超网络训练方法、装置、设备、介质及程序产品
文献发布时间:2024-04-18 19:58:30
技术领域
本申请实施例涉及机器学习技术领域,特别涉及一种超网络训练方法、装置、设备、介质及程序产品。
背景技术
神经结构搜索(Neural Architecture Search,NAS)是一种自动设计神经网络的技术。
经典NAS的原理是,给定一个搜索空间,这个搜索空间中包含了结构不同的多个候选神经网络,按照一定的搜索策略在搜索空间中进行网络搜索,之后对搜索到的候选神经网络进行性能评估,最终从多个候选神经网络中搜索出结构最优的神经网络。
在NAS的执行过程中,每搜索到一个候选神经网络需要进行一次网络训练和性能评估,因此,整个搜索过程需要耗费大量的运算资源。
发明内容
本申请实施例提供了一种超网络训练方法、装置、设备、介质及程序产品。所述技术方案如下:
根据本申请的一方面内容,提供了一种超网络训练方法,所述方法包括:
采用第一样本集对超网络进行第一阶段训练,所述超网络包括M个子网络,所述子网络与所述超网络共用网络参数,所述M是大于1的整数;
在所述第一阶段训练结束后,从所述M个子网络中提取出N个第一子网络,所述N是大于1且小于所述M的整数;
对所述N个第一子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络,所述K是小于或等于N的正整数;
采用第二样本集对所述K个中心子网络进行第二阶段训练,直至所述超网络在所述第二阶段训练时的误差收敛,得到训练完成的超网络。
根据本申请的另一方面内容,提供了一种超网络训练装置,所述装置包括:
训练模块,用于采用第一样本集对超网络进行第一阶段训练,所述超网络包括M个子网络,所述子网络与所述超网络共用网络参数,所述M是大于1的整数;
采样模块,用于在所述第一阶段训练结束后,从所述M个子网络中提取出N个第一子网络,所述N是大于1且小于所述M的整数;
聚类模块,用于对所述N个第一子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络,所述K是小于或等于N的正整数;
所述训练模块,用于采用第二样本集对所述K个中心子网络进行第二阶段训练,直至所述超网络在所述第二阶段训练时的误差收敛,得到训练完成的超网络。
根据本申请的另一方面内容,提供了一种计算机设备,所述计算机设备包括处理器、与所述处理器相连的存储器,所述存储器上存储有程序指令,所述处理器执行所述程序指令时实现如本申请各个方面提供的超网络训练方法。
根据本申请的另一方面内容,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有程序指令,所述程序指令被处理器执行时实现如本申请各个方面提供的超网络训练方法。
根据本申请的另一方面内容,提供了一种计算机程序产品(或计算机程序),所述计算机程序产品(或计算机程序)包括计算机指令,所述计算机指令存储在计算机可读存储介质中;计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行如本申请各个方面提供的超网络训练方法。
根据本申请的另一方面内容,提供了一种芯片,所述芯片包括可编程逻辑电路和/或程序指令,当所述芯片运行时,用于实现如本申请各个方面提供的超网络训练方法。
本申请实施例提供的技术方案带来的有益效果可以包括:
上述超网络训练方法中,首先对超网络进行第一阶段训练;在完成第一阶段训练之后从中筛选出部分子网络,对这一部分子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络;由于超网络与子网络共用网络参数,后续会针对K个中心子网络进行第二阶段训练,也即在聚类后有针对性的对中心子网络进行网络训练,不再是针对超网络中的所有子网络进行网络训练,这样有利于超网络训练时误差的加速收敛,可以提高超网络的训练效率。
附图说明
为了更清楚地介绍本申请实施例中的技术方案,下面将对本申请实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1示出了本申请一个示例性实施例提供的超网络训练方法的流程图;
图2示出了本申请一个示例性实施例提供的子网络采样的示意图;
图3示出了本申请另一个示例性实施例提供的子网络采样的示意图;
图4示出了本申请另一个示例性实施例提供的超网络训练方法的流程图;
图5示出了本申请一个示例性实施例提供的子网络聚类的示意图;
图6示出了本申请一个示例性实施例提供的误差计算方法的流程图;
图7示出了本申请另一个示例性实施例提供的超网络训练方法的流程图;
图8示出了本申请一个示例性实施例提供的超网络训练装置的框图;
图9示出了本申请一个示例性实施例提供的计算机设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
