基于表层环境的矿冶区深层土壤重金属污染风险预测方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于环境污染防治技术领域,涉及一种快速评估土壤重金属污染分布预测方法,具体涉及一种基于表层环境的矿冶区深层土壤重金属污染风险预测方法。
背景技术
矿冶过程排放大量含重金属粉尘、废渣和废水,如不恰当处置,则会随干湿沉降、地表径流和污水灌溉进入周边土壤。重金属会在矿冶区土壤中不断富集,含量常常远高于土壤背景值。同时,人为、自然因素均会影响重金属的迁移和归趋,进而影响土壤重金属垂向分布。土壤重金属能二次释放迁移至食物链、地下水和地表水中,进而威胁人体健康,因此矿冶区土壤重金属污染风险防控工作尤为重要。
常规矿冶区土壤重金属垂向分布研究多依赖于大规模土壤采集,工作成本高、效率低,且检测数据缺失现象严重。同时,土壤空间位置与重金属含量,以及污染程度与重金属含量之间均存在高度复杂的非线性映射关系,尤其是矿冶区土壤污染受到自然、生产因素影响较大,且土壤自身理化性质及其与重金属相互作用对重金属垂向分布具有显著影响,导致土壤重金属垂向分布难以采用常规模型预测。因此,亟需构建一种基于表层环境的矿冶区深层土壤重金属污染风险预测方法,以解决常规方法中重金属预测精度低、效率低、成本高的技术问题。
发明内容
本发明提供一种基于表层环境的矿冶区深层土壤重金属污染风险预测方法,快速、准确、经济地评估深层土壤重金属污染风险。
为实现上述技术目的,本发明采用如下技术方案:
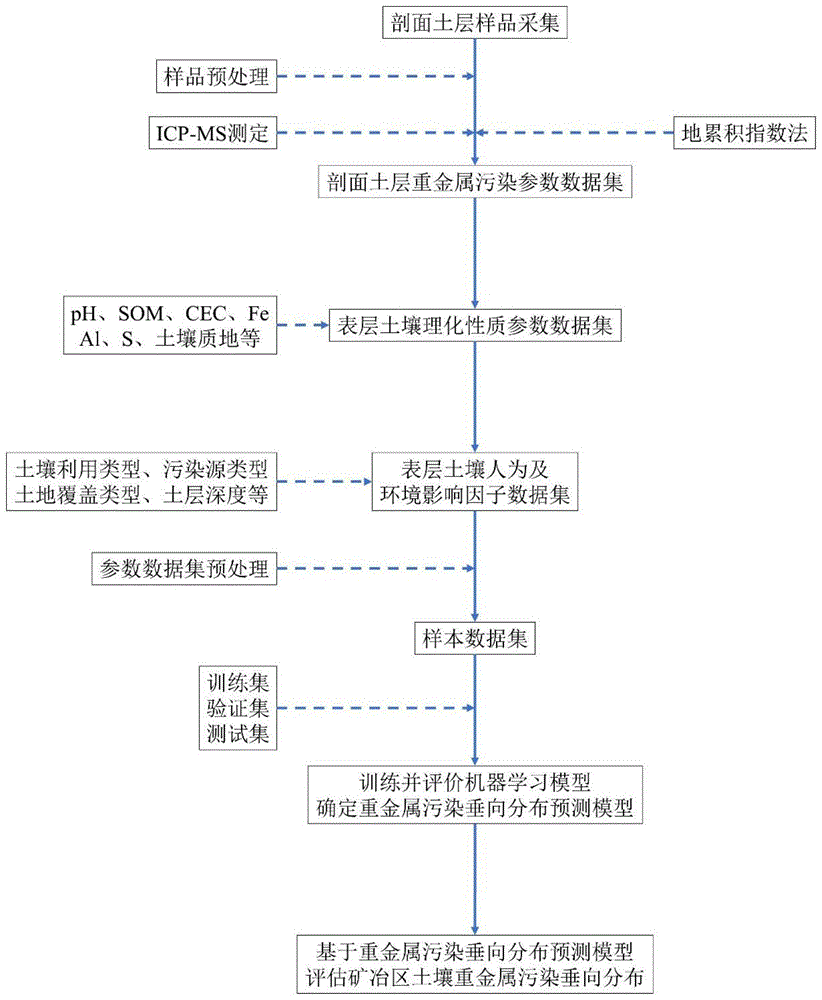
一种基于表层环境的矿冶区深层土壤重金属污染风险预测方法,包括:
步骤1,选择若干个矿冶区,在每个矿冶区均匀选择若干采样点位;
步骤2,在每个采样点位,采集地下预测深度以上各土层的土壤样品,检测各土层土壤样品的多种重金属含量,对应确定各土层土壤样品中每种重金属的污染风险指标;
步骤3,选择采样点位的表层土壤样品,检测获取表层土壤样品的多种理化性质参数和人为及环境影响因子参数;
步骤4,对每个采样点位由步骤2和步骤3得到数据进行预处理,然后根据表层土壤预处理后的多种理化性质参数和人为及环境影响因子参数构建样本的特征向量并作为机器学习模型的输入,以及根据所有土层的重金属污染指数构建样本的标签并作为机器学习模型的输出,每个采样点位对应得到一个样本;
步骤5,将所有采样点对应得到的样本集划分训练集和验证集;使用训练集的样本训练机器学习模型,确定超参数后使用验证集的样本优化超参数,得到矿冶区深层土壤重金属污染风险预测模型;
步骤6,对于深层土壤重金属污染风险未知的任意矿冶区,检测获取其表层土壤的多种理化性质参数和人为及环境影响因子参数,预处理后得到测试样本的特征向量;再将测试样本的特征向量输入至矿冶区深层土壤重金属污染风险预测模型,模型输出得到该矿冶区地下预测深度以上所有土层的重金属污染风险指标。
进一步地,步骤2检测土壤样品的多种重金属含量,具体检测方法为:将土壤样品过100目筛后采用HNO
进一步地,所述多种重金属包括以下任意一种或多种:As、Cd、Cr、Cu、Ni、Pb、Zn、Hg。
进一步地,基于地累积指数法确定各土层土壤样品中每种重金属的污染风险指标,表示为:
式中,I
进一步地,步骤3检测获取的多种理化性质参数包括:土壤pH、土壤有机质含量、土壤阳离子交换量、土壤铁含量、土壤铝含量、土壤硫含量、土壤质地。
进一步地,土壤pH采用电位法测定,土壤有机质含量采用低温外热重铬酸钾氧化-比色法测定,土壤阳离子交换量采用乙酸铵法测定,土壤铁含量和土壤铝含量均采用HNO
