营销指标实时聚合方法、装置和设备
文献发布时间:2024-04-18 20:01:30
技术领域
本申请涉及大数据技术领域,具体涉及一种营销指标实时聚合方法、装置和设备。
背景技术
目前,请参照图2,现有营销产品(例如手机流量产品)评估的方式,通常采用接口文件的方法,协调各系统定时输出约定好的校园、交通枢纽、节假日等流量产品相关的营销数据,上传至指定的FTP(File Transfer Protocol,即文件传输协议)目录,检测到文件后进行数据入库操作,再由定时调度对上一小时的数据进行流量营销评估计算,呈现推广10元10G、任我看等流量产品的渠道接触数,渠道响应数、渠道订购数、以及各年龄阶段、职位的流程接触、响应、订购情况,其主要实现架构如下:
环节一:各系统按照数据格式开发数据接口,按约定的时间定时生成营销产品的数据文件,同时推送至FTP服务器,以文件方式告知接收方进行入库操作;
环节二:接收方定时扫描FTP服务器,当扫描到营销数据后,从FTP服务器下载营销数据,同时对文件进行解析入库处理,入库至oracle数据库;
环节三:启用定时统计程序,定时从oracle数据库进行数据统计,主要统计指标:客户接触指标、客户响应指标、客户订购指标、客户画像指标。
现有技术主要存在以下问题:
1、数据采集延时,需由各渠道对营销产品的营销数据定时的输出,由需保障各系统的业务,对数据只能进行低频增量输入,在数据采集方面通常为一小时传输或闲时传输;
2、数据入库延时,由于入库程序未能实时感知各渠道数据上传情况,只能采取定时检测文件,定时做文件处理及入库,而每小时大数据量的入库,导致数据库IO瓶颈,通常需要在3-4个小时处理完成;
3、数据指标评估延时,由于数据采集、数据入库的时延过长,导致数据指标评估延时,即当到指标数据时,数据已延时5-6个小时,难以满足实时评估客户对营销产品的态度。
发明内容
本申请实施例提供一种营销指标实时聚合方法、装置和设备,用以解决数据采集延时、数据入库延时以及数据指标评估延时的技术问题。
第一方面,本申请实施例提供一种营销指标实时聚合方法,包括:
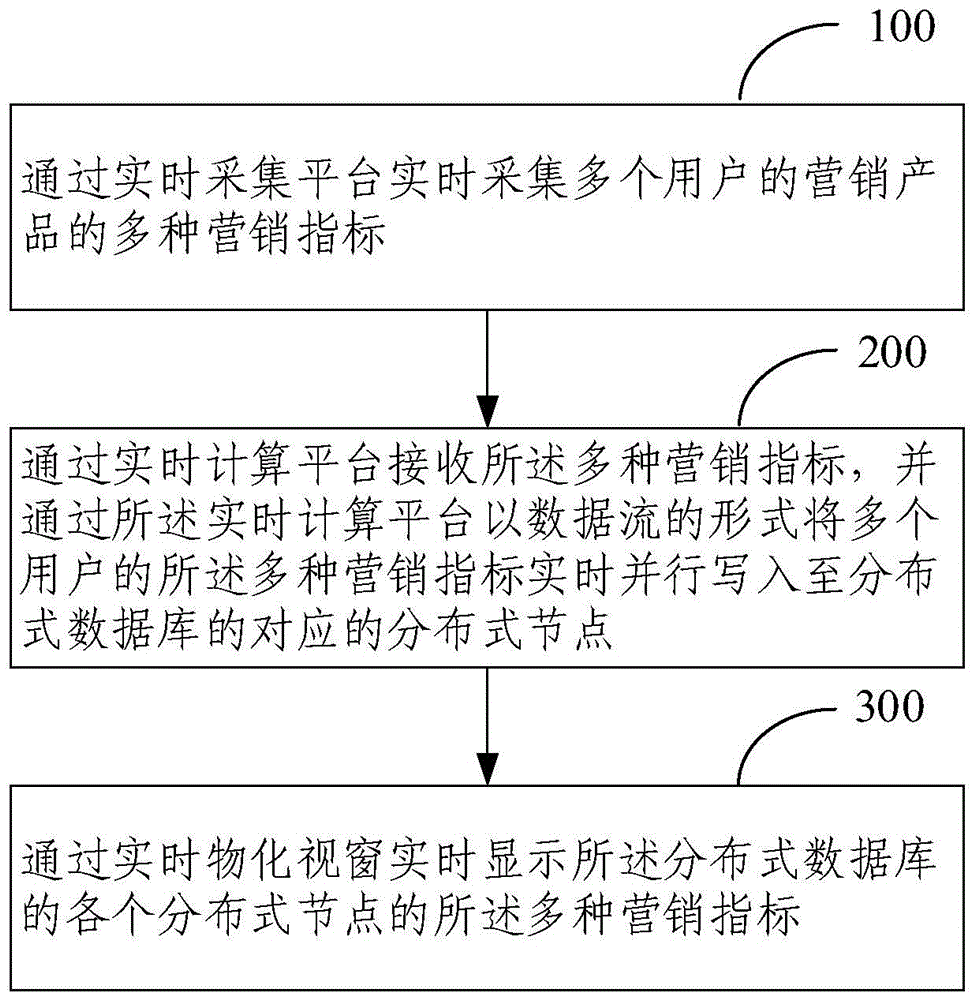
通过实时采集平台实时采集多个用户的营销产品的多种营销指标;
通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;
通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
在一个实施例中,所述通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点,包括:
通过所述实时计算平台基于一致性哈希方法计算各用户的所述多种营销指标在所述分布式数据库的待存放节点位置;
通过所述实时计算平台将待存放节点位置相同的用户的所述多种营销指标聚合形成数据流;
通过所述实时计算平台将各所述待存放节点位置的所述数据流并行写入至所述分布式数据库对应的分布式节点。
在一个实施例中,所述通过所述实时计算平台基于一致性哈希方法计算各用户的所述多种营销指标在所述分布式数据库的待存放节点位置,包括:
通过所述实时计算平台读取所述分布式数据库的多个分片表ID、分片表ID的总数量、以及多个分布式节点ID;
通过所述实时计算平台基于一致性哈希方法实时计算所述各个分片表ID对应的目标分布式节点ID;
通过所述实时计算平台实时存储所述各个分片表ID对应的目标分布式节点ID;
通过所述实时计算平台基于各用户的特征数据计算各用户的多种所述营销指标对应的待存放分片表ID;
通过所述实时计算平台基于所述待存放分片表ID查询所述各个分片表ID对应的目标分布式节点ID,得到各用户的所述多种营销指标在所述分布式数据库的待存放节点位置。
在一个实施例中,所述通过所述实时计算平台基于一致性哈希方法实时计算所述各个分片表ID对应的目标分布式节点ID,包括:
通过所述实时计算平台计算各分片表ID的哈希值;
