企划书产生系统及其方法
文献发布时间:2023-06-19 10:38:35
技术领域
本发明涉及网络文章的分析,以及从网络文章中取得热门话题并据以产生企划书的领域,尤其涉及一种企划书产生系统及其方法。
背景技术
基于从众效应,人们容易因为最近流行的主题而前往该主题相关地点探访。例如:前往美食评鉴得奖的餐厅用餐、前往稀有虚拟宝物出现的地点抓宝。
因此,行销人员经常在网络上观察近期热门话题,再自行判断这些话题能否带动某地区的人流量。举例来说,旅行社提出以“宜兰童玩节”、“台北马拉松”、“苗栗桐花祭”等地区性主题旅游企划书(此处以中国台湾宜兰市、中国台湾台北市及中国台湾苗栗县等作为地名的范例),以此吸引民众参加。然而,并不是每个热门话题都能推动地方旅游,甚至某些话题变得热门后,反而会降低民众前往话题所在地旅游的意愿。另一方面,固定周期的活动每次举办的地点未必相同,例如,音乐祭、元宵灯会、神明遶境等。从上述可知,目前尚缺乏一种判断热门主题能否提升特定地点的人潮的自动化机制,也缺少一种搜寻哪些地点的人流量可被热门主题提升的自动化机制。
发明内容
有鉴于此,本发明提出一种企划书产生系统及其方法,借此让特定领域(例如:旅游业)的行销人员得以从繁杂的网络资信中取得真正能提升来客量的话题,并根据此话题自动产生一企划书。进一步地,本发明提出一种过滤掉与特定领域无关联的话题,以达到有效的地点推荐。
依据本发明一实施例叙述的一种企划书产生方法,包括:取得多个文字档,每一文字档属于多个类别其中一者;从文字档撷取关键词,并计算关键词的话题系数以判断关键词是否为话题;从文字档中对应于话题的多个文字档撷取地名,并以话题及地名作为一配对;在产生配对之后,依据话题的网络声量而决定是否保留话题;在依据话题的网络声量而决定保留话题之后,依据地名筛选评论网站的多个评论档;依据评论档中被筛选的多个评论档计算话题出现在被筛选的评论档的第一比例,并依据第一比例而决定是否保留话题;以及在依据第一比例而决定保留话题之后,产生企划书,企划书包括推荐列,推荐列包括地名及话题。
依据本发明一实施例叙述的一种企划书产生系统,包括:通信装置,非暂时性机器可读存储装置以及一或多个处理装置。通信装置从第一服务器取得多个文字档,从第二服务器取得多个评论档,及从第三服务器取得一词汇的网络声量。非暂时性机器可读存储装置存储多个指令。一或多个处理装置电性连接通信装置及非暂时性机器可读存储装置。处理装置执行指令并引发多个操作,这些操作包括:从文字档撷取关键词,并计算关键词的话题系数以判断关键词是否为一话题;从文字档中对应于话题的多个文字档撷取一地名,并以话题及地名作为一配对;在产生配对之后,以话题作为词汇,并依据话题的网络声量而决定是否保留话题;在依据话题的网络声量而决定保留话题之后,依据地名筛选评论档;依据评论档中被筛选的多个评论档计算话题出现在被筛选的评论档的第一比例,并依据第一比例而决定是否保留话题;以及在依据第一比例而决定保留话题之后,产生企划书,企划书包括推荐列,推荐列包括地名及话题。
综上所述,本发明提出的企划书产生系统及其方法,适用于在特定领域搜索可带动人流量的话题以及地点。就旅游而言,本发明可自动化式挖掘做为大众旅游动机的话题,并以该话题密切关联的景点为核心,推荐多个区域性高网络声量的旅游景点,最终形成一份旅游景点企划书的草案供企划人员参考。
