给药前MTX治疗JIA的疗效预测系统及其建立方法
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及疾病疗效预测技术领域,尤其是涉及一种给药前MTX治疗JIA的疗效预测系统及其建立方法。
背景技术
研究发现,低剂量甲氨蝶呤(MTX)是治疗幼年特发性关节炎(JIA)的首选。但是MTX疗效个体差异大,大约只有对30%–70%的JIA患者有效。对MTX无效的患者往往会被给予生物制剂,比如英夫利昔单抗等或联合MTX治疗。生物制剂会带来更高效的疾病病情活动度控制,但若滥用生物制剂,随之而来的可能是高费用和严重的不良反应。另外,MTX产生疗效往往需要3-6个月的时间。患者在如此长的时间里接受“试错型”用药,可能会延误治疗导致关节功能不可逆损害甚至出现不良反应。因此,在开始药物治疗前,早期鉴别患者是否对MTX有效,继而选择合适的有效的治疗方案(单用MTX或者加用生物制剂),对防止疾病进展和预防关节功能远期损伤、甚至致残,都有非常重大的意义。这意味着非常有必要建立一个给药前的MTX疗效准确预测系统。
尽管MTX治疗JIA已有很长的时间,但能够准确预测谁对MTX有效的方法仍然非常有限。到目前为止,在JIA领域,仅仅Bulatovic等报道了一个MTX治疗JIA的疗效预测模型。该模型挖掘出的变量包括血沉和3个基因型。但这个模型存在的局限性就是:模型预测准确度不高(AUC为72%);模型变量中含有基因型,需要额外昂贵的检测才能使用该模型,从而限制了该模型在临床随时可得的简便应用;并且,该研究仅使用了一种传统的逻辑回归算法,而这种方法可能并不是建模最佳的方法,不能适用于所有类型的数据。除了该文之外,其他的对MTX治疗JIA疗效的研究,都仅仅局限于挖掘出哪些基因型或临床特征会影响MTX疗效,但并未提供一种定量的影响,也未提供一个可供临床实际应用的模型,无法实际应用到临床实践来预测患者疗效。
因此,急需一种简便、价廉、高效、容易在临床推广应用的MTX疗效预测模型来为临床医生和患者提供治疗前的参考。
发明内容
基于此,有必要提供一种给药前MTX治疗JIA的疗效预测系统及其建立方法。
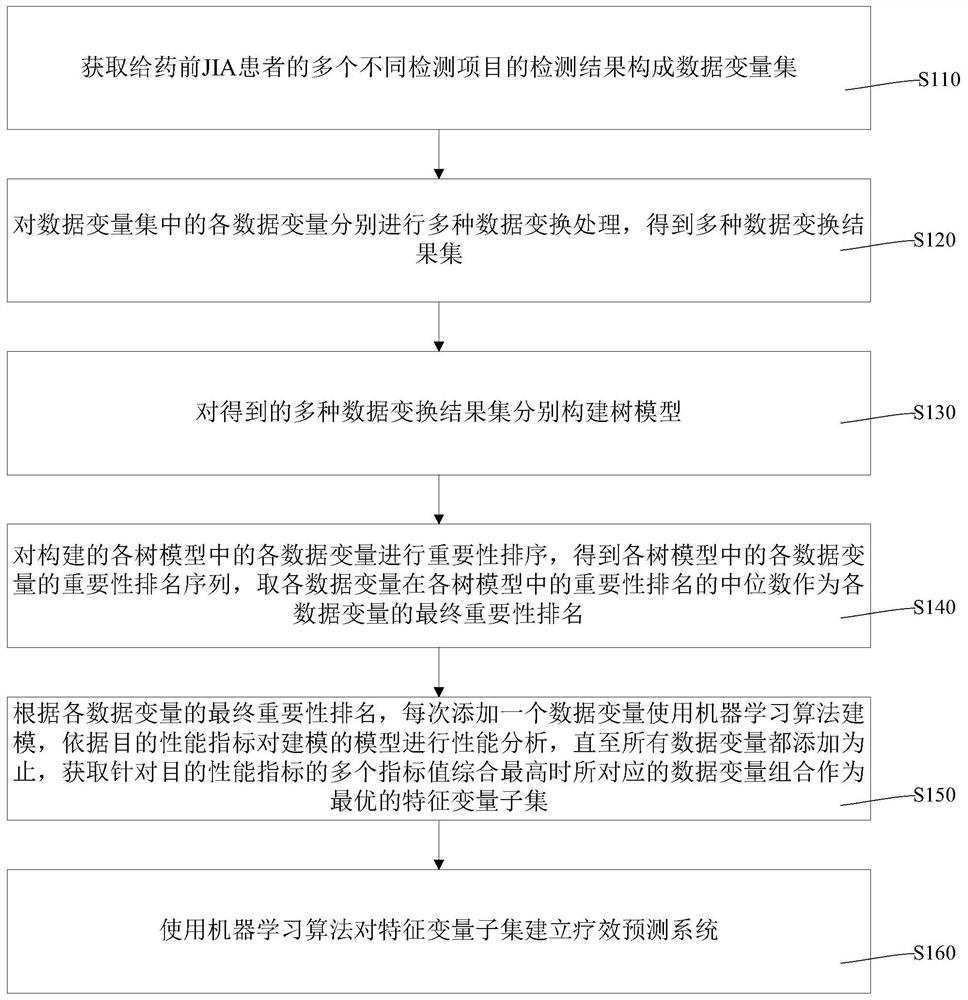
一种给药前MTX治疗JIA的疗效预测系统的建立方法,包括如下步骤:
获取给药前JIA患者的多个不同检测项目的检测结果构成数据变量集;
对所述数据变量集中的各数据变量分别进行多种数据变换处理,得到多种数据变换结果集;
对得到的多种数据变换结果集分别构建树模型;
对构建的各树模型中的各数据变量进行重要性排序,得到各树模型中的各数据变量的重要性排名序列,取各数据变量在各树模型中的重要性排名的中位数作为各数据变量的最终重要性排名;
根据各数据变量的最终重要性排名,每次添加一个数据变量使用机器学习算法建模,依据目的性能指标对建模的模型进行性能分析,直至所有数据变量都添加为止,获取针对所述目的性能指标的多个指标值综合最高时所对应的数据变量组合作为最优的特征变量子集;
使用机器学习算法对所述特征变量子集建立疗效预测系统。
在其中一个实施例中,所述获取给药前JIA患者的多个不同检测项目的检测结果构成数据变量集包括:
去除缺失值占比大于30%的数据变量,将留下的被纳入的各数据变量都分为有效组和无效组,分别计算所述有效组和所述无效组中各数据变量的均值,使用有效组均值填补所述有效组中的缺失的数据变量,使用无效组均值填补所述无效组中缺失的数据变量。
