一种高炉炉温预测方法、装置、设备和存储介质
文献发布时间:2024-04-18 19:58:26
技术领域
本申请涉及高炉冶炼技术领域,尤其是涉及一种高炉炉温预测方法、装置、设备和存储介质。
背景技术
高炉冶炼系统是一个封闭、非线性、难以直接测量的系统,通常以测量铁水含硅量间接实现对高炉炉温的测量,同时,高炉冶炼系统具有高维、大时滞、多分布参数等特点,若仅采用某一种或某几种特定变量,以及采用某一种或某几种特定的预测模型,往往只能对某一类高炉的炉温进行预测,一旦高炉的工况发生变化,则需要人工对影响炉温的变量进行重新选择和验证,费时费力。
如相关技术中,申请号为CN110427715A的中国专利,公开了一种基于时间序列和高炉多维度的炉缸热状态趋势预测的方法,利用物质流运动规律、动态时间序列相关性分析法依次给出高炉冷却壁立体水温差对炉缸温度响应的滞后时间,计算泊松相关系数确定有效的历史炉温时间序列及与炉温预测相关的其它过程参数;再利用立体高炉各指标参数及其相关历史信息,建立基于时间序列和高炉多维度的PSO-LSSVM炉缸热状态预测模型,验证高炉冷却壁立体水温差的多维性变化对炉缸热状态变化趋势预测的准确性。然而,Pearson相关系数可以有效的度量数据的线性相关性,但是难以对高炉冶炼系统的非线性变量之间的相关性进行描述,同时,也难以应对较大的数据量,如在该专利的实施例中提到,“选取某高炉不同工况下的生产数据386组,其中选取训练样本240组,剩余的146组数作为测试样本”“水温差数据采样周期为1小时”,相对来高炉系统的海量数据而言,数量级较小。
因此,申请人认为,在上述中的相关技术,存在难以对高炉冶炼系统的非线性变量之间的相关性进行描述以及难以应对较大的数据量的问题。
发明内容
本申请的目的是提供一种高炉炉温预测方法、装置、设备和存储介质,以至少部分解决上述技术问题。
第一方面,本申请提供的高炉炉温预测方法采用如下的技术方案:
一种高炉炉温预测方法,包括以下步骤:
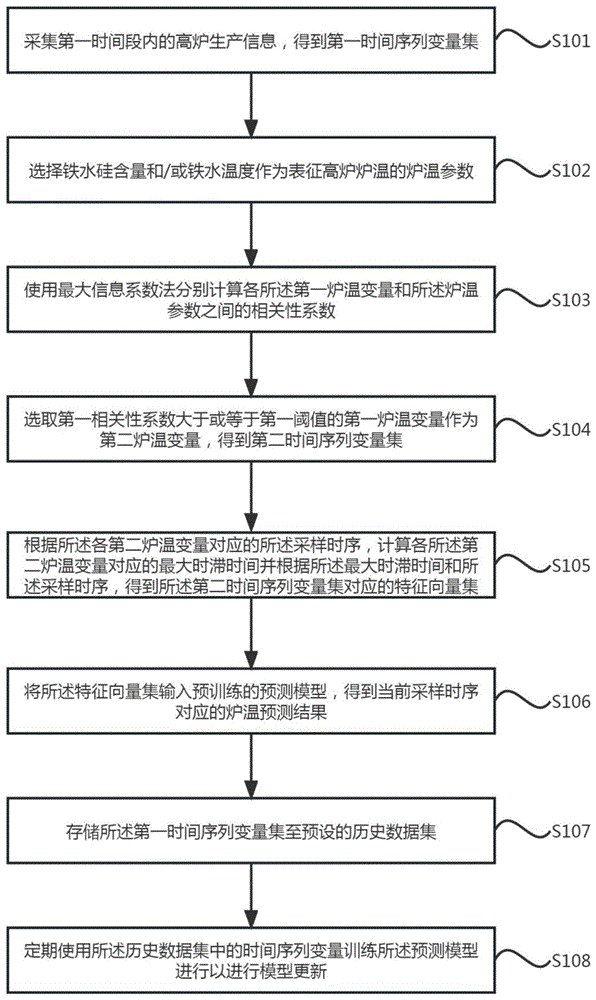
采集第一时间段内的高炉生产信息,得到第一时间序列变量集,其中,所述第一时间序列变量集包括采样时序和所述采样时序对应的第一炉温变量,所述第一时间段为临近当前采样时序的多个历史采样时序组成;
选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
使用最大信息系数法分别计算各所述第一炉温变量和所述炉温参数之间的相关性系数;
选取第一相关性系数大于或等于第一阈值的第一炉温变量作为第二炉温变量,得到第二时间序列变量集;
根据所述各第二炉温变量对应的所述采样时序,计算各所述第二炉温变量对应的最大时滞时间并根据所述最大时滞时间和所述采样时序,得到所述第二时间序列变量集对应的特征向量集;
将所述特征向量集输入预训练的预测模型,得到当前采样时序对应的炉温预测结果。
通过采用上述技术方案,能够得到用于预测炉温的第一时间序列变量集,由于选取的是临近当前时序的历史变量,预测结果将更为准确,同时,第一时间段可根据实际生产情况进行划定,以进一步提高预测的精准度;
由于高炉的特殊性,无法直接测量高炉内部温度,通常选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
同时,影响高炉炉温的炉温变量较多,采用最大信息系数法计算炉温参数和炉温变量之间的相关性,不仅能够更好地应对高炉冶炼系统非线性的特点,而且能够避免噪声影响,提高预测模型的稳健性;
通过设置第一阈值,能够排除一部分与炉温参数相关度较低的炉温变量,在后续预测时,能够提高预测的精准度和速度;
通过计算最大时滞时间,能够消除炉温变量的滞后性,进一步提高预测的准确度;
最终得到了与炉温参数相关性较高并且消除了滞后性的特征向量集,以该特征向量集作为预测模型的输入,能够取得较好的预测结果。
