数据存储装置、数据处理系统及其加速装置
文献发布时间:2023-06-19 09:29:07
相关申请的交叉引用
本申请要求于2019年7月8日向韩国知识产权局提交的申请号为10-2019-0082000的韩国申请的优先权,其通过引用整体并入本文。
技术领域
各个实施例涉及一种数据存储装置、数据处理系统及其加速装置。
背景技术
人工智能(AI)加速器可以是一种应用,其通过利用硬件实施已在软件中处理的诸如多层感知(MLP)、长短期记忆(LSTM)和卷积神经网络(CNN)的应用,能够最大化相关操作的性能,同时减轻主机在执行操作和利用资源方面的负担。
AI加速器可具有较高的功耗。在这种情况下,AI加速器中使用的功率可划分为计算功率和存储器功率。通常,存储器功率可随着存储器带宽的增加而增加。
在深度学习中,可根据网络模型来确定主要应用。例如,CNN可以是一种需要相对较多计算器的应用,并且MLP和LSTM中的每一个可以是一种需要较大存储器带宽的应用。
发明内容
各个实施例涉及一种根据存储器带宽而灵活调整存储器功率和计算功率的加速装置,以及包括该加速装置的数据处理系统。
在实施例中,一种数据处理系统包括:主机装置,被配置成基于网络模型或批量(batch)大小或两者来选择存储器带宽的速度模式,根据速度模式的选择来调整加速器的计算功率和存储器功率;以及数据存储装置,包括加速器,该加速器被配置成通过基于存储器带宽的速度模式,控制输入到处理元件(PE)阵列的第一输入数据和第二输入数据的传送路径,来改变PE阵列的结构,其中如果选择第一速度模式,则总功率预算中的存储器功率从存储器功率的初始值起增加,并且如果选择第二速度模式,则总功率预算中的计算功率从计算功率的初始值起增加。
在实施例中,加速装置包括加速器,该加速器被配置成通过基于存储器带宽的速度模式控制输入到处理元件(PE)阵列的第一输入数据和第二输入数据的传送路径,来改变PE阵列的结构。
加速器可包括:PE阵列,包括第一PE组和第二PE组,第一和第二PE组中的每一个包括布置在第一和第二方向上的多个PE;PE阵列自适应块,位于PE阵列中的第一PE组和第二PE组之间,并且被配置成在PE阵列中的第一方向上,将第一数据组的第一输入数据或第二数据组的第一输入数据选择性地输入到第二PE组,并且在PE阵列中的第二方向上,将第三数据组的第二输入数据或第四数据组的第二输入数据选择性地输入到第二PE组。
在实施例中,一种数据存储装置包括:中央处理单元(CPU),被配置成基于网络模型或批量大小或两者来选择存储器带宽的速度模式,根据速度模式的选择来调整加速器的计算功率和存储器功率;以及加速器,被配置成通过基于存储器带宽的速度模式控制输入到处理元件(PE)阵列的第一输入数据和第二输入数据的传送路径,来改变PE阵列的结构,其中如果选择第一速度模式,则总功率预算中的存储器功率从存储器功率的初始值起增加,并且如果选择第二速度模式,则总功率预算中的计算功率从计算功率的初始值起增加。
附图说明
图1示出根据实施例的数据处理系统和外部服务器之间的连接关系。
图2示出根据实施例的数据处理系统。
图3示出根据实施例的在主机装置中确定速度模式的方法。
图4示出根据实施例的总功率预算。
图5A和图5B示出根据实施例的存储器功率和计算功率的调整。
图6示出根据实施例的数据存储装置。
图7示出根据实施例的加速器。
图8示出根据实施例的PE阵列。
图9示出根据另一实施例的PE阵列。
图10示出根据实施例的PE阵列结构。
图11示出根据实施例的存储器控制器和存储器管芯之间的连接关系。
图12示出根据速度模式的性能改变。
图13示出根据实施例的加速装置。
图14示出根据另一实施例的数据存储装置。
具体实施方式
