一种刷量用户识别方法及装置
文献发布时间:2023-06-19 10:19:37
技术领域
本发明涉及数据处理领域,具体涉及一种刷量用户识别方法及装置。
背景技术
在现代的社交媒体中,一些用户通过脚本或者工具不断的执行一些操作,这种行为干扰了平台正常的秩序,需要把这些用户找出来。现在原始数据是访问日志,格式是:
访问时间,访问接口,访问用户id,即uid
2020-03-22-08:33:21:888,A,39
一条日志代表了用户对网站的一次访问行为,这种日志一般数量巨大,以肉眼来分析其中的用户性质几乎是不可能的。
在实现本技术方案的过程中,发现现有技术中存在以下问题:现有技术中通过分析用户网站访问日志数据,与预先设置的对比矩阵数据进行计算判断,所使用的矩阵在实际使用中可能过于巨大,导致其运算、网络传输均极慢。还会因矩阵过于巨大导致内存、算力不足进而程序无法运行的问题。
发明内容
本发明实施例提供一种刷量用户识别方法及装置,在尽量缩小矩阵大小,提升整个系统的计算速度和网络传输速度的同时,解决了因内存和计算力量不足所导致的程序无法运行的问题。
为达到上述目的,一方面,本发明实施例提供了一种刷量用户识别方法,所述方法包括:
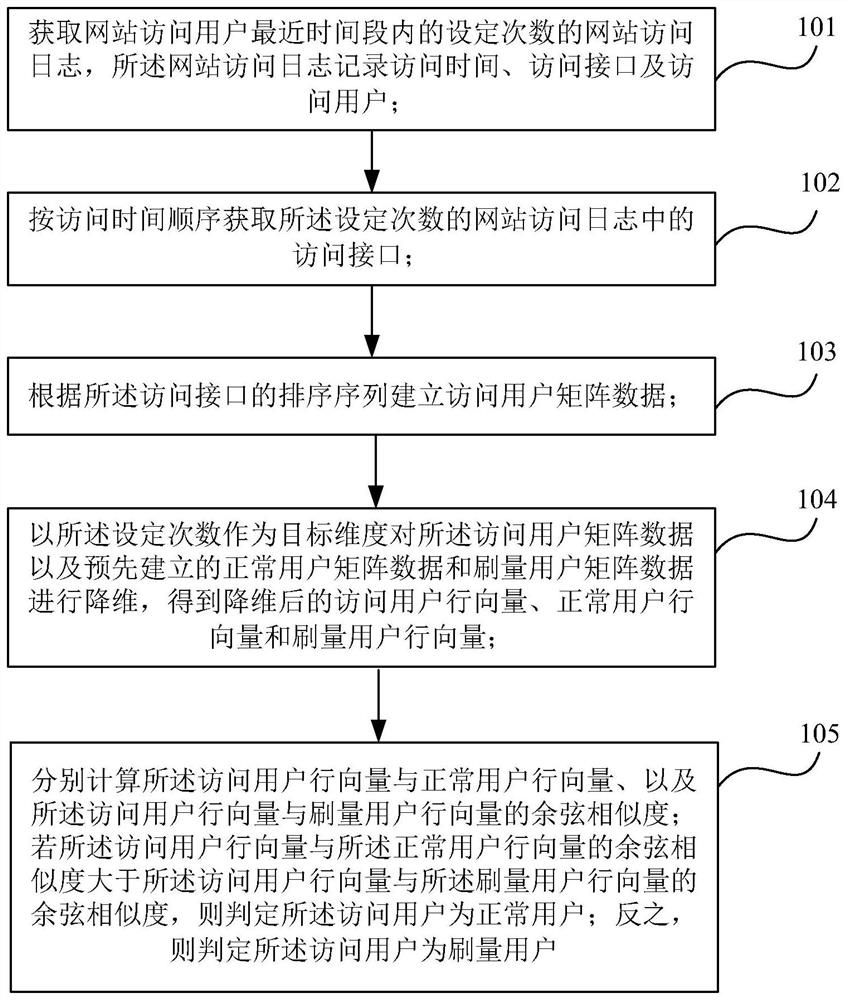
获取网站访问用户最近时间段内的设定次数的网站访问日志,所述网站访问日志记录访问时间、访问接口及访问用户;
按访问时间顺序获取所述设定次数的网站访问日志中的访问接口;
根据所述访问接口的排序序列建立访问用户矩阵数据;
根据设定的目标维度对所述访问用户矩阵数据以及预先建立的正常用户矩阵数据和刷量用户矩阵数据进行降维,得到降维后的访问用户行向量、正常用户行向量和刷量用户行向量;
分别计算所述访问用户行向量与正常用户行向量和与刷量用户行向量的余弦相似度;若所述访问用户行向量与所述正常用户行向量的余弦相似度大于与所述刷量用户行向量的余弦相似度,则判定所述访问用户为正常用户;反之,则判定所述访问用户为刷量用户。
另一方面,本发明实施例提供了一种刷量用户识别装置,所述装置包括:
日志获取单元,用于获取网站访问用户最近时间段内的设定次数的网站访问日志,所述网站访问日志记录访问时间、访问接口及访问用户;
访问接口获取单元,用于按访问时间顺序获取所述设定次数的网站访问日志中的访问接口;
用户矩阵建立单元,用于根据所述访问接口的排序序列建立访问用户矩阵数据;
降维单元,用于根据设定的目标维度对所述访问用户矩阵数据以及预先建立的正常用户矩阵数据和刷量用户矩阵数据进行降维,得到降维后的访问用户行向量、正常用户行向量和刷量用户行向量;
识别单元,用于分别计算所述访问用户行向量与正常用户行向量,以及所述访问用户行向量与刷量用户行向量的余弦相似度;若所述访问用户行向量与所述正常用户行向量的余弦相似度大于所述访问用户行向量与所述刷量用户行向量的余弦相似度,则判定所述访问用户为正常用户;反之,则判定所述访问用户为刷量用户。
