并列中文名词短语精准识别方法及模型
文献发布时间:2023-06-19 13:46:35
技术领域
本申请涉及一种并列名词短语识别方法及模型,特别涉及一种并列中文名词短语精准识别方法及模型,属于并列名词短语识别技术领域。
背景技术
从海量的数据中准确定位并快速获取资源是当前的迫切需求,作为人工智能和计算机领域中及其重要的研发方向,句法分析在自然语言处理中起到了非常关键的作用,是将自然语言处理成计算机能够处理的语言中不可缺少的部分。并列名词短语在文本中使用非常广泛,通过并列中文名词短语可以获取语句中丰富的实体信息,获取文本中的实体信息,可以提高在海量数据中资源定位的准确性,同时有利于信息检索、自动摘要等应用领域的研发,因此对并列中文名词短语的精准识别具有巨大的实际意义及应用价值。
本申请提出并列中文名词短语识别方法,有以下几个方面的动机和应用价值:
一是并列中文名词短语承载了丰富的实体信息,通过识别并列中文名词短语,获取文本中较具体的实体信息,比如人名、会议、事件、单位等,有利于自然语言处理中自动摘要,机器翻译、信息检索等应用领域,通过输入的检索信息准确定位到目标资源,对提高信息检索的质量非常重要,识别并列中文名词短语能够改善信息检索的质量,提高检索的准确性。
二是正确识别并列中文名词短语中各并列项的边界能够帮助消除自然语言中的歧义,对并列中文名词短语的并列结构的理解直接影响对文本的理解,对这个并列中文名词短语的理解直接关系到对语句的理解,通过正确识别并列中文名词短语的并列连词可消除各并列项之间层次不明导致的歧义问题。
三是帮助提高语块分析的精确率,由于并列中文名词短语各并列项内部结构的复杂性以及名词短语边界跨度大,针对并列中文名词短语的识别是一个难点,使用有效方法自动识别并列中文名词短语对提高语块分析的精确率能起到帮助作用。
四是降低句法分析难度,书面表达中并列中文名词短语使用非常广泛,并列结构复杂多样,一个语句中存在多个并列中文名词短语或者嵌套的并列中文名词短语的情况,通过对并列中文名词短语的识别和分析能够简化语句,从而降低句法分析的难度。
现有技术语块分析研发:并列结构的自动识别是语块分析组块识别与分析,并列名词短语属于并列结构的一种。总结组块识别的现有技术,识别方法主要分为:基于规则的方法、基于概率统计的方法、基于规则和统计相结合的方法。基于规则的组块识别方法的基本思路为:一是针对所选取的语言进行语言特点的研究,二是根据总结出来的语言特点,找出需要识别的短语的特征,建立规则模板,三是将前置处理模块的输出结果用于短语识别模型的输入,根据制定的规则模板进行匹配和标注,最后输出标注的文本。基于规则的方法具有的缺点也很明显:一是规则是面向语言和语料库的,不同的语言和语料都需要相应的规则;第二、需要大量的工作来建立规则模板,模板计算量太大,并且需要丰富的语言学知识。
现有技术并列结构识别研发:目前专门针对并列结构识别的研发工作相对组块识别较少,现有技术采用支持向量机模型将并列结构的识别问题看成是分类问题,对嵌套的并列结构、多项并列的并列结构、单个词并列的并列结构进行识别,发现错误率较高,在比较了基于规则的方法后,得出基于规则的方法优于支持向量机模型地方法。
现有技术并列中文名词短语相关研发:没有针对中文并列名词短语识别的相关研发。
现有技术的没有可靠的并列名词短语识别方法,本申请的难点和待解决的问题主要集中在以下方面:
第一,目前针对并列中文名词短语的研究应用包括并列中文名词短语消歧、并列中文名词短语的语言学特征等方面,现有技术还没有专门针对并列中文名词短语识别的方法,现有技术的方法或者不能对并列名词短语进行有效的识别,或者对中文识别的可靠性差,或者缺少鲁棒性和稳定性好的识别模型,导致并列名词短语边界识别准确率和F值较低;连接标识的识别F也低值,因而不适用于中文并列名词短语识别;
