一种面板数字识别与按取方法
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及面板数字按键识别与按取,尤其涉及一种面板数字识别与按取方法。
背景技术
目标检测与识别是计算机视觉的重要组成部分,也是其主要应用部分之一。随着人工智能技术的高速发展,计算机视觉也得到了迅速的发展,例如在人脸识别、工业智能检测、自动驾驶、图像识别行为分析等领域得到了很好的应用。例如,将目标检测与识别应用于机器人、机械臂等自动按取控制面板相应按键,以实现自动控制和自动操作等目的,但是由于控制面板的数字容易受到光照强度、图像采集角度、物体本身的形状等各种因素的影响,导致识别和按取速度慢、准确率低等问题。
发明内容
为了解决上述技术问题的至少一个,本发明提供了一种面板数字识别与按取方法。
本发明的技术方案是这样实现的:
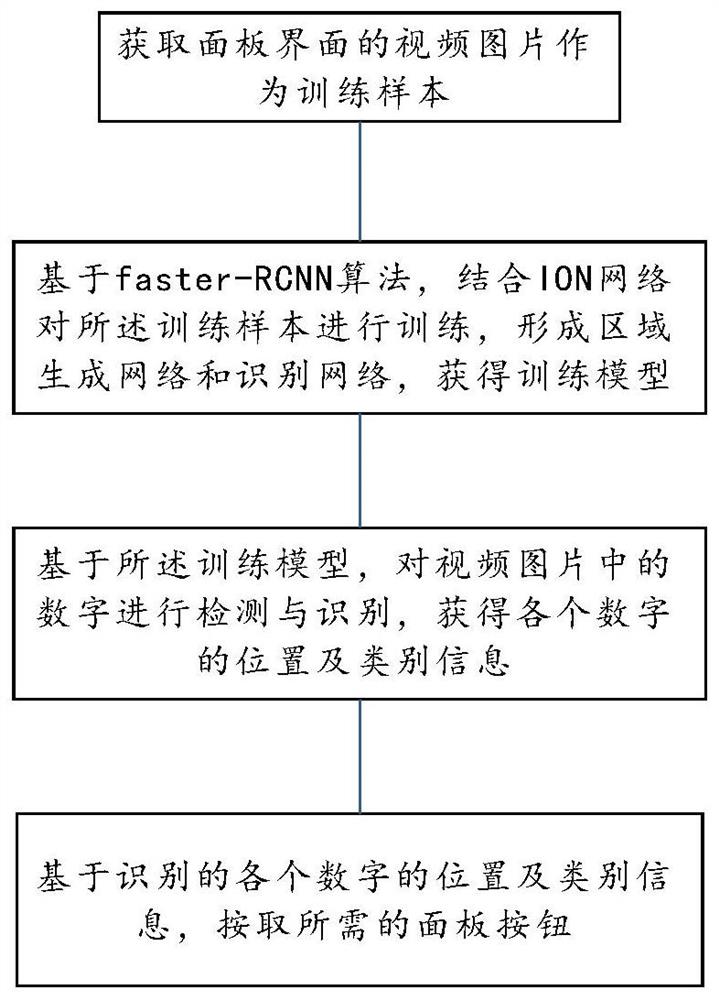
一种面板数字识别与按取方法,包括:
获取面板界面的视频图片作为训练样本,其中,所述视频图片中包括面板的数字;
基于faster-RCNN算法,结合ION网络对所述训练样本进行训练,形成区域生成网络和识别网络,获得训练模型;
基于所述训练模型,对视频图片中的数字进行检测与识别,获得各个数字的位置及类别信息;
基于识别的各个数字的位置及类别信息,按取所需的面板按钮。
进一步地,所述基于faster-RCNN算法,结合ION网络对所述训练样本进行训练的方法包括:
基于faster-RCNN算法,生成候选区域;
在所述候选区域内,通过连接不同Scale下的Feature Map,实现多尺度特征融合;
在所述候选区域外,基于目标数字的上下文信息,通过添加两个RNN层提取上下文特征。
进一步地,所述在所述候选区域内,通过连接不同Scale下的Feature Map,实现多尺度特征融合,包括:
利用Skip-pooling,从faster-RCNN网络的conv3-4-5-context分别提取特征。
进一步地,所述获取面板界面的图片作为训练样本包括:
利用摄像头采集面板上包含数字的视频,并对视频进行反交错处理后,获取数张视频图片;
对所有所述视频图片中的数字位置及类别通过标签标定;
预设若干包括面板数字的训练图片,将所述训练图片与所述视频图片混合,并对所述训练图片中的数与类别通过标签标定;
标定后的所述视频图片和标定后的所述训练图片作为训练样本。
进一步地,所述区域生成网络与所述识别网络交替训练,并共享视频图像深层次特征的数层卷积层。
进一步地,基于faster-RCNN算法,结合ION网络对所述训练样本进行训练,形成区域生成网络和识别网络,获得训练模型,包括:
分配正anchor,并同步分配负anchor,形成正负样本;
把正负样本输入到模型中,得到一个输出;
利用损失函数计算该输出和真正的标签值之间的损失。
进一步地,所述分配正anchor包括:
首先给每一个Ground Truth匹配一个anchor box,取具有两者之间的最大IOU的anchor box;
然后用剩下的anchor box匹配所有Ground Truth,取IOU大于0.7的anchor box;
将所述anchor box作为正anchor,并将objectness分数设置为1。
进一步地,所述分配负anchor包括:
用剩下的anchor box匹配所有Ground Truth,取IOU小于0.3的anchor box;
将所述anchor box作为负anchor,并将ojectness分数设置为0。
进一步地,所述利用损失函数计算该输出和真正的标签值之间的损失,包括:
通过以下函数计算总损失:
其中,i是一个mini-batch中anchor的索引,pi是预测出的第i个anchor对应的边界框的objectness分数,pi*是第i个anchor真正的objectness分数;ti是一个参数化的向量,其值为第i个anchor预测出的边界框的坐标,ti*是第i个正anchor与当前ground truth的参数化向量;Lcls是log损失函数;Lreg是smoothL1损失函数;
所述log损失函数如下:
所述smoothL1损失函数如下:
x=t
t
t
log(h
t
t
其中,x,y,w,h表示Bbox的坐标和宽高,x,x
附图说明
附图示出了本发明的示例性实施方式,并与其说明一起用于解释本发明的原理,其中包括了这些附图以提供对本发明的进一步理解,并且附图包括在本说明书中并构成本说明书的一部分。
图1是本发明的面板数字识别与按取方法的流程示意图;
图2是ION网络原理示意图;
具体实施方式
下面结合附图和实施方式对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施方式仅用于解释相关内容,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分。
需要说明的是,在不冲突的情况下,本发明中的实施方式及实施方式中的特征可以相互组合。下面将参考附图并结合实施方式来详细说明本发明。
实施例一
参照图1和图2,本实施例提供一种面板数字识别与按取方法,包括:
获取面板界面的视频图片作为训练样本,其中,所述视频图片中包括面板的数字;
基于faster-RCNN算法,结合ION网络对所述训练样本进行训练,形成区域生成网络和识别网络,获得训练模型;
基于所述训练模型,对视频图片中的数字进行检测与识别,获得各个数字的位置及类别信息;
基于识别的各个数字的位置及类别信息,按取所需的面板按钮。
本实施例通过利用faster-RCNN的训练框架,并引入ION,新的区域候选网络(Region Proposal Network,RPN)在生成ROI时效率更高;通过交替训练,使RPN和Fast-R-CNN网络共享参数,检测识别效率高、准确率也高。
Faster R-CNN可以简单看做是“区域生成网络(RPN)+fast R-CNN“的系统,faster_rcnn首先使用一组基础conv+relu+pooling层提取image的feture map,然后区域生成网络RPN网络用于生成region proposcals。该层通过softmax判断anchors属于foreground或者background,再利用box regression修正anchors获得精确的。RoiPooling层收集输入的feature map和proposcal,综合这些信息提取proposal featuremap,送入后续的全连接层判定目标类别。利用proposal feature map计算proposcal类别,同时再次bounding box regression获得检验框的最终精确地位置。新的候选区域网络(RPN)在生成ROI时效率更高。同时faster-rcnn改进算法ION网络算法,不仅可以提升对小目标的检测精度,而且还可以对目标被遮挡的物体有比较好的适应。
所述基于faster-RCNN算法,结合ION网络对所述训练样本进行训练的方法包括:
基于faster-RCNN算法,生成候选区域;
在所述候选区域内,通过连接不同Scale下的Feature Map,实现多尺度特征融合;本实施例中利用Skip-pooling,从faster-RCNN网络的conv3-4-5-context分别提取特征。多尺度特征能够提升对小目标的检测精度。
在所述候选区域外,基于目标数字的上下文信息,通过添加两个RNN层提取上下文特征。通过添加了两个RNN层实现上下文特征提取。上下文信息对于目标遮挡有比较好的适应。