通过所述实时计算平台将各所述哈希值放置于哈希环中,在哈希环上顺时针查找距离所述各分片表ID的哈希值最近的分布式节点ID,并确定距离所述各分片表ID的哈希值最近的分布式节点ID为各分片表ID对应的目标分布式节点ID。
在一个实施例中,所述通过所述实时计算平台基于各用户的特征数据计算各用户的多种所述营销指标对应的待存放分片表ID,包括:
通过所述实时计算平台基于FNV1_32_HASH方法计算各用户的特征数据的哈希值;
通过所述实时计算平台基于所述分片表ID的总数量对所述各用户的特征数据的哈希值进行取余运算,得到各用户的多种所述营销指标对应的待存放分片表ID。
在一个实施例中,所述营销指标实时聚合方法还包括:
确定预设解析规则和预设清洗规则,将预设解析规则和预设清洗规则广播至所述实时计算平台的各个执行节点;
通过各个所述执行节点基于预设解析规则对各所述营销指标中的字段进行解析;
通过各个所述执行节点基于预设清洗规则对解析后各所述营销指标中的字段进行清洗。
第二方面,本申请实施例提供一种营销指标实时聚合装置,包括:
采集模块,用于通过实时采集平台实时采集多个用户的营销产品的多种营销指标;
入库模块,用于通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;
实时物化视窗实时显示模块,用于通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
第三方面,本申请实施例提供一种电子设备,包括处理器和存储有计算机程序的存储器,所述处理器执行所述程序时实现第一方面所述的营销指标实时聚合方法的步骤。
第四方面,本申请实施例提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的营销指标实时聚合方法的步骤。
第五方面,本申请实施例提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现第一方面所述的营销指标实时聚合方法的步骤。
本申请实施例提供的营销指标实时聚合方法、装置和设备,通过实时采集平台实时采集多个用户的营销产品的多种营销指标,从而本申请实施例实现多个用户的多种营销指标的实时采集;又通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;从而本申请实施例充分利用分布式数据库优势,多个用户的营销产品的多种营销指标以数据分片方式实现实时并行写入至分布式数据库对应的分布式节点,又通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。本申请实施例采用实时物化视图,以低消耗方式实现营销指标的自动更新,便于实时查询、展示及评估营销指标。
附图说明
为了更清楚地说明本申请或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的营销指标实时聚合方法的流程示意图之一;
图2是现有方法提供的营销指标实时聚合方法的流程示意图;
图3是本申请实施例提供的分布式数据库的结构示意图;
图4是本申请实施例实现调整营销策略的流程示意图;
图5是本申请实施例提供的营销指标实时聚合方法的流程示意图之二;
图6是本申请实施例提供的营销指标实时聚合方法的流程示意图之三;
图7是本申请实施例提供的通过所述实时计算平台基于所述分片表ID的总数量对所述各用户的特征数据的哈希值进行取余运算,得到各用户的多种所述营销指标对应的待存放分片表ID的示意图;
图8是本申请实施例提供的营销指标实时聚合装置的结构示意图;
图9是本申请实施例提供的电子设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
图1为一种营销指标实时聚合方法。请参照图1,本申请实施例提供一种营销指标实时聚合方法,可以包括:
步骤100、通过实时采集平台实时采集多个用户的营销产品的多种营销指标;