可选的,所述第一炉温变量包括风量、风压、压差、富氧量、鼓风湿度、鼓风动能、煤气利用率、顶温平均值、十字测温Z值、十字测温W值、前两个采样时序的炉温参数和人为操作中的一种或多种,所述第一时间序列变量集对应的所述炉温参数的炉温预测结果为后两个采样时序的炉温参数。
通过采用上述技术方案,由于采用了最大信息系数法计算相关度,能将更多的炉温变量纳入考虑范围,进一步提高预测的准确度,其中,人为操作可以是任一采样时序对任一变量人为进行的修改。
可选的,所述预训练的预测模型包括贝叶斯模型、支持向量机模型、随机森林模型、BP神经网络模型、LR模型、GBR模型、xgboost模型、lightgbm模型、PLSR模型以及adaboost模型中的一种或多种。
通过采用上述技术方案,由于本申请中,将更多的炉温变量纳入了考虑范围,以及高炉冶炼本身的复杂性,因此不同预测模型在不同炉温变量下的预测结果往往各有优势,而使用一种以上的预测模型对炉温进行预测,能够得到多种预测结果,再进行比较后,能得到更为精准的预测结果。
可选的,同时使用多种预训练的预测模型对炉温进行预测,得到多个炉温预测结果,根据预设的评价指标,对所述多个炉温预测结果进行评价,输出最优炉温预测结果;
所述评价指标包括相关指数R
获取所述多个炉温预测结果对应的评价指标,所述评价指标包括相关指数R
分别对所述各炉温预测结果的第一命中率、第二命中率和第三命中率进行比较,选择第一命中率最高的第一炉温预测结果、第二命中率最高的第二炉温预测结果和第三命中率最高的第三炉温预测结果作为第一候选结果;
对第一候选结果中各炉温预测结果对应的相关指数R
对第二候选结果中各炉温预测结果对应的均方根误差进行比较,选择均方根误差最低的炉温预测结果作为最优炉温预测结果。
通过采用上述技术方案,能够在多个炉温预测模型中,选择最适合当前时序变量的预测模型,输出最佳预测结果。
可选的,计算所述相关性系数的步骤包括:
S1031、根据预设的尺度(i,j),对某一炉温变量和所述炉温参数构成的散点图进行网格化,得到该散点图对应的若干i行i列的网格化散点图,每个所述网格化散点图被划分为i*j个单元;
S1032、分别计算各个网格化散点图中各单元对应的互信息值并求和,得到若干第一互信息值;
S1033、选取所述若干第一互信息值中最大值作为当前预设尺度下的最大互信息值;
S1034、对所述最大互信息值进行归一化,得到当前预设尺度对应的第二互信息值;
S1035、重复S1031至S1034,获取所有预设尺度对应的第二互信息值,选择各预设尺度对应的第二互信息值中,数值最大的第二互信息值,作为目标炉温变量和所述炉温参数之间的相关性系数;
S1036、重复S1031至S1035,获取第一炉温变量中,所有炉温变量和所述炉温参数之间的相关性系数。
通过采用上述技术方案,能够准确地得到各炉温变量与炉温参数之间的相关性系数。
可选的,所述预训练的预测模型的训练步骤包括:
将预存储的高炉生产信息对应的时间序列变量集划分为训练集、验证集和测试集;
确定预测模型的超参数和各超参数的初始值;
使用训练集对预测模型进行训练,直到找到使目标预测模型损失函数最小的第一最优函数时停止训练;
使用网格搜索算法在验证集中对所述第一最优函数进行度量以获得目标预测模型的超参数组合,计算并保存目标预测模型的相关指数R
获得目标预测模型的最优超参数组合时停止训练;
整合训练集和验证集后,对最优超参数组合中均方根误差最小的目标预测模型进行训练,直到找到使目标预测模型损失函数最小的第二最优函数时停止训练;
使用测试集对目标模型的第二最优函数的泛化性能进行度量。
通过采用上述技术方案,能够根据给出的训练数据,自动获得对应的最优参数组合,在提高预测精准度的同时,便于后续获得新的训练数据时,及时对预测模型进行更新。