在本申请的描述中,需要理解的是,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。在本申请的描述中,需要说明的是,除非另有明确的规定和限定,术语“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本申请中的具体含义。此外,在本申请的描述中,除非另有说明,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
首先,对本申请涉及的几个名词进行介绍:
超网络(Supernet),是由多个神经网络结构组合而成的一个整体网络,其中,在超网络中一个神经网络结构也被称为一个子网络。
示例性的,在NAS的执行过程中,需要对搜索空间中的多个神经网络结构依次训练与测试,整个搜索过程需要耗费大量的运算资源,因此,提出了一次学习的NAS技术,也即One-Shot NAS技术。在One-Shot NAS技术中,构建了一个整体的网络结构,在这个网络结构中可以搜索到多个神经网络结构,相当于将搜索空间中的多个神经网络结构结合成为了一个更大的网络结构;在技术实现过程中,包括了超网络训练、子网络搜索、子网络微调、以及子网络性能测试这4个步骤。其中,超网络中的网络参数是共享的,也即超网络与子网络共用网络参数,在超网络训练的过程中,每一轮训练需要从超网络中搜索一个子网络进行训练,直至超网络的误差收敛,完成对超网络的训练。
一般地,超网络的搜索空间很大,尤其地,搜索空间中包含的子网络数量可以随着网络层数呈指数型增长,训练较多结构不同的子网络,导致超网络的误差收敛速度很慢。因此,本申请提供了一种超网络训练方法,其详细实现方式如下实施例所示。
图1是本申请一个示例性实施例提供的超网络训练方法的流程图,该方法应用于计算机设备中,示例性的,该计算机设备可以是终端或者服务器,该方法包括:
步骤110,采用第一样本集对超网络进行第一阶段训练,超网络包括M个子网络,子网络与超网络共用网络参数,M是大于1的整数。
示例性的,计算机设备中存储有样本集;或者,数据库中存储有样本集。上述样本集包括第一样本集;计算机设备从自身存储器或者数据库中获取第一样本集;采用第一样本集对超网络进行第一阶段训练。
在第一阶段训练的过程中,针对每一轮训练,计算机设备从超网络中采样一个第三子网络;将第一样本集中的训练样本输入第三子网络,得到第二输出结果;计算第二输出结果与实际结果之间的第一误差;基于第一误差对第三子网络中的网络参数进行调整,也即对超网络的网络参数进行调整。
比如,超网络支持用于图像识别的子网络搜索;相应地,第一样本集中的训练样本包括图像样本,该图像样本上标记有标准结果;计算机设备将上述图像样本输入第三子网络,输出对图像样本的识别结果(也即第二输出结果);计算识别结果与标准结果(也即实际结果)之间的第一误差;基于第一误差对第三子网络中的网络参数进行调整。
计算机设备采用第一样本集对超网络进行Q轮训练,完成超网络的第一阶段训练;其中,Q的取值是由设计人员预先设置的。
或者,计算机设备在超网络的训练过程中,检测超网络的误差收敛情况;在超网络的误差小于第一误差阈值的情况下,结束对超网络的第一阶段训练。其中,上述第一误差阈值是由设计人员预先设置的。比如,计算机设备计算得到第一误差之后,在超网络的第一误差小于第一误差阈值的情况下,停止对超网络的网络参数的调整,完成超网络的第一阶段训练。
示例性的,上述样本集中包括:图像样本、视频样本、语音样本、文字样本中的至少一种;也即,本申请中的超网络支持用于图像、视频、语音、文字等的神经网络结构搜索。
示例性的,对于第三子网络的搜索,计算机设备可以采用如下任意一种搜索方法:随机搜索、贝叶斯优化算法、进化算法、强化学习、基于梯度的算法。
步骤120,在第一阶段训练结束后,从M个子网络中提取出N个第一子网络,N是大于1且小于M的整数。
示例性的,对于第一子网络的搜索,计算机设备可以采用如下任意一种搜索方法:随机搜索、贝叶斯优化算法、进化算法、强化学习、基于梯度的算法。比如,计算机设备在第一阶段训练结束后,从M个子网络中随机搜索出N个第一子网络。其中,提取第一子网络与第三子网络的搜索方法可以相同或者不同。
设置有缩放率列表,缩放率列表中包括至少两个缩放率;计算机设备从超网络中搜索第一子网络的过程中,选取至少一个缩放率作为采集第一子网络中各层网络的缩放比例,缩放率用于指示子网络与超网络对应的各层网络的宽度比值;基于至少一个缩放率从超网络中采样第一子网络。示例性的,至少一个缩放率可以是从缩放率列表中随机选取的。
比如,如图2所示,一个L层的超网络中每层网络的宽度均为4,L为大于1的整数。在这个超网络中采样子网络时,采用的缩放率列表={0.25,0.5,0.75,1.0};计算机设备可以采用缩放率列表中两个及以上的缩放率对第一子网络中的各层网络进行采样,得到子网络1至子网络C,C为大于1、且小于或等于L
可选地,计算机设备采用均匀采样方式,从M个子网络中提取出N个第一子网络,其中,均匀采样方式是指采用同一缩放率(shrink ratio)对神经网络结构中的每一层采样的方式。示例性的,如图3所示,一个L层的超网络中每层网络的宽度均为4。在这个超网络中采样子网络时,采用的缩放率列表={0.25,0.5,0.75,1.0};计算机设备可以采用缩放率列表中任意一个缩放率对第一子网络中的各层网络进行采样,得到子网络1至子网络4。其中,对于子网络1的搜索,计算机设备采用0.75采集宽度为3的层1至3;对于子网络4的搜索,计算机设备采用0.5采集宽度为2的层1至层3。示例性的,上述一个缩放率可以是从缩放率列表中随机选取的。