在其中一个实施例中,被去除的缺失值占比大于30%的数据变量包括:用MTX前的胱抑素、用MTX前的25羟维生素D测定、用MTX前的类风湿因子和用MTX前的抗核抗体;
留下的被纳入的数据变量包括如下四十六个数据变量:用MTX前的部分凝血酶原时间、用MTX前的纤维蛋白原、用MTX前的C反应蛋白、用MTX前的T细胞绝对计数、用MTX前的凝血酶原时间、用MTX前的凝血酶时间、用MTX前的血间接胆红素、用MTX前的类风湿因子IgG、用MTX前的疼痛关节数、用MTX前的血直接胆红素、用MTX前的抗环瓜氨酸肽抗体、用MTX前的血总胆红素、用MTX前的肌酐、用MTX前的IgM、用MTX前的血清铁蛋白、用MTX前的抑制T细胞/淋巴细胞、用MTX前的血沉、用MTX前的血糖、用MTX前的B细胞/淋巴细胞、用MTX前的IgE、用MTX前的尿素、用MTX前的辅助T细胞/抑制T细胞、用MTX前的血小板、年龄、用MTX前的C3、用MTX前的IgG、用MTX前的血白蛋白、用MTX前的辅助T细胞/淋巴细胞、用MTX前的NK细胞/淋巴细胞、用MTX前的血红细胞、用MTX前的IgA、用MTX前的红细胞压积、用MTX前的C4、用MTX前的血淋巴细胞、用MTX前的谷丙转氨酶、第一次MTX用量、用MTX前的血中性粒细胞、用MTX前的血红蛋白、用MTX前的谷草转氨酶、用MTX前的血白细胞、用MTX前的肿胀关节数、用MTX前的体重、性别、发病到开始用MTX的时间、JIA关节亚型及发病年龄。
在其中一个实施例中,获得的最优的特征变量子集包括:用MTX前的C反应蛋白、用MTX前的纤维蛋白原、用MTX前的部分凝血酶原时间、用MTX前的T细胞绝对计数、用MTX前的凝血酶原时间、用MTX前的凝血酶时间、用MTX前的疼痛关节数、用MTX前的类风湿因子IgG、用MTX前的血直接胆红素以及用MTX前的血间接胆红素。
在其中一个实施例中,所述多种数据变换处理包括最小-最大归一化处理、Z-分数标准化处理、L2-正则化处理以及保持原型处理,得到四种数据变化结果集。
在其中一个实施例中,所述对得到的多种数据变换结果集分别构建树模型是用极端随机树、梯度提升决策树、随机森林和极限梯度提升树及5折交叉验证法分别对所述四种数据变换结果集构建树模型,得到十六个树模型。
在其中一个实施例中,所述每次添加一个数据变量使用机器学习算法建模是使用极限梯度提升树算法建模;
所述目的性能指标包括准确度、灵敏度和受试者工作特征曲线下面积。
在其中一个实施例中,所述使用机器学习算法对所述特征变量子集建立疗效预测系统是使用极限梯度提升树、随机森林、支持向量机和/或逻辑回归算法对所述特征变量子集构建模型化的疗效预测系统。
在其中一个实施例中,所述给药前MTX治疗JIA的疗效预测系统的建立方法还包括对构建的模型化的疗效预测系统进行分析评估的步骤:按照8:2将由多个不同JIA患者构成的数据集随机划分为训练集和测试集,然后用多种所述机器学习算法及5折交叉法分别基于训练集构建疗效预测模型,使用测试集评估建立的各个疗效预测模型的性能并且对比模型性能,选择最优的模型作为模型化的疗效预测系统。
一种给药前MTX治疗JIA的疗效预测系统,其采用上述任一实施例所述的建立方法建立。
