一种自然场景下弯曲文本识别的方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及计算机视觉技术领域,具体为一种自然场景下弯曲文本识别的方法。
背景技术
文本识别是计算机视觉研究领域的分支之一。文本识别的目标是将图像或自然场景中的文本转换为可编辑和可搜索的文本形式。它可以应用于各种领域,如自动化办公、数字化档案管理、图书馆信息管理、车牌识别、票据处理、自动驾驶、智能手机应用等。
现有技术中,通过文本识别,可以大大加快信息处理速度。其中自然场景中的文字的检测和识别对我们理解世界很有帮助,它应用在图像搜索、即时翻译、机器人导航、工业自动化等领域。
但是,为了识别出自然场景下的文本,我们需将文本从复杂的图片场景中独立出来,剔除场景的干扰。然后针对不同的文本进行调整。尤其是弯曲文本,需要进行弯曲文本的矫正以及拉平,然后再对水平文字进行识别。
发明内容
本发明的目的在于提供一种自然场景下弯曲文本识别的方法,以解决上述背景技术中提出的问题。
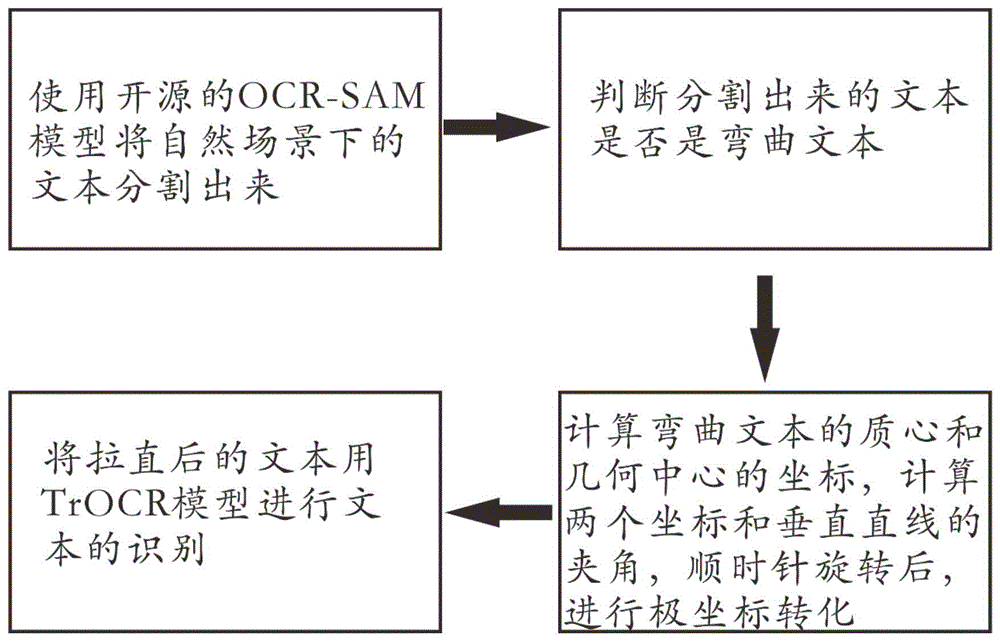
为实现上述目的,本发明提供如下技术方案:一种自然场景下弯曲文本识别的方法,所述方法包括以下步骤:
用开源的OCR-SAM网络模型将自然场景下的文本分割出来;
判断分割出来的文本是否是弯曲文本;
计算弯曲文本的质心和几何中心的坐标,计算两个坐标和垂直直线的夹角,顺时针旋转后,进行极坐标转化;
将拉直后的文本用TrOCR模型直接进行文本识别。
优选的,还包括计算分割出来的文字的面积,再计算分割出来的图像的最小旋转矩形的面积,最小旋转矩形是能够完全包围该文字的最小面积矩形,用两者相除的值,如果小于一定的值,说明整个矩形中还有很多空余的面积,判断分割出来的文字是弯曲的文字。
优选的,图像的质心的公式为:
对于更实际的离散且有限点集的情形下,前面二维的形式转化为如下形式:
上述公式2中的被除数就是图像的高斯面积,具体计算的方法是将分割出来的图像转灰度图,再进行二值化处理,图像变成由0和1组成,将图像每个像素点相加就是图像的高斯面积,获取二值图像中非零像素的坐标,并分别计算x和y方向上的坐标和,就是上述公式2中的除数。
优选的,几何中心坐标的计算时,先计算分割出来的图像的最小外接圆,然后圆心坐标就是图像的几何中心坐标,将两个坐标相减后求:
其中geo代表几何中心,gra代表质心,求出角度后将图像顺时针旋转角度,将图像矫正后就将坐标转化为极坐标,拉直。
与现有技术相比,本发明的有益效果是:
本发明提出的自然场景下弯曲文本识别的方法,通过分割出自然场景下的文本,再判断其中弯曲的部分,将这部分的文本矫正拉直后再进行识别,实现了自然场景下弯曲文本识别。
附图说明
图1为本发明方法流程图。
具体实施方式
