一种基于近端策略优化算法的无人驾驶变道决策控制方法
文献发布时间:2023-06-19 19:30:30
技术领域
发明涉及无人驾驶领域和深度强化学习领域,尤其涉及基于深度强化学习的无人驾驶变道决策控制方法。
背景技术
人驾驶车辆(简称无人车)是智能车辆发展的高级阶段,它能综合利用其具有的感知、决策和控制能力,在特定的环境中代替人类驾驶员,独立地执行车辆驾驶任务。城市道路交通安全、交通拥堵、交通污染、能源消耗等是当今世界城市和交通发展面临的重要问题,无人驾驶车辆的应用是解决这些问题的重要途径。变道是无人车的一种基础驾驶行为,通过操控油门、刹车和方向盘使得无人车从一条车道进入另一条车道的驾驶行为。
目前实现无人驾驶变道驾驶行为的方法主要有:基于规则的方法、基于深度学习的方法与基于深度强化学习的方法。基于规则的方法在简单封闭的环境中可以实现变道驾驶行为;但面对复杂环境时,规则库难构建困难且难以覆盖所有场景。基于深度学习的方法需要采集大量标注数据作为输入以保证模型训练的泛化性,因此难以训练。深度强化学习方法结合了深度学习的感知能力和强化学习的决策能力,更加适用于解决高维状态空间下的决策问题,目前深度强化学习方法在无人驾驶领域得到了广泛的应用研究。目前应用在无人驾驶领域主要的深度强化学习方法,如深度Q网络算法(Deep Q Network,DQN)、深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)等,在训练模型时往往存在学习率难以准确设置的问题。学习率设置过大,会导致收敛困难;学习率设置过小,会造成训练速度缓慢。PPO算法利用Actor网络与OldActor网络的比例,限制了Actor网络的更新幅度,降低了策略梯度对较大步长的敏感性,解决了DDPG等算法中学习率难以准确设置的问题,同时加快了收敛速度。对此,本发明提出一种基于近端策略优化算法的无人驾驶变道决策控制方法。
发明内容
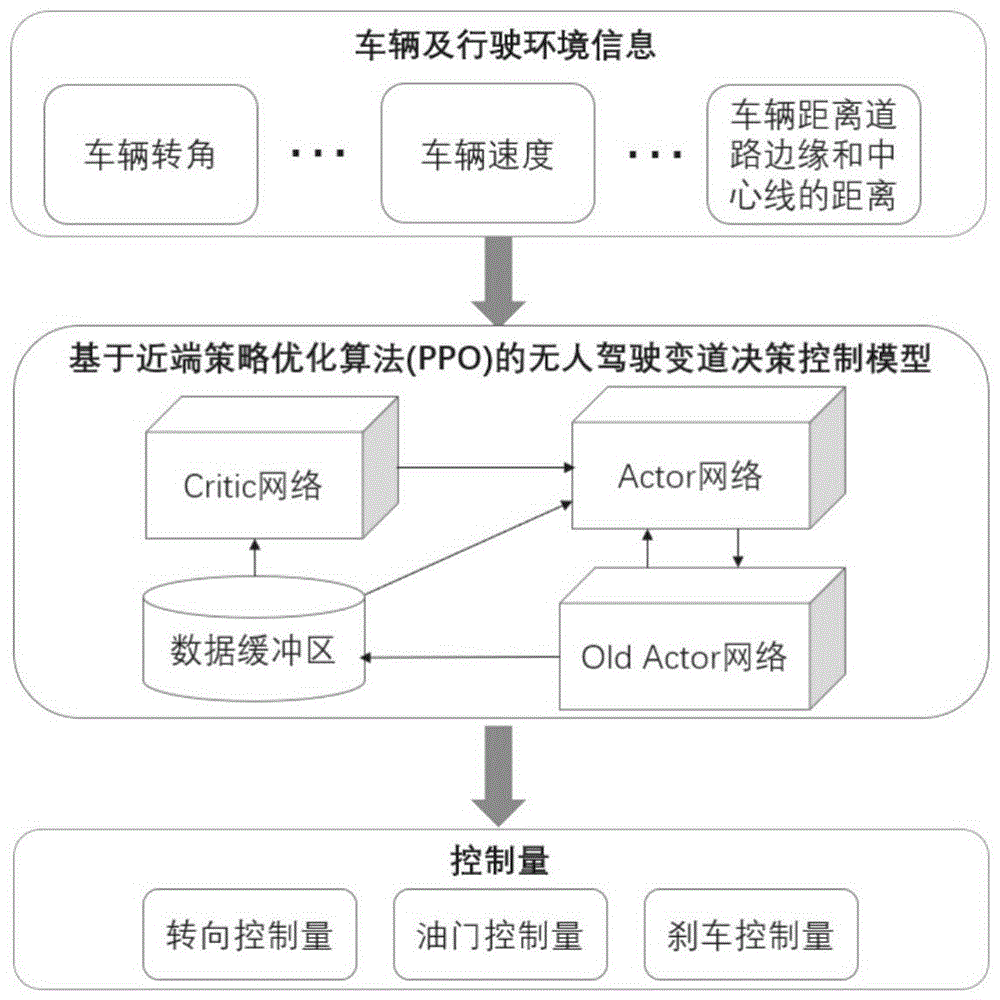
鉴于此,本发明提出了一种基于近端策略优化算法的无人驾驶变道决策控制方法以解决采用常用深度强化学习方法例如深度确定性策略梯度算法难以确定学习率的问题。其模型结构示意图如图2所示。
本发明采用的技术方案为一种基于近端策略优化算法的无人驾驶变道决策控制方法,包括以下步骤:
步骤1:构建基于近端策略优化算法的无人驾驶变道决策控制模型。所述无人驾驶变道决策控制模型的神经网络由演员网络和评论家网络构成,演员网络包括Actor网络和Old Actor网络,评论家网络包括一个Critic网络。其中,Actor网络用于决策无人车执行变道驾驶行为时输出的控制量,输入传感器获取到的无人车当前环境信息s
步骤2:训练基于近端策略优化算法的无人驾驶变道决策控制模型。无人车与所在环境交互获取当前环境信息s