通过使用上述给药前MTX治疗JIA的疗效预测系统的建立方法建立的疗效预测系统,优选采用高级机器学习算法(例如使用极限梯度提升树(XGBoost)、随机森林(RF)、支持向量机(SVM)与传统算法逻辑回归法(logistics regression)等,进行建模和对比,进一步优选XGBoost)进行系统建立,得到的疗效预测系统的受试者工作特征曲线下面积(AUC)高达97%。相应的模型预测灵敏性、特异性和准确性都在90%以上,比传统方法建立的系统的预测性能(灵敏性、特异性和准确性)显著提高。
该疗效预测系统在疗效预测时不用涉及昂贵的基因型检测,系统建立后只需要将患者常规的必检项目输入前述建立的系统就可以完成疗效模型的预测,无需额外缴费检测,无需患者长时间的等待结果回复,只需来就诊当天完成常规检测后即可以预测疗效。在医生及时看到预测结果后,可立即对患者进行给药决策。若预测结果显示患者对MTX有效,则可以给予患者MTX;若预测结果为无效,则无需给予MTX或者是联用生物制剂。通过本发明的方法建立的疗效预测系统显著提高了医生的决策效率,缩短了患者的等待时间,减少了患者的经济负担,减少了患者的疾病的进展对关节功能的损害,避免了药物不良反应的发生,避免了可能的致残致死。因此,上述方法建立的给药前MTX治疗JIA的疗效预测系统是一种简便易用、高效、早期、准确预测患者MTX疗效的有效工具。
附图说明
图1为本发明一实施例的给药前MTX治疗JIA的疗效预测系统的建立方法流程示意图;
图2为疗效预测系统建立过程中各数据变量的重要程度分级示意图,横柱越短,说明重要性排序越高。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
如图1所示,本发明一实施例提供了一种给药前MTX治疗JIA的疗效预测系统的建立方法,其包括如下步骤:
步骤S110:获取给药前JIA患者的多个不同检测项目的检测结果构成数据变量集;
步骤S120:对数据变量集中的各数据变量分别进行多种数据变换处理,得到多种数据变换结果集;
步骤S130:对得到的多种数据变换结果集分别构建树模型;
步骤S140:对构建的各树模型中的各数据变量进行重要性排序,得到各树模型中的各数据变量的重要性排名序列,取各数据变量在各树模型中的重要性排名的中位数作为各数据变量的最终重要性排名;
步骤S150:根据各数据变量的最终重要性排名,每次添加一个数据变量使用机器学习算法建模,依据目的性能指标对建模的模型进行性能分析,直至所有数据变量都添加为止,获取针对目的性能指标的多个指标值综合最高时所对应的数据变量组合作为最优的特征变量子集;
步骤S160:使用机器学习算法对特征变量子集建立疗效预测系统。
在步骤S110中,可以通过患者的电子病历获取给药前多个JIA患者的多个不同检测项目的检测结果。
在一个具体示例中,步骤S110中,还包括对获取的数据进行预处理的步骤,具体包括:
去除缺失值占比大于30%的数据变量,进而采用分组均值填补缺失的数据变量,具体是:将留下的被纳入的各数据变量都分为有效组和无效组,分别计算有效组和无效组中各数据变量的均值,使用有效组均值填补有效组中的缺失的数据变量,使用无效组均值填补无效组中缺失的数据变量。
缺失值指的是数据变量的值为空,例如362个患者案例中,用MTX前的纤维蛋白原(数据变量)有50个缺失值,则说明该数据变量有312个是有具体结果值,50个值为空,为缺失的。使用分组均值填充缺失的数据变量:比如362个患者案例中:213个有效组,149个无效组,而用MTX前的纤维蛋白原(数据变量)的50个缺失值中:30个是来于有效组,20个是无效组的,则填充如下:计算213个有效组中用MTX前的纤维蛋白原的均值(总213个,30个缺失,则应该是183个的均值)填充30个缺失的数据变量;计算149个无效组中用MTX前的纤维蛋白原的均值(总149个,20个缺失,则应该是129个的均值)填充20个缺失的数据变量。
