一种高效隐私保护的鲁棒联邦学习方法
文献发布时间:2023-06-19 18:25:54
技术领域
本发明属于联邦学习鲁棒性和高效性领域的研究,具体涉及一种高效隐私保护的鲁棒联邦学习方法。
背景技术
众所周知,机器学习需要大量的数据来训练模型。然而,随着越来越多的国家强调对个人隐私的保护,诸如通用数据保护条例(General Data protection Regulation)等法规的出台,使得敏感的隐私数据可能无法直接收集和访问。为了解决这个问题,联邦学习(Federated Learning)提供了一种协作式机器学习框架,允许多个用户或机构(客户端)在不共享自己数据的情况下协同训练一个共享的全局模型。在联邦学习中,通常有一个主服务器协调多个客户端通过多次迭代来解决一个优化问题。主服务器可以与每个客户端进行通信,并在迭代过程中通过聚合客户端的本地模型来获得新的全局模型。联邦学习尤其适合海量IoT、手机端用户合作训练。
尽管联邦学习具有诸多优点,但它容易受到拜占庭攻击和隐私推断攻击的影响。拜占庭攻击主要发生在客户端,拜占庭客户端在聚合过程中注入恶意的本地模型,从而降低新的全局模型的性能。隐私推断攻击主要发生在服务器,服务器可以通过客户端的本地模型推断客户端数据的属性甚至重构客户端数据。很少有同时防御拜占庭攻击和隐私推断攻击的防御措施。最近的研究表明,只有一个具有拜占庭故障的单一客户端才能攻破诸如FedAvg的线性聚合规则,其中联邦学习中的拜占庭故障包括计算故障、设备故障、数据样本和标签的偏差。但在最坏的情况下,恶意客户端会试图破坏全局模型。为了解决上述问题,机器学习社区最近开发了一些拜占庭弹性聚合规则,典型的包括Krum and Multi-Krum和Median and Trimmed mean。其中,前者基于本地模型之间的欧氏距离,选择一个与其他本地模型最近的本地模型作为新的全局模型,而后者计算所有本地模型参数的中位数,并将其作为新的全局模型对应的参数。而在防止隐私推断攻击方面,同态加密(HomomorphicEncryption)和安全多方计算(Secure Multi-Party Computation)协议得到广泛应用,前者参与方计算开销较大,且支持的操作类型有限,后者参与方计算开销很小,支持的操作类型广泛,但参与方间通信开销较大。现有的一些防御方案利用秘密共享技术实现隐私保护的距离计算,并使用基于距离的拜占庭弹性聚合规则(如Multi-Krum)来获得新的全局模型,然而这些方案的计算开销巨大,且成对距离的泄露可能带来新的隐私威胁。因此,研究新的具有更好安全性的高效联邦学习方案,是十分迫切的需求。
发明内容
为此,需要提供一种高效隐私保护的鲁棒联邦学习方法,本发明的目的,一方面是防止服务器从本地模型推断出隐私数据的部分属性,甚至重构原始数据。另一方面,在MPC协议的保护下,减少联邦学习算法的隐私保护乘法数量,降低算法整体开销,提高算法效率,在保持鲁棒性的前提下,使联邦学习算法获得更好的可扩展性。
