一种基于4D毫米波雷达和图像的融合3D目标检测方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于自动驾驶技术领域,具体为一种基于4D毫米波雷达和图像的融合3D目标检测方法。
背景技术
3D目标检测是自动驾驶汽车视觉感知系统的重要组成部分。3D目标检测的整体目标是通过绘制一个定向的3D边界框,输出包括目标的三维位置和朝向信息。
现代自动驾驶汽车通常配备多种传感器,如激光雷达和摄像头。视觉传感器采集的数据具有丰富的颜色纹理信息,易于对目标进行识别分类且成本较低,但其缺乏深度信息,且易受天气(雨、雾、灰尘)和光照(夜晚)的影响。激光雷达通过发射光束并接受目标的反射信号,可以得到目标的距离和角度等空间位置参数,被广泛应用于3D目标检测领域,但其抗干扰能力较低,易受天气影响,且对系统实时性有较高要求,同时价格高昂。毫米波雷达通过发射和接受电磁波,可以得到目标的距离、径向速度和方位角等空间位置参数,且对于恶劣天气鲁棒性强,具有全天候的特点,同时成本较低,但传统毫米波雷达缺乏高度信息,无法将道路交通信息反映在真实的3D空间中。近年来,4D毫米波雷达的出现弥补了传统毫米波雷达的缺陷,在拥有更稠密的点云的同时,增加了高度信息,可以捕捉车辆周围目标的空间坐标和速度。但相较于相机和高线束激光雷达,4D毫米波雷达语义信息模糊,仅仅依靠4D毫米波雷达进行精确感知仍然非常困难。
因此,在保证低成本以及系统鲁棒性和冗余性的前提下,如何融合4D毫米波雷达和图像的信息实现高精度的3D目标检测任务是自动驾驶亟待解决的问题。
发明内容
本发明的目的在于提供一种基于4D毫米波雷达和图像的融合3D目标检测方法,以提升目标检测精度。
为实现上述目的,本发明采用如下技术方案:
一种基于4D毫米波雷达和图像的融合3D目标检测方法,包括以下步骤:
步骤1、获取样本数据集,样本数据集包括4D毫米波雷达的点云和单目相机图像;
步骤2、基于样本数据集构建端到端3D目标检测网络,并进行训练;
步骤3、计算损失函数值,根据计算出的损失函数值反向传播更新端到端3D目标检测网络参数;
步骤4、利用更新好的端到端3D目标检测网络进行目标检测。
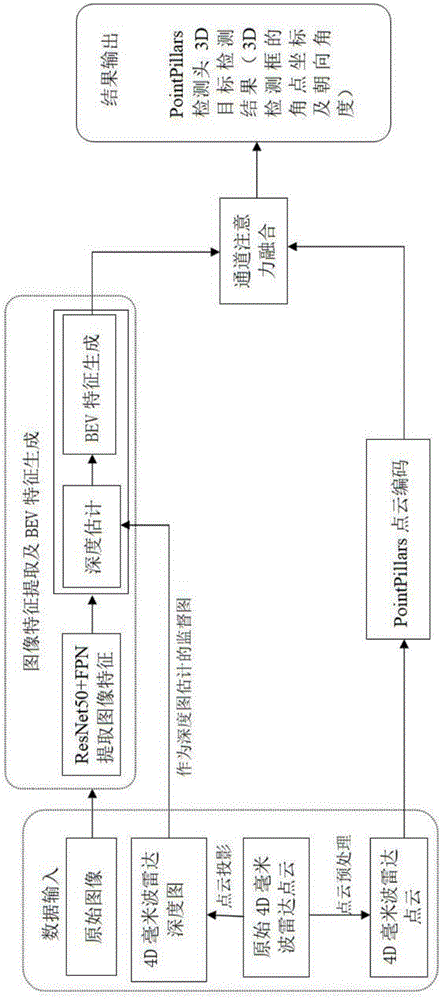
进一步的,所述步骤2的训练过程如下:
2.1、生成第一BEV特征和第二BEV特征
所述第一BEV特征的生成包括以下子步骤:
a1、根据4D毫米波雷达点云生成用作显示监督的稀疏深度图;
a2、以单目图像为输入,使用预训练的ResNet50主干网络和FPN网络提取图像特征;然后将提取的图像特征输入至单目深度估计网络,预测图像的深度估计,并在预测过程中引入稀疏深度图对单目深度估计网络进行显示监督,从而得到第一BEV特征;
所述第二BEV特征的生成包括以下子步骤:
b1、对4D毫米波雷达点云的速度维度进行特征工程,并将其加入到原始的毫米波雷达点云特征之中,得到7维的4D毫米波雷达点云;
b2、使用PointPillars的点云编码方法,对b1得到的7维的4D毫米波雷达点云进行转化,得到第二BEV特征;
2.2、使用通道注意力机制的卷积神经网络融合第一BEV特征和第二BEV特征,得到融合特征;
2.3、以融合特征为输入,使用神经网络进行预测得到预测检测结果;将预测检测结果与预设锚框进行匹配、回归,得到最终的目标检测结果。
更进一步的,所述a1生成稀疏深度图的计算公式如下所示:
(2)
其中,pts为原始点云,大小为N×3,Tr_velo_to_cam为点云转换至相机坐标系的外参,P0为相机内参矩阵。
更进一步的,所述a2单目深度估计网络采用了Lift-Splat-Shoot(LSS)结构。