在一个具体示例中,被去除的缺失值占比大于30%的数据变量包括:用MTX前的胱抑素、用MTX前的25羟维生素D测定、用MTX前的类风湿因子和用MTX前的抗核抗体。
进一步,留下的被纳入的数据变量包括如下四十六个数据变量:用MTX前的部分凝血酶原时间(APTT,s)、用MTX前的纤维蛋白原(FIB,g/L)、用MTX前的C反应蛋白(CRP,mg/L)、用MTX前的T细胞绝对计数(CD3+Abs,cells/μl)、用MTX前的凝血酶原时间(PT,s)、用MTX前的凝血酶时间(TT,s)、用MTX前的血间接胆红素(IBIL,μmol/mL)、用MTX前的类风湿因子IgG(RF-IgG,U/mL)、用MTX前的疼痛关节数(TJC)、用MTX前的血直接胆红素(DBIL,μmol/mL)、用MTX前的抗环瓜氨酸肽抗体(Anti-CCP,U/mL)、用MTX前的血总胆红素(TBIL,μmol/L)、用MTX前的肌酐(SCr,μmol/L)、用MTX前的IgM(IgM,g/L)、用MTX前的血清铁蛋白(FER,ng/mL)、用MTX前的抑制T细胞/淋巴细胞(CD3+CD8+,%)、用MTX前的血沉(ESR,mm/h)、用MTX前的血糖(GLU,mmol/L)、用MTX前的B细胞/淋巴细胞(CD19,%)、用MTX前的IgE(IgE,IU/mL)、用MTX前的尿素(Urea,mmol/L)、用MTX前的辅助T细胞/抑制T细胞(Th/Ts)、用MTX前的血小板(PLT,10
可参见图2所示,在一个优选的示例中,筛选的获得的最优的特征变量子集包括:用MTX前的C反应蛋白、用MTX前的纤维蛋白原、用MTX前的部分凝血酶原时间、用MTX前的T细胞绝对计数、用MTX前的凝血酶原时间、用MTX前的凝血酶时间、用MTX前的疼痛关节数、用MTX前的类风湿因子IgG、用MTX前的血直接胆红素以及用MTX前的血间接胆红素。
在步骤S120中,所述多种数据变换处理包括最小-最大归一化处理、Z-分数标准化处理、L2-正则化处理以及保持原型处理,得到四种数据变化结果集。
在步骤S130中,对得到的多种数据变换结果集分别构建树模型是用极端随机树(ET)、梯度提升决策树(GBDT)、随机森林(RF)和极限梯度提升树(XGBoost)及5折交叉验证法分别对四种数据变换结果集构建树模型,得到十六个树模型。
进一步,在重要性排名时,例如在给药前模型特征选择过程中,对多种数据变换结果集分别构建树模型,一共有4×4=16个树模型,在后续步骤S140中对每个树模型都对各数据变量进行重要性排序,则每个数据变量都有16个重要性排序名次,各数据变量取这16个中的中位数作为最终排名。此时是属于变量特征选择的下一步,在确定所有数据变量的最终重要性排名后,但还未确定选择多少个数据变量比较合适之前,因此,后续是从最终重要的数据变量开始,依次添加一个数据变量建模进而确定变量个数:比如,当变量个数为10个时,模型的综合指标最佳,则特征选择前10个重要变量构成特征变量子集。
在步骤S150中,每次添加一个数据变量使用机器学习算法建模是使用XGBoost算法建模。
目的性能指标优选包括准确度(accuracy)、灵敏度(sensitivity)和受试者工作特征曲线下面积(AUC)。
