子NUMA集群中的集群间共享数据管理
文献发布时间:2024-04-18 19:58:21
背景
1.技术领域
本公开总体上涉及处理器技术和存储器集群技术。
2.背景技术
非均匀存储器访问(non-uniform memory access,NUMA)是一种用于多处理的计算机存储器设计,其中存储器访问时间取决于相对于处理器的存储器位置。在NUMA下,处理器可以比访问非本地存储器(另一处理器本地的存储器或处理器之间共享的存储器)更快地访问其自己的本地存储器。NUMA的好处仅限于特定的工作负载,特别是在其中数据通常与某些任务或用户密切相关联的服务器上。
一些处理器/服务器可包括用于支持子NUMA集群(sub-NUMAcluster,SNC)的特征。SNC可以将处理器的核心、缓存和存储器划分为多个NUMA域。在一些系统中,(一个或多个)SNC可提高NUMA感知且经优化的工作负载的性能。SNC可类似于一些处理器/服务器中的管芯上集群(cluster-on-die,COD)特征,但两者之间存在一些差异。SNC通过将来自其中一个本地存储器控制器的地址映射到更靠近该存储器控制器的最后一级缓存(last-levelcache,LLC)切片的一半中,并将被映射到另一个存储器控制器的地址映射到另一半的LLC切片中,从而在处理器内创建两个本地化域。通过这种地址映射机制,在SNC域中的一个SNC域上在核心上运行的进程使用来自同一SNC域中的存储器控制器的存储器观察到相较于被映射到同一域之外的位置的访问的等待时间更低的LLC和存储器等待时间。
与缓存行可能在每个集群的LLC中具有副本的COD机制不同,SNC针对LLC中的每一个地址具有唯一位置,并且该唯一位置永远不会在LLC区块(bank)内被复制。此外,每个SNC域的LLC内地址的本地化仅适用于被映射到同一插槽中的存储器控制器的地址。映射到远程插槽上存储器的所有地址独立于SNC模式而跨所有LLC区块均匀地分布。因此,即使在SNC模式下,插槽上的整个LLC容量对于每个核心都是可用的,并且通过CPUID报告的LLC容量不受SNC模式的影响。
附图说明
以示例方式且非限制方式在附图的各图中图示本发明的各实施例,在附图中:
图1是根据实施例的系统的示例的框图;
图2是根据实施例的系统的另一示例的框图;
图3是根据实施例的服务器的示例的框图;
图4是根据实施例的硬件的示例的框图;
图5是根据实施例的方法的示例的流程图;
图6至图7是根据实施例的方法的另一示例的流程图;
图8A是图示根据本发明的实施例的示例性有序管线和示例性的寄存器重命名、乱序发出/执行管线两者的框图。
图8B是图示根据本发明的实施例的要包括在处理器中的有序体系结构核心的示例性实施例和示例性的寄存器重命名、乱序发出/执行体系结构核心两者的框图;
图9A-图9B图示更具体的示例性有序核心体系结构的框图,该核心会是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核心);
图10是根据本发明的实施例的可具有多于一个的核心、可具有集成存储器控制器以及可具有集成图形器件的处理器的框图;
图11-图14是示例性计算机体系结构的框图;以及
图15是根据本发明的实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。
具体实施方式
本文中讨论的实施例以各种方式提供用于子非均匀存储器访问(sub-non-uniform memory access,子NUMA)集群(sub-NUMA cluster,SNC)中的集群间共享数据管理的技术和机制。本文中描述的技术可以在一个或多个电子设备中实现。可以利用本文中描述的技术的电子设备的非限制性示例包括任何种类的移动设备和/或固定式设备,诸如,相机、蜂窝电话、计算机终端、桌面型计算机、电子阅读器、传真机、自动服务机、膝上型计算机、上网本计算机、笔记本计算机、互联网设备、支付终端、个人数字助理、媒体播放器和/或记录器、服务器(例如,刀片服务器、机架安装服务器、其组合等)、机顶盒、智能电话、平板个人计算机、超移动个人计算机、有线电话、上述各项的组合,等等。更一般地,本文中描述的技术可在各种电子设备中的任何电子设备中被采用,各种电子设备包括可操作用于提供SNC存储器分配策略提示以及在SNC中分配存储器空间的请求的集成电路系统。
在下列描述中,讨论了众多细节,以提供对本公开的实施例的更透彻的解释。然而,对本领域技术人员将显而易见的是,可以在没有这些特定细节的情况下实施本公开的实施例。在其他实例中,以框图形式,而不是详细地示出公知的结构和设备,以避免使本公开的实施例变得模糊。
注意,在实施例的对应附图中,利用线来表示信号。一些线可以较粗以指示更多数量的成份信号路径,和/或在一个或多个末端处具有箭头以指示信息流的方向。此类指示不旨在是限制性的。相反,线结合一个或多个示例性实施例使用,以促进对电路或逻辑单元的更容易的理解。如由设计需要或偏好所规定,任何所表示的信号都可实际包括可在任一方向上行进的一个或多个信号,并可利用任何合适类型的信号方案来实现。
贯穿说明书以及在权利要求书中,术语“连接的”意指所连接的物体之间的诸如电气、机械、或磁性连接之类的无需任何中介设备的直接连接。术语“耦合的”意指直接的或间接的连接,诸如所连接的物体之间的直接的电气、机械、或磁性连接或者通过一个或多个无源或有源中介设备的间接连接。术语“电路”或“模块”可以指布置成用于彼此合作以提供期望功能的一个或多个无源和/或有源组件。术语“信号”可指至少一个电流信号、电压信号、磁信号、或数据/时钟信号。“一(a/an)”和“该”的含义包括复数引用。“在……中”的含义包括“在……中”和“在……上”。
术语“设备”一般可以指根据使用那个术语的上下文的装置。例如,设备可以指层或结构的堆叠、单个结构或层、具有有源和/或无源元件的各种结构的连接,等等。一般而言,设备是三维结构,具有沿x-y-z笛卡尔坐标系的x-y方向的平面以及沿z方向的高度。设备的平面也可以是包括该设备的装置的平面。
术语“缩放”一般指将设计(示意图和布局)从一种工艺技术转换为另一种工艺技术,并随后在布局区域中被减小。术语“缩放”一般还指在同一技术节点内缩小布局和设备的大小。术语“缩放”还可指信号频率相对于另一参数(例如,功率供应水平)的调整(例如,减速或加速——即,分别为缩小或放大)。
术语“基本上”、“接近”、“近似”、“附近”以及“大约”一般指处于目标值的+/-10%内。例如,除非在其使用的明确的上下文中以其他方式指定,否则术语“基本上相等”、“大约相等”和“近似相等”意指在如此描述的物体之间仅存在偶然变化。在本领域中,此类变化典型地不大于预定的目标值的+/-10%。
应当理解,如此使用的术语在适当情况下是可互换的,例如使得本文中所描述的本发明的实施例能够以不同于本文中图示或以其他方式描述的那些取向的其他取向来操作。
除非另外指定,否则使用序数形容词“第一”、“第二”、“第三”等来描述公共对象,仅仅指示类似对象的不同实例被提及,并且不旨在暗示如此描述的对象必须在时间上、空间上、排名上、或以任何其他方式处于给定序列中。
在说明书和权利要求书中的术语“左”、“右”、“前”、“后”、“顶”、“底”、“在……上方”、“在……下方”等(如果有)用于描述性目的,并且不一定用于描述永久的相对位置。例如,如本文中所使用的术语“在……上方”、“在……下方”、“前侧”、“后侧”、“顶”、“底”,“在……上方”、“在……下方”和“在……上”是指一个组件、结构或材料相对于设备内其他所引用的组件、结构或材料的相对位置,其中此类物理关系是显著的。本文仅出于描述性目的采用这些术语,并且这些术语主要在设备z轴的上下文内,因此这些术语可以相对于设备的取向。因此,在本文中所提供的图中的上下文中在第二材料“上方”的第一材料如在设备相对于所提供的图的上下文上下颠倒地取向情况下也可以在该第二材料“下方”。在材料的上下文中,设置在另一材料上方或下方的一种材料可直接接触,或者可具有一种或多种中介材料。此外,设置在两种材料之间的一种材料可直接与这两个层接触,或者可具有一个或多个中介层。相比之下,在第二材料“上”的第一材料与该第二材料直接接触。在组件组装件的上下文中进行类似的区分。
可在设备的z轴、x轴或y轴的上下文中采用术语“在……之间”。在两种其他材料之间的材料可以与那两种材料中的一种或两种接触,或者该材料可通过一种或多种中介材料来与其他那两种材料两者分开。因此,在两种其他材料“之间”的材料可以与其他那两种材料中的任一种接触,或者该材料可通过中介材料耦合至其他那两种材料。在两个其他设备之间的设备可直接连接到那两个设备中的一个或两个,或者该设备可通过一个或多个中介设备与其他那两个设备两者分开。
如贯穿说明书以及在权利要求书中所使用,由术语“……中的至少一个”或“……中的一个或多个”联接的项列表可意指所列举的项的任何组合。例如,短语“A、B或C中的至少一个”可意指A;B;C;A和B;A和C;B和C;或A、B和C。应指出,附图的具有与任何其他附图的要素相同的附图标记(或名称)的那些要素能以与所描述的方式类似的任何方式操作或起作用,但不被限于此。
此外,本公开中讨论的组合逻辑和时序逻辑的各种元件可涉及物理结构(诸如,AND门、OR门或XOR门),或涉及实现作为所讨论的逻辑的布尔等效的逻辑结构的器件的合成的或以其他方式优化的集合。