可选的,还包括存储所述第一时间序列变量集至预存储的历史数据集;
定期使用所述历史数据集中的时间序列变量训练所述预测模型进行以进行模型更新。
通过采用上述技术方案,能够对预测模型进行持续更新迭代,以保证预测的准确度。
第二方面,本申请提供的高炉炉温预测装置采用如下的技术方案:
一种高炉炉温预测装置,包括:
第一采集模块,用于采集第一时间段内的高炉生产信息,得到第一时间序列变量集,其中,所述第一时间序列变量集包括采样时序和所述采样时序对应的第一炉温变量,所述第一时间段为临近当前采样时序的多个历史采样时序组成;
第二采集模块,用于选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
第一运算模块,用于使用最大信息系数法分别计算各所述第一炉温变量和所述炉温参数之间的相关性系数;
第二运算模块,用于选取第一相关性系数大于或等于第一阈值的第一炉温变量作为第二炉温变量,得到第二时间序列变量集;
第三运算模块,用于根据所述各第二炉温变量对应的所述采样时序,计算各所述第二炉温变量对应的最大时滞时间并根据所述最大时滞时间和所述采样时序,得到所述第二时间序列变量集对应的特征向量集;
预测模块,用于将所述特征向量集输入预训练的预测模型,得到当前采样时序对应的炉温预测结果。
第三方面,本申请提供一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面中任一项所述的高炉炉温预测方法。
第四方面,本申请提供一种计算机可读存储介质,存储有能够被处理器加载并执行如第一方面中任一项所述的高炉炉温预测方法的计算机程序。
综上所述,本申请包括以下至少一种有益技术效果:
能够得到用于预测炉温的第一时间序列变量集,由于选取的是临近当前时序的历史变量,预测结果将更为准确,同时,第一时间段可根据实际生产情况进行划定,以进一步提高预测的精准度;
由于高炉的特殊性,无法直接测量高炉内部温度,通常选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
同时,影响高炉炉温的炉温变量较多,采用最大信息系数法计算炉温参数和炉温变量之间的相关性,不仅能够更好地应对高炉冶炼系统非线性的特点,而且能够将尽可能多的炉温变量纳入考虑范围,同时,还能够处理更高数量级的数据,提高了预测模型的精准度,另外,也而且能够避免噪声影响,提高预测模型的稳健性;
通过设置第一阈值,能够排除一部分与炉温参数相关度较低的炉温变量,在后续预测时,能够提高预测的精准度和速度;
通过计算最大时滞时间,能够消除炉温变量的滞后性,进一步提高预测的准确度;
最终得到了与炉温参数相关性较高并且消除了滞后性的特征向量集,以该特征向量集作为预测模型的输入,能够取得较好的预测结果。
附图说明
图1是本申请中一种高炉炉温预测的实施方式的第一流程示意图;
图2是本申请中一种高炉炉温预测的实施方式的第二流程示意图;
图3是本申请中一种高炉炉温预测的实施例的第一流程示意图;
图4是本申请中一种高炉炉温预测装置的实施例的结构框图。
具体实施方式
以下结合图1-图4,对本申请作进一步详细说明。
参照图1,本申请公开一种高炉炉温预测的实施方式。
高炉炉温预测方法,包括以下步骤:
S101、采集第一时间段内的高炉生产信息,得到第一时间序列变量集,其中,第一时间序列变量集包括采样时序和采样时序对应的第一炉温变量,第一时间段为临近当前采样时序的多个历史采样时序组成,同时,第一炉温变量包括风量、风压、压差、富氧量、鼓风湿度、鼓风动能、煤气利用率、顶温平均值、十字测温Z值、十字测温W值、前两个采样时序的炉温参数和人为操作中的一种或多种,第一时间序列变量集对应的炉温参数的炉温预测结果为后两个采样时序的炉温参数;