为了减少隐私保护乘法的数量,创新性地提出在计算成对距离之前对所有本地模型的秘密共享进行随机投影操作,随机生成元素为1或-1的投影矩阵,将本地模型的共享矩阵与投影矩阵直接相乘,将高维空间中的本地模型投影到低维空间中。投影操作只引入了在MPC协议中开销为免费的加法和减法,不需要任何通信开销。这样在低维空间中计算成对距离所需的隐私保护乘法数量将大大减少。
为实现上述目的,本发明采用如下技术方案:
一种高效隐私保护的鲁棒联邦学习方法,包括如下步骤,
步骤1、两个服务器协同地选择n个客户端参与联邦学习过程,并分别将自己的全局模型广播给这些客户端;
步骤2、客户端用接收到的全局模型对本地模型进行初始化,用本地数据集训练本地模型,将训练后的本地模型发送给两个服务器;
步骤3、两个服务器用接收到的本地模型构建共享矩阵,并将其投影到降维的共享矩阵中;
步骤4、两个服务器协同地对共享矩阵执行拜占庭弹性聚合算法,获得新的全局模型。
本技术方案进一步的优化,所述步骤2中将训练后本地模型中的浮点数转换为整数,然后用MPC协议共享本地模型并发送给两个服务器。
本技术方案进一步的优化,所述步骤2客户端i将本地模型L
本技术方案更进一步的优化,所述步骤3中每个服务器收集所有客户端发来的所有秘密共享,并构建共享矩阵
本技术方案更进一步的优化,所述步骤3中投影矩阵与本地模型共享的乘积之前还有一个系数
本技术方案更进一步的优化,所述步骤4的拜占庭弹性聚合算法构建之前,首先构建三个基本模块:1)
本技术方案更进一步的优化,所述步骤4的拜占庭弹性聚合算法中,两个服务器交换
区别于现有技术,上述技术方案具有如下有益效果:该方案基于两个非共谋服务器,开销极低,且不揭示任意两个本地模型之间的距离。创新性地提出在计算成对距离之前对本地模型的共享矩阵进行随机投影操作,将高维空间中的本地模型投影到低维空间中,这些本地模型之间的成对距离可以在低维空间中以较小的误差保持,从而大大减少了私有乘法的数量。该思想可应用于任何基于距离的拜占庭弹性聚合规则的隐私保护实现,且几乎不影响聚合算法的鲁棒性。然后,为了避免成对距离的暴露带来的潜在隐私威胁,基于ABY框架实现隐私保护的拜占庭弹性聚合算法Multi-Krum,仅暴露所选客户端的索引和新的全局模型,延续了联邦学习中保障数据隐私的优点。
附图说明
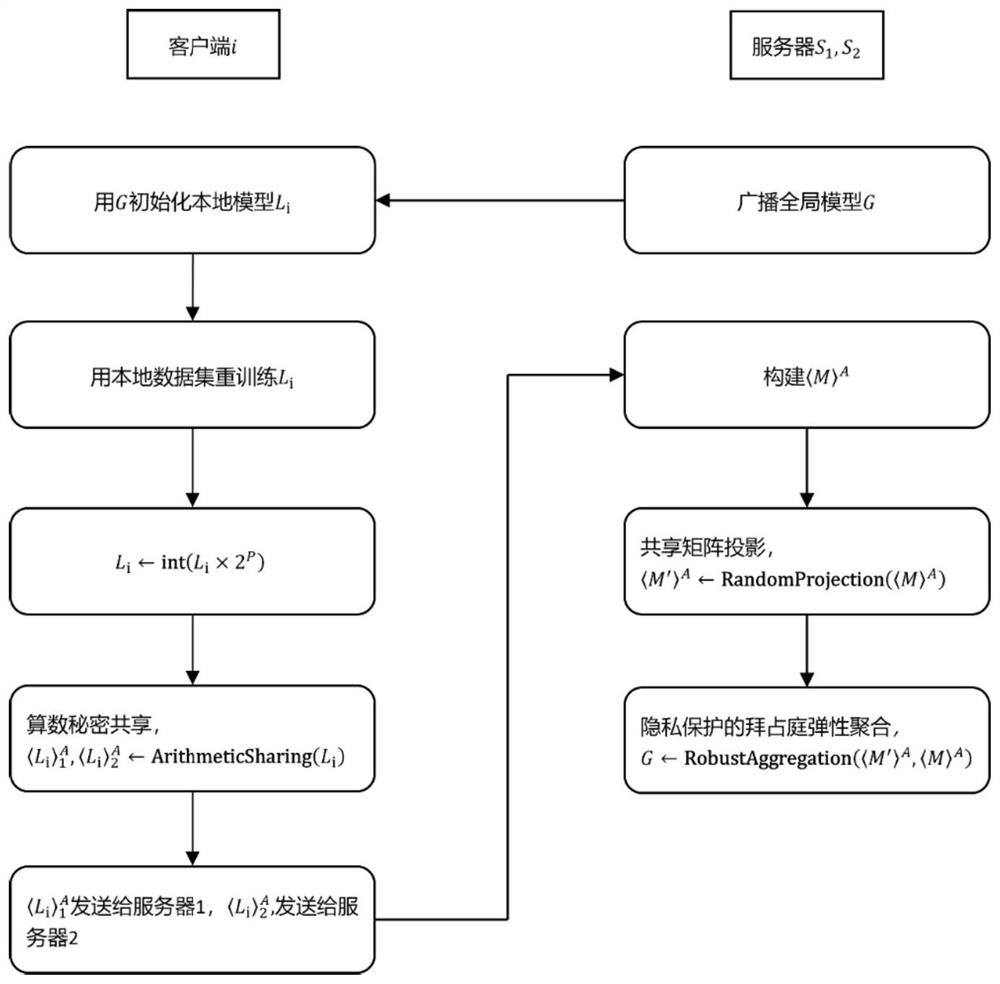
图1是客户端和服务器交互流程图;
图2是投影方案"RandomProjection"的算法步骤图;
图3是Multi-Krum和MKRP分别使用MNIST、Fashion-MNIST、CIFAR-10数据集在Gaussian attack下不同拜占庭客户端数量的模型预测准确率对比图;
图4是Multi-Krum和MKRP分别使用MNIST、Fashion-MNIST、CIFAR-10数据集在label flipping attack下不同拜占庭客户端数量的模型预测准确率对比图;
图5是Multi-Krum和MKRP使用CIFAR-10数据集的训练时间对比图。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