一些实施例可以提供用于子NUMA集群化中的集群间共享数据管理的技术。在传统的SNC系统中,在数据的初始化期间对数据放置的控制是有限的。默认情况下,硬件将数据放置在接触数据的第一NUMA集群/节点中。这种放置策略可导致数据跨在实际计算期间访问数据的集群被不均等地分布的情况,甚至可能导致所有数据被指派给单个集群的情况。此类不均等地分布的数据可能在很大程度上以两种方式导致集群间共享数据的效率低下。首先,对于组织为SNC的第三级(level-three,L3)缓存,不均等地分布的集群间共享数据将不会利用L3缓存的全部容量,这可能会导致更高的缓存未命中率。其次,由于访问被重定向到每条数据的所有者集群,因此不均等的所有权分布导致流量拥堵,从而导致更大的访问等待时间和更低的网格/缓存带宽利用率。
一些处理器中的管芯上集群(CoD)技术可以有效地将单个共享L3缓存拆分为多个L3缓存,其中每个集群一个L3缓存。硬件在这些L3缓存中的每个L3缓存中提供读取共享数据,从而使对共享数据的后续访问本地化,这是因为每个核心将命中其自己的L3缓存。然而,CoD复制由多个集群共享的数据,从而消耗附加L3容量并可能增加缓存未命中率。CoD技术还要求在多个集群之间维持一致性,这增加了L3缓存设计的复杂性。
一些系统可包括可在运行时被设置的交织存储器设置。在一些系统中,交织设置允许在运行时期间分配的所有页以交织方式跨不同的NUMA集群被放置。一旦被设置,交织存储器设置对运行时期间分配的所有数据应用页交织放置。问题在于,在程序中的数据的子集优选最先接触分配(例如,数据将仅由单个集群访问)的情况下此种设置可损害性能。一些实施例利用引导支持SNC的硬件更高效地防止共享数据的技术克服了上述一个或多个技术问题。
参考图1,系统100的实施例可包括两个或更多个子非均匀存储器访问(子-NUMA)集群(SNC)110、处理器核心120以及电路系统130,该电路系统130通信耦合至两个或更多个SNC 110和处理器核心120。电路系统130可被配置成用于根据初始化指定的存储器空间的请求中指示的SNC存储器分配策略(例如,请求随附的SNC策略提示)在两个或更多个SNC110中分配该指定的存储器空间。例如,系统100可包括用于存储指示的SNC存储器分配策略的寄存器140(例如,模型特定寄存器(model specific register,MSR))。替代地或附加地,电路系统130可被配置成用于基于触发初始化指定的存储器空间的请求的指令(例如,SNC策略提示指令)来确定指示的SNC存储器分配策略。
在一些实施例中,电路系统130可被进一步配置成用于利用指示的SNC存储器分配策略超控(override)两个或更多个SNC 110的默认存储器分配策略。例如,电路系统130可被配置成用于确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织,如果确定是,则分配要在两个或更多个SNC 110中的所有SNC 110之间被交织的指定的存储器空间。在一些实施例中,电路系统130可被配置成用于分配要以页粒度在两个或更多个SNC110中的所有SNC 110之间被交织的指定的存储器空间。替代地或附加地,电路系统130可被配置成用于分配要以块粒度在两个或更多个SNC 110中的所有SNC110之间被交织的指定的存储器空间。
电路系统130的实施例可以与任何有用的处理器或控制器集成。合适的处理器的非限制性示例包括核心990(图8B)、核心1102A-1102N(图10、图14)、处理器1210(图11)、协处理器1245(图11)、处理器1370(图12-图14)、处理器/协处理器1380(图12-图14)、协处理器1338(图12)、处理器1315(图12)、协处理器1520(图14)和/或处理器1614、1616(图15)。合适的控制器的非限制性示例包括(一个或多个)集成存储器控制器单元1114(图10)、GMCH1290(图11)、IMC 1372和1382(图12)、芯片组1390(图12和图13)、控制逻辑1472和1482(图13)、以及(一个或多个)互连单元1502(图14)。
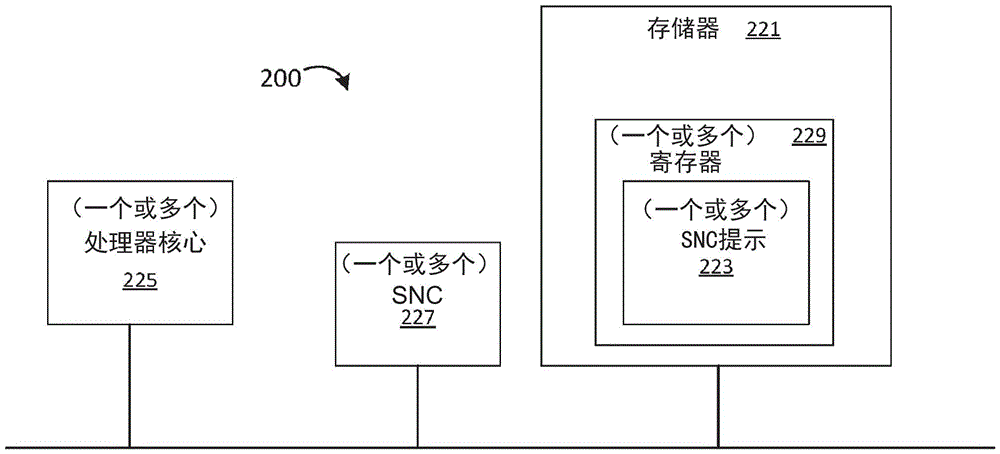
参考图2,系统200的实施例可包括:存储器221,用于存储与初始化数据的相应请求相关联的一个或多个SNC提示数据结构223;以及一个或多个处理器核心225,通信地耦合至存储器221,用于基于存储在(一个或多个)SNC提示数据结构223中的SNC提示值来在一个或多个SNC 227中分配存储器空间。例如,SNC提示可指示用于存储器空间的优选的SNC存储器分配策略。在一些实施例中,存储器221可包括用于存储(一个或多个)SNC提示数据结构223的(一个或多个)寄存器229。替代地或附加地,(一个或多个)处理器核心225可基于触发初始化数据的请求的指令(例如,SNC策略提示指令)来确定SNC提示。
在一些实施例中,(一个或多个)处理器核心225可利用SNC提示指示的优选的SNC存储器分配策略来超控用于(一个或多个)SNC 227的默认存储器分配策略。例如,如果SNC提示指示指定的存储器空间要被交织,则(例如,即使默认/当前存储器分配策略指示不交织)(一个或多个)处理器核心225分配要在所有的SNC 227之间被交织的指定的存储器空间。在一些实施例中,SNC提示可指示指定的存储器空间要以页粒度或块粒度在所有的SNC227之间被交织。在另一示例中,如果SNC提示指示指定的存储器空间要被放置在(一个或多个)SNC 227的单个节点中,则(例如,即使默认/当前存储器分配策略指示不放置)(一个或多个)处理器核心225将指定的存储器空间分配给接触数据的、SNC 227中的第一节点。
处理器核心225的实施例可以与任何有用的处理器或控制器集成。合适的处理器的非限制性示例包括核心990(图8B)、核心1102A-1102N(图10、图14)、处理器1210(图11)、协处理器1245(图11)、处理器1370(图12-图14)、处理器/协处理器1380(图12-图14)、协处理器1338(图12)、处理器1315(图12)、协处理器1520(图14)和/或处理器1614、1616(图15)。合适的控制器的非限制性示例包括(一个或多个)集成存储器控制器单元1114(图10)、GMCH1290(图11)、IMC 1372和1382(图12)、芯片组1390(图12和图13)、控制逻辑1472和1482(图13)、以及(一个或多个)互连单元1502(图14)。
为了改进共享数据在子NUMA聚类系统中的放置,一些实施例提供用于变量初始化的、指示要被应用于为该变量分配的存储器空间的SNC策略的一个或多个特定指令(例如,有时本文统称为SNC策略提示指令)。特定SNC策略提示指令的代表性实施例包括MOVSNCSHARE指令、VMOVSNCSHARE指令和TMOVSNCSHARE(例如,分别用于标量、高级向量扩展(advanced vector extension,AVX)和高级矩阵扩展(advanced matrixextension,AMX))。指令可以作为携载向硬件的、要以页或块粒度跨所有集群交织特定存储器空间的提示的存储操作被执行。有利的是,一些实施例使编程人员能够管理全局地共享数据。编程人员可以确保由所有集群共享的数据将在所有SNC缓存和存储器设备之间更均等地分布,同时仍然允许每个集群私有的数据保持在该集群的本地(例如,经由默认的最先接触策略),从而可能提高应用性能。
参考图3,服务器300的实施例包括支持SNC的处理器310。如图3所示,对于在逻辑上被分区为四个集群(例如,以SNC-4模式来组织,具有NUMA节点0到NUMA节点3)的系统存储器330(例如,DRAM),多个核心各自包括缓存代理(caching agent,CA)和最后一级缓存(last-level cache,LLC)的L3缓存。用户可以将每个软件线程固定到特定集群,并且如果数据被适当地管理,则LLC和DRAM访问等待时间和/或管芯上互连流量可能减少。
在SNC模式下,默认情况下,跨集群共享的数据被放置在最先接触数据的NUMA节点(例如,也称为集群)中。这可被称为最先接触存储器分配策略。以下是其中数组A在所有线程之间共享并且每个线程在其计算期间需要访问A的全部的并行伪代码的示例:
在上述示例中,数组A由主/主要线程使用常规的memset指令在并行部分之外分配和初始化。利用该常规指令,数组A将被放置在主线程的集群(例如,该集群的存储器通道和L3缓存)中。这种数据放置可导致两种效率低下:1)数据将不利用芯片的全部L3缓存容量,这导致与数据均匀跨所有集群均等地分布的情况相比更高的L3未命中率;以及2)对数组A的所有请求将仅去往芯片的L3切片和/或存储器控制器的四分之一(1/4),从而造成显著的管芯上互连拥塞。管芯上互连拥塞可能增加访问等待时间,并减少每个核心可以从L3缓存和系统存储器获得的有效带宽。
一些实施例可提供特定SNC策略提示指令,如下:
MOVSNCSHARE(mem,reg)
VMOVSNCSHARE(m512,zmm1)
VMOVSNCSHARE(m256,ymm1)
VMOVSNCSHARE(m128,xmm1)
TMOVSNCSHARE(sibmem,tmm1)
上述指令可用于变量初始化。例如,指令可被执行,以将数据从源操作对象(例如,reg、zmm1、ymm1、xmm1、tmm1)写入到目的地操作对象(例如,mem、m512、m256、m128、sibmem)中指定的(一个或多个)地址,并引导物理页/块以交织方式在所有集群之间被分配(例如,指令本身固有地为交织存储器分配策略提供SNC提示)。以下是使用VMOVSNCSHARE可能的固有属性来进行数据初始化的并行伪代码的示例:
在上述实施例中,替代常规的memset指令,数组A使用MOVSNCSHARE指令进行分配和初始化,即使默认存储器分配策略是最先接触存储器分配策略,该MOVSNCSHARE指令向硬件提供对用于数组A的存储器空间进行交织的提示。一些实施例可利用页交织和/或块交织。
页交织示例
对于页交织方法,一些实施例分配跨所有集群交织的物理页,这可能需要或受益于与操作系统(operating system,OS)的交互。例如,OS 340可以使用各种存储器分配策略,这些存储器分配策略包括本地节点策略(例如,LINUX中的“节点本地(NODE LOCAL)”)和交织策略(例如,LINUX中的“交织(INTERLEAVE)”)。在本地节点策略下,OS 340对来自执行的核心本地的存储器节点的页进行分配。在交织策略下,OS 340以轮询(round robin)方式对来自所有存储器节点的页进行分配。例如,常规LINUX系统在启动时使用交织作为LINUX内核分配的默认存储器策略。然而,当系统在SNC模式下运行时,节点本地策略是默认的存储器分配策略。
对于在SNC模式下运行的LINUX系统的实施例,针对使用SNC策略提示指令(例如,MOVSNCSHARE、VMOVSNCSHARE或TMOVSNCSHARE指令)接触的数据,节点本地策略被超控并且交织策略的使用被触发。当应用执行MOVSNCSHARE指令时,如果相对应的页表条目中的物理页尚未被分配,则内核将介入并找到未使用的物理页。在这个实施例中,代替于如节点本地策略中实现的只找到映射到核心的本地集群的未使用的物理页,OS 340替代地使用以轮询方式在NUMA节点上对页进行分配(例如,节点0、节点1、节点2、节点3、节点0……)的交织存储器策略。在一些实施例中,OS页错误处置程序350可被配置成用于检查触发页错误的指令,并且如果指令是SNC策略提示指令,则页错误处置程序350被配置成用于使用交织策略而不是节点本地策略来进行存储器分配。在一些实施例中(例如,如果检查触发指令被认为有问题),(一个或多个)执行的SNC策略提示指令可在递送页错误时使状态比特(例如,在型号特定寄存器(model specific register,MSR)中)置位,以将提示传递给OS 340。
在一些实施例中,代替于或附加于特定SNC策略提示指令,可以使用共享存储器位置或共享寄存器(例如,诸如MSR)将使用交织策略的提示传达给OS。例如,代替于将数据连同提示一起初始化的特定指令,软件可以利用用于向MSR写入期望的状态的指令(例如,WRMSR指令)来设置特定MSR的状态,以向OS 340指示软件正在开始初始化代码。然后,当初始化被完成时,软件可从MSR清除状态。在本实施例中,OS错误处置程序350可被配置成用于检查MSR而不是触发指令。如果相对应的MSR状态被设置,OS 340将利用交织策略来分配页。否则,OS 340将使用节点本地策略来进行页分配。
块交织示例
利用页交织的SNC中集群间共享数据管理的实施例可以以相当粗糙的粒度在集群中交织数据。带宽受限的应用可受益于利用块交织的SNC中集群间共享数据管理的实施例。块交织技术的实施例可允许数据以更精细的粒度(例如,以缓存行粒度)以交织方式跨所有集群被放置,并且可独立于页交织实施例。
例如,在LINUX中,存储器在代表存储器空间范围的区中进行管理。在SNC模式下,每个NUMA节点可以与一个或多个区相关联。在一些实施例中,OS被配置成用于分配专门用于集群间共享数据的区。当SNC策略提示指令触发页错误并OS去映射改页时,OS被给予将该页映射到集群间共享数据区的提示。一些实施例添加了用于记录集群间共享区的地址范围的附加硬件SNC范围寄存器。
根据SNC模式下系统的实施例,硬件将物理地址与SNC范围寄存器中的集群间共享数据地址范围进行比较,如果地址在该范围内,则硬件将使用全局散列函数(例如,类似于当不在SNC模式下时使用的全局散列函数)来确定在哪里映射数据。全局散列函数以缓存块粒度跨SNC交织数据。有利的是,与默认存储器分配策略相比,根据(例如,由提供的提示指示的)期望的SNC存储器分配策略进行块交织的实施例允许共享数据结构跨L3片均等地分布,可能减少L3缓存和/或存储器访问等待时间和管芯上互连流量拥塞。
OS支持示例
根据一些实施例,可以通过添加专用能力比特来枚举对SNC提示能力的支持。例如,专用能力比特可以由硬件通过CPUID指令中的附加能力比特来枚举。在一些实施例中,SNC提示能力可仅在某些处理器模式下(例如,在64比特操作中)可用。
在一些实施例中,可由系统软件使用通用寄存器或专用寄存器中(例如,CR4中或体系结构型号特定寄存器(MSR)中)的特定启用比特来启用SNC提示特征。或者,SNC提示的指令支持的可用性可以以软件已启用该特征为条件。例如,当SNC提示未被启用时,使用SNC提示的指令可触发错误。
在一些实施例中,硬件可以提供用于允许与SNC提示相关联的状态的快速保存/恢复的扩展。例如,硬件可以向XSAVE/XSTORE体系结构提供针对与SNC提示相关联的新状态组件和/或用于保存/恢复寄存器列表(例如,包括与SNC提示相关联的那些寄存器)的特定指令的扩展。
根据一些实施例,操作系统可以以各种方式管理SNC提示。例如,OS可以选择只启用一种模式或提供API来允许应用选择其需要的模式。两个示例状态管理策略包括全局SNC提示模式和虚拟SNC提示模式。
图4图示硬件600的实施例,该硬件600用于处理诸如SNC策略提示指令(例如,MOVSNCSHARE、VMOVSNCSHARE、TMOVSNCSHARE等)之类的指令。如所示,存储装置643存储要被执行的一个或多个SNC策略提示指令641。解码电路系统645可被配置成用于对单个指令进行解码,该单个指令包括用于操作码的字段,并且执行电路系统649用于根据操作码来执行经解码的指令。
SNC策略提示指令641中的一个SNC策略提示指令641由解码电路系统645接收。例如,解码电路系统645从取得(fetch)逻辑/电路系统接收该指令。指令包括用于操作码、第一源、以及目的地的字段。在一些实施例中,源和目的地是寄存器,并且在其他实施例中,源和目的地中的一个或多个是存储器位置。在一些实施例中,操作码详述要执行哪个SNC存储操作,以及对于该SNC存储操作而言优选的SNC存储器分配策略是什么。
解码电路系统645将指令解码成一个或多个操作。在一些实施例中,这种解码包括生成要被执行电路系统(诸如,执行电路系统649)执行的多个微操作。解码电路系统645也对指令前缀进行解码。
在一些实施例中,寄存器重命名、寄存器分配和/或调度电路系统647提供用于以下各项中的一项或多项的功能:1)将逻辑操作对象值重命名为物理操作对象值(例如,一些实施例中的寄存器别名表);2)向经解码的指令分配状态比特和标志;以及3)从指令池调度经解码的指令以供在执行电路系统上执行(例如,在一些实施例中,使用预留站)。
寄存器(寄存器堆)和/或存储器648将数据存储为要由执行电路系统649对其进行操作的、指令的操作对象。示例性寄存器类型包括紧缩(packed)数据寄存器、通用寄存器和浮点寄存器。
执行电路系统649执行经解码的指令。示例性详述的执行电路系统如图8B等所示。经解码的指令的执行引起执行电路系统649根据操作码执行经解码的指令。例如,对于一些SNC策略提示指令,经解码的指令的执行引起执行电路系统649向支持(一个或多个)SNC的硬件和/或软件提供指示的SNC存储器分配策略(例如,SNC提示)。在一些实施例中,操作码固有地指定指示的SNC存储器分配策略。替代地或附加地,可进一步引起执行电路系统649根据SNC策略提示指令操作码执行经解码的指令,以将信息存储在与指示的SNC存储器分配策略相对应的寄存器(例如,MSR)中。
在一些实施例中,单个指令进一步包括用于源操作对象的标识符的字段和用于目的地操作对象的标识符的字段,并且执行电路系统649进一步用于:根据操作码执行经解码的指令,以从由源操作对象指示的位置取回源信息;以及根据指示的SNC存储器分配策略将源信息存储到由目的地操作对象指示的位置。例如,执行电路系统649可以进一步用于:根据操作码来执行经解码的指令,以根据指示的SNC存储器分配策略在两个或更多个SNC中分配由目的地操作对象指定的存储器空间。在一些实施例中,执行电路系统649进一步用于:根据操作码来执行经解码的指令,以利用指示的SNC存储器分配策略来超控用于两个或更多个SNC的指定的存储器空间的默认存储器分配策略。
在一些实施例中,执行电路系统649可进一步用于:根据操作码来执行经解码的指令,以确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织;并且如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。例如,执行电路系统649可以进一步用于:根据操作码来执行经解码的指令,以分配要以页粒度在所有两个或更多个SNC之间被交织的指定的存储器空间。替代地或附加地,执行电路系统649可以进一步用于:根据操作码来执行经解码的指令,以分配要以块粒度在所有两个或更多个SNC之间被交织的指定的存储器空间。
在一些实施例中,引退/写回电路系统653在体系结构上将目的地寄存器提交到寄存器或存储器648中,并且引退指令。
图5图示由处理器执行以处理SNC策略提示指令的方法760的实施例。例如,如图8B中所示的处理器核心、如下文详述的管线等执行该方法。
在761处,取得指令。例如,取得SNC策略提示指令。SNC策略提示指令包括用于操作码、目的地操作对象和源操作对象中的一者或多者的字段。在一些实施例中,从指令缓存取得指令。源操作对象和目的地操作对象是紧缩数据。SNC策略提示指令的操作码指示优选的SNC存储器分配策略。SNC策略提示指令可进一步指示要执行哪个存储操作。
