一种融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及人工智能技术领域,具体而言,尤其涉及一种融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法。
背景技术
人工智能已经被成功地应用于各种不同的实际任务中,其中深度神经网络是最成功的人工智能模型之一,并在多个应用领域取得了最先进的性能。深度神经网络能够使用大规模网络从大量数据中提取有用特征,这是它能够成功的主要因素。然而,这使得深度神经网络普遍存在参数规模庞大、计算复杂等特征,从而阻碍了它在移动和嵌入式设备上的部署。随着这一问题的出现,各种网络压缩方法应运而生。
网络剪枝是重要的人工智能模型压缩方法,常被用于压缩深度神经网络模型,它通过去除网络中一些不重要的部分,在不影响原始精度的情况下获得更加紧凑的网络。特别是结构性剪枝,能够将网络中地冗余结构整体去除,有利于实现模型的压缩和加速。
现存的结构性剪枝方法主要包括基于重要性的方法和基于正则化的方法。基于重要性的方法通过一些重要性标准,对网络结构进行排序,对重要性较低的结构进行修剪。这种修剪方法需要较多的重训练来恢复因剪枝带来的精度损失,会增加大量的计算成本。基于正则化的方法能够在训练过程中对网络权重进行惩罚,将冗余的结构的权重压缩至零,并将其从网络中去除。由于这些权重很小,对网络的输出几乎没有贡献,它们的去除并不会造成大的精度损失,不需要太多的重训练就可以得到较好的精度。因此,这种方法不会增加计算成本。
网络剪枝是重要的人工智能模型压缩方法,其中基于组正则化的结构性剪枝方法能够有效的修剪网络模型中的冗余结构,同时实现网络模型压缩和模型加速。然而,现存的组正则化方法通常使用固定的惩罚因子将权重压缩至零,这其中存在一个不合理的假设,即假设所有权重都是同等重要的。在实际情况下,神经网络的权重往往具有不同的重要性。一些权重可能对网络的性能具有较大的贡献,而另一些权重可能对网络的性能影响较小。因此,使用相同的惩罚因子,简单地将所有权重按相同的惩罚强度压缩至零,会导致网络性能的下降。另外,惩罚因子作为超参数,它的取值缺乏通用的理论指导,通常需要根据不同的问题进行调参,需要消耗大量的时间成本和计算成本。
组正则化方法是专门用于结构性剪枝的正则化方法,其结构性剪枝效果已经得到了很多工作的验证。然而,现存的组正则化方法通常使用固定的惩罚因子将权重压缩至零,这其中存在一个不合理的假设,即假设所有权重都是同等重要的。这种假设与实际情况相悖,在实际情况下,神经网络的权重往往具有不同的重要性。一些权重可能对网络的性能具有较大的贡献,而另一些权重可能对网络的性能影响较小。因此,使用相同的惩罚因子,简单地将所有权重按相同的惩罚强度压缩至零,会导致网络性能的下降。另外,惩罚因子作为超参数,它的取值缺乏通用的理论指导,通常需要根据不同的问题进行调参,需要消耗大量的时间成本和计算成本。
发明内容
根据上述提出的技术问题,本发明提出了一种融合组正则化剪枝和重要性剪枝的模型压缩方法。该方法在组正则化剪枝中,根据权重组的重要性自适应地调整惩罚因子。使用自适应调整的惩罚因子,能够更合理地对网络进行剪枝,更好地保留对网络性能有重要贡献的权重组。
本发明采用的技术手段如下:
一种融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法,包括:
S1、对深度卷积神经网络中的权重和偏置进行初始化,并初始化组正则化惩罚因子;
S2、将交叉熵损失函数和组正则化损失函数相加得到网络训练的总损失函数;
S3、根据总损失函数进行反向传播,计算损失函数的梯度,并更新网络的权重和偏置,以最小化损失函数;
S4、通过多次迭代的训练过程,不断优化权重和偏置,最终得到训练完善的网络参数;
S5、在训练结束后,对网络进行剪枝操作,压缩网络模型;
S6、对剪枝后的网络进行微调训练,帮助网络适应剪枝后的结构。
进一步地,所述步骤S1,具体包括:
S11、将权重和偏置从正态分布中随机采样为一个较小的值;
S12、对组正则化因子初始化设置为0。
进一步地,所述步骤S2,具体包括:
S21、将交叉熵损失函数表示为
S22、将组正则化损失函数表示为
S23、将交叉熵损失函数和组正则化损失函数相加得到网络训练的总损失函数
其中,
S24、对