电子设备通过实时采集平台实时采集多个用户的营销产品的多种营销指标。其中,营销产品可以是各种进行对用户业务营销的营销产品,例如本申请实施例中营销产品是手机流量产品。营销指标是手机流量产品对应的营销数据。例如是:营销活动编码、客户群编码、流量产品编码、用户手机号码、流量产品推送时间、渠道编号、广告位编码、用户响应内容、响应时间、响应结果、归属地市,其中响应结果为:已接触、已办理、办理失败、已接触有意向、拒绝中的任意一种。渠道编号是各个线上渠道如:短信、网页广告位等渠道的编号。客户群编码包括学生群体、上班族群体、老人群体的编码。
实时采集平台可选用各种能够实时采集多个用户的营销指标的数据采集平台。例如可以是Filebeat、Flume、Sqoop、LogStash、DataX、Canal Flume等实时采集平台。在本申请实施例中,使用Filebeat作为实时采集工具,Filebeat是用于转发和集中日志数据的轻量级传送工具,相对于其他的采集工具,其所占系统的CPU和内存几乎可以呼略不计,因此,基于轻量化的需求本申请实施例采用Filebeat作为实时采集平台。
本申请实施例通过实时采集平台实时采集多个用户的营销产品的多种营销指标,从而本申请实施例实现多个用户的多种营销指标的实时采集。
步骤200、通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;
电子设备通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点。
其中,实时计算平台可选用各种实时计算引擎,例如SparkStreaming、FLINK、Storm等。本申请实施例中选用SparkStreaming作为实时计算平台。
需要说明的是,在一些实施例中,实时采集平台实时采集的多个用户多种营销指标通过消息中间件进行缓冲,电子设备控制实时采集平台多个用户多种营销以文本方式实时推送至kafka集群。电子设备控制实时计算平台SparkStreaming实时通过kafka集群读取多个用户的多种营销指标。
本申请实施例的分布式数据库可选用各种采取分布式架构的数据库,例如分布式数据库可以是AnalyticDB、PostgreSQL、MYSQL等。本申请实施例选用AnalyticDB作为分布式数据库。
AnalyticDB是大规模并行分析数据库,其分布式架构,可线性扩展的特性,可以应付TB级/PB的大数据计算分析与存储。依据其分布式架构的特性,以及其提供的以分布式表创建,本申请实施例为加速数据的存储与计算分析,设计以用户的特征数据(如手机号码或身份证号码)为分布式主键,同时使用一致性哈希算法(或称一致性哈希方法)将用户的手机号码的营销指标分布到分布式数据库AnalyticDB的多个分布式节点(即segment节点),利用多主机、多磁盘的优势,加速大数据的计算分析与存储。
请参照图3,分布式数据库AnalyticDB通过主节点(即图3中的Master节点)存储元数据信息,不负责存储业务数据,主节点存储主表与分片表的对应关系,同时处理所有用户连接,对接收到的语句建立查询计划,协调工作处理过程,将执行语句分发至各分布式节点(即图3中的segment节点),收集各分布式节点的执行结果,返回由主节点返回最终执行结果。
分布式数据库AnalyticDB创建分片表结构的代码如下:
CREATE TABLE FEED_BACK_USR_LOG(
USR_NBR VARCHAR(30),--用户手机号码
ACT_STEP_ID VARCHAR(30),--策略编码
CUSTOM_CODE VARCHAR(30),--客户群编码
.......--其他字段信息
FEED_BACK_TIME TIMESTAMP--反馈时间
)DISTRIBUTED BY HASH(USR_NBR)--采用以用户的手机号码为键值采用哈希算法作分片表。
本申请根据分布式数据库AnalyticDB的特性,建立以用户的手机号码为键值的分片表,分片表存储多个用户的多种营销指标。以将用户的手机号码对应的多种营销指标均匀打散到AnalyticDB的每一个分布式节点。
具体的,通过所述实时计算平台通过一致性哈希方法计算各个用户的多种营销指标的在分布式数据库的待存放位置(即分片表)。以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点。