在763处,对取得的指令进行解码。例如,由诸如本文中详述的解码电路系统之类的解码电路系统对所取得的SNC策略提示指令进行解码。
在765处,取回与经解码的指令的源操作对象相关联的数据值,并且调度经解码的指令的执行。例如,当源操作对象中的一个或多个源操作对象是存储器操作对象时,从所指示的存储器位置取回数据。
在767处,由诸如本文中详述的执行电路系统(硬件)之类的执行电路系统(硬件)执行经解码的指令。对于SNC策略提示指令,执行将引起执行电路系统根据操作码来提供指示的SNC存储器分配策略(例如,针对支持(一个或多个)SNC的硬件和/或软件的SNC提示)。
在一些实施例中,在769处,提交或引退指令。
在一些实施例中,在771处,经解码的SNC策略提示指令的执行将使得执行电路系统将信息存储在与指示的SNC存储器分配策略相对应的寄存器中。在一些实施例中,在773处,指令具有用于目的地操作对象和源操作对象的字段,并且操作码固有地指定指示的SNC存储器分配策略。例如,在775处,经解码的SNC策略提示指令的执行可使得执行电路系统:从由源操作对象指示的位置取回源信息;以及根据指示的SNC存储器分配策略将源信息存储到由目的地操作对象指示的位置。
在一些实施例中,在777处,经解码的SNC策略提示指令的执行可使得执行电路系统根据指示的SNC存储器分配策略在两个或更多个SNC中分配由目的地操作对象指定的存储器空间。例如,在779处,经解码的SNC策略提示指令的执行可使得执行电路系统利用指示的SNC存储器分配策略超控用于两个或更多个SNC的指定的存储器空间的默认存储器分配策略。在一些实施例中,在781处,经解码的SNC策略提示指令的执行可使得执行电路系统确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织,并且如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。例如,在783处,经解码的SNC策略提示指令的执行可使得执行电路系统分配要以页粒度或块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
图6至图7图示由处理器执行以使用仿真或二进制转译来处理SNC策略提示指令的方法850的实施例。例如,如图8B中所示的处理器核心、如下文详述的管线等执行该方法。
在851处,取得指令。例如,取得SNC策略提示指令。SNC策略提示指令包括用于操作码、目的地操作对象和源操作对象中的一者或多者的字段。在一些实施例中,从指令缓存取得该指令。源操作对象和目的地操作对象是紧缩数据。SNC策略提示指令的操作码可指示优选的SNC存储器分配策略。SNC策略提示指令可进一步指示要执行哪个存储操作。
在852处,将第一指令集的所取得的指令转译为第二指令集的一个或多个指令。
在853处,对第二指令集的一个或多个经转译的指令进行解码。在一些实施例中,转译和解码被合并。例如,由诸如本文中详述的解码电路系统之类的解码电路系统对SNC策略提示指令进行解码。
在855处,取回与经解码的指令的源操作对象相关联的数据值,并且调度经解码的指令的执行。例如,当源操作对象中的一个或多个源操作对象是存储器操作对象时,从所指示的存储器位置取回数据。
在857处,由诸如本文中详述的执行电路系统(硬件)之类的执行电路系统(硬件)执行经解码的指令。对于SNC策略提示指令,执行将使得执行电路系统根据操作码来提供指示的SNC存储器分配策略(例如,针对支持(一个或多个)SNC的硬件和/或软件的SNC提示)。
在一些实施例中,在859处,提交或引退指令。
在一些实施例中,在861处,经解码的SNC策略提示指令的执行将使得执行电路系统将信息存储在与指示的SNC存储器分配策略相对应的寄存器中。在一些实施例中,在863处,指令具有用于目的地操作对象和源操作对象的字段,并且操作码固有地指定指示的SNC存储器分配策略。例如,在865处,经解码的SNC策略提示指令的执行可使得执行电路系统:从由源操作对象指示的位置取回源信息;以及根据指示的SNC存储器分配策略将源信息存储到由目的地操作对象指示的位置。
在一些实施例中,在867处,经解码的SNC策略提示指令的执行可使得执行电路根据指示的SNC存储器分配策略在两个或更多个SNC中分配由目的地操作对象指定的存储器空间。例如,在869处,经解码的SNC策略提示指令的执行可使得执行电路系统利用指示的SNC存储器分配策略来超控用于两个或更多个SNC的指定的存储器空间的默认存储器分配策略。在一些实施例中,在871处,经解码的SNC策略提示指令的执行可使得执行电路系统:确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织,并且如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。例如,在873处,经解码的SNC策略提示指令的执行可使得执行电路系统分配要以页粒度或块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
本领域技术人员将领会,各种设备可受益于前述实施例。以下示例性核心体系结构、处理器和计算机体系结构是可有益地包含本文中描述的技术的实施例的设备的非限制性示例。
示例性核心体系结构、处理器和计算机体系结构
处理器核心能以不同方式、出于不同的目的、在不同的处理器中实现。例如,此类核心的实现方式可以包括:1)旨在用于通用计算的通用有序核心;2)旨在用于通用计算的高性能通用乱序核心;3)旨在主要用于图形和/或科学(吞吐量)计算的专用核心。不同处理器的实现可包括:1)CPU,其包括旨在用于通用计算的一个或多个通用有序核心和/或旨在用于通用计算的一个或多个通用乱序核心;以及2)协处理器,其包括旨在主要用于图形和/或科学(吞吐量)的一个或多个专用核心。此类不同的处理器导致不同的计算机系统体系结构,这些计算机系统体系结构可包括:1)在与CPU分开的芯片上的协处理器;2)在与CPU相同的封装中但在分开的管芯上的协处理器;3)与CPU在相同管芯上的协处理器(在该情况下,此类协处理器有时被称为专用逻辑或被称为专用核心,该专用逻辑诸如,集成图形和/或科学(吞吐量)逻辑);以及4)片上系统,其可以将所描述的CPU(有时被称为(一个或多个)应用核心或(一个或多个)应用处理器)、以上描述的协处理器和附加功能包括在同一管芯上。接着描述示例性核心体系结构,随后描述示例性处理器和计算机体系结构。
示例性核心体系结构
有序和乱序核心框图
图8A是图示根据本发明的各实施例的示例性有序管线和示例性的寄存器重命名的乱序发出/执行管线两者的框图。图8B是示出根据本发明的各实施例的要包括在处理器中的有序体系结构核心的示例性实施例和示例性的寄存器重命名的乱序发出/执行体系结构核心的框图。图8A-图8B中的实线框图示有序管线和有序核心,而任选增加的虚线框图示寄存器重命名的、乱序发出/执行管线和核心。考虑到有序方面是乱序方面的子集,将描述乱序方面。
在图8A中,处理器管线900包括取得(fetch)阶段902、长度解码阶段904、解码阶段906、分配阶段908、重命名阶段910、调度(也被称为调遣或发出)阶段912、寄存器读取/存储器读取阶段914、执行阶段916、写回/存储器写入阶段918、异常处置阶段922和提交阶段924。
图8B示出处理器核心990,该处理器核心990包括前端单元930,该前端单元930耦合到执行引擎单元950,并且前端单元930和执行引擎单元950两者都耦合到存储器单元970。核心990可以是精简指令集计算(reducedinstruction set computing,RISC)核心、复杂指令集计算(complex instruction setcomputing,CISC)核心、超长指令字(very longinstruction word,VLIW)核心、或混合或替代性核心类型。作为又一选项,核心990可以是专用核心,诸如例如,网络或通信核心、压缩引擎、协处理器核心、通用计算图形处理单元(general purpose computing graphics processing unit,GPGPU)核心、图形核心,等等。
前端单元930包括分支预测单元932,该分支预测单元932耦合到指令缓存单元934,该指令缓存单元934耦合到指令转译后备缓冲器(translationlookaside buffer,TLB)936,该指令转译后备缓冲器936耦合到指令取得单元938,该指令取得单元938耦合到解码单元940。解码单元940(或解码器)可对指令解码,并且生成从原始指令解码出的、或以其他方式反映原始指令的、或从原始指令导出的一个或多个微操作、微代码进入点、微指令、其他指令、或其他控制信号作为输出。解码单元940可使用各种不同的机制来实现。合适机制的示例包括但不限于,查找表、硬件实现、可编程逻辑阵列(programmablelogicarray,PLA)、微代码只读存储器(read only memory,ROM)等。在一个实施例中,核心990包括存储用于某些宏指令的微代码的微代码ROM或其他介质(例如,在解码单元940中,或以其他方式在前端单元930内)。解码单元940耦合到执行引擎单元950中的重命名/分配器单元952。