步骤3:测试基于近端策略优化算法的无人驾驶变道决策控制模型。使用训练好的基于近端策略优化算法的无人驾驶变道决策控制模型在新的环境中进行变道,以验证基于近端策略优化算法的无人驾驶变道决策控制模型的可靠性。
进一步地,步骤2中,与环境交互的过程具体为:
步骤2.1,初始化基于近端策略优化算法的无人驾驶变道决策控制模型的各个神经网络的网络参数并与无人车所在的环境开始交互。
步骤2.2,无人车与环境交互获取当前环境信息s
步骤2.3,根据动作a
步骤2.4,无人车执行动作a
步骤2.5,重复若干次步骤2.2至2.4,并将每一次执行步骤2.2至2.4后获取到的元组信息放入数据缓冲区中,每一步都将生成包含当前环境信息s
步骤2.6,根据数据缓冲区中获取到的所有数据,计算每一条数据的此后累积奖励值R
R
在总时长T中,r
步骤2.7,将数据缓冲区中的每条数据的当前环境信息s
步骤2.8,将数据缓冲区中的每条数据的当前环境信息s
步骤2.9,根据步骤2.7中计算出的估计对数概率Logprob_eval与数据缓冲区中存储的对数概率Logprob计算Actor网络与OldActor网络输出动作的概率比r
为Actor网络输出的动作概率,/>
步骤2.10,根据步骤2.6中得到的
步骤2.11,根据公式(4)计算Actor网络的损失值,并更新Actor网络。
步骤2.12,根据公式(5)计算Critic网络的损失值,并更新Critic网络。
步骤2.13,重复动作步骤2.2至2.12,直至Actor网络表现收敛,则表明基于近端策略优化算法的无人驾驶变道决策控制模型训练完成。
进一步地,Actor网络与Critic网络的更新频率为无人车与环境交互一次,进行一步训练,进行若干步训练时更新一次。
进一步地,无人车通过多种传感器获取车辆及行驶环境相关信息(如车辆转角、车辆速度、车辆距离道路边缘和中心线的距离等)作为输入状态,经过模型的处理后直接输出车辆油门、刹车和转向的控制量,通控制无人车的方向盘、油门踏板、刹车踏板完成变道驾驶行为。
与现有技术相比,基于近端策略优化算法的无人驾驶变道决策控制模型具有较快的收敛速度,提高了训练效率。
附图说明
图1为本发明的模型结构图。
图2为本发明的PPO作用机理图。
图3为本发明的变道驾驶行为示意图。
图4为本发明的TORCS训练与测试地图。
图5为本发明的PPO模型与DDPG模型训练时间对比图。
具体实施方式
下面结合附图对本发明做进一步的说明。本发明提出了一种基于近端策略优化算法的无人驾驶变道决策控制模型,并在TORCS仿真平台上实现,包括以下具体步骤:
步骤1:搭建TORCS环境。
步骤1.1,安装Ubuntu20.04操作系统。
步骤1.2,安装TORCS仿真平台版,TORCS的版本为1.3.1。
步骤1.3,安装Anaconda及其依赖包。
