一种基于Spark的大数据清洗方法
文献发布时间:2023-06-19 10:24:22
技术领域
本发明涉及数据清洗领域,特别是涉及一种基于Spark的大数据清洗方法。
背景技术
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
在大数据清洗技术方面,当前的技术除了针对具体数据编写MapReduce程序外,还可采用Hadoop的Hive。传统的基于Hadoop的系统存在无法满足业务需求以及设备成本过高的问题。在业务需求方面,从历史数据分析与实时数据流处理,Hadoop虽然能够处理大数据,但是效率较低,另外一方面,设备成本过高。
发明内容
本发明的发明目的在于:针对上述存在的问题,提供一种基于Spark的大数据清洗方法,通过应用Spark技术进行大数据的清洗,一方面极大的提高了数据清洗的速度与清洗准确率;另一方面,降低了设备成本。
本发明采用的技术方案如下:
一种基于Spark的大数据清洗方法,包括以下步骤:
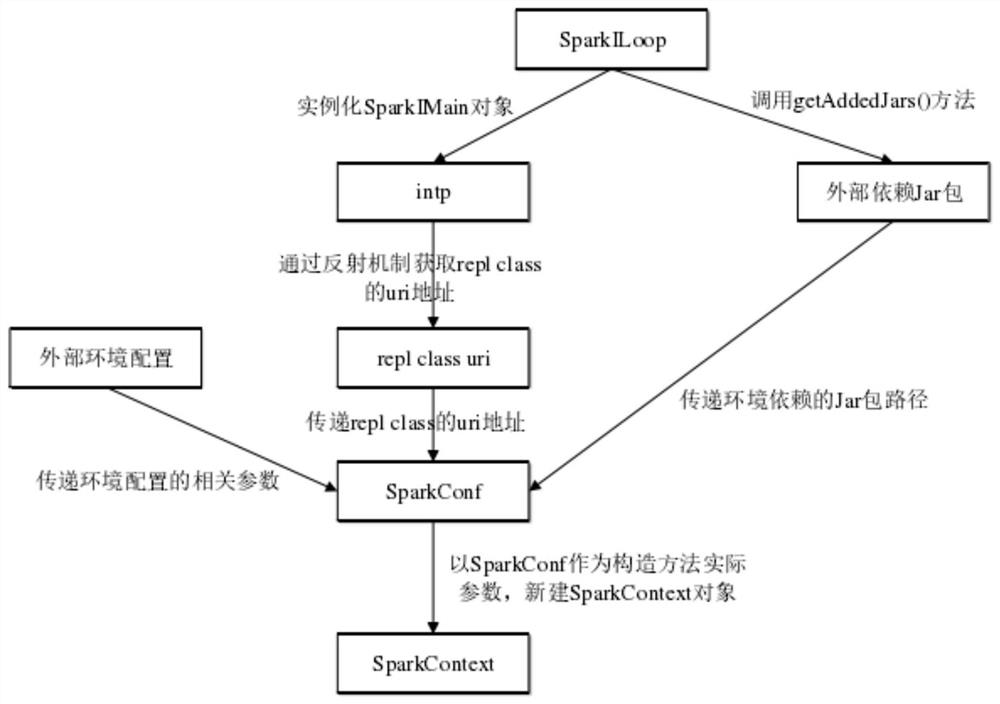
S1.实例化一个org.apache.spark.repl包下的SparkILoop类的对象;
S2.通过第S1步获取到的SparkILoop类对象,调用getAddedJars()方法,加载org.apache.spark.repl.Main所依赖的外部Jar包环境;
S3.通过第S1步获取到的SparkILoop类对象,实例化解释器类SparkIMain的对象intp;
S4.由第S3步获取到的解释器类对象intp,通过Java的反射机制,获取repl classuri地址属性值,将该属性值传递到SparkConf中;同时,将外部环境配置相关参数,以及第S2步中获取到的环境依赖Jar包的路径,一并传递到SparkConf中;
S5.由org.apache.spark.repl包通过SparkConf生成一个新的SparkContext对象;
S 6.然后系统提交的业务组件都交给解释器类对象intp,连续反复地提交执行,并返回运行结果。
2、权利要求1所述的一种基于Spark的大数据清洗方法,其特征在于:所述数据清洗方法采用深度优先遍历多叉树计算流,以递归的方式进行大数据清洗。
进一步地,本发明公开了一种基于Spark的大数据清洗方法的优选实施方式,包括主程序Spark-ETL,所述主程序Spark-ETL包括Algorithms,所述Algorithms包括单个大数据清洗单元,所述单个大数据清洗单元包括其工作内容划分方法和基础的数据操作方式;所述Spark采用流水线设计,采用多叉树结构定义计算流,毎个树枝节点代表数据清洗,而叶节点代表数据存入某个数据库表或者文件中。
进一步地,所述大数据清洗单元围绕存储表划分,具体方法如下:数据从原始数据开始,在Stage1阶段完成基础表的生成,下一阶段的表依赖于上一阶段的表内数据,进一步划分Stage2。
进一步地,所述主程序Spark-ETL设置有RDD共享机制,数据存储在内存中,不用写入到数据库即可传递给下一个Job继续处理数据;所述Stage2的清洗单元数据来自于多个Stage1中的表,整个过程与Spark底层的RDD计算流程一一映射。
进一步地,所述深度优先遍历多叉树计算流采用流水线处理数据,包括步骤:a.从Kafka接收数据开始进入Spark Data Frame,然后进入操作1;b.操作1进入操作2和操作4;c.操作2进入操作3,操作4进入操作5;d.操作5进入操作6和操作7;e.操作3的下一步为Tabel-1,操作6进入Tabel-2,包括操作7进入Tabel-3。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.本发明应用Spark技术进行大数据的清洗,一方面极大的提高了数据清洗的速度与清洗准确率;另一方面,降低了设备成本。
2.通过实施本方法,能满足不同客户,不同行业的数据清洗任务;运用该技术做数据清洗准确率提高37%,速度提高41%。
附图说明
图1是本发明基于Spark框架的数据清洗流程图;
图2是是本发明Spark-ETL模块结构图;
图3是是本发明清洗单元划分示意图;
图4是是本发明数据流水线示意图。
具体实施方式