执行引擎单元950包括重命名/分配器单元952,该重命名/分配器单元952耦合到引退单元954和一个或多个调度器单元的集合956。(一个或多个)调度器单元956表示任何数量的不同调度器,包括预留站、中央指令窗等。(一个或多个)调度器单元956耦合到(一个或多个)物理寄存器堆单元958。(一个或多个)物理寄存器堆单元958中的每一个物理寄存器堆单元表示一个或多个物理寄存器堆,其中不同的物理寄存器堆存储一种或多种不同的数据类型,诸如,标量整数、标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点,状态(例如,作为要执行的下一个指令的地址的指令指针)等等。在一个实施例中,(一个或多个)物理寄存器堆单元958包括向量寄存器单元、写掩码寄存器单元和标量寄存器单元。这些寄存器单元可以提供体系结构向量寄存器、向量掩码寄存器和通用寄存器。(一个或多个)物理寄存器堆单元958由引退单元954重叠,以图示可实现寄存器重命名和乱序执行的各种方式(例如,使用(一个或多个)重排序缓冲器和(一个或多个)引退寄存器堆;使用(一个或多个)未来的堆、(一个或多个)历史缓冲器、(一个或多个)引退寄存器堆;使用寄存器图谱和寄存器池,等等)。引退单元954和(一个或多个)物理寄存器堆单元958耦合到(一个或多个)执行集群960。(一个或多个)执行集群960包括一个或多个执行单元的集合962以及一个或多个存储器访问单元的集合964。执行单元962可执行各种操作(例如,移位、加法、减法、乘法)并可对各种数据类型(例如,标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点)执行。尽管一些实施例可以包括专用于特定功能或功能集合的多个执行单元,但是其他实施例可包括仅一个执行单元或全都执行所有功能的多个执行单元。(一个或多个)调度器单元956、(一个或多个)物理寄存器堆单元958和(一个或多个)执行集群960示出为可能有多个,因为某些实施例为某些类型的数据/操作创建分开的管线(例如,标量整数管线、标量浮点/紧缩整数/紧缩浮点/向量整数/向量浮点管线,和/或各自具有其自身的调度器单元、(一个或多个)物理寄存器堆单元和/或执行集群的存储器访问管线——并且在分开的存储器访问管线的情况下,实现其中仅该管线的执行集群具有(一个或多个)存储器访问单元964的某些实施例)。还应当理解,在使用分开的管线的情况下,这些管线中的一个或多个可以是乱序发出/执行,并且其余管线可以是有序的。
存储器访问单元的集合964耦合到存储器单元970,该存储器单元970包括数据TLB单元972,该数据TLB单元972耦合到数据缓存单元974,该数据缓存单元974耦合到第二级(L2)缓存单元976。在一个示例性实施例中,存储器访问单元964可包括加载单元、存储地址单元和存储数据单元,其中的每一个均耦合到存储器单元970中的数据TLB单元972。指令缓存单元934还耦合到存储器单元970中的第二级(L2)缓存单元976。L2缓存单元976耦合到一个或多个其他级别的缓存,并最终耦合到主存储器。
作为示例,示例性寄存器重命名的乱序发出/执行核心体系结构可如下所述地实现管线900:1)指令取得938执行取得阶段902和长度解码阶段904;2)解码单元940执行解码阶段906;3)重命名/分配器单元952执行分配阶段908和重命名阶段910;4)(一个或多个)调度器单元956执行调度阶段912;5)(一个或多个)物理寄存器堆单元958和存储器单元970执行寄存器读取/存储器读取阶段914;执行集群960执行执行阶段916;6)存储器单元970和(一个或多个)物理寄存器堆单元958执行写回/存储器写入阶段918;7)各单元可牵涉到异常处置阶段922;以及8)引退单元954和(一个或多个)物理寄存器堆单元958执行提交阶段924。
核心990可支持一个或多个指令集(例如,x86指令集(具有已与较新版本一起添加的一些扩展);加利福尼亚州桑尼维尔市的MIPS技术公司的MIPS指令集;加利福尼亚州桑尼维尔市的ARM控股公司的ARM指令集(具有诸如NEON的可选的附加扩展)),其中包括本文中描述的(一个或多个)指令。在一个实施例中,核心990包括用于支持紧缩数据指令集扩展(例如,AVX1、AVX2)的逻辑,由此允许使用紧缩数据来执行由许多多媒体应用使用的操作。
应当理解,核心可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,各种方式包括时分多线程化、同时多线程化(其中单个物理核心为物理核心正在同时多线程化的线程中的每一个线程提供逻辑核心)、或其组合(例如,时分取得和解码以及此后的诸如
尽管在乱序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序体系结构中使用寄存器重命名。尽管所图示的处理器的实施例还包括分开的指令和数据缓存单元934/974以及共享的L2缓存单元976,但是替代实施例可以具有用于指令和数据两者的单个内部缓存,诸如例如,第一级(L1)内部缓存或多个级别的内部缓存。在一些实施例中,该系统可包括内部缓存和在核心和/或处理器外部的外部缓存的组合。或者,所有缓存都可以在核心和/或处理器的外部。
具体的示例性有序核心体系结构
图9A-图9B图示更具体的示例性有序核心体系结构的框图,该核心将是芯片中的若干逻辑块(包括相同类型和/或不同类型的其他核心)中的一个逻辑块。取决于应用,逻辑块通过高带宽互连网络(例如,环形网络)与一些固定的功能逻辑、存储器I/O接口和其他必要的I/O逻辑进行通信。
图9A是根据本发明的实施例的单个处理器核心以及它至管芯上互连网络1002的连接及其第二级(L2)缓存的本地子集1004的框图。在一个实施例中,指令解码器1000支持具有紧缩数据指令集扩展的x86指令集。L1缓存1006允许对进入标量和向量单元中的、对缓存存储器的低等待时间访问。尽管在一个实施例中(为了简化设计),标量单元1008和向量单元1010使用分开的寄存器集合(分别为标量寄存器1012和向量寄存器1014),并且在这些寄存器之间传输的数据被写入到存储器,并随后从第一级(L1)缓存1006读回,但是本发明的替代实施例可以使用不同的方法(例如,使用单个寄存器集合或包括允许数据在这两个寄存器堆之间传输而无需被写入和读回的通信路径)。
L2缓存的本地子集1004是全局L2缓存的一部分,该全局L2缓存被划分成多个分开的本地子集,每个处理器核心一个本地子集。每个处理器核心具有到其自身的L2缓存的本地子集1004的直接访问路径。由处理器核心读取的数据被存储在其L2缓存子集1004中,并且可以与其他处理器核心访问其自身的本地L2缓存子集并行地被快速访问。由处理器核心写入的数据被存储在其自身的L2缓存子集1004中,并在必要的情况下从其他子集转储清除。环形网络确保共享数据的一致性。环形网络是双向的,以允许诸如处理器核心、L2缓存和其他逻辑块之类的代理在芯片内彼此通信。每个环形数据路径为每个方向1012比特宽。
图9B是根据本发明的实施例的图9A中的处理器核心的一部分的展开图。图9B包括L1缓存1006的L1数据缓存1006A部分,以及关于向量单元1010和向量寄存器1014的更多细节。具体地,向量单元1010是16宽向量处理单元(vector processing unit,VPU)(见16宽ALU 1028),该单元执行整数、单精度浮点以及双精度浮点指令中的一个或多个。该VPU通过混合单元1020支持对寄存器输入的混合,通过数值转换单元1022A-B支持数值转换,并且利用复制单元1024支持对存储器输入的复制。写掩码寄存器1026允许断言所得的向量写入。
图10是根据本发明的实施例的可具有多于一个的核心、可具有集成存储器控制器、以及可具有集成图形器件的处理器1100的框图。图10中的实线框图示具有单个核心1102A、系统代理1110、一个或多个总线控制器单元的集合1116的处理器1100,而虚线框的可选增加图示具有多个核心1102A-N、系统代理单元1110中的一个或多个集成存储器控制器单元的集合1114以及专用逻辑1108的替代处理器1100。
因此,处理器1100的不同实现方式可包括:1)CPU,其中专用逻辑1108是集成图形器件和/或科学(吞吐量)逻辑(其可包括一个或多个核心),并且核心1102A-N是一个或多个通用核心(例如,通用有序核心、通用乱序核心、这两者的组合);2)协处理器,其中核心1102A-N是旨在主要用于图形和/或科学(吞吐量)的大量专用核心;以及3)协处理器,其中核心1102A-N是大量通用有序核心。因此,处理器1100可以是通用处理器、协处理器或专用处理器,诸如例如,网络或通信处理器、压缩引擎、图形处理器、GPGPU(general purposegraphics processing unit,通用图形处理单元)、高吞吐量的集成众核心(manyintegrated core,MIC)协处理器(包括30个或更多核心)、嵌入式处理器,等等。该处理器可以被实现在一个或多个芯片上。处理器1100可以是一个或多个基板的一部分,和/或可使用多种工艺技术(诸如例如,BiCMOS、CMOS、或NMOS)中的任何技术被实现在一个或多个基板上。
存储器层次体系包括核心1102A-N内的一个或多个级别的相应缓存1104A-N、一个或多个共享缓存单元的集合1106、以及耦合到集成存储器控制器单元的集合1114的外部存储器(未示出)。共享缓存单元的集合1106可包括一个或多个中间级别的缓存,诸如,第二级(L2)、第三级(L3)、第四级(L4)或其他级别的缓存、最后一级缓存(last level cache,LLC)和/或以上各项的组合。虽然在一个实施例中,基于环的互连单元1112将集成图形逻辑1108、共享缓存单元的集合1106以及系统代理单元1110/(一个或多个)集成存储器控制器单元1114互连,但是替代实施例可使用任何数量的公知技术来互连此类单元。在一个实施例中,在一个或多个缓存单元1106与核心1102A-N之间维持一致性。