第二,并列中文名词短语属于并列短语的一种,由于现有技术无法针对中文并列名词进行精准识别,因而不能够对语块分析提供帮助,由于并列中文名词短语对自然语言处理多个应用领域都有极为重要的作用,因而也不能获取语句中丰富的实体信息,无法提高在海量数据中资源定位的准确性,同时制约信息检索、自动摘要等应用领域的研发,引发并列中文名词短语识别技术卡脖子的问题;
第三,现有技术的相关研发也不能对中文并列名词短语识别形成技术指引和有效支撑,基于规则的方法的缺点:一是规则是面向语言和语料库的,不同的语言和语料都需要相应的规则;第二、需要大量的工作来建立规则模板,模板计算量太大,并且需要丰富的语言学知识;专门针对并列结构识别的研发工作相对组块识别较少,现有技术采用支持向量机模型将并列结构的识别问题看成是分类问题,对嵌套的并列结构、多项并列的并列结构、单个词并列的并列结构进行识别,发现错误率较高,对于许多场景下的运用,都存在很大的局限性;
第四,现有技术还没有专门针对并列中文名词短语识别的方法,缺少并列中文名词短语精准识别模型,缺少将并列中文名词短语识别问题转换为联合词概率建模问题的思路,缺少采用STEc融合词汇特征、词性特征、词长特征以及三种结构特征对并列中文名词短语边界及连接标识进行识别的思路,无法对识别过程中出现的错误进行分析总结并做针对性处理,无法在识别并列中文名词短语的边界信息时融合并列连词和以顿号为代表的标点符号的识别,无法对最外层的连接标识进行了识别,造成中文并列名词短语识别的针对性差,无法达到工业化应用的标准。
发明内容
为了解决以上问题,本申请提出并列中文名词短语精准识别方法及模型,采用STEc将并列中文名词短语识别问题转换为联合词概率建模问题,采用STEc融合词汇特征、词性特征、词长特征以及三种结构特征对并列中文名词短语边界及连接标识进行识别,对识别过程中出现的错误进行分析总结并做针对性处理,实现并列中文名词短语精准识别,通过并列中文名词短语可获取语句中丰富的实体信息,获取文本中的实体信息,提高在海量数据中资源定位的准确性,同时有利于信息检索、自动摘要等应用领域的研发,具有巨大的实际意义和广泛的应用前景。
为实现以上技术特征,本申请所采用的技术方案如下:
并列中文名词短语精准识别方法及模型,包括:并列名词短语语料标注和基于STEc的并列名词短语精准识别模型;首先基于名词短语和并列结构所具有的特征,总结得到并列中文名词短语的定义,结合中文树库给出并列中文名词短语的模型化定义,设计抽取算法对语料中并列中文名词短语进行抽取,构建一个并列中文名词短语语料库,在抽取过程中对语料中的错误进行针对性处理;然后,基于CTB的语料对并列中文名词短语从并列标识、名词短语内部词性序列及并列中文名词短语类型三个方面进行分析总结并列中文名词短语具有的特点;将并列中文名词短语识别问题转换为联合词概率建模问题,采用STEc优化模型对并列中文名词短语边界和连接标识进行识别,根据并列中文名词短语所具有的语言学特征进行特征选取并制定相应的特征模板,对并列名词短语进行识别;
(一)并列名词短语语料标注包括:并列中文名词短语抽取方法、并列中文名词短语特征解析、语料错误解析;基于CTB语料中语句短语结构树,统计语料中标点符号以及并列连词的出现频率,然后根据语料结合并列中文名词短语的定义给出并列中文名词短语模型化定义用于语料中并列中文名词短语边界信息的抽取,并给出并列中文名词短语边界信息的抽取方法,再基于语料对并列中文名词短语进行分析,便于后续对并列中文名词短语识别的特征选取,最后提出语料中存在的语料标注错误,对影响并列中文名词短语正确性的错误进行人工校正;
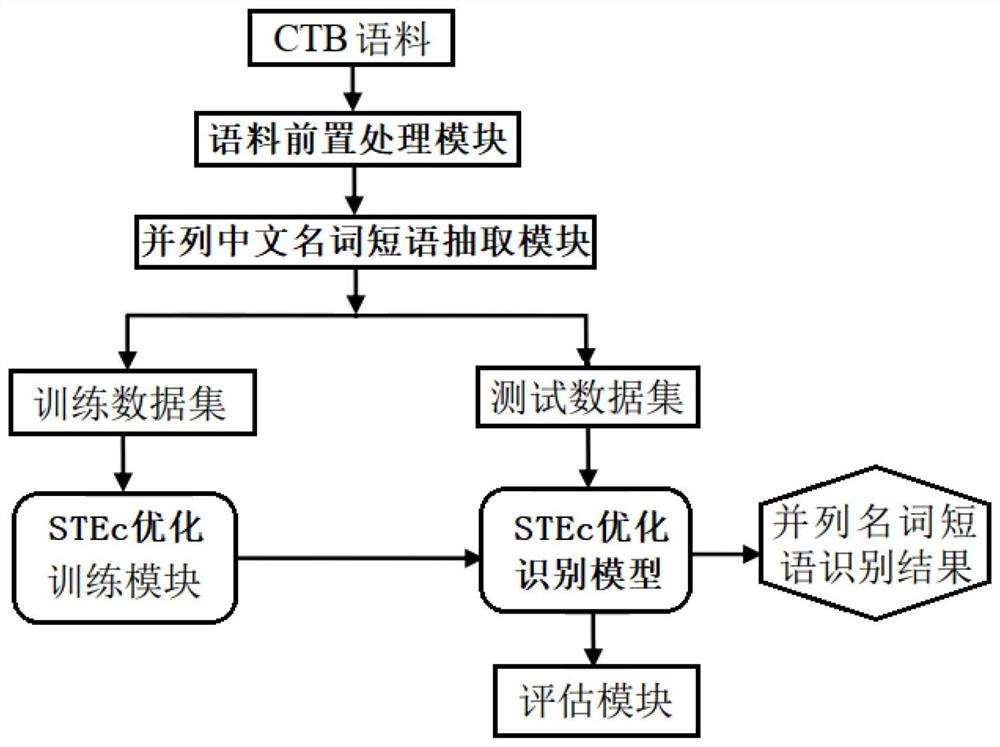
(二)基于STEc的并列名词短语精准识别模型包括:STEc的无向优化模型、STEc调和序列表示、联合词概率建模、STBc优化模型参数估计、标识集选取、并列名词特征选取、并列短语特征模板;基于STEc优化模型的并列中文名词短语识别流程为:
