基于面部关键点轨迹特征图的视频情感识别方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于多媒体信号处理领域,涉及一种基于面部关键点轨迹特征图的视频情感识别方法。
背景技术
视频情感识别技术在各种智能系统中的应用具有很大的潜力,包括数字广告业务,在线游戏,客户反馈评估,医疗行业等。
早期的视频情感识别分类器主要是基于从静态面部图像中提取的手工浅层特征。面部特征可以从整个面部区域或特定的局部区域中提取,并分为两类:基于几何形状或基于外观。基于几何形状的特征表示考虑形状信息(如面部点或眉毛、眼睛、嘴、鼻子的位置),而忽略面部的纹理。值得注意的是,这种特征表示易受光照变化影响。大多基于几何特征的方法通过主动外观模型跟踪一组面部关键点。另一方面,基于外观的特征表示利用强度值或像素值来表示面部的纹理变化,例如皱纹和条纹。基于外观的经典特征有尺度不变特征变换(SIFT)、局部二值模式(LBP)、梯度直方图(HOG)、Gabor小波表示。主成分分析(PCA)技术被广泛用于特征降维,并在表情识别中取得了很好的成绩。
2002年自动表情识别领域的相关研究发现CNN对人脸位置变化和尺度变化具有鲁棒性,并且在出现之前未见的人脸姿态变化的情况时CNN的表现超过多层感知机(MLP)。利用CNN可以解决人脸表情识别中的主体独立性、平移、旋转、尺度不变性等问题。基于CNN的基础架构,一些变型也被应用于解决表情识别的问题,包括AlexNET、深度卷积神经网络(DCNN)、残差神经网络(Resnet)、Inception和双通道CNN,一个通道是标准CNN网络,另一个通道被训练为卷积自编码器。在视频中帧和帧之间有上下文关联性,增加了比单纯的图像更多的时间信息。Donahue等人于2018年通过将CNN中学习到的视觉特征表示和LSTM的可变长输入输出优势相结合,创造了一种时间和空间上的深度模型,该模型将CNN的输出作为LSTM网络的输入,用于设计时变输入和输出的各种视觉任务中,许多类似的级联网络被陆续提出。
2015年Jung等人提出了人脸关键点轨迹,然而当前的人脸关键点轨迹特征的使用方法存在不足,直接使用了没有归一化的关键点坐标,或者将一组特征点坐标拼接成一维特征向量送入浅层的分类网络中。这样做的不足在于人脸的关键点运动不仅仅受到面部表情的驱动,头部的姿态变化和运动同样会导致面部关键点发生位移。即使面部关键点位置进行了归一化处理,但是侧脸、低头、抬头等动作都能引发面部关键点的位移,真正有意义的是这些点之间的相对距离变化。此外,浅层分类网络的性能也很难让人满意。
发明内容
本发明的目的是提供一种基于面部关键点轨迹特征图的视频情感识别方法,以缓解现有的人脸关键点轨迹特征的使用不充分的问题。
为实现上述目的,本发明采用的技术方案为:
一种基于面部关键点轨迹特征图的视频情感识别方法,包括以下步骤:
步骤1,对视频序列中的视频帧图像进行处理,并获得一组面部关键点坐标;
步骤2,计算步骤1得到的这一组面部关键点坐标之间的相对距离在相邻视频帧上的变化值矩阵,将面部关键点轨迹特征编码,得到面部关键点轨迹特征图;
步骤3,将视频序列对应的一系列面部关键点轨迹特征图送入CNN-LSTM深度时空网络中进行情感识别任务。
进一步的,所述步骤1包括:
步骤1.1,将视频序列中的视频帧图像进行预处理,得到每帧图像;
步骤1.2,通过Dlib提供的基于集成回归树的面部关键点定位方法获取每帧图像上的面部的68个关键点坐标。
所述步骤1.1中,视频序列来源于RAVDESS数据集,RAVDESS数据集中的视频帧大小为1280*720,将每帧图像的大小调整到128*128。
进一步的,所述步骤2包括:
步骤2.1,对于每一帧图像,计算68个面部关键点之间的L2范数,并进行归一化处理,得到维度为68*68的面部关键点归一化距离矩阵,对于视频序列,获得一组面部关键点归一化距离矩阵;
步骤2.2,对相邻两帧的面部关键点归一化距离矩阵逐元素做差,获得面部关键点归一化距离在相邻两帧上的差分值矩阵,作为最终的面部关键点轨迹特征图。
进一步的,所述步骤3包括:
步骤3.1,将步骤2得到的一组面部关键点轨迹特征图送入深度神经网络中,从中提取抽象特征,用于生成帧级别的深度学习特征表示;
步骤3.2,将步骤3.1得到的帧级别的深度学习特征表示送入LSTM长短期记忆网络中,学习这一组面部关键点轨迹特征图之间的长期相关性,得到视频序列级的深度学习特征表示;
步骤3.3,将步骤3.2得到的视频序列级的深度学习特征表示输入到全连接网络中,然后将全连接网络连接到Softmax层,利用softmax将网络的输出压缩到0到1之间,并且输出的和为1,表征视频序列所属情感类别的概率;
步骤3.4,将步骤3.3得到的概率利用交叉熵损失函数得到网络的损失值(Loss),通过反向误差传播算法优化网络参数;
