视觉位置识别方法及装置、计算机设备及可读存储介质
文献发布时间:2023-06-19 10:08:35
技术领域
本申请涉及机器视觉技术领域,特别涉及一种视觉位置识别方法、视觉位置识别装置、计算机设备及非易失性计算机可读存储介质。
背景技术
视觉位置识别在很多领域有重要的应用价值,例如,用于SLAM系统的闭环检测,还可以用于基于视觉内容的图像搜索,3D建模和车辆导航等。视觉位置识别面临着许多挑战,例如气候、光照引起的环境变化、动态物体遮挡、摄像机获取内容的不同角度、系统的实时性等均会对视觉位置识别的准确率产生影响。
目前,可以通过基于深度学习的视觉定位方法进行视觉位置识别。但是,目前基于深度学习的视觉定位方法存在一些问题,比如,这些方法中的模型的健壮性是以大量的内存为代价的,这些内存被深度网络的过多参数占用,从而导致特征提取时间长;此外,这些方法需要花费大量的精力来生成带标签的图像来训练模型。可以通过引入自编码器来解决上述问题。自编码器是一种无监督学习的深度网络模型。自编码器由编码器和解码器两部分组成。编码器将模型的输入压缩到一个深层的表达,再由解码器将其还原成输入的表示。然而,目前的自编码器通常使用传统的手工特征作为自编码器的约束条件,使得自编码器不能较好地提取场景的有效信息,视觉位置识别的准确率不高。
发明内容
本申请实施方式提供了一种视觉位置识别方法、视觉位置识别装置、计算机设备及非易失性计算机可读存储介质,以解决视觉位置识别的准确率不高的问题。
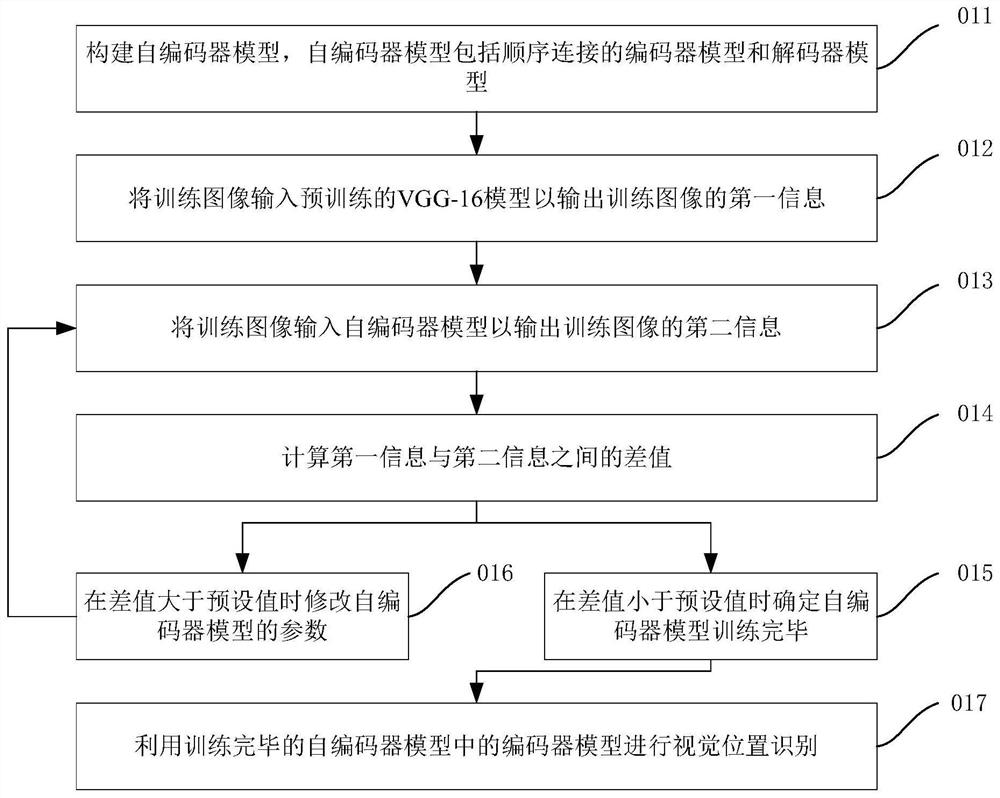
本申请实施方式的视觉位置识别方法包括:构建自编码器模型,所述自编码器模型包括顺序连接的编码器模型和解码器模型;将训练图像输入预训练的VGG-16模型以输出所述训练图像的第一信息;将所述训练图像输入所述自编码器模型以输出所述训练图像的第二信息;计算所述第一信息与所述第二信息之间的差值;在所述差值小于预设值时确定所述自编码器模型训练完毕;在所述差值大于预设值时修改所述自编码器模型的参数,并返回所述将所述训练图像输入所述自编码器模型以输出所述训练图像的第二信息的步骤;利用训练完毕的所述自编码器模型中的编码器模型进行视觉位置识别。
在某些实施方式中,所述编码器模型包括多个卷积层和多个池化层,所述解码器模型包括多个全连接层。
在某些实施方式中,至少一个所述卷积层中添加有惩罚项;和/或至少两个相邻的所述全连接层之间设置有丢弃层。
在某些实施方式中,所述计算所述第一信息与所述第二信息之间的差值,包括:利用L2损失函数计算所述第一信息与所述第二信息之间的差值。
在某些实施方式中,所述视觉位置识别方法在所述利用训练完毕的所述自编码器模型中的编码器模型进行视觉位置识别的步骤前,还包括:将测试图像输入训练完毕的所述自编码器模型中以获得所述测试图像的第三信息;将检索图像输入训练完毕的所述自编码器图像中以获得所述检索图像的第四信息;根据所述第三信息和所述第四信息计算所述测试图像与所述检索图像的相似度;根据所述相似度确定视觉位置识别结果;计算所述测试图像的索引与所述检索图像的索引之间的索引差值;根据所述索引差值确定所述视觉识别结果的准确度。
在某些实施方式中,所述根据所述第三信息和所述第四信息计算所述测试图像与所述检索图像的相似度,包括:根据所述第三信息和所述第四信息计算所述测试图像与所述检索图像的余弦相似度;所述根据所述相似度确定视觉位置识别结果,包括:在所述余弦相似度大于预设相似度时,确认所述测试图像与所述检索图像对应同一场景;在所述余弦相似度小于所述预设相似度时,确认所述测试图像与所述检索图像对应不同场景。