进一步地,步骤3检测获取的人为及环境影响因子参数包括:土地利用类型、土地覆盖类型、污染源类型、土层深度;土地利用类型包括场地、农用地、林地、草地、废弃地、居住用地;土地覆盖类型包括农作物、植物、废渣、裸地、混凝土;污染源类型包括大气沉降、废水地表径流、废渣地表径流、降雨、农业灌溉、农肥施用、降雨。
进一步地,步骤4中的预处理包括标准化处理和降维处理。
进一步地,所述机器学习模型采用多元线性回归、支持向量机、随机森林或者神经网络;采用贝叶斯优化、遗传算法、网格搜索或者随机搜索法,确定机器学习模型的超参数;采用交叉验证法优化机器学习模型的超参数。
进一步地,所述机器学习模型为BP神经网络,优化的超参数包括神经网络层数、网络类型、每层神经元数量、神经元激活函数种类、损失函数、优化方法、批量数据大小、迭代次数、学习率、正则系数、权重初始化方法中的一种或多种。
有益效果
本发明通过表层土壤的理化性质参数和人为及环境影响因子预测深层土壤重金属污染风险的评估技术,综合考虑了土壤自身理化性质和人为及环境因子对土壤重金属污染风险垂向分布的影响,有效提高了矿冶区深层土壤重金属污染风险预测模型的准确性、普适性和泛化能力。同时,该方法评估效率高、实施成本低,对推动高空间异质性区域深层土壤重金属污染防控具有重要意义。
附图说明
图1为本发明提供的基于表层环境的矿冶区深层土壤重金属污染风险预测方法的流程图。
图2为本发明实施例中铜冶炼区域深层土壤重金属污染风险预测模型评价的拟合结果图,其中(a)(b)(c)(d)(e)分别为As、Cd、Cu、Pb、Zn垂向污染预测值与真实值的拟合线。
图3为本发明实施例中铜冶炼区域深层土壤重金属污染风险预测模型评价的性能参数结果图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例以本发明的技术方案为依据开展,给出了详细的实施方式和具体的操作过程,对本发明的技术方案作进一步解释说明。
下面将结合附图对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明的一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
并且,本发明各个实施方式之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
当实施例给出数值范围时,应理解,除非本发明另有说明,每个数值范围的两个端点以及两个端点之间任何一个数值均可选用。除非另外定义,本发明中使用的所有技术和科学术语与本技术领域的技术人员对现有技术的掌握及本发明的记载,还可以使用与本发明实施例中所述的方法、设备、材料相似或等同的现有技术的任何方法、设备和材料来实现本发明。
下面对本发明的实施例作详细说明,本实施例以本发明的技术方案为依据开展,给出了详细的实施方式和具体的操作过程,对本发明的技术方案作进一步解释说明。
以湖南省某铜冶炼区土壤重金属污染垂向分布预测为例。一种基于表层环境的矿冶区深层土壤重金属污染风险预测方法,包括以下步骤:
步骤1,选择多个冶炼区,均划分200m×200m采样栅格,每个栅格作为1个采样点位用于采集土壤剖面样品。
步骤2,在每个栅格采样点位进行土壤剖面取样,0~1m深度每隔0.2m采集,1~4m每隔0.5m采集,大于4m每隔1m采集,共采集土壤剖面76个,剖面土层样品共1292个。
对采集到的每个采样点位的各土层土壤样品,检测其多种重金属含量,对应确定各土层土壤样品中每种重金属的污染风险指标。
其中,多种重金属含量的检测方法为:将土壤样品过100目筛后采用HNO
基于地累积指数法确定各土层土壤样品中每种重金属的污染风险指标,表示为:
式中,I
步骤3,选择采样点位的表层土壤样品,检测获取表层土壤样品的多种理化性质参数和人为及环境影响因子参数。