以上的关于本发明内容的说明及以下的实施方式的说明用以示范与解释本发明的精神与原理,并且提供本发明的专利申请范围更进一步的解释。
附图说明
图1是依据本发明一实施例的企划书产生系统所绘示的方块架构图;
图2是依据本发明一实施例的企划书产生方法所绘示的流程图;
图3是依据本发明第二实施例的企划书产生方法所绘示调整外部类别权重值的流程图。
符号说明:
10 企划书产生系统
1 通信装置
3 非暂时性机器可读存储装置
5 处理装置
N 网络
V1 第一服务器
V2 第二服务器
V3 第三服务器
S21~S47、S61~S69 步骤
具体实施方式
以下在实施方式中详细叙述本发明的详细特征以及特点,其内容足以使任何本领域技术人员了解本发明的技术内容并据以实施,且根据本说明书所揭露的内容、权利要求及附图,任何本领域技术人员可轻易地理解本发明相关的构想及特点。以下的实施例进一步详细说明本发明的观点,但非以任何观点限制本发明的范畴。
本发明基于如下概念被提出:一个地点的网络声量(internet volume)与一个地点的人流量成正比。本发明适用于多种特定领域,后文主要以“旅游”此一特定领域为例进行说明,但本发明并不以此为限。
图1绘示本发明一实施例的企划书推荐系统的方块架构图。如图1所示,所述的企划书产生系统10,包括:通信装置1、非暂时性机器可读存储装置3以及处理装置5。处理装置5电性连接通信装置1及非暂时性机器可读存储装置3。
通信装置1通信连接至网际网络N,借此从第一服务器V1取得多个文字档,从第二服务器V2取得多个评论档,从第三服务器V3取得一词汇的一网络声量。上述三个服务器V1、V2、V3例如是网页服务器(web server)。实质上,第一服务器V1例如呈现一新闻网站或一电子布告栏,其提供多个已分类的文章。第二服务器提供的网站具有多个评论档的,例如旅游网志网站、美食评论网站,其中的文章归属于一特定领域。第三服务器呈现一网际网络搜寻网站,例如是Google。
非暂时性机器可读存储装置3,例如存储器或硬碟,可存储多个指令及文字资料。本发明不限制非暂时性机器可读装置3的硬体类型。
处理装置5可执行非暂时性机器可读存储装置3存储的多个指令,借此引发多个操作。需注意的是,图1所绘示的处理装置仅为范例而非用以限制本发明一实施例的企划书推荐系统10中的处理装置5的数量。关于处理装置5引发的多个操作,下文配合图2进一步说明。
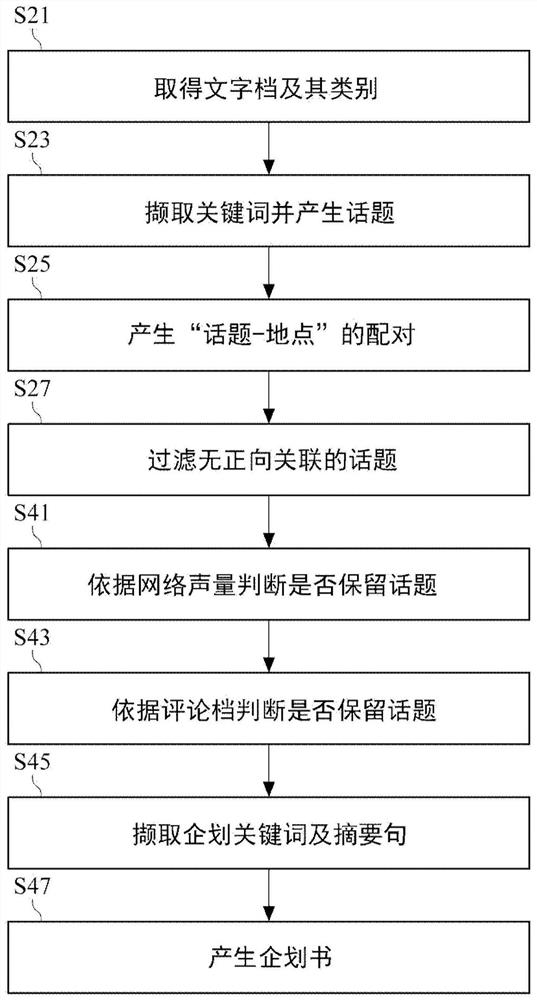
请参考图2,其绘示本发明一实施例的企划书产生方法。本方法适用于前述的企划书产生系统10。
请参考步骤S21,取得多个文字档。每个文字档属于多个类别其中一者。详言之,通信装置10从新闻网站或入口网站取得多个外部类别底下的文章,以及这些外部类别的标题,例如“娱乐”、“运动”、“美食”、“政治”。采用ETL(Extract-Transform-Load)的方式,通信装置1将网页上的文章转换为纯文字档案,例如为CSV档,并存放在非暂时性机器可读存储装置3。
在第一实施例中,虽然每个文字档属于多个外部类别其中一者,然而这些文字档是按照多个内部类别分别存储。内部类别与外部类别具有一对应关系,其范例如下表。
在第一实施例中,运算装置5依据外部类别与内部类别的对应关系,指定每一文字档为多个内部类别其中一者。例如将从P论坛中外部类别为“电影”的文章归类为“娱乐”的内部类别。
在第二实施例中,这些文字档直接按照外部类别分别被存储。