还需要说明的是,计算机设备在上述第一阶段训练的过程中,还可以采用均匀采样方式从超网络中提取子网络进行训练。
步骤130,对N个第一子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络,K是小于或等于N的正整数。
计算机设备采用聚类算法对N个第一子网络进行聚类分析,得到K个聚类集合,其中,每一个聚类集合中包括一个位于聚类中心的子网络,也即中心子网络;从K个聚类集合中获取K个中心子网络。
示例性的,上述聚类算法可以是如下任意一种:K均值(K-means)算法、二分K-means算法、K最近邻(K Nearest Neighbor,KNN)分类算法、高斯混合模型(Gaussian MixedModel,GMM)。比如,计算机设备采用K-means算法,计算N个第一子网络中位于K个聚类中心的K个中心子网络;其中,K的取值为设计人员预先设置的。
示例性的,计算机设备采用聚类算法,按照子网络之间的相似度对N个第一子网络进行聚类分析。比如,计算机设备采用聚类算法,按照子网络之间的结构相似度对N个第一子网络进行聚类分析。
步骤140,采用第二样本集对K个中心子网络进行第二阶段训练,直至超网络在第二阶段训练时的误差收敛,得到训练完成的超网络。
示例性的,上述样本集包括第二样本集;计算机设备从自身存储器或者数据库中获取第二样本集;采用第二样本集对K个中心子网络进行第二阶段训练,直至超网络在第二阶段训练时的误差收敛,得到训练完成的超网络。
示例性的,计算机设备采用第二样本集对K个中心子网络进行循环训练,直至超网络在第二阶段训练时的误差收敛,得到训练完成的超网络。比如,存在3个中心子网络:子网络01、子网络02和子网络03;计算机设备采用第二样本集中的训练样本对子网络01、子网络02和子网络03依次进行一轮训练,然后再次对子网络01、子网络02和子网络03依次进行一轮训练,如此循环训练至超网络的误差收敛,得到训练完成的超网络。
在第二阶段训练的过程中,针对每一轮训练,计算机设备将第二样本集中的训练样本输入中心子网络,得到第三输出结果;计算第三输出结果与实际结果之间的第三误差;基于第三误差对中心子网络中的网络参数进行调整,也即对超网络的网络参数进行调整。
在超网络的训练过程中,为了表征子网络的网络结构,计算机设备通过独热(One-hot)编码对子网络的网络结构信息列表进行编码,得到子网络的编码标识,该编码标识用于唯一标记该子网络。
需要说明的是,本申请实施例中不同子网络之间结构不同,和/或,不同子网络之间采用的收缩率相同或者不同。
综上所述,本实施例提供的超网络训练方法,首先对超网络进行第一阶段训练;在完成第一阶段训练之后从中筛选出部分子网络,对这一部分子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络;由于超网络与子网络共用网络参数,后续会针对K个中心子网络进行第二阶段训练,也即在聚类后有针对性的对中心子网络进行网络训练,不再是针对超网络中的所有子网络进行网络训练,这样有利于超网络训练时误差的加速收敛,可以提高超网络的训练效率。
其次,计算机设备在超网络的整个训练过程中,采用均匀采样方式从超网络中提取子网络,使得采样得到的各个子网络中各层网络的宽度缩放比例一致,减少了训练的子网络结构的多样性,这样更有利于超网络训练时误差的快速收敛。
为了加快超网络的误差收敛的同时,能够提高超网络的精度,计算机设备可以从性能较好的子网络中选取中心子网络,来进行超网络的第二阶段训练。示例性的,计算机设备采用均匀采样方式,从M个子网络中提取符合第一性能要求的N个第一子网络,如图4所示,可以将图2中的步骤120替换为步骤122至步骤126来实现这一步骤,如下所示:
步骤122,在第一阶段训练结束后,采用均匀采样方式,从M个子网络中提取出G个第二子网络,G大于或等于N,且小于M。
示例性的,对于第二子网络的搜索,计算机设备可以采用如下任意一种搜索方法:随机搜索、贝叶斯优化算法、进化算法、强化学习、基于梯度的算法。比如,计算机设备在第一阶段训练结束后,从M个子网络中随机搜索出G个第二子网络。其中,提取第二子网络与第三子网络的搜索方法可以相同或者不同。
设置有缩放率列表,缩放率列表中包括至少两个缩放率;计算机设备从超网络中搜索第二子网络的过程中,选取一个缩放率作为采集第二子网络中各层网络的缩放比例;基于该缩放率从超网络中采样第二子网络。示例性的,上述一个缩放率可以是从缩放率列表中随机选取的。
步骤124,采用第一测试样本对第二子网络进行性能测试,得到G个第二子网络对应的G个性能测试结果。
计算机设备中存储有第一测试样本;或者,数据库中存储有第一测试样本。计算机设备从自身存储器或者数据库中获取第一测试样本;采用第一测试样本对第二子网络进行性能测试,得到G个第二子网络对应的G个性能测试结果。其中,性能测试也即性能评估,用于评估训练得到的神经网络结构的泛化能力。第二子网络的性能测试结果用于指示第二子网络的泛化能力。