在下文中,将通过实施例的各个示例并参照附图来描述数据存储装置、数据处理系统及其加速装置。
图1示出根据实施例的数据处理系统20和外部服务器10之间的连接关系。图2示出根据实施例的图1所示的数据处理系统20。
在下文中,将参照图3、图4以及图5A和图5B来描述实施例,其中图3示出根据实施例的在主机装置中确定或选择速度模式的方法,图4示出根据实施例的总功率预算,并且图5A和图5B示出根据实施例的存储器功率和计算功率的调整。
参照图1,数据处理系统20可通过网络30电联接到外部服务器10,并且可从外部服务器10接收数据。在这种情况下,数据可包括稍后将描述的批量大小。深度学习应用可以批量为单位(或批量单位)来处理数据。
批量的大小(或批量大小)可对应于数据处理系统20可一次处理的数据量。例如,如果第一输入数据是照片图像数据,则第一输入数据中包括的照片图像的数量可被称为批量大小。10批量表示10个照片图像被用作第一输入数据。10个第一输入数据与相同数量的第二输入数据,例如10个第二输入数据一起执行乘法和累加(MAC)运算。
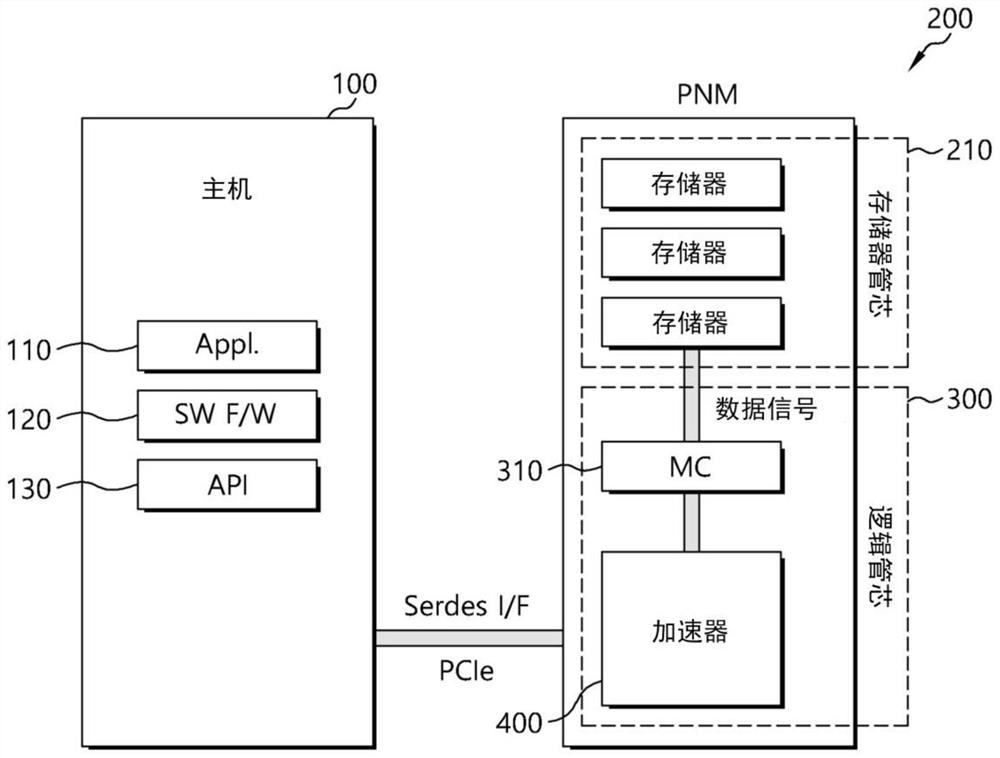
数据处理系统20可包括主机装置100和数据存储装置200。
参照图2,主机装置100可包括应用110、软件固件(SW F/W)120和应用编程接口(API)130。数据存储装置200可以是近处理存储器(processing-near-memory,PNM)。PNM可包括被结合在高级集成电路(IC)封装中的至少一个存储器管芯210和逻辑管芯300。
主机装置100的SW F/W 120可基于网络模型和批量大小中的至少一个来确定或选择存储器带宽的速度模式,从而调整数据存储装置200中包括的加速器400的计算功率和存储器功率。
参照图3,主机装置100可基于网络模型信息执行数据编译操作(530),该网络模型信息包括硬件架构信息,诸如网络信息510和近处理存储器(PNM)架构信息520。在这种情况下,主机装置100对PNM执行编译操作,以便执行功率均衡。具体地,除了仅针对加速器的现有编译之外,主机装置100还执行编译,用于稍后描述的调整总功率预算中的存储器功率和计算功率。
因为存储器管芯210的数据信号线电联接到PNM中的逻辑管芯300,所以PNM可具有比高带宽存储器(HBM)的数据引脚结构相对更高的速度。这是因为在PNM中通过将存储器管芯210和逻辑管芯300结合在高级IC封装中而移除对芯片外连接(off-chip connection)的速度限制。
图1的网络30可以是神经网络,但不限于此。神经网络可包括卷积神经网络(CNN)、多层感知(MLP)、长短期记忆(LSTM)等。主机装置100可预先识别网络信息。
PNM架构信息520可包括加速器架构信息、每个计算器的功率、每个存储器带宽(BW)的功率、关于计算器的最大结构的信息以及关于存储器BW的最大结构的信息。
在这种情况下,计算器的最大结构可代表计算器的最大数量。存储器BW的最大结构可代表存储器BW的最大大小。计算器的最大结构和存储器BW的最大结构是预先确定的。在本公开的实施例中,计算器的数量和存储器BW的大小可在预定的最大结构内改变。
例如,当存在N个计算器时,所分配的计算器的数量不能超过N,并且当存储器BW的最大大小为M时,所分配的存储器BW的大小不能超过M,N和M是正整数。因此,预先提供计算器和存储器BW的最大结构,以基于计算器的最大结构和存储器BW的最大结构来确定或选择存储器BW的速度模式。
主机装置100可输出以针对PNM优化的形式编译的数据,包括存储器BW的速度模式(540)。在这种情况下,存储器BW的速度模式可包括低速模式和高速模式。