第一步,将CTB语料通过语料前置处理模块进行前置处理,将结果用于并列中文名词短语抽取模块,将语料中的并列中文名词短语标注出来并进行人工校正,将最终的并列中文名词短语语料用于STEc优化识别模型;
第二步,将标注好并列中文名词短语的语料划分为训练数据集以及测试数据集,从语料中分析并列中文名词短语的特征,选取特征并制定相应的特征模板,特征在STEc优化识别模型中起重要作用,用于STEc训练模型对识别模型进行训练;
第三步,通过训练得到的STEc优化识别模型,将测试数据集及对应的特征模板作为输入进行并列中文名词短语和连接标识的识别,将模型最后预测的结果作为输出,并对识别进行评估,得到最终的评估结果。
并列中文名词短语精准识别方法及模型,进一步的,并列中文名词短语抽取方法:采用CTB语料中标注的括号信息将语句转换为对应的语句结构树,对CTB语料自动抽取并列中文名词短语边界信息以及最外层连接标识信息,用于并列中文名词短语的识别;
并列中文名词短语定义为:两个及两个以上名词或者名词短语通过连接标识连接组合成的并列结构,连接标识包括并列连词和标点符号;
并列中文名词短语的模型化定义使用符号CoMk表示连接标识即顿号、并列连接词;
模型化定义一:当两项名词短语或名词通过一个连接标识并列时有:
x*ZMD+CoMk+y*ZMD
其中x,y为非0的正整数,ZMD为名词短语;
模型化定义二:当两项及以上的名词短语通过多个连接标识并列时,以三项名词短语并列为例定义多项并列中文名词短语即:
x*ZMD+CoMk+y*ZMD+CoMk+z*ZMD+other
其中x,y,z为非0的正整数,other表示类似于“等、等等、……”类的省略情况;
抽取边界信息:先将每个语句对应的括号嵌套的形式转换为树结构的形式,对每个语句建立一颗语句树,然后根据并列中文名词短语模型化定义结合树结构的遍历算法遍历每棵语句树,从中找出符合模型化定义的并列中文名词短语并标识出并列中文名词短语的边界信息。
并列中文名词短语精准识别方法及模型,进一步的,STEc的无向优化模型:定义无向图F=(U,B)表示概率分布,其中U表示图中节点的集合,并且节点u∈U表示一个随机变量Y
Q(Y
对任意节点u成立,则概率分布Q(Y|X)为STEc,其中k-u表示在无向图F=(U,B)中与节点u有边连接的所有节点k,k≠u表示节点u以外的所有节点,Y
Q(Y
其中,i=2,1,…,m,在i=1和m时只考虑单边,则Q(Y|X)为STEc线性链,在联合词概率建模时中,X表示输入观测序列,Y表示对应的输出标识序列或状态序列。
并列中文名词短语精准识别方法及模型,进一步的,STEc调和序列表示:调和序列是在图结构中的最大团上严格非负、实数值序列,在用STBc构建联合词概率建模模型时,观察序列X=(X
其中r
定义特征函数前,先构造观察序列的实数特征值e(X,j)集合来描述训练数据的经验分布特征,这些特征与模型同分布,如:
每个特征函数表示一个实数值的观察特征e(X,j),如果当前状态或前一个状态和当前状态具有特定值,则所有特征都是实数值,统一转移函数和状态函数,将状态函数写成如下形式:
c
并用g
R为总观察时刻,对已知的观察序列X=(X
其中,V(X)是归一化因子,引入归一化因子Z保证调和序列的乘积满足概率公理,且是图F=(U,B)中节点所表示随机变量的联合概率分布,归一化因子形式为:
表示出Q(Y|X)。
并列中文名词短语精准识别方法及模型,进一步的,联合词概率建模:通过建立STEc统计模型Q(Y|X)求解联合词概率建模,是STEc统计模型的预测问题,已知STEc模型Q(Y|X)和输入观察序列X,求条件概率最大的输出标注序列Y
其中为求得条件概率最大的标注序列Y
并列中文名词短语精准识别方法及模型,进一步的,STBc优化模型参数估计:基于最大熵模型给定训练数据集A={(X
并列中文名词短语精准识别方法及模型,进一步的,标识集选取:并列中文名词短语识别任务转化为联合词概率建模问题,首先根据对实验语料中的并列中文名词短语进行标注,本申请采用的语料库已经过分词及词性标注,那么应选取一种适合并列中文名词短语识别的标识方法,用于识别模型的输入;