示例性的,该性能测试结果包括以下数据中的任意一项:错误率;精度;查准率(Precision,P)和查全率(Recall,R);度量参数F1,其中,F1=(2×P×R)/(P+R),“×”表示乘以,“/”表示除以;ROC(Receiver Operating Characteristic,受试者工作特征)曲线的AUC(Area Under Curve,曲线下的面积)。也即,计算机设备可以采用错误率和精度来评价子网络的泛化能力;或者可以从查准率和查全率的角度来评价子网络的泛化能力;或者,可以采用ROC曲线来评价子网络的泛化能力,实际情况下采用何种评价方式可以根据任务需求来设计。
步骤126,基于G个性能测试结果,从G个第二子网络中确定出符合第一性能要求的N个第一子网络。
可选地,第一性能要求包括子网络的泛化能力高于第一泛化能力。比如,性能测试结果包括精度,第一性能要求包括子网络的精度高于第一精度阈值;又比如,性能测试结果包括错误率,第一性能要求包括子网络的错误率低于第一错误率阈值;又比如,性能测试结果包括F1,第一性能要求包括子网络的F1大于第一阈值。其中,第一泛化能力是预先设置的能力阈值。
示例性的,计算机设备基于G个性能测试结果,从G个第二子网络中确定出泛化能力高于第一泛化能力的N个第一子网络。比如,计算机设备基于G个精度,从G个第二子网络中确定出精度高于第一精度阈值的N个第一子网络;又比如,计算机设备基于G个F1,从G个第二子网络中确定出F1高于第一阈值的N个第一子网络。
可选地,第一性能要求包括了子网络的泛化能力位于由大到小排序的前N位。比如,计算机设备对G个F1由大到小排序,确定出排序在前N位的F1,将前N位的F1对应的N个第二子网络确定为N个第一子网络;又比如,计算机设备对G个错误率由小到大排序,确定出排序在前N位的错误率,将前N位的错误率对应的N个第二子网络确定为N个第一子网络。
在一些实施例中,为了降低性能评估的计算量,可以采用子网络的测试误差来表征子网络的泛化能力。这一情景下,对于上述步骤124至步骤126的实现,计算机设备可以采用第一测试样本测试第二子网络的输出结果与实际结果之间误差,得到G个第二子网络对应的G个测试误差;按照G个测试误差从小到大的顺序,选取出前N个测试误差对应的前N个第二子网络,得到符合第一性能要求的N个第一子网络。
或者,计算机设备在得到G个测试误差之后,还可以从G个测试误差中确定出小于第二误差阈值的N个测试误差;将N个测试误差对应的N个第二子网络,确定为符合第一性能要求的N个第一子网络。
也即,第一性能要求包括子网络的测试误差位于由小到大排序的前N位。或者,第一性能要求包括子网络的测试误差小于第二误差阈值。其中,上述第二误差阈值是预先设置的。示例性的,上述第一误差阈值可以小于或者等于上述第二误差阈值。
示例性的,如图5所示,如果K的取值为4,计算机设备在得到性能较好的N个第一子网络之后,采用K-means算法对N个第一子网络进行聚类,得到4个簇:子网络簇1、子网络簇2、子网络簇3和子网络簇4;位于簇中心的子网络即为中心子网络。
综上所述,本实施例提供的超网络训练方法,在聚类分析的过程中,通过第一性能要求的设置,从超网络中提取出性能表现较好的N个第一子网络,过滤掉性能较差的子网络,进而从N个第一子网络中聚类分析出K个中心子网络,保证第二阶段训练时的子网络均具备较好的性能,这样能够避免训练性能较差的子网络干扰性能较好子网络的权重调整,导致训练得到的超网络的性能降低,继而提升超网络的性能;且这一方式还能够缩小子网络的搜索空间,只训练结构最具代表性的子网络,提高超网络训练过程中的误差收敛速度。
其次,上述方法中对子网络进行性能评估时,可以采用子网络的测试误差来实现,相对于采用精度、错误率、F1等性能评估方式,能够极大地降低计算量,从而提高子网络的性能评估时间,降低超网络训练的整体时长,提高了超网络训练的训练效率。
在第一阶段训练过程中,为了提高第一阶段训练的效率,还可以基于知识蒸馏的方式,对第三子网络进行训练,示例性的,步骤110可以实现成为如下步骤:
步骤110(a),在第一阶段训练的过程中,获取基准网络。
上述基准网络是预先训练过的神经网络结构,且上述基准网络与上述超网络均是针对同一任务需求设计的神经网络结构。
可选地,上述基准网络是独立于超网络之外的神经网络结构。示例性的,上述基准网络是训练至误差收敛的神经网络结构;或者,上述基准网络是训练至误差小于第三误差阈值的神经网络结构。这一基准网络可以是由计算机设备训练得到的;或者是由其它设备训练得到之后迁移至该计算机设备上使用的,其它设备是指除上述计算机设备之外的其它计算机设备。
可选地,上述基准网络是超网络中的子网络。上述基准网络是训练至误差小于第三误差阈值的神经网络结构。示例性的,计算机设备对超网络的第一阶段训练可以分为两个子阶段;在第一子阶段时,计算机设备采用第一样本集中的部分样本对超网络进行训练;在超网络中存在误差小于第三误差阈值的子网络的情况下,将该子网络作为基准网络;在第二子阶段时,执行如下步骤110(b)至步骤110(f)。