参照图4,总功率预算可包括存储器功率和计算功率。在这种情况下,存储器功率和计算功率中的每一个可包括可调整的动态功率部分和静态功率部分。图4示出最大限度地使用存储器功率和计算功率的情况。
存储器BW的速度模式可包括高速模式和低速模式,在图5A所示的高速模式中,存储器功率从初始设置参考值起增加。在图5B所示的低速模式中,计算功率从初始设置参考值起增加。
重新参照图3,当网络模型为CNN时,主机装置100可确定存储器BW的速度模式为低速模式(550)。当网络模型为CNN时,数据在逻辑管芯300中被相对大量地重复使用,因此主机装置100确定存储器BW的速度模式为低速模式,因为虽然存储器BW较低,但数据处理系统20的总性能由计算功率的性能来确定。
另一方面,当网络模型为MLP和LSTM中的任意一种时,主机装置100可检查批量大小,并且将该批量大小与参考值K进行比较(560)。如果批量大小超过参考值K(即,批量大小>K),则主机装置100可确定存储器BW的速度模式为低速模式(550)。如果批量大小等于或小于参考值K,则主机装置100可将确定存储器BW的速度模式为高速模式(570)。
虽然网络模型为MLP或LSTM,但随着批量大小的增加,对更大计算功率的需求可能会增加。因此,虽然网络模型为MLP或LSTM,但主机装置100将批量大小与参考值K进行比较。
在这种情况下,可从外部服务器10接收批量大小,并且批量大小被包括在PNM架构信息中。在逻辑管芯300中没有重新使用数据的诸如MLP、LSTM或递归神经网络(RNN)的网络模型中,因为存储器BW可以是确定数据处理系统20的总性能的主要因素,所以主机装置100可确定存储器BW的速度模式为高速模式。
重新参照图2,逻辑管芯300可包括存储器控制器(MC)310和加速器400。
参照图11,示出了根据实施例的MC 310和存储器管芯210之间的连接关系,MC 310可将存储器BW的速度模式传送到存储器管芯210。
存储器管芯210可基于由MC 310传送的存储器BW的速度模式来改变存储器的时钟。在这种情况下,数据存储装置200中包括的存储器管芯210的数量可以是至少一个。
在另一实施例中,MC 310可基于存储器BW的速度模式来改变存储器的时钟。
图6示出根据实施例的数据存储装置。
下面将参照图7至图12描述图6所示的数据存储装置。图7示出根据实施例的加速器。图8和图9中的每一个示出根据实施例的PE阵列。图10示出根据实施例的PE阵列结构。图11示出根据实施例的MC和存储器管芯之间的连接关系。图12示出根据速度模式的性能改变。
图6所示的数据存储装置可对应于图2所示的数据存储装置200。
参照图6,数据存储装置200可包括加速器400,该加速器400被配置成通过根据存储器BW的速度模式来控制处理元件(PE)阵列430的第一输入数据和第二输入数据的传送路径来改变PE阵列430的结构。
加速器400可接收第一输入数据和第二输入数据,将第一输入数据和第二输入数据相乘,并且将相乘的数据与先前存储的数据相加。在这种情况下,第二输入数据可以是权重数据。
参照图6,第一输入数据可在行方向上传送,并且第二输入数据可在列方向上传送。通过将相乘的数据与先前存储的数据相加而获得的结果数据包括节点所需的所有的第二输入数据和第一输入数据,并且通过IO缓冲器450传送。在对结果数据执行MAC之后,激活函数单元(AFU)480对通过IO缓冲器450传送的数据执行激活函数,从而提供输出数据。
参照图6和图7,加速器400可包括PE控制器(PE CTRL)420、PE阵列430、PE阵列自适应块440、IO缓冲器450、权重缓冲器460、自适应数据路径控制器470、激活函数单元(AFU)480、特定函数单元(SFU)490和行电平功率控制器495。