当由多个词组成的语块时,E表示当前词为组块的开始,J表示当前词为组块的内部,B表示当前词为组块的结束;当由一个词组成的语块时,C表示组块,Y表示组块的外部,再增加一种连接标识符号的标注方法对并列中文名词短语的边界及最外层连接标识进行标注,语句中每个词包括标点符号采用{E、Y、J、R、B}进行标注,E表示并列中文名词短语的开始,J表示并列中文名词短语的内部,B表示并列中文名词短语的结束,R表示并列中文名词短语内部最外层连接标识。
并列中文名词短语精准识别方法及模型,进一步的,并列名词特征选取:采用词汇特征、词性特征及其词词长、并列中文名词短语结构特征对并列中文名词短语进行识别;
特征一:词特征,STEc优化模型通过词与词之间的差异性寻找词本身的内部特征;
特征二:词性特征,是指一个词对应的词性,对并列中文名词短语边界识别很重要;
特征三:词长特征,即一个词由多少个汉字组成;
特征四:结构特征,通过本申请对并列中文名词短语的语言学特征分析,得到一些结构特征用于STEc优化识别模型的训练以提高并列中文名词短语边界的识别效果;
第一,从词的角度,构成并列中文名词短语的各并列项中可能含有相同的词,采用该特点对并列名词短语边界奖项识别;
第二,从名词短语词性序列及并列结构特征的角度,构成并列中文名词短语中各并列项的词性序列以及含有的词的个数相同,由连接标识顿号分隔的名词短语对应的词序相同,采用这种连接标识前后词序相同的结构特征对并列中文名词短语边界进行识别。
并列中文名词短语精准识别方法及模型,进一步的,并列短语特征模板:根据词特征、词性特征、词长特征以及三种结构特征制定STEc优化识别模型的特征模板,采用k
词特征一元特征模板:模板<一元词特征>;符号表示 词特征二元特征模板:模板<二元词特征>;符号表示 对词性的m元特征模板进行选取时,词性特征在选取一元特征、二元特征及三元特征时效果最佳,制定的词性特征模板为: 词性特征模板<一元词性特征>;符号表示 词性特征模板<二元词性特征>;符号表示 词性特征模板<三元词性特征>;符号表示 对三种结构特征制定相应的特征模板,通过实验分析得到三种结构特征模板相同,都选取一元特征模板为最优,语句C对应的结构特征标注序列为c 与现有技术相比,本申请的创新点和优势在于: 第一,目前针对并列中文名词短语的研究应用包括并列中文名词短语消歧、并列中文名词短语的语言学特征等方面,现有技术还没有专门针对并列中文名词短语识别的方法。本申请基于自然语言处理中语块分析中的组块识别,提出并列中文名词短语精准识别方法及模型,总结本申请的创新点包括:一是本申请将并列中文名词短语识别问题转换为联合词概率建模问题;二是提出的并列中文名词短语识别方法及模型,提出在采用STEc模型识别并列中文名词短语的边界信息时融合了并列连词和以顿号为代表的标点符号的识别,对最外层的连接标识进行了识别;因此,本申请能对并列名词短语进行有效的识别,针对中文识别的可靠性好,具备鲁棒性和稳定性好的识别模型,并列名词短语边界识别准确率和F值较高,连接标识的识别F也较高,因而能够实现中文并列名词短语的精准识别; 第二,本申请提出并列中文名词短语精准识别方法及模型,采用STEc将并列中文名词短语识别问题转换为联合词概率建模问题,采用STEc融合词汇特征、词性特征、词长特征以及三种结构特征对并列中文名词短语边界及连接标识进行识别,对识别过程中出现的错误进行分析总结并做针对性处理,实现并列中文名词短语精准识别,通过并列中文名词短语可获取语句中丰富的实体信息,获取文本中的实体信息,提高在海量数据中资源定位的准确性,同时有利于信息检索、自动摘要等应用领域的研发,具有巨大的实际意义和广泛的应用前景; 