示例性的,计算机设备在第一子阶段时,从超网络中选取一个第三子网络;将第一样本集中的训练样本输入第三子网络,得到第二输出结果;计算第二输出结果与实际结果之间的第一误差;在第一误差小于第三误差阈值的情况下,将这一第三子网络作为基准网络。或者,计算机设备在计算得到第一误差之后,基于第一误差对第三子网络中的网络参数进行调整;采用第三测试样本测试这一第三子网络的误差;在测试得到的误差小于第三误差阈值的情况下,将这一第三子网络作为基准网络;后续执行如下步骤110(b)至步骤110(f),从超网络中继续提取另一第三子网络进行新一轮的训练。
上述第三误差阈值是预先设置的。示例性的,在上述基准网络是独立于超网络之外的神经网络结构的情况下,不限定第三误差阈值与第一误差阈值、以及第二误差阈值之间的大小关系;在上述基准网络是超网络中的子网络的情况下,上述第三误差阈值可以大于或者等于上述第一误差阈值;和/或,上述第三误差阈值还可以大于或者等于上述第二误差阈值。
步骤110(b),针对每一轮训练,从M个子网络中选取一个第三子网络。
步骤110(c),将第一样本集中的训练样本输入基准网络,得到第一输出结果;以及将训练样本输入第三子网络,得到第二输出结果。
示例性的,上述第一输出结果是基准网络按照任务需求对训练样本进行处理得到的结果;上述第二输出结果是第三子网络按照任务需求对训练样本进行处理得到的结果。在每一轮训练中,第一输出结果与第二输出结果是按照同一任务需求对同一训练样本进行处理得到的结果。
需要说明的是,本实施例中对第一输出结果与第二输出结果的计算顺序不加以限定,仅以步骤110(c)中同时计算的方式为例进行说明。
步骤110(d),计算第二输出结果与实际结果之间的第一误差。
在一些实施例中,还可以采用第三子网络中第一中间层的输出结果与基准网络中第二中间层的输出结果计算第一误差;比如,计算机设备计算第一中间层的输出结果与第二中间层的输出结果之间的误差,作为第一误差;其中,第二中间层是基准网络中与第一中间层对应的中间层。
步骤110(e),计算第一输出结果与第二输出结果之间的第二误差。
需要说明的是,本实施例中对步骤110(d)与步骤110(e)的执行顺序不加以限定,仅以顺序执行步骤110(d)与步骤110(e)为例进行说明。
步骤110(f),基于第一误差与第二误差,对第三子网络中的网络参数进行调整。
第三子网络与超网络共用网络参数,计算机设备基于第一误差与第二误差的加权和;基于第一误差与第二误差的加权和对第三子网络中的网络参数进行调整,得到调整后的网络参数,即得到超网络的网络参数。
预先设置第一误差对应的权重为第一权重,第二误差对应的权重为第二权重;计算机设备将第一误差与第一权重相乘,得到第一乘积;以及将第二误差与第二权重相乘,得到第二乘积;对第一乘积与第二乘积求和,即得到第一误差与第二误差的加权和,即加权后的误差;按照加权后的误差对第三子网络中的网络参数进行调整;其中,第一权重和第二权重的和为1。
可选地,第一权重和第二权重的取值是预先设置的经验值。
可选地,第一权重和第二权重是网络训练过程中学习得到的。也即,第一权重与第二权重作为超网络的网络参数,是在超网络的训练过程中学习得到的。比如,第三子网络的网络参数包括第一权重和第二权重;第1轮训练的过程中,计算机设备采用设置的第一权重和第二权重的初始值;第i+1轮训练时,计算机设备采用第i轮训练过程中调整后的第一权重和第二权重。
示例性的,第三子网络中的网络参数为超网络中的部分网络参数,则计算机设备在得到调整后的网络参数之后,基于调整后的网络参数对超网络的部分网络参数进行更新。
如上所述,第三子网络的训练可以采用知识蒸馏的方式,在知识蒸馏的过程中,上述基准网络可以被称为教师网络,第三子网络可以被称为学生网络。
综上所述,本实施例提供的超网络训练方法,在第一阶段训练的过程中,获取基准网络,来参与超网络中子网络的训练,通过知识蒸馏的方式对超网络中的子网络进行训练,加速超网络中子网络的学习速度,从而提高超网络的收敛速度。且该方法中还可以通过第三误差阈值来选择性能好的基准网络,在提高超网络中子网络的学习速度的同时,保证了超网络中子网络的学习精度。
在一些实施例中,在顺序执行步骤110(d)与步骤110(e)的情况下,第一权重与第二权重的取值均大于0,计算机设备还在计算第一输出结果与第二输出结果之间的第二误差之前,计算第一输出结果与实际结果之间的第三误差;在第三误差与第一误差之间的差值小于或者等于差值阈值的情况下,将第一权重的取值重置为1,以及将第二权重的取值重置为0;之后执行步骤110(e)至步骤110(f)。
示例性的,如图6所示,计算机设备采用知识蒸馏进行网络训练的过程中,加权后的误差的计算如下所示:
210,将第一样本集中的训练样本分别输入子网络10和教师网络20,子网络10也即第三子网络。
220,通过子网络10对训练样本进行处理,输出Y
230,计算Y
240,通过教师网络20对训练样本进行处理,输出Y
250,计算Y
260,判断Loss0是否小于或等于α;若否,执行步骤270;若是,执行步骤280。
