关系型数据库与大数据系统间的数据同步方法及系统
文献发布时间:2023-06-19 10:19:37
技术领域
本发明涉及大数据技术领域,尤其涉及一种关系型数据库与大数据系统间的数据同步方法及系统。
背景技术
现阶段,金融机构支付系统的交易数据主要还是集中在关系型数据库(例如,DB2数据库)上,可通过CDC实时同步到备库(例如,Oralce 12C数据库)进行备份,用以供其他信息类系统进行业务监控和数据采集分析。随着历史数据的积累以及日业务量的增加,备库已经很难承载日益增加的业务系统需求。
发明内容
本发明的一个目的在于提供一种关系型数据库与大数据系统间的数据同步方法,可实现关系型数据库与大数据系统间的数据实时同步,并保证数据同步过程的完整性。本发明的另一个目的在于提供一种关系型数据库与大数据系统间的数据同步系统。本发明的再一个目的在于提供一种计算机设备。本发明的还一个目的在于提供一种可读介质。
为了达到以上目的,本发明一方面公开了一种关系型数据库与大数据系统间的数据同步方法,包括:
通过多个线程分别获取Kafka Topic中的表数据;
对获取的表数据进行反序列化后写入HDFS临时目录;
多线程并发读取HDFS临时目录中的临时数据并将所述数据写入Hive中。
优选的,进一步包括:
针对每个Kafka Topic表数据所对应的HDFS临时目录的子目录创建对应的WAL日志;
当写入Hive出现异常中止时,根据所述WAL日志为HDFS临时目录的表数据确定下一个需要插入Hive的数据位置;
从所述数据位置开始继续进行并发写Hive操作。
优选的,进一步包括:
确定HDFS临时目录中已经写入HIVE的过期表数据;
通过清理线程清理所述过期表数据。
优选的,进一步包括:
通过所述表数据的主键参数对Hive中数据进行聚合;
对聚合后的数据根据数据写入HDFS临时目录时形成的时间戳进行排序,根据排序后的数据确定最后一次写入数据的数据形态;
将所述数据形态与关系型数据库表数据进行比对校验以确定Hive中数据是否完整。
优选的,所述通过多个线程分别获取Kafka Topic中的表数据具体包括:
通过HDFS Sink Connector插件建立多个任务线程,通过多个任务线程并行获取Kafka Topic中的数据并写入HDFS临时目录。
优选的,所述通过HDFS Sink Connector插件建立多个任务线程具体包括:
通过connector集群建立多个任务,每个任务为一个线程。
本发明还公开了一种关系型数据库与大数据系统间的数据同步系统,包括:
数据获取模块,用于通过多个线程分别获取Kafka Topic中的表数据;
临时数据模块,用于对获取的表数据进行反序列化后写入HDFS临时目录;
数据导入模块,用于多线程并发读取HDFS临时目录中的临时数据并将所述数据写入Hive中。
优选的,进一步包括日志记录模块,用于针对每个Kafka Topic表数据所对应的HDFS临时目录的子目录创建对应的WAL日志;当写入Hive出现异常中止时,根据所述WAL日志为HDFS临时目录的表数据确定下一个需要插入Hive的数据位置;从所述数据位置开始继续进行并发写Hive操作。
优选的,进一步包括数据清理模块,用于确定HDFS临时目录中已经写入HIVE的过期表数据;通过清理线程清理所述过期表数据。
优选的,进一步包括数据校验模块,用于通过所述表数据的主键参数对Hive中数据进行聚合;对聚合后的数据根据数据写入HDFS临时目录时形成的时间戳进行排序,根据排序后的数据确定最后一次写入数据的数据形态;将所述数据形态与关系型数据库表数据进行比对校验以确定Hive中数据是否完整。
优选的,所述数据获取模块具体用于通过HDFS Sink Connector插件建立多个任务线程,通过多个任务线程并行获取Kafka Topic中的数据并写入HDFS临时目录。数据导入模块
本发明还公开了一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,
所述处理器执行所述程序时实现如上所述方法。
本发明还公开了一种计算机可读介质,其上存储有计算机程序,
该程序被处理器执行时实现如上所述方法。