在某些实施方式中,所述根据所述索引差值确定所述视觉识别结果的准确度,包括:在所述索引差值小于预设索引差值时,确定所述视觉识别结果的准确度大于预定阈值;在所述索引差值大于所述预设索引差值时,确定所述视觉识别结果的准确度小于预定阈值。
本申请实施方式的视觉位置识别装置包括构建模块、第一输入模块、第二输入模块、第一计算模块、第一确定模块及识别模块。构建模块用于构建自编码器模型,所述自编码器模型包括顺序连接的编码器模型和解码器模型。第一输入模块用于将训练图像输入预训练的VGG-16模型以输出所述训练图像的第一信息。第二输入模块用于将所述训练图像输入所述自编码器模型以输出所述训练图像的第二信息。第一计算模块用于计算所述第一信息与所述第二信息之间的差值。第一确定模块用于:在所述差值小于预设值时确定所述自编码器模型训练完毕;在所述差值大于预设值时修改所述自编码器模型的参数,并返回所述将所述训练图像输入所述自编码器模型以输出所述训练图像的第二信息的步骤。识别模块用于利用训练完毕的所述自编码器模型中的编码器模型进行视觉位置识别。
本申请实施方式的计算机设备包括处理器、存储器及一个或多个程序,所述一个或多个程序存储在所述存储器中,所述一个或多个程序被所述处理器执行以实现上述任意实施方式所述的视觉位置识别方法。
本申请实施方式的非易失性计算机可读存储介质包含计算机程序。所述计算机程序被处理器执行时上述任意实施方式所述的视觉位置识别方法。
本申请实施方式的视觉位置识别方法、视觉位置识别装置、计算机设备及非易失性计算机可读存储介质基于深度网络VGG-16的特征作为约束条件来训练自编码器中的编码器,由此,通过深度网络特征代替传统手工特征,并通过自编码器实现对特征的进一步压缩,得到更精确强大的特征。提升了对光照和视角等影响的鲁棒性,取得了较高的视觉位置识别的准确率。
本申请实施方式的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
本申请的上述和/或附加的方面和优点可以从结合下面附图对实施方式的描述中将变得明显和容易理解,其中:
图1是本申请某些实施方式的视觉识别方法的流程示意图;
图2是本申请某些实施方式的视觉识别装置的模块示意图;
图3是本申请某些实施方式的视觉识别方法的原理示意图;
图4是本申请某些实施方式的视觉识别方法的流程示意图;
图5是本申请某些实施方式的视觉识别装置的模块示意图;
图6是本申请某些实施方式的视觉识别方法的原理示意图;
图7是本申请某些实施方式的计算机设备的示意图;
图8是本申请某些实施方式的非易失性计算机可读存储介质与处理器的交互示意图。
具体实施方式
下面详细描述本申请的实施方式,所述实施方式的示例在附图中示出,其中,相同或类似的标号自始至终表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本申请的实施方式,而不能理解为对本申请的实施方式的限制。
请参阅图1,本申请公开一种视觉位置识别方法,其特征在于,包括:
011:构建自编码器模型,自编码器模型包括顺序连接的编码器模型和解码器模型;
012:将训练图像输入预训练的VGG-16模型以输出训练图像的第一信息;
013:将训练图像输入自编码器模型以输出训练图像的第二信息;
014:计算第一信息与第二信息之间的差值;
015:在差值小于预设值时确定自编码器模型训练完毕;