更进一步的,在a2采用单目深度估计网络预测过程中,针对引入的稀疏深度图,采用了双线性插值方法构深度标签,以获得稠密深度图,从而提升监督效果。
更进一步的, 所述b2的详细步骤包括:
b2.1、在x-y平面上均匀划分P个网格,每个网格代表一个柱子,每个柱子在z方向都是无限延伸的;
b2.2、将预处理后的7维点云分配至每个柱子中并进行编码,添加每个点到所属柱子的算数平均值的距离、以及每个点x-y方向上到柱子x-y中心的偏移量;
b2.3、采用多采样、少补零的方法在每个柱子中设置最大点云数量N,形成一个(9,P,N)的稠密张量,使用点网从9维的稠密张量中提取特征得到点云特征图,并对其进行进行最大池化处理,得到每个柱子中最具代表性的点;
b2.4、将P个柱子按照第一步的划分规则划分为H×W投影到x-y平面,得到(C,H,W)的伪图像,即第二BEV特征。
更进一步的,所述2.2的详细步骤包括:
2.2.1、以第一BEV特征为输入,先使用1×1卷积层减少特征的通道数量,再使用两个3×3卷积层进行深层特征提取之后与其相加,得到对齐的第一BEV特征;
2.2.2、将对齐的第一BEV特征与第二BEV特征进行通道注意力计算,得到融合特征。
更进一步的,所述2.3将预测检测结果与预设锚框进行匹配,得到最终的目标检测结果步骤包括:
2.3.1、使用PointPillars作为检测头,根据不同检测类别预设锚框,每个检测类别的锚框数量和角度根据需求设定;
2.3.2、采用是2D IOU的匹配算法,完成预测检测结果与预设锚框的匹配,并根据匹配结果进行回归得到最终的目标检测结果输出,所述目标检测结果包括3D检测框的位置和朝向信息。
进一步的,所述步骤3的损失函数值包括:深度估计损失和3D目标检测损失,深度损失计算如式(6)所示,3D目标检测损失计算如式(7)所示:
(6)
其中,
(7)
其中,
本发明提供的一种基于4D毫米波雷达和图像的融合3D目标检测方法,通过构建端到端的3D目标检测网络,实现了目标检测精度的提升。在端到端的3D目标检测网络中,以单目图像为输入提取的图像特征,再将图像特征输入至单目深度估计网络预测图像的深度估计,并在预测过程中引入稀疏深度图对单目深度估计网络进行显示监督,从而得到第一BEV特征。以4D毫米波雷达点云为输入,对4D毫米波雷达点云的速度维度进行特征工程,得到7维的4D毫米波雷达点云;使用PointPillars的点云编码方法,对b1得到的7维的4D毫米波雷达点云进行转化,得到第二BEV特征。然后对第一BEV特征和第二BEV特征进行融合,从而实现了在BEV视角下预测3D目标检测结果。
与现有技术相比,本发明的有益效果是:
1、本发明利用多模态数据,即利用不同性质传感器采集数据之间的冗余性提升系统的鲁棒性,通过对4D毫米波雷达进行速度维度的特征工程处理,实现了保证检测精度的前提下,提升自动驾驶场景下3D目标检测的鲁棒性。
2、本发明利用毫米雷达数据的高度稀疏性,提升了处理速率。
附图说明
图1是本发明融合3D目标检测方法的流程图;
图2是本发明融合部分网络结构的示意图。
实施方式
下面将结合附图与实施例实对本发明技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
参阅图1,本实施例提供的一种基于4D毫米波雷达和图像的融合3D目标检测方法,括以下步骤:
步骤1、获取样本数据集。样本数据集包括4D毫米波雷达的点云和单目相机图像。本实施例获取的单目相机图像分辨率为1936 × 1216。4D毫米波雷达点云包含
步骤2、基于样本数据集构建端到端3D目标检测网络,并进行训练。所述训练过程包括:
2.1、生成第一BEV特征和第二BEV特征。
生成第一BEV特征