本发明通过多个线程并发读取Kafka中不同Topic中的表数据,将获取的表数据反序列化后写入HDFS临时目录。进一步通过多线程并发读取HDFS临时目录的临时数据并将临时数据写入Hive中,实现从Kafka到Hive中的数据同步,实现关系型数据库与大数据系统间的数据实时同步,并保证数据同步过程的完整性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例的流程图;
图2示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例S100的流程图;
图3示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例通过HDFS Sink Connector进行数据同步的流程图;
图4示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例S400的流程图;
图5示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例记录WAL日志的流程图;
图6示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例S500的流程图;
图7示出本发明关系型数据库与大数据系统间的数据同步方法一个具体实施例S600的流程图;
图8示出本发明关系型数据库与大数据系统间的数据同步系统一个具体实施例的结构图;
图9示出本发明关系型数据库与大数据系统间的数据同步系统一个具体实施例包括日志记录模块的结构图;
图10示出本发明关系型数据库与大数据系统间的数据同步系统一个具体实施例包括数据清理模块的结构图;
图11示出本发明关系型数据库与大数据系统间的数据同步系统一个具体实施例包括数据校验模块的结构图;
图12示出适于用来实现本发明实施例的计算机设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
由于目前备库很难满足日益增加的数据备份存储需求,于是希望逐步由大数据系统来替代备库的部分数据存储功能。当采用Oracle 12C数据库和Hadoop分布式文件系统(HDFS)的大数据系统时,需要实现数据从Oracle 12C到HDFS之间的实时数据同步。目前主流的Oracle(或者DB2)关系型数据库同大数据系统之间的数据实时同步工具比如IBM CDC,再比如Oracle OGG,都仅仅是把表数据以某种格式(如Avro)实时扔进消息队列Kafka的Topic中(比如关系型数据库中表table1的数据最终会以Avro格式进入Kafka队列:topic_table1中),而涉及数据从Kafka到HDFS再到Hive这一过程的数据格式转换、数据字段的映射、数据实时性以及数据完整性都没有相关技术保证。由此,本发明通过并发读取Kafka中不同Topic的数据(Avro格式),写入HDFS并以Parquet格式进行存储(Gzip压缩),再通过并发把数据映射到相对应的Hive表中,并按照指定列对数据进行分区存储,同时需要保证这一个过程的数据的实时性和完整性。
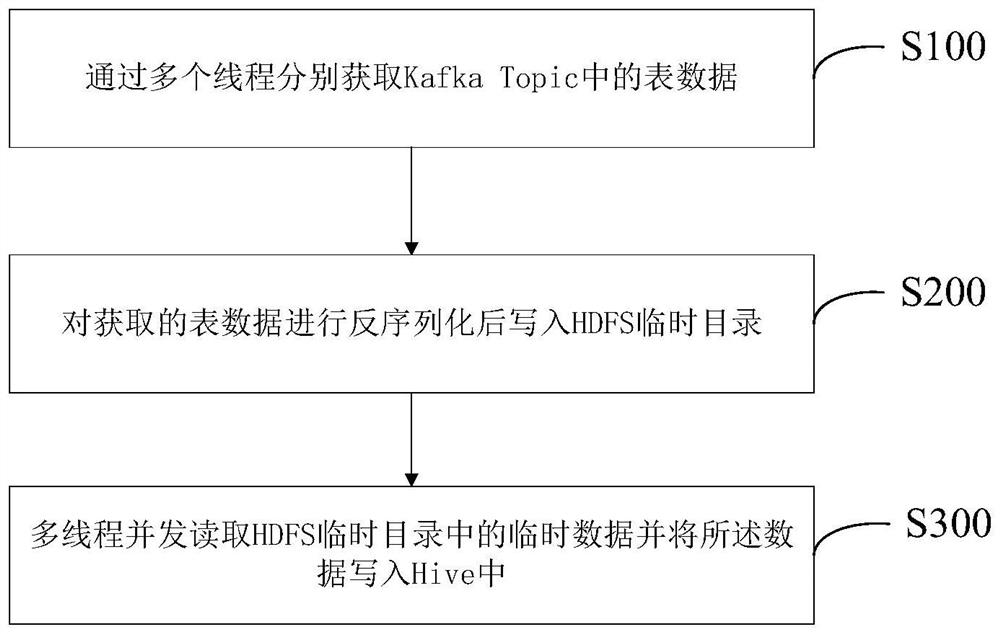
根据本发明的一个方面,本实施例公开了一种关系型数据库与大数据系统间的数据同步方法。如图1所示,本实施例中,所述方法包括:
S100:通过多个线程分别获取Kafka Topic中的表数据。
S200:对获取的表数据进行反序列化后写入HDFS临时目录。
S300:多线程并发读取HDFS临时目录中的临时数据并将所述数据写入Hive中。
本发明通过多个线程并发读取Kafka中不同Topic中的表数据,将获取的表数据反序列化后写入HDFS临时目录。进一步通过多线程并发读取HDFS临时目录的临时数据并将临时数据写入Hive中,实现从Kafka到Hive中的数据同步,实现关系型数据库与大数据系统间的数据实时同步,并保证数据同步过程的完整性。
在优选的实施方式中,如图2所示,所述S100中通过多个线程分别获取KafkaTopic表数据具体包括:
S110:通过HDFS Sink Connector插件建立多个任务线程。
S120:通过多个任务线程并行获取Kafka Topic中的数据并写入HDFS临时目录。
具体的,在该优选的实施方式中,如图3所示,Kafka Topic数据到HDFS的实时同步,引入了Connector框架的插件HDFS Sink Connector,建立起不同Kafka Topic到HDFS之间的实时数据管道。而CDC写入Kafka的数据,每一个Topic对应一张表(比如topic:topic_table1则对应表table1的数据),可针对每一个Topic建立了一个线程task(即Connector中一个数据处理线程),这个task负责把该Topic中的数据(Avro)反序列化后,实时或定时(例如,间隔2s)写入HDFS的临时目录中。
Kafka Topic中的数据通过Connector写入HDFS临时目录中,该目录在结构上会根据系统、表名或自然时间进行切割。其中,切割主要是针对一张数据表而言,按数据产生的时间分目录进行存储。比如oracle数据库中由表hvps.hvpszdt0101产生的流水数据,通过kafka落入HDFS数据会按数据产生的时间分散在多个目录下,目录结果可为:
hdfsbase/hvps/hvpszdt0101/20200714000500,
hdfsbase/hvps/hvpszdt0101/20200714001000,
hdfsbase/hvps/hvpszdt0101/20200714001500,
……。
这些目录下把由表hvps.hvpszdt0101产生的数据按照自然时间五分钟进行归类存储。
后续可通过导入工具(ImpData)并发读取HDFS临时目录中的数据,插入Hive中,这个过程中会涉及数据字段的映射,数据类型的转化以及Hive上分区字段的切割。这个导入工具是一个多线程并发处理数据的程序,该程序的并发数以及每个线程负责处理的表数据完全是通过一个Json配置文件驱动的,可根据不同表的数据量随时进行调整。比如对于数据量大的表,可配置每张表一个线程处理。而对于一些数据量较小的表,则可以配置为多张表一个线程处理,非常灵活便捷。其中,Json配置文件需要指定各线程task使用的connector插件(本实施例中为HDFSSinkConnector)、kafka topic、目标hdfs路径、反序列化方式和拉取频率等等。
在优选的实施方式中,所述S110中通过HDFS Sink Connector插件建立多个线程具体包括:
S111:通过connector集群建立多个任务,每个任务为一个线程。
可以理解的是,随着需要实时采集的表的增多,task数量急速增加。在一个具体例子中,通过引入了两台x86服务器搭建connector集群提供多个线程,不仅可以均衡每台服务器上的task数量,同时也保证任何一台机器宕机后,其上的task能动态迁移到另一台正常服务器上。其中,kafka connector是连接kafka集群和其他数据库、集群等系统的连接器,可以在多台服务器上启动多个connector服务形成一个集群,实际任务的执行是通过提交task(一个配置文件)到connector(随机选择)后开始执行任务。一个集群下的多台服务器上启动多个connector服务,一个connector服务可以执行过个task。Connector包括的启停、提交任务、暂停任务和恢复指定任务等控制都是有相应的rest触发。
在优选的实施方式中,如图4所示,所述方法进一步包括:
S410:针对每个Kafka Topic表数据所对应的HDFS临时目录的子目录创建对应的WAL日志。
S420:当写入Hive出现异常中止时,根据所述WAL日志为HDFS临时目录的表数据确定下一个需要插入Hive的数据位置。
S430:从所述数据位置开始继续进行并发写Hive操作。
如图5所示,当Kafka Topic的数据写入HDFS临时目录,该临时目录中会生成无数带时间戳的子目录,子目录中为该时间戳内产生的数据。为了保证导入操作的一致性和可恢复性,会为每一张数据表创建一个WAL(Write-Ahead Logging)日志,记录该表的导入过程,从而保证工具异常终止后重启依然可继续连续工作。具体的,WAL日志为每张数据表记录上一次写入HDFS临时目录时已成功导入完毕的HDFS临时目录。比如WAL日志的记录如下:
hvpszdt0101 hdfsbasedir/hvps/hvpszdt0101/20200714000500;
bepszdt0101 hdfsbasedir/beps/bepszdt0101/20200714000500;
当导入异常中止后,再一次启动的时候会已成功处理的目录的下一个目录开始进行导入处理。
在优选的实施方式中,如图6所示,所述方法进一步包括:
S510:确定HDFS临时目录中已经写入HIVE的过期表数据。
S520:通过清理线程清理所述过期表数据。
具体的,HDFS上的临时数据目录会随着时间快速堆积,为了不对正常的数据导入管道造成影响,该优选的实施方式中,通过建立一个清理线程对已经写入HIVE的过期的临时数据目录进行清理,防止对数据导入造成影响。
在优选的实施方式中,如图7所示,所述方法进一步包括:
S610:通过所述表数据的主键参数对Hive中数据进行聚合。
S620:对聚合后的数据根据数据写入HDFS临时目录时形成的时间戳进行排序,根据排序后的数据确定最后一次写入数据的数据形态。
S630:将所述数据形态与关系型数据库表数据进行比对校验以确定Hive中数据是否完整。
具体的,对于交易业务来说,Kafka同步后落入Hive的数据属于交易流水数据范畴,因此在关系型数据库中所看到的一笔记录在Hive中可能是好几条流水数据的叠加。在进行数据完整性校验的时候,需要先通过表主键参数对Hive中流水数据进行聚合后,再根据操作时间(Optime)清洗出每条业务数据最终的记录形态后,再同原表进行数据校验,例如,可通过数据中的笔数或者金额进行校验。其中,Optime为数据在源端关系型数据库产生的时间。其中,通过源端CDC输入Kafka的流水数据中每一条数据都包括了数据在源端(交易系统)的产生时间(optime)。例如,源端一张表有两列:column1(PK),column2,源端插入一条数据:A,B,源端更新数据A:A,C。则源端一次插入和更新操作通过cdc过来的数据为以下两条:
column1:A,column2:B,optime:时间戳,optype:insert
column1:A,column2:C,optime:时间戳,optype:update
由此,由于源端对于同一条数据的多次操作,在目标端HDFS会以多条记录的形式存在,即交易流水数据。目标端需要从中挑选这条数据的最终形态,采用的方式就是在目标端通过主键(此处为column1)对数据进行聚合,然后再通过时间戳(optime)进行排序,选择这条记录最后一次更新后的数据形态以进行数据完整性校验。
本发明通过Connector并发实时拉去Kafka topic(可达到约50个队列)表数据,将获取的表数据反序列化后写入HDFS临时目录。进一步并发读取HDFS临时目录的临时数据并将临时数据映射至Hive中以供后续查询,实现从Kafka到Hive中的数据同步,实现关系型数据库与大数据系统间的数据实时同步,整个过程可秒级完成。进一步对Hive中数据进行校验,以保证数据同步过程的完整性。适用于针对于源端数据库为关系型数据库的实时采集。本发明可实现关系型数据库秒级落大数据平台以供外部应用使用,可以极大的减轻备库的压力,把大部分基于备库的查询统计需求转移到大数据平台,还可以实现多种实时监控和风险管控的场景。
基于相同原理,本实施例还公开了一种关系型数据库与大数据系统间的数据同步系统。如图8所示,本实施例中,所述系统包括数据获取模块11、临时数据模块12和数据导入模块13。
其中,数据获取模块11用于通过多个线程分别获取Kafka Topic中的表数据。
临时数据模块12用于对获取的表数据进行反序列化后写入HDFS临时目录。
数据导入模块13用于多线程并发读取HDFS临时目录中的临时数据并将所述数据写入Hive中。
本发明通过多个线程并发读取Kafka中不同Topic中的表数据,将获取的表数据反序列化后写入HDFS临时目录。进一步通过多线程并发读取HDFS临时目录的临时数据并将临时数据写入Hive中,实现从Kafka到Hive中的数据同步,实现关系型数据库与大数据系统间的数据实时同步,并保证数据同步过程的完整性。