从而本申请实施例充分利用分布式数据库优势,多个用户的营销产品的多种营销指标以数据分片方式实现实时并行写入至分布式数据库对应的分布式节点。
步骤300、通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
电子设备通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
多个用户的营销产品的多种营销指标以数据分片方式实现实时并行写入至分布式数据库对应的分布式节点后,通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
电子设备通过采用实时物化视图,展示实时汇总当天接触指标、响应指标、订购指标、画像指标,对比传统物化视图,实时物化视图不需要手工刷新,当基表发生变化时,实时物化视图将以较低的性能消耗同步发生改变,并可保证数据强一致。例如在一个实施例中,构建实时物化视图,以当天为维度计算实时指标总量的代码如下:CREATE INCREMENTALMATERIALIZED VIEW DAY_SUM AS SELECT count(USR_NBR)touch_sum from FEED_BACK_USR_LOG where to_char(FEED_BACK_TIME,"yyyy-MM-dd")=to_char(current_timestamp,"yyyy-MM-dd")and feed_code='1001'
上述代码展示是对接触指标建立实时物化视图,基于当天实时指标统计,只需查询该实时物化视图,可获取实时指标数据。通过实时物化视图,短时间内可完成指标统计。
接触指标是指用户通过线上渠道,如:短信、网页广告位等,统计用户在渠道上看到的广告多少次;画像指标:从离线历史数据分析出来的用户行为数据如:常住地、工作地、喜欢看视频等。或用户属性数据如:有车、有房、有小孩等。另外还包括实时画像,如正在进行时:正在浏览网页、正在看视频、在某地经过等,对这种标签数据进行统计汇总。响应指标、订购指标指的是对流量产品的响应结果、订购结果等。
分布式实时物化视图的优势在于,通过多个分布式节点的并行数据加载,加速数据的实时刷新,每个分布式节点管理自己的刷新日志,以及检测日志过程,当营销指标发生变更时,同时将营销指标刷入数据库,从而以达到数据秒级更新的效果,保证实时物化视图数据随源表数据变化而变化。
通过实时采集平台实时采集多个用户的营销产品的多种营销指标,从而本申请实施例实现多个用户的多种营销指标的实时采集;又通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;从而本申请实施例充分利用分布式数据库优势,多个用户的营销产品的多种营销指标以数据分片方式实现实时并行写入至分布式数据库对应的分布式节点;又通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。本申请实施例采用实时物化视图,以低消耗方式实现营销指标的自动更新,便于实时查询、展示及评估营销指标。
请参照图4,在通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标的基础上,依据实时入库的多种营销指标,可实时统计出流量产品在哪个渠道的订购效果好,哪个渠道客户的响应度低,哪个渠道被拒绝的次数多,同时可跟踪出,哪个人群的客户对产品的喜好度高。针对客户对渠道、广告位、产品的响应层度,依靠实时数据与离线数据融合,多维分析流量产品在不同人群的喜好层度,以实时调整流量产品的推广策略,最终达到实时精准营销的目的。
在本申请的其他方面,请参照图5,步骤200、所述通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点,包括:
步骤210、通过所述实时计算平台基于一致性哈希方法计算各用户的所述多种营销指标在所述分布式数据库的待存放节点位置;