其中,Loss0是第三误差与第一误差的差值,采用公式表示为Loss0=
270,计算
其中,Loss即是加权后的误差,Loss1(Y
示例性的,初始化时,W0=0.5,W1=0.5。
280,将第一误差作为Loss。
Loss采用公式表示为
综上所述,本实施例提供的超网络训练方法,在第三误差与第一误差的差值小于或者等于一个差值阈值时,则网络参数的调整不再参考教师网络的误差,这样可以防止网络后期对子网络的学习抑制,因为由于教师网络自身的误差局限,可能会在网络训练后期对子网络的学习产生抑制作用。
在第二阶段训练的过程中,为了保证超网络中的子网络均具备较好的性能,计算机设备还可以抽测子网络的性能是否符合第二性能要求,示例性的,步骤140可以实现成为如下步骤:
步骤140(a),采用第二样本集对K个中心子网络进行第二阶段训练。
步骤140(b),在超网络的误差收敛的情况下,从M个子网络中提取D个待测子网络,D为大于0且小于M的整数。
示例性的,对于待测子网络的搜索,计算机设备可以采用如下任意一种搜索方法:随机搜索、贝叶斯优化算法、进化算法、强化学习、基于梯度的算法。
其中,待测子网络可以与第一子网络和/或第三子网络的搜索方法相同或者不同。示例性的,计算机设备从缩放率列表中选取至少一个缩放率作为采集测试子网络中各层网络的缩放比例;基于至少一个缩放率从超网络中采样测试子网络。示例性的,至少一个缩放率可以是从缩放率列表中随机选取的。
可选地,计算机设备采用均匀采样方式,从M个子网络中提取D个待测子网络。示例性的,均匀采样方式中采用的一个缩放率可以是从缩放率列表中随机选取的。
步骤140(c),采用第二测试样本对D个待测子网络进行性能测试。
示例性的,计算机设备可以采用至少两个第二测试样本对每一个待测子网络进行性能测试,得到D个待测子网络对应的D个测试结果。测试子网络的测试结果用于指示待测子网络的泛化能力。
上述泛化能力可以采用以下任意一项信息来表示:精度;查准率和查全率;度量参数F1;ROC曲线的AUC。可选地,上述泛化能力还可以采用待测子网络的误差来表示;计算机设备采用第二测试样本对待测子网络进行性能测试,得到待测子网络的误差,作为测试结果。示例性的,第二测试样本包括至少两个的情况下,将待测子网络的误差均值作为测试结果。
步骤140(d),在D个待测子网络的性能均符合第二性能要求的情况下,确定超网络训练完成。
示例性的,第二性能要求包括待测子网络的泛化能力均高于第二泛化能力。比如,测试结果包括精度,第二性能要求包括待测子网络的精度高于第二精度阈值;又比如,测试结果包括F1,第二性能要求包括待测子网络的F1大于第二阈值;又比如,测试结果包括待测子网络的误差,第二性能要求包括待测子网络的误差小于第四误差阈值。其中,第二泛化能力是预先设置的能力阈值。示例性的,第二泛化能力高于第一泛化能力。
步骤140(e),在D个待测子网络中存在至少一个待测子网络的性能不符合第二性能要求的情况下,采用第三样本集再次对K个中心子网络进行训练,直至超网络中重新抽样测试的待测子网络的性能均符合第二性能要求。
示例性的,第二样本集与第三样本集的交集可以不为空或者为空。
综上所述,本实施例提供的超网络训练方法,在超网络的误差收敛之后,还对超网络中的子网络进行抽检,以确保超网络中的子网络均能够有较好的性能。
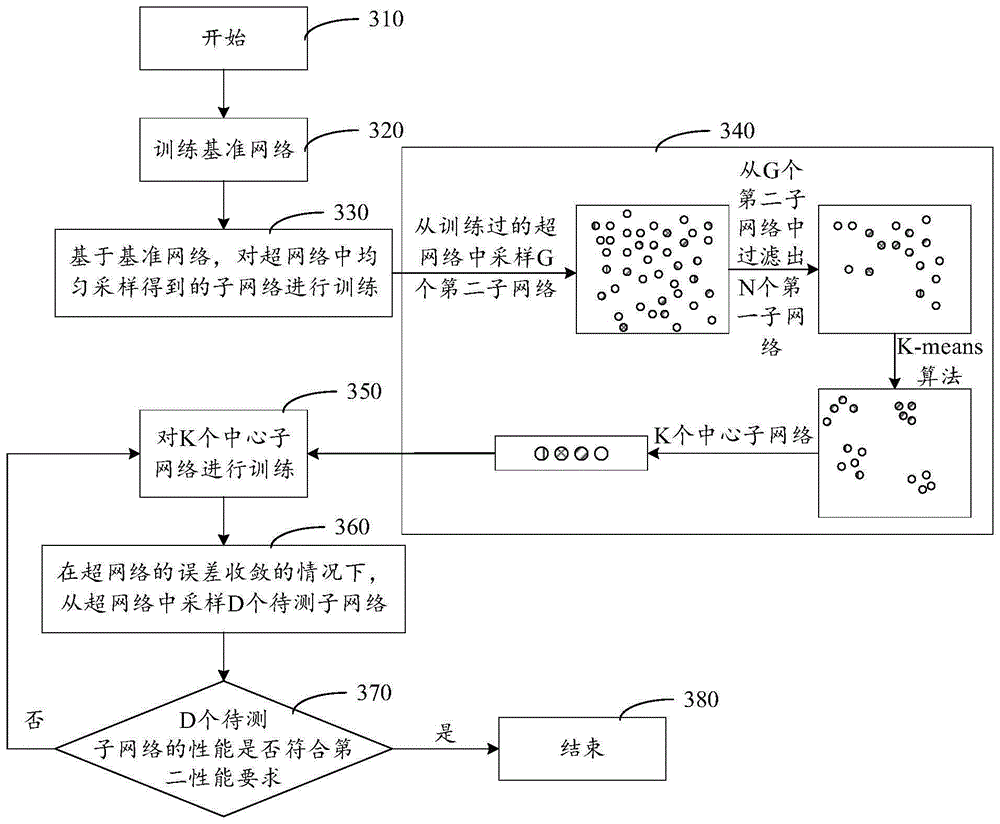
如图7所示,其是本申请一个示例性实施例提供的超网络训练方法的流程图,这一流程图体现了本申请中超网络训练的整体思路,步骤如下:
步骤310,开始。
步骤320,训练基准网络。
示例性的,计算机设备对基准网络进行独立训练,得到误差收敛的基准网络。其中,基准网络也可以称为基准模型。这一基准模型可以是独立于超网络之外设计的神经网络结构,或者,可以是从超网络中提取得到的神经网络结构。
步骤330,基于基准网络,对超网络中均匀采样得到的子网络进行训练。
示例性的,计算机设备采用均匀采样方式从超网络中提取第三子网络,将基准网络用作教师网络对第三子网络进行训练,完成对超网络的第一阶段训练。
步骤340,从训练过的超网络中采样G个第二子网络,从G个第二子网络中过滤出N个第一子网络,对N个第一子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络。
计算机设备采用均匀采样方式,从第一阶段训练完成后的超网络中采样G个第二子网络;从G个第二子网络中过滤出符合第一性能要求的N个第一子网络,也即从G个第二子网络中过滤出泛化能力大于第一泛化能力的N个第一子网络;采用K-means算法对N个第一子网络进行聚类,得到位于K个聚类中心的K个中心子网络。
步骤350,对K个中心子网络进行训练。
计算机设备依次对K个中心子网络进行训练,调整超网络中的网络参数;其中,K个中心子网络与超网络共用网络参数。
步骤360,在超网络的误差收敛的情况下,从超网络中采样D个待测子网络。
计算机设备在超网络的误差收敛的情况下,采用均匀采样方式从超网络中采样D个子网络作为待测子网络。之后计算机设备对D个待测子网络进行性能测试。
步骤370,判断D个待测子网络的性能是否符合第二性能要求;若否,返回执行步骤350;若是,执行步骤380。