第三,本申请基于名词短语和并列结构所具有的特征,总结得到并列中文名词短语的定义,结合中文树库给出并列中文名词短语的模型化定义,设计对应的抽取算法对语料中并列中文名词短语进行抽取,构建一个并列中文名词短语语料库,在抽取过程中基于语料中存在的错误,进行了针对性处理;基于CTB的语料对并列中文名词短语从并列标识、名词短语内部词性序列及并列中文名词短语类型三个方面进行分析总结并列中文名词短语具有的特点;采用STEc对并列中文名词短语边界和连接标识进行识别,根据并列中文名词短语所具有的语言学特征进行特征选取并制定相应的特征模板,并列中文名词短语边界识别模型获得了75.59%的F值,经过十折交叉验证获得最后的F值为72.39%;对连接标识的识别的F值达到了94.95%,根据本申请的训练得到的识别模型设计并实现一个并列中文名词短语识别小工具,具有精准的识别性能,针对中文名词短语识别相比于现有技术具有很大优势; 第四,并列中文名词短语属于并列短语的一种,对并列中文名词短语进行精准识别,能够对语块分析提供帮助,本申请并列中文名词短语精准识别对自然语言处理多个应用领域都有极为重要的作用,比如信息检索、文本摘要等。并列中文名词短语承载了丰富的实体信息,通过识别并列中文名词短语,获取文本中较具体的实体信息,有利于自然语言处理中自动摘要,机器翻译、信息检索等应用领域,通过输入的检索信息准确定位到目标资源,对提高信息检索的质量非常重要,识别并列中文名词短语能够改善信息检索的质量,提高检索的准确性。正确识别并列中文名词短语中各并列项的边界能够帮助消除自然语言中的歧义,帮助提高语块分析的精确率,降低句法分析难度,通过对并列中文名词短语的识别和分析能够简化语句,从而降低句法分析的难度。 附图说明 图1是基于STEc优化模型的并列中文名词短语识别流程图。 图2是本申请线性STEc模型示意图。 图3是词特征模板随m元特征变化的F值趋势示意图。 图4是并列中文名词短语识别小工具界面截图一。 图5是并列中文名词短语识别小工具界面截图二。 具体实施方法 下面结合附图,对本申请提供的并列中文名词短语精准识别方法及模型的技术方案进行进一步的描述,使本领域的技术人员能够更好的理解本申请并能够予以实施。 语块分析在自然语言处理中起到了非常关键的作用,并列中文名词短语精准识别有助于并列结构的识别,简化语句结构,降低语块分析的难度;对自然语言处理的多个应用领域中都有着非常重要的作用,包括在信息检索和文本摘要等应用领域中能迅速锁定文本中的实体,以方便检索的定位以及提高文本摘要的准确性。 本申请首先基于名词短语和并列结构所具有的特征,总结得到并列中文名词短语的定义,结合中文树库给出并列中文名词短语的模型化定义,设计对应的抽取算法对语料中并列中文名词短语进行抽取,构建一个并列中文名词短语语料库,在抽取过程中基于语料中存在的错误,进行了针对性处理;然后,基于CTB的语料对并列中文名词短语从并列标识、名词短语内部词性序列及并列中文名词短语类型三个方面进行分析总结并列中文名词短语具有的特点;将并列中文名词短语识别问题转换为联合词概率建模问题,采用STEc优化模型对并列中文名词短语边界和连接标识进行识别,根据并列中文名词短语所具有的语言学特征进行特征选取并制定相应的特征模板,对并列名词短语进行识别。 实验表明,本申请提出的将并列名词短语识别问题转换为联合词概率建模问题的方法的有效性,并列名词短语识别精准高效,本申请采用的基于STEc模型的并列中文名词短语边界识别实验最终在测试数据集上获得的准确率为76.67%,F值为75.59%;连接标识的识别获得了94.95%的F值。为保证模型的稳定性,进行了十折交叉验证,最终并列中文名词短语边界识别获的了72.39%的F值,本申请最后根据训练得到的STEc的识别模型构建一个识别小工具对给定的语句中的并列中文名词短语及连接词进行识别。 一、并列名词短语语料标注 (一)并列中文名词短语抽取方法 本申请采用CTB语料中标注的括号信息将语句转换为对应的语句结构树,对CTB语料自动抽取并列中文名词短语边界信息以及最外层连接标识信息,用于并列中文名词短语的识别。 