为了使本发明的目的、技术方案进行清楚、完整地描述,及优点更加清楚明白,以下结合附图对本发明实施例进行进一步详细说明。应当理解,此处所描述的具体实施例是本发明一部分实施例,而不是全部的实施例,仅仅用以解释本发明实施例,并不用于限定本发明实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种自然场景下弯曲文本识别的方法,包括以下步骤:
用开源的OCR-SAM网络模型将自然场景下的文本分割出来;
判断分割出来的文本是否是弯曲文本;
计算弯曲文本的质心和几何中心的坐标,计算两个坐标和垂直直线的夹角,顺时针旋转后,进行极坐标转化;
将拉直后的文本用TrOCR模型直接进行文本识别。
具体步骤如下:
OCR-SAM模型是将MMOCR和SAM模型结合的网络。其中MMOCR是一个基于PyTorch和mmdetection的开源工具箱,用于文本检测、文本识别以及相应的下游任务,包括关键信息提取。它是OpenMMLab项目的一部分。它可以使用最新训练完的文本检测模型DBNet++将自然场景下的文本进行定位,然后用SAM网络将这一部分数据进行分割。
计算分割出来的文字的面积,再计算分割出来的图像的最小旋转矩形的面积,最小旋转矩形是能够完全包围该文字的最小面积矩形。然后用两者相除的值,如果小于一定的值,说明整个矩形中还有很多空余的面积,这判断这个分割出来的文字是弯曲的文字。
识别出弯曲文字后,需要将弯曲文字进行矫正和极坐标转化。
矫正就是将原本不正的弯曲文本旋转一定的角度,使得后面的极坐标转化图像不会将文字前后顺序不对。旋转的角度由图像的质心和图像的几何中心的连线和垂直直线的夹角决定。求图像的质心的公式为
对于更实际的离散且有限点集的情形下,前面二维的形式可以转化为如下形式:
上述公式2中的被除数就是图像的高斯面积。具体计算的方法是将分割出来的图像转灰度图,再进行二值化处理,图像变成由0和1组成。将图像每个像素点相加就是图像的高斯面积。再获取上述二值图像中非零像素的坐标,并分别计算x和y方向上的坐标和,就是上述公式2中的除数。
计算出质心坐标后就再计算图像的几何中心坐标。几何中心坐标的计算需要先计算分割出来的图像的最小外接圆,然后圆心坐标就是图像的几何中心坐标。将两个坐标相减后求
其中geo代表几何中心,gra代表质心。求出角度后将图像顺时针旋转角度即可。(如果结果为负,即向逆时针旋转相应的角度)
将图像矫正后就将坐标转化为极坐标,拉直即可
使用训练完成的TrOCR模型对上述拉直后的图像进行文字识别。TrOCR是一种端到端文本识别方法,具有预先训练的图像Transformer和文本Transformer模型,它利用Transformer架构进行图像理解和单词级文本生成。TrOCR模型在印刷品、手写品和场景文本识别任务上优于目前最先进的模型。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种在原位红外分析装置的原位池中实现介质阻挡放电的装置及方法
- 一种印刷机械的具有阻挡装置的入纸装置
- 一种沟渠防堵塞回灌过滤装置
- 一种环境保护沟渠杂物阻挡转移收集装置
- 一种环境保护沟渠杂物阻挡装置及阻挡方法