在一些实施例中,核心1102A-N中的一个或多个能够实现多线程化。系统代理1110包括协调并操作核心1102A-N的那些组件。系统代理单元1110可包括例如功率控制单元(power control unit,PCU)和显示单元。PCU可以是对核心1102A-N以及集成图形逻辑1108的功率状态进行调节所需的逻辑和组件,或可包括这些逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核心1102A-N在体系结构指令集方面可以是同构的或异构的;即,核心1102A-N中的两个或更多个核心可能能够执行相同的指令集,而其他核心可能能够执行该指令集的仅仅子集或不同的指令集。
示例性计算机体系结构
图11-图14是示例性计算机体系结构的框图。本领域中已知的对膝上型电脑、桌面型电脑、手持PC、个人数字助理、工程工作站、服务器、网络设备、网络中枢、交换机、嵌入式处理器、数字信号处理器(digital signalprocessor,DSP)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般地,能够包含如本文中所公开的处理器和/或其他执行逻辑的各种各样的系统或电子设备一般都是合适的。
现在参考图11,所示出的是根据本发明一个实施例的系统1200的框图。系统1200可以包括一个或多个处理器1210、1215,这些处理器耦合到控制器中枢1220。在一个实施例中,控制器中枢1220包括图形存储器控制器中枢(graphics memory controller hub,GMCH)1290和输入/输出中枢(Input/Output Hub,IOH)1250(其可以在分开的芯片上);GMCH1290包括存储器和图形控制器,存储器1240和协处理器1245耦合到该存储器和图形控制器;IOH 1250将输入/输出(input/output,I/O)设备1260耦合到GMCH 1290。或者,存储器和图形控制器中的一个或这两者被集成在(如本文中所描述的)处理器内,存储器1240和协处理器1245直接耦合到处理器1210,并且控制器中枢1220与IOH 1250处于单个芯片中。
附加的处理器1215的可选性在图11中通过虚线来表示。每一处理器1210、1215可包括本文中描述的处理核心中的一个或多个,并且可以是处理器1100的某一版本。
存储器1240可以是例如动态随机存取存储器(dynamic randomaccess memory,DRAM)、相变存储器(phase change memory,PCM)或这两者的组合。对于至少一个实施例,控制器中枢1220经由诸如前端总线(frontsidebus,FSB)之类的多分支总线、诸如快速路径互连(QuickPath Interconnect,QPI)之类的点到点接口、或者类似的连接1295来与(一个或多个)处理器1210、1215进行通信。
在一个实施例中,协处理器1245是专用处理器,诸如例如,高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、嵌入式处理器,等等。在一个实施例中,控制器中枢1220可以包括集成图形加速器。
在物理资源1210、1215之间可以存在包括体系结构、微体系结构、热、功耗特性等一系列品质度量方面的各种差异。
在一个实施例中,处理器1210执行控制一般类型的数据处理操作的指令。嵌入在这些指令内的可以是协处理器指令。处理器1210将这些协处理器指令识别为具有应当由附连的协处理器1245执行的类型。因此,处理器1210在协处理器总线或者其他互连上将这些协处理器指令(或者表示协处理器指令的控制信号)发出到协处理器1245。(一个或多个)协处理器1245接受并执行所接收的协处理器指令。
现在参见图12,所示出的是根据本发明的实施例的第一更具体的示例性系统1300的框图。如图12中所示,多处理器系统1300是点到点互连系统,并且包括经由点到点互连1350耦合的第一处理器1370和第二处理器1380。处理器1370和1380中的每一个都可以是处理器1100的某一版本。在本发明的一个实施例中,处理器1370和1380分别是处理器1210和1215,而协处理器1338是协处理器1245。在另一实施例中,处理器1370和1380分别是处理器1210和协处理器1245。
处理器1370和1380示出为分别包括集成存储器控制器(integrated memorycontroller,IMC)单元1372和1382。处理器1370还包括作为其总线控制器单元的一部分的点到点(point-to-point,P-P)接口1376和1378;类似地,第二处理器1380包括P-P接口1386和1388。处理器1370、1380可以经由使用点到点(P-P)接口电路1378、1388的P-P接口1350来交换信息。如图12中所示,IMC 1372和1382将处理器耦合到相应的存储器,即存储器1332和存储器1334,这些存储器可以是本地附连到相应处理器的主存储器的部分。
处理器1370、1380可各自经由使用点到点接口电路1376、1394、1386、1398的各个P-P接口1352、1354来与芯片组1390交换信息。芯片组1390可以可选地经由高性能接口1339和接口1392来与协处理器1338交换信息。在一个实施例中,协处理器1338是专用处理器,诸如例如,高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、嵌入式处理器,等等。
共享缓存(未示出)可被包括在任一处理器中,或在这两个处理器的外部但经由P-P互连与这些处理器连接,使得如果处理器被置于低功率模式,则任一个或这两个处理器的本地缓存信息可被存储在共享缓存中。
芯片组1390可以经由接口1396耦合到第一总线1316。在一个实施例中,第一总线1316可以是外围组件互连(Peripheral Component Interconnect,PCI)总线或诸如PCI快速(PCI Express)总线或另一第三代I/O互连总线之类的总线,但是本发明的范围不限于此。
如图12中所示,各种I/O设备1314可连同总线桥1318一起耦合到第一总线1316,该总线桥1318将第一总线1316耦合到第二总线1320。在一个实施例中,诸如协处理器、高吞吐量MIC处理器、GPGPU、加速器(诸如例如,图形加速器或数字信号处理(DSP)单元)、现场可编程门阵列或任何其他处理器的一个或多个附加处理器1315耦合到第一总线1316。在一个实施例中,第二总线1320可以是低引脚数(low pin count,LPC)总线。在一个实施例中,各种设备可耦合到第二总线1320,这些设备包括例如键盘和/或鼠标1322、通信设备1327以及存储单元1328,该存储单元1328诸如可包括指令/代码和数据1330的盘驱动器或者其他大容量存储设备。此外,音频I/O 1324可以被耦合到第二总线1320。注意,其他体系结构是可能的。例如,代替图12的点到点体系结构,系统可以实现多分支总线或其他此类体系结构。
现在参考图13,示出的是根据本发明的实施例的第二更具体的示例性系统1400的框图。图12和13中的类似元件使用类似的附图标记,并且从图13中省略了图12的某些方面以避免混淆图13的其他方面。
图13图示处理器1370、1380可分别包括集成存储器和I/O控制逻辑(“controllogic,CL”)1472和1482。因此,CL 1472、1482包括集成存储器控制器单元,并包括I/O控制逻辑。图13图示不仅存储器1332、1334耦合到CL 1472、1482,而且I/O设备1414也耦合到控制逻辑1472、1482。传统I/O设备1415被耦合到芯片组1390。
现在参考图14,示出的是根据本发明的实施例的SoC 1500的框图。图10中的类似要素使用类似的附图标记。另外,虚线框是更先进的SoC上的可选的特征。在图14中,(一个或多个)互连单元1502被耦合到:应用处理器1510,其包括一个或多个核心的集合1102A-N的集合以及(一个或多个)共享缓存单元1106;系统代理单元1110;(一个或多个)总线控制器单元1116;(一个或多个)集成存储器控制器单元1114;一个或多个协处理器的集合1520,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(static random access memory,SRAM)单元1530;直接存储器访问(direct memoryaccess,DMA)单元1532;以及用于耦合到一个或多个外部显示器的显示单元1540。在一个实施例中,(一个或多个)协处理器1520包括专用处理器,诸如例如,网络或通信处理器、压缩引擎、GPGPU、高吞吐量MIC处理器、或嵌入式处理器,等等。
本文公开的机制的各实施例可以被实现在硬件、软件、固件或此类实现方式的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
可将程序代码(诸如,图12中图示的代码1330)应用于输入指令,以执行本文中描述的功能并生成输出信息。可以按已知方式将输出信息应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有处理器的任何系统,该处理器诸如例如,数字信号处理器(DSP)、微控制器、专用集成电路(application specific integrated circuit,ASIC)或微处理器。