1.并列中文名词短语模型化定义 并列中文名词短语定义为:两个及两个以上名词或者名词短语通过连接标识连接组合成的并列结构,连接标识包括并列连词和标点符号。 并列中文名词短语的模型化定义使用符号CoMk表示连接标识即顿号、并列连接词。 模型化定义一:当两项名词短语或名词通过一个连接标识并列时有: x*ZMD+CoMk+y*ZMD 其中x,y为非0的正整数,ZMD为名词短语; 模型化定义二:当两项及以上的名词短语通过多个连接标识并列时,以三项名词短语并列为例定义多项并列中文名词短语即: x*ZMD+CoMk+y*ZMD+CoMk+z*ZMD+other 其中x,y,z为非0的正整数,other表示类似于“等、等等、……”类的省略情况。 2.抽取边界信息 先将每个语句对应的括号嵌套的形式转换为树结构的形式,对每个语句建立一颗语句树,然后根据并列中文名词短语模型化定义结合树结构的遍历算法遍历每棵语句树,从中找出符合模型化定义的并列中文名词短语并标识出并列中文名词短语的边界信息。 (二)并列中文名词短语特征解析 基于并列中文名词短语的定义对CTB语料对并列中文名词短语进行统计:得到含并列成分的语句总数为10739,包含的并列成分总数为14374;含并列中文名词短语的语句总数为7908,包含的并列中文名词短语总数为10319,结果表明并列成分在中文书面表达中使用广泛,占所有语句的36.71%,其中并列中文名词短语占并列成分所有并列成分的73.65%,并列中文名词短语在并列结构中占很大比例,因此并列中文名词短语在书面表达中使用非常广泛。通过对CTB语料中并列连接标识、构成并列中文名词短语的名词短语内部词性序列分布、并列中文名词短语类型分布进行分析获取关于并列中文名词短语的关联语言学信息,便于后续识别。 1.并列连接标识解析 并列中文名词短语含有并列连接标识,对顿号和逗号这两种标点结合语料详细分析得出: 第一、顿号表示同类事物间并列时的停顿,比如词或者短语间的并列,顿号表示的并列在语料中占的比重也非常的大,采用顿号标点作为本申请连接标识的一种非常合理; 第二、逗号在现在中文书面表达中使用最为广泛也最为重要,通常用于语句内部,表示停顿,逗号也可以表达并列关系,由逗号表示的并列关系需要考虑并列各项之间的语义信息,在表达并列关系上没有顿号表达明显,因此基于逗号的并列关系识别是一个重难点,本申请只考虑标点符号中的顿号表示的并列中文名词短语。 2.名词短语内部词性序列分布解析 对并列中文名词短语中名词短语的结构类型进行详细分析,为并列中文名词短语识别过程中特征选取提供更丰富的语言学依据。从CTB语料中统计得到5625个并列中文名词短语,对并列中文名词短语中名词短语内部的词序进行统计,为了直观表示名词短语的词性序列分布情况,将连续的m(m≥1)个名词词类合并为一个名词性标识MM进行统计得到1196种不同结构的名词短语。得到名词短语的结构类型按出现频次排名的前10位的词性序列,词性序列为MM在语料中的并列中文名词短语中占的比例最大,其次是II MM在含修饰语的名词短语中占相当大的比重,名词短语还含有连接词的词性序列MM SS MM在整体的名词短语词性序列中也占有一定比例,最常见的是1至3范围内的名词短语,含一个名词参与构成的名词短语使用最广泛,其次是4至6范围内的名词短语,仅由7个及以上的名词连续构成名词短语存在但相对少,因此本申请对并列中文名词短语中由仅含名词构成的名词短语的识别重点在1至6范围内。 3.并列中文名词短语类型分布解析 通过对并列中文名词短语中名词短语内部词性序列分析,从含有连接标识的个数、仅含并列连词的连接标识的个数、仅含顿号的连接标识的个数、同时含有两种标识的连接标识的个数的角度对并列中文名词短语的类型分布进行统计,含一个连接标识连接的并列中文名词短语在语料中最多,约占79.98%,其次是含有两个连接标识和三个连接标识的情况,因此本申请并列中文名词短语识别的重点在连接标识个数为1至3个的情况,在仅含有一个连接标识的情况中,连接标识为并列连词的比重最大,约占76.01%;含两个连接标识的情况中,连接标识为顿号的比重最大,约占52.98%,其次是顿号和并列连词,约占43.02%。