在步骤S160中,所述使用机器学习算法对特征变量子集建立疗效预测系统是使用XGBoost、RF、支持向量机和/或逻辑回归算法对特征变量子集构建模型化的疗效预测系统。
优选地,该给药前MTX治疗JIA的疗效预测系统的建立方法还包括对构建的模型化的疗效预测系统进行分析评估的步骤:按照8:2将由多个JIA患者构成的数据集随机划分为训练集和测试集,然后用多种机器学习算法及5折交叉法分别基于训练集构建疗效预测模型,使用测试集评估建立的各个疗效预测模型的性能并且对比模型性能,选择最优的模型作为模型化的疗效预测系统。
例如将362个患者案例按8:2随机划分为训练集(290)和测试集(72),而训练集和测试集的特征变量子集都是10个,即用MTX前的C反应蛋白、用MTX前的纤维蛋白原、用MTX前的部分凝血酶原时间、用MTX前的T细胞绝对计数、用MTX前的凝血酶原时间、用MTX前的凝血酶时间、用MTX前的疼痛关节数、用MTX前的类风湿因子IgG、用MTX前的血直接胆红素以及用MTX前的血间接胆红素。
经过分析评估发现,使用XGBoost算法构建的疗效预测系统的预测结果最佳,其次是RF算法,具体可参见下表1中各算法构建的疗效预测系统的预测性能。
表1
本发明还提供了一种给药前MTX治疗JIA的疗效预测系统,其采用上述建立方法建立。
通过使用上述给药前MTX治疗JIA的疗效预测系统的建立方法建立的疗效预测系统,优选采用高级机器学习算法(例如XGBoost、RF、支持向量机与传统算法逻辑回归法等,进行建模和比较,进一步优选XGBoost)进行系统建立,得到的疗效预测系统的受试者工作特征曲线下面积(AUC)高达97%。相应的模型预测灵敏性、特异性和准确性都在90%以上,比传统方法建立的系统的预测性能(灵敏性、特异性和准确性)显著提高。
基于筛选出的特征变量子集建立系统,按照通用的方法根据不同的算法及其原理进行建模:比如逻辑回归
本发明针对每个算法构建的系统结果都进行了封装,应用模型进行预测时,只要输入待测患者对应的10个变量的值,就可以输出MTX疗效预测的结果(要么有效或者要么无效,这两种结果)。优选采用二分类建模,都是直接输出结果的:1表示有效,0表示无效;其中没有作额外限定。
该疗效预测系统在疗效预测时不用涉及昂贵的基因型检测,只需要患者常规的必检项目就可以完成疗效模型的预测,无需额外缴费检测,无需患者长时间的等待结果回复,只需来就诊当天完成常规检测后即可以预测疗效。在医生及时看到预测结果后,可立即对患者进行给药决策。若预测结果显示患者对MTX有效,则可以给予患者MTX;若预测结果为无效,则无需给予MTX或者是联用生物制剂。通过本发明的方法建立的疗效预测系统显著提高了医生的决策效率,缩短了患者的等待时间,减少了患者的经济负担,减少了患者的疾病的进展对关节功能的损害,避免了药物不良反应的发生,避免了可能的致残致死。因此,上述方法建立的给药前MTX治疗JIA的疗效预测系统是一种简便易用、高效、早期、准确预测患者MTX疗效的有效工具。
具体地,应用到JIA患者的预测实例可参见下表2。
表2应用XGBoost模型来预测临床患者的MTX疗效
预测结果与实际相符,患者AAA对MTX用药无反应,患者BBB对MTX用药有良好的反应。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 给药前MTX治疗JIA的疗效预测系统及其建立方法
- 给药后MTX治疗JIA的疗效预测系统及其建立方法