电子设备通过所述实时计算平台基于一致性哈希方法计算各用户的所述多种营销指标在所述分布式数据库的待存放节点位置。
具体的,在本申请实施例中,请参照图6,步骤210、所述通过所述实时计算平台基于一致性哈希方法计算各用户的所述多种营销指标在所述分布式数据库的待存放节点位置,包括:
步骤211、通过所述实时计算平台读取所述分布式数据库的多个分片表ID、分片表ID的总数量、以及多个分布式节点ID;
电子设备通过所述实时计算平台读取所述分布式数据库的多个分片表ID、分片表ID的总数量、以及多个分布式节点ID。例如分布式数据库的具有分片表ID的总数量为32的分片表ID,即分片表001到分片表032。分布式数据库具有5个分布式节点ID,即分布式节点1到分布式节点5。通过所述实时计算平台还读取分布式节点的连接方式,分片表结构、字段信息、记录数、分片表ID的哈希值等信息。
步骤212、通过所述实时计算平台基于一致性哈希方法实时计算所述各个分片表ID对应的目标分布式节点ID;
电子设备通过所述实时计算平台基于一致性哈希方法实时计算所述各个分片表ID对应的目标分布式节点ID。
本申请实施例根据分片表ID的哈希值,将分片表分布在不同的分布式节点。即,将分片表落于2^32的圆中,相当于将分布式数据库分成2^32的槽位,分片表将落于其中的一个槽位。其中分片表ID的ID值通过固定值加随机的方式设定,例如FEED_BACK_USR_LOG_001为分片表ID。这样,本申请实施例通过一个分片表管理不同用户的多种营销指标,又通过一个分布式节点管理多个分片表。
具体的,步骤212、所述通过所述实时计算平台基于一致性哈希方法实时计算所述各个分片表ID对应的目标分布式节点ID,包括:
步骤2121、通过所述实时计算平台计算各分片表ID的哈希值;
步骤2122、通过所述实时计算平台将各所述哈希值放置于哈希环中,在哈希环上顺时针查找距离所述各分片表ID的哈希值最近的分布式节点ID,并确定距离所述各分片表ID的哈希值最近的分布式节点ID为各分片表ID对应的目标分布式节点ID。
电子设备通过所述实时计算平台计算各分片表ID的哈希值。例如计算分片表ID为FEED_BACK_USR_LOG_001的哈希值为5。通过所述实时计算平台将各所述哈希值放置于哈希环中,在哈希环上顺时针查找距离所述各分片表ID的哈希值最近的分布式节点ID为分布式节点1,那么确定距离所述分片表ID FEED_BACK_USR_LOG_001的哈希值最近的分布式节点1为各分片表ID对应的目标分布式节点。
步骤213、通过所述实时计算平台实时存储所述各个分片表ID对应的目标分布式节点ID。
通过所述实时计算平台实时存储所述各个分片表ID对应的目标分布式节点ID。例如,分片表ID FEED_BACK_USR_LOG_001的哈希值对应分布式节点1,分片表ID FEED_BACK_USR_LOG_002的哈希值对应分布式节点2等。其中通过所述实时计算平台还实时存储包括:分布式节点的连接方式,分片表结构、字段信息、记录数、分片表ID的哈希值等信息。
具体的,电子设备控制实时计算平台通过嵌套HashMap方式,将存储所述各个分片表ID对应的目标分布式节点ID存储于实时计算平台的Executor内存中,同时采用内存cache方式,定时更新存储所述各个分片表ID对应的目标分布式节点ID,以适用于分布式节点扩容或收缩的情况,适配于实时改变分布式节点计算方式。
步骤214、通过所述实时计算平台基于各用户的特征数据计算各用户的多种所述营销指标对应的待存放分片表ID;
电子设备通过所述实时计算平台基于各用户的特征数据计算各用户的多种所述营销指标对应的待存放分片表ID。
具体的,在一个实施例中,步骤214、所述通过所述实时计算平台基于各用户的特征数据计算各用户的多种所述营销指标对应的待存放分片表ID,包括:
步骤2141、通过所述实时计算平台基于FNV1_32_HASH方法计算各用户的特征数据的哈希值;
步骤2142、通过所述实时计算平台基于所述分片表ID的总数量对所述各用户的特征数据的哈希值进行取余运算,得到各用户的多种所述营销指标对应的待存放分片表ID。