016:在差值大于预设值时修改自编码器模型的参数,并返回将训练图像输入自编码器模型以输出训练图像的第二信息的步骤;
017:利用训练完毕的自编码器模型中的编码器模型进行视觉位置识别。
请参阅图2,本申请还公开一种视觉位置识别装置10。本申请实施方式的视觉位置识别方法可以由本申请实施方式的视觉位置识别装置10实现。视觉位置识别装置10包括构建模块111、第一输入模块112、第二输入模块113、第一计算模块114、第一确定模块115及识别模块116。步骤011可以由构建模块111实现。步骤012可以由第一输入模块112实现。步骤013可以由第二输入模块113实现。步骤014可以由第一计算模块114实现。步骤015和步骤016可以由第一确定模块115实现。步骤017可以由识别模块116实现。
也即是说,构建模块111可以用于构建自编码器模型,自编码器模型包括顺序连接的编码器模型和解码器模型。第一输入模块112可以用于将训练图像输入预训练的VGG-16模型以输出训练图像的第一信息。第二输入模块113可以用于将训练图像输入自编码器模型以输出训练图像的第二信息。第一计算模块114可以用于计算第一信息与第二信息之间的差值。第一确定模块115可以用于在差值小于预设值时确定自编码器模型训练完毕,在差值大于预设值时修改自编码器模型的参数,并返回将训练图像输入自编码器模型以输出训练图像的第二信息的步骤。识别模块116可以用于利用训练完毕的自编码器模型中的编码器模型进行视觉位置识别。
请结合图3,VGG-16模型为预训练好的模型。在一个例子中,VGG-16模型可以在ImageNet上进行权重训练,以使得预训练的VGG-16模型具备特征提取能力。VGG-16模型可以对图片进行高度的抽象特征的提取,这些特征概括了图像中一些的空间特性和形状特征,可以很大程度地减少由光照和角度变化引起的影响。例如,拍摄同一场景的两张图像,其中,A图像是在光照较强时拍摄的,B图像是在光照较弱时拍摄的,那么,A图像和B图像经过VGG-16模型提取的特征相差较小。自编码器模型包括编码器模型和解码器模型,编码器模型和解码器模型顺序连接。编码器模型包括多个卷积层及多个池化层,其中,卷积层的个数可以为3个或4个,池化层的个数也可以为3个或4个。在图3所示实施例中,卷积层的个数为4个,池化层的层数也为4个,每一个池化层附加于一个卷积层之后。卷积层的核数的取值范围可以为[4,256],在此不作限制。将卷积层的个数设置为4个,既可以避免卷积层的层数过少,导致的特征提取能力弱的问题,还可以避免卷积层的层数过多,特征提取速度慢的问题。解码器模型包括多个全连接层,其中,全连接层的个数可以为2个或3个。图3所示实施例中,全连接层的层数为2个,该2个全连接层的作用类似于上采样层和反卷积层,由于全连接层可以直接设置输出的维度,因此,使用2个全连接层可以在不计算具体卷积层的情况下输出想要的维度。
在构建好自编码器模型后,需要对自编码器模型进行训练。由于自编码器模型具有无监督特点,训练不需要大量带有标签的图片,因此,自编码器模型的训练重点放在对图像类型的选择上。训练集应该包括同一场景的各种状态下的图像,才能使自编码器模型对环境变化具有一定的鲁棒性。在一个例子中,可以选用Places365-Standard数据集作为训练集。Places365-Standard数据集包含180万张图像,这些图像来自365个不同的场景,每个场景提供了5000张不同状态的同类场景,将该数据集作为训练集,可以使得自编码模型可以提取出在同一场景下的显著的特征,从而实现很强的泛化能力。