顿号在并列中文名词短语中使用非常广泛,并列连词通常连接两项名词短语或三项名词短语,在连接两项名词短语中最常用。 (三)语料错误解析 CTB语料根据一定的语料标注规则人工标注,每个人对相同标准的理解以及细心程度存在差异,语料标注过程中存在标注错误也很难避免。针对并列中文名词短语识别的问题,对本申请用到CTB语料进行检查,发现存在一些语料标注的错误包括: 错误一:括号位置标注错误导致的并列结构层次不明确; 错误二:括号多余标注错误导致的成分的遗漏。 二、基于STEc的并列名词短语精准识别模型 通过对STEc优化模型的标识集的选取以及并列中文名词短语特征的选取,结合本申请制定的并列中文名词短语的特征模板,用于STEc优化识别模型中,如图1所示,基于STEc优化模型的并列中文名词短语识别流程为: 第一步,将CTB语料通过语料前置处理模块进行前置处理,将结果用于并列中文名词短语抽取模块,将语料中的并列中文名词短语标注出来并进行人工校正,将最终的并列中文名词短语语料用于STEc优化识别模型; 第二步,将标注好并列中文名词短语的语料划分为训练数据集以及测试数据集,从语料中分析并列中文名词短语的特征,选取适合的特征并制定相应的特征模板,特征在STEc优化识别模型中起重要作用,用于STEc训练模型对识别模型进行训练; 第三步,通过训练得到的STEc优化识别模型,将测试数据集及对应的特征模板作为输入进行并列中文名词短语和连接标识的识别,将模型最后预测的结果作为输出,并对识别进行评估,得到最终的评估结果。 (一)STEc的无向优化模型 定义无向图F=(U,B)表示概率分布,其中U表示图中节点的集合,并且节点u∈U表示一个随机变量Y Q(Y 对任意节点u成立,则概率分布Q(Y|X)为STEc,其中k-u表示在无向图F=(U,B)中与节点u有边连接的所有节点k,k≠u表示节点u以外的所有节点,Y Q(Y 其中,i=2,1,…,m,在i=1和m时只考虑单边,则Q(Y|X)为STEc线性链,在联合词概率建模时中,X表示输入观测序列,Y表示对应的输出标识序列或状态序列。 (二)STEc调和序列表示 调和序列是在图结构中的最大团上严格非负、实数值序列,在用STBc构建联合词概率建模模型时,观察序列X=(X
其中r 定义特征函数前,先构造观察序列的实数特征值e(X,j)集合来描述训练数据的经验分布特征,这些特征与模型同分布,如:
每个特征函数表示一个实数值的观察特征e(X,j),如果当前状态或前一个状态和当前状态具有特定值,则所有特征都是实数值,统一转移函数和状态函数,将状态函数写成如下形式: c 并用g
R为总观察时刻,对已知的观察序列X=(X
其中,V(X)是归一化因子,引入归一化因子Z保证调和序列的乘积满足概率公理,且是图F=(U,B)中节点所表示随机变量的联合概率分布,归一化因子形式为:
表示出Q(Y|X)。 (三)联合词概率建模 通过建立STEc统计模型Q(Y|X)求解联合词概率建模,是STEc统计模型的预测问题,已知STEc模型Q(Y|X)和输入观察序列X,求条件概率最大的输出标注序列Y
其中为求得条件概率最大的标注序列Y (四)STBc优化模型参数估计 基于最大熵模型给定训练数据集A={(X (五)标识集选取 本申请并列中文名词短语识别任务转化为联合词概率建模问题,首先根据对实验语料中的并列中文名词短语进行标注,本申请采用的语料库已经过分词及词性标注,那么应选取一种适合并列中文名词短语识别的标识方法,用于识别模型的输入; 