其中,用户的特征数据可以是表示用户唯一性的数据,如用户的手机号码,用户的身份证号码等。本申请实施例采用用户的手机号码为特征数据,
例如,初始化的用户的手机号码的hash=2166136261,对字符串2166136261进行循环,取出单个字节,hash结果为32位无符号整型,因此需要舍弃高位,保留低32位:
hash=(2166136261*16777619)mod 2^32=0x050c5d1f
再对其异或运算,将0x56转化为32位的值0x00000056,然后进行异或运算:最终hash=0x050c5d1f xor 0x00000056=0x050c5d49
通过所述实时计算平台基于FNV1_32_HASH方法计算各用户的特征数据的哈希值的步骤通过代码表示为:
通过从上述FNV1_32_HASH方法得出用户的特征数据的哈希值后,依据分片表ID的总数量,对用户的特征数据的哈希值取余,计算数据最终落入的待存放分片表ID。
例如,请参照图7,FEED_BACK_USR_LOG分为32个片,如FEED_BACK_USR_LOG_000、FEED_BACK_USR_LOG_001、……、FEED_BACK_USR_LOG_031。以用户手机号码的哈希值%32定位出用户的手机号码的多种营销指标存放的位置,那么对应的余数可定位出该用户的手机号码的多种营销指标所处的分片表ID(或称分片表的表名)。
步骤215、通过所述实时计算平台基于所述待存放分片表ID查询所述各个分片表ID对应的目标分布式节点ID,得到各用户的所述多种营销指标在所述分布式数据库的待存放节点位置。
电子设备通过所述实时计算平台基于所述待存放分片表ID查询所述各个分片表ID对应的目标分布式节点ID,得到各用户的所述多种营销指标在所述分布式数据库的待存放节点位置。
例如,当用户的手机号码12345678911计算用户的多种所述营销指标对应的待存放分片表ID为FEED_BACK_USR_LOG_001时。由各个分片表ID对应的目标分布式节点ID可知,分片表ID FEED_BACK_USR_LOG_001的哈希值对应分布式节点1。因此,确定用户的手机号码12345678911对应的用户的多种营销指标应存放入分布式数据库的分布式节点1的分片表ID为FEED_BACK_USR_LOG_001的分片表。
步骤220、通过所述实时计算平台将待存放节点位置相同的用户的所述多种营销指标聚合形成数据流;
电子设备通过所述实时计算平台将待存放节点位置相同的用户的所述多种营销指标聚合形成数据流。
依据上述步骤计算出来的各个用户的多种所述营销指标对应的待存放分片表ID,采用实时计算平台SparkStreaming的分组算子,将待存放分片表ID相同的数据聚合,以实现将同一待存放分片表ID的数据汇聚,以便于实时计算平台SparkStreaming的Executor对应单库操作,使得Executor与分布式节点产生对应关系。
步骤230、通过所述实时计算平台将各所述待存放节点位置的所述数据流并行写入至所述分布式数据库对应的分布式节点。
电子设备通过所述实时计算平台将各所述待存放节点位置的所述数据流并行写入至所述分布式数据库对应的分布式节点。
为了加速数据入库,改成分布式数据库主节点的单节点入库的方式,基于工作节点并行流式入库,依据待存放分片表ID汇聚的微批量数据,构建字节内存流,将属于同一待存放分片表ID的各个用户的多种营销指标以字节内存流的方式保存于Executor中,再通过分布式数据库提供的DLL函数,从内存中将字节内存流提交至分布式数据库的对应分布式节点,实现实时数据秒级入库。
从而本申请实施例充分利用分布式数据库优势,多个用户的营销产品的多种营销指标以数据分片方式实现实时并行写入至分布式数据库对应的分布式节点,实现营销指标实时入库。本申请实施例基于营销指标的流式并行入库,解决分布式关系型数据库单节点入库问题,提升数据入库实时性,能满足秒级实时营销指标查询的效果。
在本申请实施例的其他方面,步骤200、所述通过实时计算平台接收所述多种营销指标之后,还包括:
步骤201、确定预设解析规则和预设清洗规则,将预设解析规则和预设清洗规则广播至所述实时计算平台的各个执行节点;
步骤202、通过各个所述执行节点基于预设解析规则对各所述营销指标中的字段进行解析;
步骤203、通过各个所述执行节点基于预设清洗规则对解析后各所述营销指标中的字段进行清洗。
电子设备通过实时计算平台SparkStreaming实时通过kafka集群读取渠道反馈的多个用户的多种营销指标,通过预加载方式将营销指标的预设解析规则,预设清洗规则,加载至SparkStreaming应用,同时将其广播至各个执行节点,从而加速计算效率减少数据库IO。
电子设备通过实时计算平台实时获取多个用户的多种营销指标,依据预设解析规则对字段进行必要的解析,清洗关键字段:营销活动编码、客户群编码、流量产品编码、用户手机号码、流量产品推送时间、渠道编号、广告位编码、用户响应内容、响应时间、响应结果、归属地市;并且基于预设清洗规则剔数不符合数据规则的数据,如:无号码、无产品编码、无活动编码、无渠道编码、无响应结果的数据。
本申请实施例的营销指标实时聚合方法具有以下有益效果:
1.数据实时性得到充分提升,解决文本传输滞后问题,通过实时采集、实时入库、实时计算方式快速计算指标,解决营销指标评估滞后问题,可达到实时调整实时营销策略的效果;
2.解决数据库入库瓶颈,充分利用分布式数据库优势,以数据分片方式实现多分布式节点的数据入库;
3.解决传统物化视图数据需要手动刷新,并在刷新加载过程中数据库性能消耗大的问题,采用实时物化视图,以低消耗方式实现数据自动更新,实时查询展示营销指标。
下面对本申请实施例提供的营销指标实时聚合装置进行描述,下文描述的营销指标实时聚合装置与上文描述的营销指标实时聚合方法可相互对应参照。
请参照图8,本申请实施例提供一种营销指标实时聚合装置,包括:
采集模块201,用于通过实时采集平台实时采集多个用户的营销产品的多种营销指标;
入库模块202,用于通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;
实时物化视窗实时显示模块203,用于通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
本申请实施例提供的营销指标实时聚合装置,通过实时采集平台实时采集多个用户的营销产品的多种营销指标,从而本申请实施例实现多个用户的多种营销指标的实时采集;又通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;从而本申请实施例充分利用分布式数据库优势,多个用户的营销产品的多种营销指标以数据分片方式实现实时并行写入至分布式数据库对应的分布式节点,又通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。本申请实施例采用实时物化视图,以低消耗方式实现营销指标的自动更新,便于实时查询、展示及评估营销指标。
在一个实施例中,所述入库模块,包括:
待存放节点位置计算模块,用于通过所述实时计算平台基于一致性哈希方法计算各用户的所述多种营销指标在所述分布式数据库的待存放节点位置;
数据聚合模块,用于通过所述实时计算平台将待存放节点位置相同的用户的所述多种营销指标聚合形成数据流;
数据流式入库模块,用于通过所述实时计算平台将各所述待存放节点位置的所述数据流并行写入至所述分布式数据库对应的分布式节点。
在一个实施例中,所述待存放节点位置计算模块,包括:
数据读取模块,用于通过所述实时计算平台读取所述分布式数据库的多个分片表ID、分片表ID的总数量、以及多个分布式节点ID;
目标分布式节点ID确定模块,用于通过所述实时计算平台基于一致性哈希方法实时计算所述各个分片表ID对应的目标分布式节点ID;
数据存储模块,用于通过所述实时计算平台实时存储所述各个分片表ID对应的目标分布式节点ID;
待存放分片表ID计算模块,用于通过所述实时计算平台基于各用户的特征数据计算各用户的多种所述营销指标对应的待存放分片表ID;