具体地,可以先对训练集中的图像进行缩放操作,例如将训练集中的图像缩放到大小为224x224x3,随后,再将缩放后的多张训练图像Im输入预训练的预训练的VGG-16模型以输出训练图像Im的第一信息V1(也可理解为标签),并将多张训练图像Im输入到自编码器模型中,以输出训练图像Im的第二信息V2,其中,第一信息V1和第二信息V2由向量表示。随后,可以计算第一信息V1与第二信息V2之间的差值,需要说明的是,此处用于计算差值的第一信息V1和第二信息V2对应同一幅训练图像Im。在一个例子中,可以利用L2损失函数计算第一信息V1与第二信息V2之间的差值,即||V1,V2||,L2损失函数常用于回归问题,通过L2损失函数,可以使得自编码器的输出尽可能拟合VGG-16的特征。具体地,若二者之间的差值小于或等于预设值,则确定自编码器模型训练完毕;若二者之间的差值大于预设值,则修改自编码器模型的参数(例如,修改自编码器模型的权重),并返回步骤013,需要说明的是,此时,训练图像Im是输入参数修改后的自编码器模型以输出训练图像Im的第二信息V2。如此循环往复,直至第一信息V1与第二信息V2之间的差值小于或等于预设值为止。可以理解,模型是否训练成功的评价标准是该模型的输出与模型对标的标签之间的差异。输出与标签的差值越小,则该模型的效果越好;差值越大,则该模型的效果越差。本申请实施方式中,自编码器模型为待训练的模型,VGG-16模型的输出为自编码器模型对标的标签。因此,可以通过自编码器模型输出的第二信息V2与VGG-16模型输出的第一信息V1之前的差值来评判自编码器模型的效果,当二者差值小于或等于预设值时,说明自编码器模型的效果较好,自编码器模型训练完毕。
进一步地,在训练时,还可以使用keras训练自编码器模型,使用具有0.001学习率的adam优化器以在训练时调整自编码器模型的参数以减小损失函数的值,还可以使用Earlystop技术,Earlystop为用于提前停止训练的函数,使得测试集的损失小于1.5时停止训练,从而避免训练时长过久使得自编码器模型把图像中一些无用的信息也当成有用信息,导致识别率降低的问题。整个训练过程大约需要花费8个epoch。其中,epoch表示训练的次数,训练时有365个场景,将每个场景有一个训练子集,将所有训练子集训练一次称为一个epoch。
在自编码器模型训练完毕之后,即可用训练完毕的自编码器模型中的编码器模型(也即训练完毕的编码器)进行视觉位置识别。具体地,以室内3D建模为例,用于室内3D建模的建模设备可以在室内行走并实时获取图像。该建模设备利用训练完毕的编码器模型对图像进行特征提取,并基于提取的特征进行图像匹配,从而可以确定获取的多张图像中,哪些图像指示相同的场景,并基于获取的图像和图像匹配的结果进行室内的3D建模。由于本申请实施方式的编码器模型提取的特征受光照和视角的影响较小,因此图像匹配的结果较为准确,进一步地,3D建模的结果也会更为准确。此外,由于编码器模型的卷积层数量较少,因此,特征提取时间减少,有利于提升图像匹配的速度,进一步地,降低3D建模所需的时间。
本申请实施方式的视觉位置识别方法及视觉位置识别装置10基于深度网络VGG-16的特征作为约束条件来训练自编码器中的编码器,由此,通过深度网络特征代替传统手工特征,并通过自编码器实现对特征的进一步压缩,得到更精确强大的特征。提升了对光照和视角等影响的鲁棒性,取得了较高的视觉位置识别的准确率。并且,由于编码器模型的卷积层数量较少,因此,特征提取时间减少,有利于提升视觉位置识别时图像匹配的速度。