请参考步骤S23,撷取关键词并产生话题。详言之,处理装置5从多个文字档撷取一(或多个)关键词,计算此关键词的话题系数,并依据话题系数是否超过一阈值而决定此话题可否作为一话题。实质上,运算装置5采用如tf-idf(term frequency/inverse documentfrequency)或text rank的技术从文字档撷取关键词。话题系数是关键词出现在所有文章的比例。一种计算话题系数的方式可为:假设共取得100个文字档,且预设的阈值为0.7,则若有超过70个的文字档的内容中具有“宝可梦(Pokemon)”此一关键词,“宝可梦”即可作为一话题。
请参考步骤S25,产生“话题-地名”的配对。详言之,运算装置5从那些内容包含话题的文字档中寻找并记录地名,然后将话题与这些地名组成一配对,例如为:“宝可梦-南寮”、“宝可梦-新竹”。(此处以中国台湾新竹市及中国台湾新竹市内的南寮渔港作为地名的范例)
请参考步骤27,过滤无正向关联的话题。本步骤S27是为了进一步筛选与旅游具有正向关联的“话题-地名”的配对。以下分为三个实施例叙述运算装置5在步骤S27的具体实现方式,但本发明并不以此为限。
在步骤S27的第一实施例中,运算装置5取得包括多个正向类别的类别清单,这些正向类别属于内部类别的子集合。例如,内部类别有50个,正向类别为这50个内部类别中与旅游具有较高关联性的35个类别。然后,运算装置5计算内容包含话题的文字档在每个内部类别的分布,依据正向类别的分布比例的总和计算出话题的正向系数,并依据话题的正向系数是否超过一阈值而决定是否保留此话题。例如:内容包含“宝可梦”的所有文字档在内部类别的分布为:“娱乐”类别70%、“运动”类别15%、“美食”类别5%及“其他”类别10%。假设正向类别为“娱乐”及“美食”,正向系数的阈值为70%。由于70%+5%>70%,代表“宝可梦”此一话题与旅游的正向关联度足够高,因此话题可以被保留。
上述第一实施例的正向系数计算是基于“每个内部类别对于旅游的正向程度”皆相等的假设。实质上,每个内部类别还各自具有一权重,且正向系数的公式为:正向类别的分布比例与权重值的乘积和。
在步骤S27的第二实施例中,运算装置5取得包括多个正向类别的类别清单,这些正向类别属于外部类别的子集合。每一外部类别具有一权重值,外部类别的权重值基于过去资料的反馈而自动调整。正向系数为话题对应在这些正向类别的多个分布比例值及多个外部类别的权重值的乘积和。
请参考图3,其绘示本发明第二实施例的外部类别的权重值的调整步骤。以下配合简化的范例说明图3的每个步骤。
请参考步骤S61,设置外部类别的初始权重值。例如,将“手机游戏”、“运动”、“政治”等三个外部类别的权重值初始化为1/3。
请参考步骤S63,取得多个历史文字档及历史配对。每一历史文字档属于多个外部类别其中一者。所述的历史文字档是先前执行本发明一实施例的企划书产生方法时所取得的文字档。运算装置5基于一滑动时间窗(sliding time window)从按照时间排序的历史文字档中取得一部分的历史文字档以及对应这些历史文字档的历史配对。所述的历史配对是先前执行步骤S25所产生的配对,其包含话题及地名。
请参考步骤S65,取得历史配对在外部类别的分布比例。详言之,运算装置5计算那些内容包含历史配对的历史文字档在每个外部类别的分布比例,例如:“宝可梦-南寮”此一历史配对的分布比例在“手机游戏”为70%、在“运动”为20%、在“政治”为10%。