模型与TORCS虚拟环境交互获取环境信息并输出动作信息;具体地,环境信息包括一定距离内的车与道路信息、车辆自身的速度以及无人车本身与道路中心线之间的距离和夹角信息已经目标驾驶状态信息,动作信息包括转向控制量、油门控制量和刹车控制量。
步骤2:构建基于近端策略优化算法的无人驾驶变道决策控制模型。所述无人驾驶变道决策控制模型的神经网络由演员网络和评论家网络构成,演员网络包括Actor网络和Old Actor网络,评论家网络包括一个Critic网络。其中,Actor网络用于决策无人车执行变道驾驶行为时输出的控制量,输入传感器获取到的无人车当前环境信息s
步骤3:测试基于近端策略优化算法的无人驾驶变道决策控制模型。使用训练好的基于近端策略优化算法的无人驾驶变道决策控制模型在新的环境中进行变道,以验证基于近端策略优化算法的无人驾驶变道决策控制模型的可靠性。
步骤3.1,初始化基于近端策略优化算法的无人驾驶变道决策控制模型的各个神经网络的网络参数并与无人车所在的环境开始交互。
步骤3.2,无人车与环境交互获取当前环境信息s
进一步地,当前环境信息s
骤3.3,根据动作a
步骤3.4,无人车执行动作a
进一步地,奖励函数如下算法所示:
步骤3.5,重复128次步骤3.2至3.4,并将每一次执行步骤3.2至3.4后获取到的元组信息放入数据缓冲区中,每一步都将生成包含当前环境信息s
步骤3.6,根据数据缓冲区中获取到的所有数据,计算每一条数据的此后累积奖励值R
步骤3.7,将数据缓冲区中的每条数据的当前环境信息s
步骤3.8,将数据缓冲区中的每条数据的当前环境信息s
步骤3.9,根据
步骤3.10,根据步骤3.6中得到的得到
步骤3.11,根据
步骤3.12,根据
步骤3.13,重复500次动作步骤3.2至3.12,直至Actor网络表现收敛,则表明基于近端策略优化算法的无人驾驶变道决策控制模型训练完成。
步骤4:测试基于近端策略优化算法的无人驾驶变道决策控制模型。使用训练好的基于近端策略优化算法的无人驾驶变道决策控制模型在新的环境中进行变道,以验证基于近端策略优化算法的无人驾驶变道决策控制模型的可靠性。
为了验证本发明在收敛速度上的优势,本发明采用控制变量的方法同时使用深度确定性策略梯度算法实现了无人驾驶的变道决策控制。奖励值的稳定在一定程度上代表着模型的收敛,训练过程中奖励值的变化如图5所示,纵轴代表每一回合的累积奖励值按比例缩小以后的值,横轴表示回合数,PPO Reward表示基于近端策略优化算法的无人驾驶变道决策控制模型在训练过程中奖励值的变化曲线,DDPG Reward表示基于深度确定性策略梯度算法的无人驾驶变道决策控制模型在训练过程中奖励值的变化曲线。可以看出,在训练基于近端策略优化的无人驾驶变道决策控制模型时,在300回合之前已经收敛,而基于深度确定性策略梯度算法的无人驾驶变道决策控制模型时,在接近400回合才收敛,充分证明了本发明在收敛速度上的优势。