上述技术方案具有如下有益效果:
本发明的技术方案通过序列矩阵找出网站访问日志中刷量用户的流程之后,新系统可以误伤正常用户的比率极大的下降了,而且对刷量用户的判断精准率比之前高出很多,而且判断处理几乎是实时的,用少量实时的数据就能判断用户的性质。而且现在的系统可以缩小矩阵大小,大大提升整个系统的计算速度和网络传输速度。此外还解决了因内存和计算力量不足所导致的程序无法运行的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例一种刷量用户识别方法的流程图;
图2是本发明实施例一种刷量用户识别装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本方案中相关的缩略语和关键术语定义:
序列矩阵:序列矩阵的i行j列的数字Mij意味着在用户的访问序列中,先访问i行对应接口后访问j行对应接口的总次数。序列矩阵是一种非参数纯统计的对用户访问序列建模的模型。
刷量用户:一些用户通过脚本或者工具不断的执行一些操作,这种行为干扰了平台正常的秩序,需要把这些用户找出来。
矩阵分解:矩阵分解(decomposition,factorization)是将矩阵拆解为数个矩阵的乘积,可分为三角分解、满秩分解、QR分解、Jordan分解和奇异值SVD分解等,本章里采用的是SVD分解。
如图1所示,是本发明实施例一种刷量用户识别方法的流程图,所述方法包括:
S101:获取网站访问用户最近时间段内的设定次数的网站访问日志,所述网站访问日志记录访问时间、访问接口及访问用户。
S102:按访问时间顺序获取所述设定次数的网站访问日志中的访问接口。
S103:根据所述访问接口的排序序列建立访问用户矩阵数据。
优选地,所述根据所述访问接口的排序序列建立访问用户矩阵数据,包括:
建立m*m维的全零矩阵M,m是网站所有访问接口的数量,并建立网站所有访问接口与M主对角线行列号的一一对应关系;
将所述访问用户网站访问日志中的访问接口按照访问时间顺序排列,将排列的访问接口按序组成顺序二元组;
由顺序二元组中的访问接口对应的行列号确定每个顺序二元组对应于全零矩阵M中的位置,将该位置处元素取值加1,获得访问用户的矩阵数据U。
S104:根据设定的目标维度对所述访问用户矩阵数据以及预先建立的正常用户矩阵数据和刷量用户矩阵数据进行降维,得到降维后的访问用户行向量、正常用户行向量和刷量用户行向量。
优选地,所述正常用户矩阵数据和刷量用户矩阵数据,通过以下步骤建立:
获取第一设定数量的正常用户和第二设定数量的刷量用户在同一设定时间段内的所有网站访问日志;
根据网站访问日志,按访问时间顺序获取每一个正常用户在所述设定时间段内的所有访问接口;根据所述第一设定数量的每一个正常用户的所有访问接口的排序序列建立正常用户矩阵数据;