加速器400可通过主机接口(IF)块410与主机装置100通信。在这种情况下,主机IF块410可使用主机装置100的协议来提供主机装置100和数据存储装置200之间的接口。例如,主机IF块410可使用Serdes接口协议与主机装置100通信,但协议不限于此。主机IF块410可使用诸如以下的任意一种协议来与主机装置100通信:高速PCI(PCI-E)、通用串行总线(USB)、通用闪存(UFS)、多媒体卡(MMC)、并行高级技术附件(PATA)、串行高级技术附件(SATA)、小型计算机系统接口(SCSI)、串列SCSI(SAS)、外围组件互连(PCI)等。
PE控制器420可将由主机装置100传送的存储器BW的速度模式传送到自适应数据路径控制器470。如图6所示,PE控制器420可通过向主机装置100传送数据和从主机装置100接收数据的主机IF块410接收由主机装置100传送的存储器BW的速度模式。
参照图7,PE阵列430可包括多个第一PE组,每个第一PE组包括布置在行方向上的多个PE。PE阵列自适应块440可包括位于PE阵列430中的PE之间的多个第一多路器,并且每个第一多路器可在PE阵列430内的行方向上,将相应数据组的第一输入数据和另一数据组的第一输入数据中的任意一个选择性地输入到PE。
此外,PE阵列430可包括多个第二PE组,每个第二PE组包括布置在列方向上的多个PE。PE阵列自适应块440可包括联接到PE阵列430中的PE的多个第二多路器,并且每个第二多路器可在PE阵列430内的列方向上,将相应数据组的第二输入数据和另一数据组的第二输入数据中的任意一个选择性地输入到PE。
在图6中,PE阵列430可具有N×M结构,即,PE阵列430可包括N×M个PE。在这种情况下,N可以是批量大小,M可代表权重宽度。也就是说,N可代表输入第一输入数据的行的大小,M可代表输入第二输入数据的列的大小。因此,在该实施例中,PE阵列430可包括N个第一PE组和M个第二PE组。每个第一PE组可包括布置在行方向上的M个PE,并且每个第二PE组包括布置在列方向上的N个PE。
参照图7和图10,PE阵列自适应块440可位于PE阵列430中的PE之间的存储器BW单元(例如,1x单元)中,其中第一PE阵列调整块位于第二存储器BW的前面。
例如,如果存储器BW为2xBW,则PE阵列自适应块440可位于对应于2xBW的PE的前端。在这种情况下,如图10所示,PE阵列自适应块440可包括行组A和列组B。
参照图7,PE阵列自适应块440可包括行组A中包括的用于向PE输入第一输入数据的多个第一多路器441和列组B中包括的用于向PE输入第二输入数据的多个第二多路器443。
多个第一多路器441可以PE阵列430的行为单位匹配,并且多个第二多路器443可以PE阵列430的列为单位匹配。
图10示出当N为6且M为64时包括PE阵列自适应块440的PE阵列430。参照图10,在图7中的自适应数据路径控制器470的控制下,多个第一多路器441中的多路器441-1可将第一输入数据InQ_1和InQ_7中的任意一个输入到1x33 PE。
在自适应数据路径控制器470的控制下,多个第二多路器443中的多路器443-1可将第二输入数据WB_6_1和WB_6_33中的任意一个输入到1x33 PE。
IO缓冲器450可在PE阵列430内的行方向上将第一输入数据传送到PE。
权重缓冲器460可在PE阵列430内的列方向上将第二输入数据传送到PE。
虽然图中未示出,但IO缓冲器450和权重缓冲器460可被实施为一个元件或者通过总线彼此电联接。
自适应数据路径控制器470可基于存储器BW的速度模式来控制PE阵列自适应块440。