在优选的实施方式中,如图9所示,所述系统进一步包括日志记录模块14。日志记录模块14用于针对每个Kafka Topic表数据所对应的HDFS临时目录的子目录创建对应的WAL日志;当写入Hive出现异常中止时,根据所述WAL日志为HDFS临时目录的表数据确定下一个需要插入Hive的数据位置;从所述数据位置开始继续进行并发写Hive操作。如图5所示,当Kafka Topic的数据写入HDFS临时目录,该临时目录中会生成无数带时间戳的子目录,子目录中为该时间戳内产生的数据。为了保证导入操作的一致性和可恢复性,会为每一张数据表创建一个WAL(Write-Ahead Logging)日志,记录该表的导入过程,从而保证工具异常终止后重启依然可继续连续工作。
在优选的实施方式中,如图10所示,所述系统进一步包括数据清理模块15。数据清理模块15用于确定HDFS临时目录中已经写入HIVE的过期表数据;通过清理线程清理所述过期表数据。具体的,HDFS上的临时数据目录会随着时间快速堆积,为了不对正常的数据导入管道造成影响,该优选的实施方式中,通过建立一个清理线程对已经写入HIVE的过期的临时数据目录进行清理,防止对数据导入造成影响。
在优选的实施方式中,如图11所示,所述系统进一步包括数据校验模块16。数据校验模块16用于通过所述表数据的主键参数对Hive中数据进行聚合;对聚合后的数据根据数据写入HDFS临时目录时形成的时间戳进行排序,根据排序后的数据确定最后一次写入数据的数据形态;将所述数据形态与关系型数据库表数据进行比对校验以确定Hive中数据是否完整。
具体的,对于交易业务来说,Kafka同步后落入Hive的数据属于交易流水数据范畴,因此在关系型数据库中所看到的一笔记录在Hive中可能是好几条流水数据的叠加。在进行数据完整性校验的时候,需要先通过表主键参数对Hive中流水数据进行聚合后,再根据操作时间(Optime)清洗出每条业务数据最终的记录形态后,再同原表进行数据校验,例如,可通过数据中的笔数或者金额进行校验。其中,Optime为数据在源端关系型数据库产生的时间。其中,通过源端CDC输入Kafka的流水数据中每一条数据都包括了数据在源端(交易系统)的产生时间(optime)。由此,由于源端对于同一条数据的多次操作,在目标端HDFS会以多条记录的形式存在,即交易流水数据。目标端需要从中挑选这条数据的最终形态,采用的方式就是在目标端通过主键(此处为column1)对数据进行聚合,然后再通过时间戳(optime)进行排序,选择这条记录最后一次更新后的数据形态以进行数据完整性校验。
在优选的实施方式中,所述数据获取模块11具体用于通过HDFS Sink Connector插件建立多个任务线程,通过多个任务线程并行获取Kafka Topic中的数据并写入HDFS临时目录。
具体的,在该优选的实施方式中,如图3所示,Kafka Topic数据到HDFS的实时同步,引入了Connector框架的插件HDFSSinkConnector,建立起不同Kafka Topic到HDFS之间的实时数据管道。而CDC写入Kafka的数据,每一个Topic对应一张表(比如topic:topic_table1则对应表table1的数据),可针对每一个Topic建立了一个线程task(即Connector中一个数据处理线程),这个task负责把该Topic中的数据(Avro)反序列化后,实时或定时(例如,间隔2s)写入HDFS的临时目录中。
Kafka Topic中的数据通过Connector写入HDFS临时目录中,该目录在结构上会根据系统、表名或自然时间进行切割。其中,切割主要是针对一张数据表而言,按数据产生的时间分目录进行存储。