本发明提出了一种高效隐私保护的鲁棒联邦学习方法,采用两个服务器和n个客户端的设置。首先,由两个服务器共同选择参与联邦学习的n个客户端,分别将自己的全局模型分发给每个参与联邦学习的客户端。客户端用全局模型初始化本地模型,用本地数据集训练本地模型,并生成本地模型的一对算数秘密共享,将对应的秘密共享份额分别发送给两个服务器。服务器用收到的所有秘密共享构建共享矩阵,并使用相同的投影矩阵将其投影到降维的共享矩阵中。投影操作在服务器本地进行,不产生通信开销。最后,在MPC协议的保护下,两个服务器协同地进行拜占庭弹性聚合,并输出新的全局模型。
本发明的高效隐私保护的鲁棒联邦学习方法,包括以下步骤,
步骤1、该方法每次迭代开始时,两个服务器协同地选择n个客户端参与联邦学习过程,并分别将自己的全局模型广播给这些客户端。
步骤2、客户端用接收到的全局模型对本地模型进行初始化,用本地数据集训练本地模型,将本地模型中的浮点数转换为整数,然后用MPC协议共享本地模型并发送给两个服务器。
步骤3、两个服务器用接收到的秘密共享构建共享矩阵,并将其投影到降维的共享矩阵中。
步骤4、两个服务器协同地对共享矩阵执行拜占庭弹性聚合算法,获得新的全局模型。
参阅图1所示,为客户端和服务器交互流程图。客户端用本地数据集训练本地模型后,将本地模型秘密共享给服务器。服务器构建客户端本地模型的共享矩阵,并将共享矩阵投影到低维空间中,随后执行拜占庭弹性聚合算法得到新的全局模型。
本发明优选一实例,具体实施细节如下:
步骤1、两个服务器协同地选择n个客户端,并分别将自己的全局模型G广播给这些客户端。这个设置可以防止单个服务器选择共谋客户端来帮助其推断其他客户端的隐私信息。客户端通过比较接收到的两个全局模型,判断两个服务器是否在上一轮诚实地执行了聚合协议。
步骤2、客户端i将本地模型L
需要注意的是,ABY中算术共享的操作函数只支持整数输入,因此客户端需要先将L
步骤3、每个服务器收集所有客户端发来的所有秘密共享,并构建共享矩阵
随机投影函数RandomProjection由定理1导出。
定理1假设P为d维实数域
给定ε,μ>0,令
对于整数k>k
令
令f:
(1-ε)‖u-v‖
根据定理1可得,即使从简单均匀分布中选择投影矩阵,也可以获得与Johnson-Lindenstrauss引理相同的损失。只包含+1和-1的投影矩阵的元素,在计算投影矩阵积和本地模型共享时,只需要免费的加法和减法运算。然而,投影矩阵与本地模型共享的乘积之前还有一个系数
两个服务器都需要执行投影算法。每个服务器首先使用相同的随机种子得到一个相同的随机投影矩阵R,其中R的元素为常量形式。然后每个服务器本地计算R与本地模型共享矩阵的乘积,得到低维本地模型共享矩阵。经过随机投影后,直接计算低维本地模型之间的距离,以较小的误差模拟原维本地模型之间的距离,这将大大减少MPC乘法的数量。因此,在实现大多数基于MPC的基于距离和拜占庭弹性的聚合规则时,可以应用随机投影方案来减少开销。
步骤4、使用MPC框架ABY,两个服务器协同地对
·ADD(
·GT(
·SWAP(
然后实现以下函数,用作聚合算法的基本构建模块:
·
·
·
聚合算法以原始本地模型的共享矩阵