根据网站访问日志,按访问时间顺序获取每一个刷量用户在所述设定时间段内的所有访问接口;根据所述第二设定数量的每一个刷量用户的所有访问接口的排序序列建立刷量用户矩阵数据。
进一步优选地,根据所述第一设定数量的每一个正常用户的所有访问接口的排序序列建立正常用户矩阵数据,包括:
建立m*m维的全零矩阵M,m是网站所有访问接口的数量,并建立网站所有访问接口与M主对角线行列号的一一对应关系;
将每一个正常用户的所有访问接口按照访问时间顺序排列,将排列的访问接口按序组成顺序二元组;
由顺序二元组中的访问接口对应的行列号确定每个顺序二元组对应于全零矩阵M中的位置,将该位置处元素取值加1,获得正常用户矩阵数据M0;
根据所述第二设定数量的每一个刷量用户的所有访问接口的排序序列建立刷量用户矩阵数据,包括:
建立m*m维的全零矩阵M,m是网站所有访问接口的数量,并建立网站所有访问接口与M的主对角线行列号的一一对应关系;将每一个刷量用户的所有访问接口按照访问时间顺序排列,将排列的访问接口按序组成顺序二元组;
由顺序二元组中的访问接口对应的行列号确定每个顺序二元组对应于全零矩阵M中的位置,将该位置处元素取值加1,获得刷量用户矩阵数据M1。
S105:分别计算所述访问用户行向量与正常用户行向量,以及所述访问用户行向量与刷量用户行向量的余弦相似度;若所述访问用户行向量与所述正常用户行向量的余弦相似度大于所述访问用户行向量与所述刷量用户行向量的余弦相似度,则判定所述访问用户为正常用户;反之,则判定所述访问用户为刷量用户。
优选地,根据设定的目标维度n,通过矩阵奇异值分解方法对所述访问用户矩阵数据以及预先建立的正常用户矩阵数据和刷量用户矩阵数据进行降维,得到m*n维的访问用户矩阵数据、m*n维的正常用户矩阵数据和m*n维的刷量用户矩阵数据。
具体地,先形成正常用户矩阵数据即正常用户的序列矩阵M0和刷量用户矩阵数据即刷量用户的序列矩阵M1:
1.人工标记一部分正常用户uid形成集合U0,取这些用户在一段时间的所有网站访问日志L0。在L0里把所有uid相同的日志进行聚合。每个uid都有很多行日志ul1,ul2,ul3…。ul*格式为:访问时间,访问接口,访问用户id(uid),对每个uid形成一个列表UL以存放ul*。
2.对于所有uid执行:对其中的所有ul*进行按时间排序并取日志中的访问接口a得到L,得到键值表Mk0。Mk0中的数据格式为uid:L L为[a1,a2,a3,a4…],是按时间排序过后的访问日志中的访问接口。Mk0里有很多这样的uid:L的数据。
3.取日志中所有可能的接口的数量m,形成一个m*m的全零矩阵M。并对m的行和列进行行列号和接口的一一对应关系,比如A接口对应第i列和第i行,B接口对应i+1行和列。
4.对于Mk0里的所有的L:对L中的所有顺序二元组(ai,ai+1):在m中找到ai对应的行和ai+1对应的列,给此处的数字加一。第4步完成后序列矩阵M0便构建完成。同样的方法可以人工打标一批刷量用户的uid来得到M1.