在一些实施例中,计算机设备还可以判断符合第二性能要求的待测子网络与D的比值是否大于比值阈值,若否,返回执行步骤350;若是,执行步骤380。
步骤380,结束。
需要说明的是,本实施例中各个步骤的详细实现方式可以参考如上各个实施例中内容,在此不再加以赘述。
综上所述,本实施例提供的超网络训练方法,在超网络训练过程中,引入知识蒸馏,利用性能较好的教师网络去指导子网络的训练,加速超网络的收敛。
其次,该方法中还使用动态的损失函数。示例性的,网络的损失函数由两部分组成:子网络的真实损失值
再有,在完成初步的超网络训练后,对子网络进行聚类并训练聚类中心子网络。示例性的,随机采样一些子网络,过滤性能较差的子网络,只对性能较好的子网络进行K-means聚类,并训练聚类中心。这种过滤能够有效避免较差子网络对超网络性能的干扰,从而提升超网络性能。另外,这样的方式能够缩小子网络的采样空间,只训练结构最具代表性的子网络,提高训练的收敛速度。
下述为本申请装置实施例,可以用于执行本申请方法实施例。对于本申请装置实施例中未披露的细节,请参照本申请方法实施例。
图8示出了本申请一个示例性实施例提供的超网络训练装置的结构框图。该装置可以通过软件、硬件或者两者的结合实现成为车载设备的全部或一部分。该装置与至少一个终端之间建立有通信连接,该装置包括:
训练模块410,用于采用第一样本集对超网络进行第一阶段训练,所述超网络包括M个子网络,所述子网络与所述超网络共用网络参数,所述M是大于1的整数;
采样模块420,用于在所述第一阶段训练结束后,从所述M个子网络中提取出N个第一子网络,所述N是大于1且小于所述M的整数;
聚类模块430,用于对所述N个第一子网络进行聚类分析,得到位于K个聚类中心的K个中心子网络,所述K是小于或等于N的正整数;
所述训练模块410,用于采用第二样本集对所述K个中心子网络进行第二阶段训练,直至所述超网络在所述第二阶段训练时的误差收敛,得到训练完成的超网络。
在一些实施例中,所述采样模块420,用于:
采用均匀采样方式,从所述M个子网络中提取出符合第一性能要求的所述N个第一子网络;
其中,所述均匀采样方式是指采用同一缩放率对神经网络结构中每一层采样的方式。
在一些实施例中,所述采样模块420,用于:
采用所述均匀采样方式,从所述M个子网络中提取出G个第二子网络,所述G大于或等于所述N,且小于所述M;
采用第一测试样本对所述第二子网络进行性能测试,得到所述G个第二子网络对应的G个性能测试结果;
基于所述G个性能测试结果,从所述G个第二子网络中确定出符合所述第一性能要求的所述N个第一子网络。
在一些实施例中,所述性能测试结果包括所述第二子网络的测试误差;所述采样模块420,用于:
采用所述第一测试样本测试所述第二子网络的输出结果与实际结果之间误差,得到所述G个第二子网络对应的G个测试误差;
按照所述G个测试误差从小到大的顺序,选取出前N个测试误差对应的前N个第二子网络,得到符合所述第一性能要求的所述N个第一子网络。
在一些实施例中,所述训练模块410,用于:
在所述第一阶段训练的过程中,获取基准网络;
针对每一轮训练,从所述M个子网络中选取一个第三子网络;
将所述第一样本集中的训练样本输入所述基准网络,得到第一输出结果;以及将所述训练样本输入所述第三子网络,得到第二输出结果;
计算所述第二输出结果与实际结果之间的第一误差;
计算所述第一输出结果与所述第二输出结果之间的第二误差;
基于所述第一误差与所述第二误差,对所述第三子网络中的网络参数进行调整。
在一些实施例中,所述训练模块410,用于:
将所述第一误差与第一权重相乘,得到第一乘积;以及将所述第二误差与第二权重相乘,得到第二乘积;
对所述第一乘积与所述第二乘积求和,得到加权后的误差;
按照所述加权后的误差对所述第三子网络中的网络参数进行调整;其中,所述第一权重与所述第二权重的和为1。
在一些实施例中,所述训练模块410,用于:
在所述第一权重与所述第二权重均大于0的情况下,所述计算所述第一输出结果与所述第二输出结果之间的第二误差之前,计算所述第一输出结果与所述实际结果之间的第三误差;
在所述第三误差与所述第一误差之间的差值小于差值阈值的情况下,将所述第一权重的取值重置为1,以及将所述第二权重的取值重置为0。
在一些实施例中,所述训练模块410,用于:
采用所述第二样本集对所述K个中心子网络进行所述第二阶段训练;
在所述超网络的误差收敛的情况下,从所述M个子网络中提取D个待测子网络,所述D为大于0且小于所述M的整数;
采用第二测试样本对所述D个待测子网络进行性能测试;
在所述D个待测子网络的性能均符合第二性能要求的情况下,确定所述超网络训练完成。
在一些实施例中,所述训练模块410,用于在所述D个待测子网络中存在至少一个待测子网络的性能不符合所述第二性能要求的情况下,采用第三样本集再次对所述K个中心子网络进行训练,直至所述超网络中重新抽样测试的待测子网络的性能均符合所述第二性能要求。
图9示出了本申请一个示例性实施例提供的计算机设备的结构示意图。该计算机设备可以是执行如本申请提供的超网络训练方法的设备。示例性的,该计算机设备可以是服务器或者终端。具体来讲:
计算机设备1000包括中央处理单元(CPU,Central Processing Unit)1001、包括随机存取存储器(RAM,Random Access Memory)1002和只读存储器(ROM,Read OnlyMemory)1003的系统存储器1004,以及连接系统存储器1004和中央处理单元1001的系统总线1005。计算机设备1000还包括帮助计算机内的各个器件之间传输信息的基本输入/输出系统(I/O系统,Input Output System)1006,和用于存储操作系统1013、应用程序1014和其他程序模块1015的大容量存储设备1007。
基本输入/输出系统1006包括有用于显示信息的显示器1008和用于用户输入信息的诸如鼠标、键盘之类的输入设备1009。其中显示器1008和输入设备1009都通过连接到系统总线1005的输入输出控制器1010连接到中央处理单元1001。基本输入/输出系统1006还可以包括输入输出控制器1010以用于接收和处理来自键盘、鼠标、或电子触控笔等多个其他设备的输入。类似地,输入输出控制器1010还提供输出到显示屏、打印机或其他类型的输出设备。
大容量存储设备1007通过连接到系统总线1005的大容量存储控制器(未示出)连接到中央处理单元1001。大容量存储设备1007及其相关联的计算机可读介质为计算机设备1000提供非易失性存储。也就是说,大容量存储设备1007可以包括诸如硬盘或者紧凑型光盘只读存储器(CD-ROM,Compact Disc Read Only Memory)驱动器之类的计算机可读介质(未示出)。
计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括RAM、ROM、可擦除可编程只读存储器(EPROM,Erasable Programmable Read Only Memory)、带电可擦可编程只读存储器(EEPROM,Electrically Erasable Programmable Read Only Memory)、闪存或其他固态存储其技术,CD-ROM、数字通用光盘(DVD,Digital Versatile Disc)或固态硬盘(SSD,Solid State Drives)、其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。其中,随机存取记忆体可以包括电阻式随机存取记忆体(ReRAM,Resistance RandomAccess Memory)和动态随机存取存储器(DRAM,Dynamic Random Access Memory)。当然,本领域技术人员可知计算机存储介质不局限于上述几种。上述的系统存储器1004和大容量存储设备1007可以统称为存储器。
根据本申请的各种实施例,计算机设备1000还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备1000可以通过连接在系统总线1005上的网络接口单元1011连接到网络1012,或者说,也可以使用网络接口单元1011来连接到其他类型的网络或远程计算机系统(未示出)。
上述存储器还包括一个或者一个以上的程序,一个或者一个以上程序存储于存储器中,被配置由CPU执行,以实现如上所述的超网络训练方法。
本申请实施例还提供了一种计算机可读存储介质,该计算机可读存储介质存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如上各个实施例所述的超网络训练方法。
可选地,该计算机可读存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取记忆体(RAM,Random Access Memory)、固态硬盘(SSD,Solid State Drives)或光盘等。其中,随机存取记忆体可以包括电阻式随机存取记忆体(ReRAM,Resistance RandomAccess Memory)和动态随机存取存储器(DRAM,Dynamic Random Access Memory)。
需要说明的是:上述实施例提供的超网络训练装置在执行超网络训练方法时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的超网络训练装置与超网络训练方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本申请的能够实现的示例性的实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 神经网络的训练方法、图像分割方法、装置、设备及介质
- 一种神经网络训练方法及装置、设备、介质
- 神经网络的训练方法、横向控制方法、装置、设备及介质
- 一种神经网络训练方法、装置、计算机设备和存储介质
- 图像处理方法和装置、电子设备、存储介质、程序产品
- 网络模型训练方法、装置、设备、介质及程序产品
- 神经网络训练方法、装置、电子设备、介质和程序产品