通过本实施例的上述方案,可使得机器人对面板上的数字识别不受光照强度等外界因素的影响的同时,更加快速准确的识别面板上的数字,进而高效的采取其它相关动作。
作为本实施例的优选实施方式,所述获取面板界面的图片作为训练样本包括:
利用摄像头采集面板上包含数字的视频,并对视频进行反交错处理后,获取数张视频图片;
对所有所述视频图片中的数字位置及类别通过标签标定;
预设若干包括面板数字的训练图片,增加训练样本的同时提高模型的泛化性,将所述训练图片与所述视频图片混合,并对所述训练图片中的数与类别通过标签标定;
标定后的所述视频图片和标定后的所述训练图片作为训练样本。
其中,对获取的所有视频图片通过等时间隔上传到系统,以实时采集面板视频中的数字,如果该上传图片被读取,则调用训练模型对视频中的数字进行检测与识别,输出图片中各个数字的位置及类别信息;如果该上传图片未被读取,则忽略该上传的图片,以此类推,完成数字识别;在机器人应用中,可通过机器人手爪自动按动面板按钮,关闭数字识别模式,完成最终利用机器人基于深度学习方法对面板视频中数字的识别及采取相关动作的任务。
作为本实施例的优选实施方式,所述区域生成网络与所述识别网络交替训练,并共享视频图像深层次特征的数层卷积层。通常情况下,可共享视频前是多层卷积层。
基于faster-RCNN算法,结合ION网络对所述训练样本进行训练,形成区域生成网络和识别网络,获得训练模型,包括:
分配正anchor,并同步分配负anchor,形成正负样本;
把正负样本输入到模型中,得到一个输出;
利用损失函数计算该输出和真正的标签值之间的损失。
所述分配正anchor包括:
首先给每一个Ground Truth匹配一个anchor box,取具有两者之间的最大IOU的anchor box;
然后用剩下的anchor box匹配所有Ground Truth,取IOU大于0.7的anchor box;
将以上符合条件的anchor box作为正anchor,并将objectness分数设置为1。
所述分配负anchor包括:
用剩下的anchor box匹配所有Ground Truth,取IOU小于0.3的anchor box;
将以上符合条件的anchor box作为负anchor,并将ojectness分数设置为0。
所述利用损失函数计算该输出和真正的标签值之间的损失,包括:
通过以下函数计算总损失:
其中,i是一个mini-batch中anchor的索引,pi是预测出的第i个anchor对应的边界框的objectness分数,pi*是第i个anchor真正的objectness分数;ti是一个参数化的向量,其值为第i个anchor预测出的边界框的坐标,ti*是第i个正anchor与当前ground truth的参数化向量;Lcls是log损失函数;Lreg是smoothL1损失函数;
所述log损失函数如下:
所述smoothL1损失函数如下:
x=t
t
t
t
t
其中,x,y,w,h表示Bbox的坐标和宽高,x,x
本公开把深度学习算法识别模型应用在面板视频数字识别领域,提高了机器人工作效率与准确度。与常规方法模型相比,本公开的方法识别准确率及效率较高,且不受光照强度、图像采集角度、数字本身的形状的影响,使得机器人对面板上的数字识别在不受光照强度等外界因素影响的同时,可以更加快速准确识别面板上的数字,进而高效采取其它相关动作。
本领域的技术人员应当理解,上述实施方式仅仅是为了清楚地说明本发明,而并非是对本发明的范围进行限定。对于所属领域的技术人员而言,在上述发明的基础上还可以做出其它变化或变型,并且这些变化或变型仍处于本发明的范围内。
- 一种面板数字识别与按取方法
- 一种显示面板的取像方法及装置