在某些实施方式中,至少一个所述卷积层中添加有惩罚项;和/或至少两个相邻的所述全连接层之间设置有丢弃层。
其中,至少一个卷积层添加有惩罚项可以是其中一个卷积层添加有惩罚项,也可以是两个卷积层添加有惩罚项,还可以是三个卷积层添加有惩罚项,还可以是所有卷积层均添加有惩罚项等,在此不作限制。其中,惩罚项可以是L1正则化、L2正则化等,在此不作限制。通过添加惩罚项,可以避免自编码器模型的过度拟合。作为一个示例,惩罚项可以为L2正则化。可以理解,L2正则化即在原来的损失函数的基础上加上权重参数的平方和。L2正则化可以惩罚不重要的特征的权重,从而避免自编码器模型的过度拟合。
图3所示实施例中,全连接层的个数为两个,该两个全连接层之间可以增加丢弃层。丢弃层的层数可以是一层或多层,在此不作限制。丢弃层的丢弃率的取值可以为[0.5,0.8],不同丢弃层的丢弃率可以相同,也可以不同,在此也不作限制。在本申请的一个实施例中,两个全连接层之间设置有一层丢弃层,丢弃层的丢弃率为0.5。可以理解,丢弃层使得某两个神经元不一定每次都在同一个子网络结构中出现,这可以阻止某些特征仅仅在其他特征下才能有效的情况,迫使自编码器模型去学习更加具有通适性的特征,提升自编码器的特征提取效果。
请参阅图4,在某些实施方式中,视觉位置识别方法在利用训练完毕的自编码器模型中的编码器模型进行视觉位置识别的步骤前,还包括:
018:将测试图像输入训练完毕的自编码器模型中以获得测试图像的第三信息;
019:将检索图像输入训练完毕的自编码器图像中以获得检索图像的第四信息;
020:根据第三信息和第四信息计算测试图像与检索图像的相似度;
021:根据相似度确定视觉位置识别结果;
022:计算测试图像的索引与检索图像的索引之间的索引差值;
023:根据索引差值确定视觉识别结果的准确度。
进一步地,步骤020根据第三信息和第四信息计算测试图像与检索图像的相似度,包括:
根据第三信息和第四信息计算测试图像与检索图像的余弦相似度;
步骤021根据相似度确定视觉位置识别结果,包括:
在余弦相似度大于预设相似度时,确认测试图像与检索图像对应同一场景;
在余弦相似度小于预设相似度时,确认测试图像与检索图像对应不同场景。
步骤023根据索引差值确定视觉识别结果的准确度,包括:
在索引差值小于预设索引差值时,确定视觉识别结果的准确度大于预定阈值;
在索引差值大于预设索引差值时,确定视觉识别结果的准确度小于预定阈值。
请参阅图5,在某些实施方式中,视觉位置识别装置10还包括第三输入模块117、第四输入模块118、第二计算模块119、第二确定模块120、第三计算模块121及第三确定模块122。步骤018可以由第三输入模块117实现。步骤019可以由第四输入模块118实现。步骤020可以由第二计算模块119实现。步骤021可以由第二确定模块120实现。步骤022可以由第三计算模块121实现。步骤023可以由第三确定模块122实现。
也即是说,第三输入模块117可以用于将测试图像输入训练完毕的自编码器模型中以获得测试图像的第三信息。第四输入模块118可以用于将检索图像输入训练完毕的自编码器图像中以获得检索图像的第四信息。第二计算模块119可以用于根据第三信息和第四信息计算测试图像与检索图像的相似度。第二确定模块120可以用于根据相似度确定视觉位置识别结果。第三计算模块121可以用于计算测试图像的索引与检索图像的索引之间的索引差值。第三确定模块122实现可以用于根据索引差值确定视觉识别结果的准确度。