采用本实施方式,能够得到用于预测炉温的第一时间序列变量集,由于选取的是临近当前时序的历史变量,预测结果将更为准确,同时,第一时间段可根据实际生产情况进行划定,以进一步提高预测的精准度,另外,由于后续步骤中采用了最大信息系数法计算相关度,能将更多的炉温变量纳入考虑范围,进一步提高预测的准确度,其中,人为操作可以是任一采样时序对任一变量人为进行的修改。
S102、选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
采用本实施方式,实现了对高炉炉温的间接测量,由于高炉的特殊性,无法直接测量高炉内部温度,通常选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数。
S103、使用最大信息系数法分别计算各第一炉温变量和炉温参数之间的相关性系数;其中,参照图2,计算相关性系数的步骤包括:
S1031、对炉温变量和炉温参数散点图进行网格化,具体为,根据预设的尺度(i,j),对某一炉温变量和炉温参数构成的散点图进行网格化,得到该散点图对应的若干i行i列的网格化散点图,每个网格化散点图被划分为i*j个单元;
S1032、分别计算各个网格化散点图中各单元对应的互信息值并求和,得到若干第一互信息值;
S1033、选取若干第一互信息值中最大值作为当前预设尺度下的最大互信息值;
S1034、对最大互信息值进行归一化,得到当前预设尺度对应的第二互信息值;
S1035、获取某一炉温变量和炉温参数之间相关性系数,具体为,重复S1031至S1034,获取所有预设尺度对应的第二互信息值,选择各预设尺度对应的第二互信息值中,数值最大的第二互信息值,作为目标炉温变量和炉温参数之间的相关性系数;
S1036、获取所有炉温变量和炉温参数之间相关性系数,具体为,重复S1031至S1035,获取第一炉温变量中,所有炉温变量和炉温参数之间的相关性系数;
采用本实施方式,能够将各炉温变量对炉温参数的影响进行量化,由于本申请中,影响高炉炉温的炉温变量较多,采用最大信息系数法计算炉温参数和炉温变量之间的相关性,而且能够避免噪声影响,提高预测模型的稳健性,并且,能够准确地得到各炉温变量与炉温参数之间的相关性系数。
S104、选取第一相关性系数大于或等于第一阈值的第一炉温变量作为第二炉温变量,得到第二时间序列变量集;
采用本实施方式,通过设置第一阈值,能够排除一部分与炉温参数相关度较低的炉温变量,在后续预测时,能够提高预测的精准度和速度。
S105、根据各第二炉温变量对应的采样时序,计算各第二炉温变量对应的最大时滞时间并根据最大时滞时间和采样时序,得到第二时间序列变量集对应的特征向量集;
采用本实施方式,通过计算最大时滞时间,能够消除炉温变量的滞后性,进一步提高预测的准确度。
S106、将特征向量集输入预训练的预测模型,得到当前采样时序对应的炉温预测结果;其中,预训练的预测模型包括贝叶斯模型、支持向量机模型、随机森林模型、BP神经网络模型、LR模型、GBR模型、xgboost模型、lightgbm模型、PLSR模型以及adaboost模型中的一种或多种,若同时使用多种预训练的预测模型对炉温进行预测,得到多个炉温预测结果,则根据预设的评价指标,对多个炉温预测结果进行评价,输出最优炉温预测结果;
评价指标包括相关指数R
获取多个炉温预测结果对应的评价指标,评价指标包括相关指数R
分别对各炉温预测结果的第一命中率、第二命中率和第三命中率进行比较,选择第一命中率最高的第一炉温预测结果、第二命中率最高的第二炉温预测结果和第三命中率最高的第三炉温预测结果作为第一候选结果;
对第一候选结果中各炉温预测结果对应的相关指数R
对第二候选结果中各炉温预测结果对应的均方根误差进行比较,选择均方根误差最低的炉温预测结果作为最优炉温预测结果;
具体的,预训练的预测模型的训练步骤包括:
将预存储的高炉生产信息对应的时间序列变量集划分为训练集、验证集和测试集;