图8示出具有N×M结构作为初始结构的PE阵列430,并且图9示出具有2N×M/2结构作为初始结构的PE阵列430。
因此,如果PE阵列430具有如图8所示的N×M结构的初始结构,存储器BW为2x,并且存储器BW的速度模式为低速模式,则自适应数据路径控制器470可控制第一输入数据和第二输入数据的输入路径,使得PE阵列430的结构从N×M结构改变为2N×M/2结构。在这种情况下,N可以是批量大小,M可代表权重宽度。
具体地,当图8的左侧N×M/2结构的PE从2N个数据组中的第一N数据组接收第一输入数据时,自适应数据路径控制器470可控制多个第一多路器441从两个或更多个N数据组中的第二N数据组接收第一输入数据,并且当图8的左侧N×M/2结构的PE从M/2数据组接收第二输入数据时,可控制多个第二多路器443从M/2数据组接收第二输入数据。在本文中,第一和第二数据组中的每一个可包括N个第一输入数据,并且M/2数据组可包括M/2个第二输入数据。
例如,如图8所示,如果PE阵列430具有N×M结构的初始结构,并且存储器BW为2x,则如图10所示,PE阵列430的初始结构可具有6×64的存储器结构。在这种情况下,PE阵列自适应块440可位于第一1x级和第二1x级(或2x级)之间。第一1x级对应于左侧N×M/2结构,第二1x级对应于右侧N×M/2结构。
如果存储器BW的速度模式为低速模式,则自适应数据路径控制器470可将PE阵列430的结构从6×64(参照图8)改变为12×32(参照图9)。
参照图10,自适应数据路径控制器470可控制多个第一多路器441,使得布置在列方向上的1x33 PE至6x33 PE分别接收第一输入数据InQ_7至InQ_12。
另外,自适应数据路径控制器470可控制多个第二多路器443,使得布置在行方向上的1x33 PE至1x64 PE分别接收第二输入数据WB_6_1至WB_6_31。
也就是说,布置在列方向上的1x33 PE至6x33 PE分别接收第一输入数据InQ_7至InQ_12,而非第一输入数据InQ_1至InQ_6。在行方向上布置的1x33 PE至1x64 PE分别接收第二输入数据WB_6_1至WB_6_32,而非第二输入数据WB_6_33至WB_6_64。因此,通过调整第一和第二输入数据的输入路径,PE阵列430中的PE可实施12x32的PE阵列结构。
相反,如图9所示,如果PE阵列430的初始结构为2N×M/2结构,存储器BW为2x,并且存储器BW的速度模式为高速模式,则自适应数据路径控制器470可控制第一输入数据和第二输入数据的输入路径,使得PE阵列430的结构从2N×M/2结构改变为N×M结构。
在图9中,PE阵列自适应块440可位于第一1x级和第二1x级(或2x级)之间。第一1x级对应于较低的N×M/2结构,并且第二1x级对应于较高的N×M/2结构。
当图9的下部N×M/2结构的PE从两个或更多个N数据组的第一N数据组接收第一输入数据时,自适应数据路径控制器470可控制多个第一多路器441从两个或更多个N数据组中的第一N数据组接收第一输入数据,并且当图9的下部N×M/2结构的PE从第一M/2数据组接收第二输入数据时,可控制多个第二多路器443从第二输入数据的第一M/2数据组之后的下一M/2数据组接收第二输入数据。
例如,参照图10,当图9的上部N×M/2结构包括1×33PE至6×33PE、……、及1×64PE至6×64PE时,第一输入数据InQ_1至InQ_6可被输入到布置在列方向上的1×33PE至6×33PE,并且第二输入数据WB_6_33到WB_6_64可被输入到布置在行方向上的1×33PE至1×64PE。
重新参照图7,激活函数单元(AFU)480可设置在PE阵列430的每个行中,并且通过PE阵列对操作处理的数据执行激活函数。