进一步地,第二计算模块119还可以用于根据第三信息和第四信息计算测试图像与检索图像的余弦相似度。第二确定模块120还可以用于在余弦相似度大于预设相似度时,确认测试图像与检索图像对应同一场景,在余弦相似度小于预设相似度时,确认测试图像与检索图像对应不同场景。第三确定模块122还可以用于在索引差值小于预设索引差值时,确定视觉识别结果的准确度大于预定阈值,在索引差值大于预设索引差值时,确定视觉识别结果的准确度小于预定阈值。
请结合图6,在自编码器模型训练完毕后,可以对训练完毕的自编码器模型中的编码器模型进行测试。测试图像也可以用Places365-Standard数据集中的图像。例如,可以将Places365-Standard数据集中的图像划分为训练集和测试集,由于Places365-Standard数据集中每个场景均有5000张图,则可以将其中的4200张图像作为训练集,800张图像作为测试集,测试集的图像不参与自编码器模型的训练。测试集中的图像进一步地又可以被分为测试图像集和检索图像集,测试图像集中的多张测试图像(图6所示的Queryimages)和检索图像集中的多张检索图像(图6所示的referenceimage)均为时序图像,且每张测试图像和每张检索图像均具有索引(也可以理解为编号)。例如,每一个测试集中的800张图像均被分为测试图像集和检索图像集,每一测试图像集中有400张图像,每一检索图像集中也有400张图像,对应于同一场景的测试图像集和检索图像集中,测试图像集中的400张测试图像可以为针对S场景在早上拍摄的多张连续图像,索引为1-400,检索图像集中的400张检索图像可以为针对该S场景在晚上拍摄的多张连续图像,索引为1-400。那么,测试前,可以先将测试集的所有图像进行缩放,例如缩放到224x224x3大小,随后,在测试时,可以选择多张(例如N x 224x224x3,N为正整数)测试图像输入到训练完毕的编码器模型中以获得第三信息(Qi),选择多张(例如N x 224x224x3,N为正整数)检索图像输入到训练完毕的编码器模型中以获得第四信息(Ri)。随后,根据第三信息和第四信息计算测试图像与检索图像之间的相似度,例如,可以根据公式(1)计算第三信息和第四信息计算测试图像与检测图像之间的余弦相似度:
通常地,当余弦相似度接近1时,说明两幅图像更有可能表示同一场景;当余弦相似度接近-1时,说明两幅图像更有可能表示不同场景。在本申请的一个实施例中,设定了预设相似度,例如可以为0.8或其他数值。若第三信息和第四信息的余弦相似度大于或等于预设相似度,则确认测试图像与检索图像对应同一场景;若二者的余弦相似度小于预设相似度,则确认测试图像与检索图像对应不同场景。由于是将多张测试图像和多张检索图像输入到训练完毕的编码器模型中,因此,可以根据多个第三信息和第四信息计算得到一个余弦相似度矩阵,余弦相似度矩阵中,每一行的最大值就是最优匹配。图3最右侧的图为测试图像与检索图像之间的余弦相似度矩阵对应的热力图,热力图用于显示两个数值之间的差异,当热力图的主对角线上的像素呈现为第一预定颜色,而其余位置处的像素呈现为第二预定颜色时,说明图像的匹配度较高。
由于测试集中的很多图像均为连续的序列图像,因此,可以添加一个容忍差(也即预设索引差值)来定义编码器模型是否识别出正确场景。容忍差可以被定义为公式(2):
|frame
也即是说,当测试图像的索引为3时,若其匹配到的检索图像的索引为5,5-3=2,2<4,则说明视觉识别的准确度高于预设阈值;若其匹配到的检索图像的索引为10,10-3=7,7>4,则说明视觉识别的准确度低于预设阈值。