确定预测模型的超参数和各超参数的初始值;
使用训练集对预测模型进行训练,直到找到使目标预测模型损失函数最小的第一最优函数时停止训练;
使用网格搜索算法在验证集中对第一最优函数进行度量以获得目标预测模型的超参数组合,计算并保存目标预测模型的相关指数R
获得目标预测模型的最优超参数组合时停止训练;
整合训练集和验证集后,对最优超参数组合中均方根误差最小的目标预测模型进行训练,直到找到使目标预测模型损失函数最小的第二最优函数时停止训练;
使用测试集对目标模型的第二最优函数的泛化性能进行度量;
采用本实施方式,最终得到了与炉温参数相关性较高并且消除了滞后性的特征向量集,以该特征向量集作为预测模型的输入,能够取得较好的预测结果;
由于本申请中,将更多的炉温变量纳入了考虑范围,以及高炉冶炼本身的复杂性,因此不同预测模型在不同炉温变量下的预测结果往往各有优势,而使用一种以上的预测模型对炉温进行预测,能够得到多种预测结果,再进行比较后,能得到更为精准的预测结果;
同时,在使用多个预测模型进行预测时,能够在多个炉温预测模型中,选择最适合当前时序变量的预测模型,输出最佳预测结果;
另外,在对多个预测模型进行训练时,能够根据给出的训练数据,自动获得对应的最优参数组合,在提高预测精准度的同时,便于后续获得新的训练数据时,及时对预测模型进行更新。
S107、存储第一时间序列变量集至预存储的历史数据集;
采用本实施方式,能够对历史数据集进行更新,以在后续步骤中为各预测模型的更新提供数据支持。
S108、定期使用历史数据集中的时间序列变量训练预测模型进行以进行模型更新;
采用本实施方式,能够对预测模型进行持续更新迭代,以保证预测的准确度。
综上,本申请实施方式的有益效果,除了包括:
能够得到用于预测炉温的第一时间序列变量集,由于选取的是临近当前时序的历史变量,预测结果将更为准确,同时,第一时间段可根据实际生产情况进行划定,以进一步提高预测的精准度;
由于高炉的特殊性,无法直接测量高炉内部温度,通常选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
同时,影响高炉炉温的炉温变量较多,采用最大信息系数法计算炉温参数和炉温变量之间的相关性,不仅能够更好地应对高炉冶炼系统非线性的特点,而且能够避免噪声影响,提高预测模型的稳健性;
通过设置第一阈值,能够排除一部分与炉温参数相关度较低的炉温变量,在后续预测时,能够提高预测的精准度和速度;
通过计算最大时滞时间,能够消除炉温变量的滞后性,进一步提高预测的准确度;
最终得到了与炉温参数相关性较高并且消除了滞后性的特征向量集,以该特征向量集作为预测模型的输入,能够取得较好的预测结果;
还包括:
由于采用了最大信息系数法计算相关度,能将更多的炉温变量纳入考虑范围,进一步提高预测的准确度,其中,人为操作可以是任一采样时序对任一变量人为进行的修改;
将更多的炉温变量纳入了考虑范围,以及高炉冶炼本身的复杂性,因此不同预测模型在不同炉温变量下的预测结果往往各有优势,而使用一种以上的预测模型对炉温进行预测,能够得到多种预测结果,再进行比较后,能得到更为精准的预测结果;
能够在多个炉温预测模型中,选择最适合当前时序变量的预测模型,输出最佳预测结果;
能够根据给出的训练数据,自动获得对应的最优参数组合,在提高预测精准度的同时,便于后续获得新的训练数据时,及时对预测模型进行更新,以保证预测的准确度。
参照图3,本申请还公开一种高炉炉温预测方法的实施例,选取某钢铁厂1280m
高炉炉温预测方法,包括以下步骤:
S201、采集当前采样时序前8小时内的高炉生产信息,得到第一时间序列变量集,其中,第一时间序列变量集包括采样时序和采样时序对应的第一炉温变量,第一时间段为临近当前采样时序的96个历史采样时序组成,同时,第一炉温变量包括风量WF、风压WP、顶压MTP、压差PD、富氧量OEF、风温WT、喷煤PCI、鼓风湿度BH、煤气利用率GUR、顶温平均值MTT、十字测温中心点值CT-CTM、十字测温Z值Z-CTM、十字测温W值W-CTM、理燃温度TCT和鼓风动能BM,第一时间序列变量集对应的炉温参数的炉温预测结果为后两个采样时序的炉温参数;
本实施例中,采样时序为5分钟,第一时间段由临近当前采样时序的前96个采样时序组成,即前8小时的高炉生产信息,而8小时是高炉冶炼的常见周期之一,具有较强的代表性;当然,炉温变量还可以包括前两个采样时序的炉温参数和人为操作,本实施例仅考虑未经人工干预的情况下,对高炉炉温进行预测的情况。
S202、选择铁水硅含量作为表征高炉炉温的炉温参数。
S203、使用最大信息系数法分别计算各第一炉温变量和铁水硅含量之间的相关性系数,本实施例中,计算相关性系数的步骤参照步骤S1031-S1036。
S204、选取第一相关性系数大于0.09的第一炉温变量作为第二炉温变量,得到第二时间序列变量集。
S205、获取特征向量集,具体为,根据各第二炉温变量对应的采样时序,计算各第二炉温变量对应的最大时滞时间并根据最大时滞时间和采样时序,得到第二时间序列变量集对应的特征向量集;
本实施例中,共有96个采样时序,对于某一个炉温变量,其最大时滞时间为相关系数第一个大于阈值的采样时序与最后一个大于阈值的采样时序之间的时间差,如,对于风量,96个采样时序的相关性系数均大于0.09,对应的时滞时间为8小时,对于煤气利用率,相关性系数大于0.09的采样时序区间为[0,12]和[78,86],因此,煤气利用率对应的时滞时间为(86-0)*5/60=7.17h,其余炉温变量对应的时滞时间计算方法同上,因存在风量对应的时滞时间为8小时,为第二炉温变量各炉温变量对应的时滞时间中的最大值,故而,对于本实施例中的第二炉温变量对应的最大时滞时间为8小时;最终,在本实施例中,理燃温度、十字测温中心点值、喷煤、风温和顶压这个五个炉温变量与炉温的相关性系数较低,被筛除掉,其余炉温变量构成第二炉温变量的特征向量参与后续计算。
S206、将特征向量集输入预训练的预测模型,得到当前采样时序对应的炉温预测结果;其中,在本实施例中,预训练的预测模型包括线性回归模型LR、贝叶斯岭回归模型BR、BP神经网络模型BPNN、支持向量回归模型SVR、梯度提升回归模型GBR、分布式梯度增强库模型xgboost以及偏最小二乘回归模型PLSR,当然,还可以根据高炉的实际生产情况,选择随机森林模型、lightgbm模型以及adaboost模型等预测模型,本实施例将同时使用上述多种预训练的预测模型对炉温进行预测,得到多个炉温预测结果,根据预设的评价指标,对多个炉温预测结果进行评价,输出最优炉温预测结果;
评价指标包括相关指数R
对多个炉温预测结果进行评价,输出最优炉温预测结果的步骤包括:
获取多个炉温预测结果对应的评价指标,评价指标包括相关指数R
分别对各炉温预测结果的第一命中率、第二命中率和第三命中率进行比较,选择第一命中率最高的第一炉温预测结果、第二命中率最高的第二炉温预测结果和第三命中率最高的第三炉温预测结果作为第一候选结果;
对第一候选结果中各炉温预测结果对应的相关指数R
对第二候选结果中各炉温预测结果对应的均方根误差进行比较,选择均方根误差最低的炉温预测结果作为最优炉温预测结果;
具体的,预训练的预测模型的训练步骤包括:
将预存储的高炉生产信息对应的时间序列变量集划分为训练集、验证集和测试集;
确定预测模型的超参数和各超参数的初始值;
使用训练集对预测模型进行训练,直到找到使目标预测模型损失函数最小的第一最优函数时停止训练;
使用网格搜索算法在验证集中对第一最优函数进行度量以获得目标预测模型的超参数组合,计算并保存目标预测模型的相关指数R
获得目标预测模型的最优超参数组合时停止训练;