以单目图像为输入,使用预训练的ResNet50主干网络和FPN网络提取图像特征。然后将提取的图像特征输入至单目深度估计网络,预测图像的深度估计,并在预测过程中引入稀疏深度图对单目深度估计网络进行显示监督,从而得到第一BEV特征。所述单目深度估计网络采用了Lift-Splat-Shoot(LSS)结构。具体预测方法如下:
先通过预设一组离散的深度值,对输入单目图像的每个像素点进行深度估计,然后将估计的深度特征与图像特征外积得到三维视锥特征。再将视锥特征通过相机的内外参数转换为三维坐标的点。然后通过对BEV空间划分栅格,将每个点分配到对应的栅格的“柱子”中,最后将柱子“拍扁”为BEV特征。预测出图像对应的BEV特征的,如果多个像素点在同一个位置,则采用QuickCumsum算法计算新的特征,即将同一个位置的点进行特征的相加去重,最后得到BEV特征。
为提升单目深度估计网络预测准确度,本实施例使用4D毫米波雷达点云生成稀疏深度图作为单目深度估计网络的监督值,对单目图像的深度估计网络进行监督,以增强单目图像的BEV特征,从而提升整体的检测效果。监督过程中损失函数采用公式(1)计算深度标签与预测深度之间的损失。
(1)
其中,
使用4D毫米波雷达的标定数据,先将点云从点云坐标系转换到世界坐标系,再通过外参转换至相机坐标系,最后通过相机内参转换至图像坐标系并生成深度信息,以创建出以4D毫米波雷达为显式监督的稀疏深度图。生成稀疏深度图的过程可以按照如下公式计算:
(2)
其中,pts为原始点云,大小为N×3,Tr_velo_to_cam为点云转换至相机坐标系的外参,P0为相机内参矩阵。
在实际应用中,由于4D毫米波雷达点云较为稀疏,为了获得更好的监督效果,本实施例针对引入的稀疏深度图,采用了双线性插值方法构建更加稠密的深度标签,以获得稠密深度图。其公式表示为:
(3)
其中,
生成第二BEV特征
b1、对4D毫米波雷达点云的速度维度进行特征工程,得到7维的4D毫米波雷达点云数据。4D毫米波雷达点云包含
特征工程是指在机器学习和数据挖掘任务中,通过对原始数据进行转换、提取和选择,以创建新的特征或改进现有特征的过程,是构建有效模型和提高预测性能的关键步骤之一。
现有的目标检测方法对于毫米波雷达的速度特征,一般是直接作为额外的特征维度输入网络,通过下游任务的反馈,观察其在主干网络中学习的结果,没有针对速度特征做单独的处理。
由于毫米波雷达点云相对稀疏,本实施例在输入端到端3D目标检测网络前对速度特征进行聚类,并将聚类结果作为额外的维度加入原始特征,基于相同目标的点在速度上更为相近这一特点,通过速度的聚类信息,提升目标检测的结果以此做特征工程。
b2、对7维的4D毫米波雷达点云数据进行转化,得到第二BEV特征。具体操作方法如下:
在x-y平面上均匀划分P个网格,每个网格代表一个柱子,即z方向无限延伸的体素。将预处理后的7维点云分配至每个柱子中并进行编码,添加每个点到所属柱子的算数平均值的距离、以及每个点x-y方向上到柱子x-y中心的偏移量。采用多采样、少不零的方法在每个柱子中设置最大点云数量N,形成一个(9,P,N)的稠密张量,使用点网从9维的稠密张量中提取特征得到点云特征图,并对其进行进行最大池化处理,得到每个柱子中最具代表性的点。将P个柱子按照第一步的划分规则划分为H×W投影到x-y平面,得到(C,H,W)的伪图像,即第二BEV特征。
2.2、使用通道注意力机制的卷积神经网络融合第一BEV特征和第二BEV特征,得到融合特征。本实施例中,通道注意力机制获取取到特征图的每个通道的重要程度,根据获取的重要程度给每个特征赋予一个权重值,从而让卷积神经网络重点关注某些特征通道,提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。详细的操作步骤参阅图2:
以第一BEV特征为输入,先使用1×1卷积层减少特征的通道数量,再使用两个3×3卷积层进行深层特征提取之后与其相加,得到对齐的第一BEV特征,这部分操作的表现形式为:
(4)
其中,
将对齐的第一BEV特征与第二BEV特征进行通道注意力计算,以关注更可能存在目标的区域,从而得到融合特征。详细操作步骤如下:
针对对齐后的第一BE特征和第二BE特征,先使用1×1卷积进行融合后,进行全局平均池化获取上下文信息,然后计算注意力向量引导网络关注注意力权重更高的通道。其表现形式为:
其中,Global表示全局池化操作,RadarFea和ImgFea分别对应4D毫米波雷达点云和图像的BEV特征,
2.3、使用融合特征进行3D目标检测
本实施例使用PointPillars作为检测头,设置每个类别对应的锚框进行检测框回归以及类别预测。PointPillars算法避免了在3D目标检测中使用资源消耗巨大的3D卷积,通过对柱状体素编码的方式,将融合特征转化为伪图像,然后使用2D图像的检测方式进行检测,最后再回归3D BBOX得到结果。具体操作方法如下:
以融合特征为输入,使用神经网络预测出目标检测结果。
根据不同的检测类别设置不同的锚框。本实施例共设有三个类别的锚框,每个锚框都有两个方向:分别是BEV视角下的0度和90度。每个类别的先验证只有一种尺度信息;分别是车 [3.9, 1.6, 1.56]、人[0.8, 0.6, 1.73]、自行车[1.76, 0.6, 1.73](单位:米),因此共有3种类型的6个锚框。
采用是2D IOU的匹配算法,完成预测检测结果与预设锚框进行真值匹配,并将匹配结果作为最终的目标检测结果输出,所述目标检测结果包括3D检测框的位置和朝向信息。需要说明的是,本实施例在锚框真值匹配过程中,使用的是2D IOU的匹配算法,直接在BEV视角进行匹配;并没有考虑高度信息,因此,在回归的过程中,每个锚框都需要预测7个参数,分别是
步骤3、计算损失函数值,根据计算出的损失函数值反向传播更新端到端3D目标检测网络参数。深度损失计算如式(6)所示,3D目标检测损失计算如式(7)所示:
(6)
其中,
其中,
步骤4、利用更新好的端到端3D目标检测网络进行目标检测。
对上述方法进行验证:
本实施例的训练和测试均使用VOD数据集,VOD数据集不仅包含相机和激光雷达数据,同时包含4D毫米波雷达数据,该数据集包含多个场景下8600帧数据,同时包含多个类别的标注信息,图像分辨率为1936 × 1216。VOD(The View-of-Delft dataset)数据集为代尔夫特大学发布自动驾驶数据集。使用MMDetection3D部署网络,NVIDIA GeForce GTXTITAN X上训练,批大小设置为4,使用Adam优化器,学习率设置为0.0001,并分别在20,40,60轮次将学习率减小10倍。
表1展示了本实施例的融合4D目标检测方法检测结果与传统的PointPillars检测方法检测结果。其中结果分为两种情况,第一种为对于道路全场景标注区域进行检测,而由于自动驾驶更关注行车区域的检测结果,因此特别地,对于自车前方25米,以及左右各4米内的行车区域做了检测。
表1
参阅表1可知,相较于传统的PointPillars检测方法,本实施例的融合3D目标检测方法的检测精度更高,由于毫米波雷达对于恶劣天气的鲁棒性以及低廉的成本,本发明对于实际应用有很大的价值。
上述实施例仅是本发明的较好的实施例,不局限于发明。在这里应指出对于本领域的技术人员来说,在本发明提供的技术相关启示之下,有可能趋其他相似改进,均可以实现本发明的目的,都应当是作为本发明的保护范围。
- 图像、激光雷达和4D毫米波多模态融合的3D目标检测方法
- 一种基于4D毫米波雷达与激光雷达融合的目标检测方法