。
进一步地,所述步骤S3,具体包括:
S31、使用损失函数对网络的输出进行微分,得到损失函数对输出的梯度;
S32、根据链式法则依次计算每一层的梯度,直到计算出损失函数对每个参数(权重与偏置)的梯度;
S33、如果计算出了损失函数对每个参数的梯度,则使用优化算法来更新网络的参数。
进一步地,所述步骤S33中,更新网络的参数使用的优化算法为:
新参数 = 旧参数 - 学习率 * 参数的梯度
其中,学习率是一个超参数,用于控制参数更新的步长。
进一步地,所述步骤S5,具体包括:
S51、将卷积核整体的参数进行
S52、设置一个阈值,阈值为0.0001,将小于阈值的卷积核进行去除。
进一步地,所述步骤S6,具体包括:
将剪枝后的网络进行训练,使用较小的学习率对网络模型的参数进行微小调整。
进一步地,所述方法能够对不同的权重组施加更加合理的惩罚因子,其中:
对于重要的权重组,施加较小的惩罚因子,在更新中的惩罚力度较小;
对于不重要的权重组,施加较大的惩罚因子,在更新中的惩罚力度较大。
较现有技术相比,本发明具有以下优点:
1、本发明提供的融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法,能够显著改善网络的性能和精度,以VGG16为例在相同的训练迭代次数下,最后的精度能够提升约0.34%;以ResNet18为例在相同的训练迭代次数下,最后的精度能够提升约0.28%。
2、本发明提供的融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法,可以降低网络的计算复杂度,提高网络的计算效率,以VGG16为例与正常的VGG16网络相比,参数数量可以减少87%;以ResNet18为例参数数量可以减少81%。
3、本发明提供的融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法,能够自动地识别和调整惩罚因子的大小,无需手动调整。这样可以减少人工调参的工作量,并确保网络在训练过程中始终受到适当的正则化约束。
4、本发明提供的融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法,可以方便地应用于现有的深度卷积神经网络训练和剪枝流程中,不需要进行大规模的改动或重新设计。这样可以节省时间和资源,使该方法更易于实施和推广。
综上所述,通过使用本发明提出的自适应调整组正则化惩罚因子的方法,可以有效改善深度卷积神经网络的性能和精度,减少参数数量,并简化操作流程。同时,本方法的操作简便,可以方便地应用于现有的网络训练和剪枝流程中。这些改进将为神经网络训练和人工智能模型压缩领域带来更广阔的应用前景和商业价值。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
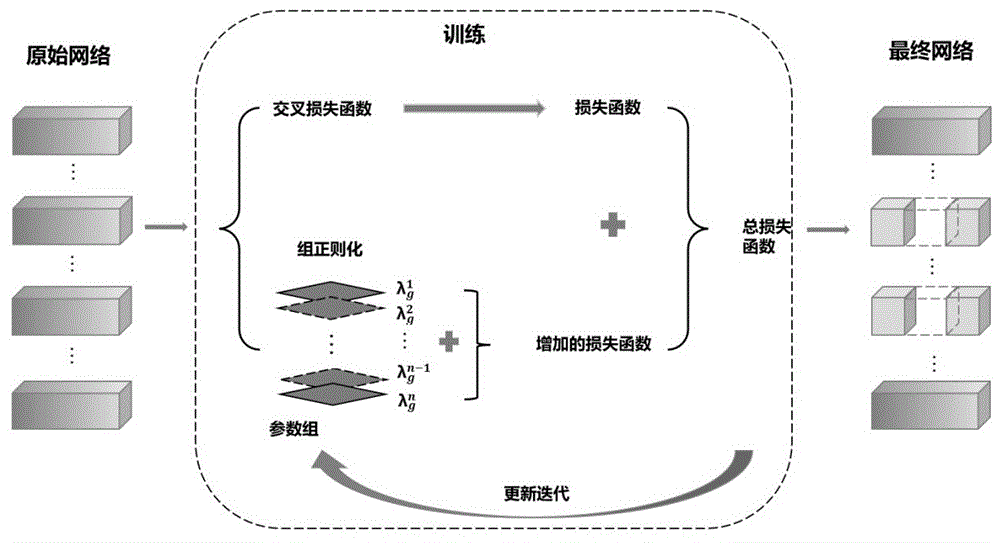
图1为本发明提供的网络修剪总路线图。
图2为本发明提供的组正则化示意图。
图3为本发明实施例提供的相同条件下不同网络在不同方法下参数数量与运行加速比对比结果。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
如图1所示,本发明提供了一种融合组正则化剪枝和重要性剪枝的人工智能模型压缩方法,包括:
S1、对深度卷积神经网络中的权重和偏置进行初始化,并初始化组正则化惩罚因子;
S2、将交叉熵损失函数和组正则化损失函数相加得到网络训练的总损失函数;在本实施例中,在每个训练迭代中,除了计算网络参数所产生的损失函数外,还需要增加组正则化损失函数。这样可以确保网络的每个权重组都受到适当的正则化约束。
S3、根据总损失函数进行反向传播,计算损失函数的梯度,并更新网络的权重和偏置,以最小化损失函数;在本实施例中,通过动态调整组正则化惩罚因子,可以更准确地保留对网络性能有重要贡献的权重组,并剪枝对网络性能影响较小的权重组。
S4、通过多次迭代的训练过程,不断优化权重和偏置,最终得到训练完善的网络参数;这样可以进一步减少网络的参数数量,提高网络的计算效率。
S5、在训练结束后,对网络进行剪枝操作,压缩网络模型;
S6、对剪枝后的网络进行微调训练,帮助网络适应剪枝后的结构。微调训练可以帮助网络适应剪枝后的结构,并提高网络的泛化能力,以进一步提高性能和精度。