综上,本申请实施方式的视觉位置识别方法及视觉位置识别装置10中,深度网络提取的特征相比传统手工特征具有更丰富的几何信息与语义信息,通过自编码器的架构,使模型学习深度网络特征更深层,更紧凑的表达。因此,本申请能够提取出场景图像中更加鲁棒的特征,达到与VGG-16相似的提取特征能力。相比深度网络VGG-16,减少了近4倍的特征提取时间。不但有效提高了在场景识别中的准确率,还减少了位置识别运行时间,满足了位置识别的实时性的要求。
请参阅图7,本申请实施方式还公开了一种计算机设备20。计算机设备20包括处理器21、存储器22及一个或多个程序。一个或多个程序存储在存储器22中,一个或多个程序被处理器21执行以实现上述任一实施方式所述的视觉位置识别方法。
例如,请结合图1和图7,一个或多个程序被处理器21执行以实现以下步骤:
011:构建自编码器模型,自编码器模型包括顺序连接的编码器模型和解码器模型;
012:将训练图像输入预训练的VGG-16模型以输出训练图像的第一信息;
013:将训练图像输入自编码器模型以输出训练图像的第二信息;
014:计算第一信息与第二信息之间的差值;
015:在差值小于预设值时确定自编码器模型训练完毕;
016:在差值大于预设值时修改自编码器模型的参数,并返回将训练图像输入自编码器模型以输出训练图像的第二信息的步骤;
017:利用训练完毕的自编码器模型中的编码器模型进行视觉位置识别。
请参阅图8,本申请实施方式还公开了一种非易失性计算机可读存储介质30。非易失性计算机可读存储介质30包含计算机程序。计算机程序被处理器21执行时实现上述任一实施方式所述的视觉位置识别方法。
例如,请结合图1和图8,计算机程序被处理器21执行时实现一下步骤:
011:构建自编码器模型,自编码器模型包括顺序连接的编码器模型和解码器模型;
012:将训练图像输入预训练的VGG-16模型以输出训练图像的第一信息;
013:将训练图像输入自编码器模型以输出训练图像的第二信息;
014:计算第一信息与第二信息之间的差值;
015:在差值小于预设值时确定自编码器模型训练完毕;
016:在差值大于预设值时修改自编码器模型的参数,并返回将训练图像输入自编码器模型以输出训练图像的第二信息的步骤;
017:利用训练完毕的自编码器模型中的编码器模型进行视觉位置识别。
在本说明书的描述中,参考术语“一个实施方式”、“一些实施方式”、“示意性实施方式”、“示例”、“具体示例”或“一些示例”等的描述意指结合所述实施方式或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施方式或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施方式或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施方式或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。
尽管上面已经示出和描述了本申请的实施方式,可以理解的是,上述实施方式是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施方式进行变化、修改、替换和变型。
- 视觉位置识别方法及装置、计算机设备及可读存储介质
- 位置识别方法、装置、设备及计算机可读存储介质