然后通过M0,M1和某用户最近的n次行为序列来判断该用户是否刷量。
5.某用户A的访问接口的顺序为[a1,a2,a3,a4…an],则对该用户形成一个用户矩阵U,其数字和M0的计数方法完全一致。
6.构建SVD矩阵分解方法f,f中指定矩阵分解的降维目标维度数n,以f来分解M0,M1,U得到m行n列的矩阵Mf0、Mf1、Uf。
7.对于Uf中的m个n长度的行向量,和Mf0中对应行的行向量求数学余弦相似度C0i,得到m个余弦相似度再加和得到总的Uf和Mf0的相似度C0,同样的方法可得C1。比较C0和C1即可判断该用户行为序列正常还是异常。
对应于上述方法,如图2所示,是本发明实施例一种刷量用户识别装置的结构示意图,所述装置包括:
日志获取单元21,用于获取网站访问用户最近时间段内的设定次数的网站访问日志,所述网站访问日志记录访问时间、访问接口及访问用户;
访问接口获取单元22,用于按访问时间顺序获取所述设定次数的网站访问日志中的访问接口;
用户矩阵建立单元23,用于根据所述访问接口的排序序列建立访问用户矩阵数据;
降维单元24,用于根据设定的目标维度对所述访问用户矩阵数据以及预先建立的正常用户矩阵数据和刷量用户矩阵数据进行降维,得到降维后的访问用户行向量、正常用户行向量和刷量用户行向量;
识别单元25,用于分别计算所述访问用户行向量与正常用户行向量、以及所述访问用户行向量与刷量用户行向量的余弦相似度;若所述访问用户行向量与所述正常用户行向量的余弦相似度大于所述访问用户行向量与所述刷量用户行向量的余弦相似度,则判定所述访问用户为正常用户;反之,则判定所述访问用户为刷量用户。
优选地,还包括对比矩阵建立单元,用于建立正常用户矩阵数据和刷量用户矩阵数据,包括:
数据获取模块,用于获取第一设定数量的正常用户和第二设定数量的刷量用户在同一设定时间段内的网站访问日志;
正常用户模块,用于根据网站访问日志,按访问时间顺序获取每一个正常用户在所述设定时间段内的所有访问接口;根据所述第一设定数量的每一个正常用户的所有访问接口的排序序列建立正常用户矩阵数据;
刷量用户模块,用于根据网站访问日志,按访问时间顺序获取每一个刷量用户在所述设定时间段内的所有访问接口;根据所述第二设定数量的每一个刷量用户的所有访问接口的排序序列建立刷量用户矩阵数据。
优选地,所述用户矩阵建立单元23具体用于:
在建立m*m维的全零矩阵M,并建立网站所有访问接口与M主对角线行列号的一一对应关系的基础上,其中m是网站所有访问接口的数量;
将所述访问用户网站访问日志中的访问接口按照访问时间顺序排列,将排列的访问接口按序组成顺序二元组;
由顺序二元组中的访问接口对应的行列号确定每个顺序二元组对应于全零矩阵M中的位置,将该位置处元素取值加1,获得访问用户的矩阵数据U。
优选地,所述正常用户模块具体用于:在建立m*m维的全零矩阵M,并建立网站所有访问接口与M主对角线行列号的一一对应关系的基础上,m是网站所有访问接口的数量;
将每一个正常用户的所有访问接口按照访问时间顺序排列,将排列的访问接口按序组成顺序二元组;
由顺序二元组中的访问接口对应的行列号确定每个顺序二元组对应于全零矩阵M中的位置,将该位置处元素取值加1,获得正常用户矩阵数据M0;
所述刷量用户模块具体用于:在建立m*m维的全零矩阵M,并建立网站所有访问接口与M的行列号的一一对应关系的基础上;
将每一个刷量用户的所有访问接口按照访问时间顺序排列,将排列的访问接口按序组成顺序二元组;
由顺序二元组中的访问接口对应的行列号确定每个顺序二元组对应于全零矩阵M中的位置,将该位置处元素取值加1,获得刷量用户矩阵数据M1。
优选地,所述降维单元24具体用于:
根据设定的目标维度n,通过矩阵奇异值分解方法对所述访问用户矩阵数据以及预先建立的正常用户矩阵数据和刷量用户矩阵数据进行降维,得到m*n维的访问用户矩阵数据、m*n维的正常用户矩阵数据和m*n维的刷量用户矩阵数据。
按照本发明的技术方案,例举一具体实例如下:
1.假设人工标记正常用户uid集合U0是{1,2},U1是{3},取到的L0是:
2020-03-22-08:33:21:888 A 1