程序代码可以用高级的面向过程的编程语言或面向对象的编程语言来实现,以便与处理系统通信。如果需要,也可用汇编语言或机器语言来实现程序代码。事实上,本文中描述的机制不限于任何特定的编程语言的范围。在任何情况下,该语言可以是编译语言或解释语言。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的表示性指令来实现,该指令表示处理器中的各种逻辑,该指令在被机器读取时使得该机器制造用于执行本文中所述的技术的逻辑。被称为“IP核心”的此类表示可以被存储在有形的机器可读介质上,并可被供应给各个客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
此类机器可读存储介质可以包括但不限于通过机器或设备制造或形成的制品的非暂态、有形布置,其包括存储介质,诸如硬盘;任何其他类型的盘,包括软盘、光盘、致密盘只读存储器(compact disk read-only memory,CD-ROM)、可重写致密盘(compack diskrewritable,CD-RW)以及磁光盘;半导体器件,诸如,只读存储器(ROM)、诸如动态随机存取存储器(dynamic randomaccess memory,DRAM)和静态随机存取存储器(static randomaccess memory,SRAM)的随机存取存储器(random access memory,RAM)、可擦除可编程只读存储器(erasable programmable read-only memories,EPROM)、闪存、电可擦除可编程只读存储器(electrically erasable programmable read-only memory,EEPROM);相变存储器(phase change memory,PCM);磁卡或光卡;或适于存储电子指令的任何其他类型的介质。
因此,本发明的实施例还包括非暂态的有形机器可读介质,该介质包含指令或包含设计数据,诸如硬件描述语言(Hardware DescriptionLanguage,HDL),它定义本文中描述的结构、电路、装置、处理器和/或系统特征。这些实施例也可被称为程序产品。
仿真(包括二进制转译、代码变形等)
在一些情况下,指令转换器可用于将指令从源指令集转换至目标指令集。例如,指令转换器可以将指令转译(例如,使用静态二进制转译、包括动态编译的动态二进制转译)、变形、仿真或以其他方式转换成要由核心处理的一个或多个其他指令。指令转换器可以用软件、硬件、固件、或其组合来实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上且部分在处理器外。
图15是根据本发明的实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所图示的实施例中,指令转换器是软件指令转换器,但替代地,该指令转换器可以用软件、固件、硬件或其各种组合来实现。图15示出可使用x86编译器1604来编译高级语言1602形式的程序,以生成可由具有至少一个x86指令集核心的处理器1616原生执行的x86二进制代码1606。具有至少一个x86指令集核心的处理器1616表示通过兼容地执行或以其他方式执行以下各项来执行与具有至少一个x86指令集核心的英特尔处理器基本相同的功能的任何处理器:1)英特尔x86指令集核心的指令集的实质部分,或2)目标为在具有至少一个x86指令集核心的英特尔处理器上运行以便取得与具有至少一个x86指令集核心的英特尔处理器基本相同的结果的应用或其他软件的目标代码版本。x86编译器1604表示可操作用于生成x86二进制代码1606(例如,目标代码)的编译器,该二进制代码可通过或不通过附加的链接处理在具有至少一个x86指令集核心的处理器1616上执行。类似地,图15示出可以使用替代性指令集编译器1608来编译高级语言1602形式的程序,以生成可以由没有至少一个x86指令集核心的处理器1614(例如,具有执行加利福尼亚州桑尼维尔市的MIPS技术公司的MIPS指令集、和/或执行加利福尼亚州桑尼维尔市的ARM控股公司的ARM指令集的核心的处理器)原生执行的替代性指令集二进制代码1610。指令转换器1612用于将x86二进制代码1606转换成可以由没有x86指令集核心的处理器1614原生执行的代码。该转换后的代码不大可能与替代性指令集二进制代码1610相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作,并且由来自替代指令集的指令构成。因此,指令转换器1612通过仿真、模拟或任何其他过程来表示允许没有x86指令集处理器或核心的处理器或其他电子设备执行x86二进制代码1606的软件、固件、硬件或其组合。
附加注解与示例
示例1包括一种系统,该系统包括:两个或更多个子非均匀存储器访问集群(SNC);处理器核心;以及电路系统,该电路系统通信地耦合至两个或更多个SNC和处理器核心,该电路系统用于根据从对指定的存储器空间进行初始化的请求指示的SNC存储器分配策略,在两个或更多个SNC中分配指定的存储器空间。
示例2包括示例1的系统,进一步包括用于存储指示的SNC存储器分配策略的寄存器。
示例3包括示例1至2中的任一项的系统,其中电路系统进一步用于基于触发对指定的存储器空间进行初始化的请求的指令来确定指示的SNC存储器分配策略。
示例4包括示例1至3中的任一项的系统,其中电路系统进一步用于利用指示的SNC存储器分配策略来超控用于两个或更多个SNC的默认存储器分配策略。
示例5包括示例1至4中的任一项的系统,其中电路系统进一步用于:确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织;以及如果确定为是,则分配在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例6包括示例5的系统,其中电路系统进一步用于分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例7包括示例5至6中的任一项的系统,其中电路系统进一步用于分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例8包括一种装置,该装置包括:解码电路系统,用于对单个指令进行解码,该单个指令包括用于操作码的字段;以及执行电路系统,用于根据操作码来执行经解码的指令,以提供指示的子非均匀存储器访问集群(SNC)存储器分配策略。
示例9包括示例8的装置,其中执行电路系统进一步用于根据操作码来执行经解码的指令,以进行:将信息存储在与指示的SNC存储器分配策略相对应的寄存器中。
示例10包括示例8至9中的任一项的装置,其中操作码固有地指定指示的SNC存储器分配策略。
示例11包括示例10的装置,其中单个指令进一步包括用于源操作对象的标识符的字段和用于目的地操作对象的标识符的字段,并且其中执行电路系统进一步用于根据操作码来执行经解码的指令以进行:从由源操作对象指示的位置取回源信息;以及根据指示的SNC存储器分配策略将源信息存储到由目的地操作对象指示的位置。
示例12包括示例11的装置,其中执行电路系统进一步用于根据操作码来执行经解码的指令,以进行:根据指示的SNC存储器分配策略在两个或更多个SNC中分配由目的地操作对象指定的存储器空间。
示例13包括示例12的装置,其中执行电路系统进一步用于根据操作码来执行经解码的指令,以利用指示的SNC存储器分配策略来超控用于两个或更多个SNC的指定的存储器空间的默认存储器分配策略。
示例14包括示例12至13中的任一项的装置,其中执行电路系统进一步用于根据操作码来执行经解码的指令,以进行:确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织;以及如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例15包括示例14的装置,其中执行电路系统进一步用于根据操作码执行经解码的指令,以进行:分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例16包括示例14至15中的任一项的装置,其中执行电路系统进一步用于根据操作码来执行经解码的指令,以进行:分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例17包括一种方法,该方法包括:取得指令,该指令具有用于操作码的字段;对指令进行解码;调度指令的执行;以及根据操作码来执行经解码的指令,以提供指示的子非均匀存储器访问集群(SNC)存储器分配策略。
示例18包括示例17的方法,进一步包括将信息存储在与指示的SNC存储器分配策略相对应的寄存器中。
示例19包括示例17至18中的任一项的方法,其中指令具有用于目的地操作对象和源操作对象的字段,并且其中操作码固有地指定指示的SNC存储器分配策略。
示例20包括示例19的方法,进一步包括:从由源操作对象指示的位置取回源信息;以及根据指示的SNC存储器分配策略将源信息存储到由目的地操作对象指示的位置。
示例21包括示例19至20中的任一项的方法,进一步包括:根据指示的SNC存储器分配策略在两个或更多个SNC中分配由目的地操作对象指定的存储器空间。