查询模块,用于通过所述实时计算平台基于所述待存放分片表ID查询所述各个分片表ID对应的目标分布式节点ID,得到各用户的所述多种营销指标在所述分布式数据库的待存放节点位置。
在一个实施例中,所述目标分布式节点ID确定模块,包括:
第一哈希值计算模块,用于通过所述实时计算平台计算各分片表ID的哈希值;
最终目标分布式节点ID确定模块,用于通过所述实时计算平台将各所述哈希值放置于哈希环中,在哈希环上顺时针查找距离所述各分片表ID的哈希值最近的分布式节点ID,并确定距离所述各分片表ID的哈希值最近的分布式节点ID为各分片表ID对应的目标分布式节点ID。
在一个实施例中,待存放分片表ID计算模块包括:
第二哈希值计算模块,用于通过所述实时计算平台基于FNV1_32_HASH方法计算各用户的特征数据的哈希值;
最终待存放分片表ID计算模块,用于通过所述实时计算平台基于所述分片表ID的总数量对所述各用户的特征数据的哈希值进行取余运算,得到各用户的多种所述营销指标对应的待存放分片表ID。
在一个实施例中,所述营销指标实时聚合装置还包括:
规则确定模块,用于确定预设解析规则和预设清洗规则,将预设解析规则和预设清洗规则广播至所述实时计算平台的各个执行节点;
解析模块,用于通过各个所述执行节点基于预设解析规则对各所述营销指标中的字段进行解析;
清洗模块,用于通过各个所述执行节点基于预设清洗规则对解析后各所述营销指标中的字段进行清洗。
图9示例了一种电子设备的实体结构示意图,如图9所示,该电子设备可以包括:处理器(processor)910、通信接口(Communication Interface)920、存储器(memory)930和通信总线940,其中,处理器910,通信接口920,存储器930通过通信总线940完成相互间的通信。处理器910可以调用存储器930中的计算机程序,以执行营销指标实时聚合方法的步骤,例如包括:通过实时采集平台实时采集多个用户的营销产品的多种营销指标;通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
此外,上述的存储器930中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
另一方面,本申请实施例还提供一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序可存储在非暂态计算机可读存储介质上,所述计算机程序被处理器执行时,计算机能够执行上述各实施例所提供的营销指标实时聚合方法的步骤,例如包括:
通过实时采集平台实时采集多个用户的营销产品的多种营销指标;通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
另一方面,本申请实施例还提供一种处理器可读存储介质,所述处理器可读存储介质存储有计算机程序,所述计算机程序用于使处理器执行上述各实施例提供的方法的步骤,例如包括:通过实时采集平台实时采集多个用户的营销产品的多种营销指标;通过实时计算平台接收所述多种营销指标,并通过所述实时计算平台以数据流的形式将多个用户的所述多种营销指标实时并行写入至分布式数据库的对应的分布式节点;通过实时物化视窗实时显示所述分布式数据库的各个分布式节点的所述多种营销指标。
所述处理器可读存储介质可以是处理器能够存取的任何可用介质或数据存储设备,包括但不限于磁性存储器(例如软盘、硬盘、磁带、磁光盘(MO)等)、光学存储器(例如CD、DVD、BD、HVD等)、以及半导体存储器(例如ROM、EPROM、EEPROM、非易失性存储器(NANDFLASH)、固态硬盘(SSD))等。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 一种利用回转窑工艺添加石灰石制备高赤铁矿自熔性球团矿的方法
- 一种利用红曲发酵麦胚红枣山药制备无桔霉素发酵液方法
- 一种老面面包复合发酵剂及制备方法、应用和利用其制备的面包
- 一种利用发酵工艺制备高稳定性普伐他汀的方法
- 一种利用发酵工艺制备高稳定性普伐他汀的方法