视觉观测、执行的动作以及当前任务的第一分类任务变量作为输入,采用高斯混合变量获取隐空间中输入量的空间外观的多模态分布,输出重建的图像。
其中,混合世界模型基于一组分类任务变量,学习混合高斯先验,获取当前任务的隐动力学。分类任务变量包括第一分类任务变量k和第二分类任务变量
预测性经验回放模块,将第二分类任务变量作为输入,采用上一任务的生成模型副本、世界模型副本以及动作模型副本进行轨迹重演,并采用重演轨迹和真实轨迹对当前任务的生成模型和机械臂进行训练,确定训练完成的生成模型和机械臂。
其中,预测性经验回放模块通过轨迹重演进行数据增强,以扩大对机械臂的世界模型训练的训练数据,增加观测-行动对的数量,防止世界模型过度拟合有限的训练数据,导致超出分布范围的样本表现较差。
通过上述技术方案,基于第一分类任务变量和第二分类任务变量,学习混合高斯先验,获取当前任务的隐动力学,采用上一任务的生成模型副本作为额外的生成模型重现历史任务的初始视频帧,并采用世界模型副本和动作模型副本进行轨迹重演,混合重演轨迹和当前轨迹,以对当前任务的生成模型和机械臂进行训练,确定训练完成的生成模型和机械臂,训练过程和轨迹重演过程交替进行。通过本公开。能够控制机械臂实现高效记忆的数据重演,克服世界模型的灾难性遗忘,以在机械臂多任务长程决策场景中面对多个任务时,能够灵活地做出决策,提高机械臂的自主性和适应性,具有广泛的应用前景和价值。
在一种可能的实施例中,混合世界模型模块在应用于在特定的任务中时,可能会有不同的编码架构和解码架构,但其编码架构和解码架构始终遵循高斯混合表示的统一学习范式,采用高斯混合变量获取隐空间视觉动力学和输入/输出的观测空间中空间外观的多模态分布。
在一种可能的实施例中,混合世界模型模块包括:
表征模块,将当前时刻的视觉观测、执行的动作作为输入,输出第一隐状态。
其中,表征模块的定义式为:
其中,z
表征模块用于对当前时刻的视觉观测和执行的动作进行编码,以预测第一隐状态。
如图1所示,在一种可能的实施例中,混合世界模块将第一分类任务变量作为额外输入,处理输入空间中的协变量偏移。
示例地,表征模块采用输入空间中的第一分类任务变量k∈{1,…,K},处理输入空间中的协变量偏移。
转移模块,将第一分类任务变量作为输入,输出预测的第二隐状态。
其中,转移模块用于预测第二隐状态
转移模块的定义式为:
其中,
在一种可能的实施例中,表征模块和转移模块之间采用KL散度进行联合优化,学习第一隐状态的先验分布和后验分布。
观测模块,将第一分类任务变量和第一隐状态作为输入,输出重建图像。
其中,观测模块用于采用第一分类任务变量k和第一隐状态z
观测模块的定义式为:
其中,
奖励模块,将第一分类任务变量和第一隐状态作为输入,输出预测的奖励。
其中,奖励模块用于采用第一分类任务变量k和第一隐状态z
奖励模块的定义式为:
其中,
在混合世界模型模块中,第一隐状态z
在一种可能的实施例中,对于任务
其中,
其中,α=1.0,
在一种可能的实施例中,
在一种可能的实施例中,预测性经验回放模块将上一任务的生成器副本和机械臂结合,以有效生成历史轨迹。为克服时变环境中的图像外观的协变移,引入的上一任务的生成器副本还采用高斯混合分布形成隐前验e。
预测性经验回放模块在对上一任务完成训练后,保留一个生成器
其中,生成器即为上文所述的生成模型。
在一种可能的实施例中,预测性经验回放模块还用于将第二分类任务变量输入上一任务的生成模型副本中,输出上一任务的轨迹的初始帧。
预测性经验回放模块还用于根据上一任务的轨迹的初始帧,确定上一任务的轨迹的零初始化动作。
预测性经验回放模块还用于将上一任务的轨迹的初始帧和上一任务的轨迹的零初始化动作输入上一任务的世界模型副本和动作模型副本,生成上一任务的重演轨迹。
示例地,对于每一历史任务
在一种可能的实施例中,预测性经验回放模块还用于将重演轨迹和当前轨迹进行混合,生成混合轨迹,并采用混合轨迹训练当前时刻的生成器和机械臂,确定训练完成的生成器和机械臂。
其中,重演轨迹
在一种可能的实施例中,在当前任务
其中,
并且,生成器
其中,q(·|·)表示表征模块,p(·|·)表示编码模块,D
在一种可能的实施例中,预测性经验回放模块还用于根据上一任务的生成模型、世界模型和动作模型更新当前任务的生成器副本、世界模型副本以及动作模型副本。
在预测性经验回放过程中,即重演轨迹过程中,生成器副本
其中,世界模型
通过上述技术方案,通过训练一个额外的生成模型,即生成器,来生成历史任务中的初始视频帧,并将其输入已学习到的世界模型副本中,生成用于机械臂学习的后续图像序列,其与机械臂的训练过程交替进行,无需在缓冲区中保留大量历史数据,节省内存。
图2是根据一示例性实施例示出的一种面向机械臂多任务长程决策的强化学习过程的示意图。
如图2所示,在一种可能的实施例中,机械臂与环境A进行交互学习,以学习在环境A中的任务决策,并完成环境A中的一系列任务,在环境A中训练完成机械臂之后,保留一个环境A中的机械臂的生成模型副本、世界模型副本和动作模型副本。
在环境B中,根据环境A中保留的生成模型副本、世界模型副本和动作模型副本更新当前环境B中的机械臂,并将环境A中机械臂执行环境A中的一系列任务的数据进行轨迹重演,确定重演轨迹数据
在环境C中,根据环境B中保留的机械臂的生成模型副本、世界模型副本和动作模型副本更新当前环境C中的机械臂,并将环境B中机械臂执行环境B中的一系列任务的数据
通过上述技术方案,训练一个额外的生成模型副本来重演历史任务中的初始视频帧,并将其输入已学到的世界模型副本和动作模型副本中,生成用于数据演练的后续图像序列,即重演数据,无需在缓冲区保留大量数据,节省内存。
以上对本公开的具体实施例进行了描述。需要理解的是,本公开并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本公开的实质内容。上述各优选特征在互不冲突的情况下,可以任意组合使用。