请参考步骤S67,指定历史配对的标签值。本步骤S67例如通过问卷调查的形式,由使用者自行判断历史配对中的话题是否与旅游具有正相关。标签值是反映历史配对的正向关联度。例如,若使用者认为“宝可梦-南寮”此一历史配对与旅游具有正相关,则将标签值设定为1,否则将标签设定为0。所述的标签值亦可选用1、0.5、0三种值以表示与旅游的高、中、低相关程度。本发明对标签值的数值型态与其代表含意不予限制。
请参考步骤S69,依据标签值更新权重值。例如,对于“宝可梦-南寮”此一历史配对,进行每个外部类别的权重值更新如下所示:
mobile-game
exercise
politics
其中,mobile-game
承前例,举另一例说明步骤S69的另一种权重值更新的情况:假设在步骤S63中取得另一个历史配对为“登革热-高雄”;(此处以中国台湾高雄市作为地名的范例)在步骤S65中,“登革热-高雄”此历史配对在“手机游戏”为0%、在“运动”为0%、在“政治”为100%;在步骤S67中,使用者认为此一历史配对与旅游不具正相关,因此将其标签值设为0;因此在步骤S69中,对于“登革热-高雄”此一历史配对,进行每个外部类别的权重值更新如下所示:
mobile-game
exercise
politics
依此类推,步骤S63-S69可依据不同的历史配对被循环执行多次。最后将更新完成的多个外部类别权重值予以标准化,控制权重值介于0到1之间。例如,若计算得到的权重值为负值,则修正为0。
按照图3的流程进行更新的外部类别的权重值可被用来计算话题的正向系数。例如,假设外部类别“手机游戏”更新后的权重值为0.87,外部类别“运动”更新后的权重值为1,外部类别“政治”更新后的权重值为0;并且考虑“宝可梦-南寮”此一历史配对的分布比例在“手机游戏”为70%、在“运动”为20%、在“政治”为10%;则运算装置5计算“宝可梦-南寮”此一历史配对的正向系数如下所示:
0.7*0.87+0.2*1+0.1*0=0.809
承上所述,在图2的步骤S25中,可设定运算装置5只保留正向系数为一阈值(例如:0.7)以下的话题,借此获得与旅游具有高度正相关的“话题-地名”的配对。此外,本第二实施例亦可节省运算装置5另外将外部类别的文字档重新分类为内部分类的时间。
在步骤S27的第三实施例中,运算装置5取得包括多个正向类别的一类别清单,其中一个正向类别底下具有一或多个从属正向类别。换言之,正向类别与从属正向类别具有多阶层(multi-level)的关系。例如,正向类别为“户外活动”,从属正向类别为“爬山”、“马拉松”。类别清单中的正向类别及从属正向类别皆属于内部(或外部)类别的子集合。运算装置5检查话题所对应到的类别是否匹配到一从属正向类别及具有此从属正向类别的正向类别而决定是否保留该话题。例如,“棱线纵走”此一话题可匹配“户外活动”此一正向类别及其底下的“爬山”此一从属正向类别,因此运算装置5保留此话题。若一话题不具有上述多阶层的匹配关系,则将该话题视为正向关联度不足,因此运算装置5不保留该话题。
需注意的是,本发明其他实施例允许在步骤S25产生配对之后直接执行步骤S41以提升整体处理速度。然而,加入步骤S27可有效过滤与旅游无正向关联的话题以提升企划书的品质。实质上,可根据需求决定是否执行步骤S27,本发明对此不予限制。