整合训练集和验证集后,对最优超参数组合中均方根误差最小的目标预测模型进行训练,直到找到使目标预测模型损失函数最小的第二最优函数时停止训练;
使用测试集对目标模型的第二最优函数的泛化性能进行度量;
在本实施例中,例如,在对分布式梯度增强库模型xgboost进行训练时,需要对决策树最大深度max_depth、学习率learning_rate以及决策树数量n_estimators三种超参数进行设置,各超参数的初始值可分别设为‘max_depth’:[4,6,8,10],‘learning_rate’:[0.03,0.1,0.3],‘n_estimators’:[200,200,400,500];其余预测模型的超参数和超参数的初始值根据实际情况进行选取。
S207、存储第一时间序列变量集至预存储的历史数据集;
S208、每一周使用历史数据集中的时间序列变量训练预测模型进行以进行模型更新。
本申请还公开一种高炉炉温预测装置的实施例。
参照图4,高炉炉温预测装置,包括:
第一采集模块,用于采集第一时间段内的高炉生产信息,得到第一时间序列变量集,其中,所述第一时间序列变量集包括采样时序和所述采样时序对应的第一炉温变量,所述第一时间段为临近当前采样时序的多个历史采样时序组成;
第二采集模块,用于选择铁水硅含量和/或铁水温度作为表征高炉炉温的炉温参数;
第一运算模块,用于使用最大信息系数法分别计算各所述第一炉温变量和所述炉温参数之间的相关性系数;
第二运算模块,用于选取第一相关性系数大于或等于第一阈值的第一炉温变量作为第二炉温变量,得到第二时间序列变量集;
第三运算模块,用于根据所述各第二炉温变量对应的所述采样时序,计算各所述第二炉温变量对应的最大时滞时间并根据所述最大时滞时间和所述采样时序,得到所述第二时间序列变量集对应的特征向量集;
预测模块,用于将所述特征向量集输入预训练的预测模型,得到当前采样时序对应的炉温预测结果。
在本申请所提供的几个实施例中,应该理解到,所提供的方法和装置,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的;例如,某个模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块可以结合或者可以集成到另一个装置,或一些特征可以忽略,或不执行。
本申请还公开一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述中任一项所述的高炉炉温预测方法。
本申请还公开一种计算机可读存储介质,存储有能够被处理器加载并执行如上述中任一项所述的高炉炉温预测方法的计算机程序。
其中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用;计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、电线、光缆、RF等等,或者上述的任意合适的组合。
需要说明的是,在上述实施例中,对各个实施例的描述各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
本具体实施方式的实施例均为本申请的较佳实施例,并非依此限制本申请的保护范围,其中相同的零部件用相同的附图标记表示。故:凡依本申请的结构、形状、原理所做的等效变化,均应涵盖于本申请的保护范围之内。
- 一种网络安全态势预测方法、装置、设备及存储介质
- 一种进馆档案数量预测方法、装置、电子设备及存储介质
- 一种身体质量指数预测方法、装置、电子设备及存储介质
- 一种物资需求预测的方法、装置、设备及可读存储介质
- 一种运载火箭数据预测方法及装置、存储介质和电子设备
- 一种高炉炉温预测方法、终端设备及存储介质
- 一种高炉炉温自动调节方法、终端设备及存储介质