当由多个词组成的语块时,E表示当前词为组块的开始,J表示当前词为组块的内部,B表示当前词为组块的结束;当由一个词组成的语块时,C表示组块,Y表示组块的外部,再增加一种连接标识符号的标注方法对并列中文名词短语的边界及最外层连接标识进行标注,语句中每个词包括标点符号采用{E、Y、J、R、B}进行标注,E表示并列中文名词短语的开始,J表示并列中文名词短语的内部,B表示并列中文名词短语的结束,R表示并列中文名词短语内部最外层连接标识,如实施例1所示:三(CD)年(M)多(AD)来(LC),(QU)全(DR)省(MM)先后(AD)投入(UU)五十五亿(CD)元(M)进行(UU){口岸(MM)码头(MM)、(QU)基地(MM)场地(MM)及(SS)配套(MM)设施(MM)的(DEC)建设(MM)和(SS)半岛(MM)基础(MM)设施(MM)建设(MM)},(QU)为(Q)构建(UU)大(JJ)湾区(MM)出海(JJ)通道(MM)创造(UU)良好(UA)的(DEC)条件(MM)。(QU)。采用本申请标注方法,实施例1对应的标注的结果为:YYYYYYYYYYYEJJJJJJJJRJJJBYYYYYYYYYYYYY。 (六)并列名词特征选取 采用词汇特征、词性特征及其词词长、并列中文名词短语结构特征对并列中文名词短语进行识别。 特征一:词特征,STEc优化模型通过词与词之间的差异性寻找词本身的内部特征; 特征二:词性特征,是指一个词对应的词性,对并列中文名词短语边界识别很重要; 特征三:词长特征,即一个词由多少个汉字组成; 特征四:结构特征,通过本申请对并列中文名词短语的语言学特征分析,得到一些结构特征用于STEc优化识别模型的训练以提高并列中文名词短语边界的识别效果。 第一,从词的角度,构成并列中文名词短语的各并列项中可能含有相同的词,采用该特点对并列名词短语边界奖项识别; 第二,从名词短语词性序列及并列结构特征的角度,构成并列中文名词短语中各并列项的词性序列以及含有的词的个数相同,由连接标识顿号分隔的名词短语对应的词序相同,采用这种连接标识前后词序相同的结构特征对并列中文名词短语边界进行识别。 (七)并列短语特征模板 根据词特征、词性特征、词长特征以及三种结构特征制定STEc优化识别模型的特征模板,采用k 词特征一元特征模板:模板<一元词特征>;符号表示 词特征二元特征模板:模板<二元词特征>;符号表示 对词性的m元特征模板进行选取时,词性特征在选取一元特征、二元特征及三元特征时效果最佳,制定的词性特征模板为: 词性特征模板<一元词性特征>;符号表示 词性特征模板<二元词性特征>;符号表示 词性特征模板<三元词性特征>;符号表示 对三种结构特征制定相应的特征模板,通过实验分析得到三种结构特征模板相同,都选取一元特征模板为最优,语句C对应的结构特征标注序列为c 三、、并列中文名词短语识别小工具 根据本申请得到的基于STEc优化识别模型运用JaUa编程框架以及E/S结构搭建了一个网页版的小工具用于对给定的语句进行并列中文名词短语边界以及连接标记的识别。具体识别效果如图4和图5所示。图4和图5中是对输入的一个语句,首先进行分词和词性标注,这个小工具中使用Ancj的分词工具以及斯坦福的词性标注,然后用本申请的STEc优化识别模型进行预测,得到的结果如图中黑框框所示。通过这个小工具的实现,将并列中文名词短语的识别模型进行初步的实际应用。 四、实验分析 首先对实验中用的数据的标注一致性进行验证,给出实验的评价标准。选取句法分析的现有模型Stanford Parser和Berkeley Parser对测试数据集进行并列中文名词短语边界识别和连接标识识别;结合本申请选取的六种特征设置六组实验进行STEc并列中文名词短语边界识别实验和连接标识识别实验。本申请提出的基于STEc优化模型的并列中文名词短语边界识别实验获得的F值为75.59%,准确率为76.67%。为保证模型的稳定性,进行十折交叉验证最后并列中文名词短语边界识别获的了72.39%的F值;连接标识的识别获得了94.95%的F值。
- 并列中文名词短语精准识别方法及模型
- 中文模型训练、中文图像识别方法、装置、设备及介质