下面结合附图,对本发明作详细的说明。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1:
如附图1所示,本发明公开了一种基于Spark的大数据清洗方法的优选实施方式,包括以下步骤:
S1.实例化一个org.apache.spark.repl包下的SparkILoop类的对象;
S2.通过第S1步获取到的SparkILoop类对象,调用getAddedJars()方法,加载org.apache.spark.repl.Main所依赖的外部Jar包环境;org.apache.spark.repl.Main即为Spark-Shell的运行主类。
S3.通过第S1步获取到的SparkILoop类对象,实例化解释器类SparkIMain的对象intp;
S4.由第S3步获取到的解释器类对象intp,通过Java的反射机制,获取repl classuri地址属性值,将该属性值传递到SparkConf中;同时,将外部环境配置相关参数,以及第S2步中获取到的环境依赖Jar包的路径,一并传递到SparkConf中;外部环境配置相关参数采用Spark的缺省参数或用户自定义参数。
S5.由org.apache.spark.repl包通过SparkConf生成一个新的SparkContext对象;
S 6.然后系统提交的业务组件都交给解释器类对象intp,连续反复地提交执行,并返回运行结果。
如图2所示,主程序Spark-ETL模块包括Spark-ETL Web Client,所述Spark-ETLWeb Client连接有Spark-ETL Job Server模块、Algorithms、Spark SQL、Spark-ETL JobSDK。
所述主程序Algorithms包括单个大数据清洗单元,所述单个大数据清洗单元包括其工作内容划分方法和基础的数据操作方式;所述Spark采用流水线设计,采用多叉树结构定义计算流,毎个树枝节点代表数据清洗,而叶节点代表数据存入某个数据库表或者文件中。流水线的设计遵循尽量减少数据计算的原则。所述数据清洗方法采用深度优先遍历多叉树计算流,以递归的方式进行大数据清洗。
如图3所示的大数据清洗单元设计,是依照业务划分的清洗单元,图中的设计围绕存储表划分,数据从原始数据开始,在Stage1阶段完成基础表的生成,下一阶段的表依赖于上一阶段的表内数据,所以进一步划分Stage2。Spark-ETL设计的RDD共享机制,提供了另外的数据传递选择,不需要将表的数据存储到实际的数据库表中,即可传递给下一个Job继续处理数据。显然,Stage2的清洗单元数据来自于多个Stage1中的表,具体由其清洗单元自行控制,整个过程与Spark底层的RDD计算流程一一映射。所以,一个清洗单元实际映射到具体的一次业务需求。
如图4的流水线配置设计,包括步骤:a.从Kafka接收数据开始进入Spark DataFrame,然后进入操作1;b.操作1进入操作2和操作4;c.操作2进入操作3,操作4进入操作5;d.操作5进入操作6和操作7;e.操作3的下一步为Tabel-1,操作6进入Tabel-2,包括操作7进入Tabel-3。在某个实际项目中设计的数搪处理流水线,从Kafka接收数据开始进入SparkData Frame,实际原始数据为Json格式。操作2与操作4共同依赖于操作1,操作6与操作7共同依赖于操作5。相比于一般的单流水线模式,这种树结构设计能够有效重用己经计算的RDD,在树枝分又的节点调用RDD的cache()方法,从而提高效率,否则因为内存空间不足,往往会择放计算过程中的一些RDD内存空间,即使Spark本身会重用已经计算过的RDD,所以在计算过程中必须手动缓存分支节点的RDD数据,多叉树计算流,才能优于单流水线摸式。
本发明应用Spark技术进行大数据的清洗,一方面极大的提高了数据清洗的速度与清洗准确率;另一方面,降低了设备成本。通过实施本方法,能满足不同客户,不同行业的数据清洗任务;运用该技术做数据清洗准确率提高37%,速度提高41%。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于Spark的大数据清洗方法
- 一种基于Spark计算引擎的配电网大数据分区处理方法