2020-03-22-08:33:21:889 B 1
2020-03-22-08:33:21:890 C 1
2020-03-22-08:33:21:888 A 2
2020-03-22-08:33:21:889 B 2
异常用户日志L1是:
2020-03-22-08:33:21:888 A 3
2020-03-22-08:33:21:889 A 3
2020-03-22-08:33:21:890 A 3
2020-03-22-08:33:21:891 A 3
对相同uid的日志进行聚合,得到:
1号用户:UL为
[2020-03-22-08:33:21:888 A 1
2020-03-22-08:33:21:889 B 1
2020-03-22-08:33:21:890 C 1]
2号用户:UL为
[2020-03-22-08:33:21:888 A 2
2020-03-22-08:33:21:889 B 2]
3号用户:UL为
[2020-03-22-08:33:21:888 A 3
2020-03-22-08:33:21:889 A 3
2020-03-22-08:33:21:890 A 3
2020-03-22-08:33:21:891 A 3]
2.对于所有uid执行:对其中的所有ul*进行按时间排序并取日志中的访问接口a得到L,得到键值表Mk0。Mk0中的数据格式为uid:L,L为[a1,a2,a3,a4…],是按时间排序过后的访问日志中的访问接口。Mk0里有很多这样的uid:L的数据。
对于1号用户:
[2020-03-22-08:33:21:888 A 1
2020-03-22-08:33:21:889 B 1
2020-03-22-08:33:21:890 C 1]
进行按时间排序,再去日志的访问接口字段,得到1:[A,B,C],
最后得到键值表Mk0:{1:[A,B,C],2:[A,B]},Mk1:{3:[A,A,A]}。
3.取日志中所有可能的接口的数量m,形成一个m*m的全零矩阵M。并对m的行和列进行行列号和接口的一一对应关系,比如A接口对应第i列和第i行,B接口对应i+1行和列。
一共有3种接口ABC即m=3形成M0和M1为3*3的全零矩阵。接下来定义ABC和行列号的对应关系这里可以选择A对应第一行列,B对应第二行列,C对应第三行列。此时M0,M1形如:
4.对于Mk0里的所有的L:对L中的所有顺序二元组(ai,ai+1):在m中找到ai对应的行和ai+1对应的列,给此处的数字加一。第4步完成后序列矩阵M0便构建完成。同样的方法可以人工打标一批刷量用户的uid来得到M1。此处还可得到M0中所有数字之和S0,同理可得S1
对于Mk0里的所有的L,此处是[A,B,C]和[A,B],
对于L中的所有顺序二元组((A,B),(B,C),(A,B)):
在M0中找到对应行列并加一
完成之后M0:
同理M1:
对于Mk1里的所有的L(此处是[A,A,A]和),
对于L中的所有顺序二元组((A,A),(A,A)):
在M1中找到对应行列并加一
完成之后M1:
现在假设M0、M1都是非常大的矩阵,对其进行的每个操作都需要巨量的内存、网络和计算资源。如果对其进行矩阵分解得到小的矩阵,则对应的问题都迎刃而解了。这里选择SVD矩阵分解,m=3。此时选择目标降维数n=2,则会形成3个小矩阵。实际应用中只需用工具即可方便的得到分解结果。
假设用户A的访问接口顺序是[A,A,A],B的访问接口顺序是[A,B]
则对A来说:
U1=np.array([[2,0,0],[0,0,0],[0,0,0]])
对B来说:
U2=np.array([[0,1,0],[0,0,0],[0,0,0]])
在python中定义SVD分解方法f并指定n=2然后训练f:
from sklearn.decomposition import TruncatedSVD
svd=TruncatedSVD(2)
svd.fit(N0-N1)
这里以N0-N1训练f的目的是让f正负样本都看到,有利于之后的分解。
然后得到Mf0 Mf1 U1f U2f
Mf0=svd.transform(M0)