步骤5、通过实验验证本方案,考虑了三个分类任务需要高维模型的图像数据集,包括MNIST,Fashion-MNIST和CIFAR-10。MNIST和Fashion-MNIST都由70000个28×28的灰度图像组成,CIFAR-10包含60000个32×32的彩色图像。在这三个数据集上分别训练一个10类分类器。对于MNIST和Fashion-MNIST,使用相同的深度神经网络(DNN),架构为2个卷积层和2个全连接层。对于CIFAR-10,使用轻量级的ResNet-18进行分类。与原始的ResNet-18不同,轻量级的ResNet-18将第一个卷积层的大小修改为32×3×3。
为了评估随机投影在Multi-Krum上的效果,对Multi-Krum和采用随机投影的Multi-Krum(Multi-Krum with random projection,MKRP)在三个数据集上进行了评估。参阅图3所示,在高斯攻击(Gaussian attack)下测试了不同拜占庭客户端数量时的准确率,可以看出随机投影对Multi-Krum没有影响。β相同时,MKRP在MNIST、Fashion-MNIST和CIFAR-10上的准确率比Multi-Krum分别最多下降0.2%,0.2%和0.6%,几乎可以忽略不计。随着β从4增加到12,Multi-Krum在MNIST、Fashion-MNIST和CIFAR-10上的准确率分别下降了0,0.1%和0.8%,而MKRP的准确率分别下降了0.3%、0.3%和0.9%。MKRP和Multi-Krum之间的降幅最多为0.3%,可以忽略不计。因此,随机投影对Multi-Krum的影响不随β改变。
在标签翻转攻击(label flipping attack)下测试了不同拜占庭客户端数量时的准确率。该攻击方法与高斯攻击方法的不同之处在于拜占庭局部模型与良性局部模型遵循不同的分布。拜占庭局部模型和良性局部模型的得分差距取决于模型和数据集,因此随机投影的影响是不同的。参阅图4所示,在拜占庭客户数量相同的情况下,与Multi-Krum相比,MKRP在MNIST、Fashion-MNIST和CIFAR-10上的准确率最多下降0.2%、1%和5%。
使用CIFAR-10数据集时,Multi-Krum和MKRP的训练时间参阅图5所示。可以看到,在随机投影策略的作用下,与Multi-Krum相比,MKRP的训练时间得到了大约40倍的优化,这表明随机投影操作能够有效提高联邦学习算法的效率。
本发明的优点如下:1.减少了聚合算法中私有乘法的数量;2.投影操作几乎不影响聚合算法的鲁棒性;3.隐私保护的拜占庭弹性聚合算法Multi-Krum仅暴露所选客户端的索引和新的全局模型,延续了联邦学习中保障数据隐私的优点;4.在保证联邦学习算法隐私性和鲁棒性的前提下,有效地提高了联邦学习算法效率。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
- 一种基于级联自适应鲁棒联邦滤波的车载导航计算方法
- 一种通信高效、保护隐私且抗攻击的联邦学习方法
- 一种高效通信且保护隐私的个性化联邦学习方法