示例22包括示例21的方法,进一步包括:利用指示的SNC存储器分配策略来超控用于两个或更多个SNC的指定的存储器空间的默认存储器分配策略。
示例23包括示例21至22中的任一项的方法,进一步包括:确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织;以及如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例24包括示例23的方法,进一步包括:分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例25包括示例23至24中的任一项的方法,进一步包括:分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例26包括一种设备,该设备包括:用于在两个或更多个子非均匀存储器访问集群(SNC)中存储数据的装置;以及用于根据对指定的存储器空间进行初始化的请求指示的SNC存储器分配策略在两个或更多个SNC中分配指定的存储器空间的装置。
示例27包括示例26的设备,进一步包括用于将指示的SNC存储器分配策略存储在寄存器中的装置。
示例28包括示例26至27中的任一项的设备,进一步包括用于基于触发对指定的存储器空间进行初始化的请求的指令来确定指示的SNC存储器分配策略的装置。
示例29包括示例26至28中的任一项的设备,进一步包括用于利用指示的SNC存储器分配策略来超控用于两个或更多个SNC的默认存储器分配策略的装置。
示例30包括示例26至29中的任一项的设备,进一步包括:用于确定指示的SNC存储器分配策略是否指示指定的存储器空间要被交织的装置;以及在确定为是的情况下,用于分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间的装置。
示例31包括示例30的设备,进一步包括用于分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间的装置。
示例32包括示例30至31中的任一项的设备,进一步包括用于分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间的装置。
示例33包括一种集成电路,该集成电路包括电路系统,该电路系统用于:确定与对指定的存储器空间进行初始化的请求相关联的子非均匀存储器访问集群(SNC)存储器分配策略提示;以及根据SNC存储器分配策略提示在两个或更多个SNC中分配指定的存储器空间。
示例34包括示例33的集成电路,进一步包括用于存储SNC存储器分配策略提示的寄存器。
示例35包括示例33至34中的任一项的集成电路,其中电路系统进一步用于基于触发对指定的存储器空间进行初始化的请求的指令来确定SNC存储器分配策略提示。
示例36包括示例33至35中的任一项的集成电路,其中电路系统进一步用于利用SNC存储器分配策略提示指示的策略来超控用于两个或更多个SNC的默认存储器分配策略。
示例37包括示例33至36中的任一项的集成电路,其中电路系统进一步用于确定SNC存储器分配策略提示是否指示指定的存储器空间要被交织;以如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例38包括示例37的集成电路,其中电路系统进一步用于分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织指定的存储器空间。
示例39包括示例37至38中的任一项的集成电路,其中电路系统进一步用于分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例40包括一种方法,该方法包括:确定与对指定的存储器空间进行初始化的请求相关联的子非均匀存储器访问集群(SNC)存储器分配策略提示;以及根据SNC存储器分配策略提示在两个或更多个SNC中分配指定的存储器空间。
示例41包括示例40的方法,进一步包括将SNC存储器分配策略提示存储在寄存器中。
示例42包括示例40至41中的任一项的方法,进一步包括基于触发对指定的存储器空间进行初始化的请求的指令来确定SNC存储器分配策略提示。
示例43包括示例40至42中的任一项的方法,进一步包括利用SNC存储器分配策略提示指示的策略来超控用于两个或更多个SNC的默认存储器分配策略。
示例44包括示例40至43中的任一项的方法,进一步包括:确定SNC存储器分配策略提示是否指示指定的存储器空间要被交织;以及如果确定为是,则分配要在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例45包括示例44的方法,进一步包括:分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例46包括示例44至45中的任一项的方法,进一步包括:分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间。
示例47包括一种设备,该设备包括:用于确定与对指定的存储器空间进行初始化的请求相关联的子非均匀存储器访问集群(SNC)存储器分配策略提示的装置;以及用于根据SNC存储器分配策略提示在两个或更多个SNC中分配指定的存储器空间的装置。
示例48包括示例47的设备,进一步包括用于将SNC存储器分配策略提示存储在寄存器中的装置。
示例49包括示例47至48中的任一项的设备,进一步包括用于基于触发对指定的存储器空间进行初始化的请求的指令来确定SNC存储器分配策略提示的装置。
示例50包括示例47至49中的任一项的设备,进一步包括用于利用SNC存储器分配策略提示指示的策略来超控用于两个或更多个SNC的默认存储器分配策略的装置。
示例51包括示例47至50中的任一项的设备,进一步包括用于确定SNC存储器分配策略提示是否指示指定的存储器空间要被交织的装置;以及在确定为是的情况下,用于分配在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间的装置。
示例52包括示例51的设备,进一步包括用于分配要以页粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间的装置。
示例53包括示例51至52中的任一项的设备,进一步包括用于分配要以块粒度在两个或更多个SNC中的所有SNC之间被交织的指定的存储器空间的装置。
本文中描述了用于提供SNC提示以及在SNC中分配存储器空间的请求的技术和体系结构。在上文描述中,出于解释的目的,阐述了众多特定细节以提供对某些实施例的透彻理解。然而,对本领域技术人员而言将显而易见的是,某些实施例可在无需这些特定细节的情况下实施。在其他实例中,以框图形式示出结构和设备以避免使描述模糊。
在说明书中对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。在本说明书中的不同位置处出现短语“在一个实施例中”不一定全都指同一个实施例。
本文中的详细描述的一些部分在对计算机存储器内的数据比特的操作的算法和符号表示方面来呈现。这些算法描述和表示是计算机领域内技术人员使用的手法,它最有效地将其工作本质传达给本领域内其他技术人员。算法在本文中被一般地构思成达到所需结果的自洽步骤序列。这些步骤是需要对物理量进行物理操纵的那些步骤。通常但非必要地,这些量采用能够被存储、传输、组合、比较、以及以其他方式操纵的电信号或磁信号的形式。主要出于常见用途的理由,将这些信号称为比特、值、元素、符号、字符、项、数字等已被证明有时是方便的。
然而,应当铭记,所有这些和类似术语都与适当的物理量相关联,并且仅仅是应用于这些量的方便标示。除非以其他方式明确陈述,否则如从本文的讨论中显而易见的,要领会贯穿说明书,利用诸如“处理”或“计算”或“运算”或“确定”或“显示”等术语的讨论,是指计算机系统或类似电子计算设备的动作和进程,该计算机系统或类似电子计算设备操纵在该计算机系统的寄存器和存储器内被表示为物理(电子)量的数据并将其转换成在该计算机系统存储器或寄存器或其他此类信息存储、传输或显示设备内类似地被表示为物理量的其他数据。
某些实施例还关于用于执行本文中的操作的装置。该装置可专门构造来用于所需目的,或其可包括通用计算机,该通用计算机由存储在该计算机中的计算机程序有选择地激活或重新配置。此类计算机程序可以存储在计算机可读存储介质中,这些计算机可读存储介质诸如但不限于任何类型的盘,包括软盘、光盘、CD-ROM、磁光盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)(诸如,动态RAM(dynamicRAM,DRAM))、EPROM、EEPROM、磁卡或光卡、或适用于存储电子指令且耦合至计算机系统总线的任何类型的介质。
本文中呈现的算法和显示并非固有地与任何特定计算机或其他装置相关。可以将各种通用系统与根据本文中的教导的程序一起使用,或可以证明构造更专门的装置来执行所要求的方法步骤是方便的。用于各种这些系统的所需结构将从本文中的描述呈现。此外,某些实施例不是参考任何特定编程语言来描述的。将会领会,可以使用各种编程语言来实现本文所描述的此类实施例的教导。
除了本文中所描述的内容,可对所公开的实施例及其实现方式作出各种修改而不背离其范围。因此,本文中的说明和示例应当被解释成说明性的,而非限制性的。本发明的范围应当仅通过参照所附权利要求书来界定。
- 一种集群渲染过程中镜头共享数据管理的方法
- 一种集群渲染过程中镜头共享数据管理的方法