在这种情况下,激活函数可使用各种算法,例如ReLU、tanh、sigmoid等。此外,激活函数可以查找表的形式来配置,或者可以微内核的形式来配置。
特定函数单元(SFU)490可与相应的激活函数单元480匹配,并且除了激活函数之外还执行附加操作。例如,特定函数单元490可执行处理操作,例如LSTM的逐元素乘法(element-wise multiplication)。
行电平功率控制器495可以行为单位对PE阵列430执行时钟门控控制处理。
如上所述,因为针对每行提供了激活函数单元480和特定函数单元490,所以行电平功率控制器495可以行为单位执行时钟门控控制处理。因此,当执行计算操作时,可降低功耗。
图12示出根据速度模式的性能改变。参照图12,可看出的是,如果使用相同的功率预算,则通过将存储器BW的速度模式适当地改变为低速模式或高速模式,MLP和LSTM应用的性能从P1提高到P2。图12示出因为批量大小为参考值K或更小而应用高速模式的MLP和LSTM。参考值K已在上面参照图3进行了描述。
图13示出根据实施例的加速装置600。
参照图13,加速装置600可包括加速器400,用于通过控制处理元件(PE)阵列430的第一输入数据和第二输入数据的传送路径来改变PE阵列430的结构。
加速器400可执行以下操作:接收第一输入数据和第二输入数据,将第一输入数据和第二输入数据相乘,并且将相乘的数据与先前存储的数据相加。在这种情况下,第二输入数据可以是权重数据。
重新参照图6,第一输入数据可在行方向上传送,并且第二输入数据可在列方向上传送。通过将相乘的数据与先前存储的数据相加而获得的结果数据包括节点所需的所有的第二输入数据和第一输入数据,并且通过IO缓冲器450传送。在对结果数据执行MAC之后,激活函数单元(AFU)480对通过IO缓冲器450传送的数据执行激活函数,从而提供输出数据。
更具体地,加速器400可包括PE控制器420、PE阵列430、PE阵列自适应块440、IO缓冲器450、权重缓冲器460、自适应数据路径控制器470、AFU 480、特定函数单元(SFU)490和行电平功率控制器495。
加速器400可通过主机IF块410与图1和图2所示的主机装置100通信。在这种情况下,主机IF块410可使用主机装置100的协议来使图1和图2所示的主机装置100和包括加速器400的数据存储装置200之间接口连接。例如,主机IF块410可通过Serdes接口协议与主机装置100通信,但该协议不限于此。
PE控制器420可将主机装置100传送的存储器BW的速度模式传送到自适应数据路径控制器470。
PE阵列自适应块440可包括位于PE阵列430之间的多个第一多路器,并且每个第一多路器可在PE阵列430内的行方向上,将相应数据组的第一输入数据和另一数据组的第一输入数据中的任意一个选择性地输入到PE。在实施例中,PE阵列430包括多个第一PE组,每个第一PE组包括布置在行方向上的多个PE。
此外,PE阵列自适应块440可包括位于PE阵列430之间的多个第二多路器,并且每个第二多路器可在PE阵列430内的列方向上,将相应数据组的第二输入数据和另一数据组的第二输入数据中的任意一个选择性地输入到PE。在实施例中,PE阵列430包括多个第二PE组,每个第二PE组包括布置在列方向上的多个PE。
PE阵列自适应块440可位于PE阵列430之间的存储器BW单元中。
参照图7,PE阵列自适应块440可包括用于将第一输入数据输入到PE的多个第一多路器441和用于将第二输入数据输入到PE的多个第二多路器443。
多个第一多路器441可以PE阵列430的行为单位匹配,并且多个第二多路器443可以PE阵列430的列为单位匹配。