具体地,本实施例中检测的多种理化性质参数包括:土壤pH、土壤有机质含量、土壤阳离子交换量、土壤铁含量、土壤铝含量、土壤硫含量、土壤质地。其中,土壤pH采用电位法测定,土壤有机质含量采用低温外热重铬酸钾氧化-比色法测定,土壤阳离子交换量采用乙酸铵法测定,土壤铁含量和土壤铝含量均采用HNO
检测获取的人为及环境影响因子参数包括:土地利用类型(场地、农用地、林地、草地、废弃地、居住用地等)、土地覆盖类型(农作物、植物、废渣、裸地、混凝土等)、污染源类型(大气沉降、废水地表径流、废渣地表径流、降雨、农业灌溉、农肥施用、降雨等)、土层深度。
步骤4,对每个采样点位由步骤2和步骤3得到数据进行预处理,然后根据表层土壤预处理后的多种理化性质参数和人为及环境影响因子参数构建样本的特征向量并作为机器学习模型的输入,以及根据所有土层的重金属污染指数构建样本的标签并作为机器学习模型的输出,每个采样点位对应得到一个样本。
其中的预处理包括标准化处理和降维处理,标准化处理可采用Min-Max标准化法、Z-score标准化法、0-1标准化法、线性比例标准化法等,降维处理可采用主成分分析(PCA)、线性判别分析(LDA)、等距特征映射(ISOMap)等,本实施例中采用0-1标准化法和主成分分析法进行预处理。
步骤5,将所有采样点对应得到的样本划分训练集和验证集;使用训练集的样本训练机器学习模型,确定超参数后使用验证集的样本优化超参数,得到矿冶区深层土壤重金属污染风险预测模型。
本实施例中,为了对训练优化得到的预测模型进行测试,在训练集的基础上还划分测试集,即将所有采样点对应得到的样本采用随机划分的方法,按3:1:1的比例划分训练集、验证集和测试集。
其中,所述机器学习模型采用多元线性回归、支持向量机、随机森林或者神经网络等;确定机器学习模型的超参数,具体可采用贝叶斯优化、遗传算法、网格搜索或者随机搜索法等;采用交叉验证法优化机器学习模型的超参数。
在本实施例中,机器学习模型具体采用BP神经网络,优化的超参数包括神经网络层数、网络类型、每层神经元数量、神经元激活函数种类、损失函数、优化方法、批量数据大小、迭代次数、学习率、正则系数、权重初始化方法中的一种或多种。
利用训练集训练神经网络,通过遗传算法确定超参数后在验证集上交叉验证优化超参数,优化后的超参数分别为“神经网络类型为BP神经网络”,“神经网络层数=2”,“每层神经元数量=5”,“神经元激活函数为Rectifier激活函数”,其余参数均为默认值。
再采用测试集对确定并优化超参数过后的机器学习模型进行评价,将评价结果最佳的机器学习模型用于深层土壤重金属污染风险预测。其中,对机器学习模型进行评价的指标包括决定系数(R
式中,N为采样点数量,Obs
步骤6,对于深层土壤重金属污染风险未知的任意矿冶区,检测获取其表层土壤的多种理化性质参数和人为及环境影响因子参数,预处理后得到测试样本的特征向量;再将测试样本的特征向量输入至矿冶区深层土壤重金属污染风险预测模型,模型输出得到该矿冶区地下预测深度以上所有土层的重金属污染风险指标。
本实施例中,经过多次循环运行之后性能表现最佳的机器学习模型是BP神经网络。如图2和图3所示,矿冶区深层土壤重金属污染风险预测模型在测试集上As、Cd、Cu、Pb、Zn垂向污染预测值与真实值之间的R
以上实施例为本申请的优选实施例,本领域的普通技术人员还可以在此基础上进行各种变换或改进,在不脱离本申请总的构思的前提下,这些变换或改进都应当属于本申请要求保护的范围之内。
- 一种基于土壤重金属DTPA提取态含量的水稻籽粒重金属污染风险预测方法
- 一种基于土壤重金属DTPA提取态含量的水稻籽粒重金属污染风险预测方法