具体实施时,作为本发明优选的实施方式,所述步骤S1,具体包括:
S11、将权重和偏置从正态分布中随机采样为一个较小的值;
S12、对组正则化因子初始化设置为0。
具体实施时,作为本发明优选的实施方式,所述步骤S2,具体包括:
S21、将交叉熵损失函数表示为
S22、将组正则化损失函数表示为
S23、将交叉熵损失函数和组正则化损失函数相加得到网络训练的总损失函数
其中,
S24、对
。
在本实施例中,网络模型的参数被分成两个模块进行处理,其中一个模块进行数据拟合,产生交叉熵损失函数,另一个模块能够惩罚网络过滤器对应的权重组,将冗余结构的权重全部压缩为零,如图2所示,其中
具体实施时,作为本发明优选的实施方式,所述步骤S3,具体包括:
S31、使用损失函数对网络的输出进行微分,得到损失函数对输出的梯度;
S32、根据链式法则依次计算每一层的梯度,直到计算出损失函数对每个参数(权重与偏置)的梯度;
S33、如果计算出了损失函数对每个参数的梯度,则使用优化算法来更新网络的参数。更新网络的参数使用的优化算法为:
新参数 = 旧参数 - 学习率 * 参数的梯度
其中,学习率是一个超参数,用于控制参数更新的步长。在本实施例中,初始为0.1,并在网络迭代次数进行50%时与75%时将参数累乘0.1。
在本实施例中,使用网络批处理归一化层(BN层)的比例因子作为重要性标准,来表示权重组的重要性,进而构造可自适应调整的惩罚因子,这样可以给重要性高的过滤器施加小的惩罚因子,对其进行强化保留,给重要性低的过滤器施加大的惩罚因子,将其压缩至零。BN层的比例因子作为重要性标准的优势明显:
(1)BN层的比例因子是网络训练过程中固有的参数,不需要再额外构造参数作为重要性标准,这能节省计算成本;
(2)BN层的比例因子与过滤器输出的特征图息息相关,能够更加准确的表示过滤器的重要性;
(3)BN层的比例因子自身是可更新的,可以带动由其构造的惩罚因子的更新,因此不需要额外设计负责的惩罚因子更新规则。
具体实施时,作为本发明优选的实施方式,所述步骤S5,具体包括:
S51、将卷积核整体的参数进行
S52、设置一个阈值,阈值为0.0001,将小于阈值的卷积核进行去除。
具体实施时,作为本发明优选的实施方式,所述步骤S6,具体包括:
将剪枝后的网络进行训练,使用较小的学习率(0.0005)对网络模型的参数进行微小调整。
具体实施时,作为本发明优选的实施方式,所述方法能够对不同的权重组施加更加合理的惩罚因子,其中:
对于重要的权重组,施加较小的惩罚因子,在更新中的惩罚力度较小;
对于不重要的权重组,施加较大的惩罚因子,在更新中的惩罚力度较大。
实施例
以下表格中VGG、ResNet是标准网络;SSL是同模型下应用固定组正则化因子方法;DRFGR是同模型下应用自适应调整的惩罚因子。
表一 相同条件下Vgg16 与Vgg19在不同方法下不同指标结果
表二 相同条件下ResNet18 与ResNet50 在不同方法下不同指标结果
综上所述,使用自适应调整的惩罚因子的组正则化方法,能够更合理地对网络进行剪枝,可以有效地实现对网络模型的压缩和修剪,同时保持模型的性能和准确性。本发明的改进部分将带来性能、精度、效率、简便性、泛化能力和可扩展性的提升。这些技术效果和主要性能指标的提高将使得本发明的方法在人工智能模型压缩领域具有广泛的应用前景和商业价值。通过使用本发明提出的自适应调整组正则化惩罚因子的方法,可以有效改善深度卷积神经网络的性能和精度,减少参数数量,并简化操作流程。同时,本方法的操作简便,可以方便地应用于现有的网络训练和剪枝流程中。这些改进将为神经网络训练和人工智能模型压缩领域带来更广阔的应用前景和商业价值。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 一种电解液及其制备方法和在双排链轮轴电解加工精密修形中的应用
- 一种高压高电导电解液及其制备方法与应用
- 一种电解液以及使用它的锂硫电池及其制备方法和应用
- 一种电池用电解液及其制备方法和应用、包含其的锂离子电池
- 一种含(2-烯丙基苯氧基)三甲硅烷添加剂的高压功能电解液及其制备方法与应用
- 一种具有防过充和阻燃功能的锂离子电池电解液及其在制备锂离子电池中的应用
- 一种锂电池电解液防过充添加剂及其制备方法