IO缓冲器450可在PE阵列430内的行方向上将第一输入数据传送到PE。
权重缓冲器460可在PE阵列430内的列方向上将第二输入数据传送到PE。
自适应数据路径控制器470可基于存储器BW的速度模式来控制PE阵列自适应块440的输入处理。
存储器BW的速度模式可包括高速模式和低速模式。在高速模式下,存储器功率从初始设置参考值起增加。在低速模式下,计算功率从初始设置参考值起增加。
如果PE阵列430具有如图8所示的N×M结构的初始结构,存储器BW为2x,并且存储器BW的速度模式为低速模式,则自适应数据路径控制器470可控制第一输入数据和第二输入数据的输入路径,使得PE阵列430的结构从N×M结构改变为图9所示的2N×M/2结构。N可以是批量大小,M可代表权重宽度。
特别地,自适应数据路径控制器470可控制多个第一多路器441从两个或更多个数据组的第二N数据组接收第一输入数据,并且可控制多个第二多路器443从M/2数据组接收第二输入数据。
相反,如果PE阵列430的初始结构为如图9所示的2N×M/2结构,存储器BW为2x,并且存储器BW的速度模式为高速模式,则自适应数据路径控制器470可控制第一输入数据和第二输入数据的输入路径,使得PE阵列430的结构从2N×M/2结构改变为如图8所示的N×M结构。
自适应数据路径控制器470可控制多个第一多路器441从两个或更多个数据组中的第一N数据组接收第一输入数据,并且可控制多个第二多路器443从第一M/2数据组之后的下一M/2数据组接收第二输入数据。
图14示出根据另一实施例的数据存储装置200'。
数据存储装置200'可包括中央处理单元(CPU)700、加速器400、存储器控制器(MC)310和多个存储器管芯210。在这种情况下,MC310、加速器400和CPU 700可被包括在逻辑管芯300'中。
CPU 700可基于网络模型和批量大小中的至少一个来确定存储器BW的速度模式,从而在总功率预算中调整加速器400的计算功率和存储器功率。存储器BW的速度模式可包括高速模式和低速模式,在高速模式中,存储器功率从初始设置参考值起向上调整,并且在低速模式中,总功率预算中的计算功率从初始设置参考值起向上调整。在这种情况下,CPU700在数据存储装置200内实施图2中公开的主机装置100的功能。主机装置100的所有功能都可应用于CPU 700中。
CPU 700可通过通信网络来电联接到外部服务器(例如,图1中的外部服务器10),并且可从外部服务器10接收数据。在这种情况下,数据可包括批量大小。批量大小可被包括在PNM架构信息中。虽然未示出,但CPU 700可包括有线接口或用于向外部服务器10传送数据和从外部服务器10接收数据的接口。
加速器400可通过基于存储器BW的速度模式控制处理元件(PE)阵列430的第一输入数据和第二输入数据的传送路径来改变PE阵列(例如,图6中的PE阵列430)的结构。
参照图6和图7,加速器400可包括PE控制器(PE CTRL)420、PE阵列430、PE阵列自适应块440、IO缓冲器450、权重缓冲器460、自适应数据路径控制器470、AFU 480、SFU 490和行电平功率控制器495。
PE控制器420可将CPU 700传送的存储器BW的速度模式传送到自适应数据路径控制器470。
PE阵列自适应块440可位于PE阵列430之间,并且在PE阵列430内的行方向上,将相应数据组的第一输入数据和另一数据组的第一输入数据中的任意一个选择性地输入到PE。
此外,PE阵列自适应块440可位于PE阵列430之间,并且在PE阵列430内的列方向上,将相应数据组的第二输入数据和另一数据组的第二输入数据中的任意一个选择性地输入到PE。