请参考步骤S41,依据网络声量判断是否保留话题。依据该话题的一网络声量而决定是否保留该话题。详言之,运算装置5通过通信装置1从第三服务器V3查询网络声量,例如Google搜寻趋势(Google trends)、QSearch,并且只保留网络声量大于一阈值的话题,或只保留网络声量具有一正向成长趋势(逐渐增加、突然增加)的话题,或保留网络声量大于一阈值且具有正向成长趋势的话题。举例来说,运算装置5取得的话题如下方表格所示:
对于那些在步骤S41保留的话题,运算装置5进一步分析这些“热门”话题是否有助于带动特定地点的观光,所述的特定地点包括配对中的地名(后文称为“核心地名”)所代表的地点以及关联核心地名的其他地名(后文称为“周边地名”)所代表的地点。请参考步骤S43,依据评论档判断是否保留话题。详言之,运算装置5首先确认要用来筛选评论档的核心地名及周边地名。然后运算装置5通过通信装置5依据这些地名筛选一评论网站的多个评论档。评论网站例如为国际性旅游评论网站,“猫途鹰(TripAdvisor)”;评论档的来源为网站中的旅游网志或旅游文章。具体来说,运算装置5基于核心地名及一地理拓扑取得周边地名,所述周边地名关联于配对的核心地名。周边地名对应地点可以是核心地名对应地点的一行政区,或者周边地名对应地点与核心地名对应地点两者之间的地理距离小于一阈值。假设配对的核心地名是台北市(此处以中国台湾台北市作为地名的范例),运算装置5基于地理拓扑取得的周边地名可包括:信义区、万华区(属于台北市辖区)以及板桥区、平溪区(位于台北市邻近的地区)等。承前例,运算装置5取得的核心地名及周边地名例如下方表格所示:
在确认用来筛选的核心地名及周边地名之后,依据被筛选的多个评论档,运算装置5从中计算话题出现在被筛选的评论档的第一比例,并依据第一比例而决定是否保留此话题。例如,若以“南寮”筛选的多个旅游网志中,有80%以上的文章内容皆提到“宝可梦”,则代表“宝可梦-南寮”此配对确实可因为“宝可梦”此一话题的网络声量上涨,而吸引人潮前往南寮旅游。
请参考步骤S45,撷取企划关键词及摘要句。详言之,运算装置5从依据核心地名或周边地名筛选的评论档中撷取企划关键词及关联于企划关键词的摘要句。撷取企划关键词的方式如同步骤S23,其差别在于前者从不限定特定领域的多个类别的文字档中进行撷取,后者从限定特定领域(旅游)的评论档中进行撷取。换言之,所述的企划关键词是在旅游评论档中关联于话题的另一关键词。所述摘要句是关联于企划关键词的上下文。承前例,运算装置5取得的企划关键词如下方表格所示:(此处以中国台湾新竹市的香山湿地作为地名的范例)
请参考步骤S47,产生企划书。详言之,在步骤S45撷取企划关键词之后,运算装置5进一步计算企划关键词对应于内部(或外部)类别的多个第二比例,依据这些第二比例的最大值选择对应的一个内部(或外部)类别,并产生一企划书。企划书的文本包含多个推荐列。每个推荐列包括核心地名(或周边地名)、对应此核心地名(或周边地名)的话题、企划关键词、被选择的类别以及摘要句。企划书的范例如下表所示:
综上所述,本发明提出的企划书产生系统及其方法,适用于在特定领域搜索可带动人流量的话题以及地点。就旅游而言,本发明可自动化式挖掘做为大众旅游动机的话题,并以该话题密切关联的景点为核心,推荐多个区域性高网络声量的旅游景点,最终形成一份旅游景点企划书的草案供企划人员参考。
- 企划书产生系统及其方法
- 光产生装置、具备光产生装置的曝光装置、曝光系统、光产生方法及曝光光致抗蚀剂制造方法