Mf1=svd.transform(M1)
U1f=svd.transform(U1)
U2f=svd.transform(U2)
此时Mf0 Mf1 U1f U2f都是m*n分解好的小矩阵了。以下是这4个矩阵的具体数值。
array([[1.41421356e+00,1.59682547e-21],[-4.10755055e-22,1.00000000e+00],[0.00000000e+00,0.00000000e+00]])
array([[-1.41421356e+00,4.35034728e-22],[0.00000000e+00,0.00000000e+00],[0.00000000e+00,0.00000000e+00]])
array([[-1.41421356e+00,4.35034728e-22],[0.00000000e+00,0.00000000e+00],[0.00000000e+00,0.00000000e+00]])
array([[7.07106781e-01,7.98412733e-22],[0.00000000e+00,0.00000000e+00],[0.00000000e+00,0.00000000e+00]])
然后计算相似度:
对于U1f和Mf0的相似度,一共m行,对于第i行来说,把该行的行向量丛两个矩阵中取出进行cosine相似度计算得到C0i。再把这些C0i加起来得到C0。
实际应用中在python中可以利用已有函数进行简便的运算:
from sklearn.metrics.pairwise import cosine_similarity as cosine
C0-A=cosine(ap,o1p).diagonal().sum()
C1-A=cosine(bp,o1p).diagonal().sum()
C0-B=cosine(ap,o2p).diagonal().sum()
C1-B=cosine(bp,o2p).diagonal().sum()
最后结果是
-1.0
1.0
1.0
-1.0
也就是A用户和异常矩阵M1非常相似
B用户和正常矩阵M0非常相似。由此得出判断。
应该明白,公开的过程中的步骤的特定顺序或层次是示例性方法的实例。基于设计偏好,应该理解,过程中的步骤的特定顺序或层次可以在不脱离本公开的保护范围的情况下得到重新安排。所附的方法权利要求以示例性的顺序给出了各种步骤的要素,并且不是要限于所述的特定顺序或层次。
在上述的详细描述中,各种特征一起组合在单个的实施方案中,以简化本公开。不应该将这种公开方法解释为反映了这样的意图,即,所要求保护的主题的实施方案需要比清楚地在每个权利要求中所陈述的特征更多的特征。相反,如所附的权利要求书所反映的那样,本发明处于比所公开的单个实施方案的全部特征少的状态。因此,所附的权利要求书特此清楚地被并入详细描述中,其中每项权利要求独自作为本发明单独的优选实施方案。
为使本领域内的任何技术人员能够实现或者使用本发明,上面对所公开实施例进行了描述。对于本领域技术人员来说;这些实施例的各种修改方式都是显而易见的,并且本文定义的一般原理也可以在不脱离本公开的精神和保护范围的基础上适用于其它实施例。因此,本公开并不限于本文给出的实施例,而是与本申请公开的原理和新颖性特征的最广范围相一致。
上文的描述包括一个或多个实施例的举例。当然,为了描述上述实施例而描述部件或方法的所有可能的结合是不可能的,但是本领域普通技术人员应该认识到,各个实施例可以做进一步的组合和排列。因此,本文中描述的实施例旨在涵盖落入所附权利要求书的保护范围内的所有这样的改变、修改和变型。此外,就说明书或权利要求书中使用的术语“包含”,该词的涵盖方式类似于术语“包括”,就如同“包括,”在权利要求中用作衔接词所解释的那样。此外,使用在权利要求书的说明书中的任何一个术语“或者”是要表示“非排它性的或者”。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种刷量用户识别方法及装置
- 一种智能客服的刷量用户识别方法、装置及服务器