图6示出具有N×M结构的PE阵列430。在这种情况下,N可以是批量大小,M可代表权重宽度。也就是说,N可表示输入第一输入数据的PE行的数量。M可代表输入第二输入数据的PE列的数量。
参照图7和图10,PE阵列自适应块440可位于PE阵列430中的PE之间的存储器BW单元(例如,1x单元)中,其中第一PE阵列调整块位于第二存储器BW之前。
参照图7,PE阵列自适应块440可包括用于将第一输入数据输入到PE的多个第一多路器441和用于将第二输入数据输入到PE的多个第二多路器443。
多个第一多路器441可以PE阵列430的行为单位匹配,并且多个第二多路器443可以PE阵列430的列为单位匹配。
IO缓冲器450可在PE阵列430内的行方向上将第一输入数据传送到PE。
权重缓冲器460可在PE阵列430内的列方向上将第二输入数据传送到PE。
虽然未示出,但IO缓冲器450和权重缓冲器460可被实施为一个元件,或者通过总线彼此电联接。
自适应数据路径控制器470可基于存储器BW的速度模式来控制PE阵列自适应块440的输入处理。
如果PE阵列430具有如图8所示的N×M结构的初始结构,存储器BW为2x,并且存储器BW的速度模式为低速模式,则自适应数据路径控制器470可控制第一输入数据和第二输入数据的输入路径,使得PE阵列430的结构变成图9所示的2N×M/2结构。在这种情况下,N可以是批量大小,M可代表权重宽度。
相反,如果PE阵列430的初始结构为如图9所示的2N×M/2结构,存储器BW为2x,并且存储器BW的速度模式为高速模式,则自适应数据路径控制器470可控制第一输入数据和第二输入数据的输入路径,使得PE阵列430的结构变成如图8所示的N×M结构。
激活函数单元(AFU)480可设置在PE阵列430的每个行中,并且通过PE阵列对操作处理的数据执行激活函数处理。
特定函数单元(SFU)490可与相应的激活函数单元480匹配,并且除了激活函数处理之外还执行附加操作。例如,特定函数单元490可执行处理操作,例如LSTM的逐元素乘法。
行电平功率控制器495可以行为单位对PE阵列430执行时钟门控控制处理。
参照图11,MC 310可将存储器BW的速度模式传送到存储器管芯210。
存储器管芯210可基于由MC 310传送的存储器BW的速度模式来改变存储器的时钟。在这种情况下,存储器管芯210的数量可以是至少一个。
基于存储器带宽的速度模式来改变存储器的时钟可由MC 310直接处理。数据存储装置200可以是近处理存储器(PNM)。
在上述公开的实施例中,当存储器BW为2x BW时,通过使用包括多个第一多路器441和多个第二多路器443的PE阵列自适应块440来控制第一输入数据和第二输入数据的输入路径来调整计算功率和存储器功率,但实施例不限于此。
在另一实施例中,当存储器BW为2x BW时,可将布置在行方向上的M个第二多路器设置在列方向上的N/2位置处,其中PE阵列430具有N×M结构,使得PE阵列430改变为N/2x2M结构。在又一实施例中,当存储器BW为4x BW时,可将布置在行方向上的M个第二多路器设置在具有N×M结构的PE阵列430中的PE之间沿列方向的每个N/4位置处,即N/4、2N/4和3N/4位置,使得PE阵列430改变为N/4x 4M结构。
根据本实施例,因为根据存储器BW的速度模式灵活地调整了计算功率和存储器功率,所以可提高每个网络模型的主要应用的性能。
尽管上面已经描述了各个实施例,但是本领域技术人员将理解,所描述的实施例仅作为示例。因此,本文所描述的系统和装置不应受到所描述的实施例的限制。
- 数据存储装置、数据处理系统及其加速装置
- 数据存储装置、数据处理系统及数据存储装置的操作方法