后续可通过导入工具(ImpData)并发读取HDFS临时目录中的数据,插入Hive中,这个过程中会涉及数据字段的映射,数据类型的转化以及Hive上分区字段的切割。这个导入工具是一个多线程并发处理数据的程序,该程序的并发数以及每个线程负责处理的表数据完全是通过一个Json配置文件驱动的,可根据不同表的数据量随时进行调整。比如对于数据量大的表,可配置每张表一个线程处理。而对于一些数据量较小的表,则可以配置为多张表一个线程处理,非常灵活便捷。其中,Json配置文件需要指定各线程task使用的connector插件(本实施例中为HDFSSinkConnector)、kafka topic、目标hdfs路径、反序列化方式和拉取频率等等。
可以理解的是,随着需要实时采集的表的增多,task数量急速增加。在一个具体例子中,通过引入了两台x86服务器搭建connector集群提供多个线程,不仅可以均衡每台服务器上的task数量,同时也保证任何一台机器宕机后,其上的task能动态迁移到另一台正常服务器上。其中,kafka connector是连接kafka集群和其他数据库、集群等系统的连接器,可以在多台服务器上启动多个connector服务形成一个集群,实际任务的执行是通过提交task(一个配置文件)到connector(随机选择)后开始执行任务。一个集群下的多台服务器上启动多个connector服务,一个connector服务可以执行过个task。Connector包括的启停、提交任务、暂停任务和恢复指定任务等控制都是有相应的rest触发。
由于该系统解决问题的原理与以上方法类似,因此本系统的实施可以参见方法的实施,在此不再赘述。
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机设备,具体的,计算机设备例如可以为个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。
在一个典型的实例中计算机设备具体包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述方法。
下面参考图12,其示出了适于用来实现本申请实施例的计算机设备600的结构示意图。
如图12所示,计算机设备600包括中央处理单元(CPU)601,其可以根据存储在只读存储器(ROM)602中的程序或者从存储部分608加载到随机访问存储器(RAM))603中的程序而执行各种适当的工作和处理。在RAM603中,还存储有系统600操作所需的各种程序和数据。CPU601、ROM602、以及RAM603通过总线604彼此相连。输入/输出(I/O)接口605也连接至总线604。
以下部件连接至I/O接口605:包括键盘、鼠标等的输入部分606;包括诸如阴极射线管(CRT)、液晶反馈器(LCD)等以及扬声器等的输出部分607;包括硬盘等的存储部分608;以及包括诸如LAN卡,调制解调器等的网络接口卡的通信部分609。通信部分609经由诸如因特网的网络执行通信处理。驱动器610也根据需要连接至I/O接口605。可拆卸介质611,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器610上,以便于从其上读出的计算机程序根据需要被安装如存储部分608。
特别地,根据本发明的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本发明的实施例包括一种计算机程序产品,其包括有形地包含在机器可读介质上的计算机程序,所述计算机程序包括用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分609从网络上被下载和安装,和/或从可拆卸介质611被安装。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
为了描述的方便,描述以上装置时以功能分为各种单元分别描述。当然,在实施本申请时可以把各单元的功能在同一个或多个软件和/或硬件中实现。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本申请,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 关系型数据库与大数据系统间的数据同步方法及系统
- 一种关系型数据库间结构化数据的同步方法及系统