步骤3.5,在测试过程中,将由步骤2得到的一组面部关键点轨迹特征图送入CNN-LSTM深度时空网络后,会得到视频序列对应的情感类别的概率向量,最大概率值所对应的情感类别即为视频序列的预测情感类别。
进一步的,所述步骤3.1中,深度神经网络利用1×1,3×3,5×5的不同尺度卷积核并联,从面部关键点轨迹特征图中提取不同尺度的特征进行拼接,从而聚合高层次的全局特征和低层次的局部细节特征。
进一步的,所述步骤3.2中,LSTM网络中,信息在LSTM节点上流动,从而对这一组帧级别的深度学习特征表示进行聚合,生成视频序列级的深度学习特征表示。
有益效果:针对现有的人脸关键点轨迹特征的使用不充分的问题,本发明方法通过计算一组关键点之间的相对距离在相邻帧上的变化值矩阵将关键点轨迹特征编码成面部关键点轨迹特征图,然后输入CNN-LSTM深度时空网络提取序列级别的深度学习特征表示用于视频情感识别,有效的提升了模型的识别准确率。
附图说明
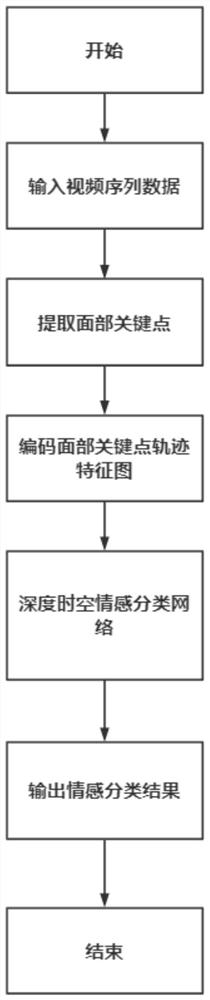
图1为本发明基于面部关键点轨迹特征图的视频情感识别方法流程图;
图2为本发明深度时空情感分类网络示意图;
图3为本发明深度神经网络结构示意图;
图4为训练过程准确率曲线图;
图5为本发明在RAVDESS测试集上的混淆矩阵。
具体实施方式
下面结合附图对本发明作更进一步的说明。
如图1所示,一种基于面部关键点轨迹特征图的视频情感识别方法,包括以下步骤:
步骤1,对视频序列中的视频帧图像进行处理,并获得一组面部关键点坐标;具体步骤为:
步骤1.1,将视频序列中的视频帧图像进行预处理,得到每帧图像;其中,视频序列来源于RAVDESS数据集,RAVDESS数据集中的视频帧大小为1280*720,将每帧图像的大小调整到128*128;
步骤1.2,通过Dlib提供的基于集成回归树的面部关键点定位方法获取每帧图像上的面部的68个关键点坐标。
步骤2,计算步骤1得到的这一组面部关键点坐标之间的相对距离在相邻视频帧上的变化值矩阵,将面部关键点轨迹特征编码,得到面部关键点轨迹特征图;具体步骤为:
步骤2.1,对于每一帧图像,计算68个面部关键点之间的L2范数,并进行归一化处理,得到维度为68*68的面部关键点归一化距离矩阵,对于视频序列,获得一组面部关键点归一化距离矩阵;
步骤2.2,对相邻两帧的面部关键点归一化距离矩阵逐元素做差,获得面部关键点归一化距离在相邻两帧上的差分值矩阵,作为最终的面部关键点轨迹特征图。
步骤3,将视频序列对应的一系列面部关键点轨迹特征图送入CNN-LSTM深度时空网络中进行情感识别任务;具体步骤为:
步骤3.1,将一组面部关键点轨迹特征图送入深度神经网络中,从中提取抽象特征,用于生成帧级别的深度学习特征表示;其中,深度神经网络利用1×1,3×3,5×5的不同尺度卷积核并联,从面部关键点轨迹特征图中提取不同尺度的特征进行拼接,从而聚合高层次的全局特征和低层次的局部细节特征;
步骤3.2,将步骤3.1得到的帧级别的深度学习特征表示送入LSTM长短期记忆网络中,学习这一组面部关键点轨迹特征图之间的长期相关性,得到视频序列级的深度学习特征表示;其中,LSTM网络中,信息在LSTM节点上流动,从而对这一组帧级别的深度学习特征表示进行聚合,生成视频序列级的深度学习特征表示;
步骤3.3,将步骤3.2得到的视频序列级的深度学习特征表示输入到全连接网络中,然后将全连接网络连接到Softmax层,利用softmax将网络的输出压缩到0到1之间,并且输出的和为1,表征视频序列所属情感类别的概率;
步骤3.4,将步骤3.3得到的概率利用交叉熵损失函数得到网络的损失值(Loss),通过反向误差传播算法优化网络参数;
步骤3.5,在测试过程中,将由步骤2得到的一组面部关键点轨迹特征图送入CNN-LSTM深度时空网络后,会得到视频序列对应的情感类别的概率向量,最大概率值所对应的情感类别即为视频序列的预测情感类别。
如图4所示,整个迭代过程为100次,大约在70次迭代左右模型收敛,在验证集上的准确率开始保持稳定。由于利用了视频帧之间的上下文关联,同时RAVDESS数据集是不含噪声的实验室数据集,从而取得了比基于单张图片的情感分类器更高的准确率,在测试集上最终取得了73.88%的分类准确率。如图5为RAVDESS数据集上的混淆矩阵,在混淆矩阵中,快乐、厌恶和惊讶的识别率较高,这是由于这几种情感在面部肌肉运动的方向上有着显著特征,更易被检出。整体而言,本发明提出的基于面部关键点轨迹特征图的视频情感识别方法在RAVDESS数据集上的识别率达到了73.88%,性能表现理想。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 基于面部关键点轨迹特征图的视频情感识别方法
- 一种基于情感显著性特征融合的视频情感识别方法